
Abstract
In this work, we propose a model order reduction framework to deal with inverse problems in a non-intrusive setting. Inverse problems, especially in a partial differential equation context, require a huge computational load due to the iterative optimization process. To accelerate such a procedure, we apply a numerical pipeline that involves artificial neural networks to parametrize the boundary conditions of the problem in hand, compress the dimensionality of the (full-order) snapshots, and approximate the parametric solution manifold. It derives a general framework capable to provide an ad-hoc parametrization of the inlet boundary and quickly converges to the optimal solution thanks to model order reduction. We present in this contribution the results obtained by applying such methods to two different CFD test cases.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Inverse problems is a wide family of problems that crosses many different sciences and engineering fields. Inverse problems aim to compute from the given observations the cause that has produced them, as also explained in [1, 2]. Formally, we can consider an input I and an output O, and suppose that there exists a map
that models a mathematical or physical law. The computation of the output as \(o={\mathcal {M}}(i)\) is called direct problem, whereas the problem of finding the input given the output is called inverse problem. Given a certain output \(o_t\), the inverse problem consists of inverting the map \({\mathcal {M}}\) and finding the input \(i_t\) which produces the output \(o_t\), i.e., which satisfies \({\mathcal {M}}(i_t)=o_t\). Inverse problems may be of interest for a lot of mathematical fields, from heat transfer problems to fluid dynamics. The case study which is here analysed is a Navier–Stokes flow in a circular cylinder, and the aim is to find the proper boundary condition in order to obtain the expected distribution within the domain. Such an application tries to solve a typical naval problem, numerically looking for the inlet setting which provides the right working condition during the optimization of the propulsion system. Propeller optimization is indeed very sensitive to modifications in the velocity distribution at the propeller plane: to obtain an optimized artifact it becomes very important to set up the numeric simulation such that the velocity distribution is as close as possible to the target distribution, usually collected by experimental tests. The problem is the identification of the inlet boundary condition, given the velocity distribution at the so-called wake, which is the plane (or a portion of it) orthogonal to the cylinder axis where the propeller operates. To achieve that, the inlet distribution is searched by parametrizing the target wake—by exploiting a neural network, as we will describe in the next paragraphs—and optimizing these parameters such that in the simulation the velocity is close to the target wake. It must be said that to produce meaningful results, we assume here the flow has a main direction that is perpendicular to the inlet and wake planes: in such a way, the distributions at these planes are similar to each other, allowing us to search for the optimal inlet among the parametrized wake distributions. Even if in this case the numerical experiments are conducted in a Computational Fluid Dynamics (CFD) setting, the methodology is in principle easily transferable to different contexts.
Typically, such an operation is performed within an optimization procedure, in which the direct problem is iteratively solved by varying the input until the desired output is reached. This, of course, implies the necessity to numerically parametrize the input in a proper way, possibly allowing a large variety of admissible inputs and at the same time a limited number of parameters. Moreover, the necessity to solve the direct problem for many different instances makes the entire process computationally expensive, especially dealing with the numerical solution of Partial Differential Equations (PDEs). A possible solution to overcome such computational burden is offered by the Reduced Order Modelling (\(\text {ROM}\)) techniques.
\(\text {ROM}\) constitutes a constantly growing approach for model simplification, allowing for a real-time approximation of the numerical solution of the problem at hand. Among the methods already introduced in the literature, the Proper Orthogonal Decomposition (\(\text {POD}\)) has become in recent developments an important tool for dealing with PDEs, especially in parametric settings [3,4,5,6]. Such a framework aims to efficiently combine the numerical solutions for different configurations of the problem, typically pre-computed using consolidated methods—e.g. finite volume, finite element — such that at any model inference all this information is combined for providing a fast approximation. Within iterative and many-query processes, like inverse problems, this methodology allows a huge computational gain. The many repetitions of the direct problem, needed to find the target input, can be performed at the reduced level, requiring then a finite and fixed set of numerical solutions only for building the \(\text {ROM}\). The coupling between \(\text {ROM}\) and the inverse problem has been already investigated in literature for heat flux estimation in a data assimilation context [7], in aerodynamic application [8], in haemodynamic problems [9]. An alternative way to efficiently deal with this kind of problem has been explored in a Bayesian framework [10]. Moreover, among all the contributions in literature we cite [11, 12] as an example of inverse problem with pointwise observations and inverse problem in a boundary element method context, respectively.
This contribution introduces an entire and novel machine learning pipeline to deal with the inverse problems in a \(\text {ROM}\) setting. In specific, we combine three different uses of Artificial Neural Network (\(\text {ANN}\)), that are: i) parametrization of the boundary condition given a certain target distribution or pointwise observations, ii) dimensionality compression of the discrete space of the original—the so-called full-order—model and iii) approximation of the parametric solution manifold. It derives a data-driven pipeline (graphically represented in Fig. 1) able to provide a parametrization of the original problem, which is successively exploited for the optimization in the reduced space. Finally, the optimization is carried out by involving a Genetic Algorithm (GA), but in principle can be substituted by any other optimization algorithm.

Flow diagram for the data-driven pipeline followed in the paper
The contribution presents in Sect. 2 an algorithmic overview of the employed methods, whereas Sect. 3 illustrates the results of the numerical investigation pursued to the above-mentioned test case. In particular, we present details for all the intermediate outcomes, comparing them to the results obtained by employing state-of-the-art techniques. Finally, Sect. 4 is dedicated to summarizing the entire content of the contribution, drawing future perspectives and highlighting the criticisms highlighted during the development of this contribution.
2 Methodology
We dedicate this section to providing an algorithmic overview of the numerical tools composing the computational pipeline.
2.1 Boundary Parametrization Using ANN
Neural networks are a class of regression techniques and the general category of Feed-forward neural networks has been the subject of considerable research in several fields in recent years. The capability of ANN to approximate any function [13] and the even greater computational availability allowed indeed the massive employment of such an approach to overcome many limitations. In the field of PDEs, we cite [14,15,16,17,18,19,20,21] as some of main impacting frameworks recently explored. A not yet investigated usage of ANN, to the best of authors’ knowledge, is instead the parametrization of a given (scattered) function. We suppose that we have a target distribution \( {\varvec{v}}^{\text {target}}= ({\varvec{v}}^{\text {target}}_i)_{i=1}^{P}\), corresponding to the wake velocity distribution in our case, which has P degrees of freedom. We want to reproduce this distribution by exploiting a neural network technique.
A neural network is defined as a concatenation of an input layer, multiple hidden layers, and a final layer of output neurons. An output of the i-th neuron in the l-th layer of the network is generally defined as:
where \(\sigma \) is the activation function (which provides non-linearity), \(b{^l_i}\) the bias and W refers to the so-called weights of the synapses of the network, \(N_l\) is the number of neurons of the l-th hidden layer, H is the number of layers of the network.
