
Abstract
Droughts pose a significant challenge to farmers, insurers as well as governments around the world and the situation is expected to worsen in the future due to climate change. We present a large scale drought risk assessment approach that can be used for current and future risk management purposes. Our suggested methodology is a combination of a large scale agricultural computational modelling -, extreme value-, as well as copula approach to upscale local crop yield risks to the national scale. We show that combining regional probabilistic estimates will significantly underestimate losses if the dependencies between regions during drought events are not taken explicitly into account. Among the many ways to use these results it is shown how it enables the assessment of current and future costs of subsidized drought insurance in Austria.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The assessment and management of extreme risks, especially against natural hazards, is a very active research area today. This is due to the fact of ever rising disaster losses as well as respective climate change considerations (IPCC 2012; GFDRR 2016). For example, overall disaster losses in 2017 were at astonishing 330 billion US$, almost double the ten-year average of 170 billion US$. Additionally, losses from weather-related natural catastrophes set a new record in 2017, with insured losses almost three times higher than the average of US$ 49 billion (Munich Re 2018). The observed trend is predominantly a result of more people and assets being exposed to natural hazards (Meyer et al. 2013). However, there are strong indications that climate change will play an important role in future increases of such losses (IPCC 2012). As a consequence, the need to actively assess and manage current and future extreme risks is increasingly prominent in the global debate driven by various risk bearers, including insurers, re-insurers, the capital market as well as governments (World Economic Forum 2014; UNISDR 2015). For all these reasons, many modeling approaches have been developed in recent years to assess and ultimately manage catastrophe risk (usually called catastrophe modelling approaches, see Grossi and Kunreuther 2006 for an introduction).
However, few studies so far (e.g. Jongman et al. 2014) have explicitly incorporated the risk dependent nature of hazard events into their assessment. Simply put, due to atmospheric conditions some hazards, including floods and droughts, are not always just local spatially limited phenomena but can affect large regions at once. The flood events in 2002 as well as the heat waves in 2003 in Europe can serve as prominent examples here. Consequently, neglection of (tail) dependencies may lead to a serious underestimation of risk, including the underestimation of economic consequences, as well as wrong selection of management options (as they will likely fail when they are most needed, see Hochrainer-Stigler et al. 2017). As suggested in this article, copula approaches are a promising way forward to take the special nature of extremes, namely tail dependency, explicitly into account, either for extreme risk assessment (Timonina et al. 2015), scenario generation (Kaut and Wallace 2011) or systemic risk evaluation (Pflug and Pichler 2018). While in financial research domains copula approaches are now well established (Kovacevic and Pflug 2015) within the natural hazard domain the copula approach is mostly applied to flood events (Jongman et al. 2014) and no methodology exists yet for the assessment of large scale drought events. This is problematic as droughts pose a significant challenge to farmers as well as governments (UNISDR 2013) around the world and the situtation is expected to worsen due to climate change in the future (IPCC 2012; Li et al. 2015).
One reason for the current lack of such modelling approaches is the fact that the detection and modelling of extremes including climate change is extremely complicated and current methods applied are focusing on average changes on very localized scales that do not incorporate regional dependencies (Zhao and Dai 2016). However, averages do not give any indications of possible extreme risks that could realize and are less usefull for risk management considerations, including economic evaluation as well as applying optimization techniques to reduce extreme risks (Pflug and Römisch 2007). We overcome this shortage and present an advanced computational modelling approach which, for the first time, is able to estimate drought risk on the country level and can account for current as well as future climate conditions. Our suggested methodology is built around four major challenges which need to be addressed for a probabilistic assessment of drought risk on the country scale including non-stationarity aspects which were, up till now, not tackled simultaneously. Firstly, extreme events such as droughts are rare and therefore difficult to be empirically estimated in a probabilistic way (Reiss and Thomas 2007). Secondly, even if enough past data is available changes of extreme risks often need to be considered from a non-stationarity point of view (IPCC 2012). For example, climate change impacts cannot be included via past observations in a risk based approach for future events. Thirdly, as already indicated, drought impacts are usually happening across regions and there need to be regional dependencies assumed to avoid underestimation of risk, e.g. due to atmospheric conditions droughts are usually not local phenomena and therefore not spatially limited but affect large regions at once (Jongman et al. 2014). Fourthly, even if probabilistic estimates on local levels are available, current approaches upscale these losses to larger geographical areas by focusing on averages which do not give any information on extreme risks and therefore are of limited value for risk management approaches (Hochrainer et al. 2013; Kassie et al. 2015).
Our suggested methodology is a combination of a large scale agricultural computational modelling-, extreme value theory- as well as copula- approach. We will show that combining regional probabilistic estimates will underestimate the full losses if the dependencies between regions during drought events are not taken explicitly into account. The model estimates can be used for risk management purposes, e.g. to identify monetary losses and insurance premiums. Even more important, the methodology can provide country estimates of future drought risks under different climate scenarios. This is policy relevant as the assessed risks can be used to determine the increasing burden in loss sharing mechanisms (including insurance subsidies) for risk-bearers given different climate conditions in the future. Consequently, the risk estimates can indicate if current risk management options would be also feasible in the future or if limits of adaptation with such kind of instruments are reached (Adger et al. 2009). Consequently, our approach is advantageous not only methodology wise but also in relation to policy guidance on how drought risk could be dealt with on various levels over time. We employ our approach to the case of Austria which will be heavily affected by climate change, however, the approach can be applied for all countries in the world given some modest data requirements are met.
