
Abstract
Biomarkers are important for early detection of cancer, prognosis, response prediction, and detection of residual or relapsing disease. Special attention has been given to diagnostic markers for prostate cancer since it is thought that early detection and surgery might reduce prostate cancer-specific mortality. The use of prostate-specific antigen, PSA (KLK3), has been debated on the base of cohort studies that show that its use in preventive screenings only marginally influences mortality from prostate cancer. Many groups have identified alternative or additional markers, among which PCA3, in order to detect early prostate cancer through screening, to distinguish potentially lethal from indolent prostate cancers, and to guide the treatment decision. The large number of markers proposed has led us to the present study in which we analyze these indicators for their diagnostic and prognostic potential using publicly available genomic data. We identified 380 markers from literature analysis on 20,000 articles on prostate cancer markers. The most interesting ones appeared to be claudin 3 (CLDN3) and alpha-methysacyl-CoA racemase highly expressed in prostate cancer and filamin C (FLNC) and keratin 5 with highest expression in normal prostate tissue. None of the markers proposed can compete with PSA for tissue specificity. The indicators proposed generally show a great variability of expression in normal and tumor tissue or are expressed at similar levels in other tissues. Those proposed as prognostic markers distinguish cases with marginally different risk of progression and appear to have a clinically limited use. We used data sets sampling 152 prostate tissues, data sets with 281 prostate cancers analyzed by microarray analysis and a study of integrated genomics on 218 cases to develop a multigene score. A multivariate model that combines several indicators increases the discrimination power but does not add impressively to the information obtained from Gleason scoring. This analysis of 10 years of marker research suggests that diagnostic and prognostic testing is more difficult in prostate cancer than in other neoplasms and that we must continue to search for better candidates.
Similar content being viewed by others


1 Introduction
Prostate cancer is the most commonly diagnosed non-skin cancer and the second leading cause of cancer death for males in the USA. More than 240,000 men were diagnosed with the disease and more than 33,000 died of it in 2011 [1]. If the current prostate-specific antigen-based screening schemes will be applied in the future, it can be estimated that 16.2 % of American men alive today will be diagnosed with the neoplasm and approximately 3 % will die of it. There is a general epidemiological trend towards growing incidence while mortality is stable. The increasing incidence is particularly evident for the period between 1980 and 1995 in affluent countries and at present in emerging countries [2]. This trend is probably at least in part due to the introduction of prostate cancer screening using prostate-specific antigen (PSA) as a marker. Introduction of PSA [3] has led to a drastic increase in the early detection of prostate cancer resulting in an increased reported incidence, in part due to indolent cancers.
PSA, a marker for prostate cells [4], is not specific for prostate cancer. Currently, PSA is used both as a diagnostic marker for early detection of prostate cancers and for follow-up after surgery or during prostate cancer therapy. PSA is expressed almost exclusively by the prostate; therefore, its expression is tightly linked to the presence of prostatic cells. After the initial clearance of residual PSA from the serum of patients who had their prostate surgically removed, increasing PSA levels indicate the presence of disseminated and eventually growing cells. During chemical castration, growing PSA levels can indicate failure of the therapy. While it is recognized an undisputable value as a follow-up marker, there is a longstanding discussion on its use as a diagnostic marker. The U.S. Preventive Services Task Force has reviewed the existing evidence for the benefit of PSA screening and has issued a recommendation against PSA screening in men over 65 years old in 2008 [5] that has been extended to younger men as a draft in 2011 [6] confirmed in 2012 [7]. The recommendation is based on two clinical trials that come to opposite conclusions: the US Prostate, Lung, Colorectal, and Ovarian cancer screening trial [8] showed an increased absolute risk of prostate cancer-specific mortality of 0.2/1,000 men associated with screening, whereas in the European Randomized Study of Screening for Prostate Cancer (ERSPC) [9], screening was associated with a decreased absolute risk of prostate cancer mortality of 0.6/1,000 men. The two associations were not statistically significant but, applying the statistical analyses planned a priori, a significant reduction of mortality (0.7/1,000 men; 1,410 screenings to prevent 1 death) was detected for the subgroup of men aged 55 to 65 years only in ERSPC.
PSA velocity, the increase over time of PSA serum levels, has been proposed as a more specific marker for cancer [10] but there is contrasting evidence [11]. The increase of PSA levels in the year before surgery identifies more aggressively growing cancers [12]. Most of PSA is bound to serum proteins and a minor part is free in the serum. The use of free PSA or the ratio between free and serum protein-bound PSA as markers may reduce unnecessary biopsies for men with relatively low PSA levels between 4 and 10 ng/ml [13].
A more recent addition to the urologist's toolbox is the prostate cancer antigen 3, PCA3, identified by Bussemaker and colleagues in 1999 [14] under the name DD3 using digital display screening for prostate cancer-specific RNAs (for a recent review see [15]). PCA3 is a non-coding RNA of unknown function. It is analyzed by RNA amplification methods from urine sediments after prostate massage [16]. In contrast to PSA, PCA3 is specifically expressed by prostate cancer cells [17]. The increased specificity is contrasted by a reduced sensitivity and PCA3 is therefore applied in association with PSA where it can reduce the number of unnecessary biopsies after a negative biopsy in men with elevated PSA levels [18, 19]. PCA3 may also have some prognostic potential inasmuch as its expression correlates with the Gleason score [20, 21], yet it has not been reported whether the combination of PCA3 and Gleason can improve prognostic power.
While the discussion on the appropriateness of PSA (and PCA3) screening is still open, it is widely held that improved biomarkers, especially biomarkers that distinguish normal prostate tissue from prostate cancer and markers associated with aggressive disease, could greatly improve prostate cancer screening results and deliver the benefit of early diagnosis and appropriate treatment to many men.
Cancer biomarkers are invaluable for early detection of cancer. An ideal marker would be expressed by tumor cells but not by the normal counterpart or other tissues. Diagnostic markers are applied to screening of healthy people, in particular of those with an elevated specific risk and must therefore be measurable in the least invasive manner possible. Although screening programs invariably lead to some degree of overdiagnosis, early detection has led to a reduction in cancer mortality for breast cancer (mammography, echography) [22], cervical cancer (Papanicolaou test, HPV screening) [23], and colon cancer (occult fecal blood, colonoscopy) [24].
Prognostic biomarkers can help to distinguish relatively benign cancers from aggressive ones and might orient treatment decisions. These markers are useful post-detection where they should be able to distinguish aggressive disease so as to direct the surgical/therapeutic intervention that might be unnecessary for non-aggressive cancers. Prognostic histopathological analyses are standard for many cancers, and prognostic gene expression signatures are being applied to the treatment decision for breast cancer [25–27].
Predictive markers can detect drug sensitivity or resistance guiding the treatment choice. These markers are useful after diagnosis and most often are detected in tissue samples obtained by biopsy or surgery. Examples of predictive markers are epidermal growth factor receptor (EGFR) and k-RAS mutations in non-small cell lung cancer that guide the use of EGFR-specific tyrosine kinase inhibitors [28] or HER2 overexpression or amplification that indicates the treatment with anti-HER2 antibodies [29] or adjuvant anthracyclines [30].
