
Abstract
Transformative disaster resilience in times of climate change underscores the importance of reflexive governance, facilitation of socio-technical advancement, co-creation of knowledge, and innovative and bottom-up approaches. However, implementing these capacity-building processes by relying on census-based datasets and nomothetic (or top-down) approaches remains challenging for many jurisdictions. Web 2.0 knowledge sharing via online social networks, whereas, provides a unique opportunity and valuable data sources to complement existing approaches, understand dynamics within large communities of individuals, and incorporate collective intelligence into disaster resilience studies. Using Twitter data (passive crowdsourcing) and an online survey, this study draws on the wisdom of crowds and public judgment in near-real-time disaster phases when the flood disaster hit Germany in July 2021. Latent Dirichlet Allocation, an unsupervised machine learning technique for Topic Modeling, was applied to the corpora of two data sources to identify topics associated with different disaster phases. In addition to semantic (textual) analysis, spatiotemporal patterns of online disaster communication were analyzed to determine the contribution patterns associated with the affected areas. Finally, the extracted topics discussed online were compiled into five themes related to disaster resilience capacities (preventive, anticipative, absorptive, adaptive, and transformative). The near-real-time collective sensing approach reflected optimized diversity and a spectrum of people’s experiences and knowledge regarding flooding disasters and highlighted communities’ sociocultural characteristics. This bottom-up approach could be an innovative alternative to traditional participatory techniques of organizing meetings and workshops for situational analysis and timely unfolding of such events at a fraction of the cost to inform disaster resilience initiatives.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In July 2021, country-wide flooding in Germany affected about 40,000 people, claimed more than 197 lives and 1000 injuries, and caused total damage of about $40 billion (“EM-DAT,” 2022). The high death toll (the highest since 1962) in the world’s fourth largest economy, unfamiliar with this scale of death and destruction, raised questions about the resilience of Germany to such unforeseen floods and its readiness to deal with the impacts of climate change (Fekete & Sandholz, 2021). Moreover, the recently published 6th Assessment Report of the Intergovernmental Panel on Climate Change (IPCC) warns that such extreme events will continue to increase in frequency and severity in the coming decades (“IPCC,” 2022). This underscores the need to shift from a reactive to a proactive approach in addressing climate-related hazards and unforeseen disasters and improving community resilience. To improve community resilience, it is critical to overcome the limitations of nomothetic (top-down) resilience approaches that use a set of indicators to characterize resilience and statically measure inherent baseline conditions (Cutter, 2016; Yabe et al., 2022). Complementing this, idiographic (bottom-up) approaches to disaster resilience that leverage collective local knowledge and information, reflect the resilience capacities of communities, and propose place-based resilience strategies are urgently needed.
Furthermore, Web 2.0 has changed how people communicate, seek, exchange, and generate knowledge on online social platforms (Ziegler, 2022). In particular, social media channels such as Facebook, Instagram, and Twitter, as passive crowdsourcing platforms, provide unique venues in an online space through which people’s collective place-based knowledge, experiences, and perceptions can be captured (Lamoureux & Fast, 2019; Muñoz et al., 2020). These platforms also enable the public to produce geographic information on a voluntary basis, which can be referred to as Volunteered Geographic Information (VGI) (Degrossi et al., 2019; Elwood et al., 2012). On the one hand, this allows the wisdom of crowds to be captured in specific spatial and temporal units through researchers’ large-scale observations and social sensing techniques, so-called passive crowdsourcing (Fan et al., 2020; Ghermandi & Sinclair, 2019). On the other hand, using these platforms enables different levels of participation and engagement of citizens who are not otherwise involved in scientific or administrative activities (Haklay, 2013; Howe, 2006). Twitter, in particular, offers a unique perspective because the social network is widely shared, user-driven, and network-based. These characteristics of Twitter as an open-source micro-blogging platform make it a valuable and useful source of data, as each tweet is typically linked to temporal-spatial and textual information, resulting in relatively homogeneous and comparable corpora for understanding the dynamics within large communities of individuals due to the relatively short message size (Rachunok et al., 2021; Rudra et al., 2019).
Twitter has proven useful for situational awareness, distributed problem-solving, and collective action, especially during crises (Ghermandi & Sinclair, 2019). However, there is a shortage of studies that harness the power of these valuable data sources that provide specific local and contextual knowledge based on collective and foundational insights about individuals and communities (collective intelligence) to inform community resilience from the bottom up (Fan et al., 2020; Rachunok et al., 2021). Therefore, this study presents one of the first attempts that harness social media (Twitter) data and an online survey to aggregate flood-related individual judgments and inform flood resilience in Germany through a bottom-up collective sensing approach.
To this end, after mining flood-related tweets (with a set of hashtags for each disaster phase) from July 12 to July 31, 2021 (short-term before, during, and after the flood disaster) and pre-processing the raw data, we performed textual, spatial, and temporal analysis for each phase. For the textual/semantic analysis, Latent Dirichlet Allocation (LDA) was used as an unsupervised machine learning model for Topic Modeling to obtain latent topics of the corpora (Blei et al., 2003). Kernel Density Estimation (KDE) at the state level and temporal clustering of tweets in different disaster phases were performed to analyze the spatiotemporal characteristics of disaster-related tweets. As an additional data layer, we conducted an online survey among the responders of the September 2021 flood disaster. We also modeled the topics (using LDA) that were highlighted in open-ended questions by this stakeholder group in German emergency management. Finally, the results of the Twitter Topic Modeling and the online survey were compiled into different themes of preventive, anticipative, absorptive, adaptive, and transformative resilience capacities for evidence-based improved resilience.
The practical implication of this novel and interactive web-based approach is grouping a large number of judgments to optimize the diversity and spectrum of experience and knowledge of contributors (wisdom of crowds) with different backgrounds on flood resilience in a timely manner. Passive crowdsourcing integrated with online surveying could also be an alternative to traditional participatory methods and techniques that organize meetings and workshops for situation analysis and unfolding such events. Finally, reflecting on the collective intelligence, perceptions, and expectations within the decision-making process contributes to identifying short-term priorities for action and developing place-based disaster resilience strategies based on the community’s medium- to long-term needs and capacities.
Background
Disaster resilience
International agreements and agendas compete to address the challenges posed by natural hazards and the impacts of climate change. In the Sustainable Development Goals (SDGs), target 1.5 calls for “…strengthening the resilience of people in vulnerable situations and reducing their exposure and vulnerability to climate-related extreme events and other economic, social and environmental shocks and disasters”, Goal 11 calls for “making cities and human settlements inclusive, safe, resilient and sustainable” in line with the Sendai Framework (11.b), while Goal 13 calls for urgent climate action (United Nations, 2015b). The Sendai Framework for Disaster Risk Reduction also prioritizes building resilience to reduce disaster risk, understanding disaster risk, and enhancing disaster preparedness for effective response and building back better in recovery and rehabilitation (United Nations, 2015a).
