
Abstract
Over the last decade, the use of robots in production and daily life has increased. With increasingly complex tasks and interaction in different environments including humans, robots are required a higher level of autonomy for efficient deliberation. Task planning is a key element of deliberation. It combines elementary operations into a structured plan to satisfy a prescribed goal, given specifications on the robot and the environment. In this manuscript, we present a survey on recent advances in the application of logic programming to the problem of task planning. Logic programming offers several advantages compared to other approaches, including greater expressivity and interpretability which may aid in the development of safe and reliable robots. We analyze different planners and their suitability for specific robotic applications, based on expressivity in domain representation, computational efficiency and software implementation. In this way, we support the robotic designer in choosing the best tool for his application.
Similar content being viewed by others


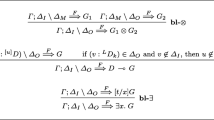
Avoid common mistakes on your manuscript.
1 Introduction
Robots are increasingly being used in industries, including smart industries for improving the efficiency of production environments and co-operation with the human workers (Bogue 2011, 2018), services for the elderly and domestic assistance (Mandel et al. 2005; Harmo et al. 2005), and recently for autonomous driving (Levinson et al. 2011; Campbell et al. 2010). One of the most challenging requirements for robots in such complex scenarios is autonomy, that is the ability to fulfill a mission without external supervision. In various operating scenarios, an autonomous robot is challenged by the external state of the system, i.e., the state which is not controlled by the robot, for example unpredictability of the environment. The environment where the robot is operating is often uncertain and continuously changing, except in controlled settings as industry. Moreover, the mission may consist of one or more sub-missions named tasks, which can be defined at run-time according to the changing situation. For instance, consider a robot operating in a domestic environment. The mission could be to search for objects located in different rooms, and move them all to a target room. This requires the completion of tasks as moving to each room, searching for one object, bringing the object to the target room, etc. However, if an object is heavy, the mission may require the additional task of asking for human help to carry it to destination. Furthermore, available prior knowledge about the environment to be explored may be exploited by the robot, e.g., usual locations of objects or connections between rooms.
As a consequence, autonomy requires deliberation, which is defined as the ability to make decisions which are motivated by reasoning on the available resources, i.e., the capabilities of the robot, the actual description of the environment and the given mission (Ingrand and Ghallab 2017).
1.1 Requirements for deliberative robotic systems
In the last 20 years, the requirements of a deliberative robotic system have been investigated (Ghallab et al. 2016; Ingrand and Ghallab 2017; Rajan et al. 2013; Matarić 2006). Though different interpretations and characterizations of deliberation have been proposed in the field of Artificial Intelligence (AI) (Bratman 1987, 1988; Bolisani and Bratianu 2017), in this paper we refer to the functional model proposed by Ingrand and Ghallab (2017), which identifies the main modules for deliberation, namely planning, acting, monitoring, observing, goal reasoning and learning (Fig. 1). Planning is defined as the ability to devise a strategy to fulfill a mission, as the combination of strategies to fulfill individual tasks. From now on, we will refer to the strategy for a single task as the plan, while keeping the generic nomenclature strategy for the full mission. The planning module considers the resources of the robot, tasks and information from the sensors, provided by the observing module, to generate a plan. Since the planning module combines robot and environmental information, and aids in the determination of the robot’s behaviour in the environment, it is a key requirement for deliberative robots. Depending on the complexity of the individual tasks, the plan can be either a motion trajectory to be directly executed by the acting module (motion planning), or a higher-level sequence of elementary operations to be translated into motion trajectories (task planning). Reasoning on the order of execution of tasks in the mission is performed through goal reasoning. Moreover, in complex scenarios where interaction with the environment and/or with humans or other robots is involved, a monitoring module is needed to supervise the planning-acting-observing loop and guarantee the overall correctness of the execution, triggering re-planning if necessary. Finally, the learning capability is required when the available information is not enough to devise a strategy for the mission. This is particularly useful, e.g., in robotics for exploration, where the environment is unknown or only partially known and information about it must be retrieved during execution. In this manuscript, we focus on the task planning aspect of the deliberation process for robots.

The functions of a deliberative robot. In this manuscript, we focus on logic-based implementations of the task planning function of a deliberative robot
1.2 Task planning for deliberation
We now define in more detail the task planning problem considered in this paper. Inspired by the definitions by Ghallab et al. (2016), we consider a robotic system as a set of robots with a common task, which can be achieved through a set of actions, i.e., elementary operations which can be performed by the robots in the environment. Actions depend on task resources. Resources are relevant entities of the scenario, specifically robotic agents and elements of the environment (e.g., instruments which can be used in the task, or obstacles). The environment is defined through relevant state variables related to specific features (e.g., position of objects and spatio-temporal relations between them). The task planning problem is then defined by the goal, the resources and user-prescribed specifications. Specifications include preconditions of actions, i.e., the set of conditions which must be verified before executing the actions; postconditions or effects of actions, i.e., conditions which hold after actions are executed; execution constraints, i.e., sets of conditions which cannot hold at the same time. Conditions involved in the specifications may be conditions on actions (e.g., an action must occur after another one) or on environmental state variables (e.g., an action can be performed only if the environment is in a specific state). The output of the task planner is a plan, i.e., an ordered sequence of actions to be executed to accomplish the goal of the task, satisfying the task specifications.
1.3 Scope and structure of the paper
While motion planning techniques have always been of interest in the robotic community from its very beginning, hence have been exhaustively surveyed for a variety of applications (Raja and Pugazhenthi 2012; Kamil et al. 2015; González et al. 2015), a detailed and practical review on task planning for robotics is still missing. This is mainly because task planning is an even wider problem, concerning with the coordination of actions in the long-term behavior of agents as they interact with the environment. This has always been of interest in the AI community (Ghallab et al. 2004, 2016), while the robotic community started focusing on it relatively recently, when robotic applications in more complex human scenarios have surged. The task planning problem can be represented and solved with a multitude of formalisms and frameworks depending on the specific application. An overview of possible approaches is provided by several authors, e.g., by Ghallab et al. (2004, 2016) mainly in the context of planning for AI and with only some insights in generic task-motion planning for robotic applications; Jiménez et al. (2012) for learning-based planning; and Karpas and Magazzeni (2020), Nakawala et al. (2018), who considered generic action representation formalisms for robotics. The purpose of our paper is to provide a comprehensive review on the state-of-the-art solutions for representing and solving the task planning problem for deliberative robots, with a focus on logic programming tools. We want to go beyond the presentation of high-level action models and formalisms, analyzing instead how these can be implemented, evaluating advantages and drawbacks of key software implementations and categorizing different planners depending on their specific field of application. The popularity of logic programming (Lloyd 2012) has significantly increased in recent years in the robotic community, since robots are being more and more involved in human environments [as testified by recent surveys on human-robot collaboration, e.g., by Goodrich and Schultz (2008), Chandrasekaran and Conrad (2015), and particularly safe human-robot interaction, e.g., by Zacharaki et al. (2020), Lasota et al. (2017)]. In fact, differently from, e.g., learning-based methods (Goebel et al. 2018), a logic formalism allows to define the task planning problem in such a way that the autonomous behavior is interpretable by a human supervisor, i.e., the input (typically, the environmental and intrinsic robot context, e.g., its configuration) and output (plan) to the robotic system can be easily supervised by an operator. This guarantees the reliability of the robot when it operates with other humans, e.g., in an industrial environment with other workers (Zhang et al. 2017), or when the robot is assisting elderly or disabled people in a domestic environment (Alami et al. 2005). Moreover, interpretable planning is a requirement of the latest proposal for European regulation on high-risk AI systemsFootnote 1, and attention to explainable planning is rapidly emerging in AI and robotic research (see the work by Fox et al. (2017) for a deeper insight on the topic). Focusing only on logic programming solutions for task planning allows to provide enough details for a roboticist willing to use this tool for his/her task planning problem, which would be otherwise infeasible considering the full span of related methodologies as in, e.g., Ghallab et al. (2016).
In Section 2, based on recent reviews, we present possible taxonomies of task planners. We then introduce a specific class of task planners based on logic programming for robotics, which offer high expressiveness in the description of the planning problem. Sect. 3 then specifies how the review process has been conducted, motivating the following organization of this document. Section 4 shows how to describe the task planning problem using an action language, which constitutes the formal foundation to implement planners based on logic programming. An overview of main results of this review is then presented in Sect. 5, with details provided in Sects. 6–8. Finally, Sect. 9 concludes the paper.
2 Taxonomy of task planners
The task planning problem can be described with a large number of formalisms, extensively presented in the field of AI, e.g., by Ghallab et al. (2016), Geffner and Bonet (2013). Different taxonomies of task planners have been proposed. Ghallab et al. (2016) distinguish domain-dependent and domain-independent task planning. Domain-independent planning (Wilkins 1984) is interesting to the robotic community because it is expected to solve the task planning problem in different environments or operational scenarios, starting from a very high-level generic description of the domain. For instance, in a complex robotic task involving transport of objects, the domain-independent planner is useful to define a general plan to reach the objective for all objects. However, manipulation of single objects depends on their specific properties and is thus more efficiently managed by a domain-dependent planner (Dornhege et al. 2009). For this reason, Ghallab et al. (2016) propose configurable task planning to combine high-level domain-independent task planning with domain-dependent sub-task planning. An explanatory example of this approach can be found in Shivashankar et al. (2013), where the full mission is split into a sequence of simpler tasks. While the global strategy is planned through domain-independent hierarchical task planning, a specific domain-dependent planner is in charge of the single tasks. The method is validated successfully on benchmark planning problems, including the famous block-world example. In general, domain-dependent planning has the potential to find more robotic applications, since it bridges the gap between formalization of the problem and practical implementation.
However, this categorization of task planners is too coarse, since it is mainly independent of the specific characteristics of the use scenario. An alternative classification is proposed by Ingrand and Ghallab (2017), distinguishing between deterministic and non-deterministic task planners. Non-deterministic (or probabilistic) task planners are usually based on Markov decision processes and Bayesian models. They capture the stochastic nature of the environment, uncertainty with the sensors and output the most probable plan (Kolobov 2012; Teichteil-Königsbuch et al. 2010; Likhachev et al. 2005). Probabilistic planners offer easier integration with the acting and observing modules of deliberation. However, they are data-driven, hence they do not generally provide enough support to the definition of complex task constraints, e.g., temporal and semantic relations between objects and robots.
On the contrary, deterministic planners rely on a more formal description of the scenario, in terms of resources and specifications. Any implementation starts from a high-level action language (Erdem and Patoglu 2012), which represents entities of the domain and relations between them with different expressive power. A state-of-the-art example in the field of robotics are the Planning Domain Description Language (PDDL) by Aeronautiques et al. (1998) and its extensions (Fox and Long 2003; Younes and Littman 2004).
The planning representation can then be translated to an implementative form, as proposed, e.g., by Armando et al. (1999), Vidal and Ghallab (1996), Vidal and Fargier (1997), Frank and Jónsson (2003), Fratini et al. (2011) for temporal constraint networks with time intervals. Even higher expressiveness is guaranteed by planners based on logic formalisms, representing expert knowledge about the declarative task in terms of logic statements. One key advantage of logic formalisms is the interpretability of the generated plan when evaluated by a (possibly non technical) human supervisor. This guarantees the reliability of the robot when it operates with humans. Some logic-based planners support the open-world assumption (the truth value of a statement may be stated irrespective of whether or not it is known to be true). Under the open-world assumption, description of the robotic domain can be stored in an ontology (Poli et al. 2010), i.e., a high-level knowledge base. A description logic (see Baader et al. (2003b) for an overview of related formalisms) then provides operators [e.g., first-order-logic operators, Smullyan (1995)], allowing to reason on abstract concepts and relations encoded in the knowledge base and to instantiate them in the real world through logical inference. This is particularly useful for complex scenarios with a high numbers of resources, as autonomous surgery (Nagy et al. 2018; Gibaud et al. 2018; Ginesi et al. 2019), human-robot interaction (Lemaignan et al. 2010; Bruno et al. 2017) and complex industrial (Diab et al. 2019) and domestic (Tenorth and Beetz 2013) scenarios. Description logic offers high expressivity, allowing to reason on sub-classes, properties and more complex relations between entities of the knowledge base. However, as evidenced by Vitucci and Gini (2019); Nakawala et al. (2019), the improved expressivity also increases the computational burden, which is a major drawback in robotic applications with real-time demands. A more computationally tractable approach is logic programming (Lloyd 2012), which provides slightly reduced expressivity with respect to description logic, e.g., no quantifiers \(\forall , \exists\) nor hierarchical class relations and properties. However, as we will show in the following of this paper, this still allows the application in realistic robotic domains. Moreover, in Sect. 5 (and sequent) we will highlight some logic programming frameworks that can be integrated with ontologies for open-world reasoning.
The categorization in deterministic and probabilistic task planners is still inadequate for a formal characterization. One drawback is that a clear decision between deterministic and probabilistic representation cannot sometimes be taken. In fact, there exist extensions of natively deterministic frameworks which support probabilistic formalism (Younes and Littman 2004; Vidal 1999). Moreover, as reported by, e.g., Ghallab et al. (2004), Karpas and Magazzeni (2020), planning scenarios can be better grouped into three main categories, depending on the expressivity of specifications. In this sense, it is possible to distinguish between classical planners, assuming the robot interacts via instantaneous actions with a deterministic environment; temporal planners which operate on complex temporal specifications; and probabilistic planners which relax the deterministic assumption. In this paper, we make use of this categorization for logic programming frameworks for robotic task planning. Though the distinction is not always clear (see Table 1), we think that the expressivity of the logic formalism is a good choice for taxonomy, since it encompasses, e.g., the distinction between deterministic and probabilistic planning.
