
Abstract
In the last decade, a few models of portfolio construction have been proposed which apply second order stochastic dominance (SSD) as a choice criterion. SSD approach requires the use of a reference distribution which acts as a benchmark. The return distribution of the computed portfolio dominates the benchmark by the SSD criterion. The benchmark distribution naturally plays an important role since different benchmarks lead to very different portfolio solutions. In this paper we describe a novel concept of reshaping the benchmark distribution with a view to obtaining portfolio solutions which have enhanced return distributions. The return distribution of the constructed portfolio is considered enhanced if the left tail is improved, the downside risk is reduced and the standard deviation remains within a specified range. We extend this approach from long only to long-short strategies which are used by many hedge fund and quant fund practitioners. We present computational results which illustrate (1) how this approach leads to superior portfolio performance (2) how significantly better performance is achieved for portfolios that include shorting of assets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Second order stochastic dominance (SSD) has been long recognised as a rational criterion of choice between wealth distributions (Hadar and Russell 1969; Bawa 1975; Levy 1992). Empirical tests for SSD portfolio efficiency have been proposed in Post (2003), Kuosmanen (2004). In recent times SSD choice criterion has been proposed (Dentcheva and Ruszczynski 2003, 2006; Roman et al. 2006) for portfolio construction by researchers working in this domain. The approach described in Dentcheva and Ruszczynski (2003, 2006) first considers a reference (or benchmark) distribution and then computes a portfolio which dominates the benchmark distribution by the SSD criterion. In Roman et al. (2006) a multi-objective optimisation model is introduced in order to achieve SSD dominance. This model is both novel and usable since, when the benchmark solution itself is SSD efficient or its dominance is unattainable, it finds an SSD efficient portfolio whose return distribution comes close to the benchmark in a satisficing sense. The topic continues to be researched (Dentcheva and Ruszczynski; Fábián et al. 2011a, b; Post and Kopa 2013; Kopa and Post 2015; Post et al. 2015; Hodder et al. 2015; Javanmardi and Lawryshy 2016) from the perspective of modelling as well as that of computational solution.
These models start from the assumption that a reference (benchmark) distribution is available. It was shown in Roman et al. (2006) that the reference distribution plays a crucial role in the selection process: there are many SSD efficient portfolios and the choice of a specific one depends on the benchmark distribution used. SSD efficiency does not necessarily make a return distribution desirable, as demonstrated by the optimal portfolio with regards to maximum expected return. It was shown in Roman et al. (2006) that this portfolio is SSD efficient - however, it is undesirable to a large class of decision-makers.
In the last two decades, quantitative analysts in the fund management industry have actively debated about the benefit of active fund management in contrast to passive investment. Passive investment equates to holding a portfolio determined by the constituents of a chosen market index. Active fund managers are engaged in finding portfolios which provide better return than that of a passive index portfolio. Set against this background the index is a natural benchmark (reference) distribution which an active fund manager would like to dominate. There have been several papers under the topic of “enhanced indexation” (di Bartolomeo 2000) which discuss alternative ways of doing better than the passive index portfolio. It has been shown empirically that return distributions of financial indices are SSD dominated (Post 2003; Kuosmanen 2004; Post and Kopa 2013; Kopa and Post 2015; Post et al. 2015).
In Roman et al. (2013) we introduced SSD-based models for enhanced indexation and reported encouraging practical results. An essential aspect of our approach to portfolio construction can be articulated by the qualitative statement “reduction of the downside risk and improvement of the upside potential”. This can be translated as finding return distributions with high expected value and skewness, meaning a left tail that is closer to the mean. An index does not necessarily (indeed very rarely) possess these properties. Thus the SSD dominant portfolio solutions, when we choose an index as the benchmark, do not necessarily have return distributions with a short left tail, high skewness and controlled standard deviation. Research effort in this direction include SSD based models in which, by appropriately selecting model parameters, the left tail of the resulting distribution can be partially controlled, in the sense that more “weight” can be given to tails at specified levels of confidence (Kopa and Post 2015; Hodder et al. 2015), see also Javanmardi and Lawryshy (2016).
In this paper, we propose a different approach that stems from a natural question to ask: how should we choose the reference distribution in SSD models such that the resulting portfolio has a return distribution that, in addition to being SSD efficient, has specific desirable properties, in the form of (1) high skewness and (2) standard deviation within a range?
The contributions of this paper are summarised as follows:
-
(a)
we propose a method of reshaping, or enhancing, a given (reference) distribution, namely, that of a financial index, in order to use it as a benchmark in SSD optimisation models;
-
(b)
we formulate and solve SSD models that include long-short strategies which are established financial practice to cope with changing financial regimes (bull and bear markets);
-
(c)
we investigate empirically the in-sample and out-of sample performance of portfolios obtained using enhanced benchmarks and long-short strategies.
The rest of the paper is organised in the following way. In Sect. 2 we present portfolio optimisation models based on the SSD concept and the role of the benchmark / reference distribution. The method of reshaping a benchmark distribution is presented in Sect. 3. In Sect. 4 we extend the long-only formulation presented in Sect. 2 to include long-short strategies as discussed in (b) above. Section 5 contains the results of our numerical experiments. We compare the in-sample and out-of sample performance of portfolios obtained in SSD models, using an original benchmark and a reshaped benchmark. The comparison is made in a long-only setting as well as in the context of various long-short strategies. A summary and our conclusions are presented in Sect. 6.
2 Portfolio optimisation using SSD
We consider a portfolio selection problem with one investment period. Let n denote the number of assets into which we may invest. A portfolio \( x=(x_1, \ldots x_n) \in \mathbb {R}^n \) represents the proportions of the portfolio value invested in the available assets. Let the n-dimensional random vector \( R = (R_1, \ldots , R_n)\) denote the returns of the different assets at the end of the investment period.
It is usual to consider the distribution of R as discrete, described by the realisations under a finite number of scenarios S; scenario j occurs with probability \(p_j\) where \(p_j>0\) and \(p_1+ \cdots +p_S=1\). Let us denote by \(r_{ij}\) the return of asset i under scenario j. The random return of portfolio x is denoted by \( R_{x}\), with \( R_{x} := x_1R_1+ \cdots x_nR_n\).
