
Abstract
We introduce a convex non-convex (CNC) denoising variational model for restoring images corrupted by additive white Gaussian noise. We propose the use of parameterized non-convex regularizers to effectively induce sparsity of the gradient magnitudes in the solution, while maintaining strict convexity of the total cost functional. Some widely used non-convex regularization functions are evaluated and a new one is analyzed which allows for better restorations. An efficient minimization algorithm based on the alternating direction method of multipliers (ADMM) strategy is proposed for simultaneously restoring the image and automatically selecting the regularization parameter by exploiting the discrepancy principle. Theoretical convexity conditions for both the proposed CNC variational model and the optimization sub-problems arising in the ADMM-based procedure are provided which guarantee convergence to a unique global minimizer. Numerical examples are presented which indicate how the proposed approach is particularly effective and well suited for images characterized by moderately sparse gradients.









Similar content being viewed by others


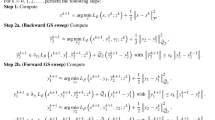
References
Bioucas-Dias, J., Figueredo, M.: Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 19(9), 2345–2356 (2010)
Blake, A., Zisserman, A.: Visual Reconstruction. MIT Press, Cambridge (1987)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1122 (2011)
Calvetti, D., Reichel, L.: Tikhonov regularization of large linear problems. BIT Numer. Math. 43, 263–283 (2003)
Calvetti, D., Morigi, S., Reichel, L., Sgallari, F.: Tikhonov regularization and the L-curve for large, discrete ill-posed problems. J. Comput. Appl. Math. 123, 423–446 (2000)
Chan, R.H., Tao, M., Yuan, X.M.: Constrained total variational deblurring models and fast algorithms based on alternating direction method of multipliers. SIAM J. Imag. Sci. 6, 680–697 (2013)
Chen, P.Y., Selesnick, I.W.: Group-sparse signal denoising: non-convex regularization, convex optimization. IEEE Trans. Sign. Proc. 62, 3464–3478 (2014)
Christiansen, M., Hanke, M.: Deblurring methods using antireflective boundary conditions. SIAM J. Sci. Comput. 30, 855–872 (2008)
Clarke, F.H.: Optimization and Nonsmooth Analysis. Wiley, New York (1983)
Corless, R.M., Gonnet, G.H., Hare, D.E.G., Jeffrey, D.J., Knuth, D.E.: On the Lambert W Function. Adv. Comput. Math. 5, 329–359 (1996)
Ekeland, I., Temam, R.: Convex Analysis and Variational Problems (Classics in Applied Mathematics). SIAM, Philadelphia (1999)
Engl, H.W., Hanke, M., Neubauer, A.: Regularization of Inverse Problems. Kluwer, Dordrech (1996)
Glowinski, R., Le Tallec, P.: Augmented Lagrangians and Operator-Splitting Methods in Nonlinear Mechanics. SIAM, Philadelphia (1989)
He, C., Hu, C., Zhang, W., Shi, B.: A fast adaptive parameter estimation for total variation image restoration. IEEE Trans. Image Process. 23(21), 4954–4967 (2014)
Lanza, A., Morigi, S., Sgallari, F.: Convex image denoising via non-convex regularization. Scale Space Var. Meth. Comput. Vis. 9087, 666–677 (2015)
Lu, C.W.: Image restoration and decomposition using nonconvex nonsmooth regularisation and negative Hilbert-Sobolev norm. IET Image Process. 6(6), 706–716 (2012)
Ng, M.K., Chan, R.H., Tang, W.C.: A fast algorithm for deblurring models with neumann boundary conditions. Siam J. Sci. Comput. 21, 851–866 (1999)
Nikolova, M.: Estimation of binary images by minimizing convex criteria. Proceedings of IEEE International Conference Image Processing, vol. 2, pp. 108–112 (1998)
Nikolova, M.: Analysis of the recovery of edges in images and signals by minimizing nonconvex regularized least-squares. Multiscale Model. Simul. 4(3), 960–991 (2005)