3 Review methodology

Categorization of logic programming frameworks and relative robotic application papers (total 114). Three papers are related to probabilistic CTL, hence they are included both in the temporal and probabilistic logic category
Logic programming frameworks and relative applications appearing in this review have been selected according to a systematic search methodology. In particular, we have searched Google Scholar and Scopus engines for keywords extracted from relevant books and reviews (Ghallab et al. 2004, 2016; Ingrand and Ghallab 2017; Matarić 2006; Baader et al. 2003a; Karpas and Magazzeni 2020), such as logic programming, task planning and robot (evaluated both separately and in conjunction). Then, we have selected only frameworks and related papers with applications on real robotic systems, thus excluding, for instance, popular action representation formalisms as STRIPS (Fikes and Nilsson 1971) and simplified action structure (Bäckström and Klein 1991)—though their use in robotics is not discouraged, e.g., by Karpas and Magazzeni (2020). Finally, we have decided to include only frameworks which have found concrete robotic applications in the last 20 years, in order to provide the reader with a state-of-the-art guide. In this way, frameworks with long history (e.g., Prolog by Van Emden and Kowalski (1976) and temporal logic programming) are still present, but their oldest robotic applications (Kadonoff 1987; Tzafestas and Plouzennec 1989) are discarded.
As explained in Sect. 2, we have organized the paper distinguishing between classical, temporal and probabilistic planning. In the context of logic programming frameworks, this results in a categorization of the underlying logic formalism, either standard Boolean logic (classical logic operators), temporal logic or probabilistic logic. According to this taxonomy, Table 1 shows the classification of relevant logic programming frameworks (i.e., \(\ge 2\) robotic use cases), while Fig. 2 represents the distribution of different frameworks and relative applications in the robotic domain.
In the next section, we present the basic notions for logic programming implementation, starting from an action language description of the robotic task domain.
4 Representing the task planning problem with logic programming
Starting from a task description in human language, it is useful to represent it in an action language, in order to formally define task entities and specifications. An action language provides the foundation for the implementation of the task planning problem in any specific logic program. This section shows the example formalization of the representative peg transfer task from the Fundamentals of Laparoscopic Surgery (Soper and Fried 2008) in the state-of-the-art action language of Planning Domain Description Language (PDDL) by Kovacs (2011), and its translation to the syntax of a logic program.
4.1 The peg transfer task

The setup for the peg transfer task with da Vinci surgical robot. The red dashed line defines the reachability regions for the PSMs
The peg transfer (Fig. 3) is a surgical training task for novice surgeons, executed on a surgical robotic systems, e.g., while learning manipulation with the state-of-the-art da Vinci surgical robotic platform (Intuitive Surgical Inc., Sunnyvale, CA, USA) (DiMaio et al. 2011). The setup consists of two Patient-Side Manipulators (PSMs) and an Endoscopic Camera Manipulator (ECM) with a RGBD sensor mounted on it. The PSMs, equipped with surgical tools, operate on a peg base with (up to four) colored rings, whose goal is to place them on the same-colored pegs. Several constraints influence the workflow of execution. In particular, reachability regions for the two robotic arms are defined, in order to prevent collisions. Depending on the reachability of rings and pegs, one single arm can pick and place a ring (e.g., PSM1 with the red ring in Fig. 3), or transfer from one PSM to the other may be needed (e.g., the blue ring in Fig. 3). Rings may be initially placed on pegs, thus extraction may be needed before moving them to the peg or transfer point. Furthermore, colored pegs may be occupied by rings with unmatched color, hence grey pegs may be used as temporary placement for rings before task completion.
The peg transfer is chosen as a paradigmatic robotic scenario in this paper for three reasons. First, it is an instance of a pick-and-place task, so it represents a well-known use case both in the robotic and AI community. Second, the specifications of the task introduce several variations on the workflow of execution. As a consequence, enumerating sequences of actions for all possible setup configurations would not be feasible, and reasoning directly on task knowledge is a more convenient solution for planning. Third, the peg transfer is currently the benchmark in the field of Autonomous Robotic Surgery (ARS) (Nagy and Haidegger 2021). ARS rises safety and interpretability issues (Fiazza and Fiorini 2021) that make this task an adequate use case for the logic programming paradigms presented in this manuscript.
4.2 From PDDL to logic programming formalization
Following the definitions proposed in Sect. 1.2, the peg transfer task knowledge includes:
-
goal definition, i.e., the rings must be placed on the same-colored pegs;
-
resources, i.e., rings, pegs (with the color property) and the robotic arms with possible actions. In this paper, we consider four main actions, i.e., moving to a ring or a peg, transferring and extractingFootnote 2;
-
environmental variables describing the relative positions between the resources (e.g., to evaluate reachability or peg occupancy);
-
specifications as reported in the previous section.
PDDLFootnote 3 allows to represent this knowledge in a formalism which specifies a domain definition and a problem instance. The domain definition contains declaration of types, i.e., classes of objects in the resources (e.g., objects of type Ring or Peg); declaration of names and argument types of predicates representing specific features of the domain (e.g., on(Ring, Color, Peg, Color) for relative positions of rings with respect to pegs); actions with their parameters, preconditions and effects. The domain definition for peg transfer is as follows:
Given the domain definition, a problem instance specifies the goal of the task; the initial state init, i.e., initial values for predicates; objects, i.e., instances of types (e.g., actual rings and pegs with specific colors). One possible problem instance for peg transfer is as follows:
Starting from this high-level representation, a logic programming language encodes the task knowledge using a sorted signature \({\mathscr {D}}\), with symbols (terms) which can be arranged hierarchically to form atoms, i.e., predicates of terms representing attributes of the domain. Terms may be variables or constants. A term which is constant is ground, and atoms are ground when terms in them are all ground. Atoms are either fluents or statics, depending on whether they depend on time or not, respectively.Footnote 4
In order to clarify these concepts, consider the peg transfer task description in PDDL. Ring, Peg, Color and Arm are static variables, with possible constant values defined by objects in problem instance. From now on, we will use the short notation R, P, C, A when referring to types as unassigned variables, respectively. Fluents are environmental features (PDDL predicates) with their parameters, i.e., reachable(A, P/R, C), on(R, C1, P, C2), holding(A, R, C), and actions move(A, R/P, C), extract(A, R, C), transfer(A, R, C).
Logic programming languages also introduce operators which allow to write the specifications. Different operators are allowed, e.g., temporal (e.g., until and release operators) or Boolean (e.g., logic implication and conjunction), depending on the underlying logic formalism. This will be clarified in the next sections. For instance, consider move(A, P, C) in the PDDL description for peg transfer. Preconditions and effects can be represented as implications between atoms:
where the left-hand side is usually referred to as head, while the right-hand side as body of the specification. Similarly, it is possible to define constraints in the form \(\bot \leftarrow\) atoms, being \(\bot\) the logic falsum. For instance, the precondition for move(A, P, C) can be also expressed as:
Given a logic program, a language-specific solver computes the plan as the set of ground actions, starting from initial grounding of environmental variables from available evidence. Grounding translates the program to a set of propositional logic formulas, where grounded atoms become Boolean variables. Then, logic deduction is exploited to propagate grounded atoms through specifications, until a plan is found. For example, consider the above PDDL problem instance. Initial conditions satisfy preconditions for move(psm1, ring, blue). This leads to the grounding of corresponding effect holding(psm1, ring, blue). Then, precondition for transfer(psm1, ring, blue) holds, whose effect leads to grounding of holding(psm2, ring, blue) and, finally, last action move(psm2, peg, blue) to complete the problem instance.
Before detailing how representation and solving specialize for different logic programming frameworks, we give an overview of main results of this review, in order to guide the interested reader to a deeper insight only in the relevant sections for his/her specific needs.
5 Overview of logic programming frameworks for robotic task planning
A summary of the results of the analysis of the state of the art in logic programming for robotic task planning is presented in Table 2. The choice of the appropriate logic programming framework for task planning depends on several criteria, which will be further highlighted in the end of Sects. 6–8.
5.1 Expressivity of logic formalism
The expressivity of the underlying logic formalism must be considered. Our review has identified several applications of logic programming for robotic task planning, including domestic/service scenarios, navigation, industry, search & rescue, human-robot interaction, multi-robot coordination, surveillance and manipulation tasks. Most of these applications are covered by standard logical planners, which allow to specify conditional laws, constraints and optimization statements for optimal plan generation. The state-of-the-art Prolog-based planner, SWI-Prolog (Wielemaker et al. 2012) (\(>250\) citations on Scopus), can cope with different data types, including real variables, supporting the designer in the definition of proper specifications for real robots dealing with continuous data from sensors. Planners based on the answer set semantics are still limited in this sense, though the main representative Clingo by Gebser et al. (2019) (\(>50\) citations on Scopus) allows to define arithmetic constraints. Moreover, Clingo supports multiple plan computation and preference reasoning for optimal planning.
Temporal planners shall be preferred when complex temporal relations between robotic agents and the environment are required to properly describe the scenario. This is the case, for instance, of tasks requiring long human-robot interaction, or (multi-robot) exploration of large complex environments. Moreover, temporal logic can easily express conditions from system theory, as invariance and reachability of sets (e.g., for definition of system stability). This makes planners based on temporal logic advantageous for applications with a tight integration of task and motion planning, e.g., multi-robot exploration. To this aim, TuLiP toolbox (Wongpiromsarn et al. 2010) (\(>100\) citations on Scopus) is the state-of-the-art solution. However, it is fair to remark that some temporal concepts can be expressed with standard logical planners, e.g., using event calculus in answer set semantics as in Son et al. (2006), Meli et al. (2021a), at the expense of increased size of represented knowledge (e.g., additional temporal variables or specifications). Moreover, temporal extensions of answer set programming have been recently introduced, e.g., telingo (Cabalar et al. 2019a), though not applied to robotic use cases yet. Hence, the choice of the logic formalism should be tailored on the peculiarities of the applicative domain and the most relevant and frequent concepts (e.g., either temporal or causal) to be represented.
Probabilistic planners are useful in tasks involving continuous interaction with the environment, requiring reasoning on uncertain sensor information to refine the knowledge of the scenario. This may be the case, for instance, of manipulation and navigation tasks. Main implementations are Problog (De Raedt et al. 2007) (\(>450\) citations on Scopus), which allows to reason on discrete probability distributions with a syntax similar to Prolog, and Distributional Clauses (DC) by Gutmann et al. (2011) (\(\approx 50\) citations on Scopus), representing continuous probability distributions.
5.2 Computational efficiency
An important requirement is the computational efficiency of plan generation. This is related to the expressivity of the underlying logic formalism. In fact, in general the problem of deciding whether a problem is solvable is PSPACE complete in the case of classical planning (Bylander 1994), and becomes EXPSPACE complete when considering temporal planning (Rintanen 2007), or even undecidable when considering continuous variables, e.g., in probabilistic planning (Helmert 2002). As a consequence, it is important to carefully choose the most suitable logic programming framework for the specific robotic application, identifying the best tradeoff between expressivity and efficiency. In general, standard logic programming frameworks should be preferred, also because they implement most efficient algorithms for solving, and allow to represent complex task planning domains with realistic number of robotic agents, actions and environmental features. In particular, planners based on the answer set semantics offer some advantages with respect to Prolog-based, e.g., they do not require prior stratification of the task knowledge and the ordering of statements and atoms in them is not relevant.
On the contrary, temporal and probabilistic logic programming framework should be considered only when the complexity (number of resources and specifications) of the scenario is limited. In fact, the solving efficiency of these programs does not scale well with the problem dimension, due to state explosion problems, unless the specific use case justifies strict assumptions, e.g., on the limited time horizon for the plan or neglectible specifications. When advanced expressivity is required, currently the best solution is to rely on frameworks which combine standard logic programming framework with specific tools, e.g., answer set semantics in conjunction with Markov decision processes (Sridharan et al. 2019) or telingo (Cabalar et al. 2019a) to represent temporal operators in Clingo.
5.3 Software implementation
Software implementation and programming language support are important factors to choose a logic programming framework, in order to build robotic architectures integrating multiple deliberative functions. Standard logic programming is well established in the robotic community, hence it offers integration with the standard Robot Operating System (ROS) (Koubâa 2017) for robotic research. ROSPlan (Cashmore et al. 2015) (\(>150\) citations on Scopus) is a particularly versatile framework, since it does not require any specific logic formalism for task specifications, but generic PDDL interpretations. Clingo and Prolog also offer APIs for integration in ROS-compliant languages.
The only temporal planner logic programming framework offering direct integration with ROS is LTLMoP (Finucane et al. 2010) (\(>100\) citations on Scopus), while ProbCog (Jain et al. 2009) (\(\approx 25\) citations on Scopus) was born as a probabilistic extension to the CRAM project (Beetz et al. 2010b), hence it offers built-in ROS interface. However, relevant frameworks as TuLiP and Problog support Python and Java, hence they can be easily integrated in the ROS framework.
5.4 Support for open world planning
Support for open-world planning is an interesting feature for complex robotic applications, e.g., exploration of large environments with many resources, where external knowledge bases may be queried in order to provide useful information about the domain. In general, Prolog-based tools offer the best performance in these scenarios, since they natively support query-based reasoning. SWI-Prolog is part of the well established CRAM project for open-world planning, but also novel DLVHEX (Eiter et al. 2018) for the answer set semantics offers easy integration with external knowledge bases, though applications to robotics are not known at the writing of this survey. Among probabilistic planners, ProbCog is the natural statistical extension to the CRAM project.
5.5 Plan revision opportunity
Finally, plan revision is a key ability for online robotic task planners, since it allows to cope with dynamic conditions which occur in many robotic scenarios. Planners based on Prolog and the answer set semantics rely on the formalism of non-monotonic logic, hence they inherently support online plan adaptation.
Also several probabilistic planners allow plan revision, since they are usually stochastic extensions of Prolog-based planners. Most temporal planners do not offer this feature, because they are based on monotonic versions of LTL. This is partly due to the different scope of temporal planners, which are intended to generate correct-by-constructions plans.
6 Standard logic programming
The terminology standard logic refers to logic programming frameworks based on classical Boolean logic, where specifications are expressed using operators as negation, conjunction, disjunction and implication. In order to represent the temporal sequence of actions and fluents, an explicit time variable t must be defined. Hence, with reference to the peg transfer domain, fluents have an additional argument t (e.g., on(R, C1, P, C2, t)). Given this formalism, it is important to introduce an explicit temporal delay between actions and their effects, e.g., for move(A, P, C, t) in the peg transfer task:
In this way, a temporal sequence of actions can be generated.
Logic programming frameworks in this class can be grouped in two main categories, either based on Prolog (Sect. 6.1) or answer set semantics (Sect. 6.2), which differ mainly in the solving strategy. Other application-specific implementations are mentioned in Sect. 6.3.