The bias and the weights are the hyperparameters of the network, that are tuned during the training procedure to converge to the optimal values for the approximation in hand. We can think of these hyperparameters as the degree of freedom of our approximation, allowing us to manipulate such distribution by perturbating them. We define the optimal hyperparameters (computed with a generic optimization procedure [22, 23]) as \(b^*\) and \(W^*\); the network exploiting these hyperparameters reproduces as output an approximation of our target wake distribution:
The input \({\textbf{x}}\) to the whole neural network in this paper corresponds to the polar coordinates of the points of the wake, so we have a two-dimensional input. We can then rearrange Eq. (1) to express the parametrized output of a single hidden layer as follows:
where \(\varvec{\mu }^l\) is the vector of parameters in layer l, which applies only to the bias of the layers. We finally obtain the parametrized output \(N({\textbf{x}}, \varvec{\mu })\).
The main advantage of this approach is the capability to parametrize any initial distribution, since the weights are initially learnt during the training and then manipulated to obtain its parametric version. On the other hand, the dimension of the weights is typically very large, especially in networks with more than one layer. In networks composed of a large number of layers, a high number of hyperparameters should be tuned. A possible solution to overcome such an issue could be to manipulate just a subset of all the hyperparameters. Indeed, in this paper, only the bias parameters of two hidden layers are perturbed.
Such a posteriori parametrization of any generic distribution is employed in this work to deal with the inverse problem. The main idea is to compute different inlet velocity distributions corresponding to different weights of the ANN. The weights perturbations are used as parameters to build the reduced order model, providing an ad-hoc parametrization of the boundary condition based on the target output. It must be said that such parametrization may lead to good results only if some correlation between the boundaries and the target output exists.
2.2 Model Order Reduction
\(\text {ROM}\)s are a class of techniques aimed to reduce the computational complexity of mathematical models.
The technique used in this paper is data-driven or non-intrusive ROM, which allows us to build a reduced model without requiring the knowledge of the governing equations of the observed phenomenon. For this reason, this technique is suitable to deal with experimental data and it has been widely used in numerical simulations for industrial, naval, biomedical, and environmental applications [24,25,26,27,28,29,30].
Non-intrusive \(\text {ROM}\)s are based on an offline-online procedure. Each stage of the procedure can be approached in different ways, which are analyzed in the following Sections. All the techniques presented in the next lines have been implemented in the Python package called EZyRB [31].
2.2.1 Dimensionality Reduction
In the dimensionality reduction step, a given set of high-dimensional snapshots is represented by a few reduced coordinates, in order to fight the curse of dimensionality and make the pipeline more efficient.
We consider the following matrix of M snapshots, collecting our data:
where \({\varvec{v}}^{\text {wake}}_i \in {\mathbb {R}}^P\), \(i=1,\dotsc ,M\) are the velocity distributions in our case, each one corresponding to a different set of parameters \(\mu _i \in {\mathbb {R}}^p\) for \(i=1,\dotsc ,M\). The goal is to calculate the reduced snapshots \(\{ \hat{{\varvec{v}}}^{\text {wake}}_i \in {\mathbb {R}}^L\}_{i=1}^M\) such that
where \(\Psi : {\mathbb {R}}^P \rightarrow {\mathbb {R}}^L\). We specify that the latent dimension \(L \ll P\) has to be selected a priori.
Such phase can be approached by making use of linear or non-linear techniques, such as the \(\text {POD}\) and the usage of an Autoencoder (\(\text {AE}\)), respectively.
Proper Orthogonal Decomposition In the first case, the offline part consists of the computation of a reduced basis, composed of a reduced number of vectors named modes. The main assumption on which it is based is that each snapshot can be approximated by a linear combination of modes:
with \(\varvec{\varphi }_i \in {\mathbb {R}}^P\) are the modes and \(a_i^k\) are the related modal coefficients.
The computation of modes in the \(\text {POD}\) procedure can be done in different ways, such as via Singular Value Decomposition (SVD) or the velocity correlation matrix. In the first case, the matrix \({\textbf{Y}}\) can be decomposed via singular value decomposition in the following way:
where the matrix \({\textbf{U}} \in {\mathbb {R}}^{P \times {L}}\) stores the \(\text {POD}\) modes in its columns and matrix \({\varvec{\Sigma }} \in {\mathbb {R}}^{{L} \times {L}}\) is a diagonal matrix including the singular values in descending order. The matrix of modal coefficients — so, the reduced coordinates — in this case can be computed by:
where the \({\hat{{\textbf{Y}}}} \in {\mathbb {R}}^{{L}\times M}\) columns are the reduced snapshots. In the second case, the POD space \({\mathbb {V}}_{POD} = \text {span} \{[{\varvec{\phi }}_i]_{i=1}^L\)} is found solving the following minimization problem:
where \({\textbf{Y}}^n\) is the n-th column of the matrix \({\textbf{Y}}\). This problem is equivalent to computing the eigenvectors and the eigenvalues of the velocity correlation matrix:
where \(\Omega \) is the domain on which the velocity is defined (the propeller wake plane in this case). The \(\text {POD}\) modes are expressed as:
where \(V^y\) stores the eigenvectors of the correlation matrix in its columns and \(\uplambda ^y_i\) are its eigenvalues.
Autoencoder \(\text {AE}\) refers to a family of neural networks that, for its architectural features, has become a mathematical tool for dimensionality reduction [17]. In general, an \(\text {AE}\) is a neural network that is composed of two main parts:
-
the encoder: a set of layers that takes as input the high-dimensionality vector(s) and returns the reduced vector(s).
-
the decoder, on the other hand, computes the opposite operation, returning a high-dimensional vector by passing as input the low-dimensional one.
The layers composing the \(\text {AE}\) could be in principle of any type — e.g. convolutional [32], dense—but in this work both the encoder and the decoder are feed-forward neural networks. For sake of simplicity, we assume here that both the encoder and the decoder are built with only one hidden layer and we denote by \({\mathcal {D}}\) the decoder and with \({\mathcal {E}}\) the encoder. If \({\varvec{v}}^{\text {wake}}\) is the input of the \(\text {AE}\), we denote by \({\tilde{{\varvec{v}}}^{\text {wake}}}=({\mathcal {D}} \circ {\mathcal {E}})({{\varvec{v}}^{\text {wake}}}) = \text {AE}({{\varvec{v}}^{\text {wake}}})\) the output of the encoder, where formally:
A generic structure of an autoencoder is schematized in Fig. 2.

