
Abstract
The bivariate Fay–Herriot model is an area-level linear mixed model that can be used for estimating the domain means of two correlated target variables. Under this model, the dependent variables are direct estimators calculated from survey data and the auxiliary variables are true domain means obtained from external data sources. Administrative registers do not always give good auxiliary variables, so that statisticians sometimes take them from alternative surveys and therefore they are measured with error. We introduce a variant of the bivariate Fay–Herriot model that takes into account the measurement error of the auxiliary variables and we give fitting algorithms to estimate the model parameters. Based on the new model, we introduce empirical best predictors of domain means and we propose a parametric bootstrap procedure for estimating the mean squared error. We finally give an application to estimate poverty proportions and gaps in the Spanish Living Condition Survey, with auxiliary information from the Spanish Labour Force Survey.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Survey sample sizes are generally calculated to obtain precise direct estimates of target parameters in planned territories, but they might be not large enough for obtaining reliable estimates in unplanned smaller regions or small areas. Small area estimation (SAE) theory introduces indirect model-based or model-assisted estimators for treating these situations. SAE is an important part of statistical inference in finite populations with applications to social and economic statistics. The monograph of Rao and Molina (2015) contains a general description of SAE.
When auxiliary variables related to the target variable are available at the small area level, the most widely used area-level model in SAE is the Fay–Herriot (FH) model. This model was first proposed by Fay and Herriot (1979) to obtain estimates of mean per capita income in U.S. small areas using survey data. Esteban et al. (2012a, b), Marhuenda et al. (2013) and Morales et al. (2015) apply variants of the basic FH model to the small area estimation of poverty indicators in the Spanish Living Condition Survey (SLCS), with auxiliary information from the Spanish Labour Force Survey (SLFS).
If there is more than one target variables, multivariate area-level mixed models can take into account their correlations. These correlations can be an important additional information for the estimation. Fay (1987) and Datta et al. (1991) showed that small area estimators obtained from multivariate models have, in general, better precision than the ones obtained from univariate models for each response variable. Molina et al. (2007) and López-Vizcaíno et al. (2013), López-Vizcaíno et al. (2015) made use of this idea and applied it to estimate labour force indicators. Several other authors have investigated and applied multivariate Fay–Herriot (MFH) models in the SAE setup, e.g. Datta et al. (1996), González-Manteiga et al. (2008), Porter et al. (2015) or Benavent and Morales (2016).
Under the MFH model, the values of the dependent variable are direct estimates calculated from survey data and the auxiliary variables are “true” domain means obtained from administrative registers. However, it is not always possible to find good auxiliary variables in administrative registers and MFH models are sometimes applied with auxiliary variables measured with errors. Oftentimes, direct estimates obtained from a sample of a different survey are used. The aforementioned applications do not take into account the measurement error of the auxiliary variables. This manuscript addresses this practical issue.
Concerning the contributions to area-level linear mixed models with covariates measured with error, Ybarra and Lohr (2008) introduced a functional measurement error model where the underlying true values of the covariates are fixed but unknown quantities. Their model can be viewed as a generalization of the Fay–Herriot model. They also introduced a new small area estimator that accounts for sampling variability in the auxiliary information, and derive its properties, in particular showing that it is approximately unbiased. They applied their estimator to predict quantities measured in the U.S. National Health and Nutrition Examination Survey, with auxiliary information from the U.S. National Health Interview Survey. Marchetti et al. (2015) presented an application where measures derived from Big Data are used as covariates in a Fay–Herriot model to estimate poverty indicators, accounting for the presence of measurement error in the covariates. Polettini and Arima (2015) introduced predictors of small area means based on area-level linear mixed models with covariates perturbed for disclosure limitation.
Adopting a Bayesian approach, Arima et al. (2015) rewrote the Ybarra-Lohr measurement error model as a hierarchical model and introduced Bayes predictors. This last work was later extended by Arima et al. (2017) proposing multivariate Fay–Herriot Bayesian predictors of small area means under functional measurement error. On the other hand, Burgard et al. (2019) followed a likelihood-based approach for extending the Ybarra-Lohr model. They proposed residual maximum likelihood (REML) estimators of the model parameters and introduced empirical best predictors and a mean squared error analytical approximation.
Concerning unit-level models, further contributions to the Bayesian SAE literature on measurement error models are Ghosh et al. (2006), Ghosh and Sinha (2007), Torabi et al. (2009), Datta et al. (2010) and Arima et al. (2012). More recently, Torabi (2013) presented an application of data cloning conducting a frequentist analysis of GLMM with covariates subject to the measurement error model.
This paper introduces a three-step bivariate Fay–Herriot model by assuming that the vector of true domain means of auxiliary variables differ from the corresponding vector of direct estimators in a zero-mean multivariate normally distributed random error. The introduced functional measurement error model can be considered as a multivariate adaptation of the Ybarra-Lohr univariate model to a parametric inference setup with multivariate normal measurement errors. The proposed approach can also be considered as the non Bayesian counterpart of the statistical methodology introduced by Arima et al. (2017).
Ybarra and Lohr (2008) did not assume the normality of the measurement errors and they proposed a weighted least squared approach to estimate the model parameters. Arima et al. (2017) assumed the multivariate normality of the measurement errors and they considered a Bayesian approach. They simulated the posterior distributions of the model parameters and calculated the hierarchical Bayes predictors of domain means by applying Markov Chain Monte Carlo algorithms. This paper preserves the likelihood modelling of Arima et al., but applies a non Bayesian approach. The main target is to calculate empirical best predictors of domain means and to estimate the corresponding mean squared errors (MSE).
Assuming that measurement errors have a multivariate normal distribution is a natural choice in practice, as due to the central limit theorem, the distribution of the auxiliary variable estimators has an asymptotic multivariate normal distribution. This adaption, besides giving another motivation of the empirical best predictor provided by Ybarra and Lohr (2008), has two mayor advantages. First, we derive Fisher-scoring algorithms for calculating maximum likelihood (ML) and pseudo-residual maximum likelihood (pseudo-REML) estimators of model parameters. Second, we provide a parametric bootstrap procedure for estimating the mean squared errors.
The rest of the paper is organized as follows. Section 2 introduces the measurement error bivariate Fay–Herriot model. Section 3 derives the best predictors of random effects and target domain parameters. It also calculates the MSEs of the best predictors. Section 4 presents the relative efficiency matrix of the best predictors that takes into account that variables are measured with error compared to the corresponding ones that ignores this information. Section 5 proposes a parametric bootstrap procedure for estimating the mean squared error of the empirical best predictors. Section 6 describes the pseudo-REML method for estimating the model parameters. Section 7 carries out simulation experiments to investigate the behavior of the pseudo-REML fitting algorithm, the empirical best predictors and the bootstrap estimator of the mean squared error of the empirical best predictors. Section 8 gives an application to real data where the target is the small area estimation of poverty proportions and gaps in the SLCS, with auxiliary information from the SLFS. Sections 9 summarizes some conclusions. The paper contains three appendixes that are provided as supplementary file. Appendix A gives some auxiliary results for the calculation of the best predictors and their MSEs. Appendix B shows some tables with results of the application to SLCS data. Appendix C presents the Fisher scoring algorithm for calculating the ML estimators of the model parameters.
