
Abstract
We present a novel method of conducting biometric analysis of twin data when the phenotypes are integer-valued counts, which often show an L-shaped distribution. Monte Carlo simulation is used to compare five likelihood-based approaches to modeling: our multivariate discrete method, when its distributional assumptions are correct, when they are incorrect, and three other methods in common use. With data simulated from a skewed discrete distribution, recovery of twin correlations and proportions of additive genetic and common environment variance was generally poor for the Normal, Lognormal and Ordinal models, but good for the two discrete models. Sex-separate applications to substance-use data from twins in the Minnesota Twin Family Study showed superior performance of two discrete models. The new methods are implemented using R and OpenMx and are freely available.







Similar content being viewed by others


Notes
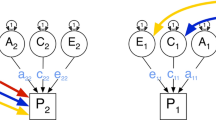
We use “monophenotype twin model” to refer to what behavior geneticists commonly refer to as a “univariate twin model.” The latter terminology is rather unfortunate. The independent unit of analysis is the twin pair, and thus, a sample of twin data on a single phenotype is a sample of realizations of random 2-vectors, that is, from a bivariate distribution.
If, say, people’s latent tendency to drink were normally distributed in the population, and number of drinks each day were conditionally Poisson, then daily number of drinks would follow a Hermite distribution in the population (Kemp and Kemp, 1966). The present paper does not consider the Hermite distribution, as it would be most appropriate for variables with multimodal distributions (Johnson et al. 2005; Giles 2010).
We considered basing our quadratic loss metric on \({\mathbf{y}}_{i}\)’s Mahalanobis distance from \({\hat{\mathbf{y}}}_{i}\). But, if the predicted variances are systematically too large, the sum of squared Mahalanobis distances will be smaller than if the variances were accurately predicted—not a desirable property for a loss metric.
References
Atkins DC, Gallop RJ (2007) Rethinking how family researchers model infrequent outcomes: a tutorial on count regression and zero-inflated models. J Fam Psychol 21(4):726–735
Balakrishnan N, Lai C-D (2009) Continuous bivariate distributions, 2nd edn. Springer, New York
Barton DE (1957) The modality of Neyman’s contagious distribution of Type A. Trabajos de Estadística 8:13–22
Boker, S., Neale, M., Maes, H., Wilde, M., Spiegel, M., Brick, T e al. (2011) OpenMx: An open source extended structural equation modeling framework. Psychometrika 76(2):306–317. doi: 10.1007/S11336-010-9200-6. Software and documentation available at http://openmx.psyc.virginia.edu/
Cameron AC, Trivedi PK (1986) Econometric models based on count data: comparisons and applications of some estimators and tests. J Appl Econom 1(1):29–53
Consul PC (1989) Generalized poisson distributions: properties and applications. Marcel Dekker Inc., New York
Consul PC, Famoye F (2006) Lagrangian probability distributions. Birkhäuser, Boston
Famoye F (2010) A new bivariate generalized Poisson distribution. Stat Neerl 64(1):112–124. doi:10.1111/j.1467-9574.2009.00446.x
Famoye F, Consul PC (1995) Bivariate generalized Poisson distribution with some applications. Metrika 42:127–138
Forbes C, Evans M, Hastings N, Peacock B (2011) Statistical distributions, 4th edn. Wiley, Hoboken
Genest C, Favre A-C (2007) Everything you always wanted to know about copula modeling but were afraid to ask. J Hydrol Eng 12(4):347–368
Genz A, Bretz F (2009) Computation of multivariate normal and t probabilities. Springer, Heidelberg. Software and documentation available at http://cran.r-project.org/web/packages/mvtnorm/index.html
Genest C, Nešlehová J (2007) A primer on copulas for count data. Astin Bulletin 37(2):475–515
Giles DE (2010) Hermite regression analysis of multi-modal count data. Econ Bull 30(4):2936–2945
Good IJ (1960) Generalizations to several variables of Lagrange’s expansion, with applications to stochastic processes. Math Proc Cambridge Philos Soc 56:367–380. doi:10.1017/S0305004100034666
Hastie T, Tibshirani R, Friedman J (2009) The elements of statistical learning: data mining, inference, and prediction, 2nd edn. Springer, New York. doi: 10.1007/b94608