Follow-up markers allow for the screening of residual or relapsing disease and should be measured in a noninvasive way, by the analysis of sera, plasma, or urine. Serum PSA, in particular free PSA, is widely used as a follow-up marker after surgery and during therapy given its specificity for prostate tissue [31]. In addition, specific radiation response markers for prostate cancer have been proposed [32, 33]. New markers are therefore mostly needed for screening, for early diagnosis, and for prognosis.
PSA is almost exclusively produced by the prostate and released into the serum. Yet, its use as a diagnostic marker is limited by the fact that it is also expressed in healthy prostate tissue and that circulating levels can be elevated in subjects with prostatitis, inflammation, benign prostatic hyperplasia [34], and after recent ejaculation [35]. In addition, the PSA screening trials show that many diagnosed prostate cancers do not develop into a life-threatening disease. Further, prostate cancer can develop in individuals whose PSA levels remain low.
Biomarker research today can rely on a large number of publicly available data that allow for in-depth analyses of the association between gene expression and clinical and histopathological variables. Our aim in this study is to review the state of the art and eventually to restrict the number of candidate markers to those with molecular characteristics and expression profiles compatible with a selective marker function. We have analyzed the literature over the last 10 years identifying a large number of markers that have been proposed as diagnostic or prognostic markers for prostate cancer. We analyzed these markers using several datasets for their ability to discriminate healthy and neoplastic prostate tissue and for their capability to predict the clinical behavior of the tumors. Finally, we tried to develop prognostic signatures on the base of the published markers. Our results show that the proposed markers either taken alone or combined in a signature have a limited diagnostic or prognostic power and that further studies need to be done across an increasing range of potential marker sources.
2 Methods
2.1 Identification of prostate cancer markers
PubMed was screened for scientific articles published from 2001 to 2011 with the terms “prostate” AND “marker*” or “prostate” AND “biomarker*” in any field. The articles identified were manually analyzed for genes encoding the prostate cancer biomarkers reported. For markers that were reported in more than one paper, the paper publishing the marker for the first time was used as a reference. No further filtering was applied. All markers were considered without regard to the nature of the originally proposed markers (protein or mRNA) or the analysis method used. The official gene symbol and the Ensembl accession number of the genes encoding the markers were identified using the gene ID conversion tool of DAVID Bioinformatics Resources 6.7 (http://david.abcc.ncifcrf.gov/) [36], and the resulting list was manually managed in order to obtain the gene IDs for all markers. All markers considered are listed in Supplementary Table 1.
2.2 Datasets used
General gene expression data have been obtained from the GeneSapiens database. Briefly, GeneSapiens (http://www.genesapiens.org/) [37] is a collection of 9,873 Affymetrix microarray gene expression profiling experiments. All samples are reannotated and normalized with a custom algorithm. The data are collected from various publicly available sources, including Gene Expression Omnibus and ArrayExpress and cover 175 different tissue types. Mean expression of each gene was determined in prostate cancer (n = 349) and healthy prostate (n = 147).
For the evaluation of the prognostic potential of markers, we used gene expression data of prostate cancers of the Swedish Watchful Waiting cohort with up to 30 years of clinical follow-up data set sampling 281 prostate cancers analyzed by microarray analysis of formaldehyde-fixed formalin-embedded specimens (GSE16560) [38]. We used the GSE21034 dataset [39] for external validation. This dataset derives from a study of integrated genomics of 218 prostate cancers. The gene expression analysis was performed using Affymetrix Exon 1.0 microarrays.
For additional analyses of marker expression in normal and tumoral tissue, we used the GSE6919 dataset containing 152 human samples including prostate cancer tissues, prostate tissues adjacent to tumor, and organ donor prostate tissues, obtained from men of various ages [40, 41].
2.3 Statistical analyses
All biomarkers extracted from the literature for which a corresponding probe set was present on the two array platforms used were used for all analyses irrespective of the scope for which they have been designed (diagnostic or prognostic markers). Thus, we should be able to detect eventual prognostic power of diagnostic markers and vice versa as well as the original application. For gene expression analyses in prostate cancer versus normal prostate tissue, Student's t test was used.
Correlations with survival were performed using the GSE16560 and GSE21034 datasets. All markers for which probe sets were present were analyzed using the complete dataset. The prognostic value of the signature was tested by Kaplan–Meier survival analysis and Cox regression analysis. As endpoints, we used survival (“indolent” = over 10 years survival after diagnosis and “lethal” = death within 10 years after diagnosis) for GSE16560 and distant metastasis for GSE21034 since the latter contained only few disease-specific deaths.
3 Results
The analysis of the literature has led to the identification of over 20,000 articles on prostate markers published between January 1, 2001 and June 1, 2011. Articles published in journals not indexed in the Journal Citation Reports and articles reporting on markers that are not measured as mRNA or protein expression were omitted from further analyses. Two hundred forty-four articles report for the first time at least one new mRNA or protein marker for a total of 380 markers. There is a trend towards slightly increasing numbers of articles reporting prostate cancer markers over time (Fig. 1a). The studies have been published in journals with a wide range of impact factors from 0.822 (Ca. J. Urol) to 18.97 (J. Clin. Oncol.) (Fig. 1b). The complete bibliography containing the list of references for all studies included in this analysis is available as Supplementary Table 1.

Publications on prostate cancer biomarkers 2001–2011. a Publications per year. b Distribution of publications according to impact factor
We analyzed all markers together irrespective of the potential application (diagnostic, prognostic, or follow-up) of the marker claimed in the original publication. We evaluated the markers for their diagnostic potential using a set of microarray data of the GeneSapiens database containing 147 normal prostate and 329 prostate cancer tissues. Of the 287 markers identified in the microarray data, 143 markers had significantly different expression values when normal and cancer tissues were compared (p < 0.01). Figure 2 shows the ten markers with highest (downregulated in cancer) and ten with the lowest (overexpressed in cancer) expression ratio and, for comparison, kallikrein-related peptidase 3 (KLK3), the gene encoding PSA. The lowest score, 0.46, is attained by filamin C (FLNC) [42] and the highest score, 3.00, by claudin 3 (CLDN3) [43] (KLK3/PSA = 0.56). The data for all markers are reported in Supplementary Table 2.

Expression of prostate cancer biomarkers in healthy and tumoral prostate tissues. The ratios of expression in healthy and tumoral prostate tissues of the 20 prostate cancer biomarkers that are most significantly differentially expressed are reported. KLK3 (PSA) has been added for comparison
We investigated the expression of the markers in an independent dataset (GSE6919) containing data from 152 human prostate tissues including normal prostate tissue from healthy donors, prostate cancers, peritumoral tissues, and prostate metastases. Hierarchical clustering of the expression data for the 380 markers reveals that almost all of the metastases and many of the tumor tissues cluster together in a cluster distinct from the clusters containing mainly peritumoral and normal tissues, indicating that the combination of markers distinguishes to some extent healthy and tumor tissues. However, the clusters formed are not strongly distinct as the distances in the dendrogram are short (Fig. 3a). When the same analysis is limited to the 20 markers from Fig. 2 whose expression is most different in normal versus tumor tissues, the clusters formed become slightly more robust and all the metastases and the majority of tumors are in one cluster, yet the clusters are still not very distinct (Fig. 3b).

