
Abstract
Glaucoma is one of the leading causes of blindness worldwide. There is no cure for glaucoma but detection at its earliest stage and subsequent treatment can aid patients to prevent blindness. Currently, optic disc and retinal imaging facilitates glaucoma detection but this method requires manual post-imaging modifications that are time-consuming and subjective to image assessment by human observers. Therefore, it is necessary to automate this process. In this work, we have first proposed a novel computer aided approach for automatic glaucoma detection based on Regional Image Features Model (RIFM) which can automatically perform classification between normal and glaucoma images on the basis of regional information. Different from all the existing methods, our approach can extract both geometric (e.g. morphometric properties) and non-geometric based properties (e.g. pixel appearance/intensity values, texture) from images and significantly increase the classification performance. Our proposed approach consists of three new major contributions including automatic localisation of optic disc, automatic segmentation of disc, and classification between normal and glaucoma based on geometric and non-geometric properties of different regions of an image. We have compared our method with existing approaches and tested it on both fundus and Scanning laser ophthalmoscopy (SLO) images. The experimental results show that our proposed approach outperforms the state-of-the-art approaches using either geometric or non-geometric properties. The overall glaucoma classification accuracy for fundus images is 94.4 % and accuracy of detection of suspicion of glaucoma in SLO images is 93.9 %.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
Background
Glaucoma is one of the leading causes of irreversible blindness worldwide accounting for as much as 13 % of all cases of vision loss [1, 2]. It is estimated that more than 500,000 people suffer from glaucoma in England alone, with more than 70 million people affected across the world [3, 4]. The changes occur primarily in the optic disc [5], which gradually can lead to blindness if left untreated. As glaucoma-related vision loss is irreversible, early detection and subsequent treatment are essential for affected patients to preserve their vision. Conventionally, retinal and optic nerve disease identification techniques are based in part, on subjective visual assessment of structural features known to correlate with the pathologic disease. When evaluating retinal images, optometrists and ophthalmologists often rely on manual image enhancements such as adjusting contrast and brightness and increasing magnification to accurately interpret these images and diagnose results based on their own experience and domain knowledge. This process is time consuming and its subjective nature makes it prone to significant variability. With the advancement in digital imaging techniques, digital retinal imaging has become a promising approach that leverages technology to identify patients with glaucoma [6]. Retinal imaging modalities such as fundus cameras or Scanning Laser Ophthalmoscopes (SLO) have been widely used by the eye clinicians. Retinal imaging with automated or semi-automated image analysis algorithms can potentially reduce the time needed by clinicians to evaluate the image and allow more patients to be evaluated in a more consistent and time efficient manner [7, 8].
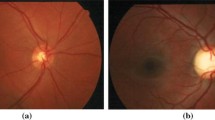
Glaucoma is associated with erosion of the neuroretinal rim which often enhances the visibility of chorioretinal atrophy in the peripapillary tissue (the latter is referred to as peripapillary atrophy (PPA)) [9, 10]. This can be quantified by geometrical measures (e.g. an increased cup-to-disc ratio (CDR), a well-established glaucoma indicator in the research community, particularly in the vertical meridian (Fig. 1).

Comparison of the optic disc area of the a normal and b glaucomatous image. The cup boundary is shown with the red outline in both images and disc boundary is shown with blue outline in (b) only. There is significantly larger cup in relation to the size of the optic disc in the glaucoma image compared to the normal image. Inferior sector Peripapillary Atrophy (PPA) in the glaucoma image (b) is also evident possibly due to concomitant erosion of the inferior neuro-retinal rim tissue
There are several efforts made for the classification between normal and glaucomatous patients, which we can broadly divide into two categories including: geometrical based methods and non-geometrical based methods. The geometrical based methods involve the automatic calculation of glaucoma associated geometrical features (e.g. optic cup, disc shapes/diameters , or CDR). Their automatic determination require automatic segmentation of anatomical structures such as optic disc and optic cup in a retinal image. Nayak et al. [11] performed segmentation using morphological operations [12] for calculation of the CDR and performed classification using neural networks. The classification accuracy was 90 % on 15 images after training the classifier on 46 normal and glaucoma images. Other efforts stated the accuracy of the methods in terms of optic disc and cup segmentation [13].
On the other hand, the non-geometrical based methods extract image features such as pixel appearance, textural properties, intensity values, colour, etc. of the optic disc cropped image. Bock et al. [14] calculated image texture, Fast Fourier Transform (FFT) Coefficients, Histogram Models, B-Spline coefficients on the illumination corrected images. Based on these features they calculated a Glaucoma Risk Index using a two-stage classification scheme. Dua et al. [15] used Wavelet-Based Energy Features and compared the performance of different classifiers such as Support Vector Machines (SVM), Naive Bayes [12], Random Forests [16] and Sequential Minimal Optimization (SMO) [17]. Texture and Higher Order Spectra (HOS) based information has also been used for the classification between normal and glaucoma images [18, 19]. Here different classifiers were investigated and it was found the maximum accuracy was achieved using the SVM. All these methods focus on image features of the retinal image obtained from 45 ∘ field of view fundus camera except the Bock’ method which focus on optic disc cropped image.
Hypothesis and contributions
Despite the existing methods mentioned above are encouraging, they only focus on either geometrical properties or non-geometrical properties. In fact, in an optic disc cropped image, there are certain indications in different regions of optic disc cropped image apart from increased cup size (such as PPA) which can be quantified for automatic glaucoma classification. Our hypothesis is that the classification between normal and glaucoma images can be improved through combining both geometrical and non-geometrical features.
Therefore, different from all the existing approaches, we propose a novel holistic approach: Regional Image Features Model (RIFM) to extract both geometrical and non-geometrical properties in different regions of optic disc and its surroundings. The proposed approach can automatically, accurately localise, segment the optic disc, divide optic disc cropped images into different regions, and classify an image into the right category (i.e. normal or glaucoma). Our contributions include:
-
1)
A new accurate algorithm of automatic optic disc localisation based on weighted feature maps to enhance optic disc and vasculature converging at its centre.
