
Abstract
This work develops and estimates a three-factor term structure model with explicit sentiment factors in a period including the global financial crisis, where market confidence was said to erode considerably. It utilizes a large text data of real time, relatively high-frequency market news and takes account of the difficulties in incorporating market sentiment into the models. To the best of our knowledge, this is the first attempt to use this category of data in term-structure models. Although market sentiment or market confidence is often regarded as an important driver of asset markets, it is not explicitly incorporated in traditional empirical factor models for daily yield curve data because they are unobservable. To overcome this problem, we use a text mining approach to generate observable variables which are driven by otherwise unobservable sentiment factors. Then, applying the Monte Carlo filter as a filtering method in a state space Bayesian filtering approach, we estimate the dynamic stochastic structure of these latent factors from observable variables driven by these latent variables. As a result, the three-factor model with text mining is able to distinguish (1) a spread-steepening factor which is driven by pessimists’ view and explaining the spreads related to ultra-long term yields from (2) a spread-flattening factor which is driven by optimists’ view and influencing the long and medium term spreads. Also, the three-factor model with text mining has better fitting to the observed yields than the model without text mining. Moreover, we collect market participants’ views about specific spreads in the term structure and find that the movement of the identified sentiment factors are consistent with the market participants’ views, and thus market sentiment.













Similar content being viewed by others


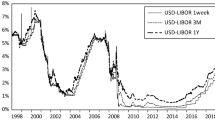
Notes
For example, from the beginning of the Global Financial Crisis, some policymakers at central banks clearly identified the importance of sentiment factors or market confidence on asset markets’ pricing and trading. See Nishimura (2008).
In a companion paper now in progress, Nishimura, Saito and Takahashi develop theoretical foundation of this empirical model based on the theory of fundamental uncertainty called Knightian uncertainty. See Nishimura and Ozaki (2017) for the formulation of pessimism and optimism under Knightian uncertainty.
In Japan, government bonds of maturity longer than 10 years are called “super-long term” bonds, while in other countries they are often called “ultra-long term” bonds. In the following, we use “ultra-long”, and put “super” in parentheses if necessary.
They argue their news sentiment factor is distinct from the three yield curve factors such as level, slope, and curvature as well as from fundamental macroeconomic variables. However, although the t-statistics values for the news sentiment factor’s coefficients look significant for the yields up to the 3–5 year maturities, the adjusted \(R^2\)s in their regression analyses are low: 0.02–0.17 with only the news sentiment factor as an explanatory variable, and 0.10–0.25 with macro variables (nonfarm payrolls, CPI, ISM Manufacturing Index) and the 10–2 year spread in addition to the news sentiment variable.
See “Appendix B.2” for a Quadratic-Gaussian model.
See, for example, Nakano et al. (2018) for the details.
See MeCab (2006) for the description of the software.
We have also examined one-word groups. It has turned out that one-word groups usually lack sufficient detail. So we use two-word groups.
See “Appendix C” for a new estimation method for trends and correlations in non-stationary noisy time series data.
There are attempts (for example, Rudebusch and Wu (2008)) in the macro-finance literature that try to explain dynamic factors in the term structure models by macro economic variables including monetary policy. However, the attempts are not very successful so far. The reason is that level, slope and curvature (volatility) components in the term structure of interest rates happen to be poorly correlated with macro variables in the first place. See Adrian (2017)).
Cox et al. (1985).
\(\alpha \in (0,0.5)\) gives asymptotic consistency for the SIML correlation estimator.
References
Adrian, T. (2017). The term structure of interest rates and macrofinancial dynamics. In Speech at Bank of Canada conference on advances in fixed income and macro-finance research, August 17, 2017.
Bain, A., & Crisan, D. (2008). Fundamentals of stochastic filtering. Berlin: Springer.
Bauer, M. D. (2015). Nominal interest rates and the news. Journal of Money, Credit and Banking, 47(2–3), 295–332.
Cox, J. C., Ingersoll, J. E., & Ross, S. A. (1985). A theory of the term structure of interest rates. Econometrica, 53, 385–407.
Fukui, T., Sato, S., & Takahashi, A. (2017). Style analysis with particle filtering and generalized simulated annealing. International Journal of Financial Engineering, 4(02n03), 1750037.
