
Abstract
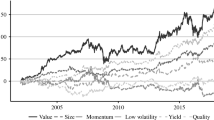
Exposures to risk factors, as opposed to individual securities or bonds, can lead to an ex-ante improved risk management and a more transparent and cheaper way of developing active asset allocation strategies. This paper provides an extensive analysis of eight state-of-the-art risk-minimization schemes and compares risk factor performance in a conditional performance analysis, contrasting good and bad states of the economy. The investment universe spans a total of 25 risk factors, including size, momentum, value, high profitability and low investments, from five non-overlapping regions (i.e., USA, UK, Japan, Developed Europe ex. UK and, Asia ex. Japan). Considering as investment period the interval from May 2004 to June 2015, our results show that each single factor yields positive premia in exchange for risk, which can lead to considerable underperformance and extensive recovery periods during times of crisis. The best factor investments can be found in Asia ex. Japan and the US. However, risk factor based portfolio construction across the various regions enables the investor to exploit low correlation structures, reducing the overall volatility, as well as tail- and extreme risk measures. Finally, the empirical results point towards the long-only global minimum variance portfolio, as the best risk minimization strategy.



Similar content being viewed by others


Notes
Please refer to the ERI Scientific Beta Website for a complete list of all scoring criteria. http://www.scientificbeta.com/.
We extend our analysis to also cover, 250 (1 year) and 1250 (5 years) daily observations. The reported results with regard to the factor indices and the portfolios are robust towards those changes, and available upon request.
The \(\ell _{1}\)-Norm is defined as: \(||\varvec{w}||_{1} = \sum _{i=1}^{K}|w_{i}|\).
1 bps = 0.01% = 0.0001.
Detailed results for the different cost regimes are available from the authors upon request.
Please refer to Sect. 4.3 for a detailed explanation of the ENC.
See Sect. 4.3 for a detailed description of the ENUB.
It might be argued, following Fama and French (2006), that the value factor is redudant, given that one already considers the market, the size, the investment and the profitability premium. However, in the presence of the momentum factor, Asness et al. (2015) show that adding a value tilt does enhance the risk diversification of a factor portfolio.
References
Amenc, N., Goltz, F., Lodh, A., & Martellini, L. (2015). Scientific beta multi-strategy factor indices: Combining factor tilts and improved diversification. ERI Scientific Beta Publication.
Asness, C., Frazzini, A., Israel, R., & Moskowitz, T. (2015). Fact, fiction, and value investing. Journal of Portfolio Management, 42(1), 34–52.
Bai, J., & Ng, S. (2002). Determining the number of factors in approximate factor models. Econometrica, 70(1), 191–221.
Becker, F., Guertler, M., & Hibbeln, M. (2015). Markowitz versus michaud: Portfolio optimization strategies reconsidered. The European Journal of Finance, 21(4), 269–291.
Benartzi, S., & Thaler, R. (2001). Naive diversification ststrategies defined contribution plans. American Economic Review, 91(1), 79–98.
Bessler, W., & Wolff, D. (2015). Do commodities add value in multi-asset-portfolios? An out-of-sample analysis for different investment strategies. Journal of Banking and Finance, 60, 1–20.
Bessler, W., Opfer, H., & Wolff, D. (2017). Multi-asset portfolio optimization and out-of-sample performance: An evaluation of Black–Litterman, mean-variance, and naive diversification approaches. The European Journal of Finance, 23(1), 1–30.
Best, M., & Grauer, J. (1991). On the sensitivity of mean-variance-efficient portfolios to changes in asset means: Some analytical and computational results. The Review of Financial Studies, 4(2), 315–342.
Broadie, M. (1993). Computing efficient frontiers using estimated parameters. Annals of Operations Research, 45(1), 2158.
Brodie, J., Daubechies, I., DeMol, C., Giannone, D., & Loris, D. (2009). Sparse and stable markowitz portfolios. Proceedings of the National Academy of Science, 106(30), 12,267–12,272.
Bruder, B., & Roncalli. T. (2012). Managing risk exposures using the risk budgeting approach. SSRN www.ssrn.com/abstract=2009778.
Chopra, V., & Ziemba, W. (1993). The effect of errors in means, variances, and covariances on optimal portfolio choice. Journal of Portfolio Management, 19, 6–12.