In academic circles, there are numerous theoretical and operationalizable frameworks on disaster resilience, that emphasize the extension of preventive (ability of systems to adopt sustainable pathways and reduce vulnerability, presence, or impact of hazards), anticipative (ability to understand risks based on risk data and scenarios to predict where, when, and whom disaster will affect), absorptive (the ability of systems to withstand change and bounce back to a previous state), adaptive (adjustment to change and reorganizing without significant qualitative changes in functions or structures), and transformative (transformation through learning, self-organization, and exploration of new pathways along with flexibility and substantial modifications to existing structures) capacities within different resilience dimensions (individual, social, economic, institutional, infrastructural, environmental, and community capital) to build and enhance overall disaster resilience at multiple levels (Asadzadeh et al., 2015; Assarkhaniki et al., 2020; Béné et al., 2012; Cutter et al., 2008; Khazai et al., 2015, 2018; Manyena et al., 2019; Moghadas et al., 2019; Rajabifard, 2020).
However, the importance of building disaster resilience by considering the role of good governance, empowered people, and technology-driven approaches to create solutions in a place-based, inclusive, and forward-looking manner has compelled recent urban resilience initiatives to focus on the concept of transformative resilience, especially when incremental adaptation and conventional resilience planning are insufficient (Asadzadeh et al., 2022; Moghadas et al., 2022; Rajabifard et al., 2021). Transformational approaches emphasize the role of technological-social development and the integration of new data (VGI, social media, crowdsourcing, etc.) that can contribute to improved situational awareness and the development of indicators that reflect soft attributes of resilience (e.g., community solidarity, learning from the past, knowledge of climate resilience) (Fekete & Rhyner, 2020; Feldmeyer et al., 2020; Moghadas et al., 2022; Yabe et al., 2022).
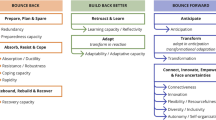
Disaster Risk Management (DRM) activities also focus on strengthening the social and economic resilience of individuals and societies in the face of disaster risk through the process of prevention (activities and measures to avoid existing and new disaster risks), preparedness (effectively anticipate, respond to and recover from the impacts of disasters), response (actions taken directly before, during or immediately after a disaster), and recovery (rehabilitation and restoration of services and facilities essential to the functioning of a community in the short term and reconstruction, rebuilding, and sustainable restoration of affected systems and communities in the medium to long term), and utilizing a mix of different financial instruments, such as national emergency funds, contingency credit, insurance, and reinsurance (Fekete et al., 2020; Manyena et al., 2019; UNDRR, 2022). With this background, Fig. 1 shows a schematic representation of disaster resilience capacities within the DRM cycle.

Schematic representation of disaster resilience capacities within the disaster management cycle
Although the representation of the DRM cycle has been criticized because it lacks the idea of progress, building back better, and learning, it is still frequently used. We also use it here only schematically to provide a link to DRM and disaster resilience capacities.
Crowdsourced social media in disaster resilience
The Sendai Framework promotes the use of information and communications technology innovations to improve data collection, analysis, and dissemination, as well as the increased use of social media and mobile networks to support real-time, data-driven measures for successful disaster risk communications (United Nations, 2015a). Social media platforms enable access to near real-time, affordable, up-to-date, and fit-for-purpose geospatial information that can be complementary data sources in disasters for better situational awareness (Fan et al., 2020; Moghadas et al., 2022). Social media platforms, moreover, enable passive and active (when they voluntarily share spatial information) participation by citizens who are not otherwise involved in disaster-related activities (Muñoz et al., 2020; Tzavella et al., 2022). In this context, crowdsourcing approaches like “People as Sensors” and Collective Sensing (Haklay, 2013; Resch et al., 2016) can play a crucial role in better disaster resilience planning.
Given the increasing use of social media crowdsourcing and new VGI data sources such as Twitter, Wang et al. (2021) articulate that Twitter could be used to monitor people’s responses at different phases of disasters to better understand resilience. They examined the relationship between Twitter usage and community resilience during Hurricane Isaac in 2012. They found significant positive correlations between Twitter usage density and resilience indicators, confirming that communities with higher resilience characterized by better social-ecological conditions tend to have higher Twitter usage. Resch et al. (2018) argue that classical disaster management methods have shortcomings in temporal and spatial resolution, and this can be improved by generating a new and unseen layer of information in near real-time using social media data. The proposed approach uses LDA for semantic information extraction combined with spatial and temporal analysis for hotspot detection.
Moreover, Fan et al. (2020) argue that social sensing complements physical sensing techniques to improve situational awareness of disturbances in the built environment and that effective and efficient disaster response and recovery requires reliable situational awareness of infrastructure disturbances and their social impacts. They proposed an integrated Textual-Visual-Geo framework for situational awareness using Twitter data. They used a graph-based approach to detect critical tweets, an image ranking algorithm based on the number of retweets, text content to select important images, and kernel density estimation to estimate the geographic extent of the disruption in the case of Houston during Hurricane Harvey in 2017.
In the context of social media data analysis during disasters in Germany, Fathi et al. (2020) introduced Virtual Operations Support Teams (VOSTs) as a new team for organizing intelligence-gathering effort recently established by the German Federal Agency for Technical Relief (THW). Their role is to improve situational awareness among decision-makers in disaster response. Their study analyzed the structural, procedural, and technical requirements of VOSTs for joint operations with emergency management agencies in terms of social media monitoring, information verification, and crisis mapping in practice. Netzel et al. (2021) analyzed Twitter communication about heavy precipitation events to improve future risk communication and disaster preparedness in Germany. The study was carried out from February 2019 until August 2019 and examined the time series, networks, and content of tweets regarding pluvial flooding. They found that warnings originating from established stakeholders were the most common type of message and emphasized that the role of these actors is crucial for continuous communication.
Furthermore, Gründer-Fahrer et al. (Gründer-Fahrer et al., 2018) analyzed topics and topical phases in German social media (Twitter and Facebook) communication during the flooding of 2013. They analyzed German social media communication’s thematic and temporal structure using LDA Topic Modeling, sentiment analysis, and temporal clustering. Their findings revealed that Facebook content focuses on empathy and emotion. In contrast, Twitter is mainly used to share current and concrete information about the event and takes a more objective view of the event.
Although the above studies highlight the importance of using social media platforms and data for disaster management and communication, there is a shortage of studies that analyzes and leverages communities’ collective knowledge to inform disaster resilience capacities.
2021 floods in Germany
EM-DAT, the International Disaster Database, ranked the July 2021 flood in Germany as the 10th deadliest in Europe in the last 100 years (“EM-DAT,” 2022). Shown in Fig. 2, a slow-moving large summer storm system named ‘Bernd’, whose size and moisture are attributed to climate change, resulted in high rainfall amounts -up to 150–200 mm within 48 h and corresponding runoff peaks (Junghänel et al., 2021).

Torrential rains caused catastrophic flooding in Germany (especially in the western states) from July 12 to 18, 2021; Source: modified from (Junghänel et al., 2021)
Although the affected federal states were Baden-Wuerttemberg, Bavaria, Hesse, North Rhine-Westphalia, Rhineland-Palatinate, Saxony, Saxony-Anhalt, and Thuringia, the worst flooding occurred in the western states of Rhineland-Palatinate and North Rhine-Westphalia on the evening of July 14, and in Saxony and Bavaria in the south on July 17(“EM-DAT,” 2022; Fekete & Sandholz, 2021). On July 12, 2021, the European Flood Awareness System (EFAS) issued an extreme flood warning for Germany and Belgium and updated the weather situation in the following days. EFAS shares the information with national authorities responsible for disaster preparedness and response. These then forward the information and ensure the necessary measures are taken (European Parliament, 2021).