2 The measurement error bivariate Fay–Herriot model
Let U be a finite population partitioned into D domains \(U_1,\ldots ,U_D\). Let \(\mu _{d}=\left( \mu _{d1},\mu _{d2}\right) ^{\prime }\) be a vector of characteristics of interest in the domain d and let \({y}_{d}=\left( {y}_{d1},{y}_{d2}\right) ^{\prime }\) be a vector of direct estimators of \(\mu _d\) calculated by using the data of the target survey sample. The measurement error bivariate Fay–Herriot (MEBFH) model is defined in three steps. The first step indicates that direct estimators are unbiased and follow the sampling model
where the vectors \({e}_{d}=(e_{d1},e_{d2})^\prime \sim N_2\left( 0,{V}_{ed}\right) \) are independent and the \(2\times 2\) covariance matrices \({V}_{ed}\) are known. In most cases, \({V}_{ed}\) is taken to be the design-based covariance matrix of the direct estimator \(y_d\), \(d=1,\ldots ,D\).
In the second step the true area characteristic \(\mu _{dk}\) is assumed to be linearly related to \(p_k+q_k\) explanatory variables, \(k=1,2\), \(d=1,\ldots ,D\). Let \(\tilde{x}_{dk}^\prime =(\tilde{x}_{dk1},\ldots ,\tilde{x}_{dkp_k})\) be a row vector containing the true aggregated (population) values of \(p_k\) explanatory variables for \(\mu _{dk}\) and let \(\tilde{X}_{d}=\text{ diag }(\tilde{x}_{d1}^\prime ,\tilde{x}_{d2}^\prime )\) be a \({2\times p}\) block-diagonal matrix with \(p=p_1+p_2\). Let \(\lambda _{k}=(\lambda _{k1},\ldots ,\lambda _{kp_k})^\prime \) be a column vector of size \(p_k\) containing regression parameters for \(\mu _{dk}\) and let \(\lambda =\left( \lambda _{1}^{\prime },\lambda _{2}^{\prime }\right) ^{\prime }_{p\times 1}\). Let \(z_{dk}^\prime =(z_{dk1},\ldots ,z_{dkq_k})\) be a row vector containing the true aggregated (population) values of \(q_k\) explanatory variables for \(\mu _{dk}\) and let \(Z_{d}=\text{ diag }(z_{d1}^\prime ,z_{d2}^\prime )\) be a \({2\times q}\) block-diagonal matrix with \(q=q_1+q_2\). Let \(\eta _{k}=(\eta _{k1},\ldots ,\eta _{kq_k})^\prime \) be a column vector of size \(q_k\) containing regression parameters for \(\mu _{dk}\) and let \(\eta =\left( \eta _{1}^{\prime },\eta _{2}^{\prime }\right) ^{\prime }_{q\times 1}\).
The linking model is
where the vectors \({u}_{d}\)’s are independent of the vectors \({e}_{d}\)’s. The \(2\times 2\) covariance matrices \({V}_{ud}\) depend on 3 unknown parameters, \(\theta _{1}=\sigma _{u1}^2\), \(\theta _{2}=\sigma _{u2}^2\) and \(\theta _{3}=\rho \), i.e.
This manuscript assumes that the \(\tilde{x}_{dk}\)’s are unknown random vectors that are predicted from independent data sources. These data sources could be administrative registers or other surveys with larger sample sizes than the target survey. For \(k=1,2\), let us define the random measurement error vectors \(v_{dk}^\prime =(v_{dk1},\ldots ,v_{dkp_k})\). We assume that the vectors \({v}_{d}=(v_{d1}^\prime ,v_{d2}^\prime )^\prime \) are independent with distributions \({v}_{d}\sim N_p(0,\Sigma _d)\) and known \(p\times p\) covariance matrices
The third step considers the functional measurement error model
where \(x_{dk}^\prime \) is a row vector containing the unbiased predictors of the components of \(\tilde{x}_{dk}^\prime \) and the vectors \({v}_{d}\) and \({x}_{d}=(x_{d1}^\prime ,x_{d2}^\prime )^\prime \), \(d=1,\ldots ,D\), are independent. In most cases, \(x_{dk}\) is a vector of direct estimators calculated from data of a different survey and \(\Sigma _{dk_1k_2}\) is taken to be the design-based covariance matrix of vectors \(x_{dk_1}\) and \(x_{dk_2}\), \(k_1,k_2=1,2\).
Let us also define the \(2\times p\) block diagonal matrices \(B_d=\text{ diag }(\lambda _{1}^\prime ,\lambda _{2}^\prime )\) and \({X}_{d}=\text{ diag }({x}_{d1}^\prime ,{x}_{d2}^\prime )\).
The measurement error bivariate Fay–Herriot (MEBFH) model can be expressed as a single model in the form
or in the matrix form
where \(B=\underset{1\le d \le D}{\hbox {diag}}(B_d)\), \(X=\underset{1\le d \le D}{\hbox {col}}({X}_{d})\), \(Z=\underset{1\le d \le D}{\hbox {col}}({Z}_{d})\) and
We finally assume that matrices \(V_{ud}\), \(\Sigma _d\) and \(V_{ed}\) are invertible and that \(x_d\), \(v_d\), \(u_d\), \(e_d\), \(d=1,\ldots ,D\), are independent, but we only introduce inference procedures conditionally on X. If there are no measurement errors, then the \(v_d\)’s are null vectors and the bivariate Fay–Herriot (BFH) model is obtained as a special case of (4). The MEBFH model can be considered as a multivariate generalization of the Fay–Herriot model with measurement error studied by Ybarra and Lohr (2008) or by Burgard et al. (2019). This approach was also considered by Arima et al. (2017) in a Bayesian context. Note that the MEBFH model is not a linear mixed model as the matrix B depends on the vector \(\lambda \) of model parameters. Therefore, the MEBFH model cannot be expressed in the standard form \(Y=X\beta +Zu+e\).
It holds that
Therefore, \(V_u=\text{ var }(u)=\underset{1\le d \le D}{\hbox {diag}}(V_{ud})\), \(V_e=\text{ var }(e)=\underset{1\le d \le D}{\hbox {diag}}(V_{ed})\) and \(\text{ var }(Bv)=\underset{1\le d \le D}{\hbox {diag}}(V_{\lambda d})\). Conditioned to \(x_d\), \(d=1,\ldots ,D\), the covariance matrix of y is
Further, it holds that \(y_d|_{x_d}\sim N_2\big (Z_d\eta +X_d\lambda ,V_{\lambda d}+V_{ud}+V_{ed}\big )\),
3 Best predictors under the MEBFH model
This section derives the best predictors (BP) of the random effects \(v_d\) and \(u_d\) and of the target parameter \(\mu _d\). It also calculates variances and expectations of cross products. The proofs of the following propositions are based on the properties of the multivariate normal distribution. We recall that the kernel of the n-variate normal distribution is
The first two propositions deal with the BP of \(v_d\) and its basic properties.
Proposition 1
Under model (4), the best predictor of \(v_d\) is
where
Proof
The conditional distribution of \(v_d\), given the estimators \(x_d\) and \(y_d\), is
Therefore, we have
We have proved that \(f(v_d|x_d,y_{d})\) is a multivariate normal distribution with parameters
By applying Lemma A.1 of Appendix A in the supplementary file, the results follows. \(\square \)
Proposition 2
Under model ( 4 ), it holds that \(E[\hat{v}_d^{bp}|x_d]=0\) and
Proof
We recall that \(y_d-Z_d\eta -X_d\lambda =B_dv_d+u_d+e_d\). Therefore, we have
\(\square \)
The following two propositions derive the BP of \(u_d\), show that it is predictively unbiased and calculate its variance.