-
2)
A new accurate, automatic optic disc segmentation method derived from our previous work [20] so as to avoid misguidance due to vasculature or atrophy in case of glaucoma.
-
3)
A new regional image feature model (RIFM) which can extract both geometrical and non-geometrical features from different regions of optic disc and its surroundings.
The rationale behind the RIFM lies in automatic localisation and segmentation of optic disc and then dividing its surrounding into five regions: the optic disc area, inferior (I), superior(S), nasal(N) and temporal(T). In clinical practice, clinicians often visually inspect these regions and make a diagnosis. There is currently no existing work on automation of this process. Based on different regions, the features including textural, frequency, gradient, colour and illumination information are then extracted. The classifier is then built for classification between glaucoma and non-glaucoma images.
We have compared our method against the existing approaches and evaluated our prototype on both fundus and Scanning Laser Opthalmoscope (SLO) images obtained from our collaborator, Optos [21]. To the best of our knowledge, this is the first approach with a combination of geometric and non-geometric properties, which can automatically divide regions based on clinical knowledge and perform classification between normal and glaucoma, applicable to both fundus and SLO images.
The rest of this paper is organised as follows: “??” introduces datasets used in our experiments. “Method” discusses our proposed method. Section “Experimental evaluation and discussion” provides the quantitative and visual results of our proposed method. Section “Conclusion” summarizes and concludes the proposed work.
Datasets used for experimentation
RIM-ONE
RIM-ONE (An Open Retinal Image Database for Optic Nerve Evaluation) [22, 23] is a fundus image dataset composed of 85 normal and 39 glaucoma images. All the images have been annotated with boundaries of optic disc and optic cup from which we calculated vertical CDR values. The retinal images in the dataset were acquired from three different hospitals located in different regions of Spain. They have compiled the images from different medical sources which guarantee the acquisition of a representative and heterogeneous image set. All the images are non mydriatic retinal photographs captured with specific flash intensities, thus avoiding saturation.
SLO images
All ultrawide field SLO images were obtained using the Optos P200MA [21]. Unlike traditional flash-based fundus cameras, this device is able to capture a single wide retinal image without dilation. The image has two channels: red and green. The green channel (wavelength: 532nm) provides information about the sensory retina to retinal pigment epithelium whereas the red channel (wavelengh: 633nm) shows deeper structures of the retina towards the choroid. Each image has a dimension of 3900×3072 and each pixel is represented by 8-bit on both red and green channels. The SLO images have been taken from 19 patients suspected with glaucoma while 46 images are from non-glaucomatous patients. The images have been annotated and graded by glaucoma specialists at Harvard Medical School, Boston, MA, USA. The annotations are provided in terms of boundaries of optic disc and optic cup as well as vertical CDR values.
Method
The block diagram of the RIFM is shown in Fig. 2. We first localise and segment the optic disc from an image. Then the image will be divided into different regions. The main rationale of dividing the image into different regions is that geometrical changes in glaucoma can have different image features compared to normal images. For example, the higher CDR will result in higher intensity values in the optic disc in cases of glaucoma. Also the occurrence of atrophy due to glaucoma will result in different texture around optic disc surroundings. The deployment stage classifies the test image between normal and glaucoma. The subtasks of the block diagram are discussed in the following subsections.

Block diagram of regional image features model
Automatic localisation of optic disc
Although the optic disc is often the brightest region in the retinal scan, its localisation can be misguided due to the presence of disease lesions, instrument reflections and the presence of PPA. Therefore, optic disc localisation can be more accurate by determining retinal vasculature convergence point which converges at the centre of the optic disc [24]. However, vasculature area are not clearly visible in the cases with high instrument reflection from PPA. In order to make optic disc localisation more robust, we have developed a new localisation method as shown in Algorithm 1 which involves development of two weighted feature maps for enhancing the optic disc (F 1) and vasculature structure (F 2). The equations of the feature maps we developed are shown in Eq. 1. Although the summation of x and y gradients can be helpful in determining bright regions like optic disc on Y (intensity map in YUV colour space [25]), the Fast Radial Symmetry Transform [26] with specified radius r will enhance the optic disc further compared to other bright regions. Similarly, matched filtering [27] will enhance the vasculature structure further on the intensity map. In matched filtering, the mean Gaussian response in different directions (1) with difference of 30 ∘ among adjacent 𝜃 values is taken. σ is set to 4 for fundus images and 1.5 for SLO images as SLO images have low resolution optic disc due to its wide FOV. The mean response of matched filter is min-max normalized in order to make the response consistent for every image. For optic disc localisation we have performed the exhaustive search in F 2 horizontally and in F 1 vertically. The Eq. 2 estimates the optic disc centre by exhaustive search. Due to resolution difference, the maximum dimensions of optic disc are 400 and 150 in case of fundus and SLO images whereas the maximum vessel width is 50 and 12 respectively. The examples of optic disc localization in fundus and SLO images are shown in Fig. 3.


