
Abstract
We study the problem of minimizing a convex function on a nonempty, finite subset of the integer lattice when the function cannot be evaluated at noninteger points. We propose a new underestimator that does not require access to (sub)gradients of the objective; such information is unavailable when the objective is a blackbox function. Rather, our underestimator uses secant linear functions that interpolate the objective function at previously evaluated points. These linear mappings are shown to underestimate the objective in disconnected portions of the domain. Therefore, the union of these conditional cuts provides a nonconvex underestimator of the objective. We propose an algorithm that alternates between updating the underestimator and evaluating the objective function. We prove that the algorithm converges to a global minimum of the objective function on the feasible set. We present two approaches for representing the underestimator and compare their computational effectiveness. We also compare implementations of our algorithm with existing methods for minimizing functions on a subset of the integer lattice. We discuss the difficulty of this problem class and provide insights into why a computational proof of optimality is challenging even for moderate problem sizes.









Similar content being viewed by others

Notes
Although [27] considers integer convexity only for polynomials, this definition can be applied to more general classes of functions over the sets considered here.
References
Abhishek, K., Leyffer, S., Linderoth, J.T.: Modeling without categorical variables: a mixed-integer nonlinear program for the optimization of thermal insulation systems. Optim. Eng. 11(2), 185–212 (2010). https://doi.org/10.1007/s11081-010-9109-z
Abramson, M., Audet, C., Chrissis, J., Walston, J.: Mesh adaptive direct search algorithms for mixed variable optimization. Optim. Lett. 3(1), 35–47 (2009). https://doi.org/10.1007/s11590-008-0089-2
Audet, C., Dennis Jr., J.E.: Pattern search algorithms for mixed variable programming. SIAM J. Optim. 11(3), 573–594 (2000). https://doi.org/10.1137/S1052623499352024
Audet, C., Hare, W.L.: Derivative-Free and Blackbox Optimization. Springer, Berlin (2017). https://doi.org/10.1007/978-3-319-68913-5
Audet, C., Le Digabel, S., Tribes, C.: The mesh adaptive direct search algorithm for granular and discrete variables. SIAM J. Optim. 29(2), 1164–1189 (2019). https://doi.org/10.1137/18m1175872
Balaprakash, P., Tiwari, A., Wildand, S.M.: Multi-objective optimization of HPC kernels for performance, power, and energy. In: Jarvis, S.A., Wright, S.A., Hammond, S.D. (eds.) High Performance Computing Systems Performance Modeling, Benchmarking and Simulation, vol. 851, pp. 239–260. Springer, Berlin (2014). https://doi.org/10.1007/978-3-319-10214-6_12
Bartz-Beielstein, T., Zaefferer, M.: Model-based methods for continuous and discrete global optimization. Appl. Soft Comput. 55, 154–167 (2017). https://doi.org/10.1016/j.asoc.2017.01.039
Bonami, P., Biegler, L., Conn, A., Cornuéjols, G., Grossmann, I., Laird, C., Lee, J., Lodi, A., Margot, F., Sawaya, N., Wächter, A.: An algorithmic framework for convex mixed integer nonlinear programs. Discrete Optim. 5(2), 186–204 (2008). https://doi.org/10.1016/j.disopt.2006.10.011
Borwein, J.M., Bailey, D.H., Girgensohn, R., Bailey, D.H., Borwein, J.M.: Experimentation in Mathematics: Computational Paths to Discovery. CRC Press, Boca Raton (2004). https://doi.org/10.1201/9781439864197
Borwein, J.M., Vanderwerff, J.D.: Convex Functions: Constructions Characterizations and Counterexamples. Cambridge University Press, Cambridge (2010). https://doi.org/10.1017/cbo9781139087322
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004). https://doi.org/10.1017/cbo9780511804441
Buchheim, C., Kuhlmann, R., Meyer, C.: Combinatorial optimal control of semilinear elliptic PDEs. Comput. Optim. Appl. 70(3), 641–675 (2018). https://doi.org/10.1007/s10589-018-9993-2