Proposition 3
Under model ( 4 ), the best predictor of \(u_d\) is
Proof
The conditional distribution of \(u_d\), given \(x_d\) and \(y_d\), is
Therefore \(f(u_d|x_d,y_{d})\) is a multivariate normal distribution with parameters
\(\square \)
Proposition 4
Under model (4), it holds that \(E[\hat{u}_d^{bp}|x_d]=0\) and
Proof
As \(y_d-Z_d\eta -X_d\lambda =B_dv_d+u_d+e_d\), we have
\(\square \)The following two propositions give the best predictor of \(\mu _d\) and its MSE. This section ends by defining the empirical best predictor of \(\mu _d.\)
Proposition 5
Under model ( 4 ), the best predictor (MEBFH-BP) of \(\mu _d\) is
Proof
As \(\mu _d=Z_d\eta +X_{d}\lambda +B_dv_d+u_d\), \(\Psi _d=\Sigma _d-\Sigma _d\,B_d^{\prime }(V_{\lambda d}+V_{ud}+V_{ed})^{-1}B_d\Sigma _d\) and \(V_{\lambda d}=B_d\Sigma _dB_d^{\prime }\), we have
\(\square \)
Proposition 6
Under the model ( 4 ), the MSE of \(\hat{\mu }_d^{bp}\) is
Proof
It hold that
where \(E\big [\mu _d\mu _d^\prime |x_d\big ]=V_{\lambda d}+V_{ud}\).
The remaining expectations are calculated in Propositions A.2 and A.3 from Appendix A in the supplementary file. By doing the corresponding substitutions, the result follows. \(\square \)
In practice, the BPs are not calculable because the model parameters are not known.
Under model (4), the empirical best predictors (MEBFH-EBP) of \(v_d\), \(u_d\) and \(\mu _d\) are obtained from formulas (6), (7) and (8) by plugging estimators \(\hat{\varvec{\beta }}\), \(\hat{\sigma }_{u1}^2\), \(\hat{\sigma }_{u2}^2\) and \(\hat{\rho }\) in the place of \(\varvec{\beta }\), \(\sigma _{u1}^2\), \(\sigma _{u2}^2\) and \(\rho \) respectively. The MEBFH-EBP of \(\mu _d\) is
Section 6 introduces the maximum likelihood and the pseudo-REML of estimators of model parameters. In the application to real data, the MEBFH-EBP of \(\mu _d\) is calculated by plugging pseudo-REML estimators.
4 Relative efficiency matrix of best predictors
An important question is, when using estimated auxiliary variables, how much efficiency can be gained by using the MEBFH-BP instead of the BFH-BLUP. We recall that MEBFH-BP denotes the BP of \(\mu _d\) calculated by assuming that the MEBFH model is the true model. Similarly, BFH-BLUP denotes the best linear unbiased predictor of \(\mu _d\) calculated by assuming that the BFH model (with no measurement errors) is the true model. The gain in efficiency is measured as the relative reduction of the MSE when using the MEBFH-BP instead of the BFH-BLUP, under the assumption that all model parameters are known and the true model is MEBFH.
We first derive the BFH-BLUP of \(\mu _d\) and its MSE under the true MEBFH model. If we equate \(V_\lambda \) to the null matrix in (8), we obtain the BFH-BLUP, i.e.
where \( \xi _d=y_d-Z_d\eta -X_d\lambda =B_dv_d+u_d+e_d. \) The prediction error of the BFH-BLUP is
Under the MEBFH model, the BFH-BLUP is predictively unbiased. It holds that
Under the MEBFH model, we have
Under the MEBFH model, with all model parameters known, the MSE of the BFH-BLUP is
If all MEBFH model parameters are known, the relative efficiency matrix of the MEBFH-BP compared to the BFH-BLUP is
where the division of the \(2\times 2\) matrices \(MSE(\hat{\mu }_d^{bp}|x_d)\) and \(MSE(\hat{\mu }_d^{bp_0}|x_d)\) is done component by component. We are mainly interested in the diagonal components \(RE_{d11}\) and \(RE_{d11}\); this is to say, in the relative efficiencies when predicting \(\mu _{d1}\) and \(\mu _{d2}\) respectively. We further remark that \(RE_d\) does not depend on \(x_d\), \(\eta \) or D.
In what follows, we presents some numerical calculations of the relative efficiencies of the MEBFH model with respect to the BFH model. Let us consider a MEBFH model (4) with \(q_1=q_2=p_1=p_2=1\), so that the model elements are \(Z_d=\text{ diag }(z_{d1},z_{d2})\), \(\eta =(\eta _1,\eta _2)^\prime \), \(X_d=\text{ diag }(x_{d1},x_{d2})\), \(\lambda =(\lambda _1,\lambda _2)^\prime \), \(B=\text{ diag }(\lambda _1,\lambda _2)\), \(v_d=(v_{d1},v_{d2})^\prime \), \(u_d=(u_{d1},u_{d2})^\prime \), \(e_d=(e_{d1},e_{d2})^\prime \). For \(d=1,\ldots ,D\), define \(\tau _{d11}=\Sigma _{d11}\), \(\tau _{d21}=\tau _{d12}=\Sigma _{d12}\), \(\tau _{d22}=\Sigma _{d22}\) and
where \(\tau _{d12}=\rho _{\tau }\tau _{d11}^{1/2}\tau _{d22}^{1/2}\). Take \(\lambda _1=\lambda _2=1\), \(\tau =\tau _{d11}=\tau _{d22}\), \(\theta _1=1\) and \(\theta _2=3/2\).
Table 1 presents the relative efficiencies \(RE_{d11}\) (top) and \(RE_{d22}\) (bottom) for the 45 scenarios 1A,...,9E. All the scenarios take \(\theta _1=1\), \(\theta _2=3/2\). The row cases A, B, C, D, E take \(\tau =1.81, 1.41, 1.01, 0,61, 0.21\) respectively. Scenarios 1–9 take the parameters \(\rho _{\tau }\), c and \(\theta _3\) given by the rows 2, 3 and 4 of Table 1. We observe that the relative efficiencies decrease as \(\tau \) increases from case E to case A. This is to say, the greater the measurement error variance of the auxiliary variables is, the greater gain of efficiency is obtained by using the best predictor based on the MEBFH model. On the other hand, if the measurement errors are negligible (\(\tau \approx 0\)), then the gain of efficiency almost null.
The greater values of \(RE_{d11}\) and \(RE_{d22}\) are in the column case 5. Therefore, the efficiency gain when using the MEBFH model is smaller when the correlations \(\rho _{\tau }\), c and \(\theta _3\) of the components of the measurement errors \(v_d\), the sampling errors \(e_d\) and the random effects \(u_d\) respectively, are close to zero. In the limit \(\rho _{\tau }=c=\theta _3=0\), we get two independent measurement error univariate Fay–Herriot models and it is not possible to transport information from one component to other.
Figure 1 plots the relative efficiencies \(RE_{d11}\) and \(RE_{d22}\) for \(\theta _3\in \{-0.75,0.85\}\) and any \(\rho _{\tau }\) and c. The case \(\theta _3=-0.75\) covers the Scenarios 2A and 3A and any other scenario with \(\theta _3=-0.75\), \(-0.5\le \rho _\tau \le 0.5\) and \(-0.5\le c\le 0.5\). The case \(\theta _3=0.85\) contains the scenarios 8A and 9A as individual points in the right-hand printed surfaces.
In summary, Table 1 and Figure 1 show some scenarios where the MSE of the MEBFH-BP is around a half of the MSE of the BFH-EBLUP. They also show some other scenarios where the gain of efficiency is rather small. This information is useful to decide in what situations it is more profitable to use the more complex EBP based on the MEBFH model.