Our paper is organized as follows. We present the methodology in Sect. 2 and afterwards in Sect. 3 apply the method to the Austrian case study, including a discussion on possible applications of this approach. Finally Sect. 4 gives an outlook to the future. The focus in the article will be on the computational and methodology aspects as well as main results and we refer for the details to the various Online Resources provided electronically.
2 Methodology
One commonly distinguishes between four different drought types including meteorological drought, hydrological drought, agricultural drought and socioeconomic drought (see UNISDR 2009). Our focus is on agricultural drought (hereinafter, referred to simply as drought), which has the potential, due to dried soils, erosion and low rainfalls, to cause large amount of losses to different risk bearers, e.g. farmers, insurance providers and the government. The main goal of our methodology is to derive at a probabilistic drought loss distribution (in monetary terms) on the country scale. By having such a distribution various economic modelling approaches (for an introduction see Rose 2004) and optimization techniques can be applied for the management of extreme risk (Pflug and Römisch 2007). The four challenges already identified before will be tackled in the following way. The first challenge of estimating extremes is solved using extreme value theory and corresponding statistical approaches (Embrechts et al. 2013) to estimate the fat tails of underlying distributions (or in other words get non-biased estimators of extreme events). The methods and tools used in extreme value theory are now well established (see Reiss and Thomas 2007). We tackle challenge two, i.e. accounting for non-stationarity, via a bio-physical crop growth model (EPIC) to simulate current and future crop yields under non-stationarity climate change effects (Balkovič et al. 2013, 2018). The third and fourth challenge are tackled simultaneously via a copula approach which can take tail dependencies explicitly into account and therefore enable us to derive at risk estimates on the country level. The overall methodology is shown in Fig. 1.

Overall methodological steps for the assessment of drought risk on the country scale
In more detail, in the first step, crop yield distributions are fitted based on the simulation results of the EPIC model for today and future scenarios. Given the marginal crop distributions on the local scale, in step 2 we use a proxy of the dependency structure during drought events between regions, namely the Standardized Precipitation Evapotranspiration Index, for modelling drought events. Finally, in step 3 we use a copula and R-Vine approach to upscale the crop distributions to the country level, hence taking dependencies explicitly into account. We start with the biophysical crop model employed.
2.1 The biophysical crop model: EPIC
Multiple biophysical crop models are available to estimate crop growth and yield response to changing climate and weather variability on different scales, using different biophysical approaches (some of the models are summarized in Table 1 in Online Resource 1). These models differ in representation of soil and crop processes as well as management interventions. Generally speaking, the models are either (i) site-based crop models (e.g., EPIC, DSSAT), (ii) agro-ecosystem models (e.g., LPJ-GUESS, LPJmL, PEGASUS), and (iii) agro-ecological zone models (GAEZ-IMAGE)—see Rosenzweig et al. (2014). Site-based models simulate dynamic interactions among crops, soil, atmosphere and management at the field scale, while agro-ecosystem models primarily simulate carbon and nitrogen dynamics, surface energy balance, and soil water balance. The agro-ecological zone models were developed to assess agricultural potential at larger scales.
Within our approach we use the Environmental Policy Integrated Climate (EPIC, Izaurralde et al. 2006, 2012; Williams 1995) bio-physical crop model as it is able to produce crop yield time-series for today and future scenarios which can be used to estimate crop yield distributions, essentially needed for upscaling the crop yields to the country level without losing any risk information. Additionally, EPIC is one of the most widely used crop models for studies on climate change impacts in the agricultural sector (White et al. 2011).
EPIC contains routines simulating crop growth and yield formation, hydrological, nutrient and carbon cycling, soil temperature and moisture, soil erosion, tillage, fertilization, irrigation and plant environment control. The potential crop growth is calculated daily from intercepted photosynthetically active radiation using the energy-to-biomass conversion approach modified for vapour pressure deficit and atmospheric CO2 concentration effect (Monteith 1977; Stockle et al. 1992). The potential daily biomass increase is adjusted to an actual biomass increase through stress caused by—inter alia—water and nutrient deficiency or when the temperature goes beyond the optimal range. Plant phenological development, including leaf growth, plant nutrients concentration, partitioning of biomass among roots and shoots as well as yield formation are defined by heat units accumulated over the crop’s growing season. In EPIC, dynamic soil processes ranging from soil hydrology, including runoff, water storage, subsurface flow, evapotranspiration, and irrigation, to soil organic matter and bulk density dynamics are simulated (Izaurralde et al. 2012, 2006; Williams 1995), thus accounting for harmful effects of soil water deficit. Crop yields are calculated from the actual above-ground biomass at the time of harvest as defined by the potential and water-constrained harvest index. EPIC’s processes relevant for assessment of climate change impact on crops were summarized in the supplementary information of Folberth et al. (2016). More details can also be found in the Online Resource 1.
The gridded pan-European EPIC model that was used in this analysis for Austria is explained in Balkovič et al. (2013, 2018). The model was constructed by coupling the field-scale model EPIC v. 0810 described above with large-scale data on climate, environmental conditions and crop management practices in Europe. The final results from the model used in our approach are annual crop yields simulated with a 1 × 1-km spatial resolution. More details are presented in the Online Resource 4.
