
Abstract
In the modern healthcare system, the function of the Internet of Things (IoT) and the data mining methods with cloud computing plays an essential role in controlling a large number of big data for predicting and diagnosing various categories of diseases. However, when the patients suffer from more than one disease, the physician may not identify it properly. Therefore, in this research, the predictive method using the cloud with IoT-based database is proposed for forecasting the diseases that utilized the biosensors to estimate the constraints of patients. In addition, a novel Generalized Fuzzy Intelligence-based Ant Lion Optimization (GFIbALO) classifier along with a regression rule is proposed for predicting the diseases accurately. Initially, the dataset is filtered and feature extracted using the regression rule that data is processed on the proposed GFIbALO approach for classifying diseases. Moreover, suppose the patient has been affected by any diseases, in that case, the warning signal will be alerted to the patients via text or any other way, and the patients can get advice from doctors or any other medical support. The implementation of the proposed GFIbALO classifier is done with the use of the MATLAB tool. Subsequently, the results from the presented model are compared with state of the art techniques, and it shows that the presented method is more beneficial in diagnosis and disease forecast.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Recent medical management has enlarged human life anticipation by developing medical services, drugs, and record administration of patients’ health [1]. Moreover, automated medical data systems, namely Electronic Health Record (EHR) [2], Disease Prediction Scheme (DPS) [3], and Clinical Decision Support System (CDSS) [4], attract substantial research interest. However, the healthcare monitoring systems aspect major difficulties like absence of adequate medical information, misidentification, data threat, unnecessary errors, and detained broadcast [5]. Moreover, clinical decision support systems have been expanded unexpectedly because of the innovation of technologies like IoT, medical detectors [6], Fog computing and Cloud computing [7]. IoT healthcare applications are used to gather essential data like recurrent changes in strength parameters, and then it modernizes the medical parameters seriousness during a typical time interval [8]. Nowadays, IoT can enable several technologies for the continuous monitoring of people’s health [9]. Due to restricted storage facilities and resource constraints characteristics of IoT, cloud computing act as a backbone for enormous data processing and storage [10]. Especially, the cloud-based IoT technique will help to provide proficient services to the medical applications for accessing and monitoring the records from any remote location [11]. Besides, IoT-based healthcare systems can deliver an effective treatment depending on the patient necessities [12]. In particular, an application of IoT requires low expectancy, maneuverability, and cognizance provision of position, particularly for the services based on healthcare.
Furthermore, the cloud-based medical management system offers the facility to the patients when the sufferer moves from one to another location and in a situation of less or no accessibility of network [13]. The healthcare system with IoT can periodically observe the sufferer’s health condition by sensors connected to the body for predicting the heartbeat, body temperature, insulin level, and other features [14]. These predictions are made through the signal coming out from the sensors connected in the body. Besides, the data mining technique is used to interpret and predict any diseases or disorders in the preliminary stage itself. Subsequently, many patients’ medical data is composed of healthcare provision providers, which creates a valuable resource for the CDSS [15]. Alternatively, the overall allocation of medical organizations worldwide collects massive EHR and necessitates huge computing property for data and storage [16]. Besides, the information can be created from different sources with the specific data type, and it is necessary to develop methods to manage the distinct features of data [17]. Moreover, a machine-learning algorithm plays a significant part in handling large information because of the higher speed of data generation, which is difficult to collect, analyze, and process [18]. With the quick progress of biomedical and health care information to predict disease risk, the technique used was machine learning [19].
Moreover, the Random Forest, Support Vector Machine (SVM), and neural networks algorithms were utilized to predict and categorize the patient’s disease like diabetes, cancer, heart disease, and liver cirrhosis, among others [20]. These algorithms have trained large amounts of data including laboratory tests and medical records. Recently, the neural network has been utilized in various applications, including in medical diagnosis. Nevertheless, neuro-fuzzy systems can handle any type of information and regulate inaccurate information. Hence, Artificial Neural Network (ANN) and Fuzzy Logic (FL) combination is applied for detecting the individuals’ health status [21]. The major scope of the monitoring system of patient health was to detect the patient’s health condition and generate an alert if any irregular conditions may occur. Recently, IoT-based healthcare systems are intended with emergency alarms for providing the alert signal to the patient or family members while the functional indication crosses the threshold level [22].
The rest of the paper is sketched out as follows. Some recent works related to this research are described in Sect. 2. In Sect. 3, the system model and problem statement are explained. Section 4 explains the proposed method of Cloud with IoT-based health monitoring system, novel neuro-fuzzy architecture, and heuristic optimization. Section 5 covers the simulation outcomes of the presented method and comparison with conventional methods. At last, in Sect. 6, the concluding remarks are exhibited.
2 Related work
Some of the recent kinds of literature related to the prediction of diseases in early stages are summarized below:
T1DM (Type 1 diabetes mellitus) was a method of diabetics that influences around 1.25 million people. Many researchers have been interested in the control technique for diabetes and developed some blood glucose level controlling algorithms for each patient, yet it has some drawbacks. For this reason, Bahremand et al. [23] proposed ANN-based Model Predictive Control (MPC), the inputs from ANN are used for BGL forecast and MPC are used for the control method and the combination of ANN. The aforementioned method is tested based on the diabetic rat’s data of BGL, food intake, and insulin injection. Nevertheless, here it is tested on the model of animals, and it is harsh and often ineffectual.
The EdgeSDN-I4COVID architecture was proposed by Rahman et al. [24] for efficient and intelligent management during the COVID-19 pandemic considering IoT networks. Moreover, the paper presents the enabled layer of SDN like control, application, and data, to automatically and effectively monitor the IoT information. The result of the presented method indicated that it handles numerous attacks. However, the data confidentiality and security are less.
Roldan et al. [25] have proposed a Complex-based Event processing (CEP) framework to extract the meaningful information attained from the results of the network based on real-time decision making. Also, a novel event-driven IoT model was presented for reliable healthcare applications data analysis. The results indicated that the presented framework reduced costs, improved the quality of healthcare, and increased reliability. Moreover, the real-time implementation is not developed.
To address the non-functional requirements like availability, response time, reliability, and interoperability that include the best practices of Fog, Cloud planes, and IoT; Hajvali et al. [26] have presented a software framework for IoT-based healthcare (IoTH) systems. Also, the graph transformation method is utilized to express the operational semantics and model transformation. The result of the proposed framework proved that it is eligible and competent for IoTH systems ecosystem. Moreover, the high-availability services and real-times are not applicable.
Ali et al. [27] have proposed a novel FOG-assisted communication and computing infrastructure (CnCI) framework for IoTH facilities. This model was proposed to minimize the weighted infrastructure sum and IoTH operational costs. To solve the issues in IoTH network planning, a Swarm-Intelligence model was utilized. Moreover, this method is reliable, cost-effective, and secure. However, the integer programming problems are big.
The key contributions of this research are summarized below:
-
Initially, the dataset is trained to the system, which involves IoT sensed data, medical data, and medical records.
-
Here, the IoT sensed data is attained by applying biosensors in the human body and obtaining actual medical information about a patient via IoT, stored in the cloud storage.
-
Moreover, the gathered data is trained and tested by a novel GFIbALO with a regression tree approach for classifying and predicting diseases.
-
Subsequently, the utilized dataset is preprocessed, and feature selection is done using a regression tree module. Also, the developed GFIbALO approach classifies the severity of the diseases.
-
Consequently, if the patients are affected by any diseases, they can get a warning via SMS, email, etc., and get the doctors’ advisory. Thus it provides IoT-based healthcare solutions at anytime and anywhere.
-
The proposed disease prediction method is compared with other existing techniques regarding its specificity, sensitivity, accuracy precision, recall, processing time, Matthews Correlation Coefficient (MCC), and Area under Curve (AUC). Thus the results show the effectiveness of the proposed approach.
3 System model
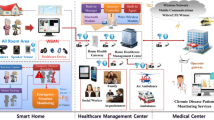
Nowadays, cloud with IoT-based health monitoring is one of the most challenging and interesting concepts for diagnosing diseases. IoT-based applications is widely used worldwide because it can be accessed from anywhere at any time [28]. In a remote healthcare system, the IoT-based biosensors are connected to the human body, which can sense the parameters such as blood, sugar, heartbeat rate, body temperature, etc. Consequently, in the communication of health data, associated application layers are utilized in the IoT cloud database [29]. Then, this medical data is passed over the prediction technique by training the data. The system model of IoT-based healthcare is shown in Fig. 1. In healthcare data analytics, the diagnosis of diseases has three main functions i.e. preprocessing, feature extraction, and classification. The noisy and annoying data are removed by the data preprocessing unit. Moreover, the feature extraction will generate a new subclass from certain features by the training data. After that, the classification algorithm is utilized to predict and diagnose diseases. The parameters more relevant to the particular disease can be observed. This will help the medical practitioners to recognize the origin causes of illness in wisdom.