While riverine flooding is more common and minor pluvial flooding has occurred more frequently in recent years, pluvial flood damage on this scale was unusual. Most importantly, the high death toll was a surprise and a shock in an industrialized country that had never experienced such a high death toll and damage. Therefore, similar to other flood disasters in other countries, a public debate about responsibility and blame soon began, and crisis management came under criticism from the media and the public (Fekete, 2021). Following the constitution, which gives states the authority to enact laws relating to disaster crisis management, states enact their own laws. The various state laws thus result in differences among the states in command and control, training, and equipment (BMI, 2012). Against this backdrop, and to create better situational awareness, distributed problem-solving, and collective knowledge of capacities and issues related to the 2021 flood disaster, the following section explains the study approach to incorporate Twitter data and online surveys into the study of community resilience.
Data and methods
The data in this study was collected through two sources: Twitter, Germany, from July 12 to 31, 2021, and an online survey conducted from September 1 to 21, 2021. Figure 3 illustrates an overview of the data collection process, pre-processing and analysis methods described in the following sub-sections.

Methodological workflow
Twitter data collection and processing
Tweet collection
First, using the academic API (application programming interface) of the Twitter platform, we mined German social media (Germany as the predefined area) data from July 12 to the end of July 2021. To extract meaningful data on disaster-related tweets, we considered the hashtags listed in Table 1 before, during, and after the flood event. Each tweet includes the date of creation, the content, the username, and possibly geolocation information such as coordinates and locations of the tweet. The timing of the tweet was used to divide the data into pre-event/preparation (July 12–13, 2021), real-time event/immediate response (July 14–17, 2021), and post-event/short-term recovery (July 18–31, 2021) phases. To determine the location of the tweet, we queried “geo” (indicating the location the user tagged in the tweet if they provided one) and also “geo.place_id” (if present, this indicates that the tweet is associated with a location) (Laylavi et al., 2016; “Twitter Developer Platform,” 2022). A total of 6640 tweets were retrieved, of which 1810 were geo-referenced.
Twitter data pre-processing
We pre-processed the entire corpus from the data mining phase after deleting duplicates and translating (4842 tweets and 1729 geo-referenced tweets remained). Pre-processing is necessary to remove noisy data, increase data quality, and improve keyword generation and analysis results (Resch et al., 2018). The raw texts were cleaned by transforming the data (removing punctuation, emails, URL links, numbers, and emojis, and converting the text to lowercase), normalizing (using lemmatization, which creates the root form of inflected words), and filtering (deleting stop words such as ‘the’, ‘on’, etc.). N-grams (bi-gram and tri-gram) were used to find frequently occurring words in the document. Term frequency-inverse document frequency (TF-IDF) was used to assign a weight to each word based on word frequency to balance the importance of the word in the tweets and the corpus. The cleaned tweets were tokenized to convert them into words for further analysis (Zhou et al., 2021).
Spatial and temporal distribution of tweets
Human reactions, such as the frequency of communication on social media, are dynamic based on disruption situations. A burst in the frequency of tweets may indicate a change in the situation or a significant impact of the disruption on people (Fan et al., 2020). Since each tweet is associated with the time of its creation, we calculated the hourly volume of tweets (frequency of tweet activity). This can show whether the temporality of tweets correlates with the flooding situation’s dynamics.
Although people rarely disclose their location on public platforms, every tweet is associated with a location. The distribution of geolocated or geo-tagged tweets can estimate the locations and extent of disturbances and provide location information. The more geo-tagged tweets posted at the same location, the greater the damage and the stronger the impact of the disruption (Fan et al., 2020; Kryvasheyeu et al., 2016). To estimate the extent of the disturbance based on the spatial distribution and density of tweets, we performed Kernel Density Estimation (KDE) approach through the heatmap analysis tool in QGIS 3.24.2. Based on the method proposed by (Rizzatti et al., 2020), we calculated the search radius for obtained tweets before, during, and after the event. In each case, we applied KDE with a radius of 136, 140, and 151 km and a pixel size of 500 m. Then, the quartic Kernel function was chosen, as it is characterized by giving more weight to points closer than those further away. The heat map was finally created, which is shown in the next section.
Semantic (textual) information extraction from Twitter data
Topic Modeling is one of the most powerful techniques in text mining, discovering latent data, and finding relationships between data and text documents, in which LDA is one of the most popular in this field (Jelodar et al., 2019). LDA is a generative probabilistic model based on the concept that a set of sentences or documents contains certain topics. A topic refers to a group of words with similar or closely related meanings under certain probabilities. If the author of the document (tweet) is a person, these topics reflect the perspective and vocabulary of that person. Therefore, in this study, LDA was applied to the final set of cleaned tweets using the Gensim library to analyze the unstructured textual information from the tweets and identify the flooding-related topics before, during, and after the floodings.
LDA models document D as a mixture of K latent topics, and each topic describes a multinomial distribution over a W word (Huang et al., 2018). Equation 1 shows how the probability of a corpus is obtained (Blei et al., 2003).
Figure 4 represents the graphical model of the LDA. The outer box indicates the documents, while the inner box represents the repeated selection of topics and words within a document.

Graphical model representation of LDA; Source: (Blei, et al., 2003)
For validation of the model and to provide a convenient way to measure how good a particular topic model is, the perplexity and coherence measures are applied. The perplexity score is intuitively based on the degree of surprise a trained model experiences when confronted with unfamiliar documents after the learning phase. Lower perplexity indicates a better generalization ability of the model (Blei et al., 2003). On the other hand, the coherence value reflects the correspondence between numerical scores and users’ perception of the quality of topic models (Mimno et al., 2011). The higher the topic coherence, the more interpretable the topic is to humans (Gründer-Fahrer et al., 2018).
Finally, pyLDAvis was used to visualize the results, which was developed to help users interpret the topics in a topic model fitted to a textual corpus of data in an interactive web-based visualization (Sievert & Shirley, 2014). Compared to traditional clustering techniques, where each tweet can only belong to a single topic, an advantage of pyLDAvis is that a word can be clustered to different topics. For example, the word ‘water-level’ may appear in a context related to situational information or emergency operation. In this case, it can better represent the nature of the language (Sievert & Shirley, 2014; Zhou et al., 2021). The topics extracted from the LDA model reflect the different aspects of the event (Huang et al., 2018; Zhou et al., 2021) from a crowds perspective. Thus, we examined the composition of words in these automatically generated topics for each phase and manually assigned semantic labels in light of the authors’ domain knowledge and their consensus (Gründer-Fahrer et al., 2018).
Online survey data collection and processing
The second data source used in this study was an online survey conducted by (Fekete, 2021) to better understand the insights and perceptions of disaster responders involved in 2021 flooding regarding flood crisis management issues and capacities. The online survey allows for open and broad participation while maintaining anonymity on such sensitive topics where organizations have limitations in sharing information. Other advantages of online surveys include independence from respondents’ local availability and time and cost savings (Nimrod, 2014). The online survey was conducted using the SoSciSurvey online tool and was divided into 31 questions, including 24 closed questions and seven open questions, with 2264 participants. The preliminary analysis of the survey was published by (Fekete, 2021). However, in this study, an in-depth analysis of the open-response texts is conducted to potentially uncover additional themes, suggestions, concerns, positive experiences, and areas for improvement by capturing direct open opinions and expressions. 911 respondents used the open response fields, and 37,400 words of text (approximately 94 pages) were collected. For analysis, each question’s text was considered a separate corpus. After pre-processing and cleaning the data, the LDA method for Topic Modeling was used and visualized by word cloud.