Chordia, T., & Shivakumar, L. (2002). Momentum, business cycle, and time-varying expected returns. Journal of Finance, 57(2), 985–1019.
Choueifaty, Y., & Coignard, Y. (2008). Toward maximum diversification. Journal of Portfolio Management, 34(4), 40–51.
Choueifaty, Y., Froidure, T., & Reynier, J. (2011). Properties of the most diversified portfolio. Journal of Investment Strategies, 2(2), 49–70.
Christoffersen, P., Errunza, V. R., Jacobs, K., & Jin, X. (2010) Is the potential for international diversification disappearing?. sSRN: http://ssrn.com/abstract=1573345.
Clarke, R., de Silva, H., & Thorley, S. (2011). Minimum variance portfolio composition. Journal of Portfolio Management, 37(2), 31–45.
Cooper, I. (2006). Asset pricing implications of non-convex adjustment costs and irreversibility of investment. The Journal of Finance, 61(1), 139–170.
Cooper, M., Gulen, H., & Schill, M. (2008). Asset growth and the cross section of stock returns. Journal of Finance, 63(4), 1609–1651.
Coqueret, G., & Milhau, V. (2014). Estimating covariance matrices for portfolio optimization. ERI Scientific Beta White Paper.
Daly, J., Crane, M., & Ruskin, H. (2008). Random matrix theory filters in portfolio optimisation: A stability approach. Physica A: Statistical Mechanics and Its Applications, 387(16–17), 4248–4260.
De Souza Oliveira, T. (2014). Discount rates, market frictions, and the mystery of the size premium. Ph.D. thesis, University of Southern Denmark.
Deguest, R., Martellini, L., & Meucci, A. (2013). Risk parity and beyond—From asset allocation to risk allocation decisions. SSRN: http://ssrn.com/abstract=2355778.
DeMiguel, V., Garlappi, L., Nogales, F., & Uppal, R. (2009a). A generalized approach to portfolio optimization: Improving performance by constraining portfolio norm. Management Science, 55, 798–812.
DeMiguel, V., Garlappi, L., Nogales, F., & Uppal, R. (2009b). Optimal versus naive diversification: How inefficient is the 1/n portfolio strategy? Review of Financial Studies, 22(5), 1915–1953.
Fama, E., & French, K. (2006). Profitability, investment and average returns. Journal of Financial Economics, 82, 491–518.
Fama, E. F., & French, K. R. (2007). Migration. Financial Analysts Journal, 63, 48–58.
Fan, J., Fan, Y., & Lv, J. (2008). High didimension covariance matrix estimation using a factor model. Journal of Econometrics, 147(1), 186–197.
Fan, J., Zhang, J., & Yu, K. (2009) Asset allocation and risk assessment with gross exposure constraints for vast portfolios. Working Paper Princton University, New Jersey, USA.
Fan, J., Zhang, J., & You, K. (2012). Vast portfolio selection with gross-exposure constraint. Journal of the American Statistical Association, 107(498), 592–606.
Fastrich, B., Paterlini, S., & Winker, P. (2015). Constructing optimal sparse portfolios using regularization methods. Computational Management Science, 12(3), 417–434.
Ferson, W., & Qian, M. (2004) Conditional performance evaluation, revisited. Boston College Working Paper.
Giamouridis, D., & Paterlini, S. (2010). Regular(ized) hedge fund clones. Journal of Financial Research, 33(3), 223–247.
Gulpinar, N., & Pachamanova, D. (2013). A robust optimization approach to asset-liability management under time-varying investment opportunities. Journal of Banking and Finance, 36(6), 2031–2041.
Hartmann, P., Straetmans, S., & de Vries, C. (2001). Asset market linkages in crisis periods. Review of Economics and Statistics, 86(1), 313–326.
Hasanhodzic, J., & Lo, A. (2006). Can hedge-fund returns be replicated?: The linear case. Journal of Investment Management, 5(2), 5–45.
Haugen, R., & Baker, N. (1991). The efficient market inefficiency of capitalization-weighted stock portfolios. Journal of Portfolio Management, 17(3), 35–40.
Hou, K., Xue, C., & Zhang, L. (2015). Digesting anomalies: An investment approach. Review of Financial Studies, 28(3), 650–705.