2.2 Estimation of extremes
Given the availability of crop yields, either via past data or simulation, crop risk assessments in the agricultural literature vary from non-parametric to parametric approaches. Parametric approaches for modelling yields are usually preferred, however, this involves the selection of various continuous distributions and estimation of their parameters by, for example, applying maximum likelihood (ML) estimation techniques. As in our approach one has to model several hundreds of different gridded simulation units covering an area (from now on called SimUs, see Balkovič et al. 2013) one additionally needs to employ an automatic computational accessible selection procedure from potential families of distributions. In order to find a proper (in terms of best fit) marginal distribution that could represent crop yield risk, we consider several families (Generalized Extreme Value distributions, Beta distribution, Gamma distribution, Normal, Inverse Gaussian to name but a few, for a full list see Online Resource 3).
After parameters for each SimU have been estimated using the ML method for each of the probability distribution functions under consideration, the most appropriate probability density function needs to be obtained which is usually based on some goodness-of-fit (GOF) tests. In our case, GOF measures are used to rank the performance of each distribution. There are three classical GOF statistics, such as Kolmogorov–Smirnov (KS), Anderson–Darling (AD) and χ2 tests, which can be used to measure how well the distribution fits the data. Moreover, there are the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC) available which are also appropriate for model selection. These information criteria are based on the likelihood function (i.e. they measure the deviance of the model fit) and have different penalty functions for overfitting. Both of them can be used in order to assess the model fit and to compare models. They are often more appropriate than the previous goodness-of-fit statistics described above which have several limitations. For example, all three test statistics described above do not penalize the distributions which have higher number of parameters. To overcome the limitations of GOF statistics which are used in the pre-selection process, the AIC and BIC information criteria are finally used for selection, given the significance of the other GOF tests.
2.3 The copula model I: a proxy for spatial and crop yield dependency
To detect dependencies between different SimUs (simulation units, usually the 1 × 1 area or grid cell) a proxy is needed due to two reasons. First, not enough empirical data on crop yields is available on this granular scale and second, the simulations from EPIC in each SimU are independent from each other (hence, cannot be used as a proxy for dependency itself). Several indices are suggested in the literature for droughts and we refer to the Online Resource 2 for a selection of the most often ones used in the literature. We selected a very much accepted one, namely the Standard Precipitation Evapotranspiration Index (SPEI, Vicente-Serrano et al. 2010) to estimate the vulnerability of crop yields due to drought events (van Oijen et al. 2013). The SPEI values were calculated for every SimU and climate scenario with monthly time steps. The dry years are identified as years with the mean SPEI (calculated from Corn sowing to maturity) of less than − 1, while normal years are with SPEI ≥ − 1. The SPEI index within a copula model can be used to determine the spatial dependency of drought events and reproduce past drought events well (see Online Resource 2). However, one additionally needs to test if low SPEI values actually lead to low crop yields. Due to several reasons, e.g. irrigation or soil conditions, not all SimUs necessarily need to show dependency in crop yields during drought events as determined by the SPEI index. For our further analysis, we therefore only selected those SimUs as dependent which showed a significant dependency between low crop yields during droughts in the past (in terms of low average yields during low SPEI events). We created additional indices, to guarantee the selection of SimUs, which are interdependent in both the SPEI index and corresponding crop yields. In more detail, SimUs are considered to be interdependent in both SPEI and crop yields, if the average crop yield during a long-term dry climate is lower than the expected value. Given the availability of a proxy for spatial and crop yield dependency it is possible to create R-Vines which essentially model the dependency structure (the copula itself measures the dependency strength) which is described next.
2.4 The copula model II: selecting copulas and the copula structure
The necessity to incorporate regional interdependencies for the correct risk estimation and therefore appropriate risk management arises naturally from the hazard phenomena which are essentially not local, and leads to the use of copula-based approaches (Nelsen 2006). Copula-based approaches are applied in different fields from technology to finance (Choros-Tomczyk et al. 2013; Choros-Tomczyk et al. 2014; Jaworski et al. 2012; Jaworski et al. 2009). However, only recently they were suggested as a possible way to derive natural disaster risk estimates at larger scales (Hochrainer-Stigler et al. 2013; Timonina et al. 2015; Borgomeo et al. 2015). In mathematical terms for agricultural applications, the total crop yield (e.g. in tons of dry matter) after a drought event is the sum of crop yields in the individual regions (SimUs) that were affected by the drought:
where each \( Y_{i} , \forall i = 1, \ldots ,N, \) represents the crop yield in a particular region SimU = \( i \) and where \( y_{i} \) is the crop yield per hectare in region \( i \) with \( w_{i} > 0 \) being the area of \( i \) in hectares (which is usually provided in the form of land use maps). The main task is to calculate the joint probability crop yield distribution.
for an entire area (i.e. all N regions. However, for dependent risks it is not enough to only know the marginal probability distributions \( F_{i} \left( x \right) = P\left( {Y_{i} \le x} \right) = P\left( {y_{i} \le \frac{x}{{w_{i} }}} \right) \) of \( Y_{i} , \forall i = 1, \ldots ,N, \) (or, equivalently, of \( y_{i} ), \) but one needs also the information on dependency between regions given an extreme event in one region occurs. The copula concept is extremely useful in such cases. A copula is defined as:
Definition
(Nelsen 2006): Copulas are distribution functions on \( \left[ {0, 1} \right]^{d} , d \ge 2 \), with standard uniform univariate margins.