We remind that second-order stochastic dominance (SSD) is a preference relation among random variables (representing portfolio returns) defined by the following equivalent conditions:
-
(a)
\( \text{ E } ( U(R) ) \ge \text{ E } ( U( R^{\prime } ) ) \) holds for any nondecreasing and concave utility function U for which these expected values exist and are finite.
-
(b)
\( \text{ E } ( [ t - R ]_+ ) \;\le \; \text{ E } ( [ t - R^{\prime } ]_+ ) \) holds for each \( t \in \mathbb {R} \).
-
(c)
\( \text{ Tail }_{\alpha }( R ) \;\ge \; \text{ Tail }_{\alpha }( R^{\prime } ) \) holds for each \( 0 < \alpha \le 1 \), where \( \text{ Tail }_{\alpha }( R ) \) denotes the unconditional expectation of the least \( \alpha *100\% \) of the outcomes of R.
If the relations above hold, the random variable R is said to dominate the random variable \(R^{\prime }\) with respect to second-order stochastic dominance (SSD); we denote this by \( R \succeq _{_{SSD}} R^{\prime } \). The strict relation \( R \succ _{_{SSD}} R^{\prime } \) is similarly defined, if, for example, in addition to (c), there exists \( \alpha \) in (0,1) such that \( \text{ Tail }_{\alpha }( R ) \; > \; \text{ Tail }_{\alpha }( R^{\prime } ) .\)
The equivalence of the above relations is well known since the works of Whimore and Findlay (1978) and Ogryczak and Ruszczynski (2002). From the first relation, the importance of SSD in portfolio selection can be clearly seen: it expresses the preference of rational and risk-averse decision makers.
Remark 1
The definition of \(\text{ Tail }_{\alpha }( R ) \) is an informal definition. For a formal definition, quantile functions can be used. Denote by \(F_R\) the cumulative distribution function of a random variable R. If there exists t such that \(F_R(t) = \alpha \) then \(\text{ Tail }_{\alpha }( R ) = \alpha E(R | R \le t)\)—which justifies the informal definition. For the general case, let us define the generalised inverse of \(F_R\) as \(F_R^{-1}(\alpha ) := \text{ inf } \{t | F_R(t) \ge \alpha \}\) and the second quantile function as \(F_R^{-2}(\alpha ) := \int _{0}^{\alpha } F_R^{-1}(\beta )d\beta \) and \(F_R^{-2}(0):= 0\). With these notations, \(\text{ Tail }_{\alpha }( R ): = F_R^{-2}(\alpha ).\)
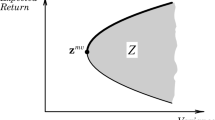
Let \( X \subset \mathbb {R}^n \) denote the set of the feasible portfolios, we assume that X is a bounded convex polyhedron. A portfolio \( {x}^{\star } \) is said to be SSD-efficient if there is no feasible portfolio \( {x} \in X \) such that \( R_{x} \succ _{_{SSD}} R_{{x}^{\star }} \).
Recently proposed portfolio optimisation models based on the concept of SSD assume that a reference (benchmark) distribution \(R^{\text {ref}}\) is available. Let \(\hat{\tau }\) be the tails of the benchmark distribution at confidence levels \( \frac{1}{S}, \ldots , \frac{S}{S}\); that is, \(\hat{\tau } = (\hat{\tau }_1, \ldots , \hat{\tau }_S) = \big ( \text {Tail}_{\frac{1}{S}}R^{\text {ref}}, \ldots , \text {Tail}_{\frac{S}{S}}R^{\text {ref}} \big )\).
Assuming equiprobable scenarios as in Roman et al. (2006, 2013), Fábián et al. (2011a, b), the model in Fábián et al. (2011b) optimises the worst difference between the “scaled” tails of the benchmark and of the return distribution of the solution portfolio; the \(\alpha \)- “scaled” tail is defined as \( \frac{1}{\alpha } \text{ Tail }_{\alpha }( R ) \) . The decision variables are the portfolio weights \(x_1, \ldots ,x_n\) and \(\mathcal {V} = \min \nolimits _{1 \le s \le S} \frac{1}{s}\big (\text {Tail}_{\frac{s}{S}} (R_x) - \hat{\tau }_s \big )\), representing the worst partial achievement of the differences between the scaled tails of the portfolio return and the scaled tails of the benchmark. The scaled tails of the benchmark are \( (\frac{S}{1}\hat{\tau }_1, \frac{S}{2}\hat{\tau }_2 \ldots , \frac{S}{S}\hat{\tau }_S).\) Using a cutting plane representation (Fábián et al. 2011a) the model can be written as:
subject to:
Remark 2
The cutting plane formulation above has a huge number of constraints (3), referred to in Fábián et al. (2011a) as “cuts”. The specialised solution method (Fábián et al. 2011a) adds cuts at each iteration until optimality is reached; it is shown that in practice, only a few cuts are needed. For example, all models with 10,000 scenarios of assets returns were solved with less than 30 iterations. For more details, the reader is referred to Fábián et al. (2011a).
Remark 3
In case that optimisation of the worst partial achievement has multiple optimal solutions, all of them improve on the benchmark (if the optimum is positive) but not all of them are guaranteed to improve until SSD efficiency is attained. The model proposed in Roman et al. (2006) has a slightly different objective function that included a regularisation term, in order to guarantee SSD efficiency for the case multiple optimal solutions. This term was dropped in the cutting plane formulation, the advantage of this being huge decrease in computational difficulty and solution time; just as an example, models with tens of thousands of scenarios were solved within seconds, while the original model formulation in Roman et al. (2006) could only deal with a number of scenarios in the order of hundreds. In Fábián et al. (2011a), extensive computational results are reported. For relatively small datasets, SSD models were solved with both the cutting plane formulation and the original formulation including the regularisation term; in all instances, both formulations led to the same optimal solutions. For more details, the reader is referred to Fábián et al. (2011a).
The tails of the benchmark distribution \((\hat{\tau }_1, \ldots , \hat{\tau }_S)\) are the decision-maker’s input. When the benchmark is not SSD efficient, the solution portfolio has a return distribution that improves on the benchmark until SSD efficiency is achieved. In case the benchmark is SSD efficient, the model finds the portfolio whose return distribution is the benchmark. For instance, if the benchmark is the return distribution of the asset with the highest expected return, the solution portfolio is that where all capital is invested in this asset.