The system model of IoT based healthcare system
However, disease prediction and hospitalization consume more energy, cost, and time. In healthcare administration (medical centers, hospitals), providing quality treatment is the main challenge [30]. Because of poor medical treatments and lack of experts can cause high faulty diagnosed circumstances. Therefore, a rapid and efficient prediction system has required to progress. The life of the patients requires saving significantly by the appropriate diagnosis and following medical treatment at the early stage [31]. In recent times, most hospitals sort the data systems of the patient to accomplish their health care. Moreover, these methods normally create large amounts of data in text, numbers, images, and charts. Unfortunately, these data are often used to care for medical result-making [32]. This practice tends to errors, annoying prejudices, and increases medical costs, which affects the excellence of aid given to the patients. Therefore, healthcare resources must be enhanced by extending the range of regular machine learning and computing techniques.
4 Proposed health monitoring system
The current work has been proposed for predicting diseases using the IoT-based sensed dataset and medical data. The IoT-based sensors collect the patient details like blood pressure, heart rate, respiratory rate, cholesterol, and body temperature. The main objective of this research is to create a novel GFIbALO approach for predicting diseases through the utilized dataset. The proposed architecture of the health observing system is shown in Fig. 2. Initially, the collected data is preprocessed for removing noisy and annoying data. Subsequently, the feature selection of the data is done by the regression tree technique. Eventually, the data will be examined by the GFIbALO classifier for identifying the severity of the diseases like Heart disease, diabetes, High Cholesterol, Kidney failure, and Hypertension.