Examples of optic disc localization on fundus image (first row) and SLO image (second row). The SLO image optic disc has been affected by atrophy area around but our proposed optic disc localization was able to locate it accurately
[!h]
Automatic segmentation of optic disc
The segmentation algorithm
After optic disc localisation, the next step is its segmentation. Building upon our proposed work, instead of determining optic disc contour on the gradient map [20], we have developed the feature maps and then estimated the contour by minimizing the distance between normal profiles of feature maps from each contour point in a test image and mean of the images in the training set. These feature maps have been determined by image convolution with a Gaussian filter bank [28]. Convolving the image with a Gaussian filter bank can determine the image features at different resolutions. The Gaussian filter can be given as:
Convolving the retinal image with a Gaussian filter bank at different scales σ determines the image details at different resolutions by adding the blur while increasing the scale. The Gaussian filter bank includes Gaussian \(\mathcal {N}(\sigma )\), its two first order derivatives \(\mathcal {N}_{x}(\sigma )\) and \(\mathcal {N}_{y}(\sigma )\) and three second order derivatives \(\mathcal {N}_{xx}(\sigma )\), \(\mathcal {N}_{xy}(\sigma )\) and \(\mathcal {N}_{yy}(\sigma )\) in horizontal(x) and vertical(y) directions. The retinal images have been convolved at different scales σ=2,4,8,16 as PPA has been diminished at higher scale whereas optic disc edges are more visible at lower scales (Fig. 4). Morever, the image convolution has been performed at both red and green channels as the optic disc boundary has more meaningful representation without PPA or vasculature occlusion at σ=8 but PPA is more visible at green channel at σ=2 which can be helpful while training the features inside and outside the optic disc boundary. Before calculation of features maps, we have performed vasculature segmentation [29] followed by morphological closing in 8 directions and retaining maximum response for each vessel pixel. This is to avoid misguidance due to vasculature occlusion.
We have then evaluated the profiles from the line normal to each contour point from the feature maps and calculated the mean V t r a i n across the images in the training set. The length of the normal lines can be set as discussed in [20]. We then estimate new contour \(\hat {\textbf {Y}}\). For test profile V, each of the contour point n can be achieved by Eq. 5 in Algorithm 2 where M is the number of feature maps. Among P test profiles, the optimum profile can be estimated with minimum mahalanobis distance [30] with V t r a i n . Then we applied the statistical shape modeling so as to adjust the estimated contour Y with the mean of shapes in the training set. This has significantly increased the segmentation performance. The optic disc boundary can now be represented as X. After determining optic disc boundary model, we have readjusted the optic disc centre as:
where X x and X y are positions of X in x-axis and y-axis respectively.


Elaboration of optic disc image after image convolution with a Gaussian filter with a original image, b red channel convolution at σ=2, c green channel convolution at σ=2 and d red channel convolution at σ=8
Regional image features model
After optic disc segmentation, we need to determine Regional Image Feature Model (RIFM). Here we have performed the following steps:
Determination of regions in the optic disc cropped image
-
i.
Optic disc cropping which should be twice the maximum diameter of optic disc in the dataset as shown in Fig. 5a. This has been done in order to fully include atrophy area around optic disc and other features if present.
-
ii.
Connecting the optic disc centre (x c ,y c ) to each corner of the cropped image. This divides the image into 4 different quadrants shown in Fig. 5b.
-
iii.
Naming the regions as inferior(I), superior(S), nasal (N) and temporal(T) regions. I and S regions are fixed for each image. However, N and T regions can be named after determining if the image is from left eye or right eye. The algorithm calculates the vasculature area (segmented during optic disc segmentation) within the optic disc in both halves of the image. In this case, the vasculature area is higher on the right so this image is considered as right eye image (Fig. 5c). Therefore, N and T regions will be on right side and left side respectively (Fig. 5d).
-
iv.
Generating the image regions mask representing optic disc and different regions in its surroundings (Fig. 5d).

Different regions of the optic disc centred image with a image of a right eye b image divided into different quadrants with the optic disc boundary represented with green and centroid with blue colour, c vasculature area within the optic disc with higher area on the right side d optic disc centred image divided into different regions
Determination of regional image features
After the generation of different regions in the optic disc cropped image, the next step is to determine the image-based features for each region. Apart from geometrical features (e.g. optic disc size, CDR), there are certain representations of an image which can distinguish two images taken from different states. These representation can be quantified by calculating features representing the image. In our case, these different states are normal and glaucoma. After optic disc segmentation and dividing the image into different regions, we can then analyze each region separately which can lead to unique contributions from each region in determining glaucoma classification. The features calculated for each region will represent a different column in a feature vector. Consider the examples from each of normal and glaucoma in Fig. 6. Both examples have been taken after optic disc segmentation and division of image into different regions. The boundary of the optic cup is not clearly evident in either image, which can lead to misidentification of CDR. Also the presence of PPA in the I and T regions in the glaucoma image is not sufficient to make a diagnosis of glaucoma [10]. Therefore, we need to evaluate the difference between normal and glaucoma by calculating the features which can represent texture, spatial and frequency based information.

Comparison of a normal and b glaucoma images after division of optic disc cropped image into different regions
For each region, we have generated the feature matrix on the basis of different features as follows:
where RG represents red and green channel respectively, texoff represents textural features with variable offset values, texscale represent textural features with variable scale, dg, g, wav and gab represent dyadic Gaussian, gradient features, wavelet features and gabor filter features. The details of each feature type are described below:
Gaussian features
The mean value of each region after convolving the image with each Gaussian filter and its first and second order derivatives determined for optic disc segmentation has been calculated to generate \(FM_{RG}^{\textit {g}}\). We have 6 gaussian filters convolved at scales σ=2,4,8,16 for red and green channels and region which makes the length of \(FM_{RG}^{\textit {g}}\) equal to 240.
Textural features
Textural features can be determined by evaluating Grey Level Co-occurrence Matrix (GLCM) [31, 32]. GLCM determines how often a pixel of a grey scale value i occurs adjacent to a pixel of the value j. The pixel adjacency can be observed in four different angles i.e. 𝜃=0∘,45∘,90∘,135∘. For the region of size p x q, we perform second order textural analysis by constructing the GLCM (C d (i,j)) and probability of pixel adjacency (P d (i,j)) as:
where Δx and Δy are offset values. The dimensions p and q represent the bounding box of the particular region among I,S,N,T and OD. We have evaluated 20 features representing textural information which are enlisted in Table 10 [33]. Since we have significantly large size of regions, the pixel adjacency can be evaluated at different offset values Δx and Δy. We have varied these values ranging from 1 to 10 for both Δx and Δy to generate \(FM_{RG}^{\textit {texoff}}\). We have evaluated 20 textural features for each red and green channel (blue channel is set to zero in SLO so we did not calculated for fundus images as well).
