
Abstract
In this paper we analyze several anisotropic bootstrap percolation models in three dimensions. We present the order of magnitude for the metastability thresholds for a fairly general class of models. In our proofs, we use an adaptation of the technique of dimensional reduction. We find that the order of the metastability threshold is generally determined by the ‘easiest growth direction’ in the model. In contrast to anisotropic bootstrap percolation in two dimensions, in three dimensions the order of the metastability threshold for anisotropic bootstrap percolation can be equal to that of isotropic bootstrap percolation.
Similar content being viewed by others

1 Introduction
In bootstrap percolation models on a finite cube [0,L]d∈ℤd, in the starting configuration every site is occupied with probability p, and empty otherwise, independent of all other sites.
The configuration then evolves according to the bootstrap rule: each site that has at least k occupied sites in its neighborhood becomes occupied, and occupied sites remain occupied. The rule will repeatedly be applied until no new site will become occupied. One is usually interested in the probability that the cube is internally spanned, that is, in the final configuration all sites are occupied. We will in this paper choose k to be half the number of sites in the neighborhood. In ordinary bootstrap percolation the neighborhood of a site consists of all its nearest neighbors. In anisotropic bootstrap percolation, however, the size or shape of the neighborhood is not equal in every direction. For earlier work on bootstrap percolation models, see e.g [2, 3, 14, 16, 20, 21, 24, 27–29].
Bootstrap percolation models and arguments have been applied in a variety of settings, from fluid dynamics, magnetic models, the theory of glasses, neural networks, the theory of sandpiles to rigidity theory and economics, see e.g. [1, 4, 10, 15, 18, 25, 26, 30].
Anisotropic bootstrap percolation models until now have been studied in two dimensions. For instance, Gravner and Griffeath [19] introduced the model where the neighborhood consists of six sites, namely, in the x direction only the nearest neighbors, but in the y direction both the nearest and the next-nearest neighbors. We will call this the (1,2) model. In this model (where k=3), an occupied rectangle can grow by the bootstrap rule most easily in the y direction. A single occupied site at distance 1 or 2 from the rectangle suffices to fill the next line segment in this direction, whereas in the x direction, two occupied sites with no more than three empty sites in between are needed to fill the next line segment. The behavior of this model is similar to that of the semi-oriented model studied in [14, 27, 29]; for a bootstrap rule whose anisotropy appears to be of qualitatively different type, as its asymptotics follows standard isotropic behavior, see [7].
We will study the following kind of anisotropic model (see Fig. 1): the neighborhood consists of the a-nearest neighbors in the x direction, the b-nearest neighbors in the y direction and the c-nearest neighbors in the z direction, with a≤b≤c, and we choose k=a+b+c. We will call this the (a,b,c) model. The notation (a,b) for two-dimensional models, like the (1,2) model of [19], is similar.

Illustration of the neighborhood of a site in the (2,3,4) model. The z axis is towards the reader
An important tool that we will use is dimensional reduction [28]. Suppose a certain sufficiently large (in all three directions) three-dimensional rectangular block is occupied. Then all sites in a slab (we call the set of sites outside the block that are adjacent to one of the faces, a slab), already have some number k′=a, b or c of occupied sites in the intersection of their neighborhood with the rectangular block. Thus, once the rectangular block is occupied, a slab in direction x will become occupied in the (a,b,c) model, if the slab is (internally) spanned in the (b,c) model. For the (a,b,c) model, we will call the (b,c) model the reduced model in the x direction, and likewise define the reduced models in the y and z directions.
Our main example is the (1,1,2) model. The (1,1,2) model has two hard growth directions and one easy one. Namely, in the z direction the reduced model is (1,1), but for the other directions it is (1,2). Our main result however is valid for all (a,b,c) models.
2 Terminology
In this section we present some common terms in bootstrap percolation, which we will use throughout the paper in the sense explained below.
Threshold lengths, sharp thresholds Call ℙ([0,L]d internally spanned) the probability that for a bootstrap percolation model on a finite cube [0,L]d, in the final configuration all sites are occupied. The typical behavior of bootstrap percolation models is that there is a sharp threshold length, this means that there is a function \(f(\frac{1}{p})\) such that, as p→0,

We will call \(e^{f(\frac{1}{p})}\) (in d=2), or \(e^{e^{f(\frac {1}{p})}}\) (in d=3) the threshold length L th(p).
Inversely, there is a percolation threshold p th (L)=Cg(L), such that asymptotically for increasing L for all positive ε the block will be internally spanned (and hence there will be of course percolation between opposite sides) if p>(1+ε)g(L) and no percolation if p<(1−ε)g(L), with high probability. The first proof of a sharp threshold length was for the isotropic model in dimension 2 by Holroyd [22]. Since then, several more sharp threshold results have been obtained [5, 6, 12, 13, 23, 24].
Order of threshold length There are many bootstrap percolation models for which there is no proof (yet) of a sharp threshold length. For some of those less precise results known, namely, lower and upper bounds for L th(p) similar to those of (2.1), but with different multiplicative constants γ and Γ>γ, namely:

In such a case we say that the order of the threshold length is known.
In this paper, we focus on \(f(\frac{1}{p})\), that is, orders of the threshold length of the following kind:
-
For (a,b) models, we are interested in the order of lnL th(p),
-
For (a,b,c) models, we are interested in the order of lnlnL th(p).
Indeed, our main result is the determination of the order of lnlnL th(p) for the general (a,b,c) model. However, since strictly speaking we do not prove that a sharp threshold length exists, we will not use this term in our theorem.
In the remainder of this paper, we will use subscripts a,b and a,b,c to refer to the (a,b) model resp. the (a,b,c) model. Sometimes we will use the term \(L^{\mathit{th}}_{a,b}(p)\) in cases where no sharp threshold result is known, that is, f a,b (1/p) is known only up to a constant. We will only use this abusive notation in cases where the constant is unimportant, to avoid cumbersome elaborations in terms of the lower and upper bounds.
We conjecture that in fact for all the models we consider, that is, every (a,b) model in two dimensions, and every (a,b,c) model in three dimensions, there exists a sharp threshold length.
Critical droplets Often, the proof for an upper bound L +(p) for L th(p) involves the notion of a “critical droplet”. This is an occupied connected set of sites of a size and shape such that, if all other sites in a finite or infinite lattice are independently occupied with probability p, then the droplet will continue to grow with high probability. Since the occurrence of such a critical droplet is (for fixed p) a local event, if L is large enough, that is to say L increases fast enough as p→0, then there will with high probability be a critical droplet in the volume of linear size L.
As a simple example, consider isotropic bootstrap percolation in one dimension, that is, on the interval [0,L]. Suppose that L increases faster than 1/p as p→0. In this case, the critical droplet is one occupied site. The probability that somewhere on the line there is an occupied site, tends to 1. Also, this critical droplet grows with probability 1: once there is at least one occupied site, then the whole line is spanned.
Note that there are multiple possibilities for choosing a critical droplet. The smaller the size of the critical droplet one chooses, the tighter upper bound for L th(p) one obtains. In this paper, our choice is always a certain occupied rectangle (rectangular block). (We expect that this choice of rectangles is not optimal; in studies such as [22] for example, the critical droplet is more subtle: it is a certain set of occupied sites such that a rectangle of size O(1/p) is internally spanned rather than fully occupied.)
Suppose the number of occupied sites in the critical droplet is V. Then the probability P that a fixed site is in a critical droplet, is of order p V. Then, disregarding some corrections due to the finite size of the droplet (which are negligible if L≫V, and p small):

where we used that \((1-P)^{\frac{1}{P}}\) tends to e −1 as p→0. We can alternatively interpret this formula as follows: suppose we have a Poisson point process with parameter P. Then the above probability is the probability that there is at least one Poisson point in the cube [0,L]d. For this reason, one also calls P the density of critical droplets. We see from this expression that ℙ([0,L]d i.s.) tends to 1 if L d tends to infinity faster than 1/P. We conclude that for every P denoting the density of a certain choice of critical droplets,

Inversely, we can say that if L<L −(p), then with high probability there is no critical droplet of any kind, so that for every choice of critical droplet, we have

Supercritical size We say that a volume is of supercritical size if the probability that it is internally spanned, tends to 1 as p→0 (we slightly abuse the term ‘size’, since actually the size is not fixed, but tends to infinity as p→0). For example, the volume [0,L]d, with L>L +(p), is of supercritical size, by the definition of L +(p). However, a volume of supercritical size does not need to be cubic. We will also consider rectangular volumes of supercritical size. For example, a rectangle is of supercritical size if it consists of at least (L +(p))d sites, and its shape is such that it is much larger than the critical droplet, in every direction.
3 Main result
Our main result is that the order of lnlnL th(p) for the general (a,b,c) model, depends only on a and b. We state this result as follows:
Theorem 3.1
For the (a,b,c) model, with a≤b≤c, there exist constants γ a,b,c and Γ a,b,c such that, as p→0,

where
-
if a=b then f a,a (1/p)=p −a+o(p −a),
-
of a<b then f a,b (1/p)=p −aln2 p+o(p −aln2 p).
Since the proof of this theorem involves dimensional reduction, we use information on f a,b (1/p), the order of the threshold length of the (a,b) model. In several cases a sharp threshold length is known, namely, for the (1,1) model [22] and for the (1,b) model with b>1 [12]. In these cases we can specify the constant Γ a,b,c . For example, it will turn out that if a=b=1, then the constant Γ1,1,c can be chosen to be twice the Holroyd constant \(2C_{H} = \frac{\pi^{2}}{9}\).
Furthermore, from the analysis of Duminil-Copin and Holroyd [11, 13], it follows that for the (a,a)-model a sharp threshold result holds, namely that there is a constant C such that (2.1) holds with \(f_{a,b}(\frac{1}{p}) = e^{Cp^{-a}+o(p^{-a})}\). We summarize the current knowledge in Table 1.
For the general case of the (a,b) model with 1<a<b it is not known whether a sharp threshold exists. For the (a,b) model with a<b, we derive the following result (see Sect. 4.2), which is sufficient for our purposes:
Claim 3.2
Let a<b, then for the (a,b) model, there exist constants γ a,b and Γ a,b , such that
Remark
For the (1,1,1) model, a sharp threshold result is already known [6]. One might expect that this result should give us a lower bound for γ a,b,c , since it seems natural to expect (and indeed we do) that an (a,b,c) model with a larger neighborhood should have more difficulty in growing, and in filling up a volume. However, a direct inequality is not that obvious. Indeed, as a pair of occupied sites on a line parallel to the y-axis at distance 4 in the (1,2)-model can cooperate, whereas they cannot in the (1,1)-model (as then they will never belong to the neighborhood of the same site) a configuration-wise ordering is excluded.
Thus, we present our intuition as a series of conjectures:
Conjecture 3.3
-
If a<b, then there is a constant C a,b such that

-
If b′>b, then C a,b′>C a,b .