Nikolova, M., Ng, M., Tam, C.: Software is available at http://www.math.hkbu.edu.hk/~mng/imaging-software.html
Nikolova, M., Ng, M.K., Tam, C.P.: Fast non-convex non-smooth minimization methods for image restoration and reconstruction. IEEE Trans. Image Process. 19(12), 3073–3088 (2010)
Parekh, A., Selesnick, I.W.: Convex denoising using non-convex tight frame regularization. arXiv Preprint arXiv:1504.00976 (2015)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (1970)
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences], vol. 317. Springer, Berlin (1998)
Rudin, L.I., Osher, S., Fatemi, E.: Nonlinear total variation based noise removal algorithms. Phys. D 60(1–4), 259–268 (1992)
Selesnick, I.W., Bayram, I.: Sparse signal estimation by maximally sparse convex optimization. IEEE Trans. Signal Proc. 62(5), 1078–1092 (2014)
Selesnick, I.W., Parekh, A., Bayram, I.: Convex 1-D total variation denoising with non-convex regularization. IEEE Signal Proc. Lett. 22(2), 141–144 (2015)
Sidky, E.Y., Chartrand, R., Boone, J.M., Pan, X.: Constrained TpV-minimization for enhanced exploitation of gradient sparsity: application to CT image reconstruction. IEEE J. Trans. Eng. Health Med. 2, 1–18 (2014)
Wen, Y.W., Chan, R.H.: Parameter selection for total-variation-based image restoration using discrepancy principle. IEEE Trans. Image Process. 21(4), 1770–1781 (2012)
Wu, C., Tai, X.C.: Augmented Lagrangian method. Dual methods, and split bregman iteration for ROF, vectorial TV, and high order models. SIAM J. Imag. Sci. 3(3), 300–339 (2010)
Zhang, X., Burger, M., Bresson, X., Osher, S.: Bregmanized nonlocal regularization for deconvolution and sparse reconstruction. SIAMJ. Imag. Sci. 3(3), 253–276 (2010)
Wu, C., Zhang, J., Tai, X.C.: Augmented Lagrangian method for total variation restoration with non-quadratic fidelity. Inv. Prob. Imag. 5(1), 237–261 (2011)
Acknowledgments
This work was supported by the “National Group for Scientific Computation (GNCS-INDAM)” and ex60% project by the University of Bologna “Funds for selected research topics”.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Proof of Proposition 3.2
Proof
Recalling that convexity of a function is invariant to non-singular linear transformations of the domain, we search for a non-singular linear transformation \(T: {\mathbb R}^3 \rightarrow {\mathbb R}^3\) of the domain of function f defined in (3.7), that is \( x = T y\), with \(x = (x_1,x_2,x_3)^T\), \(y = (y_1,y_2,y_3)^T\), \(T = (T_{i,j})_{i,j:=1,2,3}\) such that convexity conditions for the function \(f_T := f \circ T\) are easier to identify than for f. We obtain the explicit expression of function \(f_T\), depending on y and on the nine entries of the transformation matrix T, by replacing \(x = Ty\) in (3.7):
where \(Q_1\) and \(Q_2\) are the quadratic functions. We impose that both \(Q_1\) and \(Q_2\) do not contain mixed products, that \(Q_2\) does not depend on \(y_3\), and that the coefficients of both \(y_1^2\) and \(y_2^2\) in \(Q_2\) are equal to one; we obtain that the transformation matrix \(T = (0,\sqrt{2}/3,\sqrt{3}/3; \sqrt{2}/2,-\sqrt{2}/6,\sqrt{3}/3; -\sqrt{2}/2,-\sqrt{2}/6,\sqrt{3}/3)\) yields
It follows that the function \(f_T(y_1,y_2,y_3)\) above, hence also f in (3.7), is strictly convex if and only if the function \(g(y_1,y_2)\) defined in (3.9) is strictly convex. \(\square \)
1.2 Proof of Proposition 3.3
Proof
The function \(g: {\mathbb R}^2 \rightarrow {\mathbb R}\) in (3.9) can be rewritten in composite form as follows:
with the function \(\rho : {\mathbb R}^2 \rightarrow {\mathbb R}_+\) defined by
and the function \(h: {\mathbb R}_{+} \rightarrow {\mathbb R}\) defined in (3.10).