Hierarchical clustering marker gene expression in human prostate tissues from dataset GSE6919 using Euclidean distance measures and average linkage. The state of the tissue is indicated by a color code in the bar above the dendrogram (green = prostate tissues from healthy donors, yellow = peritumoral tissue, orange = tumor tissue, red = metastases). For markers represented by more than one probe set on the array, all probe sets were included in the analysis. a All prostate cancer biomarkers. b The 20 best markers from Fig. 2
Figure 4 reports the expression scatter plots of the two markers with the strongest overexpression in cancer (alpha-methylacyl-CoA racemase/AMACR [44] and CLDN3 [43]) and in normal (FLNC [42] and keratin 5/KRT5 [45]) tissue and KLK3/PSA for comparison. The new markers do not appear to be clearly superior to KLK3/PSA inasmuch as their expression is not drastically different in normal and cancerous tissues and their expression in normal and cancer tissues varies widely not allowing for the classification of single patients according to the expression levels, although the expression differences are statistically significant.

Expression scatter plots of the four best prostate cancer biomarkers (claudin 3 (CLDN3), alpha-methylacyl-CoA racemase (AMACR), keratin 5 (KRT5), filamin C (FLNC)) in comparison to KLK3 (PSA). Expression data for healthy, peritumoral, tumoral, and metastatic prostate tissues are shown for the four most differentially expressed markers in comparison to KLK3 (PSA)
The different significance level of the “new” markers as compared to KLK3/PSA (p = 1.2 × 10−16 for FLNC, 1.67 × 10−9 for CLDN3, 1.89 × 10−3 for KLK3/PSA) could indicate that these markers are more powerful for the discrimination of cancer and normal tissue. The potential as a diagnostic marker depends, however, at least for serum markers, also on the prostate-specific expression as compared to other tissues. We therefore used the GeneSapiens set of microarray data to monitor tissue-specific expression of the new markers as compared to KLK3/PSA. Figure 5 reports the expression patterns for the four best new markers and KLK3/PSA. This analysis shows that despite the greater expression difference in normal versus cancer tissues, the new markers are unlikely to be superior to KLK3/PSA given their widespread expression in other normal and neoplastic tissues as well as in tissues affected by other diseases. The prostate specificity of KLK3/PSA is unmet.

Relative expression of prostate cancer biomarkers in various tissues a claudin 3 (CLDN3), b alpha-methylacyl-CoA racemase (AMACR), c filamin C (FLNC), d keratin 5 (KRT5), e KLK3/PSA. Note that only KLK3/PSA is highly specific for prostate tissues
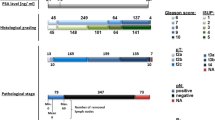
We next asked whether the markers identified have any prognostic potential. We used the GSE16560 dataset of 281 prostate cancers. The samples are derived from FFPE material from transurethral resection of prostate at the time of the initial diagnosis. Patients who died of the disease within 10 years (n = 140) and patients who survived at least 10 years (n = 141) were selected for the analysis allowing for a clear-cut distinction. For 280 of the 380 proposed markers, a corresponding probeset could be identified on the arrays used for this study. Hierarchical clustering of the gene expression data of these markers did not show strong associations of gene expression values with status (lethal or indolent) or Gleason score (Fig. 6).

Hierarchical clustering of 281 prostate cancer tissues. Gene expression values of the genes encoding potential prostate cancer biomarkers in 281 prostate cancers from dataset GSE16560 were clustered using Euclidean distance measure and average linkage. Cancer status (indolent = white, lethal = black) and Gleason score (5 = green, 6 = yellow, 7 = orange, 8 = pink, 9 = red) are indicated in the bars above the dendrogram
In order to identify the prognostic potential of single markers, we performed Cox regression analyses using the same dataset. Figure 7 shows Kaplan–Meier survival curves for two markers, BIRC5/survivin [46] and NKX3-1 [47, 48], among those with the lowest logrank test p value (p = 0). Low-risk and high-risk cases show a significantly different survival, yet it is unlikely that differences as observed here could guide treatment decisions or follow-up screenings. The collection of Kaplan–Meier curves for all markers analyzed is available as Supplementary Fig. 1.

Kaplan–Meier survival analysis of prostate cancer biomarkers. Kaplan–Meier curves for the two markers with the most significant prognostic potential based on data from dataset GSE16560 are shown
Multigene signatures have been shown to have a considerable prognostic power for several cancers [49]. We therefore asked whether a multivariate score of the markers that are significantly differentially expressed between low- and high-risk cases has a clinically relevant prognostic power. The multivariate model was calculated in a backward manner in order to leave as many genes in the model as possible. The genes selected for the model are the ATP-binding cassette (ABC) transporter with unknown substrate and function (ABCA5) [50], the engrailed homeobox gene 2 (EN2) [51], the 17-beta-hydroxysteroid dehydrogenase type 3 that converts androstenedione to testosterone (HSD17B3) [52], the NK3 homeobox 1, a negative regulator of epithelial cell growth in prostate tissue, (NKX3-1) [47], the signal transducer and activator of transcription 6 that mediates the anti-apoptotic effects of interleukin 4 (STAT6) [53], the E2F transcription factor 1 that is involved in the control of cell cycle progression (E2F1) [54], the folate hydrolase (prostate-specific membrane antigen) 1, a glutamate carboxypeptidase (FOLH1) [47], the proteasome (prosome, macropain) subunit, alpha type, 7 that plays a role in the cellular stress response by regulating hypoxia-inducible factor 1 alpha (PSMA7) [55], and the topoisomerase (DNA) II alpha (TOP2A) [54]. Table 1 shows the results of the multivariate analysis. A score indicating the strength of correlation between the expression of the given gene and survival (column B) is calculated for each gene. The global multigene score (MGS) is obtained by the sum of the expression values multiplied by the score assigned. The median value of the score is then used to classify the samples in low and high risk. Kaplan–Meier survival curves for the commonly used Gleason scoring system (Fig. 8a), the presence or absence of the fusions involving the V-Ets erythroblastosis virus E26 oncogene homolog (ERG; Fig. 8b), and the multigene score are plotted (Fig. 8c). All three prognostic measures yield risk classes with significantly different risk of death from prostate cancer (logrank test p = 0). The discrimination of high- and low-risk groups using the multigene score (Fig. 8c) is clearly superior to that observed for single genes (see Fig. 7 and Supplementary Fig. 1). The survival differences of the low- and high-risk groups are evident from the very beginning of follow-up. After 5 years, approximately 86 % of the low-risk cases and 56 % of the high-risk cases are alive, and after 10 years, these figures become 73 and 24 %, respectively. This analysis shows that the combined score can distinguish prostate cancer patients with a significantly different risk of death of prostate cancer, similar to what is obtained by Gleason scoring (Fig. 8a). ERG fusions found in 46 cases (226 cases without fusion, for 9 cases the fusion status is unknown) also confer a bad prognosis, yet the absence of a fusion is not a good indicator of an indolent evolution of the cancer (Fig. 8b).