Relative efficiencies for \(\tau =1.81\), \(\theta _1=1\), \(\theta _2=3/2\)
5 Mean squared error estimation
Obtaining an approximation to the MSE of the EBP of \(\mu _d\) under the MEBFH model requires tedious calculations. Unlike the case of no measurement errors, the obtained approximation will be quite awkward and not very useful to introduce analytic MSE estimators. This is why we propose applying a parametric bootstrap procedure, like the one introduced by González-Manteiga et al. (2008) and later extended by González-Manteiga et al. (2010) to semi-parametric Fay–Herriot models.
Let \(\psi =(\eta ^\prime ,\lambda ^\prime ,\theta ^\prime )^\prime \) be the vector of model parameters, where \(\theta =(\sigma _{u1}^2,\sigma _{u2}^2,\rho )^\prime \). The following parametric bootstrap procedure estimates \(MSE(\hat{\mu }^{ebp}_d)\).
-
1.
Calculate the estimates \(\hat{\psi }\) and \(\hat{V}_{ud}=V_{ud}(\hat{\psi })\) by using the data \((y_d,Z_d,X_d)\), \(d=1,\ldots ,D\).
-
2.
Repeat B times
-
2.1.
For \(d=1,\ldots ,D\), generate \(u_d^{*(b)}\sim N_2(0,\hat{V}_{ud})\), \(e_d^{*(b)}\sim N_2(0,V_{ed})\) \({v}_{d}^{*(b)}\sim N_2(0,\Sigma _d)\), \(y_d^{*(b)}=\mu _d^{*(b)}+e_{d}^{*(b)}\) and\(\mu _d^{*(b)}=Z_d\hat{\eta }^{(i)}+X_d\lambda ^{(i)}+ \text{ diag }(\hat{\lambda }_1^{(i)},\hat{\lambda }_2^{(i)})v_d^{*(b)}+u_d^{*(b)}\).
-
2.2.
Calculate the estimator \(\hat{\psi }^{*(b)}\) by using the data \((y_d^{*(b)},Z_d,X_d)\), \(d=1,\ldots ,D\).
-
2.3
Calculate the EBPs \(\hat{\mu }^{*(b)}_{dk}\), \(d=1,\ldots ,D\), \(k=1,2\), under the model of Step 2.1.
-
2.1.
-
3
For \(d=1,\ldots ,D\), \(k=1,2\), calculate the MSE estimator of the EBP; i.e.
$$\begin{aligned} mse_{dk}^{*}=\frac{1}{B}\sum _{b=1}^B\big (\hat{\mu }^{*(b)}_{dk}-\mu ^{*(b)}_{dk}\big )^2. \end{aligned}$$
6 Estimation of model parameters
We consider two methods for estimating \(\eta \), \(\lambda \), \(\sigma _{u1}^2\), \(\sigma _{u2}^2\) and \(\rho \) under model (4): (1) pseudo-residual maximum likelihood, and (2) maximum likelihood. Both method are based on the distribution of y|X. Appendix C in the supplementary file gives the Fisher-scoring algorithm to calculate the maximum likelihood estimators of the model parameters. However, we we do not implement this last algorithm because it has a greater computational complexity. This section describes the pseudo-residual maximum likelihood method.
ML estimators of model parameters have well known asymptotic properties. Under regularity conditions on the auxiliary variables, they are consistent and asymptotically normal. The Fisher-scoring algorithm maximizes the log-likelihood of y|X by solving the corresponding system of nonlinear equation, i.e. first partial derivatives equated to zero. It is a system with \(p+q+3\) equations and the Fisher-scoring algorithm inverts matrices of that dimension. If p or q are big, then the algorithm speed decreases and it might have convergence problems when the number of domains D is not big enough.
The REML estimators of the parameters of a linear mixed model are quite attractive. They have similar good asymptotic properties as ML estimators, but their calculation has a lower computational cost because the REML log-likelihood involves only the variance component parameters. Nevertheless, the MEBFH model is not a linear mixed model and the REML method is thus not applicable. This is why, we introduce pseudo-REML approach by treating the components of matrix \(B_d\) in (4) as known constants. In that case, the MEBFH model becomes a linear mixed model and the REML method can be applied yielding to the maximization of the derived REML log-likelihood. However, the components of \(B_d\) depends on the unknown vector of parameters \(\lambda \) and, therefore, we are not applying the REML method but a pseudo-REML approach. The small sample properties of the pseudo-REML are empirically investigated in Simulation 1.
Let us define \({T}=[Z,X]=\underset{1\le d \le D}{\hbox {col}}({T}_{d})\), \({T}_{d}=[Z_d,X_d]\) and \(\beta =(\eta ^\prime ,\lambda ^\prime )^\prime \), so that model (4) can be written in the form
The pseudo-REML log-likelihood of model (12) is
where \(\theta =(\theta _1,\theta _2,\theta _3)\), \(\theta _1=\sigma _{u1}^2\), \(\theta _2=\sigma _{u2}^2\), \(\theta _3=\rho \), \({P}{V}{P}={P}\), \({P}{{T}}=0\), \({P}={V}^{-1}-{V}^{-1}{{T}}({{T}}^{\prime }{V}^{-1}{{T}})^{-1}{{T}}^{\prime }{V}^{-1}\), and V is defined in (5). By applying the formulas
we calculate the first partial derivatives of \({l}_{reml}\) with respect to \(\theta _{\ell }\), i.e.
Let us define \(G=V^{-1}{T}({T}^{\prime }V^{-1}{T})^{-1}\), so that \(P=(I-{G}{{T}}^{\prime }){V}^{-1}=V^{-1}(I-{T} G^\prime )\). The first partial derivatives of \(P={V}^{-1}-{V}^{-1}{{T}}({{T}}^{\prime }{V}^{-1}{{T}})^{-1}{{T}}^{\prime }{V}^{-1}\) with respect to \(\theta _{\ell }\) are
Therefore, the score vector for \(\ell =1,2,3\) is
where \(P=P(\theta ,\beta )=\big (P_{d_1d_2}\big )_{d_1,d_2=1,\ldots ,D}\), \(V_\ell =V_\ell (\theta )=\frac{\partial {V}}{\partial \theta _{\ell }}=\underset{1\le d \le D}{\hbox {diag}}({V}_{ud\ell })\) and
For \(\ell =1,2,3\), we have
For \(a,b=1,2,3\), we have
For \(\ell =1,2,3\), we have
For \(a,b=1,2,3\), the second partial derivatives of the REML log-likelihood function are
where the last equality follows from the fact that \(V_\ell \) is symmetric, \(\ell =1,2,3\). By changing the sign, taking expectations and applying \(P{T}=0\), \(PV=I-V^{-1}{T} Q{T}^\prime \) and the formula
we get the components of the Fisher information matrix, i.e.
Therefore, the Fisher information matrix is
The trace of \({P}{V}_a{P}{V}_b\) can be calculated as
The pseudo-REML Fisher-scoring algorithm is
-
1.
Set the initial values \(\beta ^{(0)}\), \(\theta ^{(0)}\), and \(\varepsilon _j>0\), \(j=1,\ldots ,p+q+3\).
-
2.
Repeat the following steps until the tolerance or the boundary conditions are fulfilled.
-
(a)
Updating equation for \(\theta \): Do \(\theta ^{(i+1)}=\theta ^{(i)}+{F}^{-1}(\theta ^{(i)},\beta ^{(i)}){S}(\theta ^{(i)},\beta ^{(i)})\).