6.1 Prolog-based planners
One of the first examples of standard logic programming languages for planning is Prolog, introduced in Van Emden and Kowalski (1976). Specifically, Prolog is a language for non-monotonic logic programming, i.e., the underlying logic is non-monotonic (McDermott and Doyle 1980). To understand non-monotonicity, consider a generic task knowledge K expressed as a set of goal, resources and specifications, and a Boolean assertion A entailed by K, i.e., \(K \models A\). The knowledge is said to be monotonic if the addition of new knowledge S (e.g., further specifications or new evidence) does not affect the truth of the entailment, i.e., \(K \cup S \models A\). Otherwise, the knowledge is said to be non-monotonic. Non-monotonicity of knowledge has allowed to solve the famous qualification problem in AI, moving from the concept of circumscription of human reasoning (McCarthy 1980), and it has led to the development of several logic frameworks for decision making of expert systems, e.g., deductive databases (Eiter et al. 1997), abduction theory (Alferes et al. 2000) and stable model semantics (Dimopoulos et al. 1997). In robotic tasks, planning under non-monotonicity assumption is crucial, since the environment is usually not completely known or dynamic. Considering the peg transfer task, in order to emulate the anatomical variability in the surgical context, rings may be moved in the scene (e.g., by a human) during task execution, thus altering the reachability conditions. As a consequence, the solver must continuously update the plan and prescribe, e.g., transfer between arms instead of direct placement on peg.
The syntax of Prolog extends standard logic formalism with negation as failure (NAF). To show the difference between NAF and classical logic negation, consider a generic Boolean variable p. In order to state \(\lnot p\) in classic logic, it is necessary to prove that the negation of p holds; on the contrary, to prove not(p) (NAF syntax in Prolog) it is only required that p does not hold. The function of NAF in Prolog is two-fold. First, it introduces the closed-world assumption, since it is treated in the solving process as a classical negation (in other words, unknown facts are assumed to be false). Second, NAF supports the non-monotonic paradigm, since it is possible to specify that an atom does not hold, and then revise it as new evidence is acquired. For instance, the goal for the peg transfer task can be expressed as the constraint:
where :- represents \(\leftarrow\) in standard Boolean logic (in this specific case, it equals to \(\bot \leftarrow\), since \(\bot\) is omitted in standard Prolog syntax). This specification is not satisfied until on(R, C, P, C, t) is not grounded for any reachable ring (i.e., until all rings in the scene are not placed on the same-colored pegs). on(R, C, P, C, t) can be grounded either from external sensor information, or from specifications (e.g., effect of move(A, P, C, t) action).
Starting from Prolog III in Colmerauer (1990) and up to the latest version Prolog IV in Narboni (1999), Prolog has further extended the standard logic syntax with structures like lists and trees to represent a richer hierarchy between atoms, and is able to manage constraints on real variables which are useful for robotic applications involving continuous environmental and kinematic variables (e.g., 3D positions of rings and pegs for peg transfer task).
These features have increased the appeal of Prolog in many challenging robotic scenarios. Relevant are the many Prolog-based implementations of the Golog action language (Levesque et al. 1997), such as in Janssen et al. (2016) for multi-robot hierarchical task planning in the context of RoboEarth project (Waibel et al. 2011; Kirsch et al. 2020), where a useful integration of the Golog dialect Readylog with ROS is proposed through C++ bindings [Golog++ by Mataré et al. (2018)], with an application to the Pepper service robot; Gierse et al. (2016), where INTRGOLOG is presented to implement task interruption and resumption in reaction to anomalous events; Schiffer et al. (2012), where Readylog is used for task planning in domestic scenario with Caesar robot; Farinelli et al. (2007), where TEAMGOLOG is used for multi-robot coordination in a search-and-rescue application under partial observability. Among main implementations of Prolog, also SWI-Prolog (Wielemaker et al. 2012) shall be mentioned, which implements constructs for optimal query answering and plan generation under the paradigm of preference reasoning (Brewka et al. 2008) and has been used, e.g., in the Tartarus framework for the integration and coordination of multiple robots in cyber-physical systems (Semwal et al. 2015; Muñoz-Hernandez and Wiguna 2007), where Fuzzy Prolog is used to deal with missing information in real-time robotic soccer; Javia and Cimiano (2017), where multi-robot coordination for domestic activities is implemented in Prolog; Xu et al. (2014), where an efficient software integration between qualitative Prolog calculus and quantitative C++ processing is implemented for robotic assistance to elderly and disabled people; Pineda et al. (2013), which proposes SitLog, a Prolog-based planner for service robotic tasks in domestic scenario, in the context of RoboCup@Home international competition; Nevlyudov et al. (2008), Fakhruldeen et al. (2016) for robotic assembly in industry.
As detailed in Narboni (1999), Prolog represents task knowledge as a tree structure, following the variable-atom and atom-operator hierarchy. For instance, consider the statement representing the precondition of move(A, R, t) in the peg transfer task knolwedge:
A, R, C, t variables are leaf nodes for the corresponding predicate atoms move, reachable. Moreover, reachable is a leaf node for move, after the implication operator. Given such a tree structure, a solver for Prolog is able to respond to queries from the user implementing a backtracking algorithm.
Starting from a user’s query and available initial information (e.g., from sensors), Prolog solvers implement backtracking search along the tree branches, in order to verify whether atoms in the query can be grounded. Moreover, last explored branches in the tree are saved in a stack, so as to retrieve the root when a branch returns no solution and to restart the search process. More details on the algorithm can be found in Narboni (1999) and related references. Researchers have tried to improve the efficiency of this solving procedure, e.g., with intelligent backtracking based on the generator/consumer paradigm (Kumar and Lin 1988) or with parallel AND-tree verification in Pereira et al. (1986). More recently, Zhang and Hong (2019) presented an approach based on linear model reduction.
Backtracking requires the prior stratification of the program in order to guarantee that solving terminates. Stratification guarantees that a (propositional) logic program can be partioned in incremental subsets of clauses \(P_1 \cup ... \cup P_n\), such that:
-
if a predicate p appears as positive in \(P_i\), then it is defined in \(\bigcup _{j\le i} P_j\);
-
if a predicate p appears as negative in \(P_i\), then it is defined in \(\bigcup _{j< i} P_j\).
Since Prolog-based programs represent knowledge in a hierarchical tree structure, this subset composition guarantees that the tree search never gets stuck in a loop between predicates defined at different levels of the hierarchy. However, not all logic programs can be stratified, as evidenced by Drabent (1996).
6.2 Planners based on the answer set semantics
A non-monotonic logic programming language with similar syntax to Prolog is Answer Set Programming (ASP) (Calimeri et al. 2020). Introduced by Marek and Truszczyński (1999), ASP was first proposed in Lifschitz (1999) to solve the planning problem for autonomous agents, as applied, e.g., by Dimopoulos et al. (2019). ASP is based on the stable model semantics (Gelfond and Lifschitz 1988). In order to understand what a stable model, or answer set (Lifschitz 1999), for a logic program is, consider a classical (i.e., NAF-free) propositional logic formula F depending on a set X of Boolean variables. The reduct of F to X, represented as \(F^X\), is the formula resulting from the substitution of all variables appearing with negation with the false \(\bot\). We then define a stable model (or answer set) of F as a minimal model satisfying \(F^X\), namely a set \(Y \subseteq X\) with no proper subsets satisfying \(F^X\). For instance, let F be:
\(Y = \{s, p, q\} \subset X = \{s, p, q, r\}\) is an answer set for F, since it satisfies \(F^X : \ (q \rightarrow p) \wedge (\lnot \bot \rightarrow q) \wedge (p \rightarrow s)\) and no proper subset of Y does. If F includes NAFs, they are converted to classical negation (closed world assumption) and then the stable model is computed.
With reference to the peg transfer domain, consider the precondition for transfer action:
where not is ASP NAF syntax, similar to Prolog. In case sensors provide the initial grounding {t = 1, A = psm1, C1 = red, holding(psm1, ring, red, 1)}, not on(R, C1, P, C2, t) is converted to \(\lnot\) on(ring, red, peg, _, 1), where _ represents any possible assignment for C2. Hence, the following propositional logic formula is generated:
whose stable model is {transfer(psm1, ring, red, 1), holding(psm1, ring, red, 1)}. In other words, the transfer action can be executed. From this example, it is evident that an answer set includes all ground atoms, i.e., not only actions, but also environmental fluents. This represents one main difference with respect to Prolog-based systems, which instead answer to user’s specific queries. Computation of answer sets enhances the interpretability of the task planner, returning both the input (environmental context) and output (sequence of actions) to the task planning problem.
In general, stable models are not unique. This is evident, for instance, considering the ASP program describing the peg transfer task. For instance, when multiple rings are present in the peg transfer domain, their order is arbitrary, so multiple plans can be generated, each having a different ordering of rings. In this case, each plan is part of a separate answer set for the logic program.
ASP introduces additional constructs with respect to Prolog. Starting from the first solvers Smodels (Syrjänen and Niemelä 2001) and DLV (Eiter et al. 2000), up to the latest extensions as DLV2 (Adrian et al. 2018) and Clingo (Gebser et al. 2019), it is possible to define aggregates in the form l{a : b}u. An aggregate defines a set of atoms a, subject to preconditions b, such that the cardinality of the set (i.e., the number of grounded atoms a in the answer set) is bounded within l and u). This construct translates to a choice rule, which is useful to generate alternatives between sequences of actions in the task planning domain. For instance, multiple rings may be present in the peg transfer scenario, and either starting from any of them is possible to complete the task. However, it is possible to include preconditions to actions in an aggregate, e.g., for move(A, R, C, t):
In this way, up to only one action will be grounded in the answer set per time step, hence only one (random) plan will be finally generated. Similarly, it is possible to define an aggregate rule with an external condition:
In this case, the solver will ground up to one action for each PSM, so that the two robotic arms can operate at the same time on different rings, reducing the time for completing the task.
Choice rules may be supported by preference reasoning in ASP (Brewka et al. 2008) with weak constraints, or corresponding optimization statements introduced by the state-of-the-art Clingo system (Gebser et al. 2019). A weak constraint is expressed with the following syntax:
where b\(_{1..n}\) are body atoms depending on V\(_{1..m}\) variables, w is the weight and p is the priority level. The meaning of above syntax is that simultaneous grounding of body atoms has a cost equal to the weight. Answer sets must then guarantee the satisfaction of hard constraints defined with the usual syntax :- atom, but additionally shall preferrably minimize the weight of the weak constraint. If multiple weak constraints are grounded, then the cumulative weight has to be maximized, but priority is given to constraints with lower p. With reference to the example peg transfer task, assume to maximize economy of motion, e.g., moving first to the closest ring (to any PSM). This can be easily expressed introducing a new fluent in the domain description, distance(A, R, C, X, t), defining the distance between an arm and a ring as XFootnote 5. Then, it is possible to add the weak constraint:
in order to minimize the distance of target ring. Equivalent Clingo syntax for the weak constraint notation is the optimization statement:
ASP solvers compute answer sets with methods inherited from the area of satisfiability (SAT) checking (Biere et al. 2009). The basic approach consists in bottom-up grounding of initially known atoms (e.g., environmental information from sensors), and incrementally verifying logic implications. It is important here to mention Clingo, which allows to structure the ASP program in parts or sub-programs, specifically base, step and check. In a task planning domain, the base part typically contains definitions of resources, while specifications are in the step part and the goal is in the check sub-program. The solver verifies at each time step the check part, and increments the temporal variable to ground specifications only if the goal is not satisfied. In this way, the computation of the plan continues until the goal is not satisfied, thus implementing some capabilities of a temporal logic formalism.
Differently from Prolog tree search based mainly on Selective Linear Definite with Negation as Failure (SLDNF) (Apt and Doets 1994), ASP solvers guarantee termination (Lifschitz 2008). Moreover, SAT solving has applications in a variety of fields of computer science. For this reason, starting from the popular MiniSAT (Sorensson and Een 2005), a lot of research has been devoted to improve the efficiency of existing SAT solvers (inherently NP complete) even in complex domains [see Manthey (2016) for recent advances], e.g., with parallel evaluation of specifications as in Clingo (Kaufmann et al. 2016). Furthermore, ASP syntax forces the user to define safe statements, i.e., all variables in the head must appear also in the body without NAF. In this way, propagation of grounded atoms from bodies to heads is more efficient, since variables in the head inherit a specific assignment from the body.
Though a multitude of applications of ASP can be found in AI planning [see Erdem et al. (2016) for a recent review], the applications in robotics are still fewer than Prolog-based systems, which have been well established for a significantly longer time. This is also due to the development of research for efficient SAT solving algorithms, which is significantly advancing only in recent years. Currently, the most popular implementation for ASP, with applications in the robotic scenario, is Clingo, which from the latest release (Clingo 5) also implements constraints on reals.
Relevant applications of Clingo have been proposed by Pianpak et al. (2019), where its variant Asprilo (Gebser et al. 2018) for multi-robot logistics and warehouse automation, is exploited; Opfer et al. (2018), where Clingo system is integrated with the ALICA language for teamworking in domestic and general-purpose environment (Opfer et al. 2019; Cui et al. 2021) for general-purpose service robotics; Lu et al. (2017), proposing a task planning framework for domestic service robots receiving information and goal description in natural language from humans, at the RoboCup@Home challenge; Ginesi et al. (2020), Meli et al. (2021b), Tagliabue et al. (2022), where an integrated framework for interpretable surgical task-motion planning is proposed; Andres et al. (2015), which shows the ROSoClingo package integrating Clingo in ROS. A recent application based on the DLV system can be found in Wang et al. (2009), addressing the problem of mechanical assembly sequence in industry.
Several other implementations of ASP have been proposed by Tu et al. (2007), where an Answer Set-based Conditional Planner (ASCP) is presented with applications also to robotic examples; Chen et al. (2013), where ASP is implemented on the OK-KeJia service robot prototype for planning and decision-making based on multiple sources of information in the context of human-robot interaction; Baral and Son (2015), proving the advantages of using ASP for task planning and failure analysis and explanation in human-robot interaction; Ji (2009) for the domestic service scenario; Sridharan et al. (2019), combining ASP with Markov decision processes in a domestic scenario; Bertolucci et al. (2021) for dual arm manipulation; Falkner et al. (2018) propose a review of recent applications of ASP to industry, while Erdem and Patoglu (2018) survey recent applications in various robotic fields. Finally, we mention recently growing interest in ASP applications to the scheduling problem, either in transportation/routing (Gebser et al. 2018; Abels et al. 2019) or space assignment (Dodaro et al. 2021, 2022) scenarios. Though robotic implementations are still missing, we believe this is an interesting application of ASP to trending robotic problems, e.g., autonomous vehicle and industrial/service automation design.