“Unattainable” reference distributions are discussed in Roman et al. (2006), where the (SSD efficient) solution portfolio has a return distribution that comes as close as possible to dominating the benchmark; this is obtained by minimising the largest difference between the tails of these two distributions. However, simply setting “high targets” (i.e. a possibly unrealistic benchmark) does not solve the problem of finding a portfolio with a “good” return distribution, e.g. one having a short left tail/high skewness and controlled standard deviation.
In recent research, the most common approach is to set the benchmark as the return distribution of a financial index. This is natural since discrete approximations for this choice can be directly obtained from publicly available historical data, and also due to the meaningfulness of interpretation - it is common practice to compare / make reference to an index performance. The financial index distribution is “achievable” since there exists a feasible portfolio that replicates the index and empirical evidence (Roman et al. 2006, 2013; Post and Kopa 2013) suggests that this distribution is in most cases not SSD efficient. While it is safe to say that generally a portfolio that dominates an index with relation to SSD can be found, there is no guarantee that this portfolio will have desirable properties.
In this work, we use the distribution of a financial index as a starting point; we enhance it in the sense of increasing skewness by a decision-maker’s specified amount while keeping standard deviation within a (decision-maker specified) range.
3 Reshaping the reference distribution
We propose a method of reshaping an original reference distribution and achieving a synthetic (improved) reference distribution.
To clarify what we mean by improved reference distribution, let us consider the blue area in Fig. 1 to be the density curve of the original reference distribution, in this example closely symmetrical and with a considerably long left-tail.

Density curves for the original and improved reference distributions
The pink area in the figure represents the density curve of what we consider to be an improved reference distribution. Desirable properties include a shorter left tail (reduced probability of large losses), which translates into higher skewness, and a higher expected return, which is equivalent to a higher mean. A smaller standard deviation is not necessarily desirable, as it might limit the upside potential of high returns. Instead, we require the standard deviation of the new distribution to be within a specified range from the standard deviation of the original distribution.
We hereby introduce a method for transforming the original reference distribution into a synthetic reference distribution given target values for the first three statistical moments (mean, standard deviation and skewness).
Let the original reference distribution be represented by a sample \(Y = (y_1, \ldots , y_S)\) with mean \(\mu _Y\), standard deviation \(\sigma _Y\) and skewness \(\gamma _Y\).
Given target values \(\mu _T\), \(\sigma _T\) and \(\gamma _T\), our goal is to find a distribution \(Y'\) with values \(y'_s, s = 1, \ldots , S\), such that \(\mu _Y' = \mu _{T}\), \(\sigma _{Y'} = \sigma _T\) and \(\gamma _{Y'} = \gamma _T\).
In statistics, this problem is related to test equating. It is commonly found in standardized testing, where multiple test forms are needed because examinees must take the test at different occasions and one test form can only be administered once to ensure test security. However, test scores derived from different forms must be equivalent. Let us consider two test forms, say, Form V and Form W. It is generally assumed that the examinee groups that take test forms V and W are sampled from the same population, and differences in score distributions are attributed to form differences (e.g. more difficult questions in V than in W). Equating forms V and W involves modifying V scores so that the transformed V scores have the same statistical properties as W.
If our intention was solely to preserve the first two moments, a linear equating method would be appropriate. Linear equating (Kolen and Brennan 1995) takes the form:
In order, however, to preserve the first three moments, we make use of a quadratic curve equating method proposed by Wang and Kolen (1996). In selecting a nonlinear equating function, the authors aimed for a method that was more flexible than linear equating and would still preserve its beneficial properties such as using statistics with small random errors that are computationally simple. The method works as follows:
-
1.
Step 1: Arbitrarily define \(\mu _T\), \(\gamma _T\) and \(\sigma _T\).
-
2.
Step 2: Using the single-variable Newton–Raphson iterative method (Press et al. (1988), pp. 362–367), find d so that \(Y + d Y^2\) has skewness \(\gamma _{(Y + d Y^2)} = \gamma _T\). Using the standard skewness formula for a discrete sample, the skewness of the original reference distribution \(\gamma _Y\) is given by:
$$\begin{aligned} \gamma _Y = \frac{ \frac{1}{n} \sum _{i = 1}^{n} (y_i - \mu _{Y})^3 }{ \Big [ \frac{1}{n-1} \sum _{i = 1}^{n} (y_i - \mu _Y)^2 \Big ]^ {3/2} } \end{aligned}$$In order to find d we need to solve the equation:
$$\begin{aligned} \frac{ \frac{1}{n} \sum _{i = 1}^{n} \big ( y_i + d y_i^2 - (\frac{1}{n} \sum _{j=1}^{n} y_j + d y_j^ 2) \big )^3 }{ \Big [ \frac{1}{n-1} \sum _{i = 1}^{n} \big ( y_i + d y_i^2 - (\frac{1}{n} \sum _{j=1}^{n} y_j + d y_j^ 2) \big )^2 \Big ]^ {3/2} } - \gamma _T = 0 \end{aligned}$$ -
3.
Step 3: Let \(g = \frac{\sigma _T}{\sigma _{Y + d Y^2}}\). Then \(g (Y + d Y^2) \) will have \(\gamma _{g (Y + d Y^2)} = \gamma _T\) and \(\sigma _{g (Y + d Y^2)} = \sigma _T\) since a linear transformation (multiplication of constant g) does not change the skewness of a distribution.
-
4.
Step 4: Let \(h = \mu _T - \mu _{g(Y + dY^2)}\). Then \(Y' = h + g(X + dX^2)\) will have \(\mu _{Y'} = \mu _T\), \(\gamma _{Y'} = \gamma _T\) and \(\sigma _{Y'} = \sigma _T\) since adding a constant does not change the skewness or standard deviation of a distribution.
-
5.
Step 5: We then find \(Y'\) by computing:
$$\begin{aligned} y'_s = gdy_s^2 + gy_s + h, \;\;\;\;\;\; \forall s = 1, \ldots , S \end{aligned}$$
To apply this method we need to define values for \(\gamma _T\), \(\sigma _T\) and \(\mu _T\). In this specific context, these values should not be independent from the original distribution. For instance, if the skewness of the return distribution of a financial index is very low, simply setting a very high value for the target skewness might render it impossible to find a combination of assets (which are to some extent correlated to the original reference distribution) that dominates the synthetic distribution.