Conjecture 3.4
-
There is a constant C a,b,c such that

where f a,b (1/p) is as in Theorem 3.1.
-
If a′≥a, b′>b, and c′≥c then \(\ln\ln L_{a',b',c'}^{\mathit{th}}(p) \geq\ln\ln L_{a,b,c}^{\mathit{th}}(p)\).

We expect that the first half of Conjecture 3.3 might be derived by extending the techniques from [12]. Indeed, by [12], the conjecture holds for a=1. Nevertheless, the full proof is outside the scope of the present paper.
4 The Lower Bound
We first explain the lower bound in the case (a,b,c)=(1,1,c) in some detail, as an instructive example.
4.1 The Lower Bound for the (1,1,c) Model
In this section, we show that for all L(p) larger than the value stated in Theorem 3.1, the probability that the configuration is internally spanned, tends to 1. We choose an occupied rectangular block as critical droplet. This rectangular block will keep growing if the areas of its faces are large enough. For instance, if the area of the face in the z direction is larger than \(e^{2C_{H}(1+\varepsilon)/p}\), then the slab next to it is spanned with high probability, because its size is supercritical for the (1,1) model.
Naively, one could suppose that we need a critical droplet with one face of supercritical size for the (1,1) model, and two of supercritical size for the (1,c) model. However, we can do better than that, following essentially the same line of thought as in [17] which is similar to that in [2] and which was based on an unpublished observation of Roberto Schonmann. There a suitable critical droplet for the (1,2) model was found to be a strip of length \(\frac {C'}{p} \ln\frac{1}{p}\), and width 2, with C′ a large enough constant. Clearly the width of this strip is not supercritical, but the strip grows with large probability into a rectangle of size \(\frac{C}{p} \ln \frac{1}{p}\) times \(\frac{1}{p^{2}}\), which is of supercritical size in both directions. The probability that such a critical droplet is at a fixed position, is \(p^{\frac{C'}{p} \ln\frac{1}{p}} = e^{-\frac{C'}{p} \ln^{2}\frac{1}{p}}\).
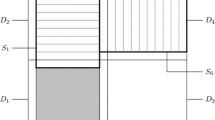
For the (1,1,c) model (Fig. 2), we choose as critical droplet a rectangular block of size N by N by 2, with N such that the droplet will grow sufficiently far in the z direction. More specifically, let us define

which is the probability that a fixed site is in a critical droplet in the (1,1) model. Then a square of size \(N^{2}\geq e^{\frac{2C_{H}(1+\varepsilon)}{p}}\) is supercritical for the (1,1) model, because with high probability there will be a critical droplet in it.

Illustration of how the critical droplet grows in the (1,1,c) model (not to scale). The z direction is towards the reader. First the droplet grows only in the z direction, then in all directions
We will choose N 2=(P 1,1)−(1+ε) slightly larger than minimally supercritical, because we need that many slabs of that size will get occupied with high probability, rather than just one. For our critical droplet to grow into a rectangular block with all faces of supercritical size, we need that M adjacent slabs get occupied with large probability, with M such that \(MN \geq(L^{\mathit {th}}_{1,c}(p))^{2}\). As was proved in [17] (and explained above), there is a constant Γ1,2 such that \(L^{+}_{1,2}(p) \leq e^{\frac{\Gamma _{1,2}}{p} \ln^{2} \frac{1}{p}}\). In [12], this result was extended: a sharp threshold length of the form \(L^{\mathit{th}}_{1,c}(p) =e^{\frac{C(c)}{p}\ln^{2} \frac{1}{p}}\) was found for all (1,c) models, where C(c) is a constant depending only on c. The probability that a slab contains a critical droplet for the (1,1) model is at least \(1-(1-P_{1,1})^{N^{2}}\), and therefore the probability that M slabs will get occupied, is at least \((1-(1-P_{1,1})^{N^{2}})^{M}\) (this all up to some irrelevant constants, due to the finite size of the droplets, possible overlapping of the droplets, etc.).
The logarithm of this probability is approximately \(-M e^{-P_{1,1} N^{2}} = -M e^{-(P_{1,1})^{-\varepsilon}} =-Me^{-e^{\frac{2C_{H}\varepsilon}{p}}}\), which is close to 0 for all \(M= o (e^{e^{\frac{2C_{H}\varepsilon}{p}}} )\). We see that it is possible for a critical droplet to grow to a size M large enough so that \(MN \geq(L^{\mathit{th}}_{1,c}(p))^{2}\) is satisfied.
Now we need to find a bound for L such that a cube [0,L]3 contains a critical droplet with high probability. This is the case if \(L^{3} \geq p^{-2N^{2}}\) (see (2.3)). We work out