The proposed architecture of the health monitoring system
Furthermore, the patients’ risk level is categorized into two categories i.e. disease affected and normal. Consequently, if the people have affected by any diseases, they will get a warning by SMS, emails, etc., and from this, the patients can get the treatments and advisory from doctors.
4.1 Data collection by IoT
The proposed GFIbALO model utilized the dataset to classify the disease types involving medical data; IoT sensed data and data from medical records. Here, IoT sensed data is based on patient details collection with the use of biosensors. The biosensors such as temperature sensors, glucose detection sensors, ECG sensors, etc., are connected to the human body that collects the patient’s specific data in continuous time intervals. Thus, it collects information about patients like respiratory and heartbeat rate, Cholesterol, the temperature of body, blood pressure, etc. In the cloud database, the collected informations were stored and it is used for processing in this work. In addition, the collected datasets are processed with three functions in the GFIbALO method i.e. data preprocessing, feature extraction, and disease prediction. The proposed system predicts the diseases efficiently by investigating the features due to active training and classification approaches.
4.2 Data preprocessing and feature selection
The proposed approach utilized the dataset for predicting the disease types. Primarily, the dataset is required for the preprocessing process because it contains some unwanted noise and mislaid data. These are removed in the preprocessing function, which is done by the proposed approach. The preprocessed data helps to attain the accurate recognition of disease-associated forms. Moreover, the feature extraction process is performed on the dataset that is illustrated in algorithm 1. Furthermore, feature selection is an essential part of the machine learning method because it improves classification accuracy and minimizes the system’s processing time. Subsequently, in the cloud database, there are many related and unrelated aspects; if the entire data are utilized for the disease prediction means, the accuracy, processing time and cost will vary. Therefore, the regression tree algorithm is utilized for the feature selection approach in this research. Consequently, this selection removes the unrelated data, diminishes the size of the data, and enhances the learning and understanding of outcomes. The regression techniques for input data are estimated by Eq. (1),
where \(\lambda_{0}\), \(\lambda_{i}\) are the least square values that are utilized to estimate the remaining value \(\tilde{\varepsilon }\) of the data list. The remaining value \(\tilde{\varepsilon }\) is calculated with the aid of test and mean value variation [23] that is given in Eq. (2),
where the detected values of the sample items are \(\lambda_{i} ......\lambda_{n}\), \(N\) is the number of considerations in the test data and \(\overline{\lambda }\) is the mean value of the data consideration.

The regression tree method is processed on the dataset that removed the unrelated data, diminished the data size, enhances the learning and understanding of the outcomes. Subsequently, this data is given the proposed GFIbALO classifier to identify the diseases’ severity.
4.3 Proposed GFIbALO classifier
The proposed classifier is the combination of novel advanced neuro-fuzzy with ALO algorithm. The flowchart of the presented GFIbALO classifier is shown in Fig. 3, and the process is detailed in algorithm 2. The GFIbALO method has five layers i.e. three hidden layers, the input fuzzification layer, and the output defuzzification layer. Subsequently, the filtered input data for n number of patients are given to the GFIbALO input layer. Also, several features about the patient are considered as the input data that are gender, age, heartbeat rate, respiratory rate, HDL cholesterol, systolic and diastolic blood pressure, LDL and total cholesterol, and body temperature. These features are trained to the input layer, and the output of this fuzzification layer is given to the second layer. In that the difference between the definite output and error rate is estimated from the predicted result. Then the knot estimation belongs to the second layer's input and provides output to the entire rule through if clause that process is evaluated by Eq. (3).

The flowchart of the proposed GFbALO classifier
Moreover, in the second layer, the linguistic value \(w\) is high, low, or normal. Besides, \(wH\), \(wL\) and \(wN\) are denotes the high, low, and normal expansion of the fuzzy membership function \(w\). Moreover, the membership function is processed using the smooth function that is given in Eq. (4),
where \(t = t_{wL}^{{}}\) or \(t = t_{wH}\) is the left or right expansion of the membership function, consequently as \(z < e\) or \(z \ge e\) and \(d\) is the error rate control.
Consequently, the membership function for data training is expressed by Eq. (5),
Here, \(wH\), \(wL\) and \(wN\) are measured as the weights of the input connection. The datasets are trained by the gradient descent approach using Eq. (6),
where, \(T_{ab}\) is the sample data, \(\rho\) is the learning parameter, \(D\) denotes the desired data, \(\phi\) is the network outcome, \(\varsigma_{ab}\) represents the normalized case and \(e_{a}\) denotes the central vector. Furthermore, the trained data provides the input to the third layer, which joins all logic conditions in law. The differentiable softmin based operation is taken in this layer using Eq. (7).
where, \(\mu_{j}\) is the amount of match connecting fuzzy labels attained by rule \((\tau )\) and equivalent input variable. Moreover, \(\omega_{\tau }\) provides an appropriate rule \(\tau\) and \(l\) is the parameter that can smoothen the \(\omega_{\tau }\).
Subsequently, the input of the fourth layer is the entire corresponding rule from the previous layer. The \(\omega_{\tau }\) provided to the layer and estimating accurate outcome as an optional using rule \(\tau\) that function is written in Eq. (8),
where \(w\) is the particular logic label, \(wH\), \(wL\) and \(wN\) are the high, low, and normal expansion of the member function of defuzzification taken as in the inverse form. This inverse function is estimated by Eq. (9),
Then the output of the trained set is given to the input of the linguistic membership purpose. At that time, the local mean of maximum triangular is estimated by Eq. (10).
In this case, where \(\omega_{\tau } = 0\), the \(v + {{(t_{wL}^{{}} - t_{wH}^{{}} )} \mathord{\left/ {\vphantom {{(t_{wL}^{{}} - t_{wH}^{{}} )} 2}} \right. \kern-\nulldelimiterspace} 2}\) is obtained by the limiting value of \(\mu^{ - 1} (\omega_{\tau } \to 0)\). From this, the membership function of the triangular median for the fuzzy condition is estimated as a set of \(\mu^{ - 1} (0,1)\). Besides, the abnormal feature must be reduced due to the various values of multi-outputs. This function can be done by Eq. (11),