In preliminary tests, we noticed that large differences in values for \(\mu _T\) have little impact in out-of-sample results. Therefore, in our computation experiments, we set \(\mu _T= \mu _Y\) and we introduce two parameters to define the amount by which the target for the other moments differ from the original values: \(\varDelta _{\gamma }\) and \(\varDelta _{\sigma }\), both defined in \(\mathbb {R}\). Given these parameters, \(\gamma _T\) and \(\sigma _T\) are defined as:
4 Long-short modelling
When short-selling is allowed, the amount available for purchases of stocks in long positions is increased. Suppose we borrow from an intermediary a specified number of units of asset i (\(i = 1, \ldots , n\)), corresponding to a proportion \(x_i^-\) of capital. We sell them immediately in the market and hence have a cash sum of \((1 + \sum _{i=1}^{n} x_i^-)C\) to invest in long positions; where C is the initial capital available.
In long-short practice, it is common to fix the total amount of short-selling to a pre-specified proportion \(\alpha \) of the initial capital. In this case, the amount available to invest in long positions is \((1 + \alpha )C\). A fund that limits their exposure with a proportion \(\alpha = 0.2\) is usually referred to as a 120/20 fund. For modelling this situation, to each asset \(i \in {1, \ldots ,n}\) we assign two continuous nonnegative decision variables \(x_i^+, x_i^-\), representing the proportions invested in long and short positions in asset i, and two binary variables \(z_i^+, z_i^-\) that indicate whether there is investment in long or short positions in asset i. For example, if 10% of the capital is shorted in asset i, we write this as \(x_i^+=0\), \(x_i^-=0.1\), \(z_i^+=0\), \(z_i^-=1\).
As in Roman et al. (2013), \(\mathcal {V} = \min \nolimits _{1 \le s \le S} \frac{1}{s}\big (\text {Tail}_{\frac{s}{S}} (R^T (x^+ - x^-)) - \hat{\tau }_s \big )\) denotes the worst partial achievement; the scaled long/short reformulation of the achievement-maximisation problem is written as:
subject to:
To solve this formulation, we implemented a branch-and-cut algorithm (Padberg and Rinaldi 1991), which modifies the basic branch-and-bound strategy by attempting to identify new inequalities before branching a partial solution. Since the branch-and-bound algorithm begins with a relaxed formulation of the problem, a solution cannot be accepted as candidate for branching unless it violates no constraints of type (11). In order to identify violated constraints we employ the separation algorithm proposed by Fábián et al. (2011a).
5 Computational results
5.1 Motivation, dataset and methodology
The aims of this computational study are:
-
1.
To investigate the effect of using a benchmark distribution, reshaped by modifying skewness and/or standard deviation, in SSD-based portfolio optimisation models; the return distributions of the resulting portfolios, as well as their out-of-sample performance, are compared to those of portfolios obtained using the original benchmark.
-
2.
To investigate the performance of various long-short strategies in comparison with the long only strategy, as used in SSD-based models with original and reshaped benchmarks.
We use real-world historical daily data (closing prices) taken from the universe of assets defined by the Financial Times Stock Exchange 100 (FTSE100) index over the period 09/10/2007 to 07/10/2014 (1765 trading days). The data was collected from Thomson Reuters Datastream (2014) and adjusted to account for changes in index composition. This means that our models use no more data than was available at the time, removing susceptibility to the influence of survivor bias. For each asset we compute the corresponding daily rates of return.
The original benchmark distribution is obtained by considering the historical daily rates of return of FTSE100 during the same time period. We implement models (2)–(4) and (5)–(12) for different values of \(\alpha , \varDelta _{\gamma }\) and \(\varDelta _{\sigma }.\)
We used an Intel(R) Core(TM) i5-3337U CPU @ 1.80 GHz with 6GB of RAM and Linux as operating system. The Branch-and-cut algorithm was written in C++ and the backtesting framework was written in R (R Core Team 2015); we used CPLEX 12.6 (IBM 2015) as mixed-integer programming solver.
The methodology we adopt is successive rebalancing over time with recent historical data as scenarios. We start from the beginning of our data set. Given in-sample duration of S days, we decide a portfolio using data taken from an in-sample period corresponding to the first \(S+1\) days (yielding S daily returns for each asset). The portfolio is then held unchanged for an out-of-sample period of 5 days. We then rebalance (change) our portfolio, but now using the most recent S returns as in-sample data. The decided portfolio is then held unchanged for an out-of-sample period of 5 days, and the process repeats until we have exhausted all of the data. We set \(S = 564\) (approximately the number of trading days in 2.5 years) ; the total out-of-sample period spans almost 5 years (January 2010–October 2014).
Once the data has been exhausted we have a time series of 1201 portfolio return values for out-of-sample performance, here from period 565 (the first out-of-sample return value, corresponding to 04/01/2010) until the end of the data.
5.2 Long-short and long-only comparison
We test \(\alpha = 0\), \(\alpha = 0.2\), \(\alpha = 0.5\) and \(\alpha = 1.0\), thus we consider 100/0 (long-only), 120/20, 150/50 and 200/100 portfolios. The benchmark distribution is that of FTSE100. Given the portfolio holding period of 5 days, during the out-of-sample evaluation period there are a total of 240 rebalances. For each rebalance, we assign a time limit of 60 s.
5.2.1 In-sample analysis
Table 1 shows in-sample statistics regarding optimal solution values. Under Optimal object value, three columns are reported: (1) Mean, showing the average of the optimal objective values in each rebalance; (2) Min and (3) Max, showing respectively the minimum and maximum optimal objective values in each rebalance.
The first thing we note is that, with the exception of 200/100 portfolios, in all rebalances a positive optimal value was obtained, which means that the solver found a portfolio that dominates the index return distribution with respect to SSD. Up to 150/50, all rebalances were solved to optimality within 60 s. This is not the case, however, for the 200/100 portfolios. Optimality was not proven within the time limit for about 15% (35 out of 240) of all 200/100 rebalances. In some cases we were not able to find a portfolio that dominates its corresponding benchmark: in Table 1, the minimum solution value found for 200/100 was \(-0.000055\).