Gotthelf, N., & Uhl, M. W. (2018). News sentiment: A new yield curve factor. Journal of Behavioral Finance. https://doi.org/10.1080/15427560.2018.1432620.
Hull, J., & White, A. (1990). Pricing interest-rate-derivative securities. The Review of Financial Studies, 3(4), 573–592.
Karatzas, I., & Shreve, S. E. (1991). Brownian motion and stochastic calculus. Berlin: Springer.
Karatzas, I., & Shreve, S. E. (1998). Methods of mathematical finance. Berlin: Springer.
Kitagawa, G. (1996). Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. Journal of Computational and Graphical Statistics, 5(1), 1–25.
Kumar, B. S., & Vadlamani Ravi, V. (2016). A survey of the applications of text mining in financial domain. Knowledge-Based Systems, 114, 128–147.
Kunitomo, N., Sato, S., & Kurisu, D. (2018). Separating information maximum likelihood method for high-frequency financial data. Berlin: Springer.
MeCab. (2006). Yet another part-of-speech and morphological analyzer. http://taku910.github.io/mecab/.
Nakano, M., Takahashi, A., Takahashi, S., & Tokioka, T. (2018). On the effect of Bank of Japan’s outright purchase on the JGB yield curve. Asia-Pacific Financial Markets, 25(1), 47–70.
Nassirtoussi, A. K., Aghabozorgi, S., Waha, T. Y., & Ngo, D. C. L. (2014). Text mining for market prediction: A systematic review. Expert Systems with Applications, 41, 7653–7670.
Nishimura, K. G. (2008). Recent economic and financial developments and the conduct of monetary policy, speech at the foreign correspondents’ club of Japan, September 29, 2008, Bank of Japan.
Nishimura, K. G., & Ozaki, H. (2017). Economics of pessimism and optimism: Theory of Knightian uncertainty and its applications. Berlin: Springer.
Rudebusch, G. D., & Wu, T. (2008). A macro-finance model of the term structure, no monetary policy and the economy. Economic Journal, 118(530), 906–926.
Shirakawa, H. (2002). Squared Bessel processes and their applications to the squared root interest rate model. Asia-Pacific Financial Markets, 9, 169–190.
Takahashi, A., & Sato, S. (2001). Monte Carlo filtering approach for estimating the term structure of interest rates. Annals of The Institute of Statistical Mathematics, 53(1), 50–62.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The views expressed in this paper are our own and do not necessarily reflect the institutions we are affiliated with. Financial supports from CARF at the University of Tokyo and JSPS KAKEN(S) #18H05217 are gratefully acknowledged. We are very grateful to Mr. Takami Tokioka at GCI Asset Management, Inc. and Prof. Taiga Satio at University of Tokyo for their precious comments and suggestions.
Appendices
Appendix A: Algorithm for Monte Carlo Filter
This appendix describes the outline of an algorithm of Monte Carlo filter used in this work, which is an adaptation of Fukui et al. (2017).
We introduce a state space model that consists of the following system and observation models:
where \(x_t, y_t\) and \(\Delta t\) denote a N dimensional state vector, a M dimensional observation vector at time t and the time interval of observational data, respectively while \(\epsilon _t\) and \(e_t\) denote the system noise and the observational noise whose density functions are given by q(v) and \(\psi (u)\) respectively. The functions f and h are generally non-linear maps, \(R^N \times R^N \mapsto R^N\) and \(R^N \mapsto R^M\), and the initial state vector \(x_0\) is assumed to be a random variable whose density function is given by \(p_0(x)\).
Next, we summarize the notations: \(p(x_t \vert y_{t-\Delta t})\), called “one step ahead prediction” denotes the conditional density function of a state vector \(x_t\) given an observation vector \(y_{t-\Delta t}\) where \(\Delta t\) is the interval of time series data. \(p(x_t \vert y_t)\), called “filter” denotes the conditional density function of \(x_t\) given \(y_t\). \(\{p_t^{[1]}, \ldots , p_t^{[m]}\}\) and \(\{s_t^{[1]}, \ldots , s_t^{[m]}\}\) represent the vectors of realization of m trials of Monte Carlo simulations from \(p(x_t \vert y_{t-\Delta t})\) and \(p(x_t \vert y_{t})\), respectively. Then, when we choose \(\{s_0^{[1]}, \ldots , s_0^{[m]}\}\) from the density function \(p_0(x)\) of the initial state vector \(x_0\), as realization of Monte Carlo simulations, an algorithm of Monte Carlo filter is as follows.
