
Abstract
A new derivative-free optimization algorithm is introduced for nonconvex functions within a feasible domain bounded by linear constraints. Global convergence is guaranteed for twice differentiable functions with bounded Hessian, and is found to be remarkably efficient even for many functions which are not differentiable. Like other Response Surface Methods, at each optimization step, the algorithm minimizes a metric combining an interpolation of existing function evaluations and a model of the uncertainty of this interpolation. By adjusting the respective weighting of these two terms, the algorithm incorporates a tunable balance between global exploration and local refinement; a rule to adjust this balance automatically is also presented. Unlike other methods, any well-behaved interpolation strategy may be used. The uncertainty model is built upon the framework of a Delaunay triangulation of existing datapoints in parameter space. A quadratic function which goes to zero at each datapoint is formed within each simplex of this triangulation; the union of each of these quadratics forms the desired uncertainty model. Care is taken to ensure that function evaluations are performed at points that are well situated in parameter space; that is, such that the simplices of the resulting triangulation have circumradii with a known bound. This facilitates well-behaved local refinement as additional function evaluations are performed.



















Similar content being viewed by others


Notes
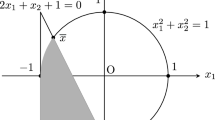
Taking a and b as vectors, \(a\le b\) implies that \(a_i\le b_i\ \forall i\).
Delaunay triangulations always exist, but are not necessarily unique. This algorithm builds on a Delaunay triangulation at each step, even if it is not unique. If a different Delaunay triangulation is used at a given step k, a different point \(x_k\) will be found, but the convergence properties are unaffected.
The logic for this conclusion is as follows: if (i) \(a\le b\) and (ii) \(a<b\ \rightarrow c<d\), then, if \(c=d\), then \(a=b\).
If \(A,B,C>0\), and \(A^2 \le AB+C\) then \(A\le B+\sqrt{C}\).
The parameters of the Weierstrass function used in this paper do not satisfy the condition assuring nondifferentiability everywhere that Weierstrass originally identified; however, according to [15], these parameters indeed assure nondifferentiability of the Weiertrass function everywhere as \(N\rightarrow \infty \).
References
Alexandria, D.A.: Convex Polyhedra. Springer, Berlin (2005)
Balinski, M.L.: An algorithm for finding all vertices of convex polyhedral sets. J. Soc. Ind. Appl. Math. 9(1), 72–88 (1961)
Belitz, P., Bewley, T.: New horizons in sphere-packing theory, part II: lattice-based derivative-free optimization via global surrogates. J. Glob. Optim. 56(1), 61–91 (2013)
Booker, A.J., Deniss, J.E., Frank, P.D., Serafini, D.B., Torczon, V., Trosset, M.W.: A Rigorous framework for optimization of expensive function by surrogates. Struct. Optim. 17(1), 1–13 (1999)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Hornus, S., Boissonnat, J.D.: An Efficient Implementation of Delaunay Triangulations in Medium Dimensions, [research report] RR-6743 (2008)
Boissonnat, J.D., Devillers, O., Hornus, S.: Incremental construction of the Delaunay triangulation and the Delaunay graph in medium dimension. In: Proceedings of the Twenty-Fifth Annual Symposium on Computational Geometry. ACM (2009)
Nielsen, H.B., Lophaven, S.N., Sndergaard, J., DACE, A.: A matlab kriging toolbox. In: Technical Report, Technical University of Denmark, Version 2.0, 1 Aug (2002)
Dwyer, R.A.: A faster divide-and-conquer algorithm for constructing delaunay triangulation. Algorithmica 2(1–4), 137–151 (1987)
Dwyer, R.A.: Higher-dimensional Voronoi diagram in linear exprected time. Discrete Comput. Geom. 6(1), 343–367 (1991)
Dwyer, R.A.: The expected number of k-faces of Voronoi diagram. Comput. Math. Appl. 26(5), 13–19 (1993)