We notice that, due to definition of function \(\rho \) in (6.4) and due to Assumption 1) in Sect. 2 on the penalty function \(\phi \), we have
It follows from (6.3)–(6.5) that the function g is such that
Hence, condition for g to be strictly convex is that its Hessian matrix \(H_g(y_1,y_2)\) is positive definite for any \((y_1,y_2) \in {\mathbb R}^2 \setminus \{(0,0)\}\). In the following, we investigate such condition.
By applying the chain rule of differentiation twice to the function g in composite form (6.3), we get
where \(H_{\rho }\) and \(\nabla \rho \) denote the Hessian matrix and the gradient of function \(\rho \) in (6.4), respectively, and where, for simplicity of notations, dependencies on independent variables are dropped and a concise notation for ordinary and partial derivatives is adopted, namely \(h' := dh / d\rho \), \(h'' := d^2h / d\rho ^2\), \(\rho _i := \partial \rho / \partial y_i\), \(\rho _{i,j} := \partial ^2 \rho / \partial y_i \partial y_j\), \(i,j \in \{1,2\}\). We remark that, since we are considering the case \((y_1,y_2) \ne (0,0)\), all the differential quantities in (6.7) are well defined and, in particular, no one-sided derivative is involved.
According to the Sylvester’s criterion, the Hessian matrix \(H_g\) in (6.7) is positive definite if and only if its two leading principal minors are positive, that is if the following two conditions hold:
The first- and second-order partial derivatives of \(\rho \) in (6.4) are as follows:
Replacing expressions (6.9) into \(H_g\) positive definiteness conditions (6.8) and recalling that \(\rho \) is a positive quantity for every \((y_1,y_2) \ne (0,0)\), we obtain

Hence, the function g defined in (3.9) is strictly convex if and only if the function h in (3.10) is monotonically increasing and strictly convex. \(\square \)
1.3 Proof of Proposition 4.2
Proof
According to Proposition (3.5), in case that the parameter pair \((\mu ,a)\) satisfies (3.13), the functional \(\mathcal {J}(u;\mu ,a)\) in (1.4) is strictly convex, thus admitting a unique minimizer \(u^*\). Then, the first-order optimality condition for \(\mathcal {J}\) at \(u^*\) given in (4.6) follows immediately from the generalized Fermat’s rule (see Theorem 10.1 in [24]).
To prove (4.7), we need to write in a more explicit form the subdifferential \(\partial _u \left[ \, \mathcal {J} \,\right] \). However, we cannot apply the additive rule of subdifferentials to the functional \( \mathcal {J}\) since the regularization term \(\Phi \) in (4.5) is non-convex in u due to concavity of the penalty function \(\phi \). Hence, we resort to notions from calculus for non-smooth non-convex functions, in particular the Clarke generalized gradient [9], which extends the concept of subdifferential for non-smooth convex functions to the case of non-smooth non-convex but locally Lipschitz functions. Indeed, the rest of the proof relies on the fact that, according to Lemma 4.1, both the total functional \(\mathcal {J}\) in (1.4) and, separately, the \(\Phi \) regularization term in (4.5) and the quadratic fidelity term are locally Lipschitz functions, such that their generalized gradient is defined.
First, we recall that for non-smooth but convex functions the Clarke generalized gradient is equal to the subdifferential [9], that is, in our case:
After recalling the definition of functional \(\mathcal {J}\) in (1.4), we can now apply the additive rule of generalized gradients [9] to the right-hand side of (6.11):
where in (6.12) we applied the property that the generalized gradient reduces to the usual gradient in case of continuously differentiable functions.