which gives us the desired lower bound.
We remark that it is possible to refine this argument and obtain a smaller estimate for N. For instance, if we suppose that M=N k for some k, then we find that an N by N by 2 occupied rectangular block with \(N^{2} = \frac{k}{P_{1,1}} \ln\frac{1}{P_{1,1}}\) is sufficiently large to act as a critical droplet. However, this refinement leads to the same conclusion.
4.2 The Lower Bound in the General Case
We start with deriving Claim 3.1, that is, we derive some basic estimates for \(L^{-}_{a,b}(p)\) and \(L^{+}_{a,b}(p)\). Since the proof mostly consists of repeating work that has already been published, here we just sketch the steps that are needed. Namely, considering that
-
an occupied rectangle of size at least Cp −a×b, with C large enough, serves as a critical droplet, as such an occupied rectangle grows with high probability into an occupied rectangle of size \(Cp^{-a}\ln\frac{1}{p} \times p^{-b}\), in the same manner as the 2 by \(C\frac{1}{p} \ln\frac{1}{p}\) critical droplet of [17] (the generalization is straightforward),
-
the probability of a fixed \(2 \times C p^{-a}\ln\frac{1}{p}\) rectangle to be occupied, is \(p^{C p^{-a}\ln\frac{1}{p}} = e^{-C p^{-a}\ln^{2} \frac{1}{p}}\),
-
therefore, \(L^{+}_{a,b}(p) \leq e^{C p^{-a} \ln^{2} \frac{1}{p}}\),
and we obtained one of the inequalities.
For the bound in the other direction, again a generalization of the method of [17] for the (1,2) model is needed. First, we generalize (2) of [17] to (5.2) (this paper, Sect. 5.1). Then we repeat the calculation that leads to (5) of [17], replacing p 2 by \(\tilde{p}^{b}\) and p by \(\hat{p}^{a}\), and choosing \(x = C_{2} \frac{1}{p^{a}}\ln\frac{1}{p}\) and y=p −b+1/2 instead of choosing \(k=\frac{1}{p^{3/2}}\) and \(l = C_{2}\frac{1}{p} \ln\frac{1}{p}\). This will lead to the other inequality.
Now we get back to the (a,b,c) model in three dimensions. We will show that for all L growing faster than with the rate stated in Theorem 3.1, the probability that the configuration is internally spanned, tends to 1. Suppose that there is an occupied rectangular block in the cube [0,L]3, then for each direction, the size of its face will determine whether it will grow easily in that direction (also, the width of the rectangular block should be large enough; width c is sufficient). For an occupied rectangular block to serve as a critical droplet, at least one of its faces should be of supercritical size for the reduced model in that direction. On the other hand, if all of the faces of an occupied rectangle are of supercritical size, then it is certainly a critical droplet.
We suppose for ease of notation that the easiest growth direction is the z direction. Only if a<b and Conjecture 3.3 does not hold, then it is possible that the (a,c) model has a lower threshold length than the (a,b) model. But in that case, these two models do have the same order of threshold length, therefore, in that case the y and z direction would behave essentially in the same manner.
We denote

Let P a,b denote the density of critical droplets for the (a,b) model (see (2.3)).
We choose as a critical droplet for the (a,b,c) model an occupied N by N by c rectangular block, where \(N \geq (L_{a,b}^{+}(p))^{1+\varepsilon}\). This rectangular block will grow easily into a N by N by M rectangular block that is of supercritical size in all directions, that is, \(MN \geq(\bar{L}^{+}(p))^{2}\).
The probability that M slabs will get occupied, is at least \((1-(1-P_{a,b})^{N^{2}})^{M}\) (up to some irrelevant constants). We take the logarithm, which is approximately \(-M e^{-P_{a,b} N^{2}} = -Me^{-P_{a,b}^{-\varepsilon}}\). This is close to 0 if \(M =o(e^{(L_{a,b}^{-}(p))^{\varepsilon }})\). By the bounds in Claim 3.1, we see that it is possible to satisfy both \(M \geq\bar{L}^{+}(p)\) and \(M =o(e^{(L_{a,b}^{-}(p))^{\varepsilon }})\).
The probability that a fixed N by N by c rectangular block is occupied, is \(p^{2N^{c}}\). Therefore, \(p^{2N^{c}}\) describes the density of critical droplets in the (a,b,c) model, and we obtain (see (2.3))