6.3 Other planners
While Prolog- and ASP-based planners are most popular and can be applied to a wide range of domains, several other implementations of planners based on standard logic programming exist. An example are constraint-handling rules (Frühwirth 1998), which improve performance of the solving process simplifying task-specific constraints online. An example of this approach is implemented in fluent executor (Thielscher 2005), which has been used, e.g., for the automation of an office robot, hence in an application involving human-robot interaction (Wu and Liu 2008).
Analogous application-specific approaches rely directly on a generic description of the task in an action language (e.g., PDDL), and implement a custom solution approach for the specific use case. An important example of this class of planners is ROSPlan (Cashmore et al. 2015), a framework combining PDDL-based task planning, motion planning, sensing and open-world planning. Basing on ROS infrastructure offers a considerable implementative advantage for application with most robotic systems. ROSPlan has been applied in several scenarios, e.g., by Miranda et al. (2018) for multi-robot navigation; Sanelli et al. (2017), integrated with Petri nets for human-robot interaction; Escudero-Rodrigo and Alquezar (2016), tackling the anchoring problem, that is matching abstract symbols from high-level knowledge to perceptions and executed actions, in order to automatically generate code for ROS nodes.
Other examples of custom implementations derived from PDDL are based on action graphs (Harman and Simoens 2020). Gragera et al. (2019) proposed a PDDL-based planner for social robotics; Moon and Lee (2019) investigated coordination of unnamed ground and aerial vehicles; Muñoz et al. (2019) implemented an integrated framework for robotic manipulator, surveillance and rover exploration; Ma et al. (2016) focused on mobile robots in the ROS framework; SHOP Nau et al. (1999) was proposed for a state-of-the-art implementation of Hierarchical Task Network (HTN) (Erol 1996), a popular and efficient formalism for task planning with sub-goals.
It is important here to highlight that task-specific approaches derived from generic PDDL descriptions of the task are not the only choice, and other custom implementations based, e.g., on ASP- and Prolog-like syntax are possible and can be adapted to the specific needs of the use case. For instance, in Dix et al. (2003) AnsProlog, the language for answer set semantics, was used to implement HTN, proving comparable efficiency with respect to SHOP [a more extended comparison is available in Son et al. (2006)]. Moreover, recently PDDL- and ASP-based planners have been compared by Jiang et al. (2019). The authors compare Clingo as the state-of-the-art implementation of ASP against the two most prominent FastDownward PDDL-based planners FDSS-1 (Helmert et al. 2011) and LAMA-2011 (Richter et al. 2011), in different experimental scenarios including robot navigation. The comparison shows that PDDL-based systems are generally more efficient when the required plan for the task is composed of a long sequence of actions. However, the computational performance of ASP-based systems are better for shorter plans, and they scale significantly better with the size of the domain description (i.e., the number of resources and specifications).
6.4 Discussion
Prolog- and ASP-based systems are the most prominent solutions to the task planning problem in robotics. Their main advantage lies in the non-monotonic representation of task knowledge, which is essential for robotic applications since it allows plan revision when environmental conditions change. Prolog-based planners as SWI-Prolog (Wielemaker et al. 2012) are query-based planners which also support advanced reasoning on continuous variables, bridging the gap between the discrete logic representation of the robotic scenario and the continuous perception of, and interaction with, the environment. However, this may reduce the computational efficiency of solving the planning problem online (Helmert 2002). Instead, ASP-based frameworks as Clingo by Gebser et al. (2019) directly compute more interpretable and informative answer sets, i.e., sets of ground atoms representing the current environmental conditions and the possible plans to accomplish a given task. Moreover, they allow multiple plan generation and preference reasoning for optimal planning.
All standard logic programming frameworks allow to represent temporal concepts (e.g., temporal sequence, or event-driven properties) by introducing an additional variable for temporal indexing, as shown in the beginning of this section and by Son et al. (2006), Meli et al. (2021a). In particular, examples of temporal Prolog extensions can be found in Abadi and Manna (1989), while recently temporal extensions to the ASP syntax telingo (Cabalar et al. 2019a) and tasplan (Cabalar et al. 2019b) have been proposed, based on Clingo solver and temporal equilibrium logic (Aguado et al. 2013). Although no relevant robotic applications of these paradigms are known to the authors, temporal extensions of ASP and Prolog may well find a wide range of applications in the future, since they offer invaluable advantages, e.g., non-monotonicity in the task knowledge representation.
For these reasons, the research community has put considerable effort in implementing time- and memory-efficient solvers, especially in the field of SAT solving for ASP-based planners. This balances the increase in the size of represented knowledge and computational cost, e.g., when additional variables and specifications for temporal reasoning are included. Also, state-of-the-art frameworks as Clingo and SWI-Prolog offer C/C++, Java and Python APIs, as well as easy integration with ROS.
In addition, some standard logic programming languages can support the open-world assumption, integrating external knowledge bases to be queried when needed during the plan execution, in order to implement modular and more efficient knowledge representation in very complex domains. In fact, the knowledge base encodes a detailed description of the scenario, while the logic program only encodes task specifications and queries the knowledge base for selective grounding. The most popular example of this approach is the CRAM framework by Beetz et al. (2010b) for advanced robotic manipulation, based on Knowrob (Tenorth and Beetz 2017) ontology for general service robotic tasks. Knowledge is queried through SWI-Prolog, as validated, e.g., by Yazdani et al. (2019), where an outdoor search-and-rescue robotic task is fulfilled, performing geometric reasoning and semantic modeling of the environment; Crespo et al. (2018) for multi-objective navigation tasks; Beßler et al. (2018) for incomplete assembly task in industry; Gonçalves and Torres (2015) for task planning in orthopaedic surgery, integrating an orthopaedic-specific knowledge base; Papadimitriou et al. (2015) for the safety-critical scenario of mine-countermeasures missions for autonomous underwater vehicles, addressing the challenge of recovery from hardware failure and changes in priority levels. Another implementation, based on the answer set semantics, is a recent extension of DLV, DLVHEX (Eiter et al. 2018), which provides specific constructs to query external knowledge bases. While not providing the same expressive power as description logics, the query-based approach integrating logic programming and ontologies is usually more efficient and preserves the non-monotonic assumption, which is essential in most applications.
7 Temporal logic programming
Standard logic programming offers the expressivity to describe many task planning problems in robotics, with operators representing causal relations between atoms. However, in several scenarios additional expressivity is required to describe complex temporal relations between resources. The scope of this section is to present logic programming solutions based on temporal logic formalism. Main temporal operators for robotic applications are:
-
eventually \(\lozenge\) a, prescribing that a statement or atom a shall hold at some point in the future;
-
next \(\text {O}\) a, specifying that a holds at the subsequent time step;
-
always \(\square\) a, prescribing that a can never be false;
-
until a\(\mathcal {U}\) b, meaning that a must hold at least until b becomes true;
-
release a\(\mathcal {R}\) b, specifying that b holds until a becomes true (in this sense, a releases b).
As mentioned in the previous section, some of these temporal relations (e.g., effects of actions with temporal delay) can be represented even with standard logic formalism. However, this requires the definition of an explicit temporal variable t. Moreover, it is not straightforward to express complex relations without specific temporal operators. For instance, consider the peg transfer task, and assume that rings have a significant mass, so that they exert high force on the grasping tool. In this case, a reasonable approach is to slowly lift a ring, e.g., to extract it from a peg, while continuously monitoring the force sensed at the end effector. If some safety threshold is overcome, then extraction must be interrupted and a recovery policy is needed. Using standard Boolean logic, e.g., with ASP, this could be ex pressed with the following set of statements:
where max_force(A, t) is a fluent grounded when force sensors detect high force at the tool. The two above statements can be replaced with a single statement in temporal logic, with the \(\mathcal {R}\) operator:
Logic programming framework in this section mainly rely on linear temporal logic (LTL) by Pnueli (1977), assuming a linear sequence of events, rather than multiple realizations as in more complex (and computationally inconvenient) non-linear temporal logic [e.g., CTL by Emerson and Clarke (1982)]. Specifically, an interpretation of LTL is considered over finite traces (LTL\(_f\)), i.e., over a finite time horizon, as proposed, e.g., by Bienvenu et al. (2006), Gabaldon (2004), Wilke (1999). This is a reasonable assumption for robotic tasks, which typically involve a limited sequence of actions to be performed. The choice to focus on LTL is justified by two reasons. First, LTL\(_f\) has been proved to be as expressive as first order logic in Diekert and Gastin (2008). LTL’s extension LDL\(_f\) (De Giacomo and Vardi 2013), including regular expressions from propositional dynamic logic (Fischer and Ladner 1979), has been proved to be as expressive as monadic second order logic for finite automata by Trakhtenbrot (1962). The problem of synthesis for LDL\(_f\) formulas (i.e., the assignment of truth values to variables so that the given formulas hold) has been proved to be equivalent to the problem of conditional planning under full observability, and 2EXPTIME-complete (De Giacomo and Vardi 2015). Hence, it is possible to encode a generic task planning problem from high-level action languages (e.g., PDDL) into LTL\(_f\)/LDL\(_f\) formulas, which are then solved through methods based on SAT checking. For simplicity, the subscript f will be omitted through the rest of this section, hence LTL will stand for LTL\(_f\).
A relevant tool for LTL in the robotic community is LTLMoP by Finucane et al. (2010), to implement temporal task specifications in the ROS framework. LTLMoP has been used for multi-target navigation (Kumar and Kala 2016); task planning in a grocery store with an Aldebaran Nao robot (Jing et al. 2012); multi-robot cooperative task planning (Kim and Kwon 2012, 2014); search-and-rescue mission in partially known environment with a Pioneer 3-DX robot (Sarid et al. 2013); task planning for modular robots (Jing et al. 2016); multi-task planning for a patrol robot (Liu et al. 2017); reactive task planning based on game theory (Schmuck et al. 2017). Also relevant is the application of LTLMoP to the problem of explanation of unsynthetizable plans for robotics (Raman and Kress-Gazit 2012), which is useful to enhance the interpretability of the robotic system. LTLMoP implements SAT checking to solve the task planning problem from temporal specifications. As evidenced by Kress-Gazit et al. (2011), one limitation of this approach is the state explosion problem, which is caused by the introduction of the temporal dimension in the planning problem and hence the different time horizons to be evaluated at the solving stage. This becomes even more crucial when implementing LTL for on real robots, typically with hybrid control (connecting discrete-time and continuous-time control) so that the lower-level motion behavior matches the task-level specifications. In this scenario, LTL-based plan synthesis becomes often intractable, due to infeasibility of analyzing all future scenarios. In order to cope with the computational issues, several solutions have been proposed.
For instance, in Lahijanian et al. (2015) the concept of quantification of satisfiability has been introduced, in order to guarantee the satisfaction of main LTL constraints while neglecting less important ones. This solution is applied, e.g., in Tumova et al. (2014), where maximal satisfaction of LTL task specifications is guaranted for a Nao robot able to grasp, drop a ball and walk managing failure conditions.
Another widely used approach is the receding time horizon (Wongpiromsarn et al. 2010), which relies on the assumption that the dynamic nature of the environment does not allow to devise a plan which extends long ahead in the future. Hence, a good design choice is to verify LTL formulas with a short time horizon, and to refine the resulting plan on the fly during the execution, according to the current state. In this way, only most probable future traces are analyzed, and the state explosion is significantly mitigated. A tool which implements the receding time horizon approach, differently from LTLMoP, is TuLiP (Wongpiromsarn et al. 2011a). Though it has been mostly applied to the provably-correct construction of hybrid controllers for integrated task-level (discrete) and motion planning (continuous) problems, worth mentioning are the applications in Lin (2014), where a robot surveillance task is planned through TuLiP, while local reactivity as in Bloem et al. (2012) and refinement is guaranteed through \(\mu\)-calculus, a modal logic which can be used to express temporal formulas (Bradfield and Stirling 2007; and Zhao et al. 2016) for whole-body biped locomotion in unstructured environment.
The two above solutions are unfortunately not always applicable in robotics. In fact, quantifying the relevance of constraints to be considered in the solving process is dangerous in safety-critic scenarios, since it could lead to undesired behavior. As for limiting the maximum time horizon, it is possible for simple tasks as the peg transfer, but it does not scale properly to complex tasks with long-term goals, e.g., exploration of wide and possibly unknown environments.
Other LTL-based paradigms for robotic task planning exist, which have the same issues as the above mentioned ones, though. They find mostly application in multi-robot systems coordination (Kloetzer and Belta 2006; Wong and Kress-Gazit 2016; Lacerda and Lima 2012), with Petri-net task representation; Guo et al. (2014), with dynamic leader selection under communication constraints; Guo et al. (2016) with mutual distance constraints; Kress-Gazit et al. (2009) for search-and-rescue and coverage scenarios; He et al. (2015) for manipulation tasks; Schillinger et al. (2017) for time optimality under the ROS framework; Gundana and Kress-Gazit (2021), where signal temporal logic (Donzé and Maler 2010), a temporal logic devised for motion planning, is combined with standard LTL to deal with event-based task planning in a multi-robot domain. It is also important to mention other applications, including Xu et al. (2016) where dynamic planning in a robotic fire-fighting scenario is investigated; Colledanchise et al. (2017) where the construction of behavioral trees from LTL specifications is used for simulated task planning of a mobile robot in adversarial environment; Bank et al. (2018) for autonomous flexible manufacturing with experimental evaluation on a Gantry robot in Siemens NX Mechatronics Concept Designer simulator; Hao et al. (2017) for warehouse robotics; Guo et al. (2013) for robot navigation, integrated with lower-level model-ckecking-based motion planning through hybrid control; Camacho et al. (2017), where LTL over finite and infinite traces specifications derived from PDDL encoding are solved through translation to non-deterministic automata; Choi et al. (2021), where LTL is used to design a medical robot tasked with roles of patient reception and triage.