Multivariate models for prostate cancer prognosis. Prognostic prostate cancer biomarkers were combined in a prognostic multigene model using multivariate Cox regression analysis and dataset GSE16560 (see also Table 1). a Kaplan–Meier survival analysis applying Gleason score (low risk = <7 or 7 (=3 + 4), high risk = >7 or 7(=4 + 3)). b Kaplan–Meier survival analysis for cases with and without rearrangements of the gene ERG. c Kaplan–Meier survival analysis for the multigene score; cases are assigned according to the median of the score. d Combination of Gleason score with the multigene score (assignment of cases as above). e Combination of ERG fusion status and multigene score. f Application of the model to the external dataset GSE21034. The scores calculated on GSE16560 were directly applied
The Gleason scoring system [56] is commonly used for prostate cancer prognosis. The combination of new molecular markers with the Gleason score must be assessed. We therefore calculated Kaplan–Meier survival curves for cases with a Gleason score below 7 or equal to 7 (=3 + 4) and cases with Gleason > 7 or equal to 7 (=4 + 3). The application of the combined marker score to the former cases shows an improved distinction of low- and high-risk cases (Fig. 8d) and cases with low Gleason score and low-risk multigene score show a clear difference in survival from the very beginning of follow-up as compared to cases where both scores indicate high risk. Cases with low and high Gleason score are further divided by the application of the MGS. This creates two intermediate groups (Gleason low, MGS high; Gleason high, MGS low) with similar Kaplan–Meier curves (Fig. 8d). Combination of the MGS with ERG fusion status shows that MGS low-risk cases without fusion have a good prognosis and cases with MGS high risk or the ERG fusion, or both, have a bad prognosis (Fig. 8e). Cases can be classified considering at high risk those cases that receive an indication of high risk by either the Gleason score or the MGS thus considering the intermediate cases as high risk. In this way, an additional 40 of 162 cases with Gleason 6 or 7 (=3 + 4) would be correctly identified as high-risk cases at the expense of 20 indolent cases that would be considered at high risk (Table 2). If instead Gleason 7 would be considered high risk with no regard of the status of the major and minor components of the tumor, additional 39 would be correctly identified as high risk yet 40 actually indolent cases would be classified at high risk. The combination of the MGS with Gleason can therefore be expected to slightly improve the assessment of cases with Gleason score of 6 or 7 (see also Table 2).
Calculation of multigene scores often leads to over-fitting yielding scores that strongly depend on the specific dataset on which they have been calculated. To avoid over-fitting, the dataset must be randomly divided into a training set on which the score is calculated and a test set to which the score is applied [57]. When we applied this strategy to the selected prostate biomarkers, the resulting risk classes show a significantly different risk (logrank test p = 0) in the training set. The same score yields a similar distinction when applied to the test set that also is statistically significant (logrank test p = 0.005) (Supplementary Fig. 2).
We further validated the MGS on an external dataset (GSE21034). The application of the MGS to this dataset also yielded risk classes with significantly different risks (p = 0.002; Fig. 8f). This dataset is based on a completely different array type (exon arrays) and probe design. Thus, the application of the score calculated on the data derived from a different platform can lead to an underestimation of the discrimination power of the classifier.
Finally, we asked whether the many biomarkers identified are functionally interrelated or independent. For this purpose, we performed a correlation analysis using more than 10,000 microarray gene expression data sets. Figure 9 shows the correlation heat map. There is generally a considerable correlation (r > 0.5) of any marker with several others. In order to understand whether correlated markers belong to groups of genes that exert similar functions or participate in similar biological processes, we analyzed the enrichment of gene ontology terms using the Database for Annotation, Visualization and Integrated Discovery [58] for the four predominant, yet arbitrarily selected clusters of the correlation map. Cluster 1 (Fig. 9) shows enrichment of several angiogenesis-related gene ontology (GO) annotations; most of which contain the angiogenic factors VEGFA and VEGFC as well as HGF. Cluster 2 shows an enrichment of extracellular matrix-related GO terms dominated by several matrix metalloproteinases (MMP2, MMP9, and MMP13). Cluster 3 shows GO terms related to peptidase activity containing several kallikreins and in cluster 4 epithelial–mesenchymal transition-related GO categories predominate (see Supplementary Table 3 for complete data). These four biological processes are clearly related to cancer development and progression. Interestingly, cell growth and proliferation are not among the most enriched GO terms despite the important role of cell proliferation in cancer prognosis.

Correlation map of prostate cancer biomarkers. The expression correlation of the prostate cancer biomarkers is calculated and plotted as a heat map. Strong correlations are indicated by a color code (blue, <−0.5; red, >0.5). Arbitrarily selected clusters containing markers with high correlation are indicated by black squares (1–4): Cluster 1 – enrichment of angiogenesis-related genes; Cluster 2 – enrichment of extracellular matrix- and matrix metalloproteinases; Cluster 3 – enhanced peptidase activity and kallikreins; Cluster 4 – enrichment for epithelial–mesenchymal transition
4 Discussion
The identification of prostate cancer biomarkers is a very active field of research. The mean impact factor of the journals in which the prostate cancer biomarkers analyzed here were published is 5.41 (range 0–18.97) reflecting the relatively high attention that the scientific community is giving to this research. The markers that show some value in this meta-analysis are published in journals with a mean impact factor of 4.63 (range 0–8.234) and 5.72 (range 4.411–7.338) for potential diagnostic and prognostic markers, respectively. Hence, there is no evidence of valid markers being published in journals with an impact factor higher than the mean.
The interest in prostate cancer biomarkers derives from the high incidence of this disease and the considerable variability in aggressiveness that ranges from almost benign to life threatening. Yet, even more emphasis in the field stems from the debate on the value of PSA screening that has culminated in the recent recommendation against screening issued by U.S. Preventive Services Task Force [7]. The balance to be found between benefits (saved lives) and costs (unnecessary surgery) could be greatly influenced by better markers. More effective biomarkers would improve the discrimination between healthy and tumor tissue and, perhaps even more importantly, allow for improved prognostication that could identify indolent cancers and limit surgery/intervention to patients who are at risk to die from the disease.
We have extracted 380 markers from the literature of 10 years and we analyzed these markers using publicly available datasets for prostate cancer. This approach has clear limits: (a) only gene expression data are used, (b) not all the data have been raised in controlled studies aimed at the identification of prostate cancer biomarkers, and (c) not all markers are represented in the dataset used (in particular, the non-coding RNA marker PCA3/DD3 [14] that is widely used in combination with PSA was not present in the dataset analyzed). Our study can therefore not exclude that some of the markers might perform much better if analyzed at the protein level since mRNA expression and protein expression are separated by several levels of regulation or that the markers not represented in the dataset used might perform better than those present. The aim of our study is to verify whether the efforts of 10 years of research can be condensed in a multigene prognostic classifier. In addition, this study raises concern on markers that are widely expressed and whose expression levels, even when protein expression is analyzed, are likely to be influenced by expression in other tissues. Finally, this study indicates how in silico analyses should be integrated in early phases of biomarker development in order to avoid unnecessary laboratory work.
