
Abstract
The authors in a previous paper devised certain subcones of the semidefinite plus nonnegative cone and showed that satisfaction of the requirements for membership of those subcones can be detected by solving linear optimization problems (LPs) with O(n) variables and \(O(n^2)\) constraints. They also devised LP-based algorithms for testing copositivity using the subcones. In this paper, they investigate the properties of the subcones in more detail and explore larger subcones of the positive semidefinite plus nonnegative cone whose satisfaction of the requirements for membership can be detected by solving LPs. They introduce a semidefinite basis (SD basis) that is a basis of the space of \(n \times n\) symmetric matrices consisting of \(n(n+1)/2\) symmetric semidefinite matrices. Using the SD basis, they devise two new subcones for which detection can be done by solving LPs with \(O(n^2)\) variables and \(O(n^2)\) constraints. The new subcones are larger than the ones in the previous paper and inherit their nice properties. The authors also examine the efficiency of those subcones in numerical experiments. The results show that the subcones are promising for testing copositivity as a useful application.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Let \(\mathcal {S}_n\) be the set of \(n \times n\) symmetric matrices, and define their inner product as
Bomze et al. (2000) coined the term “copositive programming” in relation to the following problem in 2000, on which many studies have since been conducted:
where \(\mathcal {COP}_n\) is the set of \(n \times n\) copositive matrices, i.e., matrices whose quadratic form takes nonnegative values on the n-dimensional nonnegative orthant \(\mathbb {R}^n_+\):
We call the set \(\mathcal {COP}_n\) the copositive cone. A number of studies have focused on the close relationship between copositive programming and quadratic or combinatorial optimization (see, e.g., Bomze et al. 2000; Bomze and Klerk 2002; Klerk and Pasechnik 2002; Povh and Rendl 2007, 2009; Bundfuss 2009; Burer 2009; Dickinson and Gijben 2014). Interested readers may refer to Dür (2010) and Bomze (2012) for background on and the history of copositive programming.
The following cones are attracting attention in the context of the relationship between combinatorial optimization and copositive optimization (see, e.g., Dür 2010; Bomze 2012). Here, \(\mathrm{conv}\,(S)\) denotes the convex hull of the set S.
-
The nonnegative cone \(\mathcal{N}_n := \left\{ X \in \mathcal {S}_n \mid x_{ij} \ge 0 \text{ for } \text{ all } \ i, j \in \{1,2,\ldots ,n\} \right\} \).
-
The semidefinite cone \(\mathcal{S}_n^+ := \{X \in \mathcal {S}_n \mid d^TXd \ge 0 \ \text{ for } \text{ all } \ d \in \mathbb {R}^n \} = \mathrm{conv}\,\left( \left\{ xx^T \mid x \in \mathbb {R}^n \right\} \right) \).
-
The copositive cone \(\mathcal{COP}_n := \left\{ X \in \mathcal {S}_n \mid d^TXd \ge 0 \ \text{ for } \text{ all } \ d \in \mathbb {R}^n_+ \right\} \).
-
The semidefinite plus nonnegative cone \(\mathcal{S}_n^+ + \mathcal{N}_n\), which is the Minkowski sum of \(\mathcal{S}_n^+\) and \(\mathcal{N}_n\).
-
The union \(\mathcal{S}_n^+ \cup \mathcal{N}_n\) of \(\mathcal{S}_n^+\) and \(\mathcal{N}_n\).
-
The doubly nonnegative cone \(\mathcal{S}_n^+ \cap \mathcal{N}_n\), i.e., the set of positive semidefinite and componentwise nonnegative matrices.
-
The completely positive cone \(\mathcal{CP}_n := \mathrm{conv}\,\left( \left\{ xx^T \mid x \in \mathbb {R}^n_+ \right\} \right) \).
Except the set \(\mathcal{S}_n^+ \cup \mathcal{N}_n\), all of the above cones are proper (see Section 1.6 of Berman and Monderer (2003), where a proper cone is called a full cone), and we can easily see from the definitions that the following inclusions hold:
While copositive programming has the potential of being a useful optimization technique, it still faces challenges. One of these challenges is to develop efficient algorithms for determining whether a given matrix is copositive. It has been shown that the above problem is co-NP-complete (Murty and Kabadi 1987; Dickinson 2014; Dickinson and Gijben 2014) and many algorithms have been proposed to solve it (see, e.g., Bomze 1996; Bundfuss and Dür 2008; Johnson and Reams 2008; Jarre and Schmallowsky 2009; Z̆ilinskas and Dür 2011; Sponsel et al. 2012; Bomze and Eichfelder 2013; Deng et al. 2013; Dür and Hiriart-Urruty 2013; Tanaka and Yoshise 2015; Brás et al. 2015) Here, we are interested in numerical algorithms which (a) apply to general symmetric matrices without any structural assumptions or dimensional restrictions and (b) are not merely recursive, i.e., do not rely on information taken from all principal submatrices, but rather focus on generating subproblems in a somehow data-driven way, as described in Bomze and Eichfelder (2013). There are few such algorithms, but they often use tractable subcones \(\mathcal {M}_n\) of the semidefinite plus nonnegative cone \(\mathcal{S}_n^+ + \mathcal{N}_n\) for detecting copositivity (see, e.g., Bundfuss and Dür 2008; Sponsel et al. 2012; Bomze and Eichfelder 2013; Tanaka and Yoshise 2015). As described in Sect. 5, these algorithms require one to check whether \(A \in \mathcal {M}_n\) or \(A \not \in \mathcal {M}_n\) repeatedly over simplicial partitions. The desirable properties of the subcones \(\mathcal {M}_n \subseteq \mathcal{S}_n^+ + \mathcal{N}_n\) used by these algorithms can be summarized as follows:
-
P1
For any given \(n \times n\) symmetric matrix \(A \in \mathcal {S}_n\), we can check whether \(A \in \mathcal {M}_n\) within a reasonable computation time, and
-
P2
\(\mathcal {M}_n\) is a subset of the semidefinite plus nonnegative cone \(\mathcal{S}_n^+ + \mathcal{N}_n\) that at least includes the \(n \times n\) nonnegative cone \(\mathcal {N}_n\) and contains as many elements \(\mathcal{S}_n^+ + \mathcal{N}_n\) as possible.
The authors, in Tanaka and Yoshise (2015), devised certain subcones of the semidefinite plus nonnegative cone \(\mathcal{S}_n^+ + \mathcal{N}_n\) and showed that satisfaction of the requirements for membership of those cones can be detected by solving linear optimization problems (LPs) with O(n) variables and \(O(n^2)\) constraints. They also created an LP-based algorithm that uses these subcones for testing copositivity as an application of those cones.
The aim of this paper is twofold. First, we investigate the properties of the subcones in more detail, especially in terms of their convex hulls. Second, we search for subcones of the semidefinite plus nonnegative cone \(\mathcal{S}_n^+ + \mathcal{N}_n\) that have properties P1 and P2. To address the second aim, we introduce a semidefinite basis (SD basis) that is a basis of the space \(\mathcal {S}_n\) consisting of \(n(n+1)/2\) symmetric semidefinite matrices. Using the SD basis, we devise two new types of subcones for which detection can be done by solving LPs with \(O(n^2)\) variables and \(O(n^2)\) constraints. As we will show in Corollary 1, these subcones are larger than the ones proposed in Tanaka and Yoshise (2015) and inherit their nice properties. We also examine the efficiency of those subcones in numerical experiments.
This paper is organized as follows: In Sect. 2, we show several tractable subcones of \(\mathcal{S}_n^+ + \mathcal{N}_n\) that are receiving much attention in the field of copositive programming and investigate their properties, the results of which are summarized in Figs. 1 and 2. In Sect. 3, we propose new subcones of \(\mathcal{S}_n^+ + \mathcal{N}_n\) having properties P1 and P2. We define SD bases using Definitions 1 and 2 and construct new LPs for detecting whether a given matrix belongs to the subcones. In Sect. 4, we perform numerical experiments in which the new subcones are used for identifying the given matrices \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\). As a useful application of the new subcones, Sect. 5 describes experiments for testing copositivity of matrices arising from the maximum clique problem and standard quadratic optimization problems. The results of these experiments show that the new subcones are promising not only for identification of \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) but also for testing copositivity. We give concluding remarks in Sect. 6.