We work out

where C is a suitable constant. This gives the lower bound for L in Theorem 3.1.
5 The Upper Bound
In this section, we show that for all L growing slower than the value \(L_{a,b,c}^{-}(p)\) stated in Theorem 3.1, the probability that the configuration is internally spanned, tends to 0. In the case that L≤(1/p)1/4, we simply estimate \({\mathbb{P}}([0,L]^{3} \mbox{ i.s.}) \leq1-(1-p)^{L^{3}}\), since in order to be internally spanned, at least one site needs to be occupied. This tends to 0 as p→0 for all L≤(1/p)1/4. In the case that L>(1/p)1/4 however, we need to do a lot more work.
We will apply the method introduced in [8] for the case of three-dimensional isotropic bootstrap percolation, later generalized to arbitrary dimension in [9], and again presented in [23], where some minor inaccuracies in the original presentation are corrected. We follow these arguments, and modify the method to be applicable also to the case of anisotropic bootstrap percolation.
A necessary condition for a cube [0,L]3 to be internally spanned in the (a,b,c) model is that it is internally crossed, that is, in the final set of occupied sites, there is a path of occupied sites connecting two opposite faces of the cube, in every direction. To find a suitable bound for the probability of [0,L]3 to be internally crossed, we will enhance the configuration, that is, occupy more sites. Throughout the remainder, we will suppose for ease of notation that the z direction is the easiest growth direction. Again, even though if Conjecture 3.3 does not hold then the easiest growth direction might be the y direction, this possible exception does not change our proof, since in that case the y and z direction behave essentially in the same manner.
5.1 Some Definitions and Lemmas
Definition 5.1
In weakly enhancing the initial configuration in a connected set of sites ρ, where R is the smallest rectangular block covering ρ, we do the following:
-
1.
We evolve according to the (a,b,c) bootstrap rule, only taking into account occupied sites in ρ, thus the rule only is active in R.
-
2.
We occupy sites that are weakly spanned. We find weakly spanned sites as follows: for every site that is occupied, but was initially empty, we draw lines from this site to every site in its neighborhood that is occupied in the final configuration. A weakly spanned site is an empty site that is crossed by (at least one) such a line. We give an example in Fig. 3.
Fig. 3 
An example to explain weakly spanned sites. Consider the (2,3) model, in a 6 by 6 rectangle. On the left is the initial configuration (occupied sites are marked o), in the middle the final configuration (spanned sites are marked s), and on the right we have added weakly spanned sites (marked w). We see that the rectangle is weakly crossed

We say a rectangular block is weakly crossed if it is internally crossed in every direction after weakly enhancing.
The following lemma is somewhat similar to Lemma 1 from [3]. Related arguments continue to reappear in various forms in many papers on bootstrap percolation.
Lemma 5.2
For the (a,b,c) model, suppose that the cube [0,l]3 is internally spanned. Then there are constants κ and λ that only depend on a, b and c, such that for every \(k \in[1,\frac {l-\lambda}{\kappa}]\), there is a rectangular block with longest side length in [k,κk+λ] that is weakly crossed.
Proof
First, we need some further notation. We call a set of occupied sites ρ a region if the set of occupied sites resulting from the weak enhancement of ρ is connected. Therefore, if ρ is a region then the smallest rectangular block that covers it, is weakly crossed. We say that an empty site x has a set of influencing regions if there is a set of regions such that if we empty the entire configuration except these regions then x is spanned, but if we furthermore empty any one of these regions then x is not spanned. There may be several possibilities for the set of influencing regions. The cardinality of these sets is always between 1 and a+b+c, and the distance between any two regions in one of these sets is at most 2c+1. We say that the influencing rectangular block is the smallest rectangular block such that it covers the set of influencing regions.
Next, we present a special order of occupying sites according to the bootstrap rule. After step i, we will have a set of regions \(\mathcal {C}_{i}\). We start with the set \(\mathcal{C}_{1}\) of regions with diameter 1, that consists of all single occupied sites in the initial configuration. Since we suppose that [0,l]3 is internally spanned, \(\mathcal{C}_{1}\) is not empty. Then we iterate in the following manner:
-
If there are two regions such that their union is again a region, then \(\mathcal{C}_{i+1}\) consists of all the regions in \(\mathcal {C}_{i}\) with these two regions removed, and with a new region added that is the union of these two regions. If there are several such pairs of regions, then we make an arbitrary choice.
-
If not, then we choose an arbitrary site x that has a set of influencing regions. Such an x always exists because by assumption the cube is internally spanned. If it has several such sets, then we make an arbitrary choice. Call this set \(\mathcal{S}_{i}\).
-
We suppose the entire configuration is empty except the regions in \(\mathcal{S}_{i}\).
-
We occupy x. Either we now have a single occupied connected component, or we would have one after weakly enhancing. Therefore, the union of all regions in \(\mathcal{S}_{i}\), plus x, forms a region.
-
\(\mathcal{C}_{i+1}\) consists of all the regions in \(\mathcal {C}_{i}\) with the regions in S i removed, and with a new region added that consists of the union of the regions in S i , and x.
Now the following holds: If the maximal diameter of all regions in \(\mathcal{C}_{i}\) is D i , then the maximal diameter of all regions in \(\mathcal{C}_{i+1}\) is in [D i ,(a+b+c)(D i +2c+1)], and since we supposed that [0,l]3 is internally spanned, the iteration does not end until the maximal diameter is l. Therefore, if we choose κ=a+b+c, and λ=(2c+1)(a+b+c), the proof is complete. □
Definition 5.3
In enhancing the initial configuration in a cube [0,l]3, we do the following:
-
1.
We divide the cube in l/s disjoint slices [0,l]2[is+1,is+s], with i=0,…,l/s−1. We suppose for ease of notation that l is a multiple of s. We choose s as the minimal value such that if an empty site x is in slice i, and all other slices are fully occupied, then site x still needs a+b occupied sites in the intersection of its neighborhood with slice i, to become occupied. For instance, in [8, 9] the slices have width 2, whereas for the modified model in [23] the slices can have width 1. For the (a,b,c) model, we need that a+b+c−(2c+1−s)=a+b, this implies that we have to choose s=c+1. We say that a set of sites (x,y,si+1),…,(x,y,si+s) is a minicolumn in slice i. For every minicolumn in every slice, if at least one site in the minicolumn is occupied, then we occupy all sites in the minicolumn. Since in the initial configuration minicolumns are independent, the probability for a minicolumn to be occupied is q=1−(1−p)s. Note that p≤q≤sp.
-
2.
We evolve the minicolumn configuration of every slice by the two-dimensional bootstrap rule, that is, we view minicolumns as sites in the (a,b) model with q as parameter, and iteratively occupy those that have at least half of their neighborhood occupied. Notice that by now we have occupied at least every site that would also get occupied with the three-dimensional bootstrap rule.
-
3.
We fully occupy every slice where there is an occupied component of at least some size S. We call such a slice flooded. We will choose S a rectangle of diameter d c , such that it is comparable to a critical droplet for the (a,b) model with q as parameter. We will sometimes take the maximal diameter over the different directions as the diameter of a region, this abuse of terminology only involves an irrelevant constant which will not affect our estimates anyway.
-
4.
We occupy weakly spanned minicolumns. That is, we say a minicolumn is weakly spanned if it contains a weakly spanned site. This step is not essential for arriving at (5.6), but by including this step we ensure that an enhanced configuration dominates a weakly enhanced configuration, which is necessary to arrive at (5.8).
-
5.
We fully occupy slice 0 and slice l/s−1.
We say a rectangular block is e-crossed if it is internally crossed in the z-direction after enhancing. We denote ℙ l (e-crossed) for the probability that the cube [0,l]3 is e-crossed.
The derivation of the following lemma bears resemblance to the derivation of (3.30) of [8], and of (23) of [23], but we derive the bound for the (a,b) model with arbitrary a and b. We will use this lemma for non-flooded slices, where we know that there is no large occupied component. In the case (a,b)=(1,2), one may choose d c <p −3/2 as in [17], but note that this choice for d c is not essential: the lemma is valid for any d c <p −2+ε.
Lemma 5.4
For the (a,b) model on [0,L]2 and p small enough, the expected size χ of the occupied component of the origin, given that the largest occupied component has diameter less than d c =p −b+ε, is at most \(\sqrt{p}\). This bound does not change when weakly spanned sites are occupied.
Proof
We write