Consequently, the fifth layer has various points in its outcome action. Moreover, the entire fuzzy rule output is directed in this layer using Eq. (12),
The conversion performance is enhanced in the 3rd and 4th layers, which is expressed by Eq. (13),
The action \(H\) is done, which is expressed by forebear input label functions. From the output, it predicts every patient’s disease in an accurate manner. However, the weights are modified in the second and fourth layers; otherwise, all layers have uniform weights. Sequentially, the learning in the proposed classifier is enhanced by the plan of \(H_{q} (z)\). Where, \(q\) denotes the computing of total weights in the system, which encloses the high, low, and normal of all logic classes utilized in the fuzzy method. The goal of calculating \(H\) is to exploit \(w\); therefore, the methods attained the finest condition and eliminated error. This process can be done with the use of learning parameters. Moreover, for the logic state \(w\) with constraints \(q_{w}\) with \(x\) position for \(\mu^{ - 1}\), the exploit \(H\) is linear in \(q_{w}\), yet nonlinear in \(\omega_{j}\). Then the value \(x_{\tau }\) is applied to the Eq. (14).
The differential source is associated with the estimation of \(\frac{\partial F}{{\partial qw}}\). Similarly, the antecedent logic point turn is estimated by the Eq. (20),
Therefore, the suitable learning factor is applied to each classifier node to enhance the performance. Moreover, the data weights are regulated between the output layers and the hidden layers; the severity of the disease is diagnosed using the ALO fitness. Therefore, the feature data acts towards back to the system. The predicted output is arranged randomly using Eq. (21),
where \(s(t)\) is the stochastic feature. Moreover, the location regarding the trained feature stored in the data is calculated using Eq. (22).
where \(N_{ANT}\) is the stored data concerning the optimum weights and thresholds, the number of features on the trained data is denoted as \(n\) and \(d\) is the number of inconstant data. Moreover, the equivalent objective function for the optimum severity identification of the disease is estimated by Eq. (23).
where \(N_{OAL}\) is test data fitness concerning every feature, \(g\) is the objective function. The arbitrary data estimation is used for the disease severity that is calculated using Eq. (24).
where \(p_{j}\) is the minimum threshold value in the arbitrary data, \(q_{j}\) is the maximum threshold value in the arbitrary data, \(r_{j}^{t}\) is the minimum threshold value in the arbitrary data at the time of iteration and \(q_{j}^{t}\) denotes the maximum threshold value in the arbitrary data at the time of iteration. Furthermore, the threshold value for the severity prediction is estimated by Eq. (25) and (26).
Moreover, the step for predicting suitable featured data using Eq. (27),
Where, \(R\) is the ratio. Besides, the condition is in Eq. (28) are used for disease prediction thresholds estimation.
Where \(s\) is the present iteration. In which the value is less than 0.1 denotes the lower risks, and greater than 0.1 denotes the higher risks. If the severity of the disease code is greater than the test code or the method attains its utmost iteration, then the best output is reached. Otherwise, the process is continuing to train the GFIbALO model. It provides the determined result to have either positive or negative sickness diagnose. Here, the patient risk is denoted using the threshold level. When every patient’s results exceed the threshold level, it raises a warning signal and sends an alert to the specialists. This method perfectly observes the affiliation between the data in the data set, thus enhancing the total disease prediction process.
5 Results and discussion
In this section, the efficiency of the presented GFIbALO technique is validated mainly for recognizing patients under normal or abnormal conditions. The proposed GFIbALO disease prediction technique is implemented by the MATLAB 2018Rb tool running on the Windows 7 platform. It is a numerical and restrictive programming language created by Math Works. The significant risk features for the input of disease identification and consistent normal ranges along with its coded values are mentioned in Table 1.
5.1 Case study
In this research, more than 500 data are collected by IoT medical device sensors, medical datasets, and medical records. The subcategory of features is chosen from the preprocessed database of disease. The features are gender, age, level of sugar, diastolic blood pressure, systolic blood pressure, LDL cholesterol, total cholesterol, heartbeat rate, body temperature, level of HDL cholesterol, and output. The significant feature scores by regression rule are shown in Fig. 4. During the execution of the proposed idea, the dataset is separated into testing and training data. For testing, seventy percentages of data are taken, and for training, thirty percentages of data are taken to validate the effectiveness of the disease forecasting. Around 50 patient’s data are composed; this information is processed by a certain approach to estimate the efficiency of the techniques. Moreover, the efficiency of the proposed technique is estimated by diverse performance metrics, namely sensitivity, specificity, accuracy, precision, recall, AUC, and error percentage.