2 Some tractable subcones of \(\mathcal{S}_n^+ + \mathcal{N}_n\) and related work
In this section, we show several tractable subcones of the semidefinite plus nonnegative cone \(\mathcal{S}_n^+ + \mathcal{N}_n\). Since the set \(\mathcal{S}_n^+ + \mathcal{N}_n\) is the dual cone of the doubly nonnegative cone \(\mathcal{S}_n^+ \cap \mathcal{N}_n\), we see that
and that the weak membership problem for \(\mathcal{S}_n^+ + \mathcal{N}_n\) can be solved (to an accuracy of \(\epsilon \)) by solving the following doubly nonnegative program (which can be expressed as a semidefinite program of size \(O(n^2)\)).
where \(I_n\) denotes the \(n \times n\) identity matrix. Thus, the set \(\mathcal{S}_n^+ + \mathcal{N}_n\) is a rather large and tractable convex subcone of \(\mathcal {COP}_n\). However, solving the problem takes a lot of time (Sponsel et al. 2012; Yoshise and Matsukawa 2010) and does not make for a practical implementation in general. To overcome this drawback, more easily tractable subcones of \(\mathcal{S}_n^+ + \mathcal{N}_n\) have been proposed.
We define the matrix functions \(N, S: \mathcal{S}_n \rightarrow \mathcal{S}_n\) such that, for \(A \in \mathcal {S}_n\), we have
In Sponsel et al. (2012), the authors defined the following set:
Here, we should note that \(A = S(A)+ N(A) \in \mathcal {S}_n^+ + \mathcal {N}_n\) if \(A \in \mathcal {H}_n\). Also, for any \(A \in \mathcal {N}_n\), S(A) is a nonnegative diagonal matrix, and hence, \(\mathcal {N}_n\subseteq \mathcal {H}_n\). The determination of \(A \in \mathcal {H}_n\) is easy and can be done by extracting the positive elements \(A_{ij} > 0 \ (i \ne j)\) as \(N(A)_{ij}\) and by performing a Cholesky factorization of S(A) (cf. Algorithm 4.2.4 in Golub and Van Loan 1996). Thus, from the inclusion relation (2), we see that the set \(\mathcal {H}_n\) has the desirable P1 property. However, S(A) is not necessarily positive semidefinite even if \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) or \(A \in \mathcal {S}_n^+\). The following theorem summarizes the properties of the set \(\mathcal {H}_n\).
Theorem 1
[Fiedler and Pták (1962) and Theorem 4.2 of Sponsel et al. (2012)] \(\mathcal {H}_n\) is a convex cone and \(\mathcal {N}_n \subseteq \mathcal {H}_n \subseteq \mathcal {S}_n^+ + \mathcal {N}_n\). If \(n \ge 3\), these inclusions are strict and \(\mathcal{S}_n^+ \not \subseteq \mathcal {H}_n\). For \(n=2\), we have \(\mathcal {H}_n = \mathcal {S}_n^+ \cup \mathcal {N}_n = \mathcal {S}_n^+ + \mathcal {N}_n =\mathcal {COP}_n\).
The construction of the subcone \(\mathcal {H}_n\) is based on the idea of “checking nonnegativity first and checking positive semidefiniteness second.” In Tanaka and Yoshise (2015), another subcone is provided that is based on the idea of “checking positive semidefiniteness first and checking nonnegativity second.” Let \(\mathcal{O}_n\) be the set of \(n \times n\) orthogonal matrices and \(\mathcal{D}_n\) be the set of \(n \times n\) diagonal matrices. For a given symmetric matrix \(A \in \mathcal {S}_n\), suppose that \(P=[p_1, p_2, \ldots , p_n] \in \mathcal{O}_n\) and \(\varLambda = \mathrm{Diag}\,(\lambda _1, \lambda _2, \ldots , \lambda _n) \in \mathcal{D}_n\) satisfy
By introducing another diagonal matrix \(\varOmega = \mathrm{Diag}\,(\omega _1, \omega _2, \ldots , \omega _n) \in \mathcal{D}_n\), we can make the following decomposition:
If \(\varLambda -\varOmega \in \mathcal{N}_n\), i.e., if \(\lambda _i \ge \omega _i \ (i = 1,2, \ldots ,n)\), then the matrix \(P(\varLambda -\varOmega )P^T\) is positive semidefinite. Thus, if we can find a suitable diagonal matrix \(\varOmega \in \mathcal{D}_n\) satisfying
We can determine whether such a matrix exists or not by solving the following linear optimization problem with variables \(\omega _i \ (i=1,2,\ldots ,n) \) and \(\alpha \):
Here, for a given matrix A, \([A]_{ij}\) denotes the (i, j)th element of A.
Problem \(\text{(LP) }_{P,\varLambda }\) has a feasible solution at which \(\omega _i = \lambda _i \ (i=1,2,\ldots ,n)\) and
For each \(i=1,2,\ldots ,n\), the constraints
and \(\omega _k \le \lambda _k \ (k=1,2,\ldots ,n)\) imply the bound \(\alpha \le \min \left\{ \sum _{k=1}^n \lambda _k [p_k]_i^2 \mid 1 \le i \le n \right\} \). Thus, \(\text{(LP) }_{P,\varLambda }\) has an optimal solution with optimal value \(\alpha _*(P, \varLambda )\). If \(\alpha _*(P, \varLambda ) \ge 0\), there exists a matrix \(\varOmega \) for which the decomposition (8) holds. The following set \(\mathcal {G}_n\) is based on the above observations and was proposed in Tanaka and Yoshise (2015) as the set, \(\mathcal {G}_n\)
where
for a given \(A \in \mathcal{S}_n\). As stated above, if \(\alpha _*(P,\varLambda ) \ge 0\) for a given decomposition \(A = P\varLambda P^T\), we can determine \(A \in \mathcal {G}_n\). In this case, we just need to compute a matrix decomposition and solve a linear optimization problem with \(n+1\) variables and \(O(n^2)\) constraints, which implies that it is rather practical to use the set \(\mathcal {G}_n\) as an alternative to using \(\mathcal{S}_n^+ + \mathcal{N}_n\). Suppose that \(A \in \mathcal {S}_n\) has n different eigenvalues. Then the possible orthogonal matrices \(P = [p_1, p_2, \ldots , p_n] \in \mathcal{O}_n\) are identifiable, except for the permutation and sign inversion of \(\{p_1, p_2, \ldots , p_n \}\), and by representing (6) as
we can see that the problem \(\text{(LP) }_{P,\varLambda }\) is unique for any possible \(P \in \mathcal{O}_n\). In this case, \(\alpha _*(P,\varLambda ) < 0\) with a specific \(P \in \mathcal{O}_n\) implies \(A \not \in \mathcal {G}_n\). However, if this is not the case (i.e., an eigenspace of A has at least dimension 2), \(\alpha _*(P,\varLambda ) < 0\) with a specific \(P \in \mathcal{O}_n\) does not necessarily guarantee that \(A \not \in \mathcal {G}_n\).
The above discussion can be extended to any matrix \(P \in \mathbb {R}^{m \times n}\); i.e., it does not necessarily have to be orthogonal or even square. The reason why the orthogonal matrices \(P \in \mathcal{O}_n\) are dealt with here is that some decomposition methods for (6) have been established for such orthogonal Ps. The property \(\mathcal {G}_n = \text{ com }(\mathcal {S}_n, \mathcal {N}_n)\) in Theorem 2 also follows when P is orthogonal.
In Tanaka and Yoshise (2015), the authors described another set \(\widehat{\mathcal {G}_n}\) that is closely related to \(\mathcal {G}_n\).
where for \(A \in \mathcal{S}_n\), the set \({\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {G}_n}}(A)\) is given by replacing \(\mathcal{O}_n\) in (12) by the space \(\mathbb {R}^{n \times n}\) of \(n \times n\) arbitrary matrices, i.e.,
If the set \({\mathcal {P}}{\mathcal {L}}_{\mathcal {G}_n}(A)\) in (12) is nonempty, then the set \({\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {G}_n}}(A)\) is also nonempty, which implies the following inclusions:
Before describing the properties of the sets \(\mathcal {G}_n\) and \(\widehat{\mathcal {G}_n}\), we will prove a preliminary lemma.