If interdependencies between regions can be expected (Timonina et al. 2015) one can use a copula \( C\left( {x_{1} , \ldots ,x_{N} } \right) \) model so that
where \( F_{i} \left( x \right) = P\left( {Y_{i} \le x} \right) \) are marginal distributions. In other words, the total crop yield distribution \( F \) can be calculated by the coupling of marginal loss distributions of \( Y_{1} , \ldots ,Y_{N} \) over the copula \( C \). We refer for additional details to the Online Resource 3. It is important to allow for different dependency structures via different copula types and we included a range of families from the Archimedean type but also allow for independencies as well. For example, the Clayton copula has a heavy left tail concentration, and consequently can be used to describe the dependency between low crop yields across regions. For \( \theta \in \left( {0, \infty } \right)\) the Clayton copula function is given by:
where \( u \) and \( v \) are uniformly distributed random variables on the interval (0, 1). Another important copula is the Gumbel copula which is an extreme value copula, especially valuable as one can construct multivariate extreme value distributions. For \( \theta \ge 1 \) the following dependency structure is assumed by the Gumbel copula:
The Gumbel copula has the property of upper tail dependence. A flipped copula means that the copula is rotated by 180 degrees (Jongman et al. 2014). Flipping the Gumbel copula therefore produces a copula which is showing left tail dependencies. In other words, in case of drought risks and yield distributions, the Flipped Gumbel copula would emphasize the non-linear dependency among low crop yields (i.e. drought). For more information on the copula types used we refer to Online Resource 3.
Given the strength of the dependency being estimated for different copula types one additionally needs a copula structure in order to simulate the dependency on arbitrary dimensions. We suggest using the concept of vine copulas that allows incorporating dependencies not only between all pairs of regions, but also in between all sequences of more than two regions. Vine copulas are a well-known tool to obtain joint distributions for \( N \) interdependent variables (Bedford et al. 2002; Kurowicka and Cooke 2006; Kurowicka and Joe 2010). Vine copulas combine (conditional) bivariate copulas of arbitrary types into an \( N \)-dimensional copula in the following way:
where \( f_{i} \left( {x_{i} } \right) \) are marginal crop yield densities for each SimU = \( i \), \( \forall i = 1, \ldots ,N \). For example, in the case of 3 regions, one can first construct a joint distribution for regions 1 and 3 as well as regions 2 and 3 using bivariate copulas \( C_{1|3} \) and \( C_{2|3} \) and afterwards combine these two joint distributions with the conditional bivariate copula \( C_{12|3} \). This can be generalized to arbitrary dimensions (see Online Resource 3 for more details). Numerically, the use of vine copulas can be inefficient for high dimensional cases, as the number of possible pair-copula constructions grows rapidly, i.e. when the number of dimensions gets higher. In order to organize all the decompositions, Bedford and Cooke (2002) introduced graphical models denoted regular vines (also referred to as R-vines). In general, a vine is a nested set of connected trees where the edges of one tree are the nodes for the next tree (see Online Resource 3 more information). The concept of R-vine copulas for \( N \) variables requires the construction of a sequence of \( N - 1 \) trees. Each tree is constructed in an iterative manner so that
- (a)
edges in tree \( j \) become nodes in tree \( j + 1 \);
- (b)
two nodes in tree \( j + 1 \) are joined by an edge, if the corresponding edges in tree \( j \) share a node.
The use of R-vine copulas is possible, if the initial dependence structure satisfies the regular vine condition, meaning that there is a unique sequence of edges between each two nodes in the interdependence graph (see Online Resource 3) and we used this approach for upscaling the drought risks as discussed next.
2.5 Upscaling drought risks
After the establishment of the necessary ingredients the following algorithm below summarizes the upscaling of the crop yields to the country level:

In step 1 we first distinguish between two sets of SimUs, one set includes all SimUs which show dependency between crop yield and SPEI and the other set which shows no dependency between them during droughts. The transformation in step 2 is needed as the marginal distributions of the SPEI are unknown and consequently the copula density must be estimated based on pseudo samples. Only the set which shows a relationship between SPEI and crop yields is used to estimate the copulas and R-Vine in step 3. The actual calculations of joint distributions in step 4 are based on a simulation approach using random sample techniques. Using the inverse transformation method in step 5 based on the estimated marginal distributions from the EPIC data the related crop yields are upscaled.
2.6 Data used
As indicated, we used the pan-European EPIC model powered by gridded information on soils, terrain, cropland distribution and Corn management practices, including sowing date, length of the growing season, fertilization and irrigation schedules and cultivar definition, as described by Balkovič et al. (2013)—see Online Resource 4. As climate input we have looked at a total of five bias-corrected regional climate projections from the European branch of the Coordinated Regional Downscaling Experiment program (EURO-CORDEX) developed in the Quantifying Projected Impacts Under 2 °C Warming project (IMPACT2C, http://impact2c.hzg.de) to drive crop yield projections in this study (all are RCP 4.5 scenarios, for more information we refer to Online Resource 4) The set of EURO-CORDEX climate projections (Jacob et al. 2014) was bias-corrected for minimum and maximum daily temperature, precipitation and solar radiation in the IMPACT2C project, ranging from 1971 to the end of century. For future climate change we focus on mid-future period of 2050 in this analysis. For example, Fig. 2 shows changes in the growing season temperature for 2050s relative to the historic period (1971–2000) which is used as an input for our agricultural model.