Charalambous, C., Bandler, J.W.: Non-linear minimax optimization as a sequence of least \(p\)th optimization with finite values of \(p\). Int. J. Syst. Sci. 7(4), 377–391 (1976). https://doi.org/10.1080/00207727608941924
Charalambous, C., Conn, A.R.: An efficient method to solve the minimax problem directly. SIAM J. Numer. Anal. 15(1), 162–187 (1978). https://doi.org/10.1137/0715011
Conn, A.R., Scheinberg, K., Vicente, L.N.: Introduction to Derivative-Free Optimization. SIAM, Philadelphia (2009). https://doi.org/10.1137/1.9780898718768
Costa, A., Nannicini, G.: RBFOpt: an open-source library for black-box optimization with costly function evaluations. Math. Program. Comput. 10(4), 597–629 (2018). https://doi.org/10.1007/s12532-018-0144-7
Davis, E., Ierapetritou, M.: A kriging based method for the solution of mixed-integer nonlinear programs containing black-box functions. J. Glob. Optim. 43(2–3), 191–205 (2009). https://doi.org/10.1007/s10898-007-9217-2
Dennis Jr., J.E., Woods, D.J.: Optimization on microcomputers: the Nelder–Mead simplex algorithm. In: Wouk, A. (ed.) New Computing Environments: Microcomputers in Large-Scale Computing, pp. 116–122. SIAM, Philadelphia (1987)
Dolan, E.D., Moré, J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002). https://doi.org/10.1007/s101070100263
Duran, M.A., Grossmann, I.E.: An outer-approximation algorithm for a class of mixed-integer nonlinear programs. Math. Program. 36(3), 307–339 (1986). https://doi.org/10.1007/bf02592064
Fletcher, R., Leyffer, S.: Solving mixed integer nonlinear programs by outer approximation. Math. Program. 66(1–3), 327–349 (1994). https://doi.org/10.1007/bf01581153
García-Palomares, U.M., Rodríguez-Hernández, P.S.: Unified approach for solving box-constrained models with continuous or discrete variables by non monotone direct search methods. Optim. Lett. 13(1), 95–111 (2019). https://doi.org/10.1007/s11590-018-1253-y
Geoffrion, A.M., Marsten, R.E.: Integer programming algorithms: a framework and state-of-the-art survey. Manag. Sci. 18(9), 465–491 (1972). https://doi.org/10.1287/mnsc.18.9.465
Graf, P.A., Billups, S.: MDTri: robust and efficient global mixed integer search of spaces of multiple ternary alloys. Comput. Optim. Appl. 68(3), 671–687 (2017). https://doi.org/10.1007/s10589-017-9922-9
Haarala, M., Miettinen, K., Mäkelä, M.M.: New limited memory bundle method for large-scale nonsmooth optimization. Optim. Methods Softw. 19(6), 673–692 (2004). https://doi.org/10.1080/10556780410001689225
Hemker, T., Fowler, K., Farthing, M., von Stryk, O.: A mixed-integer simulation-based optimization approach with surrogate functions in water resources management. Optim. Eng. 9(4), 341–360 (2008). https://doi.org/10.1007/s11081-008-9048-0
Hemmecke, R., Köppe, M., Lee, J., Weismantel, R.: Nonlinear integer programming. In: 50 Years of Integer Programming 1958–2008. Springer, pp. 561–618, pp. 561–618 (2010). https://doi.org/10.1007/978-3-540-68279-0_15
Holmström, K., Quttineh, N.H., Edvall, M.: An adaptive radial basis algorithm (ARBF) for expensive black-box mixed-integer constrained global optimization. Optim. Eng. 9(4), 311–339 (2008). https://doi.org/10.1007/s11081-008-9037-3
Jian, N., Henderson, S.G.: Estimating the probability that a function observed with noise is convex. INFORMS J. Comput. (2019). https://doi.org/10.1287/ijoc.2018.0847
Jian, N., Henderson, S.G., Hunter, S.R.: Sequential detection of convexity from noisy function evaluations. In: Proceedings of the Winter Simulation Conference. IEEE (2014). https://doi.org/10.1109/wsc.2014.7020215
Kiwiel, K.C.: An ellipsoid trust region bundle method for nonsmooth convex minimization. SIAM J. Control Optim. 27(4), 737–757 (1989). https://doi.org/10.1137/0327039
