
Abstract
In this paper, we study a class of nonconvex nonsmooth optimization problems with bilinear constraints, which have wide applications in machine learning and signal processing. We propose an algorithm based on the alternating direction method of multipliers, and rigorously analyze its convergence properties (to the set of stationary solutions). To test the performance of the proposed method, we specialize it to the nonnegative matrix factorization problem and certain sparse principal component analysis problem. Extensive experiments on real and synthetic data sets have demonstrated the effectiveness and broad applicability of the proposed methods.



Similar content being viewed by others


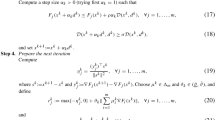
Notes
MULT is coded by the authors of this paper.
Code is available at https://sites.google.com/a/umn.edu/huang663/publications.
Code is available at http://smallk.github.io/
Code is available at http://www.math.ucla.edu/%7Ewotaoyin/papers/bcu/matlab.html.
References
Ames, B., Hong, M.: Alternating directions method of multipliers for l1-penalized zero variance discriminant analysis and principal component analysis (2014). arXiv:1401.5492v2
Bertsekas, D.P.: Nonlinear Programming, 2nd edn. Athena Scientific, Belmont (1999)
Bolte, J., Sabach, S., Teboulle, M.: Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 146(1), 459–494 (2014)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3 (2011)
Brunet, J.P., Tamayo, P., Golub, T.R., Mesirov, J.P.: Metagenes and molecular pattern discovery using matrix factorization. Proc. Natl. Acad. Sci. 101(12), 4164–4169 (2004)
d’Aspremont, A., Bach, F., Ghaoui, L.: Optimal solutions for sparse principal component analysis. J. Mach. Learn. Res. 9, 1269–1294 (2008)
d’Aspremont, A., Ghaoui, L.E., Jordan, M., Lanckriet, G.: A direct formulation for sparse pca using semidefinite programming. SIAM Rev. 49, 434–V448 (2007)
Eckstein, J.: Splitting methods for monotone operators with applications to parallel optimization (1989). Ph.D Thesis, Operations Research Center, MIT
Eckstein, J., Yao, W.: Augmented lagrangian and alternating direction methods for convex optimization: a tutorial and some illustrative computational results. RUTCOR Research Reports 32 (2012)
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 2, 17–40 (1976)
Giannakis, G.B., Ling, Q., Mateos, G., Schizas, I.D., Zhu, H.: Decentralized learning for wireless communications and networking. arXiv preprint arXiv:1503.08855 (2015)
Gillis, N.: The why and how of nonnegative matrix factorization (2015). Book Chapter available at arXiv:1401.5226v2
Glowinski, R., Marroco, A.: Sur l’approximation, par elements finis d’ordre un, et la resolution, par penalisation-dualite, d’une classe de problemes de dirichlet non lineares. Revue Franqaise d’Automatique, Informatique et Recherche Opirationelle 9, 41–76 (1975)
Hajinezhad, D., Chang, T.H., Wang, X., Shi, Q., Hong, M.: Nonnegative matrix factorization using admm: algorithm and convergence analysis. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2016)
Hajinezhad, D., Hong, M.: Nonconvex alternating direction method of multipliers for distributed sparse principal component analysis. In: 2015 IEEE International Conference on GlobalSIp 2015 (2015)
Hajinezhad, D., Hong, M., Zhao, T., Wang, Z.: Nestt: a nonconvex primal-dual splitting method for distributed and stochastic optimization. Adv. Neural Inf. Process. Syst. 29, 3207–3215 (2016)
Hestenes, M.R.: Multiplier and gradient methods. J. Optim. Appl. 4, 303–320 (1969)
Hong, M., Chang, T.H., Wang, X., Razaviyayn, M., Ma, S., Luo, Z.Q.: A block successive upper bound minimization method of multipliers for linearly constrained convex optimization (2013). Preprint, available online arXiv:1401.7079
Hong, M., Hajinezhad, D., Zhao, M.M.: Prox-PDA: The proximal primal-dual algorithm for fast distributed nonconvex optimization and learning over networks. In: Precup, D., Teh, Y.W. (eds) Proceedings of the 34th International Conference on Machine Learning, Proceedings of Machine Learning Research, vol. 70, pp. 1529–1538. PMLR, International Convention Centre, Sydney, Australia (2017)