The evaluation of the markers for a potential application in the diagnosis of prostate cancer did not yield evidence of any new marker that might substitute or complement PSA. Several markers show a more differential expression between normal and neoplastic prostate tissue than PSA yet, in contrast to the latter, they are expressed by several other normal and neoplastic tissues as well. The wide variability of expression of these markers with overlapping ranges for normal and tumor tissue makes the diagnostic assessment of the single patient difficult. It can therefore not be expected that any of these markers can resolve the problems associated with PSA-based early diagnosis of prostate cancer.
The validation of these mRNAs as prognostic markers yields a series of candidates that can discriminate cases with higher and lower risk, yet none of them appears to be clinically relevant. In addition to statistical significance, the marker sought should discriminate risk classes that deserve different therapeutic approaches. Minor yet statistically significant differences are irrelevant for the treatment decision. The combination of those markers that contribute independently to the risk assessment in a multivariate model appears to yield a discrimination of high- and low-risk cases that could be helpful in the clinics. But if the model is combined with the Gleason score, most of its potential disappears since there are few cases where Gleason score and the multigene model are strongly discordant (i.e., Gleason 6 and multigene high risk). The addition of the MGS mainly affects classification of Gleason score 7 cases.
Chen and coworkers recently reported on a seven-gene prognostic classifier for prostate cancer that they developed applying a preselection of samples mainly composed of tumor cells [59]. Similar to what we observe here, the seven-gene signature adds little to Gleason classification. The preselection procedure excludes many samples since prostate cancers typically contain a large stromal component. This also reduces the clinical applicability. Concordance of gene expression signatures with the prognostic Gleason score that we observe here has been observed by several groups [59, 60]. A nine-gene signature has been developed for the analysis of mRNAs isolated from whole blood cells [61]. This signature distinguishes rapidly progressing cancers among already castration-resistant prostate cancers and can therefore not be considered a general prognostic signature. Most of the patients in this cohort died during the follow-up of 36 months [61].
The question arises of why multigene signatures should work for breast cancer [62] but, at least so far, not or much less so for prostate cancer [38]? Several aspects of prostate cancer biology could contribute to an answer:
-
1.
The main discriminator of high- and low-risk breast cancers is proliferation, and in fact, the simple assessment of the proliferative potential of breast cancers using KI-67 or aurora kinase A as markers performs almost as well as current multigene signatures [63]. Most prostate cancers have a particularly slow progression, and proliferation might be less prognostic in prostate cancer than in breast cancer.
-
2.
Multifocal presentation and focal heterogeneity of prostate cancer may lead to sampling errors for prognostic assessment much more frequently in prostate cancer as compared to breast cancer.
-
3.
Breast cancers derive from two different cell populations, luminal or basal cells, and the cell type they derive from determines most of the metastatic risk [64]. Perhaps prostate cancers derive from a more homogenous cell population, giving rise to a more homogeneous progression scheme.
-
4.
The introduction of PSA screening has led to the identification of many low-risk cases that would not have been detected without screening. The numeric imbalance between low- and high-risk cases can make the identification of the latter more difficult (yet, this is not the case for the dataset on which we validated the prognostic power here).
-
5.
Prostate cancer therapy is relatively successful leading to extended survival even of cases with largely dedifferentiated cells (high Gleason score). Death from prostate cancer is due to resistance to therapy (i.e., androgen-independent growth) that depends on acquired molecular alterations not present at the time of first diagnosis.
-
6.
Gene expression profiles are dominated by transcription events that determine cell morphology. The influence of cell morphology on tumor progression might already be optimally assessed by the Gleason scoring system.
-
7.
Tumor progression and metastasis are intrinsically stochastic. In the absence of other determinants, prostate cancer progression follows probability.
-
8.
Important determinants of prostate cancer progression are not or not reliably reflected by gene expression. Identification of new mutations might allow for the identification of high-risk classes in analogy to the effect of ERG fusion genes [65, 66].
The identification of prostate cancer markers remains a challenge to be pursued by adding new technological approaches. Array comparative genome hybridization has revealed structural and numerical genomic alterations that correlate with outcome independently of Gleason scoring [39], and next generation sequencing (exome sequencing) has revealed a series of new mutations in prostate cancer whose prognostic value has yet to be determined [39, 65, 66]. Further, expression of new potential markers such as microRNAs and other non-coding RNAs may provide new avenues of investigation [67] as well as use of novel approaches for metabolic markers [68].
References
Brawley, O. W. (2012). Prostate cancer epidemiology in the United States. World Journal of Urology, 30(2), 195–200. doi:10.1007/s00345-012-0824-2.
Center, M. M., Jemal, A., Lortet-Tieulent, J., Ward, E., Ferlay, J., Brawley, O., et al. (2012). International variation in prostate cancer incidence and mortality rates. European Urology, 61(6), 1079–1092. doi:10.1016/j.eururo.2012.02.054.
Stamey, T. A., Yang, N., Hay, A. R., McNeal, J. E., Freiha, F. S., & Redwine, E. (1987). Prostate-specific antigen as a serum marker for adenocarcinoma of the prostate. New England Journal of Medicine, 317(15), 909–916. doi:10.1056/NEJM198710083171501 [Comparative Study Research Support, Non-U.S. Gov't].
Wang, M. C., Valenzuela, L. A., Murphy, G. P., & Chu, T. M. (1979). Purification of a human prostate specific antigen. Investigative Urology, 17(2), 159–163 [Research Support, U.S. Gov't, P.H.S.].
Lin, K., Lipsitz, R., Miller, T., & Janakiraman, S. (2008). Benefits and harms of prostate-specific antigen screening for prostate cancer: an evidence update for the U.S. Preventive Services Task Force. Annals of Internal Medicine, 149(3), 192–199 [Practice Guideline Review].
Chou, R., & LeFevre, M. L. (2011). Prostate cancer screening—the evidence, the recommendations, and the clinical implications. JAMA: Journal of the American Medical Association, 306(24), 2721–2722. doi:10.1001/jama.2011.1891.
Moyer, V. A. (2012). Screening for prostate cancer: U.S. Preventive Services Task Force recommendation statement. Annals of Internal Medicine. doi:10.1059/0003-4819-157-2-201207170-00459. E-459.
Andriole, G. L., Crawford, E. D., Grubb, R. L., 3rd, Buys, S. S., Chia, D., Church, T. R., et al. (2009). Mortality results from a randomized prostate-cancer screening trial. New England Journal of Medicine, 360(13), 1310–1319. doi:10.1056/NEJMoa0810696 [Multicenter Study Randomized Controlled Trial Research Support, N.I.H., Extramural].
Schroder, F. H., Hugosson, J., Roobol, M. J., Tammela, T. L., Ciatto, S., Nelen, V., et al. (2009). Screening and prostate-cancer mortality in a randomized European study. New England Journal of Medicine, 360(13), 1320–1328. doi:10.1056/NEJMoa0810084 [Multicenter Study Randomized Controlled Trial Research Support, Non-U.S. Gov't].