The analyzed data from these two sources, Twitter and the online survey, were ultimately compiled to reflect the wisdom of crowds and collective intelligence regarding flood resilience, which is discussed in more detail in the following section.
Results
Spatio-temporal characteristics of the flood-related tweets
By examining the spatio-temporal distribution of posts on social media, we can get an overview of citizen behavior and reactions to a disaster event. Figure 5 shows the temporal pattern of flood-related tweets in different disaster phases. Despite the extreme flood warnings issued by the EFAS as well as the extreme rainfall warnings announced by the German Weather Service (DWD) for the eastern and southern federal states on television and radio from July 12, only a few tweets were posted on the subject of flooding before July 14. Nevertheless, the spatial distribution of flood-related tweets shows that most tweets originated from these regions (see Fig. 6).

Hourly volume of flood-related tweets from 12 to July 31, 2021

Spatial distribution of flood-related tweets (Kernel density) in Germany at the state level (the more reddish the color, the higher the density of tweets)
Between July 14 and 17 (during the disaster), the number of tweets increased dramatically, showing four peaks, with the first peak occurring between 12:00 and 20:00 on July 14, the second starting at 3:00 on July 15, the third starting between 7:00 and 21:00 on July 16, and the last peak occurring between 17:00 and 20:00 on July 17. The heavy rainfall on July 14 and 15 caused enormous flash floods (evening of July 14 to the early morning of July 15) with water levels up to more than eight meters in parts of North Rhine-Westphalia (NW) and Rhineland-Palatinate (RP). In RP, the districts of Ahrweiler and Trier-Saarburg were severely affected. Indeed, the “flood on the Ahr” shaped the “media memory” (Broemme, 2022). On July 16, for an extended period during the day from 8:00 to 20:00, tweets about the flood were posted reflecting the adverse effects of the flood and the significant impact of the disruption on people, roads, transportation, infrastructure, etc. Finally, the last peak occurred on July 17, indicating another flood in southern Bavaria (BY). Several roads in the region were closed, and train traffic was partially disrupted. From July 18 (after the disaster), the temporal pattern of tweets remained the same for about 5 days. But as time passed, the number of tweets about the flooding gradually decreased until the end of the month.
From the hotpot map in Fig. 6, it can be seen that most tweets in the pre-event phase were posted from NW, BY, BW, and then RP and Berlin (BB) about weather conditions and heavy rain warnings. In the real-time flooding phase, the highest density of tweets can be seen in NW and RP, as these areas were the most affected. In the post-event phase, it can be seen that the kernel density pattern expands to BY and BB, showing the impact of flooding in the south and also in the capital city with increasing the number of corresponding tweets. Although BB was slightly affected by the pluvial flooding, tweets were mainly about humanitarian aid, risk governance, and climate adaptation (see Sect. ”Post-event Topic Modeling”).
Content (textual) analysis of social media and online survey
After pre-processing the relevant tweets in the three disaster phases (pre-event, real-time, and post-event (short-term), LDA was used to analyze the content of tweets in these periods, as it can be assumed that users send different categories of messages in the different disaster phases. LDA was also applied to the survey results indicated in the following subsections.
Pre-event topic modeling
In the pre-event phase (July 12–13), the optimal number of latent topics (k) based on perplexity (-6.43) and coherence (0.41) scores was 10. The most frequent terms were ‘storm’, ‘heavy rain’, ‘climate crisis’, ‘rain’, ‘warn’, ‘fire-brigade’, ‘flood’, ‘extreme’, ‘weather’, ‘summer’, ‘ready’. The generated topics were visualized with pyLDAvis (Fig. 7). Each bubble on the left side of the diagram represents a topic. The larger the bubble, the more prevalent the topic. A good topic model will have fairly large, non-overlapping bubbles scattered across the diagram rather than concentrated in one quadrant. By hovering over one of the bubbles, the words and bars on the right side are updated. These words are the salient keywords that make up the selected topic. For example, the selected topic in Fig. 7 is Topic 1, represented by the words on the right side of the figure.

An example of visualization of Topic clusters and top 30 words for Topic 1, pre-event phase
The top 10 keywords contributing to this phase in different topics were 0.043*”flood” + 0.034*”storm” + 0.018*”rain” + 0.018*”fire_brigade” + ’’0.018*”extreme” + 0.018*”weather” + 0.018*”warn” + 0.009*”continuous-rain” + ’’0.009*”want” + 0.009*”severe”‘, where the weight reflects how important a keyword is to this theme. Using these keywords in each topic, we identified the thematic topics and began coding. Accordingly, Table 2 shows the most representative topics, including warning, early action, protective measures, event tracking, climate change-oriented information, disbelief in flood probability, and local emergency preparedness.
Real-time event topic modeling
The period between July 14 and 17 was considered the real-time event phase for the states of NW and RP. As shown in Sect. ”Spatio-temporal characteristics of the flood-related tweets”, the temporal analysis revealed a large number of tweets related to the flood event, with a high level of posting activity compared to the other two time periods. The spatial pattern also showed that most tweets originated from the affected states. This highlights a significant temporal correlation between flood occurrence and social media activity, implying that situational information about the disruptions tends to be generated by locals and nearby communities affected by the disruptions.
LDA analysis for this phase was conducted with the optimal number of latent topics (30) based on perplexity (-7.87) and coherence (0.45) scores. The top 10 keywords contributing to this phase from different topics were 0.211*”help” + 0.245*”climate-change” + 0.151*”flood_disaster” + 0.132*”donate” + 0.127*”flood” + 0.137*”water-level” + 0.129*”catastrophe” + 0.091*”people” + 0.082*”need” + 0.080*”infrastructure”.
Table 3 shows the most relevant labeled themes extracted from these 30 clusters by analyzing the keywords in each topic. The themes are oriented around warning systems, situational information, communication with fellows, disaster mortality, affected people and their assets, damage to infrastructure, essential services and facilities, cascading effects or compounding risks, rescue, and relief oriented, humanitarian aid, donation and campaigns, sentiments, critique to politicians, and preventive measures.
Post-event topic modeling
This study considers the period between July 18 and 31, the short-term post-event phase. Temporal analysis in Fig. 5 shows that the tweet activity pattern remained the same for about five days, and the number of tweets about the flooding gradually decreased by the end of the month. According to spatial analysis, most tweets are generated from two states, NW and BY.
LDA analysis for this phase was conducted with the optimal number of latent topics (30) based on perplexity (-8.28) and coherence (0.51) scores. The top 10 keywords contributing to this phase from different topics were 0.235*”flood-disaster” + 0.161*”today” + 0.132*”climate-change” + 0.129*”help” + 0.122*”donate” + 0.112*”fire-brigade” + 0.100*”helper” + 0.091*”home” + 0.089*”death” + 0.081*”old”.