Holgate P (1964) Estimation for the bivariate Poisson distribution. Biometrika 51:241–245
Iacono WG, Carlson SR, Taylor J, Elkins IJ, McGue M (1999) Behavioral disinhibition and the development of substance-use disorders: findings from the Minnesota Twin Family Study. Dev Psychopathol 11:869–900
Iacono WG, McGue M (2002) Minnesota Twin Family Study. Twin Res 5(5):482–487
Johnson NL, Kemp AW, Kotz S (2005) Univariate discrete distributions, 3rd edn. Wiley, Hoboken
Johnson NL, Kotz S, Balakrishnan N (1997) Discrete multivariate distributions. Wiley, New York
Kemp AW, Kemp CD (1966) An alternative derivation of the Hermite distribution. Biometrika 53:627–628
Keyes MA, Malone SM, Elkins IJ, Legrand LN, McGue M, Iacono WG (2009) The Enrichment Study of the Minnesota Twin Family Study: increasing the yield of twin families at high risk for externalizing psychopathology. Twin Res Human Gen 12(5):489–501
Kirkpatrick RM (2014) RMKdiscrete (Version 0.1). Software and documentation available at http://cran.r-project.org/web/packages/RMKdiscrete/
Kocherlakota S, Kocherlakota K (1992) Bivariate discrete distributions. Marcel Dekker Inc, New York
Kocherlakota S, Kocherlakota K (2001) Regression in the bivariate Poisson distribution. Commun Stat 30(5):815–825. doi:10.1081/STA-100002259
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Stat 22(1):79–86
Lakshminarayana J, Pandit SNN, Rao KS (1999) On a bivariate Poisson distribution. Commun Stat 28(2):267–276. doi:10.1080/03610929908832297
Lee A (1999) Modelling rugby league data via bivariate negative binomial regression. Aust NZ J Stat 41(2):141–152
Lehmann EL (1999) Elements of large-sample theory. Springer, New York
Li C-S, Lu J-C, Park J, Kim K, Brinkley PA, Peterson JP (1999) Multivariate zero-inflated Poisson models and their applications. Technometrics 41(1):29–38
McGue M, Bouchard TJ (1984) Adjustment of twin data for the effects of age and sex. Behav Genet 14(4):325–343
Nelsen RB (2006) An introduction to copulas, 2nd edn. Springer, New York
Nikoloulopoulos AK, Karlis D (2009) Finite normal mixture copulas for multivariate discrete data modeling. J Stat Plan Inference 139:3878–3890. doi:10.1016/j.jspi.2009.05.034
R Core Team (2013). R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. http://www.R-project.org/. [computer software]
Teicher H (1954) On the multivariate Poisson distribution. Scand Actuar J 37:1–9
Warton DI (2005) Many zeros does not mean zero inflation: comparing the goodness-of-fit of parametric models to multivariate abundance data. Environmetrics 16:275–289. doi:10.1002/env.702
Wu H, Neale MC (2012) Adjusted confidence intervals for a bounded parameter. Behav Genet 42:886–898
Acknowledgments
The authors were supported by U.S. Public Health Service grant DA026119. William G. Iacono and Matt McGue provided the MTFS dataset, which was supported by U.S. Public Health Service Grants DA05147, AA009367, and DA013240. The first author gives his special thanks to Matt McGue, Niels G. Waller, and Hermine H. Maes for their comments on drafts of the paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
Robert M. Kirkpatrick and Michael C. Neale declare that they have no conflict of interest.
Human and animal rights and informed consent
The MTFS was reviewed and approved by the Institutional Review Board at the University of Minnesota. Written informed assent or consent was obtained from all participants, with parents providing written consent for their minor children.
Additional information
Edited by Gitta Lubke.
Electronic supplementary material
Below is the link to the electronic supplementary material.
10519_2015_9757_MOESM2_ESM.zip
Online Resource 2: 3 text files: a README file for the other two, an example R script from the Monte Carlo simulation, and an R script for producing graphs and summary statistics from the raw simulation data (read in over the web). Supplementary material 2 (zip 15 kb)
Rights and permissions
About this article

Cite this article
Kirkpatrick, R.M., Neale, M.C. Applying Multivariate Discrete Distributions to Genetically Informative Count Data. Behav Genet 46, 252–268 (2016). https://doi.org/10.1007/s10519-015-9757-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-015-9757-z