7.1 Discussion
Temporal logic programs can represent complex temporal task specifications in an elegant formalism, without the need to use an ad-hoc variable for temporal indexing. This is particularly useful in applications concerning involving long planning horizon, or when formal properties of the robotic system and the environment must be guaranteed (e.g., stability or reachability of safe states in integrated task-motion planning). The need for considerable temporal expressivity is evidenced by the many applications of temporal extensions of PDDL implemented in LTL syntax, e.g., in industrial automation (Kootbally 2016) or for multi-robot mission planning (Wurm et al. 2010, 2013; Coles et al. 2019; Carreno et al. 2020).
One main limitation of temporal logic programming is the non-monotonicity of most formalisms [apart from few exceptions with no application to robotics, e.g., by Baral and Zhao (2007)], which hinders online reconfigurability and plan revision in under dynamic environmental conditions. Moreover, the increased expressive power brings an added computational cost, induced by the inherent complexity of the decidability problem for temporal planning (Rintanen 2007). For this reason, several temporal extensions of standard logic programming paradigms exist, e.g., Prolog-like (Abadi and Manna 1989) and more recent ASP-based telingo by Cabalar et al. (2019a) mentioned in Sect. 6.4.
Nevertheless, recently a significant effort in implementing efficient LTL SAT checking is being devoted, e.g., by Dureja and Rozier (2018), Geatti et al. (2021), in order to bridge the gap between temporal logic programming and practical robotic use cases. Main paradigms presented in this section, i.e., TuLiP (Wongpiromsarn et al. 2011b) and LTLMoP (Finucane et al. 2010), also offer implementation support via, e.g., Python APIs, and the latter has been already integrated in the ROS framework.
8 Probabilistic logic programming
The logic programming solutions presented in the previous sections allow to describe task planning problems with complex constraints, involving temporal and causal relations. However, an important challenge for deliberative robots interacting with unknown environment is the quality of the perception. This requires a real-time planning system which not only accounts for the real-time information from sensors to update the environmental model, but also considers uncertainty of the sensed model and generates a sequence of most probable actions, to be refined as new evidence is acquired. In this section, logic programming languages are analyzed which enrich standard and temporal logic semantics with concepts from probability theory, in order to express specifications with some degree of uncertainty. Probabilistic logic definitions can be found, e.g., in Ng and Subrahmanian (1992), Distribution Semantics (DS) in Sato (1995) and relative extensions (Lukasiewicz 1998, 2001).
The syntax of probabilistic logic programs includes p-annotated atoms and rules. Given \(\mu \subseteq [0,1]\), a p-annotated Boolean \(a:\mu\) is a Boolean variable which is true with probability in \(\mu\). Similarly, in the formalism of logic programming it is possible to define p-atoms which can be grounded with bounded probability. A p-statement is then a statement either containing p-annotated atoms, or with its own annotation (i.e., \((a \leftarrow b):\mu\)). For instance, in the peg transfer domain the location of a ring may be known with accuracy between 50 and 80%, depending on noisy point cloud from the RGBD camera. This affects the probability of all atoms related to ring’s position, e.g., reachable(A, R, C, t) becomes a p-atom reachable(A, R, C, t):[0.5, 0.8]. As a consequence, all statements including the reachability atoms become p-statements. For example, the precondition for moving to a ring becomes:
Also move(A, R, t) then becomes a p-annotated atom, which inherits the same probability range as the p-atom precondition. If multiple preconditions hold for an atom, the annotations of all of them concur at defining its probability range.
As a consequence, the solving process for probabilistic logic programs suffers from a state explosion problem similar to temporal logic. In fact, it is not possible to ground an atom as true or false (assuming closed-world assumption), unless the probability range reduces to \(\{0\}\). Then, grounding atoms according to specifications involves combining different probability ranges for body atoms, and then propagating them to head atoms, evaluating all possible scenarios.
Several preliminary solutions have been proposed to make probabilistic logic solving more efficient. For instance, it is possible to restrict the solution of the logic program to the deduction of only tight logic consequences. Considering a set of probabilistic propositional logic clauses (resulting from grounding of p-statements) \(\mathcal {P}\), a clause c:\(\mu _c\) is said to be a tight logic consequence of \(\mathcal {P}\) if \(sup \mu _c = max \mu , inf \mu _c = min \mu\), where \(\mu \subseteq [0,1]\) is the set of real numbers for which there always exists a realization for clauses in \(\mathcal {P}\). In other words, a clause is a tight logic consequence of a set of clauses if it can be deduced from all their possible realizations. As an example, consider the peg transfer domain. From specifications, we know that it is possible to place a ring on a peg either by directly moving it to the peg, or by transferring it to the other arm first, depending on reachability conditions. Assuming that environmental fluents are p-atoms due to sensor uncertainty, we can encode this knowledge with the following probabilistic clauses:
and on(ring, red, peg, red, _) : [0.7, 1] is a tight logic consequence.
Lukasiewicz (1998) showed that the deduction of tight logic consequences can be reduced to solving two linear programs, assuming no negations are involved. However, the problem is shown to be NP in general, depending on the number of possible realizations. Hence, the author also proposed an algorithm to further mitigate the complexity of the problem when probabilistic clauses are separable from deterministic ones.
Another solution consists in using approximate sampling methods for stochastic systems, e.g., Monte Carlo. This is used, e.g., in Problog (De Raedt et al. 2007), a popular probabilistic extension to Prolog which allows to define a weight assigning discrete probabilities to atoms and specifications. In this way, discrete probabilities are assigned to p-atoms and p-statements, instead of real ranges, and propagation of grounded atoms is more efficient [recall that reasoning on continuous variables has been proved in general undecidable by Helmert (2002)]. Problog and its variants have been applied to several robotic task planning scenarios, e.g., for opening doors (Moldovan et al. 2013) and object manipulation (Moldovan et al. 2012; Tan et al. 2019; Antanas et al. 2019). An alternative approach to Problog is the framework of distributional clauses (DC) by Gutmann et al. (2011), which extends Problog allowing to define continuous probability distributions over rules and atoms. DC has been used for robotic manipulation and grasping in Moldovan and De Raedt (2014), Nitti et al. (2015); Moldovan et al. (2018).
The above mentioned approaches are still approximate or can be applied only to a restricted class of logic programs, which makes them unsuitable for most real-time robotic domains. Nevertheless, probabilistic logic programming has the potential to fill the gap between classical logic determinism and the intrinsic uncertainty deriving from the planning-acting-sensing loop of deliberative robots.
Recent research is in fact focusing on integrating query-based planners with probabilistic knowledge in open-world domains, which can be updated as new evidence is acquired (similarly, e.g., to what is done with the CRAM framework in standard logic). A relevant example is proposed in Jain et al. (2009), where the ProbCog system allows to query and reason on a Bayesian logic network (BLN) derived from the probabilistic logic of multi-entity Bayesian networks (MEBN) (Laskey 2008) in a domestic scenario with a B21 service robot. Basically, a MEBN is a knowledge representation formalism which connects fragments of Bayesian networks through statements in first-order logic. This framework has been used, e.g., in Beetz et al. (2012) for complex task decomposition and planning with a robot for home chore; Beetz et al. (2010a), Nyga and Beetz (2012) for manipulation; Maurelli et al. (2014) for cognitive underwater vehicles.
A similar approach is presented in Nyga et al. (2018) for domestic tasks, using a Markov logic network (MLN) (Richardson and Domingos 2006) instead of a BLN. MLNs are based on probabilistic weighted logic statements. In Al-Moadhen et al. (2016) task planning for manipulation and navigation scenarios is implemented querying a MLN with the STRIPS-based Metric-FF planner (Hoffmann and Nebel 2001); in Lisca et al. (2015) a robot for chemical experiment automation is proposed querying probabilistic action cores (PRACs) (Nyga and Beetz 2012) based on MLNs. A mention is also deserved by LP\(^{MLN}\) (Lee and Wang 2016, 2018) to reason on MLNs using the answer set semantics under the action language \(\mathcal{B}\mathcal{C}+\) (Babb and Lee 2015) for transition systems, though the actual application in robotic scenarios is still part of ongoing research.
It is also important to highlight that research is pushing towards the extension of the answer set semantics with probability theory. The main example is P-log (Baral et al. 2004) which is based on weighted specifications as Problog, used, e.g., in the LCORPP framework for sequential robot planning (Amiri et al. 2019). In this way, in the next future it may be possible to exploit recent advances in SAT solving strategies in the field of probabilistic logic.
Among other implementations of probabilistic logic programming with application to robotic scenarios, we mention PREGO (Belle and Levesque 2014), which is similar to DC; Probabilistic Computational Tree Logic (PCTL) by Rutten et al. (2004), a probabilistic non-linear temporal logic, to define task specification, e.g., in human-robot interaction for manufacturing (Zhang et al. 2016) and robotic swarm coordination (Brambilla et al. 2012; Gurzoni et al. 2014), where event calculus based on MLNs is applied to a search-and-rescue scenario.
8.1 Discussion
Planners based on probabilistic logic programming allow to elegantly model uncertainty of real robotic scenarios into task specifications, extending rules and atoms with discrete probability values as in Problog by De Raedt et al. (2007), or even with continuous distributions as in DC (Gutmann et al. 2011). This allows to enrich the expressivity of purely probabilistic Markov or Bayesian networks, enhancing interpretability. The main representative tool, Problog, is an extension of Prolog, so it offers most of its advantages, including Python/Java APIs, advanced constructs and possibly integration with external knowledge bases for open-world reasoning as in CRAM (Beetz et al. 2010b). Similarly, probabilistic extensions have been proposed for temporal logic programming, e.g., PCTL by Rutten et al. (2004), and the answer set semantics (Baral et al. 2004).
While several robotic applications of the probabilistic logic programming paradigms can be found in recent literature, the main limitation of current representation and reasoning tools is the computational inefficiency rising from the complexity of the planning problem under uncertainty (Helmert 2002), especially when continuous (more realistic) probability distributions are modeled. As a consequence, the most efficient solution for combining advantages of formal logics and probability theory currently consists of a hierarchical composition of standard logic [e.g., ASP by Sridharan et al. (2019), Leonetti et al. (2016) for autonomous navigation and exploration] or temporal logic programming (Leonetti et al. 2012) with Markov models, in order to constrain probabilistic reasoning and generate more efficient and interpretable robust plans.
9 Conclusion
Standard logic programming frameworks are currently the most prominent solutions (in the field of logic-based approaches) to the task planning problem for deliberative robots, since they offer sufficient expressivity for most real use cases, sufficient software support for integration in robotic applications, and implement efficient solving algorithms. Prolog-based frameworks have the longest history and popularity, but ASP-based frameworks are rapidly emerging as valid competitors. The state-of-the-art solution in the answer set semantics is Clingo, which supports optimal plan generation through preference reasoning. In general, Prolog-based tools are designed to answer external queries, so they are best suited when reasoning on large knowledge bases (e.g., in the CRAM project) or in tight human-robot interaction. On the contrary, ASP-based planners should be preferred for advanced policy search in complex scenarios.
Temporal logic provides a useful formalism for integrated task and motion planning (e.g., with TuLiP), hence it could prompt the development of next-generation deliberative robots. Similarly, probabilistic logic promises to bridge the gap between planning and sensing. Unfortunately, both formalisms suffer from computational inefficiency in realistic scenarios, due to state explosion problems. As a consequence, a generic framework has not emerged yet in the robotic community, and custom application-specific implementations, or alternative frameworks (e.g., Bayesian) are still the state of the art.
We believe that future research should push towards the integration of different frameworks, to find the best tradeoff between efficiency and expressivity. For instance, a recent framework which proposes temporal ASP is telingo by Cabalar et al. (2019a), while the hierarchical combination of logic planning and Markov decision processes has been proposed by Sridharan et al. (2019).
Data availability
Not applicable.
Code availability
Not applicable.
Notes
A more granular definition of actions is possible, e.g., considering gripper actions (opening and grasping). We decided to include them implicitly as part of the moving actions (grasping after reaching a ring, releasing after reaching a peg), in order to keep the task description contained.
Here, PDDL 3.1 syntax is used as of https://helios.hud.ac.uk/scommv/IPC-14/repository/kovacs-pddl-3.1-2011.pdf.
As clarified in the next sections, dependency on time can be made explicit through the use of a temporal variable, depending on the specific logic programming framework.