Table 4 shows the most relevant labeled themes extracted from these 30 clusters. The topics are oriented around crowdfunding and humanitarian assistance, social and financial support, sentiments for victims, needed utilities and services, infrastructure reconstruction, emergency management, information and communication, lack of security and appreciation of helpers, environmental change, etc. The data-driven topics show community discussions about socio-political and climate-related causes, collecting donations, on-the-ground assistance, information provision, and communication, as well as suggestion to improve risk governance through climate policymaking and organizational innovations.
Online survey topic modeling
LDA analysis was also performed for the survey. Considering the perplexity and coherence measures presented in Table 5, the optimal number of latent topics for each corpus (survey questions) happened to be K = 3. According to Fekete (2021), although operational organizations and responders (the group surveyed) are on the front lines of crisis management, few studies addressed their perceptions of problems and capacities. Table 5, therefore, reflects their critical point of view within the open-ended questions. Instead of the pyLDAvis visualization, presentation of the results in this section is based on the 10 contributing terms and their weights listed in Table 5.
In addition, Fig. 8 shows a visual representation of the word cloud for each survey question, highlighting the most frequently used words. This visual representation helps identify the predominant themes and issues.

Word cloud of survey questions
Discussion
Spatiotemporal and semantic characteristics of the flood-related tweets
Human reactions, such as the frequency of communication on social media, are dynamic in response to disruptive events. A spike in the number of tweets may indicate a change in the situation or a significant impact of the disruption on people (Fan et al., 2020). In this study, the spatio-temporal observations are also consistent with the results of previous studies and official reports of the July 2021 floods. These results build on existing evidence that Twitter metadata reflect actual spatiotemporal events related to flooding and that the high density of georeferenced flood-related posts on social media is consistent with actual affected areas. The spatiotemporal pattern of social media use during disasters shows that users in affected areas tend to post more information on social media compared to unaffected users. This can provide localized and near-real-time information about evolving disaster situations for decision makers and residents (Mostafavi et al., 2017). In addition, the burst of tweets can help detect such events in near real-time, such as the detection of flooding in BY (the fifth temporal peak in Fig. 5), which was underreported in the news.
In terms of semantic analysis, the pre-event topics can reflect on anticipatory and preventive capacities. For example, Fig. 5 shows insufficient tweets, and Topic Modeling shows disbelief in the likelihood of flooding. This indicates that early warning systems have not used multiple/social media channels or that there is a lack of transparent risk communication. However, in terms of prevention capacity, the topic of “predicting local situations and learning from past events” shows that people who have learned from past experiences try to protect their assets and inform their peers. In the real-time phase, when people expect the disaster’s effects, there is great uncertainty, and their emotional state is generally very vague (Gründer-Fahrer et al., 2018). The impact of the event often causes a shock at first and may paralyze people for a short time. After that, the heroic phase usually begins, characterized by high activity and altruism (Math et al., 2015). Most of these insights can reflect on absorptive capacity by providing evidence to improve risk monitoring and situational awareness for a better response and relief operation during such events.
After the event has passed and short-term recovery has begun, people typically experience a highly emotional honeymoon phase in which strong communal compassion and cohesion are observed, and people band together to solve problems (Gründer-Fahrer et al., 2018). There may be interruptions and relapses. Depending on the extent of the recurring threat, the new impact, or other events, it takes two to eight weeks (Math et al., 2015). After a disaster, people are often motivated to discover why an event occurred, who or what is responsible (or to blame), and how to prevent it from happening again. These discussions of socio-political and scientific causes can contribute to community strengthening and resilience (Houston et al., 2014). The data-driven topics show community discussions about socio-political and climate-related causes, collecting donations, on-the-ground assistance, information provision, and communication, as well as suggestion for adaptive and transformative measures to improve risk governance through climate policymaking and organizational innovations.
Topic Modeling of responders’ answers, with their high motivation, critical attitude, and high expectations for the functioning of the administration and coordination systems, highlighted the need to improve the communication system, the timely and clear transmission of information, and better coordination and management. On the other hand, they emphasized the necessity to improve knowledge about disasters to enable better disaster preparedness and planning. This requires the involvement of all levels, local people (individuals) and stakeholders (organizations), as well as state and federal governments (institutions), to achieve mutual understanding in such situations. In the following section, the extracted topics are complied to inform disaster resilience resulting form our bottom-up processing.
Compilation of extracted topics from Twitter and online survey in the context of resilience capacities
In this section, in-depth analysis of the two data sources led us to compile extracted topics under the five overarching resilience capacities (preventive, anticipative, absorptive, adaptive, and transformative) (Manyena et al., 2019) to reflect people’s collective insights, experiences, and opinions related to flood disaster for improved disaster resilience in general. This sensing approach provides localized knowledge and information for disaster resilience initiatives to develop practical solutions, that reflect the community’s place-based needs and capacities. Figure 9 thus reflects the collective opinion on flood-related issues and capacities categorized under the above mentioned resilience capacities.

Compiling social media and online survey topics under resilience capacities themes toward resilient community development in Germany
The findings underscore the need for multi-level and cross-sectoral planning and education to reduce disaster risk. Sustainable and risk-sensitive land use planning, such as the location of wind farms and the ratio of the sealed area upstream of the flood-prone zone, is emphasized. Critical infrastructure robustness was under criticism due to massive damage to water, power, and transportation systems. Based on the results, the redundancy of communication networks and communication channels should be considered to tackle problems imposed by power outages and interruptions in Internet connectivity. Response capabilities in uncertain and time-critical situations should be improved through disaster-related training and coordinated mobilization of resources. On the other hand, community-level preparedness is emphasized, such as the importance of insurance against flood hazards, which shows the community’s willingness and knowledge to take action.
Collective knowledge to improve anticipatory capacity emphasized the need for foresight and timely recognition of threats, consideration of uncertainties, the establishment of effective early warning systems using multi-level and multichannel communication, training decision makers and communities on uncertainties, and improving their disaster-related knowledge and skills. In addition, the problem of disbelief in the likelihood of flooding and lack of preparedness for unforeseen events indicates that further study is urgently needed on how such risks should be assessed and communicated at all decision-making levels to avoid such disasters in the future.
To improve absorptive capacity and reduce the number of affected people and assets, the collective insights point to the need for practical collaboration among organizations, volunteers, and affected populations based on an established mutual understanding; and better coordination and management of resources and human capital in disaster response. Moreover, the findings show the criticism of site selection for critical services such as health centers, which should not be located in flood-prone areas. However, the results show that social cohesion and community solidarity, as well as high levels of humanitarian assistance and crowdfunding, which are important indicators of socioeconomic resilience, were positively evaluated by people.
In improving adaptive capacity, people addressed the need for socio-egological adaptations to climate change impacts, such as soil erosion control, environmental and cultural heritage protection, and better ecosystem monitoring. They emphasized the need for government investment in socioeconomic security, capacity building, and empowerment of local authorities (municipalities) and communities to have active decision-making roles in emergencies. They also emphasized the need for education and training in response and recovery skills for all groups and practical tools for better risk communication in a transparent, clear, and continuous format. The emphasis on flood insurance penetration indicates that people are socioculturally aware of the insurance gap, and therefore strategies should be developed to insure more people exposed to flood risk.