[Summary of Algorithm for Monte Carlo filter]
-
1.
Apply the following steps (a)\(\sim\)(d) to each time \(t=0,\Delta t, 2\Delta t, \ldots , (T_*-\Delta t), T_*\) where \(T_*\) denotes the final time point of the data.
-
(a) Generate the system noise \(\epsilon _t^{[k]}, k=1,\ldots ,m\) according to the density function \(q(\epsilon )\).
-
(b) Compute for each \(k=1,\ldots ,m\)
$$p_t^{[k]} = f( s^{[k]}_{t-\Delta t}, \epsilon _t^{[k]}).$$We note that \(f(\cdot ,\cdot )\) is linear in our model, such as \(F s_{t-\Delta t}^{[k]} + G \epsilon _t^{[k]}\). (See the system equations in “State space model for two-factor term structure model” in Sect. 3.1 and “State space model for three-factor term structure model and two-word set frequency” in Sect. 4.)
-
(c) Evaluate the density function of \(\psi (u)\) at \(u = y_t - h(p_t^{[k]}), k=1, \ldots , m\) and define the evaluated densities as \(\alpha _t^{[k]}, k=1, \ldots , m\). In our models, \(\alpha _t^{[k]}\) is given by:
$$\alpha _t^{[k]} = \Pi _{l=1}^M \frac{1}{\sqrt{2\pi \gamma _l^2}} \exp \left( -\frac{[y_{l,t}-h_l(p_t^{[k]})]^2}{2\gamma _l^2}\right),$$(36)where \(h(\cdot )\) in our models is expressed as
$$h_l(p_t^{[k]})=a_l+b_l (p_{1,t}^{[k]})^2 +c_l (p_{2,t}^{[k]})^2 + d_l p_{3,t}^{[k]},$$here \(a_l, b_l, c_l\) and \(d_l\) are explicitly given as the constant terms, the coefficients of \(x_{j,t}^2 (j=1,2)\) and \(x_{3,t}\) in the observation equations in “State space model for two-factor term structure model” in Sect. 3.1 and “State space model for three-factor term structure model and two-word sets frequency” in Sect. 4.
-
(d) Resample \(\{s_t^{[1]}, \ldots , s_t^{[m]}\}\) from \(\{p_t^{[1]}, \ldots , p_t^{[m]}\}\). More precisely, resample each \(s_t^{[k]}, k=1, \ldots , m\) from \(\{p_t^{[1]}, \ldots , p_t^{[m]}\}\) with the probability given by
$$\text{ Prob. }(s_t^{[k]} = p_t^{[i]} \vert y_t) = {\alpha _t^{[i]} \over \sum _{k=1}^{m} \alpha _t^{[k]}},\ k=1, \ldots , m,\ i=1, \ldots , m.$$We note that when the variances of the observation noises, \(\gamma _l^2\) are very small, \(\alpha _t^{[k]}\) tends to take values close to zero (cf. (36)), which makes computation of this resampling probability difficult (infeasible) or causes inadequate resampling probabilities. (e.g. The support of a resampling distribution concentrates on a few particular values.)
-
(e) We obtain the filtered estimates \({\hat{x}}_t\) by
$${\hat{x}}_t = \frac{1}{m} \sum _{i=1}^m s_t^{[i]}.$$Particularly, in our models, we calculate
$$\begin{aligned} {\hat{x}}_{j,t}^2 & = \frac{1}{m} \sum _{i=1}^m (s_{j,t}^{[i]})^2 , \quad j=1,2 , \\ {\hat{x}}_{3,t} & = \frac{1}{m} \sum _{i=1}^m s_{3,t}^{[i]}. \end{aligned}$$
-
The estimation of unknown parameters is based on the maximum likelihood method. If \(\theta\) denotes the vector representing whole unknown parameters, the likelihood \(L(\theta )\) is given by
where \(g(y_{\Delta t}, \ldots , y_{T_{*}} \vert \theta )\) and \(g_i(y_{i \Delta t} \vert y_{\Delta t}, \ldots , y_{(i-1) \Delta t}, \theta )\) denote the joint density function of \(y_{\Delta t}, \ldots , y_{T_{*}}\) with parameter vector \(\theta\) and the conditional density function of \(y_{i \Delta t}\) given \(y_{\Delta t}, \ldots , y_{(i-1) \Delta t}\) with \(\theta\), respectively. The log-likelihood \(l(\theta )\) is computed approximately within the framework of the Monte Carlo filter by:
Then, maximize \(l(\theta )\) with respect to \(\theta\) to obtain the maximum likelihood estimator \(\theta ^*\).