Hsu, J. C. (2006). Cap-weighted portfolios are sub-optimal portfolios. Journal of Investment Management, 4(3), 1–10.
Ilmanen, A., & Kizer, J. (2012). The death of diversification has been greatly exaggerated. Journal of Portfolio Management, 38, 15–27.
Jagannathan, R., & Ma, T. (2003). Risk reduction in large portfolios: Why imposing the wrong constraints helps. The Journal of Finance, 58(4), 1651–1683.
Jegadeesh, N., & Titman, S. (1993). Returns to buying winners and selling losers: Implications for stock market efficiency. Journal of Finance, 48(1), 65–91.
Kourtis, A., Dotsis, G., & Markellos, R. (2012). Parameter uncertainty in portfolio selection: Shrinking the inverse covariance matrix. Journal of Banking and Finance, 36, 2522–2531.
Ledoit, O., & Wolf, M. (2004). Honey, I shrunk the covariance matrix. Journal of Portfolio Management, 30(4), 110–119.
Ledoit, O., & Wolf, M. (2008). Robust performance hypothesis testing with the sharpe ratio. Journal of Empirical Finance, 15, 850–859.
Liu, L., & Zhang, L. (2008). Momentum profits, factor pricing, and macroeconomic risk. Review of Financial Studies, 21(6), 2417–2448.
Lohre, H., Opfer, H., & Orszag, G. (2014). Diversifying risk parity. Journal of Risk, 16(5), 53–79.
Maillard, S., Roncalli, T., & Teiletche, J. (2008) Equally-weighted risk contributions:a new method to build risk balanced diversified portfolios. http://www.thierry-roncalli.com/download/erc-slides.pdf.
Maillard, S., Roncalli, T., & Teiletche, J. (2010). The properties of equally weighted risk contribution portoflios. The Journal of Portfolio Management, 36(4), 60–70.
Markowitz, H. (1952). Portfolio selection. The Journal of Finance, 7(1), 77–91.
Martellini, L., Milhau, V., & Tarelli, A. (2014). Towards conditional risk parity? Improving risk budgeting techniques in changing economic environments. ERI Scientific Beta Publication. http://www.edhec-risk.com/edhec-publications/all-publications.
Merton, R. (1973). An intertemporal capital asset pricing model. Econometrica, 41(5), 867–887.
Merton, R. C. (1980). On estimating the expected return on the market: An exploratory investigation. Journal of Financial Economics, 8(4), 323–361.
Meucci, A. (2010). Managing diversification. Risk, 22(5), 74–79.
Meucci, A., Santangelo, A., & Deguest R. (2014). Measuring portfolio diversification based on optimized uncorrelated factors. SSRN: http://ssrn.com/abstract=2276632.
Michaud, R. (1989). The markowitz optimization enigma: Is ’optimized’ optimal?. Financial Analyst Journal, 45(1), 31–42.
Novy-Marx R. (2013). The quality dimension of value investing. Simon Graduate School of Business. www.simon.rochester.edu.
Platanakis, E., & Sutcliffe, C. (2017). Asset-liability modelling and pension schemes: The application of robust optimization to USS. The European Journal of Finance, 23(4), 324–352.
Roncalli, T. (2013). Introduction to risk parity and budgeting. Chapman & Hall/CRC Financial Mathematics Series.
Ross, S. (1976). The arbitrage theory of capital asset pricing. Journal of Economic Theory, 13(3), 341–360.
Rouwenhorst, G. (1998). International momentum strategies. Journal of Finance, 53(1), 267–284.
Titman, S., Wei, K., & Xie, F. (2004). Capital investments and stock returns. Journal of Financial and Quantitative Analysis, 39, 677–700.
Van Gelderen, E., & Huij, J. (2013). Academic knowledge dissemination in the mutual fund industry: Can mutual funds successfully adopt factor investing strategies?. sSRN: http://ssrn.com/abstract=2295865.
Weber, V., & Peres, F. (2013). Hedge fund replication: Putting the pieces together. Journal of Investment Strategies, 3(1), 61–119.
Windcliff, H., & Boyle, P. (2004). The 1/n pension investment puzzle. North American Actuarial Journal, 8(3), 32–45.
Zhang, L. (2005). The value premium. Journal of Finance, 60(1), 67–103.