-
(b)
Boundary condition: If \(\theta _1^{(i+1)}>0\), \(\theta _2^{(i+1)}>0\) and \(\big |\theta _3^{(i+1)}\big |<1\), continue. Otherwise, do \(\hat{\theta }=\theta ^{(i)}\) and stop.
-
(c)
Updating equation for \(\beta \):Do \(\beta ^{(i+1)}=\big ({{T}}^\prime {V}^{-1}(\theta ^{(i+1)},\beta ^{(i)}){{T}}\big )^{-1}{{T}}^\prime {V}^{-1}(\theta ^{(i+1)},\beta ^{(i)})y\).
-
(d)
Tolerance condition: If \(\big |\theta _\ell ^{(i+1)}-\theta _\ell ^{(i)}\big |<\varepsilon _{p+q+\ell }\), \(\big |\beta _j^{(i+1)}-\beta _j^{(i)}\big |<\varepsilon _j\), \(j=1,\ldots ,p+q\), \(\ell =1,2,3\), do \(\hat{\theta }_\ell =\theta _\ell ^{(i+1)}\), \(\hat{\beta }=\beta ^{(i+1)}\) and stop. Otherwise, continue.
-
(a)
-
3.
Output: \(\hat{\theta }\), \(\hat{\beta }\), \({F}^{-1}(\hat{\theta },\hat{\beta })\).
The asymptotic distributions of the REML estimators \(\hat{\theta }\) and \(\hat{\beta }\),
can be used to construct \((1-\alpha )\)-level confidence intervals for the components \(\theta _{\ell }\) of \(\theta \) and \(\beta _j\) of \(\beta \), i.e.
where \({F}^{-1}(\hat{\theta },\hat{\beta })=(\nu _{ab})_{a,b=1,2,3}\), \(({{T}}^{\prime }{V}^{-1}(\hat{\theta },\hat{\beta }){{T}})^{-1}=(g_{ab})_{a,b=1,\ldots ,p+q}\) and \(z_{\alpha }\) is the \(\alpha \)-quantile of the N(0, 1) distribution. For \(\hat{\beta }_j=\beta _0\), the p-value for testing the hypothesis \(H_0:\,\beta _j=0\) is
We remark that we have changed the notation in (13) and (14), where \(\beta _j\) denotes the j-th component of the vector \(\beta \) and not the vector of regression parameters of the j-th category.
7 Simulations
This section presents simulation experiments for assessing the performance of the fitting method, the EBP estimator, and the MSE estimator. The objective is to show how the new methodology works in realistic (not extreme) scenarios. In practice, some explanatory variables can be taken from an auxiliary survey that is different from the target survey and that has bigger sample sizes. This is the case of the SLCS (target survey) and the SLFS (auxiliary survey). The second one has bigger sample sizes than the first. Therefore, it is natural to choose scenarios where the variances of the measurement errors are lower than the variances of the sampling errors and lower than the variances of the random effects.
In the calculation of Sect. 4, the variances of the sampling errors are \(\sigma _{e1}^2=\sigma _{e2}^2=1\) and the variances of the random effects are \(\sigma _{u1}^2=\theta _1=1\) and \(\sigma _{u2}^2=\theta _2=3/2=0.66\). Therefore, it is quite natural to choose scenario E, where the measurement error variances are \(\tau _{d11}=\tau _{d22}=0.21\) Concerning the random effect correlations, we are mainly interested in the case \(\theta _3=\text{ corr }(u_{d1},u_{d2})=0.45\) because \(\theta _3\) is positive in the application to real data. This is why, we consider that the scenario 6E is the most close to the application to real data presented in Sect. 8. For the sake of completeness, we also run simulations under the scenarios 5E and 4E with correlations \(\theta _3=0.05\) and \(\theta _3=-0.55\).
The data for the simulation experiments is generated as follows. We take \(q_1=q_2=p_1=p_2=1\), so that the elements of the MEBFH model (4) are \(Z_d=\text{ diag }(z_{d1},z_{d2})\), \(\eta =(\eta _1,\eta _2)^\prime \), \(X_d=\text{ diag }(x_{d1},x_{d2})\), \(\lambda =(\lambda _1,\lambda _2)^\prime \), \(B=\text{ diag }(\lambda _1,\lambda _2)\), \(v_d=(v_{d1},v_{d2})^\prime \), \(u_d=(u_{d1},u_{d2})^\prime \), \(e_d=(e_{d1},e_{d2})^\prime \). Take \(z_{d1}=z_{d2}=1\), \(\eta _1=\eta _2=\lambda _1=\lambda _2=1\) and
with \(\mu _{x1}=\mu _{x2}=1\), \(\sigma _{x1}=1.2\) and \(\sigma _{x2}=2.4\). Note that
For \(d=1,\ldots ,D\), generate \(v_d\sim N_{2}(0,\Sigma _{d})\), \({u}_{d}\sim N_{2}(0,{V}_{ud})\) and \({e}_d\sim N_{2}(0,{V}_{ed})\), where
\(\tau _{d12}=\rho _{\tau }\tau _{d11}^{1/2}\tau _{d22}^{1/2}\), \(\tau _{d11}=\tau _{d22}=\tau =0.21\), \(\rho _\tau =c=-0.35\), \(\theta _1=1\) and \(\theta _2=1.5\). Concerning the random effect correlation, we consider \(\theta _3=0.45\), \(\theta _3=0.05\) and \(\theta _3=-0.55\). This is to say, we take the same model parameters as in Scenarios 6E, 5E and 4E of Sect. 4.
7.1 Simulation 1
The target of Simulation 1 is to check the behavior of the pseudo-REML Fisher-scoring algorithm for fitting the MEBFH model. The steps of Simulation 1 are
-
1.
Generate \(z_{dk}\), \(x_{dk}\), \(d=1,\ldots ,D\), \(k=1,2\).
-
2.
Repeat \(I=1000\) times (\(i=1,\ldots ,1000\))
-
2.1.
Generate \(v_d^{(i)}\sim N_2(0,\Sigma _{d})\), \(u_d^{(i)}\sim N_2(0,V_{ud})\), \(e_d^{(i)}\sim N_2(0,V_{ed})\) and
$$\begin{aligned} y_d^{(i)}=Z_d\eta +X_d\lambda +Bv_d^{(i)}+u_d^{(i)}+e_d^{(i)}, \quad d=1,\ldots ,D. \end{aligned}$$(15) -
2.2.
For every model parameter \(\gamma \in \{\eta _1,\lambda _1,\eta _2,\lambda _2,\theta _1,\theta _2,\theta _3\}\), calculate the corresponding REML estimator \(\hat{\gamma }^{(i)}\in \{\hat{\eta }_1^{(i)},\hat{\lambda }_1^{(i)},\hat{\eta }_2^{(i)},\hat{\lambda }_2^{(i)}, \hat{\theta }_{1}^{(i)},\hat{\theta }_{2}^{(i)},\hat{\theta }_{3}^{(i)}\}\).
-
2.1.
-
3.
Output (empirical biases and root-MSEs):
$$\begin{aligned} BIAS(\hat{\gamma })=\frac{1}{I}\sum _{i=1}^{I}(\hat{\gamma }^{(i)}-\gamma ),\quad RMSE(\hat{\gamma })=\left( \frac{1}{I}\sum _{i=1}^{I}(\hat{\gamma }^{(i)}-\gamma )^2\right) ^{1/2}. \end{aligned}$$
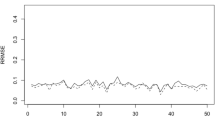
For the sake of brevity, Table 2 presents only the results of Simulation 1 under Scenario 6E. The column labeled by \(\gamma \) contains the values of the true model parameters. Simulation 1 shows that the REML Fisher scoring algorithm works properly because BIAS and RMSE decrease as D increases. Similar results are obtained under Scenarios 4E and 5E.