Apart from varying the offset values, we have also calculated these features by convolving the image with Gaussian filter at different scales σ=2,4,8,16 after fixing offset values at 1 for generating \(FM_{RG}^{\textit {texscale}}\).
Dyadic gaussian features
The Dyadic Gaussian features involve the downsampling of the optic disc cropped image at multiple spatial scales [34, 35]. The calculation of absolute difference at different spatial scales can lead to the development of low-level visual ‘feature channels’ which can discriminate between normal and glaucoma images. We can generate certain features from red channel, green channel and combinations of both channels. The blue channel is set to zero for SLO therefore we do not take this into account for fundus images as well. Apart from Red(R) and Green(G) channels, we have determined the feature channels as follows:
where I m n is the mean response of the both channels and the Y r g shows their mixed response i.e. yellow channel. The absolute difference of the particular feature channels at different spatial scales lead to determination of excitation and inhibition response. For determination of excitation and inhibition response, we have centre levels c and surround levels s of the spatial scales respectively. This can be calculated as:
where I n t e r p s−c represent interpolation to s−c level. Note that s = c + d. If we calculate mean response of each region i.e. \(FM_{RG}^{\textit {dg}}\)=[I(c,s),RG(c,s),BY(c,s)]:
where N is number of pixels in the region. The dyadic Gaussian features can excite the optic disc region while inhibiting the regions in its surroundings. For the case of glaucoma, the excited optic disc region can have higher intensity values due large optic cup size while inhibition of atrophy area in its I and T regions can also contribute towards glaucoma classification as shown in Fig. 7. We have calculated dyadic Gaussian features at c and d=[2,3,4] which make c,s pairs as [2-4,2-5,2-6,3-5,3-6,3-7,4-6,4-7,4-8]. In this way we have 135 features generated from dyadic Gaussian as shown in Table 1.

Comparison of a normal and b glaucoma images of Fig. 6 at Y r g (2,5)
Gabor features
Gabor filters can be convolved with the image at different frequencies and orientations which can generate different feature channels for image classification [36]. For determining \(FM_{RG}^{\textit {gab}}\), we have taken mean response of the gabor filter in the region. The gabor filter is represented as:
x and y are image pixel coordinates. Here we have varied σ=[2,4,8,16], γ=[\(\frac {1}{3},\frac {1}{2}\),1,2,3], f=[\(\frac {1}{4},\frac {1}{3},\frac {1}{2}\),1,2,3,4], 𝜃=[0∘,45∘,90∘,135∘]. The γ value is varied so as to determine the responses when scale of x and y axis are equal and unequal at different scales. On the similar grounds, frequency is varied in such a way so as to determine the response when wavelength is higher than frequency and vice versa. In this way a total number of 5600 features have been determined with different combination of gabor parameters.
Wavelet features
We have calculated Discrete Wavelet Transform (DWT) features \(FM_{RG}^{\textit {wav}}\) denoted by ψ [37]. The DWT features captures both spatial and frequency information of the image. DWT analyses the image by decomposing it into a coarse approximation via low-pass filtering and into detail information via high-pass filtering. Such decomposition is performed recursively on low-pass approximation coefficients obtained at each level [38]. The image is divided into four bands i.e. A(Top left (LL)), H (Top Right (LH)), V(Bottom Left (HL)) and D(Bottom Right (HH)). As an example, LH indicates that rows and columns are filtered with low pass and high pass filters, respectively. DWT decomposition is calculated on five different wavelet families i.e. haar, db3, rbio3.3, rbio3.5, rbio3.7. For a particular region in the optic disc cropped image, we can calculate two types of features using these bands i.e. average value of the coefficients (ψ A v g ) and energy of the coefficients (ψ E n e r g y ). As an example, the average value and average energy of D band are derived from the wavelet coefficients, as shown below;
where p and q represents width and height in pixels of the region respectively. We have performed the DWT decomposition to only one level as features calculated for higher levels were not significant (p v a l u e ≥0.05) thus they were not included in the feature set.
Z-score normalization
After determination of feature matrix, the feature matrix is normalized using z-score normalization [39]. It can be represented as:
where μ f is the mean of the features and σ f is the standard deviation across the examples in the training set.
Feature selection
Due to division of optic disc cropped images into five regions, the number of features generated is five times larger than the situations where features are generated for a whole image. Since the determination of classifier constructed on such a high dimension of features is not computationally efficient and also some of these features may lead to depreciation of classifier performance, we have selected the features based on p v a l u e which are statistically significant (p v a l u e ≤0.05) towards glaucoma classification. Table 1 shows the number of features generated by each feature type whereas the percentage of features selected from each feature type has been shown in Fig. 8. For fundus images, 2201 regional features out of 9175 features have been significant towards glaucoma classification and 2836 regional features have been significant towards classification in SLO images. The bar plot shows that the textural and gabor features can be more clinically significant compared to other types of features. Figure 8 and Table 1 also provides information regarding the total features generated and number of significant features selected for global features (whole image features) for comparison purpose.

Percentage of significant features selected from each category
After selection of relevant features, the feature dimension is still high for classifier construction. In order to select features most relevant towards classification, we have performed feature selection on significant feature set. In our case, we have adopted wrapper feature selection [40]. The wrapper feature selection is an iterative procedure of maximizing classification performance. In the feature selection procedure, initially the data is divided into k folds (in our case k=5). Then the first feature is selected which has maximum mean classification performance across the folds. During the next iterations, the features together with previously selected features result in highest mean classification performance are selected. This process continues until there is little or no maximization towards classification performance. This process is in contrast to the filter selection approach [41] in which the feature ranking is performed according to individual evaluation performance of each feature. The individual evaluation performance is quantified according to their classification power and the features beyond certain threshold value are selected for classifier construction. However, our recent study [33] has shown that features selected by wrapper feature selection procedure outperforms filter feature selection despite the fact that filter selection approach selects the best features from the pool whereas wrapper feature selection does not necessarily follow the similar approach. Nevertheless, the wrapper feature selection approach has been performed on the features which have been filtered out with p v a l u e ≤0.05.