Despite that, overall, we observe that adding shorting improves the quality of in-sample solutions, with the average, minimum and maximum of optima being higher when \(\alpha \) is higher (with the exception of the minimum solution value for 200/100 as stated above).
Table 2 shows how many assets on average were in the composition of optimal portfolios—also reported are minimum and maximum numbers, for each value of \(\alpha \). Statistics are shown for assets held long, short and also for the complete set. From the table we can see that the addition of shorting tends to increase the number of stocks picked. This is expected, since the higher \(\alpha \) is, the higher is the exposure. For instance, if \(\alpha = 0.5\) we have 0.5C in repayment obligations and 1.5C in long positions, having a total exposure of 2C in different assets.
However, even in long/short models, the cardinality of the optimal portfolios is not high (26.8 for 150/50, about a quarter of the total of 100 companies from FTSE100, and 42.7 for 200/100), thus we consider the introduction of cardinality constraints to be unnecessary.
5.2.2 Out-of-sample performance
Figure 2 shows graphically the performance of each of the four strategies (100/0, 120/20, 150/50 and 200/100) as well as that of the financial index (FTSE100), as represented by their actual returns over the out-of sample period January 2010 to October 2014.

Long/short out-of-sample performance, 2010–2014
From the figure it is clear that portfolios with shorting (\(\alpha > 0\)) achieved better performance than the long-only portfolio, although it is also apparent that the variability of returns was larger. This can be confirmed by analysing Table 3, which presents several out-of-sample statistics. The meaning of each column is outlined below:
-
Final value: Normalised final value of the portfolio at the end of the out-of-sample period.
-
Excess over RFR (%): Annualised excess return over the risk free rate. For FTSE100 we used a flat yearly risk free rate of 2%.
-
Sharpe ratio: Annualised Sharpe ratio (Sharpe 1966) of returns.
-
Sortino ratio: Annualised Sortino ratio (Sortino and Price 1994) of returns.
-
Max drawdown (%): Maximum peak-to-trough decline (as percentage of the peak value) during the entire out-of-sample period.
-
Max recovery days: Maximum number of days for the portfolio to recover to the value of a former peak.
-
Daily returns—Mean: Mean of out-of-sample daily returns.
-
Daily returns—SD: Standard deviation of out-of-sample daily returns.
As we increase \(\alpha \) up to 0.5, both the mean and the standard deviation of the daily returns increase. As a consequence, although 150/50 achieved better returns than 120/20, the latter obtained higher Sharpe and Sortino ratios, as well as a lower maximum drawdown. Adding shorting seems to bring better performance at the expense of greater risk.
The overall performance of 200/100 portfolios was better than the long-only portfolio, but worse than 120/20 and 150/50. The 200/100 portfolio is more volatile (both in-sample and out-of-sample), which may be the reason for its lower final value when compared to the other cases. Moreover, some rebalances were not solved within 60 s, yielding suboptimal solutions. In the next sections, where we analyse the effects of reshaping the reference distribution, we ommit 200/100 results as they show similar behaviour to the ones presented in this section.
5.3 Reshaping the reference distribution: increased skewness
We now test how reshaping the reference distribution impacts both in-sample and out-of-sample results. For \(\alpha = 0\), \(\alpha = 0.2\), \(\alpha = 0.5\), we test the effects of different values of \(\varDelta _{\gamma }\), more specifically, we test \(\varDelta _{\gamma } = [0, 1, 2, 3, 4, 5]\). In all tests in this section, \(\varDelta _{\sigma } = 0\), that is, the standard deviation is unchanged.
Setting \(\varDelta _{\gamma } = 0\) is equivalent to optimising with the original reference distribution. In the rest of the cases, the skewness is increased to \(\gamma _T = \gamma _Y + (|\gamma _Y| \varDelta _{\gamma })\). For example, if \(\varDelta _{\gamma } = 1\) and \(\gamma _Y < 0\) then \(\gamma _T = 0\). If \(\varDelta _{\gamma } = 1\) and \(\gamma _Y > 0 \) then \(\gamma _T = 2 \gamma _Y\).
5.3.1 In-sample results
Table 4 presents in-sample results for different values of \(\varDelta _{\gamma }\). Results are reported differently when compared to those in Sect. 5.2.1. A direct comparison of optimal solution values is no longer valid since the models are being optimised over different (synthetic) reference distributions. We therefore report other in-sample statistics, such as (i) Mean, (ii) SD and (iii) Skewness: average in-sample mean, standard deviation and skewness of optimal return distributions over all 240 rebalances. Other reported in-sample statistics are:
-
(iv) \(\textit{ScTail}_{\alpha }\): the \(\alpha \)- “scaled” tail, defined as in Sect. 2 as the conditional expectation of the least \(\alpha *100\%\) of the outcomes.
-
(v) \(\textit{EP}_{\rho }\): Expected conditional profit at \(\rho \%\) confidence level, equivalent to CVaR\(_{\rho }\) but calculated from the right tail of the distribution. Let \(S^{\rho } = \lceil S (\rho /100) \rceil \). EP\(_{\rho }\) is defined as \(\frac{1}{S - S^{\rho }-1} \sum _{s=S^{\rho }}^{S} r^p_s\).
Also reported are the average in-sample (vi) Skewness, (vii) \(\textit{ScTail}_{\alpha }\) and (viii) \(\textit{EP}_{\rho }\) for the synthetic benchmark. As only \(\varDelta _{\gamma }\) was changed, we do not report the average in-sample mean and standard deviation for the benchmark as these values match the original in all cases.
We also compare in-sample solutions in terms of their SSD relation. Let Y be the optimal portfolio (with worst partial achievement \(\overline{\mathcal {V}}\)) that solves the enhanced indexation model and dominates the original reference distribution with respect to SSD. Accordingly, let \(Y'\) be the optimal porfolio (with worst partial achievement \(\overline{\mathcal {V}'}\)) that dominates the synthetic (improved) reference distribution. Let also \(R^Y = [r^Y_1 \le \cdots \le r^Y_S]\) and \(R^{Y'} = [r^{Y'}_1 \le \cdots \le r^{Y'}_S]\) be the ordered set of in-sample returns for Y and \(Y'\).