For the diameter to be any number between 1 and d c , it is necessary that at least one out of \(d_{c}^{2}\) sites is occupied, which happens with probability \(1 -(1-p)^{d_{c}^{2}}\) which is less than \(p\ d_{c}^{2}\). If the diameter is in [r,d c ], then we estimate ℙ(r≤ diameter<d c )≤ℙ(diameter<d c ). To estimate this probability, we generalize (2) of [17]. We first quote this equation, which was used for the case (a,b)=(1,2):

where \(\tilde{p} \geq p\) and \(\hat{p} \geq p\) denote a parameter of order p. In words, this expression states that a necessary condition for a rectangle to be internally spanned, is that every row or column has the following property: if it were adjacent to an occupied rectangle, then it would become occupied. Thus, in the case (a,b)=(1,2), in every column one needs one site that has two occupied sites close enough to it. The probability for this to occur at a fixed site is of order p 2. In every row however, only one occupied site suffices. In a rectangle of size xy, we have x columns of length y and y rows of length x. The generalization to arbitrary a,b is straightforward:

However, we need a bound that is also valid when weakly spanned sites are occupied as well. Note that for a site to be weakly spanned, there has to be a spanned neighbor in a nearby row/column, that is, at most a resp. b columns resp. rows away. Therefore, we adapt the bound as follows:

We estimate

Now we insert that d c <p −b+ε, so that

Therefore, we find

We choose r such that −2b+(2+r)ε>1/2. With this choice of r and p small enough, χ is less than \(\sqrt{p}\), as needed. □
Lemma 5.5
Let \(\bar{P}_{a,b} = (L^{-}_{a,b}(p))^{-1}\). Let ℙ l (e-crossed) and s be defined as in Definition 5.3. Then

Proof
Since we consider the cube [0,l]3 to be e-crossed, we denote according probabilities with a subscript l.
We condition on the number of flooded slices:

Note that the first and last slice are fully occupied regardless of the initial configuration. By independence of the slices, we have

where the probability for a slice to be flooded is the probability that there is an occupied component of at least size S for the (a,b) model in the slice. We now condition on the positions of the flooded slices:

and no other slice is flooded. By \(\mathcal{E}_{i,j}\), for j>i+1, we denote the event that there exists an e-crossing from slice i+1 to slice j−1. Then