For quantification of classification performance of the wrapper feature selection, we have certain performance measures such as Area Under the Curve (AUC), linear classification accuracy and quadratic classification accuracy. The AUC can be quantified by determining the area under Receiving Operating Characteristics (ROC). ROC is a graphical plot that illustrates the performance of a binary classifier system by area under it as it is created by plotting the true positive rate against the false positive rate at various threshold settings [39]. The ROC curve of the selected regional image features has been shown in Fig. 12 with a red plot. The wrapper feature selection by maximizing AUC is termed as ‘wrapper-AUC’. On the other hand, linear classification accuracy is based on Linear Discriminant Analysis (LDA) by maximizing the distance between classes while minimizing the variance within each class. Quadratic Discriminant Analysis (QDA) works on similar principle as its linear counterpart except the classification boundary between classes is not linear and covariance matrix may not be identically equal for each class. The wrapper feature selection by maximizing LDA and QDA are termed as ‘wrapper-LDA’ and ‘wrapper-QDA’ respectively.
We have run the wrapper feature selection with the performance measures mentioned previously on the significant features. The number of features selected based on different feature selection methods (wrapper-AUC, wrapper-LDA and wrapper-QDA) is shown in Table 2. For example, for RIMONE dataset, when using wrapper-AUC, the total number of regional features selected is 11. The total number of feature selected for wrapper-LDA and wrapper-QDA is 7 and 9 respectively. The results of feature selection procedure have been shown in Fig. 9. The results shows that if the features are selected by AUC as performance measure of wrapper feature selection, we can achieve significantly higher classification accuracy compared to other performance measures. Also the classification power of regional features have been significantly better compared to global features both in case of fundus and SLO images. Moreover, the results in Table 2 shows that apart from the optic disc region, the other regions (such as I) can also play significant role in glaucoma classification. The list of features selected after wrapper feature selection for both fundus and SLO images have been shown in Table 3. The list has mostly been dominated by either textural or Gabor features. As a reference, \(H_{diffG(2)}^{OD}\) is the ‘Difference Entropy’ from Table 10 where OD in superscript represent the optic disc region, G in subscript represent the green channel where as 2 in subscript represent the offset value. If the number is not in subscript (as in case of \(corr_{G}^{OD}(2)\)), then it represent the scale (σ) value.

Feature selection procedure for both regional and whole image features in different classification performance
Classifier setting
On selected regional image features, we have constructed the binary classifier for glaucoma classification using Support Vector Machines (SVM) [42]. In recent studies [43], non-parallel SVM has performed better compared to traditional SVM methods. In traditional SVM, two parallel planes are generated such that each plane is as far apart as possible however in non-parallel SVM, the condition of parallelism is dropped. Among non-parallel SVM, Twin SVM has performed better compared to its other counterparts [44]. Mathematically, the Twin SVM is constructed by solving two quadratic programming problems
The performance of Twin SVM has been compared with traditional SVM. The traditional SVM classifier can be expressed as:
where C is the penalty term. k(x i ,x) represents the kernel function. In linear SVM case, k(x j ,x k ) = x j .x k . The kernel function in Eq. 17 can be replaced for developing non-linear SVM classifier such as Radial Based Function, polynomial and sigmoid SVM. The k(x j ,x k ) in Eq. 17 is replaced with gaussian kernel mentioned as: k(x i ,x)= exp(−Γ||x i −x||2). In polynomial function the k(x j ,x k )=(Γx j .x k )d and in sigmoid SVM k(x j ,x k ) = t a n h(Γx j .x k + c o e f f0), where c o e f f0 is sigmoid coefficient. We have tested different paremeters on libsvm [42] on C-SVC for each kernel function parameters and cost value. We have tested different parameter values for these classifiers and the values for which the respective SVM classifier performed the best in both fundus and SLO images have been shown in Table 4.
Apart from SVM classifiers, we have also compared the peformance with LDA and QDA as they have also been involved in the feature selection process
Experimental evaluation and discussion
Evaluation metrics
For optic disc segmentation performance, we have Dice Coefficient [45] as an evaluation measurement, which is the degree of overlap of two regions. It is defined as:
where A and B are the segmented regions surrounded by model boundary and annotations from the ophthalmologists respectively, ∩ denotes the intersection and ∪ denotes the union. Its value varies between 0 and 1 where a higher value, indicates an increased degree of overlap. Apart from that we have adopted standard evaluation metrics using accuracy (A c c), sensitivity (S n or true positive rate) and specificity (S p or false positive rate) described as follows:
where T P,T N,F P and FN are true positives, true negatives, false positives and false negatives respectively. The significance of the improvement of the classification accuracy has been evaluated by McNemar’s test [46]. The McNemar’s test can be used to compare classification results across different methods and can generate Chi-squared value as:
where c1 e r r and c2 e r r are the number of images misclassified by different methods. We have compared the classification performance of RIFM model to the geometric methods as well as non-geometric methods. The Chi-squared value generated is then converted to p v a l u e for testing statistical significance of the improvement. The test is considered statistically significant if the p v a l u e is below certain value. Typical standard values are 0.1, 0.05 and 0.01 (χ 2 = 2.706,3.841 and 6.635 respectively).
Accuracy comparison with the state-of-the-art approaches
We have conducted experimental evaluation on both fundus and SLO image datasets from three aspects:
-
1)
Optic disc segmentation accuracy performance.
-
2)
Accuracy performance based on different classification algorithms and feature selection methods.
-
3)
Accuracy performance comparison with either geometric or non-geometric methods.