Appendix B: Interest Rate Models with Market Sentiment
This appendix briefly explains an equilibrium model with a representative agent, which supports interest rate models with market sentiment. The model is motivated by the argument of Nishimura and Ozaki (2017 Chapter 12), which suggests the economic agent may find himself in three different states with respect to the (part or whole) of stochastic model he faces: he may be confident about the stochastic model, not confident and pessimistic (and thus maximize his utility assuming the worst case), or optimistic (assuming the best case). Particularly, we assume in a consumption-portfolio allocation a representative agent is confident about some risks (Brownian motions in this paper), but not confident about the others, of which he may be pessimistic assuming the worst case for some and optimistic assuming the best case for the rest. We present the model in an intuitive way in this appendix. A rigorous argument is found in Nishimura, Saito and Takahashi (work in progress).
We start with an appropriate filtered probability space \((\Omega ,{\mathcal {F}}, \{{\mathcal {F}}_t\}_{t\ge 0}, P)\) with d-dimensional Brownian motion \(B=(B_1,\ldots ,B_d)\). Then, we specify fundamental uncertainty as uncertainty about the stochastic model in the following way. We work with some d-dimensional progressively measurable process \(\lambda = \{\lambda _t;\, 0\le t<\infty \}\), a martingale \(Z_t(\lambda )\) defined by
and probability measure \(P^\lambda\),
We assume that the Maruyama-Girsanov theorem can be applied; that is, a process \(B^\lambda = \{(B^\lambda _{1,t},\ldots ,B^\lambda _{d,t});\,0\le t < \infty \}, B^\lambda _{j,t}:= B_{j,t}- \int _0^t \lambda _{j,s} ds\) (\(j=1,2,\ldots ,d\)) is a d-dimensional Brownian motion on \((\Omega ,{\mathcal {F}}, P^\lambda )\). (For a rigorous argument, see Chapter 1.7 and Chapter 3.9 in Karatzas and Shreve (1998) and Chapter 3.5 in Karatzas and Shreve (1991). Here \(\lambda _j\) represents fundamental uncertainty about the j-th risk (Brownian motion \(B_j\)). If \(\lambda _j \equiv 0\) (i.e. \(B^\lambda _j=B_j\)), there is no fundamental uncertainty about the j-th risk. When there is fundamental uncertainty about the the j-th risk, we only know the true j-th risk is one of \(\{B^\lambda _{j};\lambda _j \in \Lambda _j\}\) with \(B^\lambda _{j,t} := B_{j,t}- \int _0^t \lambda _{j,s} ds, 0\le t<\infty\) for some set \(\Lambda _j\), and we cannot tell which is the true one.
In a consumption-portfolio allocation for a single risky asset and an risk-free asset, a representative agent takes his/her own views for uncertainties (risks) associated with Brownian motions into account. Specifically, a representative agent who has a pessimistic (optimistic) view on Brownian motion \(B_1\)(\(B_2\)) assumes the worst (best) case. Thus, he/she implements optimization in a consumption-portfolio allocation with respect to \(\lambda _{j}\) (\(j=1,2\)), that is, minimize (maximize) the expected utility with respect to \(\lambda _{1}\)(\(\lambda _{2}\)), in addition to standard maximization for an allocation of consumption(c), a risk-free asset and a risky asset whose proportion of the agent’s wealth (W) is denoted by \(\alpha\). In contrast, for \(j=3,\ldots ,d\), the economic agent has perfect confidence, so that we have \(\lambda _{j} \equiv 0\). Then, \(B^{\lambda }_{1,t} = B_{1,t} -\int _0^t \lambda _{1,s} ds, B^{\lambda }_{2,t} = B_{2,t} -\int _0^t \lambda _{2,s} ds\) and \(B^\lambda _j = B_j\) for \(j=3,\ldots ,d\) are Brownian motions under the probability measure \(P^\lambda\) generated by a martingale \(Z(\lambda )\) with \(\lambda =(\lambda _1,\lambda _2,0,\ldots ,0)\).
