
Abstract
This work presents the modules for enhancing the security of speaker authentication by embedding the watermark in a speech signal. Speaker is authenticated by speech as well as the extracted watermark from the watermarked speech. Firstly, the speech signal is converted into frames, and discrete wavelet transform is applied to each frame, and it is preferable to embed the watermark in detail coefficients. The segment for embedding the watermark is appropriately chosen based on the energy calculations. The approximation and the modified detail coefficients are used to generate the watermarked speech by inverse discrete wavelet transform. Imperceptibility of the watermark in a watermarked speech is purely depending on the embedding of the watermark. In the receiver, the watermarked speech will undergo wavelet decomposition, and the watermark bits are extracted from the detail coefficients and appropriately transformed into watermark speech/image. The performance the work is evaluated by using the metrics such as Peak signal to noise ratio (PSNR) between original watermark and extracted watermark, PSNR between original speech and watermarked speech and Bit error rate (BER) and Perceptual evaluation speech quality (PESQ). Speaker identification system is assessed by using extraction of the perceptual features and application of features to develop the models for the set of utterances about the speaker during the training phase of the work. Testing is done by applying the original and watermarked speech utterances to the feature extraction phase, followed by we have the testing phase which is used for computing the accuracy. Accuracy is 98.2% for the speaker identification with the set of original test utterances and 98.1% with watermarked set of test utterances and it is observed that there is the marginal difference in accuracy for using speech as a watermark. It is 97.85% for using the image as a watermark. Cover speech signals and watermark speech used in our work are continuous speech utterances chosen from “TIMIT” speech database. Image watermark is the Quick response (QR) code for the LOGO. This work also emphasizes the effectiveness of the algorithm in providing robustness for copyright protection to ownership of the data and authenticating persons using speech as a biometric.









Similar content being viewed by others
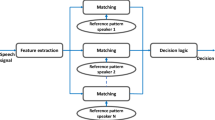
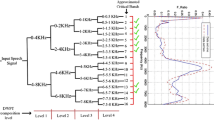

Data Availability
All relevant data are within the paper and its supporting information files.
References
Das, R. K., Jelil, S., & Prasanna, S. M. (2017). Development of multi-level speech based person authentication system. Journal of Signal Processing Systems, 88(3), 259–271.
Desai, N., & Tahilramani, N. (2016). Digital speech watermarking for authenticity of speaker in speaker recognition system. In 2016 international conference on micro-electronics and telecommunication engineering (ICMETE) (pp. 105–109). IEEE.
Desai, N. G., & Tahilramani, N. V. (2016). Speaker recognition system using watermark technology for anti-spoofing attack: A Review. International Journal of Innovative Research in Electrical, Electronics, Instrumentation and Control Engineering, 4(4), 152–156.
Dey, S., Barman, S., Bhukya, R. K., Das, R. K., Haris, B. C., Prasanna, S. R., & Sinha, R. (2014). Speech biometric based attendance system. In 2014 twentieth national conference on communications (NCC) (pp. 1–6). IEEE.
Garofolo, J. S. (1993). TIMIT acoustic phonetic continuous speech corpus. Linguistic Data Consortium, 1993.
Hermansky, H., & Morgan, N. (1994). RASTA processing of speech. IEEE Transactions on Speech and Audio Processing, 2(4), 578–589.
Hermansky, H., Morgan, N., Bayya, A., & Kohn, P. (1991). The challenge of inverse-E: the RASTA-PLP method. In 1991 conference record of the twenty-fifth asilomar conference on Signals, systems and computers (pp. 800–804). IEEE.
Hermansky, H., Tsuga, K., Makino, S., & Wakita, H. (1986). Perceptually based processing in automatic speech recognition. In IEEE international conference on acoustics, speech, and signal processing, ICASSP’86 (Vol. 11, pp. 1971–1974). IEEE.
Nematollahi, M. A., Al-Haddad, S. A., Doraisamy, S., & Ranjbari, M. (2014). Digital speech watermarking for anti-spoofing attack in speaker recognition. In 2014 IEEE on region 10 symposium (pp. 476–479). IEEE.
Nematollahi, M. A., Gamboa-Rosales, H., Akhaee, M. A., & Al-Haddad, S. A. (2015). Robust digital speech watermarking for online speaker recognition. Mathematical Problems in Engineering.
Nematollahi, M. A., Gamboa-Rosales, H., Martinez-Ruiz, F. J., Jose, I., Al-Haddad, S. A., & Esmaeilpour, M. (2017). Multi-factor authentication model based on multipurpose speech watermarking and online speaker recognition. Multimedia Tools and Applications, 76(5), 7251–7281.
Rabiner, L. R., & Juang, B. H. (1993). Fundamentals of speech recognition. Englewood Cliffs: PTR Prentice Hall.
Rani, R., & Sachdeva, R. (2016). Genetic algorithm using speech and signature of biometrics.
Revathi, A., & Venkataramani, Y. (2011) Speaker independent continuous speech and isolated digit recognition using VQ and HMM. In 2011 International conference on communications and signal processing (ICCSP) (pp. 198–202). IEEE.
Safavi, S., Gan, H., Mporas, I., & Sotudeh, R. (2016). Fraud detection in voice-based identity authentication applications and services. In 2016 IEEE 16th international conference on data mining workshops (ICDMW) (pp. 1074–1081). IEEE.
Sarria-Paja, M., Senoussaoui, M., & Falk, T. H. (2015). The effects of whispered speech on state-of-the-art voice based biometrics systems. In 2015 IEEE 28th Canadian conference on electrical and computer engineering (CCECE) (pp. 1254–1259). IEEE.
Acknowledgements
It is our work—no grant & contribution numbers.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interest
The authors have declared that no competing interest exists.
Rights and permissions
About this article

Cite this article
Revathi, A., Sasikaladevi, N. & Jeyalakshmi, C. Digital speech watermarking to enhance the security using speech as a biometric for person authentication. Int J Speech Technol 21, 1021–1031 (2018). https://doi.org/10.1007/s10772-018-09563-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-018-09563-9