Recalling the definition of the \(\Phi \) regularization term in (4.5) and applying to the first term of (6.12) the chain rule for generalized gradients [9], we obtain
From (6.13), (6.12), (6.11), and statement (4.6), statement (4.7) follows immediately. \(\square \)
1.4 Proof of Theorem 4.4
Proof
Based on the definition of the augmented Lagrangian functional in (4.3), we rewrite in explicit form the first inequality of the saddle-point condition in (4.4):

and, similarly, the second inequality:

In the first part of the proof, we demonstrate that if \(\,(u^*,z^*,t^*;\lambda _z^*,\lambda _t^*)\,\) is a solution of the saddle-point problem (4.3)–(4.4), that is it satisfies the two inequalities (6.14) and (6.15), then \(u^*\) is the unique minimizer of the functional \(\mathcal {J}(u;\mu ,a)\) in (1.4).
Since (6.14) must be satisfied for any \((\lambda _z,\lambda _t) \;{\in }\; V {\times }\, Q\), by taking \(\lambda _z = \lambda _z^*\) we obtain
Similarly, by taking \(\lambda _t = \lambda _t^*\) in (6.14) we have
The second inequality (6.15) must be satisfied for any \((u,z,t) \;{\in }\; V {\times }\, V {\times }\, Q\). Hence, by taking simultaneously \(z = u\) and \(t = Du\) in (6.15) and, at the same time, substituting in (6.15) the two previously derived conditions (6.16) and (6.17), we obtain

Inequality (6.18) indicates that \(u^*\) is a global minimizer of the functional \(\mathcal {J}(u;\mu ,a)\) in (1.4). Hence, we have demonstrated that all the saddle-point solutions, if there exists one, of problem (4.3)–(4.4) are of the form \(\,(u^*,u^*,Du^*;\lambda _z^*,\lambda _t^*)\,\), with \(u^*\) denoting the unique global minimizer of \(\mathcal {J}(u;\mu ,a)\).
In the second part of the proof, we demonstrate that at least one solution of the saddle-point problem exists. In particular, we prove that if \(u^*\) is a minimizer of \(\mathcal {J}(u;\mu ,a)\) in (1.4), then there exist \(\,(z^*,t^*) \in V {\times }\, Q\) and \(\,(\lambda _z^*,\lambda _t^*) \in V {\times }\, Q\) such that \((u^*,z^*,t^*;\lambda _z^*,\lambda _t^*)\) is a solution of the saddle-point problem (4.3)–(4.4), that is it satisfies the two inequalities (6.14) and (6.15). The demonstration relies on an initial suitable choice of the vectors \(z^*\), \(t^*\), \(\lambda _z^*\), and \(\lambda _t^*\). Analogously to the proofs in [14, 30], we take
where the term \(\bar{\partial }_{Du} \left[ \, \Phi \,\right] (Du^*)\) indicates the Clarke generalized gradient (with respect to Du, calculated at \(Du^*\)) of the non-convex regularization term \(\Phi \) in (4.5). We notice that a vector \(\lambda _t^*\) satisfying (6.20) is guaranteed to exist thanks to Proposition 4.2. In fact, since here we are assuming that \(u^*\) is a minimizer of functional \(\mathcal {J}(u;\mu ,a)\), the first-order optimality condition in (4.7) holds true.
Due to the first two settings in (6.19), the first saddle-point condition in (6.14) is clearly satisfied. Proving the second condition, that we rewrite in compact form as
is less straightforward: we need to investigate the optimality conditions of functional \(\mathcal {L}\,(u,z,t;\lambda _z^*,\lambda _t^*;\mu ,a)\) in (6.21). To this aim, we introduce below the three functions \(\mathcal {L}_u(u,z,t;\lambda _z^*,\lambda _t^*;\mu ,a)\), \(\mathcal {L}_z(u,z,t;\lambda _z^*,\lambda _t^*;\mu ,a)\), and \(\mathcal {L}_t(u,z,t;\lambda _z^*,\lambda _t^*;\mu ,a)\) representing the restriction of \(\mathcal {L}\,(u,z,t;\lambda _z^*,\lambda _t^*;\mu ,a)\) to only the terms depending on the primal variables u, z, and t, respectively:
We notice that the functions \(\mathcal {L}_u\), \(\mathcal {L}_z\), and \(\mathcal {L}_t\) above are proper, continuous, and coercive with respect to the variables u, z, and t, respectively. Moreover, the three selected functions \(F_1\) and the function \(F_2\) in (6.23) are convex, hence \(\mathcal {L}_u\) and \(\mathcal {L}_z\) are convex. For what concerns the function \(F_2\) in (6.24), it follows from the results that are given in Proposition 4.5 that it is strictly convex if and only if the condition \(\beta _t > a\) is satisfied. Since in the ADMM-based scheme that we will present for solving the saddle-point problem (4.3)–(4.4) such condition will be taken as a constraint, we can assume here that it is satisfied, such that \(F_2\) in (6.24) is convex and, hence, \(\mathcal {L}_t\) is convex as well. By finally noticing that the three functions \(F_1\) are G\(\hat{a}\)teaux differentiable, we can apply Lemma 4.3 separately to (6.22), (6.23), and (6.24) thus obtaining the following optimality conditions for a generic point \((\bar{u},\bar{z},\bar{t})\):