Lemma 1
Let \(\mathcal {K}_1\) and \(\mathcal {K}_2\) be two convex cones containing the origin. Then \(\mathrm{conv}\,(\mathcal {K}_1 \cup \mathcal {K}_2) = \mathcal {K}_1 + \mathcal {K}_2\).
Proof
Since \(\mathcal {K}_1\) and \(\mathcal {K}_2\) are convex cones, we can easily see that the inclusion \(\mathcal {K}_1 + \mathcal {K}_2 \subseteq \mathrm{conv}\,(\mathcal {K}_1 \cup \mathcal {K}_2)\) holds. The converse inclusion also follows from the fact that \(\mathcal {K}_1\) and \(\mathcal {K}_2\) are convex cones. Since \(\mathcal {K}_1\) and \(\mathcal {K}_2\) contain the origin, we see that the inclusion \(\mathcal {K}_1 \cup \mathcal {K}_2 \subseteq \mathcal {K}_1 + \mathcal {K}_2\) holds. From this inclusion and the convexity of the sets \(\mathcal {K}_1\) and \(\mathcal {K}_2\), we can conclude that
\(\square \)
The following theorem shows some of the properties of \(\mathcal {G}_n\) and \(\widehat{\mathcal {G}_n}\). Assertions (i) and (ii) were proved in Theorem 3.2 of Tanaka and Yoshise (2015). Assertion (iii) comes from the fact that \(\mathcal {S}_n^+\) and \(\mathcal {N}_n\) are convex cones and from Lemma 1. Assertions (iv)–(vi) follow from (i)–(iii), the inclusion (15) and Theorem 1.
Theorem 2
-
(i)
\(\mathcal {S}_n^+ \cup \mathcal {N}_n \subseteq \mathcal {G}_n\)
-
(ii)
\(\mathcal {G}_n = \mathrm{com}\,(\mathcal {S}_n^+, \mathcal {N}_n)\), where the set \(\mathrm{com}\,(\mathcal {S}_n^+, \mathcal {N}_n)\) is defined by
$$\begin{aligned} \mathrm{com}\,(\mathcal {S}_n^+, \mathcal {N}_n) := \{ S + N \mid S \in \mathcal {S}_n^+, \ N \in \mathcal {N}_n, \ \text{ S } \text{ and } \text{ N } \text{ commute } \}. \end{aligned}$$ -
(iii)
\(\mathrm{conv}\,(\mathcal {S}_n^+ \cup \mathcal {N}_n) = \mathcal {S}_n^+ + \mathcal {N}_n\).
-
(iv)
\( \mathcal {S}_n^+ \cup \mathcal {N}_n \subseteq \mathcal {G}_n = \text{ com }(\mathcal {S}_n^+, \mathcal {N}_n) \subseteq \widehat{\mathcal {G}_n} \subseteq \mathcal {S}_n^+ + \mathcal {N}_n \).
-
(v)
If \(n = 2\), then \( \mathcal {S}_n^+ \cup \mathcal {N}_n = \mathcal {G}_n = \mathrm{com}\,(\mathcal {S}_n^+, \mathcal {N}_n) = \widehat{\mathcal {G}_n} = \mathcal {S}_n^+ + \mathcal {N}_n \)
-
(vi)
\( \mathrm{conv}\,(\mathcal {S}_n^+ \cup \mathcal {N}_n) = \mathrm{conv}\,(\mathcal {G}_n) = \mathrm{conv}\,\left( \mathrm{com}\,(\mathcal {S}_n^+, \mathcal {N}_n)\right) = \mathrm{conv}\,(\widehat{\mathcal {G}_n}) = \mathcal {S}_n^+ + \mathcal {N}_n \).
A number of examples provided in Tanaka and Yoshise (2015) illustrate the differences between \(\mathcal {H}_n\), \(\mathcal {G}_n\). Moreover, the following two matrices have three different eigenvalues, respectively, and we can identify
by solving the associated LPs. Figure 1 draws those examples and (ii) of Theorem 2. Figure 2 follows from (vii) of Theorem 2 and the convexity of the sets \(\mathcal {N}_n\), \(\mathcal {S}_n^+\) and \(\mathcal {H}_n\) (see Theorem 1).

Examples of inclusion relations among the subcones of \(\mathcal {S}_n^+ + \mathcal {N}_n\) I

Examples of inclusion relations among the subcones of \(\mathcal {S}_n^+ + \mathcal {N}_n\) II
At present, it is not clear whether the set \(\mathcal {G}_n = \mathrm{com}\,(\mathcal {S}_n^+, \mathcal {N}_n)\) is convex or not. As we will mention our numerical results suggest that the set might be not convex.
Before closing this discussion, we should point out another interesting subset of \(\mathcal {S}_n^+ + \mathcal {N}_n\) proposed by Bomze and Eichfelder (2013). Suppose that a given matrix \(A \in \mathcal {S}_n\) can be decomposed as (6), and define the diagonal matrix \(\varLambda _+\) by \( [\varLambda _+]_{ii} = \max \{0, \lambda _i \}\). Let \(A_+: = P\varLambda _+P^T\) and \(A_- := A_+ - A\). Then, we can easily see that \(A_+\) and \(A_-\) are positive semidefinite. Using this decomposition \(A = A_+ - A_-\), Bomze and Eichfelder derived the following LP-based sufficient condition for \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) in Bomze and Eichfelder (2013).
Theorem 3
[Theorem 2.6 of Bomze and Eichfelder (2013)] Let \(x \in \mathbb {R}_n^+\) be such that \(A_+ x\) has only positive coordinates. If
then \(A \in \mathcal {COP}_n\).
Consider the following LP with O(n) variables and O(n) constraints,
where f is an arbitrary vector and e denotes the vector of all ones. Define the set,
Then Theorem 3 ensures that \(\mathcal {L}_n \subseteq \mathcal {COP}_n\). The following proposition gives a characterization when the feasible set of the LP of (17) is empty.
Proposition 1
[Proposition 2.7 of Bomze and Eichfelder (2013)] The condition \(\mathrm{ker} A_+ \cap \{x \in \mathbb {R}_n^+ \mid e^Tx =1 \} \ne \emptyset \) is equivalent to \( \{x \in \mathbb {R}_n^+ \mid A_+ x \ge e\} = \emptyset \).
Consider the matrix,
Thus, \(A_+ = A\), and the set \(\mathrm{ker} A_+ \cap \{x \in \mathbb {R}_n^+ \mid e^Tx =1 \} \ne \emptyset \). Proposition 1 ensures that \(A \not \in \mathcal {L}_2\), and hence, \(\mathcal {S}_n^+ \not \subseteq \mathcal {L}_n\) for \(n \ge 2\), similarly to the set \(\mathcal {H}_n\) for \(n \ge 3\) (see Theorem 1).
3 Semidefinite bases
In this section, we improve the subcone \(\mathcal {G}_n\) in terms of P2. For a given matrix A of (6), the linear optimization problem \(\text{(LP) }_{P,\varLambda }\) in (10) can be solved in order to find a nonnegative matrix that is a linear combination
of n linearly independent positive semidefinite matrices \(p_ip_i^T \in \mathcal {S}_n^+ \ (i=1,2,\ldots ,n)\). This is done by decomposing \(A \in \mathcal {S}_n\) into two parts:
such that the first part
is positive semidefinite. Since \(p_ip_i^T \in \mathcal {S}_n^+ \ (i=1,2,\ldots ,n)\) are only n linearly independent matrices in \(n(n+1)/2\) dimensional space \(\mathcal {S}_n\), the intersection of the set of linear combinations of \(p_ip_i^T\) and the nonnegative cone \(\mathcal {N}_n\) may not have a nonzero volume even if it is nonempty. On the other hand, if we have a set of positive semidefinite matrices \(p_ip_i^T \in \mathcal {S}_n^+ \ (i=1,2,\ldots ,n(n+1)/2)\) that gives a basis of \(\mathcal {S}_n\), then the corresponding intersection becomes the nonnegative cone \(\mathcal {N}_n\) itself, and we may expect a greater chance of finding a nonnegative matrix by enlarging the feasible region of \(\text{(LP) }_{P,\varLambda }\). In fact, we can easily find a basis of \(\mathcal {S}_n\) consisting of \(n(n+1)/2\) semidefinite matrices from n given orthogonal vectors \(p_i \in \mathbb {R}^n \ (i=1,2,\ldots ,n)\) based on the following result from Dickinson (2011).