The image datasets used for the evaluation are described in “Datasets used for experimentation”, consisting of a representative and heterogeneous image dataset including both fundus and SLO images totalling 189 images; 124 from fundus dataset and 65 from SLO dataset. Each of the fundus and SLO dataset has been split into cross-validation sets and the test sets. In the cross-validation sets, N-fold cross validation [12] has been performed for classification model validation. The essence of n-fold cross validation is to randomly divide a dataset into n equal sized subsets and of the n subsets, a single subset is retained as the validation data for testing the model, and the remaining n-1 subsets are used as training data. The cross-validation process is then repeated n times (the folds), with each of the n subsamples used exactly once as the validation data. The cross-validation accuracy has been determined after training the classifier on n-1 subsets and testing on the nth subset. This has been performed for each subset in the cross-validation set. The cross-validation sets for classifier training are different from that of feature selection process. The accuracy on the test sets for each dataset are then calculated after training the classifier on the images of cross-validation sets of the respective dataset. Additionally, to address dataset imbalance, the Ensemble Random Under Sampling (ERUS) is used, in which useful samples can be selected for learning classifiers [47].
Optic disc segmentation accuracy performance
We have compared our segmentation methods with clinical annotations and existing models such as Active Shape Model [48], Chan-Vese [49]. The experimental results are shown in Figs. 10 and 11 and our method outperforms the existing methods. The mean and standard deviation of Dice Coefficients of our previous approach [20] and proposed approach has been evaluated on both RIM-ONE and SLO datasets with respect to both healthy and glaucomatous images as shown in Table 5. Also some of the examples of optic disc segmentation compared to clinical annotations has been shown in Fig. 10. The visual results show that segmentation accuracy is quite comparable to clinical annotation; especially in the right column which represent the examples of glaucomatous optic disc with PPA.

Examples of optic disc segmentation using proposed approach a,b are examples from RIM-ONE and c,d are examples from SLO images. The red outline shows the original annotation around optic disc whereas the green outline shows the automatic annotations from proposed approach

Accuracy comparison based on different classification algorithms and feature selection methods
The performance of regional features selected under the proposed approach compared with other regional feature selection methods across different classifiers have been presented in Table 6 for cross-validation sets and in Table 7 for the test-sets. According to the results, the feature sets selected by AUC maximization have higher accuracy on both cross-validation sets and the test sets compared to the ones selected by maximization of linear and quadratic classification accuracy. The results also show that dropping the parallelization condition from the SVM can have marginal improvement in terms of classification accuracy; like in case of Twin SVM. Moreover, classifier with linear specifications i.e. Linear SVM and LDA have performed significantly better compared to other non-linear counterparts. The performance of Polynomial SVM is comparable to Linear SVM however, it has achieved this accuracy at degree d=1 which is the special case of linear classification. The performance of the classifiers on cross-validation sets and the test sets have been combined and detailed in Table 8. In Table 8, we have compared the classifier performance with respect to sensitivity and specificity along with classification accuracy. We have identified the best results of each classifier across different feature sets mentioned in Table 6. For example, Twin SVM has the best results on wrapper-AUC or RBF-SVM has the best results on wrapper-QDA so they are the best feature set for the respective classifiers. The results show that the non-linear classifiers such as RBF-SVM and QDA have high false negatives compared to their linear counterparts which have resulted the depreciation in their performance. The Twin SVM classifier has achieved the accuracy of 94.4 % on fundus images and 93.9 % on SLO image dataset.
Accuracy comparison with either geometric or non-geometric based methods
To validate our proposed method, we have compared the performance of RIFM with 1) geometrical based clinical indicators on glaucoma such as vertical and horizontal CDRs, vasculature shift, and 2) the existing methods using non-geometrical global features [15, 18, 19]. In case of geometrical indicators, both vertical as well as horizontal CDR has been clinically annotated for both fundus and SLO images whereas vasculature shift has been determined automatically using the method mentioned in [50]. The cutoff value for both CDRs is set to 0.55. In case of non-geometrical features, we have calculated global image features under the same procedure as in case of regional features except that they are calculated for whole optic disc cropped image. Like regional features, we have constructed a global image feature model under Twin SVM on the features selected by wrapper-AUC approach under the classifier parameters where global features performed the best. The performance comparison is shown with respect to ROC curves in Fig. 12 and has been quantified in Table 9. Moreover the significance of classification improvement of RIFM model has also been compared with other geometric and non-geometric based methods by McNemar’s test (4). The results show that in case of both fundus and SLO dataset, the RIFM model shows significant improvement in glaucoma classification in most of the geometric and non-geometric based methods (p v a l u e ≤0.05, 0.10). In case of clinically annotated vertical CDR and non-geometric textural features, the results can show improvement at significance level p v a l u e ≤0.10.

Comparison of Receiver Operating Characteristics of different feature sets mentioned in Table 9
Discussion
Based on our experimental evaluation, the proposed method after automatically locating and segmenting the optic disc as well as dividing the optic disc cropped image into different regions extract the regional features reflecting pixel appearance such as textural properties, frequency based information, gradient features etc. In this way the geometrical properties due to large cup size in glaucoma can be quantified and accommodated with textural changes within optic disc boundary. Moreover, the model can also accommodate the non-geometric based features from different regions around optic disc boundary. The feature selection and classification results suggests that different types of features for different regions of optic disc and its surroundings can result in better classification performance. The significance results shows that our proposed RIFM model has performed significantly better compared to the geometrical methods based on segmentation of glaucoma associated anatomical structures for determination of clinical indicators of either CDR or vasculature shift as well as non-geometrical methods based on global image feature model. This further validates our idea that if both geometrical and non-geometrical indications are combined together, this can significantly increase the glaucoma classification performance.