Significant feature scores by regression rule
At first, the variation of the system is recognized from the gradient, Mu, and validation fails. Here, the tangent of the slope represents the gradient, the control parameter is mentioned as ‘Mu’, and the validation fails were employed for terminating the function of learning. The maximum number of system training permitted 1000 epochs, the learning speed of the system is 0.09, and the least convergence error of the desired training is 0.001. The GFIbALO classifier’s finest score for various features under the training state with the objective reached after 1000 epochs are shown in Fig. 5. The variation between the sample and validation values is forecasted. The Gradient value is 0.0098721 at epoch 1000, mu is 1e-07 at epoch 1000, and validation fails are zero at epoch 1000. The best score obtained to this point predicting the severity of the diseases using the training group with GFIbALO is shown in Fig. 6. This graph clearly shows the maximum score is 98%, and it is attained for the utmost features over 500 iterations.

GFIbALO training state with objective reached after 1000 epochs

GFIbALO classifier finest scores for various features
In this, the proposed approach is developed to predict the diseases using the IoT sensed data from each person in a particular area. Consequently, the collected data is preprocessed, and the feature extraction is done by the regression tree method that features attributes are generated at this stage.
In this case study, consider the patient as Arun, age is 45, and gender is male. Furthermore, consider patients features as the systolic pressure is 140, diastolic pressure is 120, LDL cholesterol is 239, triglycerides cholesterol is 180, HDL cholesterol is 200, total cholesterol is 479, heartbeat is 98, blood sugar level is 130, and the body temperature is 98. The information about the patient from the dataset is given to the proposed GFIbALO classifier. Also, these data are tested and trained by the proposed classifier using the code value of certain features. Moreover, the patients age is taken as (0), gender (0), heartbeat (0), diastolic pressure is high (1), systolic blood pressure is high (1), LDL cholesterol high (1), LDL cholesterol normal (0), total cholesterol high (1), and body temperature normal (0). These encoded values are entered into the GFIbALO classifiers and then compared with trained and tested data. Moreover, the triangular median membership function is developed,
Rule 1: If the systolic pressure is high and diastolic pressure is high, then Hypertension.
Rule 2: If LDL cholesterol is high, HDL cholesterol is high and total cholesterol is high, then high cholesterol risk to heart diseases.
Rule 3: If LDL cholesterol is low, HDL cholesterol is low and total cholesterol is low, then no disease is affected.
The trained data from the proposed neuro-fuzzy approach is analyzed using the ALO algorithm. The data from the trained process is randomly arranged, and the trained features of data are stored in the matrix system that is mentioned in Eq. (29).
Furthermore, the threshold values are estimated by Eqs. (13) and (24) are applied to arbitrary data. The threshold values for the disease are Heart disease (0), High Cholesterol (2), no disease (3), Hypertension (4) are applied. Moreover, the applied ALO is analyzed the predicted data via the threshold estimation for the risk diagnosis.
Diagnosis: Value 0.1< low risk
Value 0.1> high risk
Furthermore, the proposed GFIbALO classifier predicts the crucial diseases and outcomes from the consideration such as Hypertension stage 2, high cholesterol, risk of heart disease, the LDL cholesterol is high, HDL cholesterol is high, normal heartbeat, high cholesterol is linked to diabetes and high blood pressure, normal temperature.
5.2 Performance evaluation
The presented GFIbALO disease prediction approach interpretation is compared with other conventional techniques, such as High sensitivity-Cardiac Troponin I (hs-CTnI) [33], Hybrid–Decision Tree (H-DT) [34], Multimodal Data-based Recurrent Convolution Neural Network (MD-RCNN) [35], Fuzzy K- Nearest Neighbor network (FKNN) [36], and Deep Trained Neocognitron Neural Network (DTNNN) [37], etc. The performance comparison of accuracy, specificity, sensitivity, precision, and recall depend on the evaluation of True Negative and Positives, False Positive and Negatives of the system. The calculation of TP rate accurately identifies the abnormal health condition, and FP data is the invalid classification of normal conditions as abnormal states from the gathered data. Moreover, the abnormal characteristics from the set of characteristics are termed as TN rate and abnormal condition characteristics if inaccurate identification is termed as FN rate. Furthermore, the sensitivity measure is the metrics to forecast the positive rate when the diseases are present. Consequently, it is essential to assess the correctness of the presented GFIbALO technique; the sensitivity measure is calculated by Eq. (30),
Based on the higher sensitivity estimation, the proposed GFIbALO identifies the issues of diseases with more accurateness. The sensitivity value comparison of the MD-RCNN, FKNN, hs-cTnI, Hybrid DT, DTNNN, and proposed GFIbALO approaches are shown in Table 2.
The proposed GFIbALO method has achieved a high specificity rate (100%) contrasted with the conventional methods such as MD-RCNN (69%), FKNN (90%), hs-cTnI (54%), Hybrid DT (92%), DTNNN (89%), which is shown in Fig. 7. The sensitivity of the proposed GFIbALO method effectively separates the healthy details of the data and withdraws the unhealthy details of the data based on the Eq. (29).