Proposition 2
[Lemma 6.2 of Dickinson (2011)] Let \(v_i \in \mathbb {R}^n (i=1,2,\ldots ,n)\) be n-dimensional linear independent vectors. Then the set \(\mathcal {V} := \{(v_i + v_j)(v_i + v_j)^T \mid 1 \le i \le j \le n\}\) is a set of \(n(n+1)/2\) linearly independent positive semidefinite matrices. Therefore, the set \(\mathcal {V}\) gives a basis of the set \(\mathcal {S}_n\) of \(n \times n\) symmetric matrices.
The above proposition ensures that the following set \(\mathcal {B}_+(p_1,p_2,\ldots ,p_n)\) is a basis of \(n \times n\) symmetric matrices.
Definition 1
(Semidefinite basis type I) For a given set of n-dimensional orthogonal vectors \(p_i \in \mathbb {R}^n (i=1,2,\ldots ,n)\), define the map \(\varPi _+: \mathbb {R}^n \times \mathbb {R}^n \rightarrow \mathcal {S}_n^+\) by
We call the set
a semidefinite basis type I induced by \(p_i \in \mathbb {R}^n (i=1,2,\ldots ,n)\).
A variant of the semidefinite basis type I is as follows. Noting that the equivalence
holds for any \(i \ne j\), we see that \(\mathcal {B}_-(p_1,p_2,\ldots ,p_n)\) is also a basis of \(n \times n\) symmetric matrices.
Definition 2
(Semidefinite basis type II) For a given set of n-dimensional orthogonal vectors \(p_i \in \mathbb {R}^n (i=1,2,\ldots ,n)\), define the map \(\varPi _+: \mathbb {R}^n \times \mathbb {R}^n \rightarrow \mathcal {S}_n^+\) by
We call the set
a semidefinite basis type II induced by \(p_i \in \mathbb {R}^n (i=1,2,\ldots ,n)\).
Using the map \(\varPi _+\) in (19), the linear optimization problem \(\text{(LP) }_{P,\varLambda }\) in (10) can be equivalently written as
The problem \(\text{(LP) }_{P,\varLambda }\) is based on the decomposition (18). Starting with (18), the matrix A can be decomposed using \(\varPi _+(p_i,p_j)\) in (19) and \(\varPi _-(p_i,p_j)\) in (21) as
On the basis of the decomposition (23) and (24), we devise the following two linear optimization problems as extensions of \(\text{(LP) }_{P,\varLambda }\):
Problem \(\text{(LP) }_{P,\varLambda }^+\) has \(n(n+1)/2+1\) variables and \(n(n+1)\) constraints, and problem \(\text{(LP) }_{P,\varLambda }^{\pm }\) has \(n^2 +1\) variables and \(n(3n+1)/2\) constraints (see Table 1 ). Since \([P\varOmega P^T]_{ij}\) in (10) is given by \(\left[ \sum _{k=1}^n \omega _{kk} \varPi _+(p_k,p_k) \right] _{ij}\), we can prove that both linear optimization problems \(\text{(LP) }_{P,\varLambda }^+\) and \(\text{(LP) }_{P,\varLambda }^{\pm }\) are feasible and bounded by making arguments similar to the one for \(\text{(LP) }_{P,\varLambda }\). Thus, \(\text{(LP) }_{P,\varLambda }^+\) and \(\text{(LP) }_{P,\varLambda }^{\pm }\) have optimal solutions with corresponding optimal values \(\alpha _*^+(P, \varLambda )\) and \(\alpha _*^{\pm }(P, \varLambda )\).
If the optimal value \(\alpha _*^+(P, \varLambda )\) of \(\text{(LP) }_{P,\varLambda }^+\) is nonnegative, then, by rearranging (23), the optimal solution \(\omega ^{+*}_{ij} \ (1 \le i \le j \le n)\) can be made to give the following decomposition:
In the same way, if the optimal value \(\alpha _*^{\pm }(P, \varLambda )\) of \(\text{(LP) }_{P,\varLambda }^{\pm }\) is nonnegative, then, by rearranging (24), the optimal solution \(\omega ^{+*}_{ij} \ (1 \le i \le j \le n)\), \(\omega ^{-*}_{ij} \ (1 \le i < j \le n)\) can be made to give the following decomposition:
On the basis of the above observations, we can define new subcones of \(\mathcal {S}_n^+ + \mathcal {N}_n\) in a similar manner as (11) and (13).
For a given \(A \in \mathcal {S}_n\), define the following four sets of pairs of matrices
where \(\alpha _*^{+}(P,\varLambda )\) and \(\alpha _*^{\pm }(P,\varLambda )\) are optimal values of \(\text{(LP) }_{P,\varLambda }^+\) and \(\text{(LP) }_{P,\varLambda }^{\pm }\), respectively. Using the above sets, we define new subcones of \(\mathcal {S}_n^+ + \mathcal {N}_n\) as follows:
From the construction of problems \(\text{(LP) }_{P,\varLambda }\), \(\text{(LP) }_{P,\varLambda }^+\) and \(\text{(LP) }_{P,\varLambda }^{\pm }\), and the definitions (27) and (28), we can easily see that
hold. The corollary below follows from (iv)–(vi) of Theorem 2 and the above inclusions.
Corollary 1
-
(i)
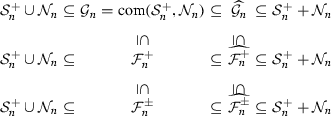
-
(ii)
If \(n = 2\), then each of the sets \(\mathcal {F}_n^{+}\), \(\widehat{\mathcal {F}_n^{+}}\), \(\mathcal {F}_n^{\pm }\), and \( \widehat{\mathcal {F}_n^{\pm }}\) coincides with \(\mathcal {S}_n^+ + \mathcal {N}_n\).
-
(iii)
The convex hull of each of the sets \(\mathcal {F}_n^{+}\), \(\widehat{\mathcal {F}_n^{+}}\), \(\mathcal {F}_n^{\pm }\), and \( \widehat{\mathcal {F}_n^{\pm }}\) is \(\mathcal {S}_n^+ + \mathcal {N}_n\).
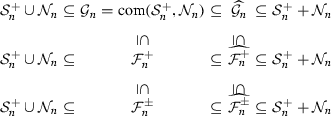
The following table summarizes the sizes of LPs (10), (25), and (26) that we have to solve in order to identify, respectively, \((P,\varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {G}_n}(A)\) (or \((P,\varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {G}_n}}(A)\)), \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {F}_n^{+}}(A)\) (or \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {F}_n^{+}}}(A)\)), and \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {F}_n^{\pm }}\) (or \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {F}_n^{\pm }}}(A)\)).
4 Identification of \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\)
In this section, we investigate the effect of using the sets \(\mathcal {G}_n\), \(\mathcal {F}_n^{+}\) and \(\mathcal {F}_n^{\pm }\) for identification of the fact \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\).
We generated random instances of \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) by using the method described in Section 2 of Bomze and Eichfelder (2013). For an \(n \times n\) matrix B with entries independently drawn from a standard normal distribution, we obtained a random positive semidefinite matrix \(S = BB^T\). An \(n \times n\) random nonnegative matrix N was constructed using \(N = C - c_{\min } I_n\) with \(C = F + F^T\) for a random matrix F with entries uniformly distributed in [0, 1] and \(c_{\min }\) being the minimal diagonal entry of C. We set \(A = S + N \in \mathcal {S}_n^+ + \mathcal {N}_n\). The construction was designed so as to maintain the nonnegativity of N while increasing the chance that \(S + N\) would be indefinite and thereby avoid instances that are too easy.