Schematic structure of an autoencoder
Weights and activation functions can be different for encoder and decoder, and of course the case with more than one hidden layer for the encoder and the decoder can be easily derived from this formulation. The \(\text {AE}\) is trained by minimizing the following loss function:
where \({{\varvec{v}}^{\text {wake}}}\) is the original (high-dimensional) vector to reduce, \({\hat{{\varvec{v}}}^{\text {wake}}}\) represents the reduced coordinates and \({\tilde{{\varvec{v}}}^{\text {wake}}}\) is the predicted vector. In this way, the network weights are optimized such that the entire AE produces the approximation of the original vector, but compressing it onto an a priori reduced dimension. The learning step aims so to discover the latent dimension of the problem at hand.
For what concerns the test cases here considered, two different types of autoencoders are taken into account:
-
(i)
a linear autoencoder, i.e. without an activation function between the hidden layers, with a single hidden layer composed of a number of neurons equal to the reduced dimension: it should exactly reproduce the behavior of the POD;
-
(ii)
a non-linear autoencoder, i.e. with an activation function, and with multiple hidden layers, whose performance is compared to that of the POD.
2.2.2 Approximation Techniques
The problem in the online part is to predict the (unknown) latent dimension \(\tilde{{\varvec{v}}}^{\text {wake}}\) given a new parameter \(\varvec{\mu }\):
where \(\pi : {\mathbb {R}}^p \rightarrow {\mathbb {R}}^L\) is the mapping from parameter space to reduced space. We can approximate such mapping by means of interpolation techniques, such as Radial Basis Functions (\(\text {RBF}\)), or regression techniques, such as ANN, in order to predict the latent dimension for any new parameter. Finally, the approximation of the solution in the original (high-dimensional) space requires the expansion of the reduced coordinates, which relies on the inverse compression method computed during the dimensionality reduction.
Remark 1
Many approximation techniques can be employed to reconstruct the solution in reduced order models. For instance, two spread techniques are the \(\text {RBF}\) and the Gaussian Process Regression (GPR). However, we remark that many other approximants can be adopted, such as the Moving Least Squares approach (MLS), which is described in detail in [33, 34]. The reason for choosing the RBF approach is that it allows us to tune different parameters, such as the radius, and the kernel of the radial basis functions, in order to adapt our approximation to different settings of the training dataset.
Radial Basis Functions The \(\text {RBF}\) is an approximation technique that reconstructs the original field in the following way:
where \((\varvec{\phi }(\Vert \varvec{\mu }-\varvec{\mu }_i \Vert ))_{i=1}^M\) are called radial basis functions, each one associated with a different center \(\varvec{\mu }_i\) and weighted with a weight \(\omega _i\). The radial functions can have different expressions, in our case we consider the multiquadric functions \(\varvec{\phi }(r)=\sqrt{1+(\varepsilon r)^2}\), where \(r=\Vert \varvec{\mu }-\varvec{\mu }_i \Vert \).
Artificial Neural Networks The other technique here investigated to approximate the parametric solution manifold is ANN. The basic structure of the method is already explained in Sect. 2.1,
We consider a neural network composed of a unique hidden layer. Its structure is:
The weight matrix and bias of the ANN are found by training the neural network with the set of parameters and snapshots \((\varvec{\mu }_i, {{\varvec{v}}^{\text {wake}}_i})_{i=1}^M\). Then, the approximated solution \({\tilde{{\varvec{v}}}^{\text {wake}}}\) is computed from the related vector of parameters \(\varvec{\mu }\) as \({\tilde{{\varvec{v}}}^{\text {wake}}}=\text {ANN}{}(\varvec{\mu })\).
The reduced order techniques presented in this Section both for dimensionality reduction and approximation are applied in this paper to two different inverse problems. In particular, the following cases are considered:
-
1.
\(\text {POD}\)-\(\text {RBF}\);
-
2.
\(\text {POD}\)-ANN;
-
3.
\(\text {AE}\)-\(\text {RBF}\);
-
4.
\(\text {AE}\)-ANN; item[5.] non-linear \(\text {AE}\)-\(\text {RBF}\);
-
6.
non-linear \(\text {AE}\)-ANN.
2.3 Wake Optimization
The construction of the reduced order model is followed by the research of the vector of parameters which better reconstructs the velocity distribution we want to reproduce. This investigation is addressed by solving an optimization problem, in which the aim is to minimize the difference between the approximated wake distribution predicted by the ROM and the real wake distribution. The optimization problem can be addressed either by using a search-based, such as the genetic algorithm (\(\text {GA}\)), initially proposed in [35], or a gradient-based algorithm. In Sects. 3.2.3 and 3.3.2 we compare the results obtained employing both approaches.
Remark 2
However, it is worth remarking that the genetic algorithm allows us to reach the global theoretical minimum without getting stuck into a local minimum. Gradient-based methods, instead, require derivable objective functions and get trapped in local minima in non-convex optimization. The genetic algorithm requires a high number of evaluations, which is not a real issue since the employment of the reduced model, but it is able to converge to the global minimum. In a data-driven ROM framework, as the one proposed in this manuscript, the solution manifold is approximated with regression techniques, without any warranties on convexity. Thus, genetic methods offer a robust approach in this context, as demonstrated by its employment in similar frameworks [25, 36].
We dedicated this section to providing a basic introduction to the genetic method, retaining a full discussion out of the topic of the present work. For a deeper focus on genetic optimization, we refer the reader to the original contribution. The first step of the algorithm is the definition of a population composed of \(N_{pop}\) individuals, in our case vectors of parameters \((\varvec{\mu }_j)_{j=1}^{N_{pop}}\), composed of p genes, \(\varvec{\mu }_j \in {\mathbb {R}}^p\). Then, we proceed by defining the objective function which should be minimized. We indicate by \({\tilde{{\varvec{v}}}^{\text {wake}}_j} \equiv {\tilde{{\varvec{v}}}^{\text {wake}}}(\varvec{\mu }_j)\) the approximation of the wake distribution computed with the reduced order model that we are taking into account. We call \({{\varvec{v}}^{\text {target}}}(\varvec{\mu })\) the real wake distribution.
The objective function defined for each individual in the population is:
The \(\text {GA}\) consists in an iterative process composed of three main steps: selection, in which the best individuals are chosen; mate or crossover, where the genes of the best individuals are combined according to a certain mate probability; mutation, changing some of the genes of the individuals. This process is iterated a number of times which is named number of generations. Regarding the technical side, the \(\text {GA}\) has been performed using the open-source package DEAP [37].
3 Numerical Results
In the present Section, the methods presented in Sect. 2 are applied to the test case of the flow in a circular cylinder.