Change in mean growing season temperature (T, in %) in the 2050s relative to the historic period (1971–2000) calculated for individual climate change projections and the ensemble mean (AT11: Burgenland, AT12: Lower Austria, AT13: Vienna, AT21: Carinthia, AT22: Styria, AT31: Upper Austria, AT32: Salzburg, AT34: Vorarlberg)
The SPEI index that is used as a proxy to detect spatial dependency between different SimUs was based on historical meteorological data from the Joint Research Centre’s Gridded Agro-Meteorological Data in Europe database available at a 25 km grid resolution (http://agri4cast.jrc.ec.europa.eu), ranging from 1980 to 2015. The SPEI data was spatially linked to SimU-based crop yield simulations from the EPIC model for the current situation. Summarizing, data requirements are relatively modest, i.e. an EPIC model calibrated to a given country for the current and future climate and SPEI indices on the same scale as the SimU crop yield data.
3 Results
We first present some background information of our case study. Agricultural wise 1.35 million hectares of land are classified as arable land (almost 50 percent of the total agriculturally used area of 2.76 million hectares) in Austria. It is mainly located in the eastern parts of the country (while grassland tends more to be located in the western part). Major land area cultivates grain, namely 900.000 hectares and it is the major line of domestic plant production. Focus of domestic plant production is on crops with around 790.000 hectares (including Corn). Around 300.000 hectares are used for Corn, which is the focus in our study and the second major crop in Austria. On an aggregated scale other crops are of minor importance, nevertheless, very important for specific farming types, including small-scale farmers. How climate change will alter drought risk on such large levels is largely unknown. A full sectorial analysis on some impacts and costs from a mostly non-risk perspective was performed recently within the COIN project (Costs of Inaction). The results can be found in Steininger et al. (2017) who analysed climate change projections of the A1B scenario. Another prominent source for climate change impacts is the Austrian Assessment Report Climate Change 2014 (AAR14) which gives a summary of all research done in the respective fields for the case of Austria and under the specific context of climate change. None of these reports presented drought risk and its effects due to climate change from a probabilistic large scale perspective as applied in our case. Like in the methodology section we present results first from an agriculture crop simulation perspective, afterwards showing the results in the form of crop distributions and finally the upscaling results to the country level.
3.1 Crop simulation
As indicated, pan-European EPIC was used to estimate regional crop yields in Austria, for the Business As Usual (BAU) scenario. In this paper we focused on Corn, however, it is not restricted to this specific crop. In more detail, the BAU scenarios represent fertilization around the year 2000 (Balkovič et al. 2013). Overall, the sub-national crop yield estimates are in a good agreement with historical yields reported by EUROSTAT, with all simulated yields within the 20% confidence interval (Fig. 3 in Online Resource 4). Regional crop yield projections driven by the EURO-CORDEX ensemble are presented again in the Online Resource 4 as our focus is not on the sub-national but country level. However, summarizing the results for Corn, average yields would increase, especially in higher altitudes, where the crops would likely benefit from alleviated low temperature limitations. However, a higher yield vulnerability of more than 20% was estimated in areas in the Pannonian zone, namely in Burgenland and Lower Austria. In Lower Austria, the vulnerable yield exceeded 40% for Corn (Fig. 5 in Online Resource 4). The results indicate that Corn may suffer serious yield damage in case of droughts in these regions (however, as indicated the results are based on averages). Similarly, though less intensive vulnerability is estimated for Burgenland. Other regions of Austria are much less vulnerable. Such differences in risk on the local level can now be explicitly incorporated within a country level perspective. Crop yield simulations from 1971 till 2100 under the respective model scenarios were calculated on a 1 × 1 km pixel level.
3.2 Crop distribution
Based on the EPIC crop yield simulations the crop distributions were fitted for today (using the time series from 1971 to 2010) and the future 2050 (using time series from 2041 to 2070). For indicative purposes Fig. 3a and b demonstrate Corn yield distributions for a specific simulation unit in Austria (SimU = 54) for time horizons 1971–2010 and 2041–2070 ranked by the AIC criterion. One can see that the marginal distribution for the future (2041–2070) is skewed and has heavier left tail, which means that the risk of lower yields is increasing in time. The AIC corresponding to the Weibull distribution of Fig. 3a is equal to 148.8, while the AIC of the Extreme Value distribution corresponding to Fig. 3b is equal to 123.5, indicating that the future fit is at least as good as the current one.

Current a and future b crop yield distribution for Corn in SimU = 54, model CSC-REMO2009/MPI-ESM-LR. a Time horizon: 1971–2010, b time horizon: 2041–2070
The approach was adopted for all SimUs (707 in total) and the risk based information on the very local level was used as the input to upscale risk to the national level using the copula approach as discussed. The information of all selected distributions, test statistics and information criteria for all SimUs can be provided upon request from the authors.
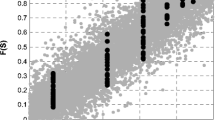
For determining possible ranges of risks we additionally performed calculations for fully interdependent and fully independent situations. The fully interdependent approach considers all SimUs in Austria as dependent on each other, regardless of the SPEI value and of a possible absence of the long-term influence of drought on crop yields. It therefore presents an upper bound on risk. The fully independent approach considers all SimUs in Austria as independent from each other, regardless of SPEI dependency or crop yield dependency in the region. It therefore presents a lower bound on risk. As indicated in Fig. 4 the fully independent approach underestimates the risk of droughts in Austria while the fully interdependent one overestimates risk.

Current corn yield distributions based on different dependency assumptions. Model CSC-REMO2009/MPI-ESM-LR
As one can see the underestimation of risk assuming independency is quite significant, e.g. on average around 20 percent compared to the copula approach. However, more importantly, the underestimation of risk gets especially pronounced for extreme events.