Carter, H. B., Pearson, J. D., Metter, E. J., Brant, L. J., Chan, D. W., Andres, R., et al. (1992). Longitudinal evaluation of prostate-specific antigen levels in men with and without prostate disease. JAMA: Journal of the American Medical Association, 267(16), 2215–2220 [Research Support, U.S. Gov't, P.H.S.].
Thompson, I. M., Ankerst, D. P., Chi, C., Goodman, P. J., Tangen, C. M., Lucia, M. S., et al. (2006). Assessing prostate cancer risk: results from the Prostate Cancer Prevention Trial. Journal of the National Cancer Institute, 98(8), 529–534. doi:10.1093/jnci/djj131 [Research Support, N.I.H., Extramural].
D'Amico, A. V., Chen, M. H., Roehl, K. A., & Catalona, W. J. (2004). Preoperative PSA velocity and the risk of death from prostate cancer after radical prostatectomy. New England Journal of Medicine, 351(2), 125–135. doi:10.1056/NEJMoa032975.
Catalona, W. J., Smith, D. S., & Ornstein, D. K. (1997). Prostate cancer detection in men with serum PSA concentrations of 2.6 to 4.0 ng/mL and benign prostate examination. Enhancement of specificity with free PSA measurements. JAMA: Journal of the American Medical Association, 277(18), 1452–1455 [Research Support, Non-U.S. Gov't].
Bussemakers, M. J., van Bokhoven, A., Verhaegh, G. W., Smit, F. P., Karthaus, H. F., Schalken, J. A., et al. (1999). DD3: a new prostate-specific gene, highly overexpressed in prostate cancer. Cancer Research, 59(23), 5975–5979 [Research Support, Non-U.S. Gov't].
Filella, X., Foj, L., Mila, M., Auge, J. M., Molina, R., & Jimenez, W. (2013). PCA3 in the detection and management of early prostate cancer. Tumour Biology, 34(3), 1337–1347. doi:10.1007/s13277-013-0739-6 [Review].
Hessels, D., Klein Gunnewiek, J. M., van Oort, I., Karthaus, H. F., van Leenders, G. J., van Balken, B., et al. (2003). DD3(PCA3)-based molecular urine analysis for the diagnosis of prostate cancer. European Urology, 44(1), 8–15. discussion 15-16; [Comparative Study].
Deras, I. L., Aubin, S. M., Blase, A., Day, J. R., Koo, S., Partin, A. W., et al. (2008). PCA3: a molecular urine assay for predicting prostate biopsy outcome. Journal of Urology, 179(4), 1587–1592. doi:10.1016/j.juro.2007.11.038 [Clinical Trial Multicenter Study Research Support, N.I.H., Extramural].
Haese, A., de la Taille, A., van Poppel, H., Marberger, M., Stenzl, A., Mulders, P. F., et al. (2008). Clinical utility of the PCA3 urine assay in European men scheduled for repeat biopsy. European Urology, 54(5), 1081–1088. doi:10.1016/j.eururo.2008.06.071 [Comparative Study Multicenter Study Research Support, Non-U.S. Gov't].
Marks, L. S., Fradet, Y., Deras, I. L., Blase, A., Mathis, J., Aubin, S. M., et al. (2007). PCA3 molecular urine assay for prostate cancer in men undergoing repeat biopsy. Urology, 69(3), 532–535. doi:10.1016/j.urology.2006.12.014 [Multicenter Study].
van Gils, M. P., Hessels, D., Hulsbergen-van de Kaa, C. A., Witjes, J. A., Jansen, C. F., Mulders, P. F., et al. (2008). Detailed analysis of histopathological parameters in radical prostatectomy specimens and PCA3 urine test results. The Prostate, 68(11), 1215–1222. doi:10.1002/pros.20781 [Research Support, Non-U.S. Gov't].
Whitman, E. J., Groskopf, J., Ali, A., Chen, Y., Blase, A., Furusato, B., et al. (2008). PCA3 score before radical prostatectomy predicts extracapsular extension and tumor volume. Journal of Urology, 180(5), 1975–1978. doi:10.1016/j.juro.2008.07.060. discussion 1978-1979; [Research Support, Non-U.S. Gov't].
Bleyer, A., & Welch, H. G. (2012). Effect of three decades of screening mammography on breast-cancer incidence. New England Journal of Medicine, 367(21), 1998–2005. doi:10.1056/NEJMoa1206809.
Arbyn, M., Anttila, A., Jordan, J., Ronco, G., Schenck, U., Segnan, N., et al. (2010). European guidelines for quality assurance in cervical cancer screening. Second edition—summary document. Annals of Oncology, 21(3), 448–458. doi:10.1093/annonc/mdp471 [Practice Guideline Research Support, Non-U.S. Gov't].
Lieberman, D. A. (2009). Clinical practice. Screening for colorectal cancer. New England Journal of Medicine, 361(12), 1179–1187. doi:10.1056/NEJMcp0902176 [Review].
Paik, S., Shak, S., Tang, G., Kim, C., Baker, J., Cronin, M., et al. (2004). A multigene assay to predict recurrence of tamoxifen-treated, node-negative breast cancer. New England Journal of Medicine, 351(27), 2817–2826. doi:10.1056/NEJMoa041588 [Clinical Trial Randomized Controlled Trial Research Support, Non-U.S. Gov't].
van't Veer, L. J., Dai, H., van de Vijver, M. J., He, Y. D., Hart, A. A., Mao, M., et al. (2002). Gene expression profiling predicts clinical outcome of breast cancer. Nature, 415(6871), 530–536. doi:10.1038/415530a [Research Support, Non-U.S. Gov't].
Pfeffer, U., Mirisola, V., Esposito, A., Amaro, A., & Angelini, G. (2013). Breast cancer genomics: from portraits to landscapes. In U. Pfeffer (Ed.), Cancer genomics: molecular classification, prognosis and response prediction. Dordrecht: Springer.
da Cunha Santos, G., Shepherd, F. A., & Tsao, M. S. (2011). EGFR mutations and lung cancer. Annual Review of Pathology, 6, 49–69. doi:10.1146/annurev-pathol-011110-130206 [Research Support, Non-U.S. Gov't Review].
Buzdar, A. U., Ibrahim, N. K., Francis, D., Booser, D. J., Thomas, E. S., Theriault, R. L., et al. (2005). Significantly higher pathologic complete remission rate after neoadjuvant therapy with trastuzumab, paclitaxel, and epirubicin chemotherapy: results of a randomized trial in human epidermal growth factor receptor 2-positive operable breast cancer. Journal of Clinical Oncology: Official journal of the American Society of Clinical Oncology, 23(16), 3676–3685. doi:10.1200/JCO.2005.07.032 [Clinical Trial Clinical Trial, Phase III Randomized Controlled Trial Research Support, Non-U.S. Gov't].