3.1 The Inverse Problem
The computational domain is a circular cylinder with height \(4.67 \, m\), diameter \(2.36 \, m\) and it is schematized in Fig. 4, where the inlet is indicated as \(\Gamma _i\), the outlet as \(\Gamma _o\) and the lateral surface of the cylinder as \(\Gamma _{side}\). The aim is to reconstruct the inlet velocity distribution given the velocity distribution at the so-called wake, which is a plane placed at a distance of 2.97 meters from the inlet plane, as showed in 4. This type of problem is known as inverse problem, which is in this case applied in a \(\text {CFD}\) setting. The physical problem at hand is modelled by the Navier-Stokes Equations (NSE) for incompressible flows. We call the fluid domain \(\Omega \in {\mathbb {R}}^3\), \(\Gamma \) its boundary; \(t \in [0,T]\) is the time, \({\textbf{u}}={\textbf{u}}({\textbf{x}},t)\) is the flow velocity vector field and \(p=p({\textbf{x}},t)\) is the normalized pressure scalar field divided by the fluid density, \(\nu =\) \({1.124} \times 10 ^{-6}{m^{2}}/s\) is the fluid kinematic viscosity. The strong form of the NSE is the following.

The boundary and initial conditions appearing in (5a) are the following:
-
at the inlet \(\Gamma _i\): \({\left\{ \begin{array}{ll} {\textbf{u}}=\mathbf {u_0},\\ \nabla p \cdot {\textbf{n}} = 0, \end{array}\right. }\) where \(\mathbf {u_0}=\mathbf {u_0}({\textbf{x}})=(0,f({\textbf{x}}),0)\) and \(f({\textbf{x}})\) is the distribution set at the inlet, specified in (6) and (7).
-
at the outlet \(\Gamma _o\): \( {\left\{ \begin{array}{ll} \nabla {\textbf{u}} \cdot {\textbf{n}} = {\textbf{0}},\\ p=0. \end{array}\right. } \)
-
on the walls \(\Gamma _{side}\): \( {\left\{ \begin{array}{ll} {\textbf{u}} \cdot {\textbf{n}} =0, \\ \nabla p \cdot {\textbf{n}} = 0. \end{array}\right. } \)
-
moreover, \({\textbf{u}}({\textbf{x}}, t) = {\textbf{0}}\) and \(p({\textbf{x}}, t)=0\), \(\forall {\textbf{x}} \in \Omega \) at initial time \(t=0\).
In the computation of the full order solutions of the NSE in (5a), the finite volume discretization is employed, by means of the open-source software OpenFOAM [38]. The finite volume method [39] is a mathematical technique that converts the partial differential equations (the NSE in our case) defined on differential volumes in algebraic equations defined on finite volumes. The computational mesh considered in this test case has been generated by blockMesh and snappyHexMesh and it is composed by \({1}\times 10^{6}\) cells. The mesh is a regular radial mesh, which presents 100 refinements both in the radial, the tangential and the axial direction, as can be seen from Fig. 3.

Representation of the mesh on a slice orthogonal to the cylinder axis (left), and on the walls (right)
The turbulence treatment at the full order level is characterized making use of the RANS (Reynolds Averaged Navier–Stokes) approach. This approach is based on the Reynolds decomposition, which was proposed for the first time by Osborne Reynolds [40], in which each flow field is expressed as the sum of its mean and its fluctuating part. The RANS equations are obtained by taking the time average of the NSE and adding a closure model for the well-known Reynolds stress tensor. The closure model considered in the full order model in OpenFOAM is the \(\kappa -\omega \) model, proposed in its standard form in [41], and in the SST form in [42]. This model is based on the Boussinesq hypothesis, which models the Reynolds stress tensor as proportional to the so-called eddy viscosity and it is based on the resolution of two additional transport equation for the kinetic energy \(\kappa \) and for the specific turbulent dissipation rate \(\omega \). In the full order model, we consider the SST \(\kappa -\omega \) model. The CFD simulation is run making use of the PIMPLE algorithm until convergence to a steady state (Fig. 4).

The computational domain
In this paper, the inverse problem presented is applied for two different wake distributions. The first one is a smooth function \(f:{\mathcal {W}}\rightarrow {\mathbb {R}}\) defined in all the wake plane \({\mathcal {W}}\), written as a function of the radial coordinate:
The second distribution is given as a set of pointwise observations only in a selected region of the wake plane. For the sake of simplicity only the distribution along the axis of the cylinder, which is the main direction of the flow, is taken into account. The contributions along the secondary directions are ignored. Thus, we denote with wake distribution or velocity distribution only the component of the velocity along the main direction of the flow. The observations are computed using the function f defined as
where x and y are the cartesian coordinates in the wake plane. In total we collect 36 observations by sampling with equispaced cartesian grid the domain \([-0.5, 0.5]^2\) in the wake plane.
3.2 First Test Case: A Smooth Distribution
In this Section of the results, the problem considered is the reconstruction of the inlet velocity distribution when the wake velocity has the smooth distribution in (6).
3.2.1 Parametrization Using \(\text {ANN}\)
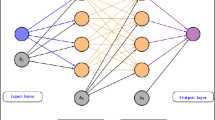
The first step in the resolution of the inverse problem is the parametrization of the real velocity distribution at the wake through a fully-connected \(\text {ANN}\). The \(\text {ANN}\) is represented in Fig. 5 and it is composed by 3 hidden layers, with 10, 5 and 3 neurons, respectively. The inputs are the polar coordinates of the wake points and the output is the wake velocity distribution; the degree of freedom of the distribution is \(P=10001\), which corresponds to the number of points at the inlet.
As explained in Sect. 2.1, the parameters coincide with a subset of weights of the \(\text {ANN}\). In particular, our choice is to consider 4 parameters, given by the biases of the last two layers.
The main idea is to generate M different distributions from the \(\text {ANN}\) by randomly perturbating the weights considered as parameters. Those distributions are set as inlet distributions in the full order model. The perturbated parameters and the wake distributions obtained from the full order computation are considered as parameters and snapshots, respectively, for the formulation of the \(\text {ROM}\).
In Fig. 6, the following distributions are represented from the left to the right: the distribution predicted from the \(\text {ANN}\) considering the same parameters as in the training stage; the real target wake distribution; two among the M distributions obtained by perturbating the parameters.

Structure of the \(\text {ANN}\) used for parametrization

First test case: parametrization of the given target sinusoidal function using a \(\text {ANN}\): from left to right are sketched the distribution after the training phase, the original distribution, and two perturbed configurations
3.2.2 Model Order Reduction
The distributions obtained by the parametrization described in Sect. 3.2.1 are then used as inlet initial conditions to run a set of M offline simulations, following the setting described in Sect. 3.1. The perturbed parameters of the ANN and the wake distributions found from high-fidelity simulations are then used to perform a model reduction. In particular, in this Section different types of techniques for the reduction and approximation stages of the \(\text {ROM}\) are evaluated and compared and the models considered are here listed:
-
1.
\(\text {POD}\)-\(\text {RBF}\);
-
2.