George, P.L., Borouchaki, H.: Delaunay Triangulation and Meshing: Application to Finite Element. Hermes, Paris (1998)
Gill, P.E., Murray, M.: Newton-type methods for unconstrained and linearly constrained optimization. Math. Progr. 7(1), 311–350 (1974)
Gutmann, H.M.: A radial basis function method for global optimization. J. Glob. Optim. 19(3), 201–227 (2001)
Hardy, G.H.: Weierstrass as non differentiable function. Trans. Amer. Math. Soc. 17(3), 301–325 (1916)
Hoffman, K.L.: A method for globally minimizing concave functions over convex sets. Math. Progr. 20(1), 22–32 (1981)
Jones, D.: A taxonomy of global optimization methods based on response surfaces. J. Glob.Optim. 21, 345–383 (2001)
Krige, D.G.: A Statistical Approach to Some Mine Valuations and Allied Problems at the Witwatersrand. Masters thesis of the University of Witwatersrand, South Africa (1951)
Lewis, R.M., Torczon, V., Trosset, M.W.: Direct Search Method: Then and Now, NASA/CR-2000-210125, ICASE Report No.2000-26 (2000)
Li, X.Y.: Generating well-shaped d-dimensional Delaunay meshes. Theor. Comput. Sci. 296(1), 145–165 (2003)
Li, X-Y, Teng, S.H.: Generating well-shaped Delaunay meshed in 3D. In: Proceedings of the Twelfth Annual ACM-SIAM Symposium on Discrete algorithms. SIAM (2001)
Manas, M., Nedoma, J.: Finding all vertices of a convex polyhedron. Numer. Math. 12(3), 226–229 (1968)
Matheiss, T.H., Rubin, D.S.: A survey and comparison of methods for finding all vertices of convex polyhedral sets. Math. Oper. Res. 5(2), 167–185 (1980)
Matheron, B.: Principles of geostatistics. Econ. Geol. 58(8), 1246–1266 (1963)
McMullen, P.: The maximum numbers of faces of a convex polytope. Mathematika 17(02), 179–184 (1970)
Yang, X.: Nature-inspired optimization algorithms. Elsevier (2014)
Nocedal, J., Wright, S.J.: Numerical Optimization. Springer, Berlin (1999)
Powell, M.J.D.: An efficient method for finding the minimum for function of several variables without calculating derivatives. Comput. J. 7(2), 155–162 (1964)
Rosenbrock, H.H.: An automatic method for finding the greatest or least value of a function. Comput. J. 3(3), 175–184 (1960)
Rasmussen, C.E., Williams, C.K.I.: Gaussian Processes for Machine Learning. MIT Press, Cambridge (2006)
Schonlau, M., Welch, W.J., Jones, D.J.: A Data-Analytic Approach to Bayesian Global Optimization. Department of Statistics and Actuarial Science and The Institute for Improvement in Quality and Productivity, 1997 ASA conference (1997)
Shewchuk, J.R.: Delaunay refinement algorithms for triangular mesh generation. Comput. Geom. 22(1), 21–74 (2002)
Spendley, W., Hext, G.R., Himsworth, F.R.: Sequential application of simplex designs in optimisation and evolutionary operation. Technometrics 4(4), 441–461 (1962)
Torczon, V.: Multi-Directional Search, A Direct Search Algorithm for Parallel Machines, Ph.D. thesis, Rice University, Houstin, TX (1989)
Wahba, G.: Spline models for observational data, Vol. 59. Siam (1990)
Watson, D.: Computing the n-dimensional Delaunay tessellation with application to Voronoi polytopes. Comput. J. 24(2), 167–172 (1981)
Torczon, V.: On the convergence of pattern search algorithms. SIAM J. Optim. 7(1), 1–25 (1997)
Torn, A., Zilinkas, A.: Global Optimization. Springer, New York (1989)
http://www.qhull.org. Accessed 31 March 2015
http://netlib.org/voronoi/hull.html. Accessed 31 March 2015
http://www.cgal.org. Accessed 31 March 2015
Acknowledgments
The authors gratefully acknowledge funding from AFOSR FA 9550-12-1-0046, from the Cymer Center for Control Systems & Dynamics, and from Leidos corporation in support of this work.
Author information
Authors and Affiliations
Corresponding author
Appendix: Polyharmonic splines
Appendix: Polyharmonic splines
The algorithms described above require the gradient and Hessian of the interpolant being used to facilitate Newton-based minimizations of the search function. Since our numerical tests all implement the polyharmonic spline interpolation formula, we now derive analytical expressions of the gradient and Hessian in this case.