Kolda, T.G., Lewis, R.M., Torczon, V.J.: Optimization by direct search: new perspectives on some classical and modern methods. SIAM Rev. 45(3), 385–482 (2003). https://doi.org/10.1137/S003614450242889
Larson, J., Menickelly, M., Wild, S.M.: Derivative-free optimization methods. Acta Numer. 28, 287–404 (2019). https://doi.org/10.1017/s0962492919000060
Le Digabel, S.: Algorithm 909: NOMAD: nonlinear optimization with the MADS algorithm. ACM Trans. Math. Softw. 37(4), 1–15 (2011). https://doi.org/10.1145/1916461.1916468
Le Digabel, S., Wild, S.M.: A taxonomy of constraints in black-box simulation-based optimization. Preprint ANL/MCS-P5350-0515, Argonne (2015-01). http://www.mcs.anl.gov/papers/P5350-0515.pdf
Liuzzi, G., Lucidi, S., Rinaldi, F.: Derivative-free methods for bound constrained mixed-integer optimization. Comput. Optim. Appl. 53(2), 505–526 (2011). https://doi.org/10.1007/s10589-011-9405-3
Liuzzi, G., Lucidi, S., Rinaldi, F.: Derivative-free methods for mixed-integer constrained optimization problems. J. Optim. Theory Appl. 164(3), 933–965 (2015). https://doi.org/10.1007/s10957-014-0617-4
Liuzzi, G., Lucidi, S., Rinaldi, F.: An algorithmic framework based on primitive directions and nonmonotone line searches for black-box optimization problems with integer variables. Math. Program. Comput. 12(4), 673–702 (2020). https://doi.org/10.1007/s12532-020-00182-7
Moré, J.J., Wild, S.M.: Benchmarking derivative-free optimization algorithms. SIAM J. Optim. 20(1), 172–191 (2009). https://doi.org/10.1137/080724083
Müller, J.: MATSuMoTo: the MATLAB surrogate model toolbox for computationally expensive black-box global optimization problems. Technial Report 1404.4261, arXiv (2014). https://arxiv.org/abs/1404.4261
Müller, J.: MISO: mixed-integer surrogate optimization framework. Opim. Eng. 17(1), 177–203 (2016). https://doi.org/10.1007/s11081-015-9281-2
Müller, J., Shoemaker, C.A., Piché, R.: SO-I: a surrogate model algorithm for expensive nonlinear integer programming problems including global optimization applications. J. Glob. Optim. 59(4), 865–889 (2013). https://doi.org/10.1007/s10898-013-0101-y
Müller, J., Shoemaker, C.A., Piché, R.: SO-MI: a surrogate model algorithm for computationally expensive nonlinear mixed-integer black-box global optimization problems. Comput. Oper. Res. 40(5), 1383–1400 (2013). https://doi.org/10.1016/j.cor.2012.08.022
Newby, E., Ali, M.M.: A trust-region-based derivative free algorithm for mixed integer programming. Comput. Optim. Appl. 60(1), 199–229 (2015). https://doi.org/10.1007/s10589-014-9660-1
Porcelli, M., Toint, P.L.: BFO, a trainable derivative-free brute force optimizer for nonlinear bound-constrained optimization and equilibrium computations with continuous and discrete variables. ACM Trans. Math. Softw. 44(1), 1–25 (2017). https://doi.org/10.1145/3085592
Rashid, K., Ambani, S., Cetinkaya, E.: An adaptive multiquadric radial basis function method for expensive black-box mixed-integer nonlinear constrained optimization. Eng. Optim. 45(2), 185–206 (2012). https://doi.org/10.1080/0305215X.2012.665450
Richter, P., Ábrahám, E., Morin, G.: Optimisation of concentrating solar thermal power plants with neural networks. In: Dobnikar, A., Lotrič, U., Šter, B. (eds.) Adaptive and Natural Computing Algorithms, vol. 6593, pp. 190–199. Springer, Berlin (2011)
Acknowledgements
We are grateful to Eric Ni for his insights on derivative-free algorithms for unrelaxable integer variables. Sven Leyffer also wishes to acknowledge the insightful discussions on an early draft of this work during the Dagstuhl seminar 18081. We are grateful for the comments from two anonymous reviewers that greatly improved an early version of this manuscript. This material is based upon work supported by the applied mathematics and SciDAC activities of the Office of Advanced Scientific Computing Research, Office of Science, U.S. Department of Energy, under Contract DE-AC02-06CH11357.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Proofs of Lemmas