\(\text {POD}\)-\(\text {ANN}\);
-
3.
\(\text {AE}\)-\(\text {RBF}\);
-
4.
\(\text {AE}\)-\(\text {ANN}\).
-
5.
Non linear \(\text {AE}\)-\(\text {RBF}\);
-
6.
Non linear \(\text {AE}\)-\(\text {ANN}\).
The details related to the structure of the neural networks and the hyperparameters used for training, i.e. the learning rate, the stopping criteria, the number of hydden layers and of neurons for each layer, are defined in the discussion Sect. 3.4.
First of all, we consider a comparison regarding the dimensionality reduction step. The reduced dimension considered in this test case is 3 and we consider a linear \(\text {AE}\), i.e. without any activation function, composed by a single hidden layer of 3 neurons for both the encoder and the decoder parts. The idea is indeed to reproduce the behaviour of the \(\text {POD}\). A preliminary study is the graphical comparison between the \(\text {POD}\) and the \(\text {AE}\) modes. In particular, the \(\text {AE}\) modes are computed by taking as input to the decoder part of the network the identity matrix of size 3. Since the \(\text {AE}\) does not include any non linear computation, the operation is linear and ideally identical to the computation of the first 3 \(\text {POD}\) modes. From Fig. 7, the shapes of the first 3 \(\text {POD}\) and \(\text {AE}\) modes appear similar.

The \(\text {POD}\) and \(\text {AE}\) modes. Modes in (b) are obtained considering a linear autoencoder
In Fig. 8 we provide a representation of the error in the \(L^2\) norm for: (a) a fixed test dataset; (b) the training dataset used to build each \(\text {ROM}\). In this sensitivity analysis, the test dataset is fixed and composed by 10 snapshots and the number of snapshots used to train the reduced models varies between 10 and 90.
Considering a dataset composed by n element, we first define the relative error for each i-th element, say:
where \(\tilde{{\varvec{v}}}^{\text {wake}}_i\) is the velocity distribution predicted by the reduced model starting from the test parameter, and \({\varvec{v}}^{\text {wake}}_i\) is the full-order snapshot in the test dataset. Then, the mean over all the elements of the test dataset is computed: \((\sum _{i=1}^{n} \varepsilon _i)/n\). This definition applies to both the test and the training datasets and it is used to compute the errors represented in Fig. 8. The neural networks appearing in \(\text {ROM}\)s are trained 3 times and Fig. 8 provides the mean test and train errors among the 3 different runs, to ensure a more reliable analysis of the \(\text {ROM}\)s accuracy.
As can be seen from Fig. 8, the results obtained for the test error of \(\text {POD}\)-\(\text {RBF}\) and \(\text {AE}\)-\(\text {RBF}\) are similar to each other and, as intuitively expected, the general trend is decreasing as the number of training snapshots increases. The reduced methods which include a regression technique for the approximation, i.e. the \(\text {ANN}\), produce better results in terms of test error with respect to the interpolating technique. In particular, the regression technique outperforms the classical \(\text {RBF}\) if we consider a small number of training snapshots; however, the results obtained by the two approximating techniques are similar when a larger training dataset is used to train the \(\text {ROM}\).

First test case: sensitivity analysis for all the \(\text {ROM}\)s with the reduced dimension \(L=3\). Error is shown for test (left) and training (right) datasets
Remark 3
The behavior of the neural networks (both the \(\text {AE}\) used for reduction and the ANN used as approximant) strongly depends on the hyperparameters of the networks. This instability occurs also in the case of nonlinear \(\text {AE}\). Indeed, in this case the training error outperforms the results obtained with the \(\text {POD}\), but the test error remains close to the one obtained with a standard \(\text {POD}\) approach, leading to the overfitting phenomenon. A wider discussion on the stability issues related to neural networks will be undertaken in Sect. 3.4.
3.2.3 Wake Optimization
In this Section, two different optimization methods are exploited to find the combination of parameters that provides the highest accuracy in the reconstruction of the original wake. In particular, the results obtained with a genetic algorithm are compared to those obtained with a gradient-based method. Both optimization processes exploit the \(\text {ROM}\) potentiality to predict the velocity distribution corresponding to each evaluation point in the parameter space. The reduced model taken into account is \(\text {POD}\)-\(\text {ANN}\), which provided the highest precision in the sensitivity analysis in 3.2.2 when the number of snapshots used for training is 90.
The \(\text {GA}\), composed by the selection, crossover and mutation steps, is evolved for 20 generations, considering an initial population of 200 individuals, where each individual is represented by a different combination of the four parameters used for the wake parametrization in Sect. 3.2.1. All the attributes of each individual are in the interval \([-0.5, 0.5]\). The fitness of each individual of the population, i.e. the objective function minimized in the \(\text {GA}\), is the relative error of the wake obtained from the \(\text {ROM}\) with respect to the reference wake we want to reproduce. We specify here more details about the implementation of the genetic evolution:
-
in the mate stage, a blend crossover is performed, that modifies in-place the input individuals;
-
in the mutation step, a Gaussian mutation of mean \(\mu =0\) and standard deviation \(\sigma =1\) is applied to the input individual. The independent probability for each attribute to be mutated is set to 0.5;
-
the evolutionary algorithm employed in the genetic process is the \((\mu + \uplambda )\) algorithm, which selects the \(\mu =50\) best individuals for the next generation and produces \(\uplambda =100\) children at each generation. Moreover, the probabilities that an offspring is produced by crossover and by mutation are set to 0.4 and 0.6, respectively.
On the other hand, for the gradient optimization we considered the BFGS (Broyden-Fletcher-Goldfarb-Shanno) algorithm. The starting point chosen in the function evaluation is \([0.5, -0.5, -0.5, 0.5]\). The algorithm evaluated the derivative of the objective function via forward differences, setting the absolute step size to \({1}\times {10^{-17}}\).
The optimal individual obtained from the genetic optimization is \(\begin{bmatrix}-0.157&-0.179&-0.157&0.0851 \end{bmatrix}\), whereas the optimal individual predicted by the gradient-based algorithm is \(\begin{bmatrix} 0.00611&-0.117&-0.0095&0.0143\end{bmatrix}\). The final value of the objective function for the optimal individual is \(\sim 3.89 \, \%\) for the genetic algorithm, and \(\sim 3.94 \, \%\) for the gradient algorithm. The graphical representations of the optimal and of the real distributions are displayed in Fig. 9.

First test case: graphical representations of the exact benchmark wake (left), the optimal wakes obtained with a genetic (center) and gradient (right) optimization
Remark 4
Although the two methods reach similar precision, the genetic algorithm is preferred since the gradient method is significantly influenced by the choice of the initial guess and by the step size used to evaluate the approximated derivative. We will show the numerical evidence for this argumentation in Sect. 3.4.