X variable can only have integer value in ASP. It is then important to convert actual distances between objects of the domain to integers, e.g., with ranking over all distances as shown by Ginesi et al. (2020)
References
Abadi M, Manna Z (1989) Temporal logic programming. J Symb Comput 8(3):277–295
Abels D, Jordi J, Ostrowski M, Schaub T, Toletti A, Wanko P (2019) Train scheduling with hybrid asp. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 3–17
Adrian WT, Alviano M, Calimeri F, Cuteri B, Dodaro C, Faber W, Fuscà D, Leone N, Manna M, Perri S et al (2018) The asp system DLV: advancements and applications. KI-Künstliche Intelligenz 32(2):177–179
Aeronautiques C, Howe A, Knoblock C, McDermott ID, Ram A, Veloso M, Weld D, SRI DW, Barrett A, Christianson D et al (1998) Pddl| the planning domain definition language. Technical Report, Tech Rep
Aguado F, Cabalar P, Diéguez M, Pérez G, Vidal C (2013) Temporal equilibrium logic: a survey. J Appl Non-Class Log 23(1–2):2–24
Al-Moadhen AA, Packianather M, Setchi R, Qiu R (2016) Robot task planning in deterministic and probabilistic conditions using semantic knowledge base. Int J Knowl Syst Sci 7(1):56–77
Alami R, Clodic A, Montreuil V, Sisbot EA, Chatila R (2005) Task planning for human-robot interaction. In: Proceedings of the 2005 joint conference on smart objects and ambient intelligence: innovative context-aware services: usages and technologies, pp 81–85
Alferes JJ, Leite JA, Pereira LM, Quaresma P (2000) Planning as abductive updating. In: Proc. of the symposium on AI planning and intelligent agents, pp 1–8
Amiri S, Shirazi MS, Zhang S (2019) Learning and reasoning for robot sequential decision making under uncertainty. arXiv preprint arXiv:1901.05322
Andres B, Rajaratnam D, Sabuncu O, Schaub T (2015) Integrating asp into ros for reasoning in robots. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 69–82
Antanas L, Moreno P, Neumann M, de Figueiredo RP, Kersting K, Santos-Victor J, De Raedt L (2019) Semantic and geometric reasoning for robotic grasping: a probabilistic logic approach. Auton Robots 43(6):1393–1418
Apt KR, Doets K (1994) A new definition of sldnf-resolution. J Log Program 18(2):177–190
Armando A, Castellini C, Giunchiglia E (1999) Sat-based procedures for temporal reasoning. In: European conference on planning, Springer, pp 97–108
Baader F, Calvanese D, McGuinness D, Patel-Schneider P, Nardi D (2003a) The description logic handbook: theory, implementation and applications. Cambridge University Press, Cambridge
Baader F, Calvanese D, McGuinness D, Patel-Schneider P, Nardi D et al (2003b) The description logic handbook: theory, implementation and applications. Cambridge University Press, Cambridge
Babb J, Lee J, Action language \(\mathcal{BC}\)+. J Logic Comput 30(4):899–922, https://doi.org/10.1093/logcom/exv062
Bäckström C, Klein I (1991) Planning in polynomial time: the sas-pubs class. Comput Intell 7(3):181–197
Bank HS, D’Souza S, Rasam A (2018) Temporal logic (TL)-based autonomy for smart manufacturing systems. Procedia Manuf 26:1221–1229
Baral C, Son TC (2015) “Add another blue stack of the same height!”: Asp based planning and plan failure analysis. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 127–133
Baral C, Zhao J (2007) Non-monotonic temporal logics for goal specification. Int Joint Conf Artif Intell 7:236–242
Baral C, Gelfond M, Rushton N (2004) Probabilistic reasoning with answer sets. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 21–33
Beetz M, Jain D, Mösenlechner L, Tenorth M (2010a) Towards performing everyday manipulation activities. Robot Auton Syst 58(9):1085–1095
Beetz M, Mösenlechner L, Tenorth M (2010b) Cram’a cognitive robot abstract machine for everyday manipulation in human environments. In: 2010 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 1012–1017
Beetz M, Jain D, Mosenlechner L, Tenorth M, Kunze L, Blodow N, Pangercic D (2012) Cognition-enabled autonomous robot control for the realization of home chore task intelligence. Proceedings of the IEEE 100(8):2454–2471
Belle V, Levesque H (2014) Prego: an action language for belief-based cognitive robotics in continuous domains. In: Twenty-eighth AAAI conference on artificial intelligence
Bertolucci R, Capitanelli A, Dodaro C, Leone N, Maratea M, Mastrogiovanni F, Vallati M (2021) Manipulation of articulated objects using dual-arm robots via answer set programming. Theory Pract Log Program 21(3):372–401
Beßler D, Pomarlan M, Beetz M (2018) Owl-enabled assembly planning for robotic agents. In: Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, AAMAS vol 3, pp 1684–1692
Bienvenu M, Fritz C, McIlraith SA (2006) Planning with qualitative temporal preferences. Int Conf Princ Knowl Represent Reason 6:134–144
Biere A, Heule M, van Maaren H (2009) Handbook of satisfiability, vol 185. IOS Press, Amsterdam
Bloem R, Jobstmann B, Piterman N, Pnueli A, Sa’ar Y (2012) Synthesis of reactive (1) designs. J Comput Syst Sci 78(3):911–938
Bogue R (2011) Robots in the nuclear industry: a review of technologies and applications. Ind Robot: Int J 38:113–118
Bogue R (2018) What are the prospects for robots in the construction industry? Ind Robot: Int J 45:1–6
Bolisani E, Bratianu C (2017) Knowledge strategy planning: an integrated approach to manage uncertainty, turbulence, and dynamics. J Knowl Manage. https://doi.org/10.1108/JKM-02-2016-0071
Bradfield J, Stirling C (2007) Modal mu-calculi. Handb Modal Logic 3:721–756
Brambilla M, Pinciroli C, Birattari M, Dorigo M (2012) Property-driven design for swarm robotics. In: 11th international conference on autonomous agents and multiagent system. AAMAS: Innovative Applications Track, vol 2, pp 664–671
Bratman M (1987) Intention, plans, and practical reason. Harvard University Press, Cambridge
Bratman ME et al (1988) Plans and resource-bounded practical reasoning. Comput Intell 4(3):349–355
Brewka G, Niemela I, Truszczynski M (2008) Preferences and nonmonotonic reasoning. AI Mag 29(4):69–69
Bruno B, Chong NY, Kamide H, Kanoria S, Lee J, Lim Y, Pandey AK, Papadopoulos C, Papadopoulos I, Pecora F et al (2017) The caresses eu-japan project: making assistive robots culturally competent. In: Italian forum of ambient assisted living, Springer, pp 151–169
Bylander T (1994) The computational complexity of propositional strips planning. Artif Intell 69(1–2):165–204
Cabalar P, Kaminski R, Morkisch P, Schaub T (2019a) telingo= asp+ time. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 256–269
Cabalar P, Rey M, Vidal C (2019b) A complete planner for temporal answer set programming. In: EPIA conference on artificial intelligence, Springer, pp 520–525
Calimeri F, Faber W, Gebser M, Ianni G, Kaminski R, Krennwallner T, Leone N, Maratea M, Ricca F, Schaub T (2020) Asp-core-2 input language format. Theory Pract Log Program 20(2):294–309
Camacho A, Triantafillou E, Muise C, Baier JA, McIlraith SA (2017) Non-deterministic planning with temporally extended goals: Ltl over finite and infinite traces. In: 31st AAAI conference on artificial intelligence, AAAI 2017, pp 3716–3724
Campbell M, Egerstedt M, How JP, Murray RM (2010) Autonomous driving in urban environments: approaches, lessons and challenges. Philos Trans R Soc A 368(1928):4649–4672
Carreno Y, Pairet È, Petillot Y, Petrick RP (2020) A decentralised strategy for heterogeneous auv missions via goal distribution and temporal planning. In: Proceedings of the international conference on automated planning and scheduling, vol 30, pp 431–439
Cashmore M, Fox M, Long D, Magazzeni D, Ridder B, Carrera A, Palomeras N, Hurtos N, Carreras M (2015) Rosplan: planning in the robot operating system. In: Twenty-fifth international conference on automated planning and scheduling
Chandrasekaran B, Conrad JM (2015) Human-robot collaboration: a survey. In: SoutheastCon 2015, IEEE, pp 1–8
Chen X, Xie J, Ji J, Sui Z (2013) Toward open knowledge enabling for human-robot interaction. J Hum-Robot Interact 1(2):100–117
Choi B, Park J, Park C (2021) Formal verification for human-robot interaction in medical environments. In: ACM/IEEE international conference on human-robot interaction, pp 181–185
Coles AJ, Coles AI, Munoz MM, Savas OE, Keller T, Pommerening F, Helmert M (2019) On-board planning for robotic space missions using temporal pddl. In: 11th international workshop on planning and scheduling for space
Colledanchise M, Murray RM, Ogren P (2017) Synthesis of correct-by-construction behavior trees. In: IEEE international conference on intelligent robots and systems, vol 2017, pp 6039–6046
Colmerauer A (1990) An introduction to prolog iii. In: Computational logic, Springer, pp 37–79
Crespo J, Barber R, Mozos OM, Beßler D, Beetz M (2018) Reasoning systems for semantic navigation in mobile robots. In: IEEE international conference on intelligent robots and systems, pp 5654–5659
Cui G, Shuai W, Chen X (2021) Semantic task planning for service robots in open worlds. Future Internet 13(2):1–19
De Giacomo G, Vardi MY (2013) Linear temporal logic and linear dynamic logic on finite traces. In: Twenty-third international joint conference on artificial intelligence
De Giacomo G, Vardi M (2015) Synthesis for ltl and ldl on finite traces. In: Twenty-fourth international joint conference on artificial intelligence
De Raedt L, Kimmig A, Toivonen H (2007) Problog: a probabilistic prolog and its application in link discovery. In: International joint conference on artificial intelligence, Hyderabad, vol 7, pp 2462–2467
Diab M, Akbari A, Ud Din M, Rosell J (2019) Pmk-a knowledge processing framework for autonomous robotics perception and manipulation. Sensors 19(5):1166
Diekert V, Gastin P (2008) First-order definable languages. Log Autom 2:261–306
DiMaio S, Hanuschik M, Kreaden U (2011) The da vinci surgical system. In: Surgical robotics, Springer, pp 199–217
Dimopoulos Y, Nebel B, Koehler J (1997) Encoding planning problems in nonmonotonic logic programs. In: European conference on planning, Springer, pp 169–181
Dimopoulos Y, Gebser M, Lühne P, Romero J, Schaub T (2019) plasp 3: towards effective asp planning. Theory Pract Log Program 19(3):477–504
Dix J, Kuter U, Nau D (2003) Planning in answer set programming using ordered task decomposition. In: Annual conference on artificial intelligence, Springer, pp 490–504
Dodaro C, Galatà G, Grioni A, Maratea M, Mochi M, Porro I (2021) An asp-based solution to the chemotherapy treatment scheduling problem. Theory Pract Log Program 21(6):835–851
Dodaro C, Galatà G, Khan MK, Maratea M, Porro I (2022) Operating room (re) scheduling with bed management via asp. Theory Pract Log Program 22(2):229–253
Donzé A, Maler O (2010) Robust satisfaction of temporal logic over real-valued signals. In: International conference on formal modeling and analysis of timed systems, Springer, pp 92–106
Dornhege C, Eyerich P, Keller T, Trüg S, Brenner M, Nebel B (2009) Semantic attachments for domain-independent planning systems. In: Nineteenth international conference on automated planning and scheduling
Drabent W (1996) Completeness of sldnf-resolution for nonfloundering queries. J Log Program 27(2):89–106
Dureja R, Rozier KY (2018) More scalable ltl model checking via discovering design-space dependencies (\(d^{3}\)). In: International conference on tools and algorithms for the construction and analysis of systems, Springer, pp 309–327
Eiter T, Leone N, Mateis C, Pfeifer G, Scarcello F (1997) A deductive system for non-monotonic reasoning. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 363–374
Eiter T, Faber W, Leone N, Pfeifer G (2000) Declarative problem-solving using the DLV system. In: Logic-based artificial intelligence, Springer, pp 79–103
Eiter T, Germano S, Ianni G, Kaminski T, Redl C, Schüller P, Weinzierl A (2018) The DLVHEX system. KI-Künstliche Intelligenz 32(2–3):187–189
Emerson EA, Clarke EM (1982) Using branching time temporal logic to synthesize synchronization skeletons. Sci Comput Program 2(3):241–266
Erdem E, Patoglu V (2012) Applications of action languages in cognitive robotics. In: Correct reasoning, Springer, pp 229–246
Erdem E, Patoglu V (2018) Applications of asp in robotics. KI-Künstliche Intelligenz 32(2–3):143–149
Erdem E, Gelfond M, Leone N (2016) Applications of answer set programming. AI Mag 37(3):53–68
Erol K (1996) Hierarchical task network planning: formalization, analysis, and implementation. PhD thesis
Escudero-Rodrigo D, Alquezar R (2016) Study of the anchoring problem in generalist robots based on ROSPlan. Front Artif Intell Appl 288:45–50. https://doi.org/10.3233/978-1-61499-696-5-45
Fakhruldeen H, Maheshwari P, Lenz A, Dailami F, Pipe AG (2016) Human robot cooperation planner using plans embedded in objects. IFAC-PapersOnLine 49(21):668–674
Falkner A, Friedrich G, Schekotihin K, Taupe R, Teppan EC (2018) Industrial applications of answer set programming. KI-Künstliche Intelligenz 32(2–3):165–176
Farinelli A, Finzi A, Lukasiewicz T (2007) Team programming in golog under partial observability. In: International joint conference on artificial intelligence, pp 2097–2102
Fiazza MC, Fiorini P (2021) Design for interpretability: Meeting the certification challenge for surgical robots. In: 2021 IEEE international conference on intelligence and safety for robotics, IEEE, pp 264–267
Fikes RE, Nilsson NJ (1971) Strips: a new approach to the application of theorem proving to problem solving. Artif Intell 2(3–4):189–208
Finucane C, Jing G, Kress-Gazit H (2010) Ltlmop: experimenting with language, temporal logic and robot control. In: 2010 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 1988–1993
Fischer MJ, Ladner RE (1979) Propositional dynamic logic of regular programs. J Comput Syst Sci 18(2):194–211
Fox M, Long D (2003) Pddl2. 1: an extension to pddl for expressing temporal planning domains. J Artif Intell Res 20:61–124
Fox M, Long D, Magazzeni D (2017) Explainable planning. In: Proceedings of international joint conference on artificial intelligence-17 workshop on explainable planning
Frank J, Jónsson A (2003) Constraint-based attribute and interval planning. Constraints 8(4):339–364
Fratini S, Cesta A, De Benedictis R, Orlandini A, Rasconi R (2011) Apsi-based deliberation in goal oriented autonomous controllers. (ASTRA 2011), Noordwijk, the Netherlands, pp. 5B_1–7, 12–14
Frühwirth T (1998) Theory and practice of constraint handling rules. J Log Program 37(1–3):95–138
