
Abstract
We consider a regularized least squares problem, with regularization by structured sparsity-inducing norms, which extend the usual ℓ 1 and the group lasso penalty, by allowing the subsets to overlap. Such regularizations lead to nonsmooth problems that are difficult to optimize, and we propose in this paper a suitable version of an accelerated proximal method to solve them. We prove convergence of a nested procedure, obtained composing an accelerated proximal method with an inner algorithm for computing the proximity operator. By exploiting the geometrical properties of the penalty, we devise a new active set strategy, thanks to which the inner iteration is relatively fast, thus guaranteeing good computational performances of the overall algorithm. Our approach allows to deal with high dimensional problems without pre-processing for dimensionality reduction, leading to better computational and prediction performances with respect to the state-of-the art methods, as shown empirically both on toy and real data.








Similar content being viewed by others


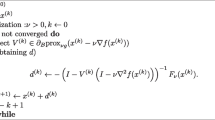
Notes
It is the solution computed via the projected Newton method for the dual problem with very tight tolerance
References
Bach, F.: Consistency of the group lasso and multiple kernel learning. J. Mach. Learn. Res. 9, 1179–1225 (2008)
Bach, F.R., Lanckriet, G., Jordan, M.I.: Multiple kernel learning, conic duality, and the smo algorithm. In: ICML. ACM International Conference Proceeding Series, vol. 69 (2004)
Bach, F., Jenatton, R., Mairal, J., Obozinski, G.: Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. 4(1), 1–106 (2012)
Bauschke, H.: The approximation of fixed points of compositions of nonexpansive mappings in Hilbert space. J. Math. Anal. Appl. 202(1), 150–159 (1994)
Bauschke, H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer, New York (2011)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009)
Becker, S., Bobin, J., Candes, E.: NESTA: A fast and accurate first-order method for sparse recovery. SIAM J. Imaging Sci. 4(1), 1–39 (2009)
Bertsekas, D.: Projected Newton methods for optimization problems with simple constraints. SIAM J. Control Optim. 20(2), 221–246 (1982)
Boyle, J., Dykstra, R.: A method for finding projections onto the intersection of convex sets in Hilbert spaces. In: Dykstra, R., Robertson, T., Wright, F. (eds.) Advances in Order Restricted Statistical Inference. Lecture Notes in Statistics, vol. 37, pp. 28–48. Springer, Berlin (1985)
Brayton, R., Cullum, J.: An algorithm for minimizing a differentiable function subject to box constraints and errors. J. Optim. Theory Appl. 29, 521–558 (1979)
Chambolle, A., Pock, T.: A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40(1), 120–145 (2011)
Chen, S., Donoho, D., Saunders, M.: Atomic decomposition by basis pursuit. SIAM J. Sci. Comput. 20(1), 33–61 (1999)
Chen, X., Lin, Q., Kim, S., Carbonell, J., Xing, E.P.: Smoothing proximal gradient method for general structured sparse regression. Ann. Appl. Stat. 6(2), 719–752 (2012)
Combettes, P.L., Wajs, V.R.: Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 4(4), 1168–1200 (2005) (electronic)
Deng, W., Yin, W., Zhang, Y.: Group sparse optimization by alternating direction method (2011)
Duchi, J., Singer, Y.: Efficient online and batch learning using forward backward splitting. J. Mach. Learn. Res. 10, 2899–2934 (2009)
Efron, B., Hastie, T., Johnstone, I., Tibshirani, R.: Least angle regression. Ann. Stat. 32, 407–499 (2004)
Fornasier, M. (ed.): Theoretical Foundations and Numerical Methods for Sparse Recovery. Radon Series on Computational and Applied Mathematics, vol. 9. de Gruyter, Berlin (2010)
Fornasier, M., Daubechies, I., Loris, I.: Accelerated projected gradient methods for linear inverse problems with sparsity constraints. J. Fourier Anal. Appl. (2008)
Hale, E.T., Yin, W., Zhang, Y.: Fixed-point continuation for l1-minimization: methodology and convergence. SIAM J. Optim. 19(3), 1107–1130 (2008)
Jacob, L., Obozinski, G., Vert, J.-P.: Group lasso with overlap and graph lasso. In: Proceedings of the 26th International Annual Conference on Machine Learning, pp. 433–440 (2009)
Jacques, L., Hammond, D., Fadili, J.: Dequantizing compressed sensing: when oversampling and non-Gaussian constraints combine. IEEE Trans. Inf. Theory 57(1), 559–571 (2011)
Jenatton, R., Audibert, J.-Y., Bach, F.: Structured variable selection with sparsity-inducing norms. Technical report, INRIA (2009)
Jenatton, R., Obozinski, G., Bach, F.: Structured principal component analysis. In: Proceedings of the 13 International Conference on Artificial Intelligence and Statistics (2010)
Liu, J., He, J.: Fast overlapping group lasso (2010)
Mairal, J., Jenatton, R., Obozinski, G., Bach, F.: Network flow algorithms for structured sparsity. Adv. Neural Inf. Process. Syst. (2010)
Meier, L., van de Geer, S., Buhlmann, P.: The group lasso for logistic regression. J. R. Stat. Soc. B 70, 53–71 (2008)