More concretely, the agent with a time-separable expected utility specified by a strictly increasing and concave function solves the following problem:
where pessimism and optimism are expressed by \(\inf _{\lambda _{1}}\) and \(\sup _{\lambda _{2}}\), respectively. Here, \(\Pi\) and \(\Lambda _j\) (\(j=1,2\)) denote appropriate admissible control sets. In particular, the conditions specifying \(\Lambda _j\) contain that \(\lambda _j\) (\(j=1,2\)) are progressively measurable processes such that \(\lambda _{j,t}^2\le {\bar{\lambda }}_j(x_{t})^2\) with a state vector process \(x=\{x_t;\, t\ge 0\}\), and \(Z(\lambda )\) is a martingale under P given \(\lambda _i\)(\(i\ne j\)).
Moreover, we exogenously specify \({\bar{\lambda }}_j(x)\), (a function of \(x, {\mathcal {R}}^n \rightarrow {\mathcal {R}}\)) so that \(Z({\bar{\lambda }})\) with a progressively measurable process \({\bar{\lambda }}(x_t)\) is a martingale under P.
Further, in what follows, we will specify u(c) as \(u(c)=\log c\) for \(c>0\).
Next, let us suppose that a n-dimensional state vector process x, a dividend process D and a price process \(\eta\) of a risky asset receiving the dividend stream \(\{D_t: t\ge 0\}\) are obtained by the following system of stochastic differential equations:
with \(\mu _x, \sigma _{x,j}:{\mathcal {R}}^n \rightarrow {\mathcal {R}}^n\) and \(\mu _D, \sigma _{D,j},\mu ,\sigma _j:{\mathcal {R}}^n \rightarrow {\mathcal {R}},\, j=1,\ldots ,d\).
We also suppose that while a state vector process x and a dividend process D are exogenously given, an interest rate r of an risk-free asset, and the expected rate of return \(\mu\) and volatilities \(\sigma _j\) of a price process \(\eta\) are endogenously determined in equilibrium.
For simplicity, for the first and second element of \(x, x_i\) (\(i=1,2\)), we assume \(\sigma _{x,j,i}=0,\, j\ne i\) (\(i=1,2\)), where \(\sigma _{x,j,i}\) denotes the i-th element of \(\sigma _{x,j}\).
Then, the representative agent’s wealth process W is described as follows: given stochastic processes of a risk-free interest rate r, a consumption c and proportion \(\alpha\) of the wealth invested in a risky asset,
Then, solving the associated HJB equation, we obtain candidates for optimal controls are given by
We remark that if \({\bar{\lambda }}_j(x_t)\sigma _{j}(x_t)>0\,\)(\(j=1,2\)), a pessimistic (optimistic) view reduce (increase) \(\alpha _t\), investment proportion of an risky asset. Hereafter, we suppose that the candidates (50) of optimal controls attain (41).
(Equilibrium) An equilibrium in this economy is characterized as follows: it holds that \(c=D\) and \(\alpha =1\). Given \(r=\{r_t;\,t\ge 0\}\), (43), (45), (47) and (49), the representative agent solves (41).
We also note that the equilibrium conditions above imply that \(W_t=\frac{1}{\beta }D_t(=\eta _t)\), and hence \(\mu (x_t) = \beta + \mu _D(x_t)\) and \(\sigma _{j}(x_t) = \sigma _{D,j}(x_t)\) in equilibrium. Thus, the condition \(\alpha =1\) provides an equilibrium interest rate as
in which the term \(\beta + \mu _D(x_t) - |\sigma _D(x_t)|^2\) is a well-known equilibrium interest rate process without pessimism and optimism for the log-utility. We remark that if \({\bar{\lambda }}_j(x_t)\sigma _{D,j}(x_t)>0\) (\(j=1,2\)), the expression agrees with our intuition, that is pessimistic (optimistic) views reduces (increases) the equilibrium interest rate.
Next, we note that x is expressed under \(Q^\lambda\), a risk-neutral probability measure induced by \(P^\lambda\) as
where \(Q^\lambda (A) = E^{P^\lambda }[Z_T(\sigma _D)1_A]\ \text{ for } \text{ any }\ T>0, A\in {\mathcal {F}}_T\),
and \(B^{Q^\lambda }\) is a d-dimensional Brownian motion under \(Q^\lambda\).