For each instance \(A \in \mathcal {S}^+_n+\mathcal {N}_n\), we used the MATLAB command “\([P, \varLambda ] = \text{ eig } (A) \)” and obtained \((P, \varLambda ) \in \mathcal {O}_n \times \mathcal {D}_n\). We checked whether \((P, \lambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {G}_n}\) (\((P,L) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {F}_n^{+}}\) and \((P,L) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {F}_n^{\pm }}\)) by solving (\(\text{ LP })_{P,\varLambda }\) in (10) ( (\(\text{ LP })_{P,\varLambda }^+\) in (25) and (\(\text{ LP })_{P,\varLambda }^{\pm }\) in (26)) and if it held, we identified that \(A \in \mathcal {G}_n\) (\(A \in \mathcal {F}_n^{+}\) and \(A \in \mathcal {F}_n^{\pm }\)).
Table 2 shows the number of matrices (denoted by “#A”) that were identified as \(A \in \mathcal {H}_n\) (\(A \in \mathcal {G}_n^{+}\), \(A \in \mathcal {F}_n^{+}\), \(A \in \mathcal {F}_n^{\pm }\) and \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\)) and the average CPU time (denoted by “A.t.(s)”), where 1000 matrices were generated for each n. We used a 3.07GHz Core i7 machine with 12 GB of RAM and Gurobi 6.5 for solving LPs. Note that we performed the last identification \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) as a reference, while we used SeDuMi 1.3 with MATLAB R2015a for solving the semidefinite program (3). The table yields the following observations:
-
All of the matrices were identified as \(A \in \mathcal {S}^+_n+\mathcal {N}_n\) by checking \((P,L) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {F}_n^{\pm }}\). The result is comparable to the one in Section 2 of Bomze and Eichfelder (2013). The average CPU time for checking \((P,L) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {F}_n^{\pm }}\) is faster than the one for solving the semidefinite program (3) when \(n \ge 20\).
-
For any n, the number of identified matrices increases in the order of the set inclusion relation: \(\mathcal {G}_n \subseteq \mathcal {F}_n^{+} \subseteq \mathcal {F}_n^{\pm }\), while the result for \(\mathcal {H}_n \not \subseteq \mathcal {G}_n\) is better than the one for \(\mathcal {G}_n\) when \(n=10\).
-
For the sets \(\mathcal {H}_n\), \(\mathcal {G}_n\) and \(\mathcal {F}_n^{+}\), the number of identified matrices decreases as the size of n increases.
5 LP-based algorithms for testing \(A \in \mathcal {COP}_n\)
In this section, we investigate the effect of using the sets \(\mathcal {F}_n^{+}\), \(\widehat{\mathcal {F}_n^{+}}\), \(\mathcal {F}_n^{\pm }\) and \(\widehat{\mathcal {F}_n^{\pm }}\) for testing whether a given matrix A is copositive by using Sponsel, Bundfuss, and Dür’s algorithm (Sponsel et al. 2012).
5.1 Outline of the algorithms
By defining the standard simplex \(\varDelta ^S\) by \(\varDelta ^S=\{x \in \mathbb {R}^n_+ \mid e^Tx =1 \}\), we can see that a given \(n \times n\) symmetric matrix A is copositive if and only if
(see Lemma 1 of Bundfuss and Dür 2008). For an arbitrary simplex \(\varDelta \), a family of simplices \(\mathcal {P}=\{\varDelta ^1, \ldots , \varDelta ^m\}\) is called a simplicial partition of \(\varDelta \) if it satisfies
Such a partition can be generated by successively bisecting simplices in the partition. For a given simplex \(\varDelta =\text{ conv }\{v_1, \ldots , v_n\}\), consider the midpoint \(v_{n+1}=\frac{1}{2}(v_i+v_j)\) of the edge \([v_i, v_j]\). Then the subdivision \(\varDelta ^1=\{v_1, \ldots , v_{i-1}, v_{n+1}, v_{i+1}, \ldots , v_n\}\) and \(\varDelta ^2=\{v_1, \ldots , v_{j-1}, v_{n+1}, v_{j+1}, \ldots , v_n\}\) of \(\varDelta \) satisfies the above conditions for simplicial partitions. See Horst (1997) for a detailed description of simplicial partitions.
Denote the set of vertices of partition \(\mathcal {P}\) by
Each simplex \(\varDelta \) is determined by its vertices and can be represented by a matrix \(V_\varDelta \) whose columns are these vertices. Note that \(V_\varDelta \) is nonsingular and unique up to a permutation of its columns, which does not affect the argument (Sponsel et al. 2012). Define the set of all matrices corresponding to simplices in partition \(\mathcal {P}\) as
The “fineness” of a partition \(\mathcal {P}\) is quantified by the maximum diameter of a simplex in \(\mathcal {P}\), denoted by
The above notation was used to show the following necessary and sufficient conditions for copositivity in Sponsel et al. (2012). The first theorem gives a sufficient condition for copositivity.
Theorem 4
[Theorem 2.1 of Sponsel et al. (2012)] If \(A \in \mathcal {S}_n\) satisfies
then A is copositive. Hence, for any \(\mathcal {M}_n \subseteq \mathcal {COP}_n\), if \(A \in \mathcal {S}_n\) satisfies
then A is also copositive.
The above theorem implies that by choosing \(\mathcal {M}_n = \mathcal {N}_n\) (see (2)), A is copositive if \(V^T_\varDelta AV_\varDelta \in \mathcal {N}_n\) holds for any \(\varDelta \in \mathcal {P}\).
Theorem 5
[Theorem 2.2 of Sponsel et al. (2012)] Let \(A \in \mathcal {S}_n\) be strictly copositive, i.e., \(A \in \mathrm{int}\,(\mathcal {COP}_n)\). Then there exists \(\varepsilon > 0\) such that for all partitions \(\mathcal {P}\) of \(\varDelta ^S\) with \(\delta (\mathcal {P}) < \varepsilon \), we have
The above theorem ensures that if A is strictly copositive (i.e., \(A \in \mathrm{int}\,(\mathcal {COP}_n)\)), the copositivity of A (i.e., \(A \in \mathcal {COP}_n\)) can be detected in finitely many iterations of an algorithm employing a subdivision rule with \(\delta (\mathcal {P}) \rightarrow 0\). A similar result can be obtained for the case \(A \not \in \mathcal {COP}_n\), as follows.
Lemma 2
[Lemma 2.3 of Sponsel et al. (2012)]
The following two statements are equivalent.
-
1.
\(A \notin \mathcal {COP}_n\)
-
2.
There is an \(\varepsilon > 0\) such that for any partition \(\mathcal {P}\) with \(\delta (\mathcal {P})<\varepsilon \), there exists a vertex \(v \in V(\mathcal {P})\) such that \(v^TAv<0\).
The following algorithm, from Sponsel et al. (2012), is based on the above three results.

As we have already observed, Theorem 5 and Lemma 2 imply the following corollary.
Corollary 2
-
1.
If A is strictly copositive, i.e., \(A \in \mathrm{int}\,(\mathcal {COP}_n)\), then Algorithm 1 terminates finitely, returning “A is copositive.”
-
2.
If A is not copositive, i.e., \(A \not \in \mathcal {COP}_n\), then Algorithm 1 terminates finitely, returning “A is not copositive.”
In this section, we investigate the effect of using the sets \(\mathcal {H}_n\) from (5), \(\mathcal {G}_n\) from (11), and \(\mathcal {F}_n^{+}\) and \(\mathcal {F}_n^{\pm }\) from (28) as the set \(\mathcal {M}_n\) in the above algorithm.
At Line 7, we can check whether \(V_\varDelta ^TAV_\varDelta \in \mathcal {M}_n\) directly in the case where \(\mathcal {M}_n = \mathcal {H}_n\). In other cases, we diagonalize \(V_\varDelta ^TAV_\varDelta \) as \(V_\varDelta ^TAV_\varDelta = P \varLambda P^T\) and check whether \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {M}_n}(V_\varDelta ^TAV_\varDelta )\) according to definitions (12) or (27). If the associated LP has the nonnegative optimal value, then we identify \(A \in \mathcal {M}_n\).