Author information
Authors and Affiliations
Corresponding author
Additional information
Disclaimer The opinions expressed in this article are those of the authors and do not necessarily reflect the views of J.P. Morgan. We thank two anonymous referees for helpful feedback that lead to a significant improvement of the paper. Sandra Paterlini acknowledges financial support from ICT COST ACTION 1408–CRONOS.
Appendices
Appendix 1: Risk minimization allocation strategies
1.1 Equally weighted portfolio
One of the thoughest benchmarks to beat is the equally weighted (EW) portfolio, which achieves a naïve form of diversification, by investing an equal amount of wealth in each of the N assets, such that:
where \(w_i\) is the weight allocated to the ith-asset, for \(i=1,{\ldots },N\).
The EW portfolio is the least concentrated portfolio in terms of weights, having the most evenly spread out dollar amount invested in each asset. It distinguishes itself from other diversification schemes, by being the portfolio with maximum effective number (N) of constituents (ENC).Footnote 6 However, the EW portfolio ignores the risk of the assets, either in isolation (volatilities) or when combined into a portfolio (covariances). The different constituents’ contributions to portfolio risk may be quite different from the dollar contribution. As a result, an EW portfolio of two assets with very different levels of volatility would have an unbalanced distribution of risk contributions, with most of the risk coming from the asset with largest volatility.
The EW is the best choice when one believes that it is impossible to predict assets volatilities, the individual return parameters of portfolio constituents, and their correlations. It coincides with the efficient portfolio in the mean-variance framework if the expected returns and volatilities of stocks are assumed to be equal and the correlation is uniform. Interestingly, DeMiguel et al. (2009b) show that this naive diversification can lead to better out-of-sample performance, in terms of SPR, certainty-equivalent return and turnover, than optimized portfolios which are generally less efficient, due to estimation errors. On the other hand, DeMiguel et al. (2009a) show that also norm-constrained portfolios can be better alternatives than EW strategies.
1.2 Global minimum variance portfolio
Disregarding the mean as an input parameter in the framework of Markowitz (1952) and restricting the weights to be larger than zero, the well-known GMV-LO portfolio can be computed, by solving the following optimization problem:
where \(\sigma _{p}^2\) is the variance of portfolio p, \(\varvec{w}\) is the \(N\times 1\)-weight vector of asset weights, and \(\varSigma \) is the \(N \times N\)-covariance matrix.
Here, we focus on the GMV portfolio under long-only constraints (GMV-LO) and also on the GMV under flexible norm constraints (GMV-N). Fan et al. (2012) show that the long-only constraint works as an \(\ell _{1}\)-norm, shrinking the portfolio weights towards zero and promoting sparse solutions. In the absence of any constraint, most of the risk reduction, accomplished by the GMV portfolio, comes from concentrating in assets with low volatility, as opposed to exploiting the correlation effects across assets. Adding, to the GMV allocation, flexible concentration constraints on the 2-norm \(||\cdot ||_{2}\), instead of rigid upper and lower bounds on individual stock weights, allow for a better use of the correlation structure and improved out-of-sample risk and return properties.
For constructing the GMV-N, we add to (2), the nonlinear constraint that the number of active positions have to be at least one-third of the number of stocks in the portfolio (N / 3):
Practically, both constraints set a lower bound on the effective number of constituents. The norm-constraint (3), aims at tackling the problem of concentration in low volatility stocks that is specific to GMV allocation (Clarke et al. 2011).
1.3 Equal risk contribution portfolio
The Equal Risk Contribution (ERC) portfolio aims to equalize the marginal risk contributions of different assets in the portfolio. In the case of the ERC approach, constituents that either have lower volatilities, lower correlation with the other assets, or both, are assigned a larger weight in the portfolio. Given that portfolio variance can be decomposed as:
the marginal contribution to the portfolio risk for asset i is given as:
where \((\varSigma \varvec{w})_{i}\) denotes the ith row of the product of \(\varSigma \) and \(\varvec{w}\).
The ERC portfolio aims to equalize risk contributions from all assets in the portfolio, but does not have an analytical solution. The reason for this is that the weights are endogenous in determining the risk contribution of each asset in the portfolio. However, the solution can be obtained numerically as:
The ERC portfolio is less sensitive to small changes in the covariance matrix than the GMV portfolio. Maillard et al. (2010) show that the ERC portfolio coincides with the optimal GMV portfolio, when the correlation and the SPR are equal among all assets. It may be viewed as a type of variance-minimizing portfolio, subject to a constraint of sufficient diversification in terms of component weights and with a volatility between that of the GMV and the EW portfolio.