Hence, equilibrium zero coupon bond price P(t, T) and zero yield Y(t, T) at time t with maturity T are expressed respectively by
with \({\bar{\lambda }}=(-{\bar{\lambda }}_1,{\bar{\lambda }}_2,0,\ldots ,0)\) and an equilibrium interest rate (51).
1.1 Appendix B.1: Example: Three-Factor Gaussian Quadratic-Gaussian Model
When we specify
associated with the Eq. (51), we obtain a concrete expression of equilibrium interest rate \(r_t\) and zero yields \(Y(t,T), 0\le t\le T<\infty\). In what follows, we present such an example for yield curve models with new factors (proxies of pessimism and optimism) that follow Quadratic-Gaussian processes, which is a simplified version of the previous section’s models.
First, as an example of the state variable process (42), let us consider the following model with three-dimensional Brownian motion \(B=(B_1,B_2,B_3)\), and constants \(a_j\ge 0, b_j>0\) (\(j=1,2\)), \(b_3\ge 0, a_3, \sigma _{x,j},\, j=1,2,3\):
Moreover, as an example of the dividend process (44), we suppose
in which
with \(\mu _{1,1}=0\) when \(a_1=0\) and \(\mu _{2,1}=0\) when \(a_2=0\).
In addition, we specify
Thus, we have \({\bar{\lambda }}_j(x_{t})\sigma _{D,j}(x_{t})= \sigma _{D,j} \phi _j x_{j,t}^2\,(j=1,2)\) in (51), and the optimal \(\lambda _{j,t}\,(j=1,2)\) are given by \(\lambda _{1,t} = -{\bar{\lambda }}_1(x_t) =-\phi _1 x_{1,t}\) and \(\lambda _{2,t} = {\bar{\lambda }}_2(x_t) =\phi _2 x_{2,t}\). (\(\lambda _{3,t}\equiv 0\) by our standing assumption.)
Then, each of \(B^{{\bar{\lambda }}}_{1,t}=B_{1,t} +\int _0^t {\bar{\lambda }}_{1,s} ds, B^{{\bar{\lambda }}}_{2,t}=B_{2,t} -\int _0^t {\bar{\lambda }}_{2,s} ds\) and \(B^{{\bar{\lambda }}}_{3,t}=B_{3,t}\) is a Brownian motion under \(P^{{\bar{\lambda }}}\) with \({\bar{\lambda }}=(-{\bar{\lambda }}_1,{\bar{\lambda }}_2,0)\). (e.g. Lemma 3.9 and Exercise 3–11-i) in Chapter 3 of Bain and Crisan (2008).)
Thus, the equilibrium interest rate (51) is given by
in which \(\mu _D(x_t)=\mu _0 + \mu _{1,1}x_{1,t}+ \mu _{2,1}x_{2,t} + \mu _{1}x^2_{1,t}+ \mu _{2}x_{2,t}^2+ \mu _3 x_{3,t}\). (\(\mu _{1,1}=0\) when \(a_1=0\) and \(\mu _{2,1}=0\) when \(a_2=0\).)
Moreover, we obtain the SDEs of \(x_{j,t}, j=1,2,3\) under \(P^{{\bar{\lambda }}}\) as
where we suppose \(b_1+ \phi _1\sigma _{x,1}>0\) and \(b_2- \phi _2\sigma _{x,2}>0\).
In addition, we have each SDE of \(x_{i,t}, i=1,2,3\) under \(Q^{{\bar{\lambda }}}\) as
where \(B^{Q^{{\bar{\lambda }}}} =(B^{Q^{{\bar{\lambda }}}}_{j})_{j=1}^3\) is a three dimensional Brownian motion under \(Q^{{\bar{\lambda }}}\), and we assume \(b_1+(\phi _1+\sigma _{D,1})\sigma _{x,1}>0\) and \(b_2-(\phi _2-\sigma _{D,2})\sigma _{x,2}>0\).
Finally, as for the term structure of interest rates (55), we omit the expression of Gaussian part (\(x_3\)), which is well-known. (e.g. “Appendix” in Nakano et al. (2018)) The expression corresponding to quadratic-Gaussian factors (\(x^2_i, i=1,2\)) will be given in the next section.