Gabaldon A (2004) Precondition control and the progression algorithm. In: International conference on automated planning and scheduling, pp 23–32
Geatti L, Gigante N, Montanari A (2021) Black: A fast, flexible and reliable ltl satisfiability checker. In: Proceedings of the 3rd Workshop on Artificial Intelligence and fOrmal VERification, Logic, Automata, and sYnthesis, CEUR-WS, vol 2987, pp 7–12
Gebser M, Obermeier P, Otto T, Schaub T, Sabuncu O, Nguyen V, Son TC (2018a) Experimenting with robotic intra-logistics domains. Theory Pract Log Program 18(3–4):502–519
Gebser M, Obermeier P, Schaub T, Ratsch-Heitmann M, Runge M (2018b) Routing driverless transport vehicles in car assembly with answer set programming. Theory Pract Log Program 18(3–4):520–534
Gebser M, Kaminski R, Kaufmann B, Schaub T (2019) Multi-shot asp solving with clingo. Theory Pract Log Program 19(1):27–82
Geffner H, Bonet B (2013) A concise introduction to models and methods for automated planning. Synth Lect Artif Intell Mach Learn 8(1):1–141
Gelfond M, Lifschitz V (1988) The stable model semantics for logic programming. Int Conf Log Program 88:1070–1080
Ghallab M, Nau D, Traverso P (2004) Automated planning: theory and practice. Elsevier, Amsterdam
Ghallab M, Nau D, Traverso P (2016) Automated planning and acting. Cambridge University Press, Cambridge
Gibaud B, Forestier G, Feldmann C, Ferrigno G, Gonçalves P, Haidegger T, Julliard C, Katić D, Kenngott H, Maier-Hein L et al (2018) Toward a standard ontology of surgical process models. Int J Comput Assist Radiol Surg 13(9):1397–1408
Gierse G, Niemueller T, Claßen J, Lakemeyer G (2016) Interruptible task execution with resumption in GOLOG. Front Artif Intell Appl (ECAI 2016) 285:1265–1273. https://doi.org/10.3233/978-1-61499-672-9-1265
Ginesi M, Meli D, Nakawala HC, Roberti A, Fiorini P (2019) A knowledge-based framework for task automation in surgery. In: 2019 19th international conference on advanced robotics, pp 37–42, https://doi.org/10.1109/ICAR46387.2019.8981619
Ginesi M, Meli D, Roberti A, Sansonetto N, Fiorini P (2020) Autonomous task planning and situation awareness in robotic surgery. In: IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 3144–3150
Goebel R, Chander A, Holzinger K, Lecue F, Akata Z, Stumpf S, Kieseberg P, Holzinger A (2018) Explainable ai: the new 42? In: International cross-domain Conference for machine learning and knowledge extraction, Springer, pp 295–303
González D, Pérez J, Milanés V, Nashashibi F (2015) A review of motion planning techniques for automated vehicles. IEEE Trans Intell Transp Syst 17(4):1135–1145
Gonçalves PJS, Torres PMB (2015) Knowledge representation applied to robotic orthopedic surgery. Robot Comput-Integr Manuf 33:90–99
Goodrich MA, Schultz AC (2008) Human-robot interaction: a survey. Now Publishers Inc, Delft
Gragera A, García AM, Fernández F (2019) A modelling and formalisation tool for use case design in social autonomous robotics. In: Iberian robotics conference, Springer, pp 656–667
Gundana D, Kress-Gazit H (2021) Event-based signal temporal logic synthesis for single and multi-robot tasks. IEEE Robot Autom Lett 6(2):3687–3694
Guo M, Johansson KH, Dimarogonas DV (2013) Motion and action planning under ltl specifications using navigation functions and action description language. In: IEEE international conference on intelligent robots and systems, pp 240–245
Guo M, Tumova J, Dimarogonas DV (2014) Cooperative decentralized multi-agent control under local ltl tasks and connectivity constraints. In: Proceedings of the IEEE conference on decision and control, vol 2015, pp 75–80
Guo M, Tumova J, Dimarogonas DV (2016) Communication-free multi-agent control under local temporal tasks and relative-distance constraints. IEEE Trans Autom Control 61(12):3948–3962
Gurzoni J J A, Cozman FG, Martins MF, Santos PE (2014) Logic-probabilistic model for event recognition in a robotic search and rescue scenario. In: Conference proceedings—IEEE international conference on systems, man and cybernetics, vol 2014, pp 1726–1731
Gutmann B, Thon I, Kimmig A, Bruynooghe M, De Raedt L (2011) The magic of logical inference in probabilistic programming. Theory Pract Log Program 11(4–5):663–680
Hao S, Huang Z, Wang L, Zhang R, Zhang X, Peng J, Yu W (2017) An optimal task decision method for a warehouse robot with multiple tasks based on linear temporal logic. In: 2017 IEEE international conference on systems, man, and cybernetics, SMC 2017, vol 2017, pp 1453–1458
Harman H, Simoens P (2020) Action graphs for proactive robot assistance in smart environments. J Ambient Intell Smart Environ 12(2):79–99
Harmo P, Taipalus T, Knuuttila J, Vallet J, Halme A (2005) Needs and solutions-home automation and service robots for the elderly and disabled. In: 2005 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 3201–3206
He K, Lahijanian M, Kavraki LE, Vardi MY (2015) Towards manipulation planning with temporal logic specifications. In: Proceedings—IEEE international conference on robotics and automation, vol 2015, pp 346–352
Helmert M (2002) Decidability and undecidability results for planning with numerical state variables. In: AIPS, pp 44–53
Helmert M, Röger G, Karpas E (2011) Fast downward stone soup: a baseline for building planner portfolios. In: International conference on automated planning and scheduling 2011 workshop on planning and learning, pp 28–35
Hoffmann J, Nebel B (2001) The ff planning system: fast plan generation through heuristic search. J Artif Intell Res 14:253–302
Ingrand F, Ghallab M (2017) Deliberation for autonomous robots: a survey. Artif Intell 247:10–44
Jain D, Mosenlechner L, Beetz M (2009) Equipping robot control programs with first-order probabilistic reasoning capabilities. In: 2009 IEEE international conference on robotics and automation, IEEE, pp 3626–3631
Janssen R, van de Molengraft R, Bruyninckx H, Steinbuch M (2016) Cloud based centralized task control for human domain multi-robot operations. Intell Serv Robot 9(1):63–77
Javia B, Cimiano P (2017) A logic programming approach to collaborative autonomous robotics, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 10505, LNAI
Ji J (2009) A cognitive architecture for a service robot: an answer set programming approach. In: Proceedings of the 25th international conference on logic programming, vol 5649, pp 532–533
Jiang Y, Zhang S, Khandelwal P, Stone P (2019) Task planning in robotics: an empirical comparison of pddl- and asp-based systems. Front Inf Technol Electron Eng 20(3):363–373
Jiménez S, De La Rosa T, Fernández S, Fernández F, Borrajo D (2012) A review of machine learning for automated planning. Knowl Eng Rev 27(4):433–467
Jing G, Finucane C, Raman V, Kress-Gazit H (2012) Correct high-level robot control from structured english. In: 2012 IEEE international conference on robotics and automation, IEEE, pp 3543–3544
Jing G, Tosun T, Yim M, Kress-Gazit H (2016) An end-to-end system for accomplishing tasks with modular robots. In: Robotics: science and systems, pp 1–5
Kadonoff MB (1987) Prolog-based world models for mobile robot navigation. In: Mobile robots II, international society for optics and photonics, vol 852, pp 305–310
Kamil F, Tang S, Khaksar W, Zulkifli N, Ahmad S (2015) A review on motion planning and obstacle avoidance approaches in dynamic environments. Adv Robot Autom 4(2):134–142
Karpas E, Magazzeni D (2020) Automated planning for robotics. Ann Rev Control Robot Auton Syst 3:417–439
Kaufmann B, Leone N, Perri S, Schaub T (2016) Grounding and solving in answer set programming. AI Mag 37(3):25–32
Kim S, Kwon G (2012) Simulation of collaborative multi-robots. In: International conference on hybrid information technology, Springer, pp 588–593
Kim S, Kwon G (2014) Multi-robot collaboration simulation using ltl synthesis. Information 17(5):1763–1769
Kirsch M, Mataré V, Ferrein A, Schiffer S (2020) Integrating golog++ and ros for practical and portable high-level control. In: ICAART 2020—proceedings of the 12th international conference on agents and artificial intelligence, vol 2, pp 692–699
Kloetzer M, Belta C (2006) Ltl planning for groups of robots. In: Proceedings of the 2006 IEEE international conference on networking, sensing and control, ICNSC’06, pp 578–583
Kolobov A (2012) Planning with markov decision processes: an AI perspective. Synth Lect Artif Intell Mach Learn 6(1):1–210
Kootbally Z (2016) Industrial robot capability models for agile manufacturing. Ind Robot: Int J 43:481–494
Koubâa A et al (2017) Robot operating system (ROS), vol 1. Springer, Cham
Kovacs DL (2011) Bnf definition of pddl 3.1. Unpublished manuscript from the IPC-2011 website
Kress-Gazit H, Fainekos GE, Pappas GJ (2009) Temporal-logic-based reactive mission and motion planning. IEEE Trans Robot 25(6):1370–1381
Kress-Gazit H, Wongpiromsarn T, Topcu U (2011) Correct, reactive, high-level robot control. IEEE Robot Autom Mag 18(3):65–74
Kumar A, Kala R (2016) Linear temporal logic-based mission planning. IJIMAI 3(7):32–41
Kumar V, Lin YJ (1988) A data-dependency-based intelligent backtracking scheme for prolog. J Log Program 5(2):165–181
Lacerda B, Lima PU (2012) Designing petri net supervisors from ltl specifications. Robot: Sci Syst 7:169–176
Lahijanian M, Almagor S, Fried D, Kavraki LE, Vardi MY (2015) This time the robot settles for a cost: a quantitative approach to temporal logic planning with partial satisfaction. In: Twenty-ninth AAAI conference on artificial intelligence
Laskey KB (2008) Mebn: a language for first-order Bayesian knowledge bases. Artif Intell 172(2–3):140–178
Lasota PA, Fong T, Shah JA et al (2017) A survey of methods for safe human-robot interaction. Now Publishers, Delft
Lee J, Wang Y (2016) Weighted rules under the stable model semantics. In: Fifteenth international conference on the principles of knowledge representation and reasoning
Lee J, Wang Y (2018) A probabilistic extension of action language \(\cal{BC} +\). Theory Pract Log Program 18(3–4):607–622
Lemaignan S, Ros R, Mösenlechner L, Alami R, Beetz M (2010) Oro, a knowledge management platform for cognitive architectures in robotics. In: 2010 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 3548–3553
Leonetti M, Iocchi L, Patrizi F (2012) Automatic generation and learning of finite-state controllers. In: International conference on artificial intelligence: methodology, systems, and applications, Springer, pp 135–144
Leonetti M, Iocchi L, Stone P (2016) A synthesis of automated planning and reinforcement learning for efficient, robust decision-making. Artif Intell 241:103–130
Levesque HJ, Reiter R, Lespérance Y, Lin F, Scherl RB (1997) Golog: a logic programming language for dynamic domains. J Log Program 31(1–3):59–83
Levinson J, Askeland J, Becker J, Dolson J, Held D, Kammel S, Kolter JZ, Langer D, Pink O, Pratt V, et al. (2011) Towards fully autonomous driving: systems and algorithms. In: 2011 IEEE intelligent vehicles symposium, IEEE, pp 163–168
Lifschitz V (1999) Answer set planning. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 373–374
Lifschitz V (2008) What is answer set programming? AAAI 8:1594–1597
Likhachev M, Thrun S, Gordon GJ (2005) Planning for Markov decision processes with sparse stochasticity. In: Advances in neural information processing systems, pp 785–792
Lin H (2014) Mission accomplished: an introduction to formal methods in mobile robot motion planning and control. Unmanned Syst 2(02):201–216
Lisca G, Nyga D, Bálint-Benczédi F, Langer H, Beetz M (2015) Towards robots conducting chemical experiments. In: 2015 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 5202–5208
Liu L, Peng J, Zhang R, Chen B, Yang Y, Zhang X (2017) Temporal logic task and motion planning of a smart robot-towards a smart substation environment. In: 2017 IEEE international conference on systems, man, and cybernetics, SMC 2017, vol 2017, pp 1110–1115
Lloyd JW (2012) Foundations of logic programming. Springer, Berlin
Lu D, Zhou Y, Wu F, Zhang Z, Chen X (2017) Integrating answer set programming with semantic dictionaries for robot task planning. In: International joint conference on artificial intelligence, pp 4361–4367
Lukasiewicz T (1998) Probabilistic logic programming. In: ECAI, pp 388–392
Lukasiewicz T (2001) Probabilistic logic programming with conditional constraints. ACM Trans Comput Log 2(3):289–339
Ma C, Fang F, Ma X (2016) Task planning of mobile robots in distributed service framework. In: Proceedings of the industrial electronics conference, pp 342–347
Mandel C, Huebner K, Vierhuff T (2005) Towards an autonomous wheelchair: cognitive aspects in service robotics. In: Proceedings of towards autonomous robotic systems, pp 165–172
Manthey N (2016) Towards next generation sequential and parallel sat solvers. KI-Künstliche Intelligenz 30(3–4):339–342
Marek VW, Truszczyński M (1999) Stable models and an alternative logic programming paradigm. In: The logic programming paradigm. Springer, Berlin, pp 375–398
Matarić MJ (2006) Situated robotics. In Encyclopedia of Cognitive Science, L. Nadel (Ed.). https://doi.org/10.1002/0470018860.s00074
Mataré V, Schiffer S, Ferrein A (2018) Golog++: an integrative system design. In: CEUR workshop proceedings, vol 2325, pp 29–35
Maurelli F, Saigol Z, Lane D (2014) Cognitive knowledge representation under uncertainty for autonomous underwater vehicles. In: Proceedings of IEEE ICRA’14 IEEE Hong Kong, workshop on persistent autonomy for underwater robotics
McCarthy J (1980) Circumscription’a form of non-monotonic reasoning. Artif Intell 13(1–2):27–39
McDermott D, Doyle J (1980) Non-monotonic logic i. Artif Intell 13(1–2):41–72
Meli D, Sridharan M, Fiorini P (2021a) Inductive learning of answer set programs for autonomous surgical task planning. Mach Learn 110(7):1739–1763
Meli D, Tagliabue E, Dall’Alba D, Fiorini P (2021b) Autonomous tissue retraction with a biomechanically informed logic based framework. In: International symposium on medical robotics, IEEE, pp 1–7
Miranda DSS, de Souza LE, Bastos GS (2018) A rosplan-based multi-robot navigation system. In: 2018 Latin American robotic symposium, 2018 Brazilian symposium on robotics and 2018 workshop on robotics in education, IEEE, pp 248–253
Moldovan B, De Raedt L (2014) Learning relational affordance models for two-arm robots. In: 2014 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 2916–2922