3.3 Second Test Case: A Set of Pointwise Observations
In practical applications, the available data is typically provided not in the form of a smooth distribution, but in a small number of pointwise observations, which are usually localized on a reduced part of the computational domain. In this section, the known data at the wake is composed of a set of 36 measurements placed inside a square of side 1 m centered on the wake plane. The reference distribution considered is expressed in (7).
The logical passages followed in Sect. 3.2 are reproduced in the present section with a different set of data.
3.3.1 Parametrization Using \(\text {ANN}\)
The \(\text {ANN}\) used to parametrize the wake in this test case is composed of 3 hidden layers, the first one with 8 neurons and the other two with 2 neurons. The number of parameters is 6 in this application and coincides with the perturbations of the weight matrix and the bias of the last hidden layer. The \(\text {ANN}\) is trained for 50000 epochs with a learning rate of \(3\times 10^{-3}\). Since in this numerical experiment there is no radial symmetry (contrary to the previous test case) we add an additional contribution to the loss term to force the continuity between 0 and \(2\pi \) angles. Formally, the loss to minimize during the train is
where \(MSE(\cdot , \cdot )\) is the mean square error, \(\uplambda \) is a weight of the additional contribution (here \(\uplambda = 1\)) and \(r_i\) for \(i = 1,\dotsc ,100\) are the equispaced sample points we spanned along the radius at the angles 0 and \(2\pi \). Figure 10 shows indeed a continuous surface that keeps such a feature also after the perturbation of the weights.

Second test case: parametrization of the given target using a \(\text {ANN}\): from left to right are sketched the distribution after the training phase, the original observations, and two perturbed configurations
As already done in Sect. 3.2.1, M sets of parameters are generated as random perturbations in the interval \([-1,1]\), which will be used as parameters of the \(\text {ROM}\). The \(\text {ANN}\) perturbed with the generated parameters is used to obtain M new velocity distributions, which are set as inlet distributions for the full-order model. Then, from the full-order simulations, the wake distributions corresponding to each set of parameters are obtained and considered as snapshots for the \(\text {ROM}\) (Fig. 11).
3.3.2 Model Order Reduction and Optimization
From the sensitivity analysis in Sect. 3.2.2 the combination of the \(\text {AE}\) and the \(\text {ANN}\) proved to have the highest precision in the reconstruction of the wake. For this reason, the \(\text {AE}\)-\(\text {ANN}\) is the \(\text {ROM}\) which is chosen in this test case to train the optimization algorithm and to provide the best (approximated) wake.

Second test case: sensitivity analysis for all the \(\text {ROM}\)s with the reduced dimension \(L=4\). Error is shown for the testing (left) and training (right) datasets
The \(\text {GA}\), composed by the selection, mate, and mutation, is here iterated for 20 generations. The number of individuals considered is 200 for the first generation and 100 for all the other generations. The fitness is the relative error between the real wake we want to reproduce and the wake reconstructed by the \(\text {ROM}\), where only the points in data are considered. In this experiment, the fitness decreases as the population evolves, until a percentage error of \(\simeq 49 \%\) is reached. Also in this case, the BFGS technique is not able to reach that fitness and gets blocked instead in some local minima at \(61 \%\) of error with respect to the target wake.
Figure 12 shows the graphical representation of the optimum wake obtained from the \(\text {GA}\). From a graphical point of view, the optimization is able to capture the trend exhibited by the pointwise measurements. However, the error remains high after the optimization since the data in this test case is not given by a target smooth distribution, but by a few amount of points. Another possible issue is that the points are given only in a limited region of the wake, leading to a more difficult reconstruction of the distribution at the inlet, especially in the external region.

Second test case: the target output at wake plane (left) and the optimum representation, obtained with a genetic algorithm (right)
3.4 Discussion
This Section is dedicated to a wider discussion of the numerical results obtained in Sects. 3.2 and 3.3.
Table 1 provides a summary of the results obtained for the two test cases. The first thing that emerges from the table is that none of the methods performs better than the others for each different value of the training snapshots. In general, for the first test case, the methods that provide the highest accuracy on the test snapshots are the \(\text {POD}\)-ANN and the linear \(\text {AE}\)-ANN, as can be seen also from Fig. 8. On the other hand, in the second test case, the reduced order methods employing the nonlinear autoencoder provide the best results in most of the M values, as can be seen in Fig. 11. For what concerns the training error, from both Figs. 8 and 11 we can deduce that the introduction of non-linearity in the reduction stage leads to a better reconstruction of the training snapshots, especially when M is small, i.e. with a limited amount of training data. Therefore, especially in the first test case, the autoencoder reaches a high accuracy on the train snapshots, but it is not able to generalize the information learned during training, leading to high errors on the test database. Indeed, the worst results in the first case are obtained with the nonlinear \(\text {AE}\) and are highlighted in red in Table 2. This behavior describes the overfitting phenomenon, which is here mitigated by the addition of a regularization term in the loss function, say:
where \(\Vert {\textbf{W}}\Vert \) is the \(L^2\) norm of the weight matrix, i.e. the sum over all the squared weight values, and \(\alpha \) is named weight decay.
In addition, we provide here different arguments to explain the stability issues concerning the neural networks’ performance:
-
The networks are highly influenced by the choice of the hyper-parameters, i.e. the learning rate, the structure of the hidden layers, the stopping criteria, and the weight decay. In order to have a good result for each value of M, the value of the hyperparameters should be tuned ad-hoc considering each case individually. In our analysis, instead, we consider the parameters fixed for each method for a fair comparison. These values are reported in Appendix 1.
-
The different performance of the autoencoder in the two test cases depends on the input data. We obtained better results in the second test case, where the \(\text {POD}\) has poor accuracy and is not able to capture the system’s behavior. To support this argumentation, we provide the results obtained in the first test case when \(L=1\). From Fig. 13 we can notice that the autoencoder improves the results obtained with the \(\text {POD}\) when M is low (Table 3).

First test case: sensitivity analysis for all the \(\text {ROM}\)s with the reduced dimension \(L=1\). Error is displayed for test (left) and training (right) datasets
An additional point that can be discussed is the type of optimization algorithm used. As pointed out in Sect. 3.2.3, the genetic algorithm is preferred to a gradient-based algorithm, because the gradient method can get stuck into local minima. The evidence of this statement is provided in Table 4, where we show the results obtained with the BFGS method starting from different initial guesses. In the first three cases analyzed, the method converges to three different local minima; in the last two cases, it gets stuck in the first evaluation point.
4 Conclusion
We presented in this paper a data-driven computational pipeline that allows us to efficiently face inverse problems by means of the model order reduction technique. Neural networks are involved in the such framework at three different levels:
-
The parametrization of a given (generic) wake distribution by perturbating a subset of the weights of a fully-connected neural network. The parameters are exploited to obtain the inlet distributions of the full-order simulations. The wake distributions obtained from the full-order simulations are considered snapshots associated with the input parameters, obtaining a parametrization of the original problem (Table 5).