Comparison of specificity (%) with dissimilar classifier techniques
Effective training, investigation, and stimulation tend to improve disease identification’s total accuracy. In congestion with the sensitivity value, the specificity estimation is most important for the effectiveness and accuracy of GFIbALO for predicting the health condition from the data. The specificity rate is estimated by Eq. (31).
Consequently, the proposed method of GFIbALO achieved a high sensitivity rate (100%) compared with existing techniques such as MD-RCNN (70%), FKNN (99%), hs-cTnI (56%), Hybrid DT (92%), DTNNN (99.87%), the graphical representation of the sensitivity along with specificity measure is shown in Fig. 8. The effective preparing, learning, and enactment capacities lead to the general improvement of disease prediction accuracy. Subsequently, the accuracy of the proposed cloud IoT-based GFIbALO in disease prediction is estimated by the accuracy calculation using Eq. (32),

Comparison of sensitivity (FPR) and specificity (TPR) with conventional classifier methods
Accuracy computation is one of the chief metrics in the performance evaluation of the system. The proposed GFIbALO technique attains utmost accuracy for disease prediction is 99.90% compared with other conventional techniques: MD-RCNN (99%), FKNN (96.74%), hs-cTnI (72%), Hybrid DT (88.47%), DTNNN (99.85%), is shown in Fig. 9.

Analysis of proposed GFIbALO with various classifiers in terms of accuracy
Besides, the precision estimation indicates how close the consideration between the repeated estimations, which are computed by Eq. (33).
Consequently, the precision of the proposed GFIbALO (99.86%) is compared with the existing methods are MD-RCNN (99%), FKNN (96.74%), hs-cTnI (72%), Hybrid DT (88.47%), DTNNN (99.85%) shown in Fig. 10.

Analysis of proposed GFI-ALO with various classifiers in terms of precision
Moreover, the recall value can be estimated by Eq. (28) because sensitivity and recall are similar. The recall of the proposed GFIbALO (99.84) is compared with the existing methods are MD-RCNN (98.08%), FKNN (80.5%), hs-cTnI (70%), Hybrid DT (99%), DTNNN (99.84%) shown in Fig. 11. In medical information, recall measure is more important rather than the measure of accuracy. Because a high recall value shows the predicted disease of patients risk and it has a low probability; therefore, the risk of the diseases is not at all.

Analysis of proposed GFIbALO with various classifiers in terms of recall
The proposed GFIbALO method effectively classifies the disease characteristics in less time 10 s compared to the existing techniques, which is shown in Fig. 12. Therefore, the proposed method of disease prediction minimizes the logical complexity while successfully investigating a huge amount of data. The processing time is evaluated based on the k value (0 to 5).

Processing time(s) with various classifiers
Moreover, the MCC is represented as the Matthews correlation coefficient, which is defined as the forecasting capacity of the proposed GFIbALO classifier; the value range is − 1 to +1. Whether the classifier predicts the disease perfectly at the value of MCC is a positive one, else the negative one means the classifier predicted the disease incorrectly. Otherwise, the classifier creates an arbitrary forecast when the MCC is close to zero. The computation of MCC is done by Eq. (34),
The AUC (%) of the proposed GFIbALO classifiers is illustrated in Fig. 13. When the area is nearer to one, then the system is enhanced. The proposed GFIbALO classifiers attained a high AUC is 88%, so the high AUC value is more effective in the performance of the proposed classifiers. Moreover, the training and testing of the proposed GFIbALO classifier attained as 88% and 87.9%, respectively.

AUC values vs. time
The value of AUC is enlarged with time, yet at the time t=10, the value of AUC is approximately residues unchanged. Hence, time t=10 is taken for simplifying the system process.
Besides, the error rate is estimated from an accurate disease prediction, which is estimated by the unity minus accurate disease prediction. Consequently, it is referred to as the misclassified rate of disease prediction. The rate of error \((e)\) is estimated by Eq. (35).
The error rate of the proposed disease prediction in the healthcare system is 0.001 percentages, and it is compared with conventional techniques that are illustrated in Fig. 14. Moreover, the overall interpretation of the presented GFIbALO is compared with existing methods and is given in Table 3.