We remark that if we set \(a_j=0\) (\(j=1,2\)) in (57) as a special case, \(y_j:=x_j^2\) is the solution to the following SDE: with \(a_{y,j}= \sigma _{x,j}^2, b_{y,j}=2 b_j\) and \(\sigma _{y,j}=2 \sigma _{x,j}\),
That is, \(x_j^2\) becomes the so called squared-root (CIRFootnote 15) process. (See Theorem 3.2 in Shirakawa (2002) for a measure change associated with \({\bar{\lambda }}_{j}(y_{j,t})=\phi _j \sqrt{y_{j,t}}\) with positive constants \(\phi _j\) (\(j=1,2\)).)
1.2 Appendix B.2: Expression of Term Structure in Quadratic-Gaussian Model
This appendix shows an expression of a term structure of interest rates corresponding to a Quadratic-Gaussian factor in the previous section. Without loss of generality, we use a notation \({\mathbb {Q}}\) instead of \({\mathbb {Q}}^\lambda\) for a risk-neutral probability measure.
First, let us introduce the following SDE: with constants \(\kappa ,{\hat{\theta }},\sigma\),
and consider a quadratic function of \(y_t\) with constants \({\hat{a}},b,c\):
in which \(x_t=y_t + \frac{b}{c}, a= {\hat{a}}-\frac{b^2}{2c}\), and
Thus, an interest rate model, determined by a quadratic function (72) of factor y which follows a mean-reverting Gaussian process (71), is represented by
This is the quadratic-Gaussian part of the interest rate model ((1) and (2)) in Sect. 2 with appropriate modification. Hereafter, we consider the above model for a term structure of interest rates.
Let P(t, T) denote a zero coupon bond price at time t with maturity \(T (t\le T)\), and define \(P_t(\tau ):=P(t,T)\) with \(\tau = T-t\). Then, we would like to obtain
Next, we conjecture that
Since \(P(x_t,t;T)e^{-\int _0^t r_u du}\) is a martingale under \({\mathbb {Q}}\), after applying Ito’s formula to \(P(x_t,t;T)e^{-\int _0^t r_u du}\) and setting the drift term to be zero, it is enough to solve the following ODEs to obtain \(A(\tau ), B(\tau ), C(\tau )\):
Then, \(C(\tau )\) is given as follows:
Given \(C(\tau )\), we have \(B(\tau )\) as
In particular, when \(\theta =0, B(\tau )\equiv 0\).
Then, given \(C(\tau )\) and \(B(\tau )\), we obtain \(A(\tau )\) as follows:
where
Here, we note that since \(\alpha = -2\sqrt{\kappa ^2+c \sigma ^2}<0\) with \(e^{\alpha \tau }<1\) and \(C_0>0\), we have \(1+C_2=\frac{\alpha }{\sigma ^2}z(0)= \frac{2\sqrt{\kappa ^2+c \sigma ^2}}{C_0\sigma ^2}>0\), and \(1+C_2 e^{\alpha \tau } = (1-e^{\alpha \tau }) + \frac{2\sqrt{\kappa ^2+c \sigma ^2}}{\sigma ^2 C_0} e^{\alpha \tau }> 0\).
Finally, we remark that \(a=0\) and \(\theta =0\) (i.e. \(B(\tau )\equiv 0\)) in our empirical analysis of the main text. Moreover, setting \({\hat{x}}_t:=\frac{x_t}{\sqrt{2}}\), we have
and then redefining \({\hat{x}}_t\) as \(x_{t}\) with \(\sigma _{x}\equiv \frac{\sigma }{\sqrt{2}}\) provide the Eqs. (2) and (6) in Sect. 2. (Here, the subindex j is omitted for simplicity.)
Appendix C: Estimation of Trend and Correlation in Noisy Time Series Data
This appendix introduces a new method for estimation of trends in time series and their correlations, which is based on the Separating Information Maximum Likelihood (SIML) method applied in Sect. 3.3.