Conclusion
In this paper, we have proposed the novel computer-aided approach: Regional Image Features Model (RIFM) which can extract both geometric and non-geometric properties from an image and automatically perform classification between normal and glaucoma images on the basis of regional image information. The proposed method automatically localises and segments the optic disc, divides the optic disc surroundings into different regions and performs glaucoma classification on the basis of image-based information of different regions. The novelties of the work include 1) a new accurate method of automatic optic disc localisation; 2) a new accurate method of optic disc segmentation; 3) a new RIFM on extraction of both geometric and non-geometric properties from different regions of optic disc and its surroundings for classification between normal and glaucoma images.
The performance of our proposed RIFM model has been compared across different feature sets, classifiers and previous approaches and has been evaluated on on both fundus and SLO image datasets. The experimental evaluation result shows our approach outperforms existing approaches using either geometric or non-geometric approaches. The classification accuracy on fundus and SLO images is 94.4 % and 93.9 % respectively. The results validate our hypothesis of combining both geometrical and non-geometrical indications since they are significantly better compared to methods which are based on either geometrical or non-geometrical indications.
Further research is needed to test the model on datasets composed of healthy as well as various stages of glaucoma. Additionally, because the most common clinical indicator for glaucoma detection is to measure CDR value (based on manual approaches), we will further develop the proposed RIFM approach for automated CDR measurement.
References
Suzanne, R., The most common causes of blindness, 2011. http://www.livestrong.com/article/92727-common-causes-blindness.
Parekh, A., Tafreshi, A., Dorairaj, S., Weinreb, R. N., Clinical applicability of the international classification of disease and related health problems (icd-9) glaucoma staging codes to predict disease severity in patients with open-angle glaucoma. J. Glaucoma 23:e18–e22, 2014.
National Health Services UK, 2011. http://www.nhscareers.nhs.uk/features/2011/june/.
Tham, Y.-C., Li, X., Wong, T. Y., Quigley, H. A., Aung, T., Cheng, C.-Y., Global prevalence of glaucoma and projections of glaucoma burden through. Ophthalmology 121(2014):2081–2090, 2040.
Jonas, J., Budde, W., Jonas, S., Ophthalmoscopic evaluation of optic nerve head. Surv. Ophthalmol. 43:293–320, 1999.
Williams, G., Scott, I., Haller, J., Maquire, A., Marcus, D., McDonald, H., Single-field fundus photography for diabetic retinopathy screening: a report by the american academy of ophthalmology. Ophthamology 111:1055–1062, 2004.
Jelinek, H., and Cree, M., (Eds.), Automated Image Detection of Retinal Pathology. Taylor and Francis Group. 2010
Patton, N., Aslam, T. M., MacGillivray, T., Deary, I. J., Dhillon, B., Eikelboom, R. H., Yogesan, K., Constabl, I., Retinal image analysis: Concepts, applications and potential. Prog. Retin. Eye Res. 25:99 127, 2005.
Budenz, D. L., Barton, K., Whiteside-de Vos, J., Schiffman, J., Bandi, J., Nolan, W., Herndon, L., Kim, H., Hay-Smith, G., Tielsch, J. M., Prevalence of glaucoma in an urban west african population. JAMA Ophthalmol. 131:651–658, 2014.
Derick, R., Pasquale, L., Pease, M., Quigley, H., A clinical study of peripapillary crescents of the optic disc in chronic experimental glaucoma in monkey eyes. Arch. Ophthalmol. 112:846–850, 1994.
Nayak, J., Acharya, R., Bhat, P., Shetty, N., Lim, T.-C., Automated diagnosis of glaucoma using digital fundus images. J. Med. Syst. 33:337–346, 2009.
Smola, A., and Vishwanathan, S., Introduction to Machine Learning: Cambridge University Press, 2008.
Haleem, M. S., Han, L., Hemert, J. v., Li, B., Automatic extraction of retinal features from colour retinal images for glaucoma diagnosis: a review. Comput. Med. Imaging Graph. 37:581–596, 2013.
Bock, R., Meier, J., Nyúl, L., Hornegger, J., Michelson, G., Glaucoma risk index:automated glaucoma detection from color fundus images. Med. Image Anal. 14:471–481, 2010.
Dua, S., Acharya, U. R., Chowriappa, P., Sree, S. V., Wavelet-based energy features for glaucomatous image classification. IEEE Trans. Inf. Technol. Biomed. 16:80–87, 2012.
Breiman, L., Random forests, Tech. rep. Berkeley: University of California, 2001.
Keerthi, S., Shevade, S., Bhattacharyya, C., Murthy, K., Improvements to platt’s smo algorithm for svm classifier design, Tech. rep.: National University of Singapore, 1998.
Acharya, R., Dua, S., Du, X., Sree, V., Chua, C. K., Automated diagnosis of glaucoma using texture and higher order spectra features. IEEE Trans. Inf. Technol. Biomed. 15:449–455, 2011.
Noronhaa, K., Acharya, U., Nayak, K., Martis, R., Bhandary, S., Automated classification of glaucoma stages using higher order cumulant features. Biomed. Signal Process. Control 10:174–183, 2014.
Haleem, M. S., Han, L., Li, B., Nisbet, A., Hemert, J. v., Verhoek, M.: Automatic extraction of optic disc boundary for detecting retinal diseases. In: 14th IASTED International Conference on Computer Graphics and Imaging (CGIM) (2013)
Optos (2015). http://www.optos.com
Fumero, F., Alayon, S., Sanchez, J., Sigut, J., Gonzalez-Hernandez, M.: Rim-one: An open retinal image database for optic nerve evaluation. In: Proceedings of the 24th International Symposium on Computer-Based Medical Systems (CBMS) (2011)
Medical image analysis group. http://medimrg.webs.ull.es/research/retinal-imaging/rim-one/
Mahfouz, A., and Fahmy, A. S., Fast localization of the optic disc using projection of image features. IEEE Trans. Image Process. 19:3285–3289, 2010.