1.1 A.1 Proof of Lemma 4
Proof
For contradiction, suppose that the set \(\{x^0\} \cup X \setminus \{x^{n+1}\}\) is not poised and therefore is affinely dependent. Then, there must exist scalars \(\beta _j\) not all zero, and (without loss of generality) \(x^n \in X\) such that
Replacing \(x^0\) with (9) in the left-hand side above yields
Since X is poised, the vectors \(\{ x^1,\ldots , x^{n+1}\}\) are affinely independent; by definition of affine independence, the only solution to \(\sum _{j=1}^{n+1} \gamma _j x^j = 0\) and \(\sum _{j=1}^{n+1} \gamma _j = 0\) is \(\gamma _j = 0\) for \(j = 1,\ldots ,n+1\). The sum of the coefficients from (22) satisfies
because \(\sum _{j=1}^{n+1}\alpha _j = 1\). This means that all coefficients of \(x^j\) in (22) are also equal to zero. Since \(\alpha _{n+1}>0\), the last term from (22) implies that \(\beta _0 = 0\). Considering the remaining coefficients in (22), we conclude that \(\beta _0 \alpha _j + \beta _j=0\), which implies that \(\beta _j = 0\) for \(j=1,\ldots , n-1\). This contradicts the assumption that not all \(\beta _j = 0\). Hence, the result is proved. \(\square \)
1.2 A.2 Proof of Lemma 5
Proof
Since \(x^0 \in \mathrm {int}\left( \mathrm {conv}\left( X\right) \right) \), there exist \(\alpha _j > 0\) such that
where the second equality follows from (9). The existence of \(\alpha _j>0\) such that \(\sum _{j=1}^{n+1}\alpha _j (x^0-x^j) = 0\) implies that the vectors \(\left\{ x^0-x^j: j \in \{ 1,\ldots ,n+1\}\right\} \) are a positive spanning set (see, e.g., [15, Theorem 2.3 (iii)]). Therefore any \(x \in {\mathbb {R}}^n\) can be expressed as
with \(\alpha _j \ge 0\) for all j.
We will show that any \(x \in {\mathbb {R}}^n\) belongs to \({\mathcal {U}}^{{{\varvec{i}}}}\) for some multi-index \({{\varvec{i}}}\) containing \(x^0\). By Lemma 4, every set of n distinct vectors of the form \((x^0 - x^j)\) for \(x^j \in X\) is a linearly independent set. Thus we can express
for some \(l \in \{1, \ldots n+1 \}\). If \(\lambda _j \ge 0\) for each j, then we are done, and \(x \in \mathrm {cone}\big (x^0 - X \setminus \{x^l\}\big )\).
Otherwise, choose an index \(j'\) such that \(\lambda _{j'}\) is the most negative coefficient on the right of (24) (breaking ties arbitrarily). Using (23), we can exchange the indices l and \(j'\) in (24) by observing that
Note that \(\frac{-\lambda _{j'}}{\alpha _{j'}}\alpha _j>0\) by (9), and we can rewrite (24) as
with new coefficients \(\mu _j\) that are strictly larger than \(\lambda _j\):
Observe that (25) has the same form as (24) but with coefficients \(\mu _j\) that are strictly greater than \(\lambda _j\). We can now define \(\lambda =\mu \) and repeat the process. If there is some \(\lambda _{j'}<0\), the process will strictly increase all \(\lambda _j\). Because there are only a finite number of subsets of size n, we must eventually have all \(\lambda _j \ge 0\). Once \(\lambda _{j'}\) has been pivoted out, it can reenter only with a positive value (like \(\mu _l\) above), so eventually all \(\lambda _j\) will be nonnegative. \(\square \)
1.3 A.3 Proof of Lemma 6
Proof
Let \({{\varvec{i}}}\) be given and \(i_j \in {{\varvec{i}}}\) fixed. We first show that \(\mathrm {cone}\big (x^{i_j} - X^{{{\varvec{i}}}}\big ) \subseteq F^{i_j}\) by showing that an arbitrary \(x \in \mathrm {cone}\big (x^{i_j} - X^{{{\varvec{i}}}}\big )\) satisfies (20) for each \(i_l \in {{\varvec{i}}}, i_l \ne i_j\). Given \((c^{i_l},b^{i_l})\) satisfying (18) and (19), then using the definition (5) yields
where we have used (18) in the last three equations. The final inequality holds because \(\lambda _l \ge 0\) by (5) and \((c^{i_l})^{{\text {T}}}x^{i_l} + b^{i_l} > 0\) by (19). Because \(i_l\) is arbitrary, it follows that any x in \(\mathrm {cone}\big (x^{i_j} - X\big )\) is also in \(F^{i_j}\).