To improve absorptive capacity and reduce the number of affected people and assets, the collective insights point to the need for practical collaboration among organizations, volunteers, and affected populations based on an established mutual understanding; and better coordination and management of resources and human capital in disaster response. Moreover, the findings show the criticism of site selection for critical services such as health centers, which should not be located in flood-prone areas. However, the results show that social cohesion and community solidarity, as well as high levels of humanitarian assistance and crowdfunding, which are important indicators of socioeconomic resilience, were positively evaluated by people.
In improving adaptive capacity, people addressed the need for socio-egological adaptations to climate change impacts, such as soil erosion control, environmental and cultural heritage protection, and better ecosystem monitoring. They emphasized the need for government investment in socioeconomic security, capacity building, and empowering local authorities (municipalities) and communities to take active decision-making role in emergencies. They also emphasized the need for education and training in response and recovery skills for all groups and practical tools for better risk communication in a transparent, clear, and continuous format. The emphasis on flood insurance penetration indicates that people are socioculturally aware of the insurance gap, and therefore strategies should be developed to insure more people who are at risk of flooding.
For transformational resilience, the public reaction and sentiment toward the government’s approaches reflect the need to incorporate new climate-related policies, investments in advanced technologies and infrastructure modernization, and new platforms and innovative municipal early warning systems to improve resilience. In addition, it has been highlighted that local governments should be equipped with an effective coordination mechanism in disaster management that allows for multi-level collaboration and flexible decision-making processes in time-critical situations. The wisdom of the crowds also reflects the importance of new social norms and values that lead to long-term behavioral changes to reduce the impacts of climate change, indicating the contributors’ exemplary climate-related knowledge. Finally, the result shows that individuals and communities supported self-organized peer-to-peer relief efforts using their capacities and resources. Better information flow, therefore, results in increased self-organization among the population affected by disasters.
This in-depth contextual analysis, along with the temporal and spatial proximity of social media posts and the online survey, allows disaster management agencies to hear from the public and build resilience capacity based on the collective sociocultural characteristics of the community. Moreover, this bottom-up and web-based approach could be a near real-time alternative or complement traditional participatory methods and techniques of organizing interviews, meetings, and workshops for situational analysis and unfolding of such events that usually last months.
Key challenges and future research
Any research approach faces challenges and is subject to certain limitations that are difficult to overcome. It is well known that social media and online surveys are not representative of the entire population. Issues such as unequal access to web-based tools (e.g., technology, skills, education), digital disengagement, and trust and privacy concerns could pose challenges in such studies. However, the rapid advances in technology, society, and digital innovation as influential drivers can provide opportunities to develop shared and collaborative platforms that all can use with different levels of education, knowledge, and skills.
Moreover, while LDA is one of the best and most widely used algorithms for topic modeling, processing its results can be challenging. Labeling the results requires a high level of expertise and is labor-intensive and time-consuming. This should be addressed in future work to facilitate practitioners and researchers in the timely use of such large datasets in decision-making processes.
Based on our research goal to obtain collective knowledge, the spatiotemporal analysis of tweets was limited to the country level due to the dramatic flooding across the country. However, according to the German constitution, which grants the states the authority to enact emergency management laws, there are differences among the states regarding leadership, training, and types of equipment. Therefore, future studies could analyze the tweets with state boundaries and compare the results with this study.
Monitoring and assessing climate resilience at multiple temporal and spatial scales is key to developing proactive management strategies to address climate change. One of the major challenges in measuring disaster resilience is the inclusion of soft sociocultural factors. This study demonstrates the potential of crowdsourcing data as a rich data source for these attributes such as community solidarity, learning from the past, social cohesion, and experience. Thus, further studies are needed to enable the integration of these into the measurement and monitoring of resilience dynamics.
Conclusion
As extreme events induced by climate change will continue to increase in frequency and severity, we should harness the power of today’s web-based communication culture to enable the timely sharing of disaster-related information, situational awareness, and unfolding of unforeseen situations. Since the July 2021 flood disaster in Germany became a tipping point for questioning community vulnerability and risk governance and practices in the face of an unexpected event, this study, analyzed two data sources, Twitter data (passive crowdsourced data) and an online survey of responders involved in the relief effort, to explore the wisdom of the crowds on that. To this end, we used the LDA method for Topic Modeling for text analysis and coded collective insights at near-real-time of flooding. In addition to semantic analysis, spatiotemporal patterns of online disaster communication were analyzed to determine the contribution patterns associated with the affected areas.
The findings provide an evidence-based and bottom-up approach to disaster resilience by optimizing the diversity and spectrum of experience and knowledge of contributors with different backgrounds on flood resilience and reflecting their sociocultural characteristics. Based on the findings of this study, to improve flood resilience, preventive and anticipatory resilience strategies such as adopting sustainable pathways (e.g., risk-sensitive land use planning and climate-resilient housing and infrastructure) and effective risk governance considering uncertainties (e.g. clear risk communication and multi-level early warning system) should be strengthened. This requires co-design and multi-level collaboration with a shared resilience vision. In addition, adaptation to the changing environment (e.g., empowering local governments and communities and market penetration of flood insurance) and achieving transformation (embedding new climate-related policies and social norms) should be promoted based on new norms, values, and flexible structures in risk thinking and governance. This needs improved risk knowledge at multiple levels, collaborative learning processes, and leveraging innovative tools and new data sources that lead to improved disaster resilience.
Passive crowdsourcing combined with online surveys as a bottom-up approach provides a more timely and cost-effective alternative to other participatory techniques, such as organizing meetings and workshops to analyze situations and unfold such events, and enables the participation of citizens who are not otherwise involved in scientific or administrative activities. This approach can also help capture soft sociocultural factors such as the extent of community solidarity or community readiness for climate-related policies. Considering collective insights, perceptions, and expectations as part of the decision-making process helps identify short-term priorities for action and ultimately develop place-based disaster resilience strategies based on the community’s medium- to long-term needs and capacities. Finally, as part of such bottom-up processes, we should be mindful of issues such as the digital divide, local disparities, and digital disengagement.
References
Asadzadeh, A., Koetter, T., Fekete, A., Moghadas, M., Alizadeh, M., Zebardast, E., & Basirat, M. (2022). Urbanization, migration, and the challenges of resilience thinking in urban planning: Insights from two contrasting planning systems in Germany and Iran. Cities, 125, 103642. https://doi.org/10.1016/j.cities.2022.103642
Asadzadeh, A., Kötter, T., & Zebardast, E. (2015). An augmented approach for measurement of disaster resilience using connective factor analysis and analytic network process (F’ANP) model. International Journal of Disaster Risk Reduction, 14, 504–518. https://doi.org/10.1016/j.ijdrr.2015.10.002
Assarkhaniki, Z., Rajabifard, A., & Sabri, S. (2020). The conceptualisation of resilience dimensions and comprehensive quantification of the associated indicators: A systematic approach. International Journal of Disaster Risk Reduction, 51, 101840. https://doi.org/10.1016/J.IJDRR.2020.101840
Béné, C., Wood, R. G., Newsham, A., & Davies, M. (2012). Resilience: New Utopia or New Tyranny? Reflection about the potentials and limits of the concept of resilience in relation to vulnerability reduction programmes. IDS Working Papers, 2012(405), 1–61. https://doi.org/10.1111/j.2040-0209.2012.00405.x
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022.