It is clear that if \(\overline{\mathcal {V}} \ne \overline{\mathcal {V}'}\), \(Y \not \succeq _{\text {SSD}} Y'\) and \(Y' \not \succeq _{\text {SSD}} Y\). If, for instance, \(Y' \succeq _{\text {SSD}} Y\), then \(Y'\) would have been chosen instead of Y as the optimal solution of the enhanced indexation model with the original reference distribution since \(\overline{\mathcal {V}'} > \overline{\mathcal {V}}\). If \(\overline{\mathcal {V}} = \overline{\mathcal {V}'}\), it is possible, albeit unlikely, that \(Y' \succeq _{\text {SSD}} Y\) or \(Y \succeq _{\text {SSD}} Y'\) - that could be the case where the mixed-integer programming model had multiple optima.
Assuming that most likely neither \(Y \succeq _{\text {SSD}} Y'\) nor \(Y' \succeq _{\text {SSD}} Y\), we can measure which solution is “closer” to dominating the other. For \(Y'\), we compute, for each rebalance, \(\mathcal {S}_{Y'} \subset \{1, ..., S\}\) where \(s \in \mathcal {S}_{Y'}\) if \(\text {Tail}_{\frac{s}{S}} R^{Y'} > \text {Tail}_{\frac{s}{S}} R^Y\), i.e. \(|\mathcal {S}_{Y'}|\) represents the number of times that the unconditional expectation of the least s scenarios of \(Y'\) is greater than the equivalent for Y. We also compute, for each rebalance, \(\mathcal {S}_{Y} \subset \{1, ..., S\}\) where \(s \in \mathcal {S}_{Y}\) if \(\text {Tail}_{\frac{s}{S}} R^{Y} > \text {Tail}_{\frac{s}{S}} R^{Y'}\).
The following columns are included in Table 4:
-
(ix) \(\overline{|\mathcal {S}_{Y'}|}\): Mean value of \(|\mathcal {S}_{Y'}|\) over all rebalances.
-
(x) \(\overline{|\mathcal {S}_{Y}|}\): Mean value of \(|\mathcal {S}_{Y}|\) over all rebalances.
From Table 4, we observe that increasing \(\varDelta _{\gamma }\) increases the in-sample skewness and also ScTail\(_{05}\) of the optimal distributions—which was expected, since increasing skewness reduces the left tail. We can also observe that the mean and standard deviation tend to decrease as we increase the skewness in the synthetic distribution. This decrease is very small or non-existent in the case of smaller deviations from the original skewness e.g. \(\gamma =1\) but more pronounced for larger values of \(\gamma \).
The skewness of the solution portfolios, although clearly increasing in line with increasing the skewness of the benchmark, is considerably below the skewness values set by the improved benchmark. The solution portfolios have on average much higher expected value and less variance than the improved benchmark.
The statistics for \(\hbox {EP}_{95}\) reach a peak somewhere between \(\varDelta _{\gamma } = 1\) and \(\varDelta _{\gamma } = 2\), and their values decrease for higher \(\varDelta _{\gamma }\). This might be due to the synthetic distribution having “unrealistic” properties if its third moment differs too much from that of the original distribution. We do observe, nevertheless, that increasing skewness also makes in-sample portfolios based on synthetic distributions “closer” to dominating those based on the original distribution, since \(\overline{|\mathcal {S}_{Y'}|}\) increases and \(\overline{|\mathcal {S}_{Y}|}\) decreases as \(\varDelta _{\gamma }\) grows.
We do not report the cardinality of the optimal portfolios as we have observed very little change in the number of stocks held due to changes in \(\varDelta _{\gamma }\).
Figure 3 highlights the differences between optimising over the original benchmark and over the synthetic benchmark. We compare, for the 150/50 case, histograms for the original benchmark distribution from the 180th rebalance (out of 240) and the equivalent synthetic benchmark distribution, where \(\varDelta _\gamma = 5\) and \(\varDelta _\sigma = 0\). We chose the 180th rebalance as the corresponding figures approximate the observed average properties. The histograms are in line with the average properties observed in Table 4. The left panel shows the difference in the benchmark distributions; the synthetic benchmark distribution has a reduced left tail, especially concerning the worst case scenarios, at the expense of having the “peak” slightly towards the left, as compared to the original benchmark. The right panel compares the return distributions of the optimal portfolios, obtained using the original and the synthetic benchmark. The portfolio based on the synthetic benchmark has a reduced left tail, at the expense of a marginally lower mean.

Left panel: original benchmark (\(\varDelta _\gamma = 0, \varDelta _\sigma = 0\)) and a synthetic benchmark with added skewness (\(\varDelta _\gamma = 5, \varDelta _\sigma = 0\)). Right panel: the distribution of 150/50 optimal portfolios obtained using the benchmarks on the left
5.3.2 Out-of-sample performance
Out-of-sample performance statistics for variations in \(\varDelta _{\gamma }\) are presented in both Table 5 and Fig. 4. Regarding the figure, we choose 120/20 portfolios and show the performance graphic for the index (FTSE100), the portfolio based on the original reference distribution and portfolios based on synthetic distributions where \(\varDelta _{\gamma } = \{1, 5\}\). The out-of-sample performance of the other 120/20 tested parameters (\(\varDelta _{\gamma } = \{2, 3, 4\}\)) was relatively similar to the ones displayed, hence for readability we did not include them in the graphic. The table, however, includes the full results.

Changing \(\varDelta _{\gamma }\), out-of-sample performance, 2010–2014
We observe that the volatility of out-of-sample returns tend to reduce as we optimise over synthetic distributions with higher skewness values. The mean returns and excess returns over the risk free rate tend to increase slightly (up to somewhere between \(\varDelta _{\gamma } = 1\) and \(\varDelta _{\gamma } = 2\)) and then start to drop. These results are consistent with observed in-sample statistics. Changing skewness had little impact in terms of drawdown and recovery from drops. While returns do tend to decrease for higher value of \(\varDelta _{\gamma }\), its reduced standard deviation might appeal to risk-averse investors. The best values of Sharpe and Sortino ratios are generally obtained when \(\varDelta _{\gamma } = 1\), 2 or 3. In particular, the 120/20 strategy with \(\varDelta _{\gamma }\)=1 or 2 seems to have the best risk-return characteristics.