7.2 Simulation 2
Simulation 2 investigates the performance of the EBPs of the mean parameters \(\mu _{dk}\). The steps of Simulation 2 are
-
1.
Generate \(z_{dk}\), \(x_{dk}\), \(d=1,\ldots ,D\), \(k=1,2\). Take \(D\in {\mathcal{D}}=\{50, 100, 200\}\).
-
2.
Repeat \(I=10^4\) times (\(i=1,\ldots ,I\))
-
2.1.
Generate \(\{(e_{d}^{(i)},u_{d}^{(i)},v_{d}^{(i)},y_{d}^{(i)}): d=1,\ldots ,D\}\) from the MEBFH model (15).
-
2.2.
Calculate the true means \(\mu _{d}^{(i)}=Z_d\eta +X_d\lambda +Bv_d^{(i)}+u_d^{(i)}\), \(d=1,\ldots ,D\).
-
2.3.
Fit the MEBFH model to the simulated data \((y_{d}^{(i)},Z_d,X_d)\), \(d=1,\ldots ,D\). Calculate the EBP \(\hat{\mu }^{(i)}_{d}\) under the MEBFH model.
-
2.1.
-
3.
For \(d=1,\ldots ,D\), \(k=1,2\), calculate the relative performance measures
-
3.1
\(E_{dk}=\Big (\frac{1}{I}\sum _{i=1}^{I}(\hat{\mu }_{dk}^{(i)}-\mu _{dk}^{(i)})^2\Big )^{1/2}\), \(B_{dk}=\frac{1}{I}\sum _{i=1}^{I}(\hat{\mu }_{dk}^{(i)}-\mu _{dk}^{(i)})\),
\(\mu _{dk}=\frac{1}{I}\sum _{i=1}^{I}\mu _{dk}^{(i)}\).
-
3.2.
\(RE_{dk}=100\frac{E_{dk}}{\mu _{dk}}\), \(RB_{dk}=100\frac{B_{dk}}{\mu _{dk}}\), \(RE_{k}=\frac{1}{D}\sum _{d=1}^DRE_{dk}\),
\(RB_{k}=\frac{1}{D}\sum _{d=1}^D|RB_{dk}|\).
-
3.1
Table 3 presents the relative performance measures \(RB_{k}\) (left) and \(RE_{k}\) (right) of EBPs under Scenarios 4E, 5E and 6E. As expected, the EBPs have almost no bias in all cases. We also note that root-MSEs decrease slowly as the number of domains increases. This is somewhat reasonable, since increasing D also increases the number of quantities \(\mu _d\) to be predicted.
7.3 Simulation 3
Simulation 3 investigates the performance of the parametric bootstrap estimator of the MSE of the EBPs. For \(D=100\), the steps of Simulation 3 are
-
1.
Take \(mse_{dk}=E_{dk}^2\), \(k=0,1\), \(d=1,\ldots ,D\), from the output of Simulation 2.
-
2.
Generate \(z_{dk}\), \(x_{dk}\), \(d=1,\ldots ,D\), \(k=1,2\).
-
3.
Repeat \(I=10^2\) times (\(i=1,\ldots ,I\))
-
3.1.
Generate \(\{(e_{d}^{(i)},u_{d}^{(i)},v_{d}^{(i)},y_{d}^{(i)}): d=1,\ldots ,D\}\) from the MEBFH model (15).
-
3.2.
Calculate the REML estimators \(\hat{\gamma }^{(i)}\in \{\hat{\eta }_1^{(i)},\hat{\lambda }_1^{(i)},\hat{\eta }_2^{(i)},\hat{\lambda }_2^{(i)}, \hat{\theta }_{1}^{(i)},\hat{\theta }_{2}^{(i)},\hat{\theta }_{3}^{(i)}\}\) by using the sample data \((y_{d}^{(i)},Z_d,X_d)\), \(d=1,\ldots ,D\).
-
3.3.
Repeat B times
-
(a)
Generate \(u_d^{*(ib)}\sim N_2(0,\hat{V}_{ud}^{(i)})\), \(e_d^{*(ib)}\sim N_2(0,V_{ed})\), \({v}_{d}^{*(ib)}\sim N_2(0,\Sigma _d)\) and
$$\begin{aligned} y_{d}^{*(ib)}&= \mu _d^{*(ib)}+e_{d}^{*(ib)}, \\ \mu _d^{*(ib)}&= Z_d\hat{\eta }^{(i)}+X_d\lambda ^{(i)}+ \text{ diag }(\hat{\lambda }_1^{(i)},\hat{\lambda }_2^{(i)})v_d^{*(ib)}+u_d^{*(ib)},\,\,\, d=1,\ldots ,D. \nonumber \end{aligned}$$(16) -
(b)
Calculate the REML estimators \(\hat{\eta }_1^{*(ib)},\hat{\lambda }_1^{*(ib)},\hat{\eta }_2^{*(ib)},\hat{\lambda }_2^{*(ib)}, \hat{\theta }_{1}^{*(ib)},\hat{\theta }_{2}^{*(ib)},\hat{\theta }_{3}^{*(ib)}\) by using the sample data \((y_d^{*(ib)},Z_d,X_d)\), \(d=1,\ldots ,D\).
-
(c)
Calculate the EBP \(\hat{\mu }^{*(ib)}_{dk}\) under the MEBFH model (16).
-
(a)
-
3.4.
For \(d=1,\ldots ,D\), \(k=1,2\), calculate the bootstrap MSE estimator of the EBP, i.e.
$$\begin{aligned} mse_{dk}^{*(i)}=\frac{1}{B}\sum _{b=1}^B\big (\hat{\mu }^{*(ib)}_{dk}-\mu ^{*(ib)}_{dk}\big )^2. \end{aligned}$$
-
3.1.
-
4.
For \(d=1,\ldots ,D\), \(k=1,2\), calculate the relative performance measures \(RE_{dk}^{*}=100E_{dk}^{*}/mse_{dk}\) and \(RB_{dk}^{*}=100B_{dk}^{*}/mse_{dk}\), where
$$\begin{aligned} E_{dk}^{*}=\Big (\frac{1}{I}\sum _{i=1}^{I}(mse_{dk}^{*(i)}-mse_{dk})^2\Big )^{1/2},\,\,\, B_{dk}^{*}=\frac{1}{I}\sum _{i=1}^{I}(mse_{dk}^{*(i)}-mse_{dk}). \end{aligned}$$ -
5.
For \(k=1,2\), calculate the averages across domains of the relative performance measures, i.e. \(RB_{k}^*=\frac{1}{D}\sum _{d=1}^D|RB_{dk}^*|\), \(RE_{k}^*=\frac{1}{D}\sum _{d=1}^DRE_{dk}^*\).
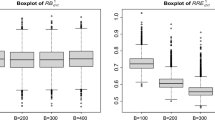
Table 4 presents the relative performance measures \(RB_k^*\) and \(E B_k^*\) (in %) under Scenarios 4E, 5E and 6E, for \(D=100\). Figures 2 and 3 presents the boxplots of the absolute performance measures \(B_{dk}^*\)’s and \(E_{dk}^*\)’s respectively under scenario 6E. Similar boxplots are constructed for Scenarios 4E and 5E, but they are not presented here. They show that the parametric bootstrap estimators of the MSEs of the EBPs have a negative bias in the simulated scenarios. Nevertheless, the observed biases are rather small in comparison with the calculated empirical root-MSEs. Simulation 3 suggests that running a parametric bootstrap algorithm with a number of replicates B between 200 and 400 give a considerably good approximation to estimate the MSE of the EBP.