Gennari, A., Sormani, M. P., Pronzato, P., Puntoni, M., Colozza, M., Pfeffer, U., et al. (2008). HER2 status and efficacy of adjuvant anthracyclines in early breast cancer: a pooled analysis of randomized trials. Journal of the National Cancer Institute, 100(1), 14–20. doi:10.1093/jnci/djm252 [Meta-Analysis Research Support, Non-U.S. Gov't].
Nash, A. F., & Melezinek, I. (2000). The role of prostate specific antigen measurement in the detection and management of prostate cancer. Endocrine-related Cancer, 7(1), 37–51 [Review].
Christensen, E., Evans, K. R., Menard, C., Pintilie, M., & Bristow, R. G. (2008). Practical approaches to proteomic biomarkers within prostate cancer radiotherapy trials. Cancer Metastasis Reviews, 27(3), 375–385. doi:10.1007/s10555-008-9139-6 [Research Support, Non-U.S. Gov't Review].
Bibault, J. E., Fumagalli, I., Ferte, C., Chargari, C., Soria, J. C., & Deutsch, E. (2013). Personalized radiation therapy and biomarker-driven treatment strategies: a systematic review. Cancer Metastasis Reviews. doi:10.1007/s10555-013-9419-7.
Nadler, R. B., Humphrey, P. A., Smith, D. S., Catalona, W. J., & Ratliff, T. L. (1995). Effect of inflammation and benign prostatic hyperplasia on elevated serum prostate specific antigen levels. Journal of Urology, 154(2 Pt 1), 407–413 [Research Support, Non-U.S. Gov't Research Support, U.S. Gov't, P.H.S.].
Herschman, J. D., Smith, D. S., & Catalona, W. J. (1997). Effect of ejaculation on serum total and free prostate-specific antigen concentrations. Urology, 50(2), 239–243. doi:10.1016/S0090-4295(97)00209-4 [Research Support, Non-U.S. Gov't].
da Huang, W., Sherman, B. T., & Lempicki, R. A. (2009). Bioinformatics enrichment tools: paths toward the comprehensive functional analysis of large gene lists. Nucleic Acids Research, 37(1), 1–13. doi:10.1093/nar/gkn923 [Research Support, N.I.H., Extramural].
Kilpinen, S., Autio, R., Ojala, K., Iljin, K., Bucher, E., & Sara, H. (2008). Systematic bioinformatic analysis of expression levels of 17,330 human genes across 9,783 samples from 175 types of healthy and pathological tissues. Genome Biology, 9(9), R139. doi:10.1186/gb-2008-9-9-r139 [Research Support, Non-U.S. Gov't].
Sboner, A., Demichelis, F., Calza, S., Pawitan, Y., Setlur, S. R., Hoshida, Y., et al. (2010). Molecular sampling of prostate cancer: a dilemma for predicting disease progression. BMC Medical Genomics, 3, 8. doi:10.1186/1755-8794-3-8 [Research Support, N.I.H., Extramural].
Taylor, B. S., Schultz, N., Hieronymus, H., Gopalan, A., Xiao, Y., Carver, B. S., et al. (2010). Integrative genomic profiling of human prostate cancer. Cancer Cell, 18(1), 11–22. doi:10.1016/j.ccr.2010.05.026 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't].
Yu, Y. P., Landsittel, D., Jing, L., Nelson, J., Ren, B., Liu, L., et al. (2004). Gene expression alterations in prostate cancer predicting tumor aggression and preceding development of malignancy. Journal of Clinical Oncology, 22(14), 2790–2799. doi:10.1200/JCO.2004.05.158 [Research Support, U.S. Gov't, P.H.S.].
Chandran, U. R., Ma, C., Dhir, R., Bisceglia, M., Lyons-Weiler, M., Liang, W., et al. (2007). Gene expression profiles of prostate cancer reveal involvement of multiple molecular pathways in the metastatic process. BMC Cancer, 7, 64. doi:10.1186/1471-2407-7-64 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't].
Vanaja, D. K., Ballman, K. V., Morlan, B. W., Cheville, J. C., Neumann, R. M., Lieber, M. M., et al. (2006). PDLIM4 repression by hypermethylation as a potential biomarker for prostate cancer. Clinical Cancer Research, 12(4), 1128–1136. doi:10.1158/1078-0432.CCR-05-2072 [Research Support, N.I.H., Extramural].
Bartholow, T. L., Chandran, U. R., Becich, M. J., & Parwani, A. V. (2011). Immunohistochemical profiles of claudin-3 in primary and metastatic prostatic adenocarcinoma. Diagnostic Pathology, 6, 12. doi:10.1186/1746-1596-6-12 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't].
Kristiansen, G., Fritzsche, F. R., Wassermann, K., Jager, C., Tolls, A., Lein, M., et al. (2008). GOLPH2 protein expression as a novel tissue biomarker for prostate cancer: implications for tissue-based diagnostics. British Journal of Cancer, 99(6), 939–948. doi:10.1038/sj.bjc.6604614.
Marin, L. V., Ferariu, D., & Mihailovici, M. S. (2010). Immunohistochemic staining for CK5/6 and P63 significance in prostate premalignant lesions and adenocarcinoma. Revista medico-Chirurgicala A Societatii de Medici si Naturalisti din Iasi, 114(3), 818–822.
Shariat, S. F., Ashfaq, R., Roehrborn, C. G., Slawin, K. M., & Lotan, Y. (2005). Expression of survivin and apoptotic biomarkers in benign prostatic hyperplasia. Journal of Urology, 174(5), 2046–2050. doi:10.1097/01.ju.0000176459.79180.d1 [Comparative Study Research Support, Non-U.S. Gov't].
Edwards, S., Campbell, C., Flohr, P., Shipley, J., Giddings, I., Te-Poele, R., et al. (2005). Expression analysis onto microarrays of randomly selected cDNA clones highlights HOXB13 as a marker of human prostate cancer. British Journal of Cancer, 92(2), 376–381. doi:10.1038/sj.bjc.6602261 [Comparative Study Research Support, Non-U.S. Gov't].
Bieberich, C. J., Fujita, K., He, W. W., & Jay, G. (1996). Prostate-specific and androgen-dependent expression of a novel homeobox gene. The Journal of Biological Chemistry, 271(50), 31779–31782.
Pfeffer, U. (Ed.). (2013). Cancer genomics: molecular classification, prognosis and response prediction. Dordrecht: Springer.
Hu, Y., Wang, M., Veverka, K., Garcia, F. U., & Stearns, M. E. (2007). The ABCA5 protein: a urine diagnostic marker for prostatic intraepithelial neoplasia. Clinical Cancer Research, 13(3), 929–938. doi:10.1158/1078-0432.CCR-06-1718.
Morgan, R., Boxall, A., Bhatt, A., Bailey, M., Hindley, R., Langley, S., et al. (2011). Engrailed-2 (EN2): a tumor specific urinary biomarker for the early diagnosis of prostate cancer. Clinical Cancer Research, 17(5), 1090–1098. doi:10.1158/1078-0432.CCR-10-2410 [Research Support, Non-U.S. Gov't].