5.4 Reshaping the reference distribution: modified standard deviation
In this section, we test how portfolios behave for different values of \(\varDelta _{\sigma }\). Since increasing skewness slightly seems to be the best choice, according to our results in the previous section, for the next tests we set \(\varDelta _{\gamma } = 1\).
We report results for \(\varDelta _{\sigma } = [-0.1, 0, 0.1, 0.3, 0.5]\); for example, if \(\varDelta _{\sigma } = 0.1\), the synthetic reference distribution will have a 10% increase in its standard deviation when compared to the original reference distribution.
5.4.1 In-sample results
Table 6 shows in-sample results for different values of \(\varDelta _{\sigma }\). We also display results for the original reference distribution (when \(\varDelta _{\sigma } = \varDelta _{\gamma } = 0\)). Apart from this case, only \(\varDelta _{\sigma }\) is changed. Due to this, when compared to Table 4, we replaced the Skewness column under In-sample benchmark performance by SD, that is, the average in-sample benchmark standard deviation.
We can see that increasing \(\varDelta _{\sigma }\) increases the standard deviation of the return distributions of optimal portfolios, but also increases their mean and skewness at the same time.
The standard deviation of the return distribution of optimal portfolios follows the same pattern as set by the improved benchmarks, in the sense that it increases (or decreases) with increased (or decreased) standard deviation of the benchmark. It is, on average, slightly lower compared to the standard deviation of the benchmark. Also, the optimal portfolios have consuderably better mean and CVaR values than their corresponding benchmarks.
For \(\varDelta _{\sigma } = -0.1\), we obtain portfolios whose return distributions have better risk characteristics in the form of lower standard deviation and higher tail value. On the other hand, their mean returns, EP\(_{95}\) and even skewness are lower. As we increase \(\varDelta _{\sigma }\), ScTail\(_{05}\) gets lower, but EP\(_{95}\) gets higher.
We also observe that, when increasing \(\varDelta _{\sigma }\), the portfolios obtained based on the original reference distribution are “closer” to dominating the portfolio obtained via the synthetic benchmark.
Once again, we do not report the cardinality of the optimal portfolios as very little alteration was observed due to changes in \(\varDelta _{\sigma }\).
Similarly to Figs. 3 and 5 shows the difference between optimising over the original and synthetic benchmarks, this time for varying standard deviation in addition to skewness. We compare, for the 150/50 case, the 180th rebalance of the original benchmark and the equivalent synthetic benchmark where \(\varDelta _\gamma = 1\) and \(\varDelta _\sigma = 0.5\). Again, the left panel compares the different benchmark distributions and the right panel compares the corresponding portfolios obtained when solving the model against each benchmark.
Increasing standard deviation leads to fatter left and right tails in both the synthetic benchmark (as compared to the original benchmark) and the distribution of the optimal portfolio (as compared to the portfolio optimised with the original benchmark). However, especially with the optimised portfolios, the tail “fattening” is much more pronounced on the right side. This is clearly a matter of choice: if an investor has a less risk-averse profile, than increasing the standard deviation of the benchmark will yield riskier but potentially more rewarding portfolios. Once again, the properties observed in the histograms are in line with the results in Table 6: as we increase \(\varDelta _\sigma \), we observe a slightly worse tail, but better mean and EP. The risk/return profile of in-sample portfolios could be adjusted by increasing standard deviation to increase potential return and, at the same time, increasing the skewness to reduce the probability of extreme losses.

Left panel: original benchmark (\(\varDelta _\gamma = 0, \varDelta _\sigma = 0\)) and a synthetic benchmark with added standard deviation and skewness (\(\varDelta _\gamma = 1, \varDelta _\sigma = 0.5\)). Right panel: distribution of optimal portfolios obtained using the benchmarks on the left
5.4.2 Out-of-sample performance
Figure 6 shows the performance graphic for the index (FTSE100), a 120/20 portfolio based on the original reference distribution and 120/20 portfolios based on synthetic distributions where \(\varDelta _{\gamma } = 1\) and \(\varDelta _{\sigma } \in \{-0.1, 0, 0.1, 0.3, 0.5\}\). From the graphic we can see that as we increase volatility and returns of in-sample portfolios, we also increase both for out-of-sample portfolios. The highest returns are obtained when \(\varDelta _{\sigma } = 0.5\), although this seems to be the portfolio with the highest variability. Performance graphics for other values of \(\alpha \) are similar, but not reported due to space constraints.

Changing \(\varDelta _{\sigma }\), out-of-sample performance, 2010–2014
Table 7 reports out-of-sample performance statistics. In accordance to our in-sample results, a higher value for \(\varDelta _{\sigma }\) implies higher returns but also higher risk. As an example, the portfolio obtained when \(\alpha = 0.5\) (150/50) and \(\varDelta _{\sigma } = 0.5\) had the highest final value (4.88) and the highest yearly excess return (37.52%), but also the highest standard deviation of returns (0.01782). As further measure of risk, the maximum drawdown also increased as we increase \(\varDelta _{\sigma }\).
The index itself, being equivalent to a highly-diversified portfolio, generally has lower volatility (0.00985) than portfolios composed of a smaller amount of assets . However, the portfolio obtained when \(\varDelta _{\sigma } < 0\) and \(\alpha = 0\) had a smaller standard deviation regardless of being composed of less assets. Furthermore, although its final value is not as high as those when \(\varDelta _{\sigma } \ge 0\), it is still much higher than that of the index, making it a potentially safer choice for investors accostumed to index-tracking funds.
We run the models for higher values of \(\varDelta _{\sigma }\), i.e. \(\varDelta _{\sigma }>0.5\) but due to space constraints we do not report the results here. It was observed that, after a certain level (\(\varDelta _{\sigma } > 0.6\)), out-of-sample returns tend to drop while standard deviation continues to increase. Parameters \(\varDelta _{\sigma }\) and \(\varDelta _{\gamma }\) should be adjusted according to investor constraints and aversion to risk.
In summary, using a benchmark distribution with a slightly lower standard deviation tends to provide lower returns on average but at the same time is a “safer” choice, having better risk characteristics. Increasing standard deviation of the benchmark is a somewhat riskier choice, but it can provide significantly higher returns.