Hong, M., Luo, Z.Q., Razaviyayn, M.: Convergence analysis of alternating direction method of multipliers for a family of nonconvex problems pp. 1410–1390 (2014). arXiv:1410.1390v1
Huang, K., Sidiropoulos, N., Liavas, A.P.: A flexible and efficient algorithmic framework for constrained matrix and tensor factorization. arXiv preprint arXiv:1506.04209 (2015)
Jeffers, J.: Two case studies in the application of principal component analysis. Appl. Stat. 16, 225–236 (1967)
Jiang, B., Lin, T., Ma, S., Zhang, S.: Structured nonconvex and nonsmooth optimization: algorithms and iteration complexity analysis. arXiv preprint arXiv:1605.02408 (2016)
Jolliffe, I.: Principal Component Analysis. Springer, New York (2002)
Jolliffe, I., Trendalov, N., Uddin, M.: A modifed principal component technique based on the lasso. J. Comput. Graph. Stat. 12, 531–V547 (2003)
Journee, M., Nesterov, Y., Richtarik, P., Sepulchre, R.: Generalized power method for sparse principal component analysis. J. Mach. Learn. Res. 11, 517–553 (2010)
Kim, H., Park, H.: Sparse non-negative matrix factorizations via alternating non-negativity-constrained least squares for microarray data analysis. Bioinformatics 23(12), 1495–1502 (2007)
Kim, J., Park, H.: Fast nonnegative matrix factorization: an active-set-like method and comparisons. SIAM J. Sci. Comput. 33(6), 3261–3281 (2011)
Laboratories, A.: Cambridge orl database of faces. http://www.uk.research.att.com/facedatabase.html
Lee, D., Seung, H.S.: Algorithms for non-negative matrix factorization. In: Advances in Neural Information Processing Systems 13, pp. 556–562. MIT Press (2001)
Li, G., Pong, T.K.: Global convergence of splitting methods for nonconvex composite optimization. SIAM J. Optim. 25(4), 2434–2460 (2015)
Lin, C.H.: Projected gradient methods for nonnegative matrix factorization. Neural Comput. 19(10), 2756–2779 (2007)
Luo, Z.Q., Tseng, P.: On the convergence of the coordinate descent method for convex differentiable minimization. J. Optim. Theory Appl. 72(1), 7–35 (1992)
Mackey, L.: Deflation methods for sparse pca. Adv. Neural Inf. Process. 21, 1017–1024 (2008)
Mordukhovich, B.S.: Variational Analysis and Generalized Differentiation, I: Basic Theory, II: Applications. Springer, Berlin (2006)
Mordukhovich, B.S., Nam, N.M., Yen, N.D.: Frchet subdifferential calculus and optimality conditions in nondifferentiable programming (2005). Mathematics Research Reports. Paper 29
Pauca, V.P., Shahnaz, F., Berry, M.W., Plemmons, R.J.: Text Mining using Non-Negative Matrix Factorizations, chap. 45, pp. 452–456
Rahmani, M., Atia, G.: High dimensional low rank plus sparse matrix decomposition. arXiv preprint arXiv:1502.00182 (2015)
Razaviyayn, M., Hong, M., Luo, Z.Q.: A unified convergence analysis of block successive minimization methods for nonsmooth optimization. SIAM J. Optim. 23(2), 1126–1153 (2013)
Richtarik, P., Takac, M., Ahipasaoglu, S.D.: Alternating maximization: unifying framework for 8 sparse pca formulations and efficient parallel codes (2012). arXiv:1212.4137
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Springer, Berlin (1998)
Sani, A., Vosoughi, A.: Distributed vector estimation for power-and bandwidth-constrained wireless sensor networks. IEEE Trans. Signal Process. 64(15), 3879–3894 (2016)
Schizas, I., Ribeiro, A., Giannakis, G.: Consensus in ad hoc wsns with noisy links—part I: distributed estimation of deterministic signals. IEEE Trans. Signal Process. 56(1), 350–364 (2008)
Shen, H., Huang, J.: Sparse principal component analysis via regularized low rank matrix approximation. J. Multivar. Anal. 99, 1015–1034 (2008)
Song, D., Meyer, D.A., Min, M.R.: Fast nonnegative matrix factorization with rank-one admm. NIPS 2014 Workshop on Optimization for Machine Learning (OPT2014) (2014)
Sun, D.L., Fevotte, C.: Alternating direction method of multipliers for non-negative matrix factorization with the beta-divergence. In: The Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) (2014)
Tseng, P.: Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 103(9), 475–494 (2001)
Turkmen, A.C.: A review of nonnegative matrix factorization methods for clustering (2015). Preprint, available at arXiv:1507.03194v2