-
The compression of the dimensionality of the full-order snapshots, which typically belong to high-dimensional spaces, obtained with a properly structured autoencoder;
-
The approximation of the solution manifold, allowing for predicting new solutions for any unseen parameters. This last task is obtained with a second fully-connected neural network.
The results obtained by both the test cases in this work are promising. The neural network parametrization shows the possibility to produce several different distributions playing with very few parameters (4 and 6), becoming a valuable tool also for such an objective. Of course, the benefits of such parametrization are strictly related to the problem at hand, since here we are assuming that the target distribution is somehow related to the boundary condition. The investigation of the parametric configuration shows also a large range of admissible distributions. However, we highlight there is no possibility to precisely select the region of interest for the parametrization and the weights of the neural network which have been perturbated have no physical significance linked to the wake velocity distribution. Dimensionality compression and manifold approximation are already investigated uses of neural networks, and also in this contribution, the results confirm their better performances with respect to the more consolidated techniques.
Possible future developments of the presented pipeline may interest the parametrization through neural networks: at the current stage, it results in a sort of black-box procedure, since the parameters and their ranges are selected following a trial and error process. Such an issue can be alleviated by looking at the intermediate output—the output of the hidden layers of the network—to propose a meaningful criterion for parameter selection.
Data availability
Enquiries about data availability should be directed to the authors.
Abbreviations
- \(\text {CFD}\) :
-
Computational fluid dynamics
- \(\text {ROM}\) :
-
Reduced order model
- PDE:
-
Partial differential equation
- \(\text {POD}\) :
-
Proper orthogonal decomposition
- \(\text {ANN}\) :
-
Artificial neural network
- \(\text {AE}\) :
-
AutoEncoder
- \(\text {RBF}\) :
-
Radial basis function
- \(\sigma \) :
-
Activation function in \(\text {ANN}\)
- M :
-
Number of snapshots in \(\text {ROM}\)
- p :
-
Number of parameters used in \(\text {ROM}\)
- P :
-
Number of degrees of freedom for the velocity field
- L :
-
Latent dimension
- \((\varvec{\varphi })_{i=1}^M\) :
-
Velocity \(\text {POD}\) modes
- \(\Vert \cdot \Vert \) :
-
Norm in \(L^2\)
References
Cetrangolo, A.: Reduced order methods for inverse problem in CFD. Master Thesis, Politecnico di Torino (2021)
Richter, M.: Inverse Problems: Basics, Theory and Applications in Geophysics. Springer, Switzerland (2020). https://doi.org/10.1007/978-3-319-48384-9
Salmoiraghi, F., Scardigli, A., Telib, H., Rozza, G.: Free-form deformation, mesh morphing and reduced-order methods: enablers for efficient aerodynamic shape optimisation. Int. J. Comput. Fluid Dyn. 32(4–5), 233–247 (2018). https://doi.org/10.1080/10618562.2018.1514115
Quarteroni, A., Manzoni, A., Negri, F.: Reduced Basis Methods for Partial Differential Equations: An Introduction, 1st edn., p. 296. Springer, Switzerland (2015). https://doi.org/10.1007/978-3-319-22470-1
Hesthaven, J.S., Rozza, G., Stamm, B.: Certified Reduced Basis Methods for Parametrized Partial Differential Equations, 1st edn., p. 135. Springer, Switzerland (2015)
Rozza, G., Hess, M., Stabile, G., Tezzele, M., Ballarin, F.: Basic ideas and tools for projection-based model reduction of parametric partial differential equations. In: Benner, P., Grivet-Talocia, S., Quarteroni, A., Rozza, G., Schilders, W.H.A., Silveira, L.M. (eds.) Model Order Reduction, vol. 2, pp. 1–47. De Gruyter, Berlin (2020). https://doi.org/10.1515/9783110671490-001
Morelli, U.E., Barral, P., Quintela, P., Rozza, G., Stabile, G.: A numerical approach for heat flux estimation in thin slabs continuous casting molds using data assimilation. Int. J. Numer. Meth. Eng. 122(17), 4541–4574 (2021). https://doi.org/10.1002/nme.6713
Bui-Thanh, T., Damodaran, M., Willcox, K.: Aerodynamic data reconstruction and inverse design using proper orthogonal decomposition. AIAA J. 42(8), 1505–1516 (2004). https://doi.org/10.2514/1.2159
Lassila, T., Manzoni, A., Quarteroni, A., Rozza, G.: A reduced computational and geometrical framework for inverse problems in hemodynamics. Int. J. Numer. Methods Biomed. Eng. 29(7), 741–776 (2013). https://doi.org/10.1002/cnm.2559
Li, J., Marzouk, Y.M.: Adaptive construction of surrogates for the Bayesian solution of inverse problems. SIAM J. Sci. Comput. 36(3), 1163–1186 (2014). https://doi.org/10.1137/130938189
Vitale, G., Preziosi, L., Ambrosi, D.: Force traction microscopy: an inverse problem with pointwise observations. J. Math. Anal. Appl. 395(2), 788–801 (2012). https://doi.org/10.1016/j.jmaa.2012.05.074
Huang, C.-H., Chen, C.-W.: A boundary element-based inverse-problem in estimating transient boundary conditions with conjugate gradient method. Int. J. Numer. Methods Eng. 42(5), 943–965 (1998). https://doi.org/10.1002/(SICI)1097-0207(19980715)42:5<943::AID-NME395>3.0.CO;2-V
Hornik, K., Stinchcombe, M., White, H.: Multilayer feedforward networks are universal approximators. Neural Netw. 2(5), 359–366 (1989). https://doi.org/10.1016/0893-6080(89)90020-8
Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019). https://doi.org/10.1016/j.jcp.2018.10.045
Chen, W., Wang, Q., Hesthaven, J.S., Zhang, C.: Physics-informed machine learning for reduced-order modeling of nonlinear problems. J. Comput. Phys. 446, 110666 (2021). https://doi.org/10.1016/j.jcp.2021.110666
Hesthaven, J.S., Ubbiali, S.: Non-intrusive reduced order modeling of nonlinear problems using neural networks. J. Comput. Phys. 363, 55–78 (2018). https://doi.org/10.1016/j.jcp.2018.02.037
Lee, K., Carlberg, K.T.: Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. J. Comput. Phys. 404, 108973 (2020). https://doi.org/10.1016/j.jcp.2019.108973
Pichi, F., Ballarin, F., Rozza, G., Hesthaven, J.S.: Artificial neural network for bifurcating phenomena modelled by nonlinear parametrized PDEs. PAMM 20(S1), 202000350 (2021). https://doi.org/10.1002/pamm.202000350