BMI. (2012). German Federal Ministry of the Interior, The Crisis Management System in Germany. Retrieved November 25, 2022, from https://www.bmi.bund.de/SharedDocs/downloads/EN/publikationen/2012/system_krisenmanagement_en.pdf?__blob=publicationFile
Broemme, A. (2022). Severe weather events: Strategies for Rhineland-Palatinate for prevention, preparation, coordination, follow-up and for improved resilience. Retrieved on November 26, 2022, from https://www.landtag.nrw.de/portal/WWW/dokumentenarchiv/Dokument/MMV17-6729.pdf
Cutter, S. L. (2016). The landscape of disaster resilience indicators in the USA. Natural Hazards, 80(2), 741–758. https://doi.org/10.1007/s11069-015-1993-2
Cutter, S. L., Barnes, L., Berry, M., Burton, C., Evans, E., Tate, E., & Webb, J. (2008). A place-based model for understanding community resilience to natural disasters. Global Environmental Change, 18(4), 598–606. https://doi.org/10.1016/j.gloenvcha.2008.07.013
Degrossi, L., Albuquerque, J. P. De, & Fortes, R. P. (2019a). An approach for assessing the quality of crowdsourced geographic information in the flood management domain.
Elwood, S., Goodchild, M. F., & Sui, D. Z. (2012). Researching volunteered geographic information: Spatial data, geographic research, and new social practice. Annals of the Association of American Geographers, 102(3), 571–590. https://doi.org/10.1080/00045608.2011.595657
EM-DAT. (2022a). Retrieved April 21, 2022a, from https://public.emdat.be/data
Fan, C., Jiang, Y., & Mostafavi, A. (2020). Social sensing in disaster city digital Twin: Integrated Textual–Visual–Geo Framework for situational awareness during built environment disruptions. Journal of Management in Engineering, 36(3), 04020002. https://doi.org/10.1061/(asce)me.1943-5479.0000745
Fathi, R., Thom, D., Koch, S., Ertl, T., & Fiedrich, F. (2020). VOST: A case study in voluntary digital participation for collaborative emergency management. Information Processing and Management, 57(4), 102174. https://doi.org/10.1016/j.ipm.2019.102174
Fekete, A., Asadzadeh, A., Ghafory-Ashtiany, M., Amini-Hosseini, K., Hetkämper, C., Moghadas, M., & Kötter, T. (2020a). Pathways for advancing integrative disaster risk and resilience management in Iran: Needs, challenges and opportunities. International Journal of Disaster Risk Reduction, 49, 101635. https://doi.org/10.1016/j.ijdrr.2020.101635
Fekete, A. (2021). Motivation, satisfaction, and risks of operational forces and helpers regarding the 2021a and 2013 flood operations in Germany. Sustainability, 13, 12587. https://doi.org/10.3390/su132212587
Fekete, A., & Sandholz, S. (2021). Here comes the flood, but not failure? Lessons to learn after the heavy rain and pluvial floods in Germany 2021b. Water, 13, 3016. https://doi.org/10.3390/w132130161
Fekete, A., & Rhyner, J. (2020). Sustainable digital transformation of disaster risk—integrating new types of digital social vulnerability and interdependencies with critical infrastructure. Sustainability, 12(22), 1–18. https://doi.org/10.3390/su12229324
Feldmeyer, D., Wilden, D., Jamshed, A., & Birkmann, J. (2020). Regional climate resilience index: A novel multimethod comparative approach for indicator development, empirical validation and implementation. Ecological Indicators, 119, 106861. https://doi.org/10.1016/J.ECOLIND.2020.106861
Ghermandi, A., & Sinclair, M. (2019). Passive crowdsourcing of social media in environmental research: A systematic map. Global Environmental Change, 55, 36–47. https://doi.org/10.1016/J.GLOENVCHA.2019.02.003
Gründer-Fahrer, S., Schlaf, A., Wiedemann, G., & Heyer, G. (2018). Topics and topical phases in German social media communication during a disaster. Natural Language Engineering, 24(2), 221–264. https://doi.org/10.1017/S1351324918000025
Haklay, M. (2013). Citizen science and volunteered geographic information: overview and typology of participation. In D. Sui, S. Elwood, & M. Goodchild (Eds.), Crowdsourcing geographic knowledge: volunteered geographic information (VGI) in Theory and Practice (pp. 105–122). Springer Netherlands. https://doi.org/10.1007/978-94-007-4587-2_7
Houston, J. B., Hawthorne, J., Perreault, M. M. F., Park, E. H. E., Goldstein Hode, M., Halliwell, M. R. M., & Griffith, S. A. (2014). Social media and disasters: A functional framework for social media use in disaster planning, response, and research. Disasters, 39(1), 1–20. https://doi.org/10.1111/disa.12092
Howe, J. (2006). The rise of crowdsourcing. Wired Magazine, 14, 1–5. https://doi.org/10.2307/25599409
Huang, Y., Li, Y., & Shan, J. (2018). Spatial-temporal event detection from geo-tagged tweets. ISPRS International Journal of Geo-Information, 7(4), 150. https://doi.org/10.3390/ijgi7040150
IPCC. (2022). Retrieved June 19, 2022, from https://www.ipcc.ch/assessment-report/ar6/
Jelodar, H., Wang, Y., Yuan, C., Feng, X., Jiang, X., Li, Y., & Zhao, L. (2019). Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimedia Tools and Applications, 78(11), 15169–15211. https://doi.org/10.1007/s11042-018-6894-4
Junghänel, T., Bissolli, P., Daßler, J., Fleckenstein, R., Imbery, F., Janssen, W., Weigl, E. (2021). Hydro-klimatologische Einordnung der Stark-und Dauerniederschläge in Teilen Deutschlands im Zusammenhang mit dem Tiefdruckgebiet “Bernd” vom 12. bis 19. Juli 2021. DWD. Offenbach, Gerrmany.
Khazai, B., Bendimerad, F., Cardona, O.-D., Carreño, M. L., Barbat, H. A., & Christopher, G. B. (2015). A guide to measuring urban risk resilience: Principles, Tools and Practice of Urban Indicators. Retrieved from http://www.emi-megacities.org
Khazai, B., Anhorn, J., & Burton, C. G. (2018). Resilience Performance Scorecard: Measuring urban disaster resilience at multiple levels of geography with case study application to Lalitpur, Nepal. International Journal of Disaster Risk Reduction, 31(March), 604–616. https://doi.org/10.1016/j.ijdrr.2018.06.012
Kryvasheyeu, Y., Chen, H., Obradovich, N., Moro, E., Van Hentenryck, P., Fowler, J., & Cebrian, M. (2016). Rapid assessment of disaster damage using social media activity. Science Advances, 2(3), 64545.