The polyharmonic spline interpolation p(x) of a function f(x) in \(\mathbb {R}^n\) is defined as a weighted sum of a set of radial basis functions \(\varphi (r)\) built around the location of each evaluation point, plus a linear function of x:
The weights \(w_i\) and \(v_i\) represent N and \(n+1\) unknowns, respectively, to be determined through appropriate conditions. First, we match the interpolant p(x) to the known values of f(x) at each evaluation point \(x_i\), i.e. \(p(x_i) = f(x_i)\); this gives N conditions. Then, we impose the orthogonality conditions \(\sum _i w_i = 0\) and \(\sum _i w_i x_{ij} = 0, \quad j = 1,\,2,\,\ldots ,\,n\). This gives \(n+1\) additional conditions. Thus,
The gradient and Hessian of p(x) may now be written as follows:
where \( \bar{v}=[v_2,v_3,\ldots ,v_{n+1}]^T \), and
Note that the calculation of the weights of a polyharmonic spline interpolant requires the solution of a \((N+n+1)\times (N+n+1)\) linear system. This system is not diagonally dominant, and does not show an easily-exploitable sparsity pattern facilitating fast factorization techniques. Nevertheless, since our algorithm adds only one point to the set of N evaluation points at each iteration, we can avoid the solution of the new linear system from scratch, and instead implement a rank-one update at each iteration as follows. First, for the set of initial points, we calculate the inverse \(A = \bigl [ {\begin{matrix} F &{} V^T \\ V &{} 0 \end{matrix}} \bigr ]\). This step is somewhat time consuming, but reduces the computations required in subsequent steps. Using Matrix Inversion Lemma, we then update the inverse of A with the new information given at each step as follows:
where b is a vector of length \(n+1\) defined as \(b = \bigl [ {\begin{matrix} 1&x_{N+1} \end{matrix}} \bigr ]^T\), and \(c = - b A_N^{-1} b^T\) is a scalar. Multiplication of \(A_{N+1}^{-1}\) in (85) with the vector \(\bigl [ {\begin{matrix} f(x_i)&0&f(x_{N+1}) \end{matrix}} \bigr ]^T\) gives the vector of weights in an unordered fashion, i.e. \(\bigl [ {\begin{matrix} w_i&v_i&w_{N+1}) \end{matrix}} \bigr ]^T\). Therefore, before adding the new function evaluation in the following iteration and performing the next rank-one update, it is necessary to permute the matrix \(A_{N+1}^{-1}\), given by
such that the desired \(2 \times 2\) block form at the next iteration is recovered:
After this permutation, it is possible to apply the Matrix Inversion Lemma (85) at the following step.
Remark 13
Another fast method to find the coefficients of radial basis functions is described in [35]. Since the present algorithms build the dataset incrementally, the method described above is less expensive in the present case.

The difference between the actual function, \(f(r)=r* \sin {1/r}\), where \(r^2=x^2+y^2\), and its interpolant for two different interpolation strategies when 1000 function evaluations are clustered near the center of a square domain. a The error of the polyharmonic spline interpolation interpolant (83). b The error of the Kriging interpolant with a Gaussian model for the corrrelation, computed using DACE
As mentioned earlier, variations of Kriging interpolation are often used in Response Surface Methods, such as the Surrogate Management Framework, for derivative-free optimization. DACE (see [8]) is one of the standard packages used for numerically computing the Kriging interpolant. Figure 20a and b compare of the polyharmonic spline interpolation method described above and the Kriging interpolation method computed using DACE, as applied to the test function \(f(r)=r* \sin {1/r}\), where \(r^2=x^2+y^2\) with \(N=1004\) data points. The data points used in this example are the 4 corners of a square domain, and 1000 random-chosen points clustered within a small neighborhood of the center of the square, which highlights the numerical challenge of performing interpolation when grid points begin to cluster in a particular region, which is common when a response surface method for derivative-free optimization approaches convergence. Figure 20a and b plot the difference between the real value of f and the value of the corresponding interpolants.
An observation which motivated the present study is that, in such problems, the Kriging interpolant is often spurious in comparison with other interpolation methods, such as polyharmonic splines. Note that various methods have been proposed to regularize such spurious interpolations in the presence of clustered datapoints, such as combining interpolants which summarize global trends with interpolants which account for local fluctuations. Our desire in the present effort was to develop a robust response surface method that can implement any good interpolation strategy, the selection of which is expected to be somewhat problem dependent.
Rights and permissions
About this article

Cite this article
Beyhaghi, P., Cavaglieri, D. & Bewley, T. Delaunay-based derivative-free optimization via global surrogates, part I: linear constraints. J Glob Optim 66, 331–382 (2016). https://doi.org/10.1007/s10898-015-0384-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-015-0384-2