At Line 8, Algorithm 1 removes the simplex that was determined at Line 7 to be in no further need of exploration by Theorem 4. The accuracy and speed of the determination influence the total computational time and depend on the choice of the set \(\mathcal {M}_n \subseteq \mathcal {COP}_n\).
Here, if we choose \(\mathcal {M}_n = \mathcal {G}_n\) (respectively, \(\mathcal {M}_n = \mathcal {F}_n^{+}\), \(\mathcal {M}_n = \mathcal {F}_n^{\pm }\)), we can improve Algorithm 1 by incorporating the set \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {G}_n}\) (respectively, \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {F}_n^{+}}\), \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {F}_n^{\pm }}\)), as proposed in Tanaka and Yoshise (2015).

The details of the added steps are as follows. Suppose that we have a diagonalization of the form (6).
At Line 8, we need to solve an additional LP but do not need to diagonalize \(V_\varDelta ^TAV_\varDelta \). Let P and \(\varLambda \) be matrices satisfying (6). Then the matrix \(V_{\varDelta }^TP\) can be used to diagonalize \(V_\varDelta ^TAV_\varDelta \), i.e.,
while \(V_{\varDelta }^TP \in \mathbb {R}^{n \times n}\) is not necessarily orthogonal. Thus, we can test whether \((V_{\varDelta }^TP, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {M}_n}}\) by solving the corresponding LP according to the definitions (14) or (27). If \((V_{\varDelta }^TP, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {M}_n}}\) holds, then we can identify \(V_\varDelta ^TAV_\varDelta \in \widehat{\mathcal {M}_n}\)
If \((V_{\varDelta }^TP, \varLambda ) \not \in {\mathcal {P}}{\mathcal {L}}_{\widehat{\mathcal {M}_n}}\) at Line 8, we proceed to the original step to identify whether \(V_\varDelta ^TAV_\varDelta \in \mathcal {M}_n\) at Line 12. Similarly to Line 7 of Algorithm 1, we diagonalize \(V_\varDelta ^TAV_\varDelta \) as \(V_\varDelta ^TAV_\varDelta = P\varLambda P^T\) with an orthogonal matrix P and a diagonal matrix \(\varLambda \). Then we check whether \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {M}_n}\) by solving the corresponding LP, and if \((P, \varLambda ) \in {\mathcal {P}}{\mathcal {L}}_{\mathcal {M}_n}\), we can identify \(V_\varDelta ^TAV_\varDelta \in \mathcal {M}_n\).
At Line 18, we don’t need to diagonalize \(V_{\varDelta ^p}^TAV_{\varDelta ^p}\) or solve any more LPs. Let \(\omega ^* \in \mathbb {R}^n\) be an optimal solution of the corresponding LP obtained at Line 8 and let \(\varOmega ^* := \mathrm{Diag}\,(\omega ^*)\). Then the feasibility of \(\omega ^*\) implies the positive semidefiniteness of the matrix \(V_{\varDelta ^p}^TP(\varLambda - \varOmega ^*)P^TV_{\varDelta ^p}\). Thus, if \(V_{\varDelta ^p}^TP\varOmega ^*P^TV_{\varDelta ^p} \in \mathcal {N}_n\), we see that
and that \(V_{\varDelta ^p}^TAV_{\varDelta ^p} \in \widehat{\mathcal {M}_n}\).
5.2 Numerical results
This subsection describes experiments for testing copositivity using \(\mathcal {N}_n\),\(\mathcal {H}_n\), \(\mathcal {G}_n\), \(\mathcal {F}_n^{+}\), \(\widehat{\mathcal {F}_n^{+}}\), \(\mathcal {F}_n^{\pm }\) or \(\widehat{\mathcal {F}_n^{\pm }}\) as the set \(\mathcal {M}_n\) in Algorithms 1 and 2. We implemented the following seven algorithms in MATLAB R2015a on a 3.07 GHz Core i7 machine with 12 GB of RAM, using Gurobi 6.5 for solving LPs:
- Algorithm 1.1::
-
Algorithm 1 with \(\mathcal {M}_n = \mathcal {N}_n\).
- Algorithm 1.2::
-
Algorithm 1 with \(\mathcal {M}_n = \mathcal {H}_n\).
- Algorithm 2.1::
-
Algorithm 2 with \(\mathcal {M}_n = \mathcal {G}_n\) and \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {G}_n}\).
- Algorithm 1.3::
-
Algorithm 1 with \(\mathcal {M}_n = \mathcal {F}_n^{+}\).
- Algorithm 2.2::
-
Algorithm 2 with \(\mathcal {M}_n = \mathcal {F}_n^{+}\) and \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {F}_n^{+}}\).
- Algorithm 2.3::
-
Algorithm 2 with \(\mathcal {M}_n = \mathcal {F}_n^{\pm }\) and \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {F}_n^{\pm }}\).
- Algorithm 1.4::
-
Algorithm 1 with \(\mathcal {M}_n = \mathcal {S}_n^{+}+\mathcal {N}_n\).
As test instances, we used the two kinds of matrices arising from the maximum clique problem (Sect. 5.2.1) and from standard quadratic optimization problems (Sect. 5.2.2).
5.2.1 Results for the matrix arising from the maximum clique problem
In this subsection, we consider the matrix
where \(E \in \mathcal {S}_n\) is the matrix whose elements are all ones and the matrix \(A_G \in \mathcal {S}_n\) is the adjacency matrix of a given undirected graph G with n nodes. The matrix \(B_\gamma \) comes from the maximum clique problem. The maximum clique problem is to find a clique (complete subgraph) of maximum cardinality in G. It has been shown (in Klerk and Pasechnik 2002) that the maximum cardinality, the so-called clique number \(\omega (G)\), is equal to the optimal value of
Thus, the clique number can be found by checking the copositivity of \(B_{\gamma }\) for at most \(\gamma =n,n-1, \ldots , 1\).
Figure 3 shows the instances of G that were used in Sponsel et al. (2012). We know the clique numbers of \(G_{8}\) and \(G_{12}\) are \(\omega (G_{8}) = 3\) and \(\omega (G_{12}) = 4\), respectively.

Graphs \(G_{8}\) with \(\omega (G_{8})=3\) (left) and \(G_{12}\) with \(\omega (G_{12})=4\) (right)
The aim of the implementation is to explore the differences in behavior when using \(\mathcal {H}_n\), \(\mathcal {G}_n\), \(\mathcal {F}_n^{+}\), \(\widehat{\mathcal {F}_n^{+}}\), \(\mathcal {F}_n^{\pm }\) or \(\widehat{\mathcal {F}_n^{\pm }}\) as the set \(\mathcal {M}_n\) rather than to compute the clique number efficiently. Hence, the experiment examined \(B_{\gamma }\) for various values of \(\gamma \) at intervals of 0.1 around the value \(\omega (G)\) (see Tables 3, 4).
As already mentioned, \(\alpha _*(P,\varLambda ) < 0\) (\(\alpha ^+_*(P,\varLambda ) < 0\) and \(\alpha ^{\pm }_*(P,\varLambda ) < 0\)) with a specific P does not necessarily guarantee that \(A \not \in \mathcal {G}_n\) or \(A \not \in \widehat{\mathcal {G}_n}\) (\(A \not \in \mathcal {F}_n^{+}\) or \(A \not \in \widehat{\mathcal {F}_n^{+}}\), \(A \not \in \mathcal {F}_n^{\pm }\) or \(A \not \in \widehat{\mathcal {F}_n^{\pm }}\)). Thus, it not strictly accurate to say that we can use those sets for \(\mathcal {M}_n\), and the algorithms may miss some of the \(\varDelta \)’s that could otherwise have been removed. However, although this may have some effect on speed, it does not affect the termination of the algorithm, as it is guaranteed by the subdivision rule satisfying \(\delta (\mathcal {P}) \rightarrow 0\), where \(\delta (\mathcal {P})\) is defined by (29).