The drawbacks of this methodology are the fact that the “marginal” contribution to risk involves an arbitrary attribution of the correlated components, i.e. the contribution of asset i to the portfolio variance depends on the covariance of asset i with the other assets included in the portfolio. Furthermore, it overlooks the fact that well-diversified portfolios, from the point of equal dollar or equal risk contribution of each constituent, may actually be heavily exposed to a small number of independent factors. Hence, they are not so diversified with regard to independent factor exposures. To circumvent these drawbacks the investor can consider a MLT-RP methodology, as presented below.
1.4 Minimum linear torsion: risk parity portfolio
The Minimum Linear Torsion-Risk Parity (MLT-RP) portfolio equalises the contribution of independent risk factors, rather than the contribution of individual constituents (Meucci et al. 2014). This methodology involves, as an additional step, the transformation of correlated asset returns into uncorrelated risk factors that are the closest to the initial assets in terms of tracking error. It is based on the diversification measure proposed by Meucci et al. (2014), namely the entropy-based measure of the effective number of uncorrelated minimum-torsion bets (ENUB).Footnote 7 Central to this methodology is that the portfolio return can be expressed as a combination of uncorrelated factors obtained through the Minimum Linear Torsion methodology. The advantage of introducing these uncorrelated factors is that the portfolio variance can be decomposed as a sum of the contributors of each factor’s variance:
where T is the decorrelated Torsion matrix, and \(w_{F_{k}}\) and \(\sigma _{F_{k}}\) is the weight and the risk corresponding to the minimum-torsion independent factor k, respectively.
It follows that the relative contribution to total risk from each uncorrelated bet is:

where  represents the variance of the minimum torsion independent factor k, and
represents the variance of the minimum torsion independent factor k, and  the variance of the portfolio returns.
the variance of the portfolio returns.
The MLT-RP-LO portfolio aims at equalizing the risk contributions from all uncorrelated bets in the portfolio. Similarly to the ERC approach, the MLT-RP-LO portfolio does not have an analytical solution because portfolio weights are endogenous in determining the risk contribution of each minimum-torsion independent factor in the portfolio. However, the solution can be obtained numerically by:

See Meucci et al. (2014) for a full description.
1.5 Inverse volatility portfolio
Maillard et al. (2010) show that under the assumption of uniform cross-correlations between the constituents, the risk parity portfolio weights are proportional to the inverse of the stocks’ individual volatilities. This is the Inverse Volatility (IV) portfolio.
Assuming equal pairwise correlations \(\rho _{ij} = \rho \) for all \(i \ne j\), the risk contribution of asset i to portfolio variance can be written as:
In order to have:
Maillard et al. (2010) show that the solution to (13) is given by:
where \(\sigma _{i}\) represents the volatility of asset i.
In other words, if one trusts the volatility estimates, and assuming constant correlation, thus disregarding estimation errors in the correlation matrix, an alternative approach to target risk parity is to weight assets by the inverse of their volatility.
A key advantage of this approach is its analytical simplicity and its intuitive appeal: the higher (lower) the volatility of a component, the lower (higher) its weight in the IV portfolio. The disadvantages of the IV portfolio include that investors cannot exploit the differences between cross-correlations in the weighting of the stocks. Maillard et al. (2008) provide evidence that the weights of the ERC portfolio may differ significantly from those of the IV portfolio, especially when both negative and positive correlations exist. The authors report that the differences seem to increase with the number of constituents. However, the two portfolios’ weights differ less, when there are only positive coefficients in the correlation matrix, which is generally the case for long-only portfolios exposed solely to equity risk.
1.6 Maximum diversification portfolio
The Maximum Diversification (MDV) portfolio, formally introduced by Choueifaty and Coignard (2008), aims at maximizing the diversification ratio, defined as the ratio of the weighted average asset volatility to overall portfolio volatility:
where \(\varvec{w}\) is the weights vector and \(DR(\varvec{w})\) is the Diversification Ratio.