Boxplots of biases \(\{B_{dk}^*: d=1,\ldots ,D\}\), \(k=1,2\)

Boxplots of root-MSEs \(\{E_{dk}^*: d=1,\ldots ,D\}\), \(k=1,2\)
8 Estimation of poverty proportions and gaps in Spanish provinces
This manuscript presents an application of the MEBFH model to the estimation of poverty proportions and gaps in Spanish provinces by sex. Spain is divided in 52 provinces (including the autonomous cities of Ceuta and Melilla) leading to \(D=104\) target domains (provinces crossed by sex) of known sizes \(N_d\), \(d=1,\ldots ,D\).
Let \(z_{dj}\) be the normalized net annual income of the household where the individual j of domain d lives. Let \(z_0\) be the poverty line, so that individuals with \(z_{dj}<z_0\) are considered as poor. The main goal of this section is to jointly estimate poverty proportions and gaps
where \(y_{d1j}=I(z_{dj}<z_0)\), \(I(z_{dj}<z_0)=1\) if \(z_{dj}<z_0\), \(I(z_{dj}<z_0)=0\) otherwise and \(y_{d2j}=z_0^{-1}(z_0-z_{dj})I(z_{dj}<z_0)\).
The Spanish Statistical Office calculates \(z_{dj}\) by summing up the net annual incomes of the household members and by dividing by its normalized size. Later, the same value of the normalized net annual income of the household is assigned to all the individuals j of the household. Therefore \(z_{dj}\) is constant within the household. The aim of normalizing the household income is to adjust for the varying size and composition of households. The definition of the total number of normalized household members is the modified OECD scale used by EUROSTAT. This scale gives a weight of 1.0 to the first adult, 0.5 to the second and each subsequent person aged 14 and over and 0.3 to each child aged under 14 in the household h. The normalized size of a household is the sum of the weights assigned to each person. So the total number of normalized household members is
where \(H_{dh\ge 14}\) is the number of people aged 14 and over and \(H_{dh< 14}\) is the number of children aged under 14. Following the standards of the Spanish Statistical Office, the poverty threshold is fixed as the 60% of the median of the normalized net annual incomes in Spanish households. The Spanish poverty threshold (in euros) in 2008 is \(z_{2008}=7488.65\). We deal with data from the SLCS of 2008 with sample size 35967. This is an annual survey where the planned domains are the regions (autonomous communities), so that sample sizes are selected to obtain precise direct estimates at the region level. As Spain is hierarchically partitioned in regions, provinces, counties (comarcas) and municipalities, estimating province-sex poverty proportions is a small area estimation problem.
The direct estimators of the size \(N_d\), the total \(Y_{dk}=\sum _{j=1}^{N_{d}}y_{dkj}\) and the mean \(\bar{Y}_{dk}=Y_{dk}/N_{d}\) are
where \(s_{d}\) is the domain sample of size \(n_d\) and the \(w_{dj}\)’s are the official calibrated sampling weights which take non response into account. The direct estimates of the domain means are used as responses in the area-level Fay–Herriot model. The design-based covariance between \(\hat{\bar{Y}}_{dk_1}^{dir}\) and \(\hat{\bar{Y}}_{dk_2}^{dir}\), \(k_1,k_2=1,2\), can be estimated by
where the case \(k_1=k_2=k\) denotes estimated variance, i.e. \(\hat{\text{ var }}_\pi (\hat{\bar{Y}}_{dk}^{dir})=\) \(\hat{\text{ cov }}_\pi (\hat{\bar{Y}}_{dk}^{dir},\hat{\bar{Y}}_{dk}^{dir})\). The last formulas are obtained from Särndal et al. (1992), pp. 43, 185 and 391, with the simplifications \(w_{dj}=1/\pi _{dj}\), \(\pi _{dj,dj}=\pi _{dj}\) and \(\pi _{di,dj}=\pi _{di} \pi _{dj}\), \(i\ne j\) in the second order inclusion probabilities.
We take data from the SLFS of 2008 to construct the data file of aggregated auxiliary variables. The SLFS is a quarterly survey with provinces as planned domains. Within each quarter, the SLFS sample sizes at the province level are fixed a priori. They are selected high enough to have precise direct estimates. By putting together the data files of the 4 quarters, the SLFS direct estimators of means at domain (province crossed by sex) level are even more precise for 2008 than using only the data of one quarter. Additionally, by doing this aggregation all the calculated SLFS direct estimators of domain means have non zero estimated variances.
The file of auxiliary variables is constructed from the SLFS data of 2008 (SLFS2008). It contains the direct estimates of the domain means by the categories of the considered auxiliary variables. It also contains the variance and covariance estimates of the calculated direct estimators. The auxiliary variables are:
Nationality, with categories Spanish and Foreigner.
Education, with categories LowEdu (less than secondary level completed), HighEdu (secondary or superior level completed)
Age, with categories age1 (\(\le 15\)), age2 (16-24), age3 (25-49), age4 (50-64), age5 (\(>64\)).
Labour situation, with categories \(\le 15\), Employed, Unemployed, Inactive.
Table 5 presents the pseudo-REML estimates of the regression parameters of the selected MEBFH model. It also contains the corresponding p-values. We note that domains with higher proportions of Spanish or unemployed people tends to have higher poverty proportions. On the other hand, the level of education is negatively related with the poverty proportion. We note that foreigners tend to live and work in rich provinces. Therefore, the obtained results are in agreement with the Spanish socioeconomic situation of 2008.
Table 6 contains the estimates of the variance component parameters and the corresponding asymptotic 95% confidence intervals.
Figure 4 (left) plots the MEBFH model residuals of poverty proportions versus the corresponding EBPs. Figure 4 (right) plots the MEBFH model residuals of poverty gaps versus their EBPs.
We observe that the residuals present greater variability on the right hand side of the OX axis. This is a natural phenomenon, as the EBPs have to smooth the behavior of the direct estimators. The plots show that EBPs tend to be smaller than direct estimates when direct estimates are large. This is due to two main reasons. First, it is part of the smoothing work that EBPs have to do. Second, the variance of the directly estimated proportion is approximately \((1-n_d/N_d)/(n_d-1)\hat{\bar{Y}}_{dk}^{dir}(1-\hat{\bar{Y}}_{dk}^{dir})\), which takes its maximum at \(\hat{\bar{Y}}_{dk}^{dir}=0.5\), for \(n_d, N_d\) fixed. Allowing in this context area specific \(V_{ud}\) is an interesting future research task, that possibly could further reduce the MSE of the EBP.
Figure 5 plots the EBPs and direct estimates of poverty proportions (left) and gaps (right) for men and women. We observe that both estimators tend to coincide as the sample size increases.

Model residuals versus EBPs of poverty proportions (left) and gaps (right)

EBPs and direct estimates of men (left) and women (right) poverty proportions
Figure 6 plots the estimated model-based root-MSEs of the EBPs and the estimated design-based root-MSEs of the direct estimators of poverty proportions (left) and gaps (right) for men and women. The first root-MSE is estimated by parametric bootstrap under the fitted MEBFH model. The second one is calculated by applying the estimator (18) for design-based variances. The EBPs have lower root-MSEs than the direct estimators. When the sample size increases the root-MSEs of all the estimators become almost equal.