Reinhard, T., and anf Pouli, E.: Colour spaces for colour transfer. In: International Conference on Computational Color Imaging, pp. 1–15. Springer, Berlin (2011)
Zelinsky, L. G., A fast radial symmetry for detecting points of interest. IEEE Transactions of Pattern Analysis and Machine Intelligence 25:959–973, 2003.
Chaudhuri, S., Chatterjee, S., Katz, N., Nelson, M., Goldbaum, M., Detection of blood vessels in retinal images using two-dimensional matched filters. IEEE Transactions of Medical Imaging 8:263–269, 1989.
Romeny, B. M. T. H., Front-end vision and multi-scale image analysis: multi-scale computer vision theory and applications, Written in Mathematica, Berlin. Germany: Springer, 2003.
Lupascu, C. A., Tegolo, D., Trucco, E., Fabc: retinal vessel segmentation using adaboost. IEEE Trans. Inf. Technol. Biomed. 14:1267–1274, 2010.
Duda, R. O., Hart, P. E., Stork, D. G., (Eds.), Pattern Classification. New York: Wiley-Interscience, 2000
Haralick, R. M., Shanmugam, K., Dinstein, I., Textural features for image classification. IEEE Trans. Syst. Man Cybern. 3.
Zhang, Y., and Wu, L., Crop classification by forward neural network with adaptive chaotic particle swarm optimization. Sensors 11:4721–4743, 2011.
Haleem, M., Han, L., van Hemert, J., Li, B., Fleming, A., Retinal area detector from scanning laser ophthalmoscope images for diagnosing retinal diseases. IEEE J. Biomed. Health Informatics 19:1472–1482, 2015.
Adelson, E. H., Anderson, C. H., Bergen, J. R., Burt, P. J., Ogden, J. M., Pyramid methods in image processing. RCA Eng 29:33–41, 1984.
Itti, L., Koch, C., Niebur, E., A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 20:1254– 1259, 1998.
Daughman, J., Complete discrete 2-d gabor transforms by neural networks for image analysis and compression. IEEE Trans. Acoust. Speech Signal Process 36:1169–1179, 1988.
Chao, W.-l, Gabor wavelet transform and its application, Tech. rep, 2010.
Zhang, Y.-D., Wang, S.-H., Yang, X.-J., Dong, Z.-C., Liu, G., Phillips, P., Yuan, T.-F., Pathological brain detection in mri scanning by wavelet packet tsallis entropy and fuzzy support vector machine. SpringerPlus 716:1–12, 2015.
Alberg, A. J., Park, J. W., Hager, B. W., Brock, M. V., Diener-West, M., The use of overall accuracy to evaluate the validity of screening or diagnostic tests. J. Gen. Intern. Med. 19:460–465, 2004.
Serrano, A. J., Soria, E., Martin, J. D., Magdalena, R., Gomez, J.: Feature selection using roc curves on classification problems. In: The International Joint Conference on Neural Networks (IJCNN) (2010)
Liu, H., Motoda, H. (Eds.), Feature Selection for Knowledge Discovery and Data Mining. Norwell: Kluwer Academic Publishers, 1998
Chang, C.-C., and Lin, C.-J., LIBSVM: A library for support vector machines. ACM Trans Intell. Syst. Technol. 2:27:1–27:27, 2011. software available at, http://www.csie.ntu.edu.tw/cjlin/libsvm.
Zhang, Y.-D., Chen, S., Wang, S.-H., Yang, J.-F., Phillips, P., Magnetic resonance brain image classification based on weighted-type fractional fourier transform and nonparallel support vector machine. Int. J. Imaging Syst. Technol. 24:317– 327, 2015.
Xu, Z., Qi, Z., Zhang, J., Learning with positive and unlabeled examples using biased twin support vector machine. Neural Comput. Applic. 25:1303–1311, 2014.
Dice, L., Measures of the amount of ecologic association between species. Ecology 26:297–302, 1945.
Fagerland, M. W., Lydersen, S., Laake, P., The mcnemar test for binary matched-pairs data: mid-p and asymptotic are better than exact conditional. BMC Med. J. Methodol. 13:1– 8, 2013.
Han, L., and Levenberg, A., A scalable online incremental learning for web spam detection. Lecture Notes in Electrical Engineering (LNEE) 124:235–241, 2013.
Cootes, T., and Taylor, C., Statistical models of appearance for computer vision: Tech. rep., University of Manchester, 2004.
Chan, T. F., and Vese, L. A., Active contours without edges. IEEE Trans. Image Process. 10:266–277, 2001.
Fuente-Arriagaa, J. A. d. l., Felipe-Riverón, E. M., Garduño Calderónc, E., Application of vascular bundle displacement in the optic disc for glaucoma detection using fundus images. Comput. Biol. Med. 47:27–35, 2014.
Noronhaa, K., and Lim, C. M., Decision support system for the glaucoma using gabor transformation. Biomed. Signal Process. Control 15:18–26, 2015.
Acknowledgments
This work is fully supported by EPSRC-DHPA funded project Automatic Detection of Features in Retinal Imaging to Improve Diagnosis of Eye Diseases and Optos plc. (Grant Ref: EP/J50063X/1). Harvard Medical school provided SLO image data and made contributions to data annotation and domain knowledge. Dr. Pasquale is supported by Harvard Medical School Distinguished Scholar Award. Dr. Song is supported by a departmental K12 grant from the NIH through the Harvard Vision Clinical Scientist Development Program with grant number 5K12EY016335.
Author information
Authors and Affiliations
Corresponding author
Additional information
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
This article is part of the Topical Collection on Transactional Processing Systems
Appendix A
Appendix A
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Haleem, M.S., Han, L., Hemert, J.v. et al. Regional Image Features Model for Automatic Classification between Normal and Glaucoma in Fundus and Scanning Laser Ophthalmoscopy (SLO) Images. J Med Syst 40, 132 (2016). https://doi.org/10.1007/s10916-016-0482-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10916-016-0482-9