Comparison of error percentage with different techniques
The sensitivity value, accuracy, precision, and recall of the proposed classifier are high compared with the other classifiers. Sequentially, the computation time is reduced by this GFIbALO of classifiers. Besides, compared with the other conventional classifiers, the proposed GFIbALO classifiers attain a greater area for testing 88% and training 87.9%. Therefore, the higher range of AUC% demonstrates more successful performance of the proposed classifier.
6 Conclusion
This work focused on improving particular and reliable disease prediction model utilizing an ensemble data mining approach. Therefore in this paper, a novel neuro fuzzy-based optimization algorithm is introduced named as GFIbALO approach to predict the patient diseases from the symptoms of a specific analysis. Consequently, the feature extraction process is performed on the dataset using regression rules, and the developed approach calculates the disease severity. Moreover, the proposed disease prediction simulation outcomes are compared with conventional techniques. The proposed method was obtained high accuracy as 99.90% and a precision rate as 99.86%. Thus, the proposed cloud IoT-based disease prediction approach predicts the disease accurately. In the future, hybridization techniques can be utilized to enhance the prediction parameters and improve the system’s security.
References
Rahmani, A.M., Babaei, Z., Souri, A.: Event-driven IoT architecture for data analysis of reliable healthcare application using complex event processing. Cluster Comput. (2020). https://doi.org/10.1007/s10586-020-03189-w
Sharma, S., Chang, V., Tim, U.S., Wong, J., Gadia, S.: Cloud and IoT-based emerging services systems. Cluster Comput. 22, 71–91 (2019). https://doi.org/10.1007/s10586-018-2821-8
Sarmah, S.S.: An efficient IoT-based patient monitoring and heart disease prediction system using deep learning modified neural network. IEEE Access 8, 135784–135797 (2020). https://doi.org/10.1109/ACCESS.2020.3007561
Zhang, C., Zhu, L., Xu, C., Lu, R.: PPDP: An efficient and privacy-preserving disease prediction scheme in cloud-based e-Healthcare system. Future Gener. Comp. Sy. 79, 16–25 (2018). https://doi.org/10.1016/j.future.2017.09.002
Jagadeeswari, V., Subramaniyaswamy, V.: A study on medical Internet of Things and Big Data in personalized healthcare system. Health Inf. Sci. Syst. 6(1), 14 (2018). https://doi.org/10.1007/s13755-018-0049-x
Niemelä, R., Pikkarainen, M., Ervasti, M.: The change of pediatric surgery practice due to the emergence of connected health technologies. Technol. Forecast. Soc. Change 146, 352–365 (2019). https://doi.org/10.1016/j.techfore.2019.06.001
Mutlag, A.A., Ghani, M.K.A., Arunkumar, N.: Enabling technologies for fog computing in healthcare IoT systems. Future Gener. Comp. Sy. 90, 62–78 (2019). https://doi.org/10.1016/j.future.2018.07.049
Pramanik, P.K.D., Upadhyaya, B.K., Pal, S., Pal, T.: Internet of things, smart sensors, and pervasive systems: enabling connected and pervasive healthcare. Healthcare Data Analytics and Management, pp. 1–58. Academic Press (2019). https://doi.org/10.1016/B978-0-12-815368-0.00001-4
Sharma, M., Singh, G.: Need and design of smart and secure energy-efficient IoT-based healthcare framework. Energy Conservation for IoT Devices, pp. 259–281. Springer, Singapore (2019). https://doi.org/10.1007/978-981-13-7399-2_11
ur Rehman, M.H., Yaqoob, I., Salah, K., Imran, M.: The role of big data analytics in industrial Internet of Things. Future Gener. Comp. Sy. 99, 247–259 (2019). https://doi.org/10.1016/j.future.2019.04.020
Talal, M., Zaidan, A.A., Zaidan, B.B., Albahri, A.S.: Smart home-based IoT for real-time and secure remote health monitoring of triage and priority system using body sensors: Multi-driven systematic review. J. Med. Syst. 43(3), 42 (2019). https://doi.org/10.1007/s10916-019-1158-z
Cheng, P.C., Panitch, H.B., Hansen-Flaschen, J.: Transition of patients with neuromuscular disease and chronic ventilator-dependent respiratory failure from pediatric to adult pulmonary care. Paediatr. Respir. Rev. (2019). https://doi.org/10.1016/j.prrv.2019.03.005
Elmisery, A.M., Rho, S., Aborizka, M.: A new computing environment for collective privacy protection from constrained healthcare devices to IoT cloud services. Cluster Comput. 22(1), 1611–1638 (2019). https://doi.org/10.1007/s10586-017-1298-1
Pradhan, N., Rani, G., Dhaka, V.S., Poonia, R.C.: Diabetes prediction using artificial neural network. Deep Learning Techniques for Biomedical and Health Informatics, pp. 327–339. Academic Press (2020). https://doi.org/10.1016/B978-0-12-819061-6.00014-8
Spruit, M., van der Rijnst, S.: Clinical decision support for infection control in surgical care. Innovation in Health Informatics, pp. 101–121. Academic Press (2020). https://doi.org/10.1016/B978-0-12-819043-2.00004-6
Pandey, P., Litoriya, R.: Implementing healthcare services on a large scale: challenges and remedies based on blockchain technology. Health Policy and Technol. (2020). https://doi.org/10.1016/j.hlpt.2020.01.004
Mohammed, K.I., Zaidan, A.A., Zaidan, B.B.: Real-time remote-health monitoring systems: a review on patients prioritisation for multiple-chronic diseases, taxonomy analysis, concerns and solution procedure. J. Med. Syst. 43(7), 223 (2019). https://doi.org/10.1007/s10916-019-1362-x