We now verify that the triplet \((z^*,t^*,u^*)\) satisfies the optimality conditions above, so that the second saddle-point condition (6.21) holds true. By substituting \((z^*,t^*,u^*)\) for \((\bar{z},\bar{t},\bar{u})\) in (6.25), (6.26), and (6.27), we obtain
where the underlined terms are null due to some of the settings in (6.19)–(6.20). The first condition (6.28) is clearly satisfied. We rewrite the second and third conditions by substituting also the settings on \(\lambda _z^*\) and \(\lambda _t^*\) in (6.20):
where in (6.32) we added the null term \(\mu \, (t^* - Du^*)\). The two optimality conditions (6.31) and (6.32) can be proved based on the concept of Bregman distance that we thus recall here briefly: given a convex not necessarily smooth function G and two points x, \(x^*\) in its domain, the Bregman distance (or divergence) associated with function G for points x, \(x^*\) is defined as
where \(\partial G\) denotes the subdifferential of G. The Bregman distance is not a distance in strict sense, but it is always non-negative for convex functions G. Inequalities (6.31) and (6.32) can be equivalently rewritten in terms of Bregman distances as follows:
In particular, (6.34) follows immediately from (6.31) and (6.33), whereas (6.35) follows from (6.32) and (6.33) and from two further observations. First, the function T in (6.35) is convex for the same reasons for which the function \(F_2\) in (6.24) is convex. Second, the first term of the scalar product in (6.35) represents the subdifferential of the convex function T. Since the Bregman distance is always non-negative, (6.34) and (6.35) hold true, the second saddle-point condition in (6.21) is satisfied, and, finally, the second part of the Theorem proof is completed. \(\square \)

Geometric representation of problem (4.33)
1.5 Proof of Proposition 4.5
Proof
Condition (4.32) for convexity of function \(\theta \) in (4.31) can be easily demonstrated based on Proposition 3.3 in Sect. 3. In fact, after rewriting \(\theta \) as follows:
with L being an affine function which, hence, does not affect convexity, we notice that the non-affine part of \(\theta \) in (6.36) can be written in composite form as
Hence, recalling demonstration of Proposition 3.3, the function \(\theta \) is convex if and only if both of the following conditions hold:
Since by hypothesis \(\beta > 0\) and the function \(\phi \) satisfies assumption (A2) in Sect. 2, namely \(\,\phi '(t;a) > 0\,\) for any \(t \ge 0\), the first condition in (6.38) is always satisfied. The second condition in (6.38) is equivalent to the convexity condition in statement (4.32).
We now prove statement (4.34), according to which the unique solution \(x^*\) of the strictly convex problem (4.33) is obtained by a shrinkage of vector r. To allow for a clearer understanding of the proof, in Fig. 10 we give a geometric representation of problem (4.33). First, we prove that the solution \(x^*\) of (4.33) lies on the closed half-line Or with origin at the 2-dimensional null vector O and passing through r, represented in solid red in Fig. 10a. To this purpose, we demonstrate that for any point z not lying on Or there always exists a point \(z^*\) on Or providing a lower value of the objective function in (4.33), that is a point \(z^*\) such that \(\theta (z) - \theta (z^*) > 0\). In particular, we define \(z^*\) as the intersection point between the half-line Or and the sphere with center in O and passing through z, depicted in solid blue in Fig. 10a. Recalling the definition of \(\theta \) in (4.31) and noting that \(\Vert z^*\Vert _2 = \Vert z \Vert _2\) by construction, we can thus write
Since \(\beta > 0\) by hypothesis, \(z^* \!\ne z\) and \(r \ne O\) by construction, and noting that the angle \(\widehat{O \, z^* z}\) is always acute, we can conclude that the expression in (6.39) is positive. Hence, the solution \(x^*\) of (4.33) lies on the closed half-line Or.