Montgomery, R. B., Mostaghel, E. A., Vessella, R., Hess, D. L., Kalhorn, T. F., Higano, C. S., et al. (2008). Maintenance of intratumoral androgens in metastatic prostate cancer: a mechanism for castration-resistant tumor growth. Cancer Research, 68(11), 4447–4454. doi:10.1158/0008-5472.CAN-08-0249 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't Research Support, U.S. Gov't, Non-P.H.S.].
Xu, L., Tan, A. C., Naiman, D. Q., Geman, D., & Winslow, R. L. (2005). Robust prostate cancer marker genes emerge from direct integration of inter-study microarray data. Bioinformatics, 21(20), 3905–3911. doi:10.1093/bioinformatics/bti647 [Evaluation Studies Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't Research Support, U.S. Gov't, P.H.S.].
Malhotra, S., Lapointe, J., Salari, K., Higgins, J. P., Ferrari, M., & Montgomery, K. (2011). A tri-marker proliferation index predicts biochemical recurrence after surgery for prostate cancer. PLoS ONE, 6(5), e20293. doi:10.1371/journal.pone.0020293 [In Vitro Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't].
Romanuik, T. L., Ueda, T., Le, N., Haile, S., Yong, T. M., Thomson, T., et al. (2009). Novel biomarkers for prostate cancer including noncoding transcripts. The American Journal of Pathology, 175(6), 2264–2276. doi:10.2353/ajpath.2009.080868 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't].
Gleason, D. F. (1977). The Veteran's Administration Cooperative Urologic Research Group: histologic grading and clinical staging of prostatic carcinoma. In M. Tannenbaum (Ed.), Urologic pathology: the prostate (pp. 171–198). Philadelphia: Lea and Febige.
Dupuy, A., & Simon, R. M. (2007). Critical review of published microarray studies for cancer outcome and guidelines on statistical analysis and reporting. Journal of the National Cancer Institute, 99(2), 147–157. doi:10.1093/jnci/djk018 [Guideline Review].
da Huang, W., Sherman, B. T., & Lempicki, R. A. (2009). Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nature Protocols, 4(1), 44–57. doi:10.1038/nprot.2008.211 [Research Support, N.I.H., Extramural].
Chen, X., Xu, S., McClelland, M., Rahmatpanah, F., Sawyers, A., Jia, Z., et al. (2012). An accurate prostate cancer prognosticator using a seven-gene signature plus Gleason score and taking cell type heterogeneity into account. PLoS ONE, 7(9), e45178. doi:10.1371/journal.pone.0045178.
Penney, K. L., Sinnott, J. A., Fall, K., Pawitan, Y., Hoshida, Y., Kraft, P., et al. (2011). mRNA expression signature of Gleason grade predicts lethal prostate cancer. Journal of Clinical Oncology, 29(17), 2391–2396. doi:10.1200/JCO.2010.32.6421 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't].
Olmos, D., Brewer, D., Clark, J., Danila, D. C., Parker, C., Attard, G., et al. (2012). Prognostic value of blood mRNA expression signatures in castration-resistant prostate cancer: a prospective, two-stage study. The Lancet Oncology. doi:10.1016/S1470-2045(12)70372-8.
Pfeffer, U., Romeo, F., Noonan, D. M., & Albini, A. (2009). Prediction of breast cancer metastasis by genomic profiling: where do we stand? Clinical & Experimental Metastasis, 26(6), 547–558. doi:10.1007/s10585-009-9254-y [Research Support, Non-U.S. Gov't Review].
Reis-Filho, J. S., & Pusztai, L. (2011). Gene expression profiling in breast cancer: classification, prognostication, and prediction. Lancet, 378(9805), 1812–1823. doi:10.1016/S0140-6736(11)61539-0 [Research Support, Non-U.S. Gov't Review].
Sorlie, T., Perou, C. M., Tibshirani, R., Aas, T., Geisler, S., Johnsen, H., et al. (2001). Gene expression patterns of breast carcinomas distinguish tumor subclasses with clinical implications. Proceedings of the National Academy of Sciences of the United States of America, 98(19), 10869–10874. doi:10.1073/pnas.191367098 [Research Support, Non-U.S. Gov't Research Support, U.S. Gov't, P.H.S.].
Barbieri, C. E., Baca, S. C., Lawrence, M. S., Demichelis, F., Blattner, M., Theurillat, J. P., et al. (2012). Exome sequencing identifies recurrent SPOP, FOXA1 and MED12 mutations in prostate cancer. Nature Genetics. doi:10.1038/ng.2279.
Grasso, C. S., Wu, Y. M., Robinson, D. R., Cao, X., Dhanasekaran, S. M., Khan, A. P., et al. (2012). The mutational landscape of lethal castration-resistant prostate cancer. Nature, 487(7406), 239–243. doi:10.1038/nature11125 [Research Support, N.I.H., Extramural Research Support, Non-U.S. Gov't Research Support, U.S. Gov't, Non-P.H.S.].
Gandellini, P., Profumo, V., Folini, M., & Zaffaroni, N. (2011). MicroRNAs as new therapeutic targets and tools in cancer. Expert Opinion on Therapeutic Targets, 15(3), 265–279. doi:10.1517/14728222.2011.550878 [Review].
Sogno, I., Conti, M., Consonni, P., Noonan, D. M., & Albini, A. (2012). Surface-activated chemical ionization-electrospray ionization source improves biomarker discovery with mass spectrometry. Rapid Communications in Mass Spectrometry, 26(10), 1213–1218. doi:10.1002/rcm.6208 [Research Support, Non-U.S. Gov't].
Acknowledgments
This work has been made possible by a grant from the Compagnia San Paolo to UP and the Associazione Italiana per la Ricerca sul Cancro to A. Albini and the Italian Ministry of Health Progetto Finalizzato to Paola Erba and A. Albini. AAm is recipient of a PO CRO Fondo Sociale Europeo Regione Liguria 2007–2013 Asse IV “Capitale Umano” fellowship. AIE is recipient of a doctoral fellowship from the University of Genoa. We thank Fey Vidal, Turku, for the help with data extraction and Renata Scarzello, Genova, for secretarial assistance.
Conflict of interest
The authors declare that they have no conflict of interest.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Fig. 1
Kaplan–Meier survival analysis of all prostate cancer biomarkers on dataset GSE16560 (PDF 839 kb)
Supplementary Fig. 2
Kaplan–Meier curves for the multigene score on a random split of the dataset GSE16560 to create training and test sets (JPEG 284 kb)
Supplementary Table 1
List of prostate cancer biomarkers considered for the present study with bibliographic references (PDF 632 kb)
Supplementary Table 2
Expression of prostate cancer markers in healthy and tumoral prostate tissue (XLSX 56 kb)
Supplementary Table 3
Functional categories of the markers in clusters of expression correlated markers (XLSX 110 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Amaro, A., Esposito, A.I., Gallina, A. et al. Validation of proposed prostate cancer biomarkers with gene expression data: a long road to travel. Cancer Metastasis Rev 33, 657–671 (2014). https://doi.org/10.1007/s10555-013-9470-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10555-013-9470-4