3.3 Copula and upscaling results
Applying the multi-regional approach to the study of crop yields in Austria, we have estimated current and future crop yield probability distributions on the national scale. The risk is described in terms of quantiles corresponding to 2-, 5-, 10-, 50-, 100-, 250-, 500, 1000-year events for Corn. The average production for the ensemble mean is around 5.2 million tons which is a little bit higher than the 5.1 million tons of Corn (average over the last 5 years). The future Corn yields increase significantly on average in the future due to climate change, however, our risk perspective gives a more worrying picture if one compares yields for different return periods. It can be noted that such an analysis would not be possible if not a risk based approach as ours is applied. For example, a 500 year event (i.e. low yields which happen approximately every 500 years on average, e.g. a very extreme event) would cause total yields around 15 percent lower compared to the average. A comparison with the future yields indicates that while the average is higher in this situation, the 500 year event would decrease by of more than 22 percent. In other words, while larger averages can be expected in the future there seems also to be larger fluctuations compared to the current situation, i.e. more and larger extremes.
Rather than presenting the crop yield distribution we want to demonstrate an important risk management application if such information is available, namely, how large the current and future fiscal risk for the government would be if it participates in insurance schemes providing assistance in case of droughts. As planned by the finance ministry in Austria, current and future risk management strategies should support insurance schemes by subsidizing it by 50 percent. Assuming that the insurance scheme is providing relief for all yields below the average, and using the 5 year average price for 1 ton of Corn, one can calculate the expected costs given that the yields are below the average. We use the 5 year average of Corn price (recognizing the large fluctuations which need to be additionally addressed) to be around 175 Euros per ton. In the case of a 50 year event the government would step in with around 69 million Euros and costs would increase to around 103 million Euros in 2050. For a more extreme event such as the 500 year event costs today for the government would be 94 million Euros and would increase to around 155 million Euros in 2050. Table 1 presents the risk based costs to the government participating in a subsidized insurance scheme for Corn for today and the future.
These numbers give a detailed picture on drought losses from a country level perspective and can also advice future risk management strategies for the government as well as insurance providers in more detail, e.g. backup capital needed for extreme events. For example, the actuarial fair premium for the government subsidizing insurance would be around 13.4 million Euros today and would increase to around 19.9 million Euros in the future. Applying a 250 year event as a reference point for determining necessary backup-capital for the government it would be around 88 million Euros today and 140 million Euros in the future. The results in Table 1 are based on the mean ensemble runs and there is the question how sensitive the results are in regards to model ambiguity as well as prices. Especially in the insurance context model ambiguity gets increasingly important and should be looked at (Pflug et al. 2017). Additionally, crop yield prices in a given year play a crucial role in regards to sufficiently compensate farmers to avoid their bankruptcy. We therefore re-run the modelling approach for each of the 5 different climate projection models as well as prices for Corn in the last 5 years. We included in Table 1 the minimum as well as maximum costs using the minimum crop yield losses over all models as well as minimum and maximum prices of Corn in the last 5 years. As one can see costs can considerably increase due to these uncertainties, however, it should be also noted that the largest part of increase or decrease is due to prices (around 80 percent of respective changes). Consequently, due to model ambiguity insurance premiums may be considerably higher than presented here (Pflug et al. 2017) and price effects will play an important role for such insurance arrangements.
3.4 Limitations
There are considerable uncertainties involved in our methodological approach. First of all, our results cannot reduce the uncertainties in respect to climate change modelling as well as biophysical crop modelling (e.g. Balkovič et al. 2018) as they are regarded as input parameters. We accounted partly for model ambiguity in regards to climate change projections, however, we did not include other possible agricultural crop models to account for model ambiguity in regards to crop projections. Secondly, within our model, the copula approach assumed the same spatial dependencies for today and the future. This has mostly to do that SPEI future indices are not available and can be very different across modeling efforts. Nevertheless, there is the possibility to change the copula parameters to make some sensitivity tests on crop yields under different dependency structures (see for example as a possible application Borgomeo et al. 2015). Thirdly, prices of crops fluctuate widely and while we used average crop prices these fluctuations need to be taken into account. Again, some sensitivity tests were performed by us but crop prices are based very much on worldwide market prices, and therefore a global agricultural price modeling approach, such as the Global Biosphere Management Model (GLOBIOM, Havlik et al. 2014) or others, would be needed here to take this into account. Last but not least, for extreme events data is scarce and there is the need to provide crop yield simulations and respective climate change scenarios with a special focus on extreme events. All of these challenges are possible to be considered in the future within our framework, however, will require some efforts to be solved.
4 Discussion
In this paper we presented a large scale computational approach how to derive probabilistic drought risk estimates on the country level. Importantly, this approach is able to incorporate future climate change impacts from a risk-based perspective. To the authors best knowledge this is the first time that such assessment was carried out using a computational modelling and risk based approach. The EPIC crop yield simulation results were used to estimate probabilistic distributions of crop yields which were upscaled to the country level using a copula approach. This enabled us to calculate a loss distribution which can be used for various risk management approaches. For example, we calculated a cost curve for the government participating in insurance schemes. We found that the incorporation of tail dependencies across regions as was shown for the Austria case study is essential, as otherwise risks will be seriously underestimated and risk management strategies are likely to fail in cases where they are most needed. The approach can also give a detailed picture of current and future risks and therefore may be especially relevant for adaptation policy purposes. For example we found that while the average corn yields would increase in the future for our climate change scenarios also extremes will be larger and more frequent. We acknowledge that not all agricultural production related risks can be covered with this approach, for example risks due to dust storms or other hazards such as storms. Nevertheless it can provide a more detailed assessment of risks on larger scales which is currently only accounted for via the investigation of changes in the averages. Our approach is able to expand this picture by providing information on the whole risk spectrum and therefore bridges the gap between traditional and more advanced risk management strategies (Mechler et al. 2014) important in current applied research areas (Lal et al. 2012).