6 Summary and conclusions
This paper is a natural sequel to our earlier work on the topic of enhanced indexation based on SSD criterion and reported in Roman et al. (2013). In that approach we computed SSD efficient portfolios that dominate (if possible) an index which is chosen as the benchmark, that is, the reference distribution. In this paper we introduce a modified / reshaped benchmark distribution with the purpose of obtaining improved SSD efficient portfolios, whose return distributions possess superior (desirable) properties.
The first step in reshaping the original benchmark is to increase its skewness. The amount by which skewness should be increased is specified by the decision maker and is stated as a proportion of the original skewness. Our numerical results show that, by using a reshaped benchmark with higher skewness, we indeed obtain SSD efficient portfolios with better, that is, shorter left tails, as measured in-sample by CVaR and skewness. On the other hand, if the skewness of the benchmark is excessively increased, the improvement in the left tail of the solution portfolio has adverse effects on the rest of the distribution, with lower returns on average and reduced right tail. We observed that as long as skewness is not increased excessively, the improvement in the left tail comes at no or little marginal cost for the rest of the distribution. We observed that, for an increase in the benchmark skewness of up to 100%, the improvement in the left tail of the solution portfolio is substantial and comes at virtually no cost to the rest of the return distribution. The out-of-sample results in this case are also considerably better than in the case of using the original benchmark.
We also experimented with a reshaped benchmark by changing the standard deviation by various amounts. We observed in Tables 6, 7 and Fig. 6 that reducing the benchmark standard deviation reflects in portfolios that have lower standard deviations and better tail characteristics, but also worse overall returns, both in-sample and out-of-sample (lower mean, skewness, Sharpe and Sortino ratios). Moreover, by increasing the benchmark standard deviation up to 30% of its original value, we obtained more volatile portfolios with better overall return characteristics, both in-sample and out-of-sample (higher mean, standard deviation, skewness, Sharpe and Sortino ratios). These results are consistent as they are reported for long-only as well as for long-short combinations (120/20 and 150/50).
We also observed consistent better performance, both in-sample and out-of-sample, of long-short portfolios as compared to long-only portfolios.
Overall, our numerical experiments have shown that, by reshaping the return distribution of a financial index and using it as a benchmark in long-short SSD models, it is possible to obtain superior portfolios with better in-sample and out-of-sample performance.
References
Bawa VS (1975) Optimal rules for ordering uncertain prospects. J Financ Econ 2(1):95–121
Dentcheva D, Ruszczynski A (2003) Optimization with Stochastic dominance constraints. SIAM J Optim 14(2):548–566
Dentcheva D, Ruszczynski A (2006) Portfolio optimization with Stochastic dominance constraints. J Bank Finance 30(2):433–451
Dentcheva D, Ruszczynski A (2010) Inverse cutting plane methods for optimization problems with second-order stochastic dominance constraints. Optim J Math Progr Oper Res 59(3):323–338
di Bartolomeo D (2000) The enhanced index fund as an alternative to indexed equity management. Northfield Information Services, Boston
Fábián C, Mitra G, Roman D (2011a) Processing second-order stochastic dominance models using cutting-plane representations. Math Progr 130(1):33–57
Fábián C, Mitra G, Roman D, Zverovich V (2011b) An enhanced model for portfolio choice with SSD criteria: a constructive approach. Quant Finance 11(10):1525–1534
Hadar J, Russell W (1969) Rules for ordering uncertain prospects. Am Econ Rev 59(1):25–34
Hodder JE, Jackwerth JC, Kolokolova O (2015) Improved portfolio choice using second order stochastic dominance. Rev Finance 19(1):1623–1647
IBM ILOG CPLEX Optimizer (2015). https://www-01.ibm.com/software/commerce/optimization/cplex-optimizer/. Accessed 3 Sept 2015
Javanmardi L, Lawryshy Y (2016) A new rank dependent utility approach to model risk averse preferences in portfolio optimization. Ann Oper Res 237(1):161–176
Kolen MJ, Brennan RL (1995) Test equating: methods and practices. Springer, New York
Kopa M, Post T (2015) A general test for SSD portfolio efficiency. OR Spectr 37(1):703–734
Kuosmanen T (2004) Efficient diversification according to stochastic dominance criteria. Manag Sci 50(10):1390–1406
Levy H (1992) Stochastic dominance and expected utility: survey and analysis. Manag Sci 38(4):555–593
Ogryczak W, Ruszczynski A (2002) Dual stochastic dominance and related mean-risk models. SIAM J Optim 13(1):60–78
Padberg M, Rinaldi G (1991) A branch-and-cut algorithm for resolution of large scale of symmetric traveling salesman problem. SIAM Rev 33:60–100
Post T (2003) Empirical tests for stochastic dominance efficiency. J Finance 58(5):1905–1931
Post T, Fang Y, Kopa M (2015) Linear tests for DARA stochastic dominance. Manag Sci 61(1):1615–1629
Post T, Kopa M (2013) General linear formulations of stochastic dominance criteria. Eur J Oper Res 230(2):321–332
Press WH, Flannery BP, Teukolsky SA, Vetterling WT (1988) Numerical recipes in C: the art of scientific computing. Cambridge University Press, New York, NY
R Core Team (2015) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. https://www.R-project.org/
Roman D, Darby-Dowman K, Mitra G (2006) Portfolio construction based on stochastic dominance and target return distributions. Math Progr 108(2):541–569
Roman D, Mitra G, Zverovich V (2013) Enhanced indexation based on second-order stochastic dominance. Eur J Oper Res 228(1):273–281
Sharpe WF (1966) Mutual fund performance. J Bus 39(1):119–138
Sortino FA, Price LN (1994) Performance measurement in a downside risk framework. J Invest 3(3):59–64
Thomson Reuters Datastream (2014). http://online.thomsonreuters.com/ Datastream/. Accessed 3 Sept 2015
Wang T, Kolen MJ (1996) A quadratic curve equating method to equate the first three moments in equipercentile equating. Appl Psychol Meas 20(1):27–43
Whimore GA, Findlay MCE (1978) Stochastic dominance: an approach to decision-making under risk. Lexington Books, Lanham
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Valle, C.A., Roman, D. & Mitra, G. Novel approaches for portfolio construction using second order stochastic dominance. Comput Manag Sci 14, 257–280 (2017). https://doi.org/10.1007/s10287-017-0274-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-017-0274-9