The DR is greater than 1 for portfolios made up of assets that are not perfectly correlated, as the relatively high volatility of component assets results in overall lower portfolio volatility through the risk reduction effect of correlations. The MDV portfolio coincides with the tangency portfolio, if the SPR for all assets are equal, or, in other words, the excess returns of assets are proportional to their volatilities.
1.7 Maximum decorrelation portfolio
Another portfolio that aims at minimizing portfolio volatility, but better exploits the information provided by the mutual correlation coefficients is the Maximum Decorrelation (MDC) portfolio. The idea behind the MDC portfolio is to combine stocks, as to exploit the risk reduction effect stemming from low correlations, rather than reducing risk by concentrating in low volatility constituents. The MDC portfolio aims at minimising the portfolio volatility under the assumption that individual volatilities are identical, that is:
where \(\varvec{w}\) is the weight vector and \(\varOmega \) is the correlation matrix.
The MDC portfolio uses only the information provided by the correlation structure. Still, the risk reduction provided by the GMV framework can potentially also be attained by the MDC portfolio, which avoids concentration by ignoring differences in individual volatilities. It is worth noting that this approach implies no explicit control on the total portfolio risk that results from the volatility of each constituent.
Appendix 2: Risk factors
Size premium The size premium captures the effect that small stocks (stocks with lower market capitalisation) on average outperform large stocks. Fama and French (2007) found evidence that the size premium is the result of small stocks earning extreme positive returns and becoming bigger stocks. Souza (2014) analyses the size premium over a long term period of 85 years and finds that the premium is positive most of the time, and statistically significant especially during time periods when risk premia are high (periods with high book-to-market equity of the aggregate stock market).
Value premium Footnote 8 The value premium is the well established finding that stocks with high book-to-market ratios (value stocks) yield higher average returns than those with low book-to-market ratios (growth stocks). In other words, value investments favour stocks that have a low price relative to fundamental firm characteristics. Economic explanations for this finding includes among others, that value firms are riskier than growth firms during turbulent periods, when the price of risk is high (Zhang 2005), or that firms with a high book-to-market ratio can benefit more from positive shocks in the real economy than low book-to-market firms, because they have excess capital (Cooper 2006).
Momentum premium The pioneering research of Jegadeesh and Titman (1993) suggests that if stock prices overreact or underreact to information, then there exist profitable trading strategies that select stocks based on their past returns. The authors show that most of the returns of the zero-cost portfolios (i.e. long winners minus short losers) are positive. Rouwenhorst (1998) supports these results, by using an internationally diversified relative strength portfolio, which invests in medium-term winners and sells past medium-term losers, showing that the momentum in returns can be found in all 12 countries of the sample. The economic rationale for the momentum premium was advocated by Chordia and Shivakumar (2002), who argue that the profit of the momentum strategies is explained by common macroeconomic variables that are related to the business cycle, while Liu and Zhang (2008) found that winners have temporarily higher loadings on the growth rate of industrial production than recent losers, and that this exposure explains more than half of the momentum profits.
High profitability and low investment premium Profitability is typically proxied by the Return on Equity (ROE), defined as net income divided by shareholders’ equity. Investment is typically characterized by asset growth, defined as the change in book value of assets over previous years. Novy-Marx (2013) shows that profitable firms generate higher returns than unprofitable firms. Cooper et al. (2008) show that a firm’s asset growth is an important determinant of stock returns. In their analysis, low investment firms (firms with low asset growth rates) generate about 8% annual outperformance over high investment firms. Titman et al. (2004) show a negative relation between investment, which they measure by the growth of capital expenditures, and stock returns in the cross section.
Regarding the economic justification for profitability and investment factors, two studies are commonly stated: (1) Fama and French (2006) derive the relation between book-to-market ratio, expected investment, expected profitability and expected stock returns from the dividend discount model, arguing that (a) controlling for book-to-market and expected growth in book equity, more profitable firms (firms with high earnings relative to book equity) have higher expected return; and (b) controlling for book-to-market and profitability, firms with higher expected growth in book equity (high reinvestment of earnings) have lower expected returns. Finally, (2) Hou et al. (2015) argue that high profitability and low investments are driven by a high discount rate. Said differently, if the discount rate was not high enough to offset the high profitability—i.e. providing investments with pos. NPV given the high discount rate—the firm would face many investment opportunities with positive NPV and thus invest more by accepting less profitable investments.