Root-MSEs of EBPs and direct estimators for men (left) and women (right)
Figures 7 and 8 plot the Spanish provinces in 4 colors depending on the values of the EBPs of the poverty proportions and poverty gaps in \(\%\). We observe that the Spanish provinces where the proportion of the population under the poverty line is smallest are those situated in the north and east. On the other hand, the Spanish provinces with higher poverty proportions are those situated in the center and south.

Estimated poverty proportions for men (left) and women (right) in 2008

Estimated poverty gaps for men (left) and women (right) in 2008
Appendix B in the supplementary file contains 2 tables with basic numerical results. To give a brief summary of the obtained numerical results, we order the Spanish provinces (including the cities of Ceuta and Melilla) by sample size and we select one in five. Table B.1 presents the EBPs and direct (dir) estimates of poverty proportions for men and women respectively. Table B.2 presents the EBPs and direct (dir) estimates of poverty gaps for men and women respectively. These tables also give the estimated root-MSEs (rmse.eblup and rmse.dir), for both types of estimators. The column \(N_d\) presents the estimates of the domain sizes calculated by using the data of the 4 quarters of the SLFS in 2008. The columns province and \(n_d\) contain the province name and the sample size respectively.
9 Conclusions
In many applications the auxiliary information used in bivariate Fay–Herriot models is not measured exactly. Under this setting, the EBLUP based on the bivariate Fay–Herriot model is not the EBP anymore, as this model assumes the exact measurement of the auxiliary variables.
By calculating relative efficiencies, we showed that not taking into account the measurement errors may lead to predictions of target parameters with greater mean squared errors. Therefore, we extended the bivariate Fay–Herriot model by allowing for multivariate normal distributed random error on the auxiliary variables. This reflects the typical situation of estimated auxiliary information. Both, the mean squared error and the bias of the new EBP are reduced with respect to the classical EBLUP.
For fitting the new model, the pseudo-REML estimation procedure showed to be stable. Further a second fitting algorithm was introduced but not implemented. In the case of exactly measured auxiliary variables, the measurement error bivariate Fay–Herriot model reduces to the classical bivariate Fay–Herriot model and, therefore, they basically give the same predictions. Finally, we recommend to use the proposed measurement error Fay–Herriot model when the auxiliary variables are estimated.
References
Arima S, Datta GS, Liseo B et al (2012) Objective bayesian analysis of a measurement error small area model. Bayesian Anal 7(2):363–384
Arima S, Datta GS, Liseo B (2015) Bayesian estimators for small area models when auxiliary information is measured with error. Scand J Stat 42(2):518–529
Arima S, Bell WR, Datta GS, Franco C, Liseo B (2017) Multivariate Fay–Herriot bayesian estimation of small area means under functional measurement error. J R Stat Soc: Ser A (Stat Soc) 180(4):1191–1209
Benavent R, Morales D (2016) Multivariate Fay–Herriot models for small area estimation. Comput Stat Data Anal 94:372–390
Burgard JP, Esteban MD, Morales D, Pérez A (2019) A fay-herriot model when auxiliary variables are measured with error. TEST. https://doi.org/10.1007/s11749-019-00649-3
Datta G, Ghosh M, Nangia N, Natarajan K (1996) Estimation of median income of four-person families: a Bayesian approach. Bayesian Anal Stat Econom 129–140
Datta GS, Fay RE, Ghosh M (1991) Hierarchical and empirical multivariate bayes analysis in small. In: Proceedings of bureau of the census 1991 annual research conference, US Department of Commerce, Bureau of the Census, vol 7, pp 63–79
Datta GS, Rao J, Torabi M (2010) Pseudo-empirical bayes estimation of small area means under a nested error linear regression model with functional measurement errors. J Stat Plan Inference 140(11):2952–2962
Esteban M, Morales D, Pérez A, Santamaría L (2012a) Two area-level time models for estimating small area poverty indicators. J Indian Soc Agric Stat 66(1):75–89
Esteban MD, Morales D, Pérez A, Santamaría L (2012b) Small area estimation of poverty proportions under area-level time models. Comput Stat Data Anal 56(10):2840–2855
Fay RE (1987) Application of multivariate regression to small domain estimation. In: Small area statistics, pp 91–102
Fay RE, Herriot RA (1979) Estimates of income for small places: an application of James–Stein procedures to census data. J Am Stat Assoc 74(366a):269–277
Ghosh M, Sinha K (2007) Empirical bayes estimation in finite population sampling under functional measurement error models. J Stat Plan Inference 137(9):2759–2773
Ghosh M, Sinha K, Kim D (2006) Empirical and hierarchical bayesian estimation in finite population sampling under structural measurement error models. Scand J Stat 33(3):591–608
González-Manteiga W, Lombardía MJ, Molina I, Morales D, Santamaría L (2008) Analytic and bootstrap approximations of prediction errors under a multivariate Fay–Herriot model. Comput Stat Data Anal 52(12):5242–5252
González-Manteiga W, Lombarda M, Molina I, Morales D, Santamaría L (2010) Small area estimation under Fay–Herriot models with non-parametric estimation of heteroscedasticity. Stat Model 10(2):215–239
López-Vizcaíno E, Lombardía MJ, Morales D (2013) Multinomial-based small area estimation of labour force indicators. Stat Model 13(2):153–178
López-Vizcaíno E, Lombardía MJ, Morales D (2015) Small area estimation of labour force indicators under a multinomial model with correlated time and area effects. J R Stat Soc: Ser A (Stat Soc) 178(3):535–565
Marchetti S, Giusti C, Pratesi M, Salvati N, Giannotti F, Pedreschi D, Rinzivillo S, Pappalardo L, Gabrielli L (2015) Small area model-based estimators using big data sources. J Off Stat 31(2):263–281
Marhuenda Y, Molina I, Morales D (2013) Small area estimation with spatio-temporal Fay–Herriot models. Comput Stat Data Anal 58:308–325
Molina I, Saei A, José Lombardía M (2007) Small area estimates of labour force participation under a multinomial logit mixed model. J R Stat Soc: Ser A (Stat Soc) 170(4):975–1000
Morales D, Pagliarella MC, Salvatore R (2015) Small area estimation of poverty indicators under partitioned area-level time models. SORT: Stat Oper Res Trans 39(1):019–34
Polettini S, Arima S (2015) Small area estimation with covariates perturbed for disclosure limitation. Statistica 75(1):57–72
Porter AT, Wikle CK, Holan SH (2015) Small area estimation via multivariate Fay-Herriot models with latent spatial dependence. Aust N Z J Stat 57(1):15–29
Rao JNK, Molina I (2015) Small area estimation, 2nd edn. Wiley, Hoboken
Torabi M (2013) Likelihood inference in generalized linear mixed measurement error models. Comput Stat Data Anal 57(1):549–557
Torabi M, Datta GS, Rao J (2009) Empirical bayes estimation of small area means under a nested error linear regression model with measurement errors in the covariates. Scand J Stat 36(2):355–369
Ybarra LM, Lohr SL (2008) Small area estimation when auxiliary information is measured with error. Biometrika 95(4):919–931
Acknowledgements
Open Access funding provided by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supported by the Spanish Grant PGC2018-096840-B-I00 and by the grant “Algorithmic Optimization (ALOP)-graduate school 2126” funded by the German Research Foundation.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Burgard, J.P., Esteban, M.D., Morales, D. et al. Small area estimation under a measurement error bivariate Fay–Herriot model. Stat Methods Appl 30, 79–108 (2021). https://doi.org/10.1007/s10260-020-00515-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10260-020-00515-9