We now prove that the solution \(x^*\) of (4.33) lies inside the segment [Or], represented in solid red in Fig. 10b. To this purpose, we demonstrate that for any point z lying on the half-line Or but outside the segment [Or] there always exists a point \(z^*\) on [Or] such that \(\theta (z) - \theta (z^*) > 0\). In particular, it suffices to choose \(z^* = r\), as illustrated in Fig. 10b. We obtain
Since \(\Vert z \Vert _2 > \Vert r \Vert _2\) by construction and the function \(\phi \) is monotonically increasing by hypothesis, the expression in (6.40) is positive, hence the solution \(x^*\) of (4.33) lies on the segment [Or].
To conclude the proof of statement (4.34), we notice that the directional derivative of the objective function \(\theta \) in (4.31) at r in the direction of r is as follows:
where the inequality follows from assumption (A2) in Sect. 2. It follows from (6.41) that the solution \(x^*\) of (4.33) never coincides with vector r.
Based on (4.34), by setting \(x = \xi r\), \(0 \le \xi < 1\), the original unconstrained 2-dimensional problem in (4.33) can be reduced to the following equivalent constrained 1-dimensional problem:

where in (6.42) we omitted the constant terms and introduced the objective function f for future reference. Since we are assuming that the function \(\phi \) is twice continuously differentiable in \({\mathbb R}_+\), so it is the cost function f in (6.42) in the optimization domain \(0 \le \xi \le 1\). Moreover, f is strictly convex since it represents the restriction of the strictly convex function \(\theta \) in (4.31) to the segment \(\xi \, r, \, 0 \le \xi \le 1\). Hence, the necessary and sufficient condition for an inner point \(0 < \xi < 1\) to be the global minimizer of f is as follows:

Since f is strictly convex, the first derivative \(f'(\xi )\) is strictly increasing in the entire domain \(0 \le \xi \le 1\) and at the extremes we have
Since \(\Vert r \Vert _2 > 0\) and \(\phi '(t;a) > 0\) for any \(t \ge 0\) by hypothesis, \(f'(1)\) in (6.44) is positive. Hence, we have two cases. If \(f'(0^+) \ge 0\), that is \(\Vert r\Vert \le \phi '(0^+;a) / \beta \), \(f'(t)\) is positive in \(0 < t \le 1\), hence the function f has its minimum at \(\xi ^* = 0\); if \(f'(0^+) < 0\), then f has the minimum at its unique stationary point \(0 < \xi ^* < 1\), which can be obtained by solving the nonlinear equation in (6.43). \(\square \)
1.6 Proof of Proposition 4.6
Proof
After setting \(\,\alpha := \Vert r \Vert _2\,\) for simplicity of notations, we have to solve the following constrained nonlinear equation:
Substituting in (6.45) the expression of the first-order derivative of the exponential penalty function reported in the second row of Table 1, we obtain
We notice that
such that (6.46) can be written as
After multiplying both sides of (6.48) by \(a \, / \, (\beta \, e^{a \alpha })\), we obtain
After the following change of variable:
we obtain
Hence, the unique solution \(y^*\) of (6.51) is given by
and, following from (6.50), the unique solution \(x^*\) of (6.46) is
where \(W_0(\cdot )\) represents the principal branch of the Lambert W function [10]. \(\square \)
Rights and permissions
About this article

Cite this article
Lanza, A., Morigi, S. & Sgallari, F. Convex Image Denoising via Non-convex Regularization with Parameter Selection. J Math Imaging Vis 56, 195–220 (2016). https://doi.org/10.1007/s10851-016-0655-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10851-016-0655-7