Wang, F., Xu, Z., Xu, H.K.: Convergence of bregman alternating direction method with multipliers for nonconvex composite problems. arXiv preprint arXiv:1410.8625 (2014)
Wang, Y., Yin, W., Zeng, J.: Global convergence of admm in nonconvex nonsmooth optimization. arXiv preprint arXiv:1511.06324 (2015)
Wen, Z., Yang, C., Liu, X., Marchesini, S.: Alternating direction methods for classical and ptychographic phase retrieval. Inverse Prob. 28(11), 1–18 (2012)
Xu, Y., Yin, W., Wen, Z., Zhang, Y.: An alternating direction algorithm for matrix completion with nonnegative factors. J. Front. Math. China pp. 365–384 (2011)
Zdunek, R.: Alternating direction method for approximating smooth feature vectors in nonnegative matrix factorization. In: Machine Learning for Signal Processing (MLSP), 2014 IEEE International Workshop on, pp. 1–6 (2014)
Zhang, R., Kwok, J.T.: Asynchronous distributed admm for consensus optimization. In: Proceedings of the 31st International Conference on Machine Learning (2014)
Zhang, Y.: An alternating direction algorithm for nonnegative matrix factorization (2010). Preprint
Zhao, Q., Meng, D., Xu, Z., Gao, C.: A block coordinate descent approach for sparse principal component analysis. J. Neurocomput. 153, 180–190 (2015)
Zlobec, S.: On the liu-floudas convexification of smooth programs. J. Glob. Optim. 32(3), 401–407 (2005)
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc.: Ser. B (Statistical Methodology) 67, 301–320 (2005)
Zou, H., Hastie, T., Tibshirani, R.: Sparse principal component analysis. J. Comput. Graph. Stat. 15, 265–286 (2006)
Acknowledgements
We would like to thank Dr. Mingyi Hong for sharing his pearls of wisdom with us during this research, and we would also thank anonymous reviewers for their careful and insightful reviews.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Proof of Lemma 1
Since \(\left( X, Z\right) ^{r+1}\) is optimal solution of (22b), it should satisfy the optimality condition which is given by:
If we combine Eq. (38) with dual update variable (22c), we have:
Applying the Eq. (23), eventually we have
The lemma is proved. Q.E.D.
1.2 Proof of Lemma 2
Part 1 First let us prove that \(r_1(X^{r+1})\le u_1(X^{r+1},X^r)\) which are given in (18) and (19), and similarly we can show that \(r_2(Y^{r+1})\le u_2(Y^{r+1},Y^r)\). When \(r_1\) is convex we have \(u_1(X,X^r)=r_1(X)\), so if we set \(X=X^{r+1}\) we get \(u_1(X^{r+1},X^r)=r_1(X^{r+1})\ge r_1(X^{r+1})\). In the second case when \(r_1\) is concave, we have
For simplicity, let us do the change of variable \(Z:=l_1(X)\), therefore we have \(r_1(X)=h_1(l_1(X))=h_1(Z).\) Based on the critical property of a concave function (i.e. linear approximation is global upper-estimation for the function) we have for every \(Z,\hat{Z}\in \text{ dom }\,(h_1)\)
If we plug back in \(Z:=l_1(X)\), and \(\hat{Z}:=l_1(\hat{X})\) in the above equation, we have
Now if we set \(X=X^{r+1}\), and \(\hat{X}=X^r\), we reach
which is equivalent to \(r_1(X^{r+1})\le u_1(X^{r+1},X^r).\)
Next, for simplicity let us define \(W^r:=(Y^{r}, (X, Z)^{r}; {\varLambda }^{r})\). Then, the successive difference of augmented Lagrangian can be written as the following by adding and subtracting the term \(L_\rho [Y^{r+1}, (X, Z)^{r+1}; {\varLambda }^{r}]\)
First we bound \(L_\rho [W^{r+1}]-L_\rho [Y^{r+1}, (X, Z)^{r+1}; {\varLambda }^{r}]\). Using Lemma 1 we have
Next let us bound \(L_\rho [Y^{r+1}, (X, Z)^{r+1}; {\varLambda }^{r}]-L_\rho [W^{r}]\).
Suppose that \(\xi _X\in \partial _X H[(X,Z)^{r+1}; X^r, Y^{r+1}, {\varLambda }^r]\) is a subgradient of function \(H[(X,Z); X^r, Y^{r+1}, {\varLambda }^r]\) at the point \(X^{r+1}\). Then we have
where \(\mathrm{(i)}\) is true because from Eqs. (18) and (19) we conclude that \(r_1(X^{r+1})\le u_1(X^{r+1},X^{r})\), \(\mathrm (ii)\) comes from the strong convexity of \(H[(X,Z); X^r, Y^{r+1}, {\varLambda }^r]\) with respect to X and Z with modulus \(\gamma _x\) and \(\gamma _z\) respectively, and we have \(\mathrm{(iii)}\) due to the optimality condition for the problem (22b), which given by
thus, the first term in the second inequality disappears because we implicitly set \(\xi _X=0\).