Micchelli, C.A., Pontil, M.: Learning the kernel function via regularization. J. Mach. Learn. Res. 6, 1099–1125 (2005)
Moreau, J.-J.: Fonctions convexes duales et points proximaux dans un espace hilbertien. C. R. Acad. Sci. Paris 255, 2897–2899 (1962)
Mosci, S., Rosasco, L., Santoro, M., Verri, A., Villa, S.: Solving structured sparsity regularization with proximal methods. In: Balcázar, J., Bonchi, F., Gionis, A., Sebag, M. (eds.) Machine Learning and Knowledge Discovery in Databases. Lecture Notes in Computer Science, vol. 6322, pp. 418–433. Springer, Berlin (2010)
Mosci, S., Villa, S., Verri, A., Rosasco, L.: A primal-dual algorithm for group sparse regularization with overlapping groups. In: Lafferty, J., Williams, C.K.I., Shawe-Taylor, J., Zemel, R.S., Culotta, A. (eds.) Advances in Neural Information Processing Systems, vol. 23, pp. 2604–2612 (2010)
Nesterov, Y.: A method for unconstrained convex minimization problem with the rate of convergence o(1/k 2). Dokl. Akad. Nauk SSSR 269(3), 543–547 (1983)
Nesterov, Y.: Smooth minimization of non-smooth functions. Math. Program., Ser. A 103(1), 127–152 (2005)
Nesterov, Y.: Gradient methods for minimizing composite objective function. CORE Discussion Paper 2007/76, Catholic University of Louvain, September 2007
Obozinski, G., Jacob, L., Vert, J.-P.: Group lasso with overlaps: the latent group lasso approach. Research report, October 2011
Park, M.Y., Hastie, T.: L1-regularization path algorithm for generalized linear models. J. R. Stat. Soc. B 69, 659–677 (2007)
Peyré, G., Fadili, J.: Group sparsity with overlapping partition functions. In: Proc. EUSIPCO 2011, pp. 303–307 (2011)
Poliak, E.: Computational Methods in Optimization: A Unified Approach. Academic Press, New York (1971)
Qin, Z., Goldfarb, D.: Structured sparsity via alternating direction methods. J. Mach. Learn. Res. 13, 1435–1468 (2012)
Qin, Z., Scheinberg, K., Goldfarb, D.: Efficient block-coordinate descent algorithms for the group lasso (2012)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14(5), 877–898 (1976)
Rosasco, L., Mosci, M., Santoro, S., Verri, A., Villa, S.: Iterative projection methods for structured sparsity regularization. Technical Report MIT-CSAIL-TR-2009-050, MIT (2009)
Rosen, J.: The gradient projection method for nonlinear programming, part I: Linear constraints. J. Soc. Ind. Appl. Math. 8, 181–217 (1960)
Roth, V., Fischer, B.: The group-lasso for generalized linear models: uniqueness of solutions and efficient. In: Proceedings of 25th ICML (2008)
Salzo, S., Villa, S.: Accelerated and inexact proximal point algorithms. J. Convex Anal. 9(4), 1167–1192 (2012)
Schmidt, M., Le Roux, N., Bach, F.: Convergence rates of inexact proximal-gradient methods for convex optimization. In: Advances in Neural Information Processing Systems (NIPS) (2011)
Subramanian, A., et al.: Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl. Acad. Sci. USA 102(43), 15545–15550 (2005)
The Gene Ontology Consortium: Gene ontology: tool for the unification biology. Nat. Genet. 25, 25–29 (2000)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B 58(1), 267–288 (1996)
Tseng, P.: Approximation accuracy, gradient methods, and error bound for structured convex optimization. Math. Program., Ser. B 125(2), 263–295 (2010)
van ’t Veer, L., et al.: Gene expression profiling predicts clinical outcome of breast cancer. Nature 415(6871), 530 (2002)
Villa, S., Salzo, S., Baldassarre, L., Verri, A.: Accelerated and inexact forward-backward algorithms. SIAM J. Optim. 23(3), 1607–1633 (2013)
Yuan, M., Lin, Y.: Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. B 68(1), 49–67 (2006)
Zhao, P., Rocha, G., Yu, B.: The composite absolute penalties family for grouped and hierarchical variable selection. Ann. Stat. 37(6A), 3468–3497 (2009)
Acknowledgements
The authors wish to thank Saverio Salzo for carefully reading the paper. This material is based upon work partially supported by the FIRB Project RBFR12M3AC “Learning meets time: a new computational approach for learning in dynamic systems” and the Center for Minds, Brains and Machines (CBMM), funded by NSF STC award CCF-1231216.
Author information
Authors and Affiliations
Corresponding author
Appendix: Projected Newton method
Appendix: Projected Newton method
In this appendix we report as Algorithm 5 Bertsekas’ projected Newton method described in [8], with the modifications needed to perform maximization instead of minimization of a function.

Projection onto \(K_{2}^{\mathcal{G}}\)
The step size rule, i.e. the choice of α, is a combination of the Armijo-like rule [43] and the Armijo rule usually employed in unconstrained minimization (see, e.g., [38]).
Rights and permissions
About this article
Cite this article
Villa, S., Rosasco, L., Mosci, S. et al. Proximal methods for the latent group lasso penalty. Comput Optim Appl 58, 381–407 (2014). https://doi.org/10.1007/s10589-013-9628-6
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-013-9628-6