Graph of Table 4: iterations versus \(\gamma \) of Algorithms 1.2, 2.1, 2.3 and 1.4 for the graph \(G_{12}\)
Tables 3 and 4 show the numerical results for \(G_{8}\) and \(G_{12}\), respectively. Both tables compare the results of the following seven algorithms in terms of the number of iterations (the column “Iter.”) and the total computational time (the column “Time (s)” ):
The symbol “−” means that the algorithm did not terminate within 6 h. The reason for the long computation time may come from the fact that for each graph G, the matrix \(B_{\gamma }\) lies on the boundary of the copositive cone \(\mathcal {COP}_n\) when \(\gamma = \omega (G)\) (\(\omega (G_8)=3\) and \(\omega (G_{12})=4\)). See also Fig. 4, which shows a graph of the results of Algorithms 1.2, 2.1, 2.3, and 1.4 for the graph \(G_{12}\) in Table 4.
We can draw the following implications from the results in Table 4 for the larger graph \(G_{12}\) (similar implications can be drawn from Table 3):
-
At any \(\gamma \ge 5.2\), Algorithms 2.1, 1,3, 2.2, 2.3, and 1.4 terminate in one iteration, and the execution times of Algorithms 2.1, 1.3, 2.2, and 2.3 are much shorter than those of Algorithms 1.1, 1.2, or 1.4.
-
The lower bound of \(\gamma \) for which the algorithm terminates in one iteration and the one for which the algorithm terminates in 6 h decrease in going from Algorithm 1.3 to Algorithm 3.1. The reason may be that, as shown in Corollary 1, the set inclusion relation \(\mathcal {G}_n \subseteq \mathcal {F}_n^{+} \subseteq \mathcal {F}_n^{\pm } \subseteq \mathcal {S}_n^{+}+\mathcal {N}_n\) holds.
-
Table 1 summarizes the sizes of the LPs for identification. The results here imply that the computational times for solving an LP have the following magnitude relationship for any \(n \ge 3\):
$$\begin{aligned}&\text{ Algorithm } \text{2.1 }< \text{ Algorithm } \text{1.3 }< \text{ Algorithm } \text{2.2 } < \text{ Algorithm } \text{2.3 } . \end{aligned}$$On the other hand, the set inclusion relation \(\mathcal {G}_n \subseteq \mathcal {F}_n^{+} \subseteq \mathcal {F}_n^{\pm }\) and the construction of Algorithms 1 and 2 imply that the detection abilities of the algorithms also follow the relationship described above and that the number of iterations has the reverse relationship for any \(\gamma \)s in Table 4:
$$\begin{aligned}&\text{ Algorithm } \text{2.1 }> \text{ Algorithm } \text{1.3 }> \text{ Algorithm } \text{2.2 } > \text{ Algorithm } \text{2.3 } . \end{aligned}$$It seems that the order of the number of iterations has a stronger influence on the total computational time than the order of the computational times for solving an LP.
-
At each \(\gamma \in [4.1, 4.9]\), the number of iterations of Algorithm 2.3 is much larger than one hundred times those of Algorithm 1.4. This means that the total computational time of Algorithm 2.3 is longer than that of Algorithm 1.3 at each \(\gamma \in [4.1, 4.9]\), while Algorithm 1.4 solves a semidefinite program of size \(O(n^2)\) at each iteration.
-
At each \(\gamma < 4\), the algorithms show no significant differences in terms of the number of iterations. The reason may be that they all work to find a \(v \in V(\{\varDelta \})\) such that \(v^T(\gamma (E-A_G)-E)v<0\), while their computational time depends on the choice of simplex refinement strategy.

Graph of Table 4: time (s) versus \(\gamma \) of Algorithms 1.2, 2.1, 2.3 and 1.4 for the graph \(G_{12}\)
In view of the above observations, we conclude that Algorithm 2.3 with the choices \(\mathcal {M}_n = \mathcal {F}_n^{\pm }\) and \(\widehat{\mathcal {M}_n} = \widehat{\mathcal {F}_n^{\pm }}\) might be a way to check the copositivity of a given matrix A when A is strictly copositive.
The above results are in contrast with those of Bomze and Eichfelder (2013), where the authors show the number of iterations required by their algorithm for testing copositivity of matrices of the form (30). On the contrary to the first observation described above, their algorithm terminates with few iterations when \(\gamma < \omega (G)\), i.e., the corresponding matrix is not copositive, and it requires a huge number of iterations otherwise (Fig. 5).
It should be noted that Table 3 shows an interesting result concerning the non-convexity of the set \(\mathcal {G}_n\), while we know that \(\mathrm{conv}\,(\mathcal {G}_n) = \mathcal {S}_n^+ + \mathcal {N}_n\) (see Theorem 2). Let us look at the result at \(\gamma = 4.0\) of Algorithm 2.1. The multiple iterations at \(\gamma = 4.0\) imply that we could not find \(B_{4.0} \in \mathcal {G}_n\) at the first iteration for a certain orthogonal matrix P satisfying (6). Recall that the matrix \(B_{\gamma }\) is given by (30). It follows from \(E - A_G \in \mathcal {N}_n \subseteq \mathcal {G}_n\) and from the result at \(\gamma = 3.5\) in Table 3 that
Thus, the fact that we could not determine whether the matrix
lies in the set \(\mathcal {G}_n\) suggests that the set \(\mathcal {G}_n = \text{ com }(\mathcal {S}_n^+, \mathcal {N}_n)\) is not convex.
5.2.2 Results for the matrix arising from standard quadratic optimization problems
In this subsection, we consider the matrix
where \(E \in \mathcal {S}_n\) is the matrix whose elements are all ones and \(Q \in \mathcal {S}_n\) is an arbitrary symmetric matrix, not necessarily positive semidefinite. The matrix \(C_\gamma \) comes from standard quadratic optimization problems of the form,
In Bomze et al. (2000), it is shown that the optimal value of the problem
is equal to the optimal value of (32).
The instances of the form (32) were generated using the procedure random_qp in Nowak (1998) with two quartets of parameters \((n, s, k, d) = (10, 5, 5. 0.5)\) and \((n, s, k, d) = (20, 10, 10. 0.5)\), where the parameter n implies the size of Q, i.e., Q is an \(n \times n\) matrix. It has been shown in Nowak (1998) that random_qp generates problems, for which we know the optimal value and a global minimizer a priori for each. We set the optimal value as \(-10\) for each quartet of parameters.
Tables 5 and 6 show the numerical results for \((n, s, k, d) = (10, 5, 5, 0.5)\) and \((n, s, k, d) = (20, 10, 10, 0.5)\). We generated 2 instances for each quartet of parameters and performed the seven algorithms for these instances. Both tables compare the average values of the seven algorithms in terms of the number of iterations (the column “Iter.”) and the total computational time (the column “Time (s)” ): the symbol “−” means that the algorithm did not terminate within 30 minutes. In each table, we made the interval between the values \(\gamma \) smaller as \(\gamma \) got closer to the optimal value, to observe the behavior around the optimal value more precisely.
From the results in Tables 5 and 6, we can draw implications that are very similar to those for the maximum clique problem, listed (we hence, omitted discussing them here). A major difference from the implications for the maximum clique problem is that Algorithm 1.2 using the set \(\mathcal {H}_n\) is efficient for solving a small (\(n=10\)) standard quadratic problem, while it cannot solve the problem within 30 minutes when \(n=20\) and \(\gamma \ge -10.3125\).
6 Concluding remarks
In this paper, we investigated the properties of several tractable subcones of \(\mathcal {S}_n^+ + \mathcal {N}_n\) and summarized the results (as Figs. 1, 2). We also devised new subcones of \(\mathcal {S}_n^+ + \mathcal {N}_n\) by introducing the semidefinite basis (SD basis) defined as in Definitions 1 and 2. We conducted numerical experiments using those subcones for identification of given matrices \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) and for testing the copositivity of matrices arising from the maximum clique problem and from standard quadratic optimization problems. We have to solve LPs with \(O(n^2)\) variables and \(O(n^2)\) constraints in order to detect whether a given matrix belongs to those cones, and the computational cost is substantial. However, the numerical results shown in Tables 2, 3, 4 and 6 show that the new subcones are promising not only for identification of \(A \in \mathcal {S}_n^+ + \mathcal {N}_n\) but also for testing copositivity.