References
Adger WN, Dessai S, Goulden M, Hulme M, Lorenzoni I, Nelson DR, Naess LO, Wolf J, Wreford A (2009) Are there social limits to adaptation to climate change? Clim Change 93(3):335–354
Balkovič J, van der Velde M, Schmid E et al (2013) Pan-European crop modelling with EPIC: implementation, up-scaling and regional crop yield validation. Agric Syst 120:61–75
Balkovič J, Skalský R, Folberth Ch, Khabarov N, Schmid E, Madaras M, Obersteiner M, van der Velde M (2018) Impacts and uncertainties of +2°C of climate change and soil degradation on European crop calorie supply. Earth’s Future 6:373–395
Bedford T, Cooke R (2002) Vines—a new graphical model for dependent random variables. Ann Stat 30:1031–1068
Borgomeo E, Pflug G, Hall H, Hochrainer-Stigler S (2015) Assessing water resource system vulnerability to unprecedented hydrological drought using copulas to characterize drought duration and deficit. Water Resour Res 51:8927–8948. https://doi.org/10.1002/2015WR017324
Choros-Tomczyk B, Härdle W, Okhrin O (2013) Valuation of collateralized debt obligations with hierarchical archimedean Copulae. J Empir Finance 24:42–62
Choros-Tomczyk B, Härdle W, Overback L (2014) Copula dynamics in CDOs. Quant. Finance 14:1573–1585
Embrechts P, Klüppelberg C, Mikosch T (2013) Modelling extremal events: for insurance and finance, vol 33. Springer, Berlin
Folberth C, Skalský R, Moltchanova E, Balkovič J, Azevedo LB, Obersteiner M, Van Der Velde M (2016) Uncertainty in soil data can outweigh climate impact signals in global crop yield simulations. Nat Commun 7:11872
GDFRR (2016) The making of a riskier future: how our decisions are shaping future disaster risk. Global Facility for Disaster Reduction and Recovery, Washington, DC. https://www.gfdrr.org/sites/default/files/publication/Riskier%20Future.pdf. Accessed 1 Nov 2018
Grossi P, Kunreuther H (2006) Catastrophe modeling: a new approach to managing risk. Springer, Berlin
Havlík P, Valin H, Herrero M, Obersteiner M, Schmid E, Rufino MC, Mosnier A, Thornton PK, Böttcher H, Conant RT, Frank S (2014) Climate change mitigation through livestock system transitions. Proc Natl Acad Sci 111(10):3709–3714
Hochrainer-Stigler S, Lugeri N, Radziejewski M (2013) Up-scaling of impact dependent loss distributions: a hybrid-convolution approach for flood risk in Europe. Natural Hazards:1437–1451
Hochrainer-Stigler S, Linnerooth-Bayer J, Lorant A (2017) The European union solidarity fund: an assessment of its recent reforms. Mitig Adapt Strat Glob Change 22(4):547–563. https://doi.org/10.1007/s11027-015-9687-3
IPCC (2012) Summary for policymakers. In: Field CB et al (eds) Managing the risks of extreme events and disasters to advance climate change adaptation. A special report of working groups I and II of the Intergovernmental Panel on Climate Change
Izaurralde RC, Williams JR, McGill WB, Rosenberg NJ, Jakas MCQ (2006) Simulating soil C dynamics with EPIC: model description and testing against long-term data. Ecol Model 192(3–4):362–384
Izaurralde RC, McGill WB, Williams JR (2012) Development and application of the EPIC model for carbon cycle, greenhouse gas mitigation, and biofuel studies. In: Liebig MA, Franzluebbers AJ, Follett RF (eds) Managing agricultural greenhouse gases. Elsevier, Amsterdam, pp 293–308
Jacob D, Petersen J, Eggert B et al (2014) EURO-CORDEX: new high-resolution climate change projections for European impact research. Reg Environ Change 14:563–578
Jaworski P, Durante F, Härdle W, Rychlik T (2009) Copula theory and its applications. In: Proceedings of the Workshop Held in Warsaw
Jaworski P, Durante F, Härdle W (2012) Copula in mathematical and quantitative finance. In: Proceedings of the Workshop Held in Cracow
Jongman B, Hochrainer-Stigler S, Feyen L, Aerts CJH, Mechler R, Botzen WJ, Bouwer LM, Pflug G, Rojas R, Ward PJ (2014) Increasing stress on disaster-risk finance due to large floods. Nat Clim Change 4:264–268. https://doi.org/10.1038/nclimate2124
Kassie BT, Asseng S, Rotter RP, Hengsdijk H, Ruane AC, Van Ittersum MK (2015) Exploring climate change impacts and adaptation options for maize production in the Central Rift Valley of Ethiopia using different climate change scenarios and crop models. Clim Change 129(1–2):145–158
Kaut M, Wallace SW (2011) Shape-based scenario generation using copulas. CMS 8(1–2):181–199
Kovacevic RM, Pflug G (2015) Measuring systemic risk: structural approaches. Quantitative financial risk management: theory and practice. Wiley, Hoboken, pp 1–21
Kurowicka D, Cooke R (2006) Uncertainty analysis with high dimensional dependence modelling. Wiley series in probability and statistics. Wiley, New York
Kurowicka D, Joe H (2010) Dependence modeling: handbook on Vine Copulae. World Scientific Publishing Co., Singapore