Next suppose \(\xi _Y\in \partial _Y G[Y^{r+1}; (X,Z)^r, Y^r,{\varLambda }^r]\). Similarly we bound \(L_\rho [Y^{r+1}, (X, Z)^{r}; {\varLambda }^{r}]-L_\rho [W^{r}]\) as follows
where \({\mathrm{(i)}}\) is true because from Eqs. (18) and (19) we conclude that \(r_2(Y^{r+1})\le u_2(Y^{r+1},Y^{r})\), \({\mathrm{(ii)}}\) comes from the strong convexity of \(G[Y;(X,Z)^r,Y^r, {\varLambda }^r]\) with respect to Y with modulus \(\gamma _y\), and we have \(\mathrm{(iii)}\) due to the optimality condition for the problem (22a), which is \(0\in \partial _YG[Y^{r+1}; (X,Z)^r, Y^r,{\varLambda }^r]\), and we set \(\xi _Y=0\). Combining the Eqs. (42), (44) and (45), we have
To complete the proof we only need to set \(C_z=\frac{\gamma _z}{2}-\frac{L^2}{\rho }\), \(C_y=\frac{\gamma _y+\beta }{2}\), and \(C_x=\frac{\gamma _x+\beta }{2}\). Furthermore, since the subproblems (22a) and (22b) are strongly convex with modulus \(\gamma _x\ge 0\), \(\gamma _y\ge 0\), we have \(C_y\ge 0\), and \(C_x\ge 0\). Consequently, when \(\rho \ge \frac{2L^2}{\gamma _{z}}\) we also have \(C_z\ge 0\). Thus, the augmented Lagrangian function is always decreasing.
Part 2 Now we show that the augmented Lagrangian function is lower bounded
where in \(\mathrm (i)\) we use Eq. (39), \(\mathrm{(ii)}\) is true because we have picked \(\rho \ge L\), and \(\mathrm{(iii)}\) comes from the fact that for Lipchitz continuous function f we have
Due to the lower boundedness of g(X, Y, Z) (Assumption A) we have \(g(X^{r+1}, Y^{r+1}, X^{r+1}Y^{r+1})\ge \underline{g}\). Together with Eq. (47), we can set \(\underline{L}=\underline{g}\).
The proof is complete. Q.E.D.
1.3 Proof of Theorem 1
Part 1 Clearly, Eq. (29) together with the fact that augmented Lagrangian is lower bounded imply
Further, applying Lemma (1) we have
Utilizing the update equation for dual variable (22c), eventually we obtain
The part (1) is proved. From this part condition (26d) can be derived.
Part 2 Since \(Y^{r+1}\) minimizes problem (22a), we have
Thus, there exists \(\xi \in \partial l_2(Y^{r+1})\) such that for every Y
where we have set \({\varPhi }_2^r = h'_2(l_2(Y^r))\) for notational simplicity. Because \(l_2(Y)\) is a convex function we have the following inequality for every \(\xi \in \partial l_2(Y^{r+1})\)
Further since we assumed that \(h_2\) is non-decreasing, we have \( h'_2(l_2(Y^r))\ge 0\). Combining this fact with (51), yields the following
If we plug Eqs. (52) into (50) we obtain
Next taking the limit over (53) and utilizing the facts that \(\Vert Y^{r+1}-Y^r\Vert \rightarrow 0\), and \(\Vert X^{r+1}Y^{r+1}-Z^{r+1}\Vert _F\rightarrow 0\), we obtain the following
where \({\varPhi }_2^* = h'_2(l_2(Y^*))\). From Eq. (54) we can conclude that
which further implies
This is equivalent to
Applying the chain rule for Clark sub-differential given in Eq. (27), we have
From this equation we can simply conclude that
This proves the Eq. (26c).
Now let us consider (X, Z) step (22b). Similarly let us define \({\varPhi }_1 = h'_1(l_1(X^{r}))\). Since \((X,Z)^{r+1}\) minimizes (22b), we have
Let us take limit over the Eqs. (56) and (57). Then invoking (48, and (49) and following the same process for proving (26b) it follows that
which verifies (26a) and (26c).
The theorem is proved. Q.E.D.
Rights and permissions
About this article

Cite this article
Hajinezhad, D., Shi, Q. Alternating direction method of multipliers for a class of nonconvex bilinear optimization: convergence analysis and applications. J Glob Optim 70, 261–288 (2018). https://doi.org/10.1007/s10898-017-0594-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-017-0594-x