The slices i j +1,…,i j+1−1 are not flooded, therefore the largest occupied connected component is strictly smaller than S. If there is an e-crossing, then there is a self-avoiding path from slice i j to slice i j+1 that visits a connected component in each slice in between, and possibly in some slices more than once through several disjoint connected components, like skipping between slices from one stepping stone to another. We choose the path such that the total number H of connected components visited is minimal. Let l j =i j+1−i j −2. We sum over possible values of H:

Note that H can take only values h k =l j +2k, with k=0,1,… . Since for each larger value of k the path contains an extra back- and forward step, for each k the number of possibilities for the order of slices visited is (l j )k. We bound this by \(2^{h_{k}}\), which is the number we get if we suppose that for every skip there are two possibilities, disregarding the fact that the path needs to lead to slice i j+1. We need the probability of H connected components: after each stepping stone, we need a new stepping stone at the right position for the path to continue. That is, if a stepping stone is contained in a rectangle of x times y, then there are at most xy choices for the site from where we skip to the next slice. Since slice i j is fully occupied, there are l 2 choices for the site from which we make the first skip. We also use that a stepping stone is smaller than \(d_{c}^{2}\), the dimensions of S. We obtain

The factor \(\sum_{x_{i}< d_{c},y_{i}<d_{c}} x_{i} y_{i} {\mathbb{P}}_{l}(\mbox{occupiedcomponent has size }x_{i} y_{i})\) does not depend on i, and is the expected size χ of a stepping stone. We will choose d c such that we can bound this expected size by \(\sqrt{q}\). By Lemma 5.4, we can choose d c <p −b+ε for some fixed ε>0. We work out

where the last bound is valid for q small enough so that \(2\sqrt{q}\leq1/2\). Therefore,

If S is a critical droplet, then we can estimate \({\mathbb {P}}_{l}(\mbox{aslice is flooded}) \leq(d_{c} l)^{2} \bar{P}_{a,b}\) if l≥d c , and 0 otherwise, since \(\bar{P}_{a,b}\) is an upper bound for the probability of any choice of critical droplet (see (2.4)). However, to be sure that S is a critical droplet we need d c ≥p −b, but we chose d c <p −b+ε. The probability that S is occupied is therefore at most a factor p −2bε larger than \(\bar{P}_{a,b}\), so we estimate

Putting everything together, we get that if l≥p −b+ε, then

We use that the number of possibilities for i 1,…,i m is at most l m, and that l 0+l 1…+l m =l−m, so that \(\prod_{j=0}^{m}q^{l_{j}/2} = q^{1/2(l-m)}\). Then

so that

We insert d c ≤p b and q≤sp and simplify, so that we finally get, for l≥p −b+ε,

In the case that l<p −b+ε, we have that ℙ l (a slice is flooded)=0. Therefore we use (5.5) with i j =1 and i j+1=l/s−1, and obtain

which tends to 0 for all (1/p)1/4<l<p −b+ε. □
5.2 Proof for the Upper Bound
Proof of Theorem 3.1 (Upper bound for L)
We use Lemma 5.2 to estimate the probability of the cube [0,L]3 to be internally spanned as follows:

To arrive at this expression, we have reasoned as follows: If a rectangular block is weakly crossed, then the smallest cube covering this rectangular block has a crossing in some direction, after weakly enhancing. The probability for this is bounded by the probability that there is a crossing in the easiest direction after weakly enhancing. We will insert our upper bound for ℙ l (e-crossed) from Lemma 5.5. This bound was derived for the enhanced configuration, which dominates the weakly enhanced configuration.
We consider three ranges for L.
If L<p −b+ε, then we estimate

which tends to 0 by (5.7).
Next, if L≥p −b+ε then we combine equations (5.8) and (5.6), and get

We will use that for p small enough, (sp)(s−1)/2 p 2b(1−ε)<1.
In the case that \(p^{-b+\varepsilon } \leq L < (L^{-}_{a,b}(p))^{1/4}\), we choose \(k = \frac{L-\lambda}{\kappa}\), then (κ−1)k+λ≤L. This gives

We estimate further

Recall that \((L^{-}_{a,b}(p))^{1/3} = \bar{P}_{a,b}\). If \(L < (L^{-}_{a,b}(p))^{1/4}\), then \(L^{9} \bar{P}_{a,b}\) tends to 0 as p→0, so that this entire expression tends to 0.
Finally, we consider the case \(L \geq(L^{-}_{a,b}(p))^{1/4}\). We now choose \(k = \frac{(L^{-}_{a,b}(p))^{1/4}-\lambda}{\kappa}\) in (5.9), so that \(\frac{(L^{-}_{a,b}(p))^{1/4}-\lambda}{\kappa}\leq l \leq(L^{-}_{a,b}(p))^{1/4}\); this means that \(l =O((L^{-}_{a,b}(p))^{1/4})\). We also have \((\kappa-1)k+\lambda\leq (L^{-}_{a,b})^{1/4}\), so that:

We write \(L^{-}_{a,b}(p) = e^{f(1/p)}\). Since \(l = O((L^{-}_{a,b}(p))^{1/4})\), there is a constant C such that the right factor of this expression tends to 0 as \(e^{-e^{Cf_{a,b}(1/p)}}\). Therefore, if L 3 tends to ∞ more slowly, then the entire expression tends to 0. This gives the required upper bound for L. □
References
Adler, J.: Bootstrap percolation. Physica A 171, 452–470 (1991)
Adler, J., Duarte, J.A.M.S., van Enter, A.C.D.: Finite-size effects for some bootstrap percolation models. J. Stat. Phys. 60, 323–332 (1990), and addendum J. Stat. Phys. 62, 505–506 (1991)
Aizenman, M., Lebowitz, J.L.: Metastability effects in bootstrap percolation. J. Phys. A 21, 3801–3813 (1988)
Amini, H.: Bootstrap percolation in living neural networks. J. Stat. Phys. 141, 459–475 (2010)
Balogh, J., Bollobas, B., Duminil-Copin, H., Morris, R.: The sharp threshold for bootstrap percolation in all dimensions. Trans. Am. Math. Soc. 364, 2667–2701 (2010). arXiv:1010.3326v1
Balogh, J., Bollobas, B., Morris, R.: Bootstrap percolation in three dimensions. Ann. Probab. 37, 1329–1380 (2009)
Bringmann, K., Mahlburg, K., Mellit, A.: Convolution bootstrap percolation models, Markov-type stochastic processes, and mock theta functions. Math. Res. Not., to appear. We thank prof. Bringmann for making this work available to us
Cerf, R., Cirillo, E.: Finite size scaling in three-dimensional bootstrap percolation. Ann. Probab. 27(4), 1837–1850 (1999)
Cerf, R., Manzo, F.: The threshold regime of finite volume bootstrap percolation. Stoch. Process. Appl. 101, 69–82 (2002)
Connelly, R., Rybnikov, K., Volkov, S.: Percolation of the loss of tension in an infinite triangular lattice. J. Stat. Phys. 105, 143–171 (2001)
Duminil-Copin, H.: private communication
Duminil-Copin, H., van Enter, A.C.D.: Sharp metastability threshold for an anisotropic bootstrap percolation model, Ann. Probab. (2010, to appear). arXiv:1010.4691
Duminil-Copin, H., Holroyd, A.: Finite volume Bootstrap Percolation with threshold dynamics on Z 2 I: Balanced case. Preprint, obtainable at H. Duminil-Copin’s homepage http://www.unige.ch/duminil/
Duarte, J.A.M.S.: Simulation of a cellular automaton with an oriented bootstrap rule. Physica A 157, 1075–1079 (1989)
Eckmann, J.P., Tlusty, T.: Remarks on bootstrap percolation in metric networks. J. Phys. A, Math. Gen. 42, 205004 (2009)
van Enter, A.C.D.: Proof of Straley’s argument for bootstrap percolation. J. Stat. Phys. 48, 943–945 (1987)
van Enter, A.C.D., Hulshof, W.J.T.: Finite-size effects for anisotropic bootstrap percolation: logarithmic corrections. J. Stat. Phys. 128, 1383–1389 (2007)
Fey, A., Levine, L., Peres, Y.: Growth rates and explosions in sandpiles. J. Stat. Phys. 138, 143–159 (2010)
Gravner, J., Griffeath, D.: First passage times for threshold growth dynamics on Z 2. Ann. Probab. 24, 1752–1778 (1996)
D. Griffeath’s webpage: http://psoup.math.wisc.edu/kitchen.html
A. Holroyd’s webpage: http://research.microsoft.com/en-us/um/people/holroyd/
Holroyd, A.: Sharp metastability threshold for two-dimensional bootstrap percolation. Probab. Theory Relat. Fields 125, 195–224 (2003)
Holroyd, A.: The metastability threshold for modified bootstrap percolation in d dimensions. Electron. J. Probab. 11(17), 418–433 (2006)
Holroyd, A., Liggett, T.M., Romik, D.: Integrals, partitions and cellular automata. Trans. Am. Math. Soc. 356, 3349–3368 (2004)
Lee, I.H., Valentiniy, A.: Noisy contagion without mutation. Rev. Econ. Stud. 67, 47–56 (2000)
Lenormand, R.: Pattern growth and fluid displacement through porous media. Physica A 140, 114–123 (1986)
Mountford, T.S.: Critical lengths for semi-oriented bootstrap percolation. Stoch. Process. Appl. 95, 185–205 (1995)
Schonmann, R.H.: On the behavior of some cellular automata related to bootstrap percolation. Ann. Probab. 20, 174 (1992)
Schonmann, R.H.: Critical points of 2-dimensional bootstrap percolation-like cellular automata. J. Stat. Phys. 58, 1239–1244 (1990)
Toninelli, C.: Bootstrap and jamming percolation. In: Bouchaud, J.P., Mézard, M., Dalibard, J. (eds.) Les Houches School on Complex Systems, Session LXXXV, pp. 289–308 (2006)
Acknowledgements
We thank Alexander Holroyd for inspiring discussions and Hugo Duminil-Copin for a helpful correspondence.
Open Access
This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
van Enter, A.C.D., Fey, A. Metastability Thresholds for Anisotropic Bootstrap Percolation in Three Dimensions. J Stat Phys 147, 97–112 (2012). https://doi.org/10.1007/s10955-012-0455-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10955-012-0455-4