We now show that \(F^{i_j} \subseteq \mathrm {cone}\big (x^{j} - X^{{{\varvec{i}}}}\big )\) by contradiction. If \(x \notin \mathrm {cone}\big (x^{i_j} - X^{{{\varvec{i}}}}\big )\) for a set of \(n+1\) poised points \(X^{{{\varvec{i}}}}\), then x can be represented as \(x^{i_j} +\displaystyle \sum \nolimits _{l=1, l\ne j}^{n+1} \lambda _l \left( x^{i_j} - x^{i_l} \right) \) only with some \(\lambda _{l} < 0\). Thus, (20) is violated for some l, and hence \(x \notin F^{i_j}\). \(\square \)
B Test problems
C Performance of MILP model

Characteristics of the first 12 instances of (CPF) generated by Algorithm 1 minimizing the convex quadratic abhi on \(\varOmega =[-2,2]^3 \cap {\mathbb {Z}}^3\). Left shows the lower bound and solution time (mean of five replications and maximum and minimum times are also shown); right shows the number of binary and continuous variables and constraints. For further details of these 12 MILP models, see Table 4
Table 4 shows the size of the MILP model at each iteration and the computational effort required for solving it. The column k refers to the iteration of Algorithm 1, sHyp denotes the number of secants (i.e., \(\left| W(X) \right| \)), and LB and UB give the lower and upper bound on f on \(\varOmega \), respectively. We show the computational effort needed to solve each MILP via time, the mean solution time (in seconds) for 5 replications; simIter, the number of simplex iterations; and nodes, the number of branch-and-bound nodes explored by the MILP solver. The size of each MILP (after presolve) is shown in terms of bVars, the number of binary variables; cVars, the number of continuous variables; and cons, the number of constraints. Table 4 also shows the optimal solution \({\hat{x}}\) of each MILP. These experiments were performed by using CPLEX (v.12.6.1.0) on a 2.20 GHz, 12-core Intel Xeon computer with 64 GB of RAM. For this small problem we see that the size of the MILP grows exponentially as the iterations proceed, which results in an exponential growth in solution time as illustrated in Fig. 10. The iteration 13 MILP was not solved after 30 minutes.
D Detailed numerical results
Tables 5, 6 contain detailed numerical results for the interested reader. Note that some solvers do not respect the given budget of function evaluations. We have used a different stopping criterion for MATSuMoTo: it is set to stop only when a point with the optimal value has been identified. Also, although the global minimum is the starting point for entropy, infnorm, onenorm, maxq and mxhilb, MATSuMoTo instead uses its initial symmetric Latin hypercube design. The last row of Table 1 in Sect. 2 shows \(\left| \varOmega \right| \) for these problems (Fig. 11).
E Derivation of tolerances
In this section, we show how one can compute sufficient values of \(M_{\eta }\), \(\epsilon _{\lambda }\), and \(M_{\lambda }\) for the MILP model (CPF). We first show that if we choose these parameters incorrectly, then the resulting MILP model no longer provides a valid lower bound.
Effect of an Insufficient \(\epsilon _\lambda \) Value. A large \(\epsilon _\lambda \) or small \(M_\lambda \) (or both) could result in an incorrect value of \(z^{i_j}=1\) for a point \(x \notin \mathrm {cone}\big (x^{i_j}-X^{{{\varvec{i}}}}\big )\), violating the implication of \(z^{i_j}=1\) and yielding an invalid lower bound on f. This is illustrated using a one-dimensional example in Fig. 12. Similarly, one can encounter an invalid lower bound at an iteration if \(M_\lambda \) is chosen to be smaller than required.

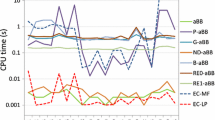
Number of evaluations for 8 test functions on \(\left[ -4,4 \right] ^5 \cap {\mathbb {Z}}^n\) before SUCIL first identifies a global minimum and evaluations required to prove its global optimality. The fewest number of evaluations required by any of DFLINT, DFLINT-M, NOMAD, NOMAD-dm, and MATSuMoTo is shown for comparison

An example of false termination of Algorithm 1 using (CPF) when an insufficient value of \(\epsilon _\lambda \) is used: \(f(x)=x^2\) and interpolation points \(-1\) and 1 are used to form the secant shown in red colour. Any value of \(\epsilon _\lambda > 0.5\) forces \(z^{{1}_1}=z^{{1}_2}=1\), activating the cut \(\eta \ge 1\) at the optimal \(x^*=0\), resulting in \(l_f^k=u_f^k=1\)
Bound on \(M_{\eta }\) Let \(l_f\) be a valid lower bound of f on \(\varOmega \). With this lower bound, scalars \(M_{{{\varvec{i}}}}\) can be defined as
If \(\varOmega = \left\{ x: l_x \le x \le u_x \right\} \), where \(l_x, u_x \in {\mathbb {R}}^n\) are known, then we can set
Then, we can either set individual values of \(M_{{{\varvec{i}}}}\) within each constraint (10), which would yield a tighter model, or use a single parameter,
as shown in (CPF).