Recently, Ahmadi et al. (2015) developed algorithms for inner approximating the cone of positive semidefinite matrices, wherein they focused on the set \(\mathcal {D}_n \subseteq \mathcal {S}_n^+\) of \(n \times n\) diagonal dominant matrices. Let \(U_{n,k}\) be the set of vectors in \(\mathbb {R}^n\) that have at most k nonzero components, each equal to \(\pm 1\), and define
Then, as the authors indicate, the following theorem has already been proven.
Theorem 6
[Theorem 3.1 of Ahmadi et al. (2015), Barker and Carlson Barker and Carlson (1975)]
From the above theorem, we can see that for the SDP bases \(\mathcal {B}_+(p_1, p_2, \ldots , p_n)\) in (20), \(\mathcal {B}_-(p_1, p_2, \ldots , p_n)\) in (22) and n-dimensional unit vectors \(e_1, e_2, \ldots , e_n\), the following set inclusion relation holds:
These sets should be investigated in the future.
References
Ahmadi, A. A., Dash, S., & Hall, G. (2015). Optimization over structured subsets of positive semidefinite matrices via column generation. arXiv:1512.05402 [math.OC].
Alizadeh, F. (2012). An Introduction to formally real Jordan algebras and their applications in optimization, Handbook on Semidefinite, Conic and Polynomial Optimization (pp. 297–337). New York: Springer.
Barker, G. P., & Carlson, D. (1975). Cones of diagonally dominant matrices. Pacific Journal of Mathematics, 57, 15–32.
Berman, A. (1973). Cones, matrices and mathematical programming. Lecture notes in economics and mathematical systems (Vol. 79). Springer.
Berman, A., & Monderer, N. S. (2003). Completely positive matrices. Singapore: World Scientific Publishing.
Bomze, I. M. (1996). Block pivoting and shortcut strategies for detecting copositivity. Linear Algebra and its Applications, 248(15), 161–184.
Bomze, I. M. (2012). Copositive optimization—Recent developments and applications. European Journal of Operational Research, 216(3), 509–520.
Bomze, I. M., & De Klerk, E. (2002). Solving standard quadratic optimization problems via linear, semidefinite and copositive programming. Journal of Global Optimization, 24(2), 163–185.
Bomze, I. M., Dür, M., De Klerk, E., Roos, C., Quist, A. J., & Terlaky, T. (2000). On copositive programming and standard quadratic optimization problems. Journal of Global Optimization, 18(4), 301–320.
Bomze, I. M., & Eichfelder, G. (2013). Copositivity detection by difference-of-convex decomposition and \(\omega \)-subdivision. Mathematical Programming, Series A, 138(1), 365–400.
Brás, C., Eichfelder, G., & Júdice, J. (2015). Copositivity tests based on the linear complementarity problem. Computational Optimization and Applications, 63, 1–33.
Bundfuss, S. (2009). Copositive matrices, copositive programming, and applications. Ph.D. Dissertation, TU Darmstadt. http://www3.mathematik.tu-darmstadt.de/index.php?id=483. Confirmed March 20, 2017.
Bundfuss, S., & Dür, M. (2008). Algorithmic copositivity detection by simplicial partition. Linear Algebra and its Applications, 428(7), 1511–1523.
Burer, S. (2009). On the copositive representation of binary and continuous nonconvex quadratic programs. Mathematical Programming, 120(4), 479–495.
De Klerk, E., & Pasechnik, D. V. (2002). Approximation of the stability number of a graph via copositive programming. SIAM Journal on Optimization, 12, 875–892.
Deng, Z., Fang, S.-C., Jin, Q., & Xing, W. (2013). Detecting copositivity of a symmetric matrix by an adaptive ellipsoid-based approximation scheme. European Journal of Operations research, 229(1), 21–28.
Diananda, P. H. (1962). On non-negative forms in real variables some or all of which are non-negative. Mathematical Proceedings of the Cambridge Philosophical Society, 58(1), 17–25.
Dickinson, P. J. C. (2011). Geometry of the copositive and completely positive cones. Journal of Mathematical Analysis and Applications, 380, 377–395.
Dickinson, P. J. C. (2014). On the exhaustivity of simplicial partitioning. Journal of Global Optimization, 58(1), 189–203.
Dickinson, P. J. C., & Gijben, L. (2014). On the computational complexity of membership problems for the completely positive cone and its dual. Computational Optimization and Applications, 57(2), 403–415.
Dür, M. (2010). Copositive programming—A survey. In Recent advances in optimization and its applications in engineering (pp. 3–20). Berlin: Springer.
Dür, M., & Hiriart-Urruty, J.-B. (2013). Testing copositivity with the help of difference-of-convex optimization. Mathematical Programming, 140(1), 31–43.
Faraut, J., & Korányi, A. (1994). Analysis on symmetric cones. Oxford: Oxford University Press.
Fenchel, W. (1953). Convex cones, sets and functions. In D. W. Blackett (Ed.), Mimeographed notes. Princeton, NJ: Princeton University Press.
Fiedler, M., & Pták, V. (1962). On matrices with non-positive off-diagonal elements and positive principal minors. Czechoslovak Mathematical Journal, 12(3), 382–400.
Golub, G. H., & Van Loan, C. F. (1996). Matrix computations (Third ed.). Baltimore: Johns Hopkins University Press.
Horst, R. (1997). On generalized bisection of \(n\)-simplices. Mathematics of Computation, 66(218), 691–698.
Horn, R. A., & Johnson, C. R. (1985). Matrix analysis. Cambridge: Cambridge University Press.
Jarre, F., & Schmallowsky, K. (2009). On the computation of \({\cal{C}}^*\) certificates. Journal of Global Optimization, 45(2), 281–296.
Johnson, C. R., & Reams, R. (2008). Constructing copositive matrices from interior matrices. The Electronic Journal of Linear Algebra, 17(1), 9–20.
Murty, K. G., & Kabadi, S. N. (1987). Some NP-complete problems in quadratic and nonlinear programming. Mathematical Programming, 39(2), 117–129.
Nowak, I. (1998). A global optimality criterion for nonconvex quadratic programming over a simplex. Pre-Print 9817, Humboldt University, Berlin. http://wwwiam.mathematik.hu-berlin.de/ivo/ivopages/work.html. Confirmed March 20, 2017.
Povh, J., & Rendl, F. (2007). A copositive programming approach to graph partitioning. SIAM Journal on Optimization, 18(1), 223–241.
Povh, J., & Rendl, F. (2009). Copositive and semidefinite relaxations of the quadratic assignment problem. Discrete Optimization, 6(3), 231–241.
Rockafellar, R. T., & Wets, R. J.-B. (1998). Variational analysis. Berlin: Springer.
Sponsel, J., Bundfuss, S., & Dür, M. (2012). An improved algorithm to test copositivity. Journal of Global Optimization, 52(3), 537–551.
Tanaka, A., & Yoshise, A. (2015). An LP-based algorithm to test copositivity. Pacific Journal of Optimization, 11(1), 101–120.
Yoshise, A., & Matsukawa, Y. (2010). On optimization over the doubly nonnegative cone. In Proceedings of 2010 IEEE multi-conference on systems and control (pp. 13–19).
Z̆ilinskas, J., & Dür, M. (2011). Depth-first simplicial partition for copositivity detection, with an application to MaxClique. Optimization Methods and Software, 26(3), 499–510.
Acknowledgements
The authors would like to sincerely thank the anonymous reviewers for their thoughtful and valuable comments which have significantly improved the paper. Among others, one of the reviewers pointed out that Proposition 2 is Lemma 6.2 of Dickinson (2011), suggested to revise the title of the paper, and the definitions of the sets \(\mathcal {G}_n\), \(\mathcal {F}_n^{+}\), etc., to be more accurate, and gave the second example in (16).
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors thank one of the anonymous reviewers for suggesting the title, which had previously been “Tractable Subcones and LP-based Algorithms for Testing Copositivity.” This research was supported by the Japan Society for the Promotion of Science through a Grant-in-Aid for Scientific Research ((B)23310099) of the Ministry of Education, Culture, Sports, Science and Technology of Japan.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Tanaka, A., Yoshise, A. LP-based tractable subcones of the semidefinite plus nonnegative cone. Ann Oper Res 265, 155–182 (2018). https://doi.org/10.1007/s10479-017-2720-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-017-2720-z