Moldovan B, Moreno P, Van Otterlo M, Santos-Victor J, De Raedt L (2012) Learning relational affordance models for robots in multi-object manipulation tasks. In: 2012 IEEE international conference on robotics and automation, IEEE, pp 4373–4378
Moldovan B, Antanas L, Hoffmann M (2013) Opening doors: an initial SRL approach, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 7842, LNAI
Moldovan B, Moreno P, Nitti D, Santos-Victor J, De Raedt L (2018) Relational affordances for multiple-object manipulation. Auton Robots 42(1):19–44
Moon J, Lee B (2019) Pddl planning with natural language-based scene understanding for uav-ugv cooperation. Appl Sci 9(18):3789
Muñoz P, R-Moreno MD, Barrero DF, Ropero F (2019) Mobar: a hierarchical action-oriented autonomous control architecture. J Intell Robot Syst: Theory Appl 94(3—-4):745–760
Muñoz-Hernandez S, Wiguna WS (2007) Fuzzy cognitive layer in RoboCupSoccer, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 4529, LNAI
Nagy TD, Haidegger TP (2021) Towards standard approaches for the evaluation of autonomous surgical subtask execution. In: 2021 IEEE 25th international conference on intelligent engineering systems, IEEE, pp 67–74
Nagy DÁ, Nagy TD, Elek R, Rudas IJ, Haidegger T (2018) Ontology-based surgical subtask automation, automating blunt dissection. J Med Robot Res 3(03n04):1841005
Nakawala H, Goncalves PJ, Fiorini P, Ferringo G, De Momi E (2018) Approaches for action sequence representation in robotics: a review. In: 2018 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 5666–5671
Nakawala H, Bianchi R, Pescatori LE, De Cobelli O, Ferrigno G, De Momi E (2019) Deep-onto network for surgical workflow and context recognition. Int J Comput Assist Radiol Surg 14(4):685–696
Narboni GA (1999) From prolog iii to prolog iv: the logic of constraint programming revisited. Constraints 4(4):313–335
Nau D, Cao Y, Lotem A, Munoz-Avila H (1999) Shop: simple hierarchical ordered planner. In: Proceedings of the 16th international joint conference on artificial intelligence, vol 2, pp 968–973
Nevlyudov I, Tsymbal O, Milyutina S (2008) The logical model of product assembly technological process design. In: TCSET 2008—modern problems of radio engineering, telecommunications and computer science—proceedings of the international conference, pp 500–501
Ng R, Subrahmanian VS (1992) Probabilistic logic programming. Inf Comput 101(2):150–201
Nitti D, Belle V, De Raedt L (2015) Planning in discrete and continuous Markov decision processes by probabilistic programming. In: Joint European conference on machine learning and knowledge discovery in databases, Springer, pp 327–342
Nyga D, Beetz M (2012) Everything robots always wanted to know about housework (but were afraid to ask). In: 2012 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 243–250
Nyga D, Roy S, Paul R, Park D, Pomarlan M, Beetz M, Roy N (2018) Grounding robot plans from natural language instructions with incomplete world knowledge. In: Conference on robot learning, pp 714–723
Opfer S, Jakob S, Geihs K (2018) Reasoning for autonomous agents in dynamic domains: towards automatic satisfaction of the module property, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 10839, LNAI
Opfer S, Jakob S, Jahl A, Geihs K (2019) ALICA 2.0—domain-independent teamwork, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 11793, LNAI
Papadimitriou G, Saigol Z, Lane DM (2015) Enabling fault recovery and adaptation in mine-countermeasures missions using ontologies. In: MTS/IEEE OCEANS 2015—Genova: discovering sustainable ocean energy for a new world
Pereira LM, Monteiro L, Cunha J, Aparicio JN (1986) Delta prolog: a distributed backtracking extension with events. In: International conference on logic programming, Springer, pp 69–83
Pianpak P, Son TC, Toups ZO, Yeoh W (2019) A distributed solver for multi-agent path finding problems. In: ACM international conference proceeding series
Pineda LA, Salinas L, Meza IV, Rascon C, Fuentes G (2013) Sit log: a programming language for service robot task. Int J Adv Robot Syst 10:1–12
Pnueli A (1977) The temporal logic of programs. In: 18th annual symposium on foundations of computer science, IEEE, pp 46–57
Poli R, Healy M, Kameas A (2010) Theory and applications of ontology: computer applications. Springer, Dordrecht
Raja P, Pugazhenthi S (2012) Optimal path planning of mobile robots: a review. Int J Phys Sci 7(9):1314–1320
Rajan K, Py F, Barreiro J (2013) Towards deliberative control in marine robotics. In: Marine robot autonomy. Springer, New York, pp 91–175
Raman V, Kress-Gazit H (2012) Explaining impossible high-level robot behaviors. IEEE Trans Robot 29(1):94–104
Richardson M, Domingos P (2006) Markov logic networks. Mach Learn 62(1–2):107–136
Richter S, Westphal M, Helmert M (2011) Lama 2008 and 2011. In: International planning competition, pp 117–124
Rintanen J et al (2007) Complexity of concurrent temporal planning. Int Conf Autom Plan Sched 7:280–287
Rutten JJ, Kwiatkowska M, Norman G, Parker D (2004) Mathematical techniques for analyzing concurrent and probabilistic systems. 23, American Mathematical Soc
Sanelli V, Cashmore M, Magazzeni D, Iocchi L (2017) Short-term human-robot interaction through conditional planning and execution. In: Twenty-seventh international conference on automated planning and scheduling
Sarid S, Xu B, Kress-Gazit H (2013) Guaranteeing high-level behaviors while exploring partially known maps. Robotics. MIT Press, Cambridge, pp 377–384
Sato T (1995) A statistical learning method for logic programs with distribution semantics. In: Proceedings of the 12th international conference on logic programming
Schiffer S, Ferrein A, Lakemeyer G (2012) Caesar: an intelligent domestic service robot. Intell Serv Robot 5(4):259–273
Schillinger P, Burger M, Dimarogonas DV (2017) Multi-objective search for optimal multi-robot planning with finite ltl specifications and resource constraints. In: Proceedings—IEEE international conference on robotics and automation, pp 768–774
Schmuck A, Majumdar R, Leva A (2017) Dynamic hierarchical reactive controller synthesis. Discr Event Dyn Syst: Theory Appl 27(2):261–299
Semwal T, Bode M, Singh V, Jha SS, Nair SB (2015) Tartarus: a multi-agent platform for integrating cyber-physical systems and robots. In: ACM international conference proceeding series, vol 2
Shivashankar V, Alford R, Kuter U, Nau D (2013) The godel planning system: a more perfect union of domain-independent and hierarchical planning. In: Twenty-third international joint conference on artificial intelligence
Smullyan RM (1995) First-order logic. Courier Corporation, Chelmsford 43. https://doi.org/10.1007/978-3-642-86718-7
Son TC, Baral C, Tran N, Mcilraith S (2006) Domain-dependent knowledge in answer set planning. ACM Trans Comput Log 7(4):613–657
Soper NJ, Fried GM (2008) The fundamentals of laparoscopic surgery: its time has come. Bull Am Coll Surg 93(9):30–32
Sorensson N, Een N (2005) Minisat v1. 13-a sat solver with conflict-clause minimization. SAT 2005(53):1–2
Sridharan M, Gelfond M, Zhang S, Wyatt J (2019) Reba: a refinement-based architecture for knowledge representation and reasoning in robotics. J Artif Intell Res 65:87–180
Syrjänen T, Niemelä I (2001) The smodels system. In: International conference on logic programming and nonmonotonic reasoning, Springer, pp 434–438
Tagliabue E, Meli D, Dall’Alba D, Fiorini P (2022) Deliberation in autonomous robotic surgery: a framework for handling anatomical uncertainty. In: IEEE international conference on robotics and automation
Tan ZX, Brawer J, Scassellati B (2019) That’s mine! learning ownership relations and norms for robots. In: Proceedings of the AAAI conference on artificial intelligence, vol 33, pp 8058–8065
Teichteil-Königsbuch F, Kuter U, Infantes G (2010) Incremental plan aggregation for generating policies in mdps. In: Proceedings of the 9th international conference on autonomous agents and multiagent systems: volume 1-volume 1, International Foundation for Autonomous Agents and Multiagent Systems, pp 1231–1238
Tenorth M, Beetz M (2013) Knowrob: a knowledge processing infrastructure for cognition-enabled robots. Int J Robot Res 32(5):566–590
Tenorth M, Beetz M (2017) Representations for robot knowledge in the knowrob framework. Artif Intell 247:151–169
Thielscher M (2005) Handling implication and universal quantification constraints in FLUX, lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), vol 3709, LNCS
Trakhtenbrot BA (1962) Finite automata and monadic second order logic. Sib Math J 3:101–131
Tu PH, Son TC, Baral C (2007) Reasoning and planning with sensing actions, incomplete information, and static causal laws using answer set programming. Theory Pract Log Program 7(4):377–450
Tumova J, Marzinotto A, Dimarogonas DV, Kragic D (2014) Maximally satisfying ltl action planning. In: IEEE international conference on intelligent robots and systems, pp 1503–1510
Tzafestas S, Plouzennec A (1989) A prolog-based expert system prototype for robot task planning. IFAC Proc Vol 22(6):225–230
Van Emden MH, Kowalski RA (1976) The semantics of predicate logic as a programming language. J ACM 23(4):733–742
Vidal T (1999) Handling contingency in temporal constraint networks: from consistency to controllabilities. J Exp Theor Artif Intell 11(1):23–45
Vidal T, Fargier H (1997) Contingent durations in temporal csps: from consistency to controllabilities. In: Proceedings of TIME’97: 4th international workshop on temporal representation and reasoning, IEEE, pp 78–85
Vidal T, Ghallab M (1996) Dealing with uncertain durations in temporal constraint networks dedicated to planning’. In: ECAI, PITMAN, pp 48–54
Vitucci N, Gini G (2019) Reasoning on objects and grasping using description logics. Adv Robot 33(13):616–635
Waibel M, Beetz M, Civera J, d’Andrea R, Elfring J, Galvez-Lopez D, Häussermann K, Janssen R, Montiel J, Perzylo A et al (2011) Roboearth. IEEE Robot Autom Mag 18(2):69–82
Wang X, Zhao L, Zeng C, Qian J, Gu T (2009) An asp based solution to mechanical assembly sequence planning. In: 3rd international conference on genetic and evolutionary computing, WGEC 2009, pp 205–208
Wielemaker J, Schrijvers T, Triska M, Lager T (2012) Swi-prolog. Theory Pract Log Program 12(1–2):67–96
Wilke T (1999) Classifying discrete temporal properties. In: Annual symposium on theoretical aspects of computer science, Springer, pp 32–46
Wilkins DE (1984) Domain-independent planning representation and plan generation. Artif Intell 22(3):269–301
Wong KW, Kress-Gazit H (2016) Need-based coordination for decentralized high-level robot control. In: IEEE international conference on intelligent robots and systems, vol 2016, pp 2209–2216
Wongpiromsarn T, Topcu U, Murray RM (2010) Receding horizon control for temporal logic specifications. In: Proceedings of the 13th ACM international conference on hybrid systems: computation and control, pp 101–110
Wongpiromsarn T, Topcu U, Ozay N, Xu H, Murray RM (2011a) Tulip: a software toolbox for receding horizon temporal logic planning. In: Proceedings of the 14th international conference on hybrid systems: computation and control, ACM, pp 313–314
Wongpiromsarn T, Topcu U, Ozay N, Xu H, Murray RM (2011b) Tulip: a software toolbox for receding horizon temporal logic planning. In: HSCC’11—proceedings of the 2011 ACM/SIGBED hybrid systems: computation and control, pp 313–314
Wu W, Liu Y (2008) Office robot controlling based on fluent calculus and flux. Comput Eng Des (11):2871–2874
Wurm KM, Dornhege C, Eyerich P, Stachniss C, Nebel B, Burgard W (2010) Coordinated exploration with marsupial teams of robots using temporal symbolic planning. In: 2010 IEEE/RSJ international conference on intelligent robots and systems, IEEE, pp 5014–5019
Wurm KM, Dornhege C, Nebel B, Burgard W, Stachniss C (2013) Coordinating heterogeneous teams of robots using temporal symbolic planning. Auton Robots 34(4):277–294
Xu S, Wu G, Zhao Q, Tu D, Zheng H (2014) Human-machine-environment cyber-physical system and hierarchical task planning to support independent living. In: Proceedings—2014 IEEE international conference on bioinformatics and biomedicine, IEEE BIBM 2014, pp 568–573
Xu N, Li J, Niu Y, Shen L (2016) An ltl-based motion and action dynamic planning method for autonomous robot. IFAC-PapersOnLine 49(5):91–96
Yazdani F, Blumenthal S, Huebel N, Bozcuoǧlu AK, Beetz M, Bruyninckx H (2019) Query-based integration of heterogeneous knowledge bases for search and rescue tasks. Robot Auton Syst 117:80–91
Younes HL, Littman ML (2004) Ppddl1. 0: an extension to pddl for expressing planning domains with probabilistic effects. Techn Rep CMU-CS-04-162 2:99
Zacharaki A, Kostavelis I, Gasteratos A, Dokas I (2020) Safety bounds in human robot interaction: a survey. Saf Sci 127:104667
Zhang W, Hong S (2019) A linear reduction model for parallel prolog system. In: 2019 IEEE 4th international conference on cloud computing and big data analysis, IEEE, pp 650–654
Zhang X, Zhu Y, Lin H (2016) Performance guaranteed human-robot collaboration through correct-by-design. In: Proceedings of the American control conference, vol 2016, pp 6183–6188
Zhang Y, Sreedharan S, Kulkarni A, Chakraborti T, Zhuo HH, Kambhampati S (2017) Plan explicability and predictability for robot task planning. In: 2017 IEEE international conference on robotics and automation, IEEE, pp 1313–1320
Zhao Y, Topcu U, Sentis L (2016) High-level planner synthesis for whole-body locomotion in unstructured environments. In: 2016 IEEE 55th conference on decision and control, IEEE, pp 6557–6564
Funding
Open access funding provided by Università degli Studi di Verona within the CRUI-CARE Agreement. This work was supported in part by the European Union Grant ERC-ADG N. 742671, ARS (Autonomous Robotic Surgery) project. URL: https://www.ars-project.eu/?lang=it.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors certify that they have no affiliations with or involvement in any organization or entity with any financial or non-financial interest in the subject matter or materials discussed in this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Meli, D., Nakawala, H. & Fiorini, P. Logic programming for deliberative robotic task planning. Artif Intell Rev 56, 9011–9049 (2023). https://doi.org/10.1007/s10462-022-10389-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10462-022-10389-w