First, we briefly explains the SIML method by using a simple case. (See Kunitomo et al. (2018) for more general cases.) Let us suppose that observed time series \((x_t)_{t=1}^{n}\) and \((y_t)_{t=1}^{n}\) are generated by the following stochastic processes, each of which is a sum of a stationary process \(e_x\) (\(e_y\)) and a non-stationary process \(\mu _x\) (\(\mu _y\)):
where each of \(\eta _{x,t}, \eta _{y,t}\) is i.i.d. normal with mean 0 across time t, and the correlation between \(\eta _{x,t}\) and \(\eta _{y,t}\) is given as a constant \(\rho _{xy}\) for all t. Then, we define a SIML correlation estimator \(cor_{SIML}(x,y)\) for \(\rho _{xy}\) as follows:
where with \(x = (x_1,x_2, \ldots , x_n)^\top , y = (y_1,y_2, \ldots , y_n)^\top , z_x = (z_{x,1}, z_{x,2}, \ldots , z_{x,n})^\top\) and \(z_y = (z_{y,1}, z_{y,2}, \ldots , z_{y,n})^\top\) are defined as
and \(m = \lfloor n^\alpha \rfloor\) with \(\alpha =0.45\).Footnote 16 Here, \(C_n^{-1}\) is an \(n\times n\)-matrix representing the first-order difference, and \(P_n\) is an \(n\times n\)-orthogonal matrix such that \(C_n^{-1}C_n^{\top -1}= P_n D_n P_n^\top\) with a diagonal matrix \(D_n\). That is,
To detect a trend component in each x and y, we use \(z_{x,i}, z_{y,i}\) only with \(i=1,\ldots ,m(<n)\) (e.g. \(m= 22\) out of \(n=977\) in an example below) for an estimation, because \(z_i\) with smaller i contains information about a longer cyclic component.
Next, we introduce a new method to estimate trends and their correlations. Concretely, we estimate trend series by \(T_x\) for x and \(T_y\) for y that are defined as as follows:
in which
Then, it is easily seen that a standard sample correlation between the first-order differences of these trend series is same as a SIML correlation estimator, i.e.

time series plot for log-frequencies of “fiscal conditions (zaisei) and foreign (gaikoku)” (x) and the steepening factor \(x_1^2\) estimated by “two-factor Gaussian minus Quadratic-Gaussian” model (y, right axis)
Next, we apply our method to a text mining analysis in Sect. 3.3, particularly, the observed log-frequency of two-word set ”fiscal conditions (zaisei) and foreign (gaikoku)” as x, and the steepening factor \(x_1^2\) estimated in Sect. 3.1 as y. We remark that since our estimate of the mean-reversion speed in the system Eq. (17) is \(\kappa _1=0.129\), which implies that the autoregressive coefficients for \(x_{1,t}\) and \(y_t=x_{1,t}^2\) (i.e. \(e^{-\kappa _1 \Delta t}\) and \(e^{-2\kappa _1 \Delta t}\) with \(\Delta t=1/250\)) are close to 1, we may regard the time series \((x_{1,t})_{t=1,\ldots ,n}\) and \((y_{t})_{t=1,\ldots ,n}\) with \(n=977\) as non-stationary processes. In fact, given the estimated time series \((y_{t})_{t=1,\ldots ,n}\), a null hypothesis, \(\beta =0\) is not rejected at 10% significant level in a simple regression equation: \(y_t-y_{t-1} = \alpha +\beta y_{t-1}+\epsilon _t\) (\(\epsilon _t \sim\) i.i.d. \(N(0,\sigma _\epsilon ^2)\)).
Figure 14 shows the result. It is observed that the estimated trends \(T_x\) and \(T_y\) show similar movements, which is captured by the SIML correlation, 0.62 as reported in Fig. 3. In contrast, because the observed two-word set’s frequency suffers from large noises, the standard sample correlation between the first-order differences of x and y is only 0.02. Moreover, the correlation between levels of those trends, i.e. \(T_x\) and \(T_y\) becomes very high (0.86), while the standard sample correlation is 0.59 as reported in Fig. 3. Further, since the estimated \(x_1^2\) has relatively small noises, the correlation between \(T_x\) and y is also high (0.83).
We finally remark that the method described in this section is expected to be effective with relatively little computational burden in detecting trends and long-term relationships embedded in very noisy time series data such as word frequencies.
Rights and permissions
About this article

Cite this article
Nishimura, K.G., Sato, S. & Takahashi, A. Term Structure Models During the Global Financial Crisis: A Parsimonious Text Mining Approach. Asia-Pac Financ Markets 26, 297–337 (2019). https://doi.org/10.1007/s10690-018-09267-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10690-018-09267-9