Appendix 3: Risk- and return measures
In the following section, we will explain our used risk and return metrics in more detail. Where applicable, we give further comments beside the plain mathematical formulation. Otherwise, we restrict ourselves to a brief explanation and refer for more details to the given references. For all measures, assume that we have N factors and T out of sample observations. Now, let \(\varvec{w}_{t} = [w_{1, t}, {\ldots }, w_{N, t}]'\), be the weight vector of the factor portfolio for one of the eight risk minimization allocation strategies at rebalancing period t, and where \(w_{n, t}\) is, respectively, the idiosyncratic weight for factor k at time t. Furthermore, let \(\varvec{r}_{t} = [r_{1}, {\ldots },r_{N}]'\), be the return vector of the N risk factors at time t, with \(r_{n, t}\) being the idiosyncratic return of factor n at time t. Then the out of sample portfolio return time series is given as \(\varvec{R} = [R_{1}, {\ldots }, R_{T}]'\), where \(R_{t} = \varvec{w}'_{t}\varvec{r}_{t}\) is the portfolio return at time t. Given \(\varvec{R}\), we compute the following risk and return metrics for each risk minimization portfolio allocation strategy:
Average return
Volatility
Loss standard deviation
Active positions
Turnover
Value at risk The historical Value at Risk (VaR 5%) is based on historical returns over the entire sample and is defined as the maximum loss an investor can occur in a certain time period. It is defined as the \(\alpha \) quantile of the return distribution. Formally given as:
Expected shortfall Closely related to the VaR is the Expected Shortfall (ES). The historical ES at 5% calculates the average losses given the portfolio loses which are more than the historical VaR at 5%.
Maximum drawdown The maximum drawdown (MDD) is the maximum loss from peak to through that an investor incurs computed over the entire sample period. Formally it is defined as:
where P is the peak value before the largest drop and L is the lowest value before the new high has been established.
Maximum drawdown period and recovery period While the MDD Period indicates the years over which the investor incurred losses between the peak and valley of the maximum drawdown, the Recovery Period after MDD, represents the years it takes the investor to bring the portfolio value back above the peak of the maximum drawdown.
Certainty equivalent The certainty equivalent (CEQ) is defined as the risk-free-rate that makes a risk averse investor indifferent to a risky gamble. We compute the CEQ as:
for which we follow DeMiguel et al. (2009a) and set \(\gamma \), the risk aversion parameter, to 5.
Effective number of constituents (ENC) The ENC is a simplistic indicator of the nominal holdings of the portfolio. More formally, it is defined as the exponential of the entropy, given the distribution of the portfolio weight vector. Given the T different portfolio observations, we compute the average ENC as:
The ENC has a minimum value of one when the portfolio is fully concentrated in one constituent, and a maximum value of N, when the portfolio is equally weighted and in which N represents the size of the investment universe. Although intuitively appealing, it disregards the volatility and correlation structure of the chosen universe. As a result, an ENC that is close to N indicates a diversified portfolio, which, however, can be very concentrated in terms of risk. Deguest et al. (2013)
Effective number of correlated bets (ENCB) The ENCB builds on the limitations of the ENC and incorporates information on the volatility and correlation structure of the constituents. The ENCB is lower, given a high volatility asset, which also has a high positive correlation with other constituents. Formally, it is represented by the entropy of the distribution of the correlated constituents’ contribution to the total variance. To compute the ENCB, recapture that the variance of the portfolio is given as:
where \(|X|_{i}\) denotes the \(i^{th}\) element of matrix X. Now, the contribution of each constituent to the overall variance can be expressed as:
The ENCB is now defined as the entropy of the distribution of the effective number of correlated factors contribution to the total variance:
The ENCB has a minimum value of one when the risk of the portfolio is fully concentrated in one asset and a maximum value of N, when the risk is evenly spread among the assets. Roncalli (2013)
Effective number of uncorrelated bets (ENUB) Closely related to the ENCB is the ENUB, which is obtained by looking at the uncorrelated factors using the Minimum Linear Torsion methodology. In detail, Meucci et al. (2014) propose to define the portfolio return not as the weighted average of its constituents, but rather as the combination of uncorrelated factors, obtained through the Minimum Linear Torsion methodology. The ENUB is then defined as the exponential of the entropy of the distribution of the uncorrelated minimum torsion factors’ that contribute to the total variance. Formally, after having obtained the \(N \times N\) torsion factor matrix \(\varvec{H}\), the contribution from the truly separate sources of risk is given as:
where \(\circ \) is the term by term product. The ENUB is the entropy-based measure given as:
Like the ENCB, the ENUB has a minimum value of 1 when the risk of the portfolio is fully concentrated in one asset and a maximum value of N, when the risk is evenly spread amongst the assets.