Lamoureux, Z., & Fast, V. (2019). The tools of citizen science: An evaluation of map-based crowdsourcing platforms. CEUR Workshop Proceedings, 2323(4), 1. Retrieved from https://ceur-ws.org/Vol-2323/SKI-Canada-2019-7-4-1.pdf
Laylavi, F., Rajabifard, A., & Kalantari, M. (2016). A multi-element approach to location inference of Twitter: A case for emergency response. ISPRS International Journal of Geo-Information, 5(5), 1–16. https://doi.org/10.3390/ijgi5050056
Manyena, B., Machingura, F., & O’Keefe, P. (2019). Disaster Resilience integrated framework for transformation (DRIFT): A new approach to theorising and operationalising resilience. World Development, 123, 104587. https://doi.org/10.1016/j.worlddev.2019.06.011
Math, S., Nirmala, M., Moirangthem, S., & Kumar, N. (2015). Disaster management: Mental Health perspective. Indian Journal of Psychological Medicine, 37(3), 261. https://doi.org/10.4103/0253-7176.162915
Mimno, D., Wallach, H. M., Talley, E., Leenders, M., & Mccallum, A. (2011). Optimizing semantic coherence in topic models. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 11). Association for Computational Linguistics, pp. 262–272.
Moghadas, M., Asadzadeh, A., Vafeidis, A., Fekete, A., & Kötter, T. (2019b). A multi-criteria approach for assessing urban flood resilience in Tehran, Iran. International Journal of Disaster Risk Reduction, 35, 101069. https://doi.org/10.1016/j.ijdrr.2019.101069
Moghadas, M., Rajabifard, A., Fekete, A., & Kötter, T. (2022). A framework for scaling urban transformative resilience through utilizing volunteered geographic information. ISPRS International Journal of Geo-Information, 22, 114. https://doi.org/10.3390/ijgi11020114
Mostafavi, A., Ganapati, N. E., Nazarnia, H., Pradhananga, N., & Khanal, R. (2017). Adaptive capacity under chronic stressors: Assessment of Water Infrastructure Resilience in 2015 Nepalese earthquake using a system approach. Natural Hazards Review, 19(1), 05017006. https://doi.org/10.1061/(ASCE)NH.1527-6996.0000263
Muñoz, L., Hausner, V. H., Runge, C., Brown, G., & Daigle, R. (2020b). Using crowdsourced spatial data from Flickr vs PPGIS for understanding nature’s contribution to people in Southern Norway. People and Nature, 2(2), 437–449. https://doi.org/10.1002/PAN3.10083/SUPPINFO
Netzel, L., Heldt, S., & Denecke, M. (2021). Analyzing Twitter communication about heavy precipitation events to improve future risk communication and disaster reduction in Germany. Urban Water Journal, 18(5), 310–319. https://doi.org/10.1080/1573062X.2021.1878241
Nimrod, G. (2014). The benefits of and constraints to participation in seniors’ online communities. Leisure Studies, 33(3), 247–266. https://doi.org/10.1080/02614367.2012.697697
European Parliament. (2021). Lessons to be learned from the devastating floods in western and central Europe. Retrieved April 23, 2022, from https://www.europarl.europa.eu/doceo/document/P-9-2021-003686_EN.html
Rachunok, B., Bennett, J., Flage, R., & Nateghi, R. (2021). A path forward for leveraging social media to improve the study of community resilience. International Journal of Disaster Risk Reduction, 59, 102236. https://doi.org/10.1016/J.IJDRR.2021.102236
Rajabifard, A. (2020). Sustainable development goals connectivity dilemma: Land and geospatial information for Urban and Rural Resilience. CRC Press.
Rajabifard, A., Paez, D., & Foliente, G. (2021c). COVID-19 Pandemic, geospatial information, and community resilience: Global applications and lessons. CRC Press.
Resch, B., Summa, A., Zeile, P., & Strube, M. (2016). Citizen-centric urban planning through extracting emotion information from Twitter in an interdisciplinary space-time-linguistics algorithm. Urban Planning, 1(2), 114–127. https://doi.org/10.17645/up.v1i2.617
Resch, B., Usländer, F., & Havas, C. (2018). Combining machine-learning topic models and spatiotemporal analysis of social media data for disaster footprint and damage assessment. Cartography and Geographic Information Science, 45(4), 362–376. https://doi.org/10.1080/15230406.2017.1356242
Rizzatti, M., Lampert Batista, N., Leonardo, P., Spode, C., Bouvier Erthal, D., Mauro De Faria, R., & Quoos, J. H. (2020). Mapping COVID-19 through Kernel Density. Metodologias e Aprendizado, 3, 44–53. https://doi.org/10.21166/metapre.v3i0.1312
Rudra, K., Goyal, P., Ganguly, N., Imran, M., & Mitra, P. (2019). Summarizing situational tweets in crisis scenarios: An extractive-abstractive approach. IEEE Transactions on Computational Social Systems, 6(5), 981–993. https://doi.org/10.1109/TCSS.2019.2937899
Sievert, C., & Shirley, K. E. (2014). LDAvis: A method for visualizing and interpreting topics. In Proceedings ofthe Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, pp. 63–70.
Twitter Developer Platform. (2022b). Retrieved April 21, 2022b, from https://developer.twitter.com/en/docs/twitter-api/tweets/search/api-reference/get-tweets-search-recent
Tzavella, K., Skopeliti, A., & Fekete, A. (2022). Volunteered geographic information use in crisis, emergency and disaster management: A scoping review and a web atlas. Geo-Spatial Information Science. https://doi.org/10.1080/10095020.2022.2139642
UNDRR. (2022). UNDRR-Terminology. Retrieved May 3, 2022, from https://www.undrr.org/terminology#R
United Nations (2015b) Transforming our world: The 2030 Agenda for Sustainable Development. General Assembley 70 session. https://doi.org/10.1007/s13398-014-0173-7.2
United Nations. (2015). Sendai framework for disaster risk reduction 2015–2030. Switzerland.
Wang, K., Lam, N. S. N., Zou, L., & Mihunov, V. (2021d). Twitter use in hurricane isaac and its implications for disaster resilience. ISPRS International Journal of Geo-Information, 10(3), 116. https://doi.org/10.3390/ijgi10030116
Yabe, T., Rao, S. C. P., Ukkusuri, S. V., & Cutter, S. L. (2022c). Toward data-driven, dynamical complex systems approaches to disaster resilience. Proceedings of the National Academy of Sciences of the United States of America, 119(8), e2111997119. https://doi.org/10.1073/pnas.2111997119
Zhou, S., Kan, P., Huang, Q., & Silbernagel, J. (2021). A guided latent Dirichlet allocation approach to investigate real-time latent topics of Twitter data during Hurricane Laura. Journal of Information Science. https://doi.org/10.1177/01655515211007724
Ziegler, M. G. (2022). Web 2.0 and knowledge sharing. a literature review. AI, Computer Science and Robotics Technology, 2022, 1–14. https://doi.org/10.5772/ACRT.03
Funding
Open Access funding enabled and organized by Projekt DEAL. This research was funded by the German Federal Ministry of Education and Research (BMBF) grant number: 01DK20101C.
Author information
Authors and Affiliations
Contributions
Conceptualization, MM and AR; methodology, MM and AF; formal analysis, MM; investigation, MM, AF; resources, TK; data curation, MM; writing original draft preparation, MM; writing review and editing, MM, AF, AR, TK; visualization, MM; supervision, TK, AR, AF. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest regarding the submitted manuscript.
Human and animal rights
The research does not include human or animal subjects.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Moghadas, M., Fekete, A., Rajabifard, A. et al. The wisdom of crowds for improved disaster resilience: a near-real-time analysis of crowdsourced social media data on the 2021 flood in Germany. GeoJournal 88, 4215–4241 (2023). https://doi.org/10.1007/s10708-023-10858-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10708-023-10858-x