Lal PN et al (2012) National systems for managing the risks from climate extremes and disasters. In: IPCC, pp 339–392
Li T, Angeles O, Radanielson A, Marcaida M, Manalo E (2015) Drought stress impacts of climate change on rainfed rice in South Asia. Clim Change 133(4):709–720
Mechler R, Bouwer LM, Linnerooth-Bayer J, Hochrainer-Stigler S, Aerts JC, Surminski S, Williges K (2014) Managing unnatural disaster risk from climate extremes. Nat Clim Change 4(4):235
Meyer V et al (2013) Review article: assessing the costs of natural hazards–state of the art and knowledge gaps. Nat Hazards Earth Syst Sci 13:1351–1373
Monteith JL (1977) Climate and the efficiency of crop production in Britain. Philos Trans R Soc Lond B Biol Sci 281(980):277–294
Munich Re (2018) Topics. Munich Re, Munich
Nelsen R (2006) An introduction to Copulas. Springer, Berlin
Österreichischer Sachstandsbericht Klimawandel 2014 (2014) Austrian panel on climate change (APCC), Austrian assessment report 2014 (AAR14). Verlag der Österreichischen Akademie der Wissenschaften, Wien
Pflug G, Pichler A (2018) Systemic risk and copula models. CEJOR. https://doi.org/10.1007/s10100-018-0525-z
Pflug G, Römisch W (2007) Modeling, measuring and managing risk. World Scientific, Singapore. ISBN 978-981-270-740-6
Pflug G, Timonina-Farkas A, Hochrainer-Stigler S (2017) Incorporating model uncertainty into optimal insurance contract design. Insur Math Econ 37:68–74. https://doi.org/10.1016/j.insmatheco.2016.11.008
Reiss RD, Thomas M (2007) Statistical analysis of extreme values, 3rd edn. Birkhäuser, Basel
Rose A (2004) Economic principles, issues, and research priorities in hazard loss estimation. In: Okuyama Y, Chang SE (eds) Modeling spatial and economic impacts of disasters. Springer, New York
Rosenzweig C, Elliott J, Deryng D et al (2014) Assessing agricultural risks of climate change in the 21st century in a global gridded crop model intercomparison. Proc Natl Acad Sci 111:3268–3273
Steininger FN et al (eds) (2017) Economic evaluation of climate change impacts: development of a cross-sectoral framework and results for Austria. Springer, New York, pp 349–366
Stockle CO, Williams JR, Rosenberg NJ, Jones CA (1992) A method for estimating the direct and climatic effects of rising atmospheric carbon dioxide on growth and yield of crops: part I—modification of the EPIC model for climate change analysis. Agric Syst 38(3):225–238
Timonina A, Hochrainer-Stigler S, Pflug G, Jongman B, Rojas R (2015) Structured coupling of probability loss distributions: assessing joint flood risk in multiple river basins. Risk Anal 35:2102–2119
UNISDR (2009) Drought risk reduction framework and practices: contributing to the implementation of the hyogo framework for action. United nations secretariat of the international strategy for disaster reduction (UNISDR), vol 213. UNISDR, Geneva
UNISDR (2013) Global assessment report on disaster risk reduction 2013. UNISDR, Geneva
UNISDR (2015) Sendai framework for disaster risk reduction 2015–2030. UNISDR, Geneva
van Oijen M, Beer C, Cramer W, Rammig A, Reichstein M, Rolinski S, Soussana J-F (2013) A novel probabilistic risk analysis to determine the vulnerability of ecosystems to extreme climatic events. Environ Res Lett 8:015032
Vicente-Serrano SM, Beguería S, López-Moreno JI (2010) A multiscalar drought index sensitive to global warming: the standardized precipitation evapotranspiration index. J Clim 23:1696–1718
White JW et al (2011) Methodologies for simulating impacts of climate change on crop production. Field Crops Res 124:357–368. https://doi.org/10.1016/j.fcr.2011.07.001
Williams JR (1995) The EPIC model. In: Singh VP (ed) Computer models of watershed hydrology. Water resources publisher, Colorado, pp 909–1000
World Economic Forum (2014) Global risks 2014. http://reports.weforum.org/global-risks-2014/. Accessed 1 Nov 2018
Zhao T, Dai A (2016) Uncertainties in historical changes and future projections of drought. Part II: model-simulated historical and future drought changes. Clim Change 144:1–14
Acknowledgements
Open access funding provided by International Institute for Applied Systems Analysis (IIASA). Funding for this research was granted by the Seventh Framework Programme (Grant No. 282746) and Austrian Climate and Energy Fund (Austrian Climate Research Program (ACRP), project FARM (project number B567169).
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Hochrainer-Stigler, S., Balkovič, J., Silm, K. et al. Large scale extreme risk assessment using copulas: an application to drought events under climate change for Austria. Comput Manag Sci 16, 651–669 (2019). https://doi.org/10.1007/s10287-018-0339-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-018-0339-4