Diversification ratio The Diversification Ratio (DR) was introduced by Choueifaty et al. (2011), and measures the ratio of the weighted variance of the portfolio constituents to the overall portfolio’s variance. It is thus a natural indicator for the diversification exploited by investing in the individual constituents. We report the average DR across all rebalancing periods as:
The DR is greater than one for portfolios composed of assets that are not perfectly correlated, as the relatively high volatility of component assets results in overall lower portfolio volatility through the risk reduction effect of correlations.
Appendix 4: Market conditions
Bull/bear markets Stock market returns are ranked in descending order. Bear market comprises the months with market returns below the median monthly return, computed considering the whole period, and Bull market comprises the rest. To represent the market returns, the following equity indices were used: S&P 500 for the US universe, FTSE 100 for the UK universe, Nikkei 225 for the Japanese universe, MSCI AC Asia ex-Japan for Asia ex-Japan universe, and STOXX Europe 600 for the European universe.
Low/high volatility market High and low volatility conditions are differentiated by using the one month realized volatility of the equity indices in each region (S&P 500, FTSE 100, Nikkei 225, MSCI AC Asia ex-Japan, and STOXX Europe 600). The monthly volatility is ranked in descending order. Low Volatility market comprises the months with realized volatility below the median monthly volatility and High Volatility market comprises the rest.
High/low interest rate regime High and low interest rate conditions are differentiated by using the changes in term spread. The term spread is the difference between the yields of the 10-year and 2-year government bonds in each region (for Developed Europe ex-UK and Asia ex-Japan, the German Bonds and Chinese Government Bonds, respectively were used as proxies; for US, UK and Japan, the bonds issued by the national governments were used). A positive change in the term spread means high interest rates and a negative change means low interest rates. High interest rate market conditions are associated with an expansion period as the monetary policy rate is usually set high in order to prevent the overheating of the economy. Conversely, low interest rate market conditions are associated with a recession period as the monetary policy rate is usually set low in order to encourage consumption and investment.
Low/high credit risk Low and high credit risk conditions are differentiated using the iTraxx indexes, which track the Credit Default Swap (CDS) spread on the largest investment-grade companies from each region. A widening (narrowing) of the CDS spread is associated with deteriorating (improving) credit conditions. Consequently, a positive change in the CDS spread means high credit risk and a negative change in the credit spread means low credit risk.
Positive/negative economic surprises Positive and negative economic surprises periods are differentiated by using the Citi Economic Surprise Index for each region. This indicator measures data surprises relative to market expectations. A positive reading means that data releases have been stronger than expected and a negative reading means that data releases have been worse than expected.
Positive/negative economic conditions Positive and negative economic conditions are differentiated by using the Merrill Lynch Economic Conditions Index, calculated for each region. The index is a composite coincident indicator of real economic activity in the respective area. For Asia ex-Japan, the index is calculated as a GDP-weighted average of the individual countries’ Purchasing Manager Index (PMI) for China, India, Korea, Taiwan, Hong-Kong and Singapore. For the rest of the regions, the methodology used, mirrors the one currently employed by the Philadelphia Fed to track US real business conditions. Its underlying economic indicators (i.e., weekly jobless claims, monthly payroll employment, industrial production, personal income less transfer payments, manufacturing and trade sales, quarterly Gross Domestic Product) blends high and low frequency information and stock and flow data, allowing continuous assessment of the state of the economy. A positive Economic Conditions index value means better than average economic conditions and a negative Economic Conditions index value means worse than average economic conditions.
Rights and permissions
About this article

Cite this article
Kremer, P.J., Talmaciu, A. & Paterlini, S. Risk minimization in multi-factor portfolios: What is the best strategy?. Ann Oper Res 266, 255–291 (2018). https://doi.org/10.1007/s10479-017-2467-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-017-2467-6