Bounds on \(\epsilon _\lambda \) and \(M_\lambda \) Sufficient values of \(M_\lambda \) and \(\epsilon _\lambda \) are not easy to calculate as they depend on the rays generated at \(x^{i_j}\), and the domain \(\varOmega \). We show next, that bounds on these values can be computed by solving a set of optimization problems. A sufficient value for \(\epsilon _\lambda \) can be computed based on the representations of the \(n+1\) hyperplanes formed using different combinations of n points, \(\forall {{\varvec{i}}}\in W(X)\). We can use one of the representations of the hyperplane passing through points \(X^{i}\setminus \{x^{i_j}\}, j=1\ldots n+1\) to obtain bounds on \(\epsilon _\lambda \), by solving an optimization problem for each \(i_j \in {{\varvec{i}}}\). Let \(c^{{{\varvec{i}}}_{i_j-}}\) and \(b^{{{\varvec{i}}}_{i_j-}}\) denote the solution of the following problem.

Problem (P\(-hyp\)) can be easily cast as an integer program by replacing \(\left\| c \right\| _1\) by \(e^Ty\), where \(e=(1,\ldots ,1)^T\) is the vector or all ones, and the variables y satisfy the constraints \(y \ge c, y \ge - c\). Because, the hyperplane is generated using n integer points, it can be shown that there exists a solution \(c^{{{\varvec{i}}}_{i_j-}}\) and \(b^{{{\varvec{i}}}_{i_j-}}\) that is nonzero and integral, as stated in the following proposition.
Proposition 1
Consider a hyperplane \(S=\{x:c^{T} x + b = 0\}\) such that c and b are integral. The Euclidean distance between an arbitrary point \({\hat{x}} \in {\mathbb {Z}}^n \setminus S\), and S, is greater than or equal to \(\frac{1}{||c ||_2}\).
Proof
The Euclidean distance between a point \({\hat{x}}\) and S is the 2-norm of the projection of the line segment joining an arbitrary point \(w \in S\) and \({\hat{x}}\), on the normal passing through \({\hat{x}}\), and can be expressed as
By integrality of c, b and \({\hat{x}}\), and since \({\hat{x}} \notin S\), \(|c^{T} {\hat{x}} + b |\ge 1\), and the result follows. \(\square \)
Proposition 1 can be used directly to get a sufficient value of \(\epsilon _\lambda \) as follows.
The bound can be tightened using the following optimization problem.

If we denote by \(\epsilon ^{{{\varvec{i}}}_{i_j-}}_\lambda \), the optimal value of (P-\(\epsilon \)), then the following is a sufficient value of \(\epsilon _\lambda \).
Similarly, if we maximize the objective in (P-\(\epsilon \)), and denote the optimal value by \(M^{{{\varvec{i}}}_{i_j-}}_\lambda \) we get a sufficient value for \(M_\lambda \) as follows.
No-Good Cuts and Stronger Objective Bounds. For our initial experiments, we tried setting arbitrarily small values for \(\epsilon _{\lambda }\) instead of obtaining the best possible values by solving a set of optimization problems as elaborated above. The problem with having such values of \(\epsilon _{\lambda }>0\) too small is that it allows us to ignore the cuts at the interpolation points, \(x^{(k)}\), causing a violation of the bound, \(\eta \ge f^{(k)}\), for \(x=x^{(k)}\) in the MILP, resulting in repetition of iterates in the algorithm. We fixed this by adding the following valid inequality to the MILP.
We can write this inequality as a linear constraint, by introducing a binary representation of the variables, x, requiring nU binary variables, \(\xi _{ij}, \; i=1,\ldots ,n, \; j=1,\ldots ,U\), where n is the dimension of our problem, and \(0 \le x \le U\). With this representation, we obtain
and write the \(\eta \)-constraint equivalently as
Rights and permissions
About this article

Cite this article
Larson, J., Leyffer, S., Palkar, P. et al. A method for convex black-box integer global optimization. J Glob Optim 80, 439–477 (2021). https://doi.org/10.1007/s10898-020-00978-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-020-00978-w