Burse, K., Kirar, V.P.S., Burse, A., Burse, R.: Various Preprocessing Methods for Neural Network Based Heart Disease Prediction. Smart Innovations in Communication and Computational Sciences, pp. 55–65. Springer, Singapore (2019). https://doi.org/10.1007/978-981-13-2414-7_6
Stergiou, C.L., Plageras, A.P., Psannis, K.E.: Secure Machine Learning scenario from Big Data in Cloud Computing via Internet of Things network. Handbook of Computer Networks and Cyber Security, pp. 525–554. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-22277-2_21
Vitabile, S., Marks, M., Stojanovic, D., Pllana, S.: Medical data processing and analysis for remote health and activities monitoring. High-Performance Modelling and Simulation for Big Data Applications, pp.186–220. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-16272-6_7
Rady, E.H.A., Anwar, A.S. (2019) Prediction of kidney disease stages using data mining algorithms. Inform. Med. Unlocked. https://doi.org/10.1016/j.imu.2019.100178
Samuel, O.W., Yang, B., Geng, Y., Asogbon, M.G.: A new technique for the prediction of heart failure risk driven by hierarchical neighborhood component-based learning and adaptive multi-layer networks. Future Gener. Comp. Sy. (2019). https://doi.org/10.1016/j.future.2019.10.034
Bahremand, S., Ko, H.S., Balouchzadeh, R., Lee, H.F.: Neural network-based model predictive control for type 1 diabetic rats on artificial pancreas system. Med. Biol. Eng. Comput. 57(1), 177–191 (2019). https://doi.org/10.1007/s11517-018-1872-6
Rahman, A., Chakraborty, C., Anwar, A., Karim, M., Islam, M., Kundu, D., Rahman, Z., Band, S.S.: SDN–IoT empowered intelligent framework for industry 4.0 applications during COVID-19 pandemic. Cluster Comput (2021). https://doi.org/10.1007/s10586-021-03367-4
Roldán, J., Boubeta-Puig, J., Martínez, J.L., Ortiz, G.: Integrating complex event processing and machine learning: an intelligent architecture for detecting IoT security attacks. Expert Syst Appl. 149, 113251 (2020). https://doi.org/10.1016/j.eswa.2020.113251
Hajvali, M., Adabi, S., Rezaee, A., Hosseinzadeh, M.: Software architecture for IoT-based health-care systems with cloud/fog service model. Cluster Comput. (2021). https://doi.org/10.1007/s10586-021-03375-4
Ali, H.M., Liu, J., Bukhari, S.A.C., Rauf, H.T.: Planning a secure and reliable IoT-enabled FOG-assisted computing infrastructure for healthcare. Cluster Comput. (2021). https://doi.org/10.1007/s10586-021-03389-y
Darwish, A., Hassanien, A.E., Elhoseny, M.: The impact of the hybrid platform of internet of things and cloud computing on healthcare systems: opportunities, challenges, and open problems. J. Amb. Intel. Hum. Comp. 10(10), 4151–4166 (2019). https://doi.org/10.1007/s12652-017-0659-1
Farahani, B., Firouzi, F., Chang, V., Badaroglu, M.: Towards fog-driven IoTeHealth: promises and challenges of IoT in medicine and healthcare. Future Gener. Comp. Sy. 78, 659–676 (2018). https://doi.org/10.1016/j.future.2017.04.036
Allison, J.J., Kiefe, C.I., Weissman, N.W., Person, S.D.: Relationship of hospital teaching status with quality of care and mortality for Medicare patients with acute MI. JAMA 284(10), 1256–1262 (2000). https://doi.org/10.1001/jama.284.10.1256
American Diabetes Association: 2. Classification and diagnosis of diabetes: standards of medical care in diabetes—2019. Diabetes Care 42, Supplement 1, S13-S28 (2019).
Nothelle, S.K., Sharma, R., Oakes, A.H., Jackson, M.: Determinants of potentially inappropriate medication use in long-term and acute care settings: a systematic review. J. Am. Med. Dir. Assoc. 18(9), 806-e1 (2017). https://doi.org/10.1016/j.jamda.2017.06.005
Hamaya, R., Yonetsu, T., Kanaji, Y., Usui, E., Hoshino, M.: Interrelationship in the prognostic efficacy of regional coronary flow reserve, fractional flow reserve, high-sensitivity cardiac troponin-I and NT-proBNP in patients with stable coronary artery disease. Heart Vessels 34(3), 410–418 (2019). https://doi.org/10.1007/s00380-018-1260-z
Nazir, N., Rajab, S., Sharma, V.: State-of-the-Art artificial intelligence techniques in heart disease diagnosis. emerging trends in expert applications and security, pp. 651–657. Springer, Singapore (2019). https://doi.org/10.1007/978-981-13-2285-3_76
Hao, Y., Usama, M., Yang, J., Hossain, M.S.: Recurrent convolutional neural network based multimodal disease risk prediction. Future Gener. Comp. Sy. 92, 76–83 (2019). https://doi.org/10.1016/j.future.2018.09.031
Malathi, D., Logesh, R., Subramaniyaswamy, V.: Hybrid reasoning-based privacy-aware disease prediction support system. Comput. Electr. Eng. 73, 114–127 (2019). https://doi.org/10.1016/j.compeleceng.2018.11.009
Vijayashree, J., Sultana, H.P.: Heart disease classification using hybridized Ruzzo-Tompamemetic based deep trained Neocognitron neural network. Health Technol (2019). https://doi.org/10.1007/s12553-018-00292-2
Acknowledgements
None.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no potential conflict of interest.
Ethical approval
All applicable institutional and/or national guidelines for the care and use of animals were followed.
Informed consent
For this type of study formal consent is not required.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Verma, A., Agarwal, G. & Gupta, A.K. A novel generalized fuzzy intelligence-based ant lion optimization for internet of things based disease prediction and diagnosis. Cluster Comput 25, 3283–3298 (2022). https://doi.org/10.1007/s10586-022-03565-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-022-03565-8