Lu, L., Jin, P., Pang, G., Zhang, Z., Karniadakis, G.E.: Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell. 3(3), 218–229 (2021). https://doi.org/10.1038/s42256-021-00302-5
Wang, S., Wang, H., Perdikaris, P.: Learning the solution operator of parametric partial differential equations with physics-informed DeepOnets. Sci. Adv. (2021). https://doi.org/10.1126/sciadv.abi8605
Papapicco, D., Demo, N., Girfoglio, M., Stabile, G., Rozza, G.: The neural network shifted-proper orthogonal decomposition: a machine learning approach for non-linear reduction of hyperbolic equations. Comput. Methods Appl. Mech. Eng. 392, 114687 (2022). https://doi.org/10.1016/j.cma.2022.114687
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back-propagating errors. Nature 323(6088), 533–536 (1986)
Rojas, R.: The backpropagation algorithm. In: Neural Networks, pp. 149–182. Springer, Berlin (1996)
Tezzele, M., Demo, N., Mola, A., Rozza, G.: An integrated data-driven computational pipeline with model order reduction for industrial and applied mathematics. Mathematics in Industry. In: Günther, M., Schilders, W. (eds.) Novel Mathematics Inspired by Industrial Challenges. Springer, Switzerland (2022)
Demo, N., Ortali, G., Gustin, G., Rozza, G., Lavini, G.: An efficient computational framework for naval shape design and optimization problems by means of data-driven reduced order modeling techniques. Bollettino dell’Unione Matematica Italiana (2020). https://doi.org/10.1007/s40574-020-00263-4
Tezzele, M., Demo, N., Stabile, G., Mola, A., Rozza, G.: Enhancing CFD predictions in shape design problems by model and parameter space reduction. Adv. Model. Simul. Eng. Sci. (2020). https://doi.org/10.1186/s40323-020-00177-y
Georgaka, S., Stabile, G., Star, K., Rozza, G., Bluck, M.J.: A hybrid reduced order method for modelling turbulent heat transfer problems. Comput. Fluids 208, 104615 (2020). https://doi.org/10.1016/j.compfluid.2020.104615
Dutta, S., Farthing, M.W., Perracchione, E., Savant, G., Putti, M.: A greedy non-intrusive reduced order model for shallow water equations. J. Comput. Phys. 439, 110378 (2021)
Zancanaro, M., Mrosek, M., Stabile, G., Othmer, C., Rozza, G.: Hybrid neural network reduced order modelling for turbulent flows with geometric parameters. Fluids 6(8), 296 (2021). https://doi.org/10.3390/fluids6080296
Girfoglio, M., Scandurra, L., Ballarin, F., Infantino, G., Nicolo, F., Montalto, A., Rozza, G., Scrofani, R., Comisso, M., Musumeci, F.: Non-intrusive data-driven ROM framework for hemodynamics problems. Acta. Mech. Sin. 37(7), 1183–1191 (2021). https://doi.org/10.1007/s10409-021-01090-2
Demo, N., Tezzele, M., Rozza, G.: EZyRB: easy reduced basis method. J. Open Source Softw. 3(24), 661 (2018). https://doi.org/10.21105/joss.00661
Romor, F., Stabile, G., Rozza, G.: Non-linear manifold rom with convolutional autoencoders and reduced over-collocation method. arXiv preprint arXiv:2203.00360 (2022)
Levin, D.: The approximation power of moving least-squares. Math. Comput. 67(224), 1517–1531 (1998)
Lancaster, P., Salkauskas, K.: Surfaces generated by moving least squares methods. Math. Comput. 37(155), 141–158 (1981)
Holland, J.H.: Genetic algorithms and the optimal allocation of trials. SIAM J. Comput. 2(2), 88–105 (1973). https://doi.org/10.1137/0202009
Demo, N., Tezzele, M., Mola, A., Rozza, G.: Hull shape design optimization with parameter space and model reductions, and self-learning mesh morphing. J. Mar. Sci. Eng. (2021). https://doi.org/10.3390/jmse9020185
Fortin, F.-A., De Rainville, F.-M., Gardner, M.-A., Parizeau, M., Gagné, C.: DEAP: evolutionary algorithms made easy. J. Mach. Learn. Res. 13, 2171–2175 (2012)
OpenFOAM website. https://openfoam.org/
Moukalled, F., Mangani, L., Darwish, M.: The Finite Volume Method in Computational Fluid Dynamics, vol. 113. Springer, Switzerland (2016). https://doi.org/10.1007/978-3-319-16874-6
Reynolds, O.: IV. On the dynamical theory of incompressible viscous fluids and the determination of the criterion. Philos. Trans. R. Soc. Lond. 186, 123–164 (1895). https://doi.org/10.1098/rsta.1895.0004
Kolmogorov, A.N.: Equations of turbulent motion in an incompressible fluid. In: Dokl. Akad. Nauk SSSR, vol. 30, pp. 299–303 (1941)
Menter, F.R.: Two-equation eddy-viscosity turbulence models for engineering applications. AIAA J. 32(8), 1598–1605 (1994). https://doi.org/10.2514/3.12149
Funding
Open access funding provided by Scuola Internazionale Superiore di Studi Avanzati - SISSA within the CRUI-CARE Agreement. This work was partially funded by INdAM-GNCS 2020-2021 projects, by European High-Performance Computing Joint Undertaking project Eflows4HPC GA N. 955558, by PRIN “Numerical Analysis for Full and Reduced Order Methods for Partial Differential Equations” (NA-FROM-PDEs) project by European Union Funding for Research and Innovation—Horizon 2020 Program—in the framework of European Research Council Executive Agency: H2020 ERC CoG 2015 AROMA-CFD project 681447 “Advanced Reduced Order Methods with Applications in Computational Fluid Dynamics” P.I. Professor Gianluigi Rozza.
Author information
Authors and Affiliations
Contributions
Conceptualization: AI, ND; Methodology: AI, ND; Formal analysis and investigation: AI; Writing—original draft preparation: AI; Writing—review and editing: ND, GR; Funding acquisition: GR; Supervision: GR.
Corresponding author
Ethics declarations
Conflict of interest
No potential competing interest was reported by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
In this section, we report the specifications of the hyperparameters of the neural networks used to build the \(\text {ROM}\)s in the first and second test cases (Tables 6 and 7).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ivagnes, A., Demo, N. & Rozza, G. Towards a Machine Learning Pipeline in Reduced Order Modelling for Inverse Problems: Neural Networks for Boundary Parametrization, Dimensionality Reduction and Solution Manifold Approximation. J Sci Comput 95, 23 (2023). https://doi.org/10.1007/s10915-023-02142-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-023-02142-4