
Abstract
In today’s information systems, the availability of massive amounts of data necessitates the development of fast and accurate algorithms to summarize these data and represent them in a succinct format. One crucial problem in big data analytics is the selection of representative instances from large and massively distributed data, which is formally known as the Column Subset Selection problem. The solution to this problem enables data analysts to understand the insights of the data and explore its hidden structure. The selected instances can also be used for data preprocessing tasks such as learning a low-dimensional embedding of the data points or computing a low-rank approximation of the corresponding matrix. This paper presents a fast and accurate greedy algorithm for large-scale column subset selection. The algorithm minimizes an objective function, which measures the reconstruction error of the data matrix based on the subset of selected columns. The paper first presents a centralized greedy algorithm for column subset selection, which depends on a novel recursive formula for calculating the reconstruction error of the data matrix. The paper then presents a MapReduce algorithm, which selects a few representative columns from a matrix whose columns are massively distributed across several commodity machines. The algorithm first learns a concise representation of all columns using random projection, and it then solves a generalized column subset selection problem at each machine in which a subset of columns are selected from the sub-matrix on that machine such that the reconstruction error of the concise representation is minimized. The paper demonstrates the effectiveness and efficiency of the proposed algorithm through an empirical evaluation on benchmark data sets.


Similar content being viewed by others



Notes
\(\Vert A \Vert _{F}^{2} = trace\left( A^TA \right) \).
The in-memory summation can also be replaced by a MapReduce combiner, Dean2008.
The data sets Reuters-21578, MNIST-4K, PIE-20 and YaleB-38 are available in MAT format at: http://www.cad.zju.edu.cn/home/dengcai/Data/data.html. PIE-20 is a subset of PIE-32x32 with the images of the first 20 persons.
The CSS algorithm of Boutsidis et al. [3] was not included in the comparison as its implementation is not available.
Revision: 5.13.4.7.
In the implemented code, the efficient recursive formulas in Section 4 of [31] are used to implement the update of QR decomposition and the swapping criterion.
In [4] (a newer version of [6]), Boutsidis et al. suggested the use of the SRRQR algorithm [31, Algorithm 4] for the deterministic phase. Although the SRRQR algorithm achieves the theoretical guarantee presented in [6], the MATLAB \(qr\) function is used in the conducted experiments as it is much faster and it achieves comparable accuracy for the experimented data sets.
For the MNIST4K data set, the range of \(l/n\) values is smaller since the rank of the matrix is very low (i.e., less than the number of pixels).
The qr and SRRQR methods both depend on the MATLAB qr function. For the document data sets, the MATLAB qr function takes very long times compared with other methods and accordingly they are not reported in the shown figures.
Fig. 1 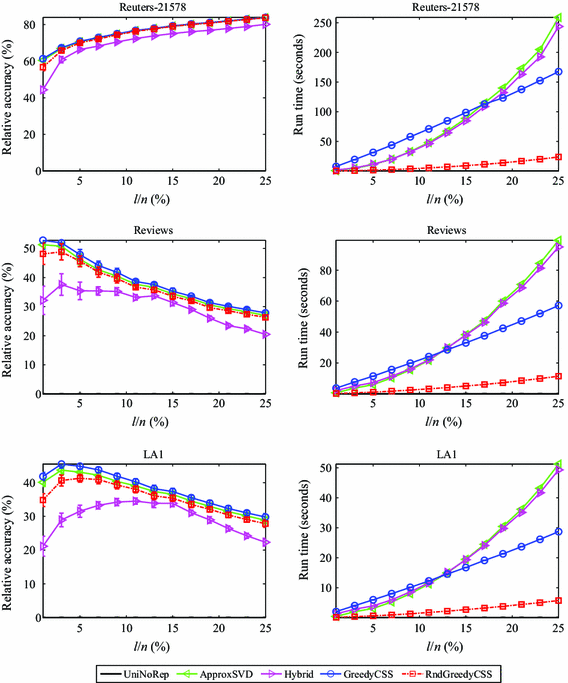
The relative accuracy measures and run times of different column-based low-rank approximations \(\tilde{A}_{\mathcal {S}}\) for the Reuters-21578, Reviews and LA1 data sets
Fig. 2 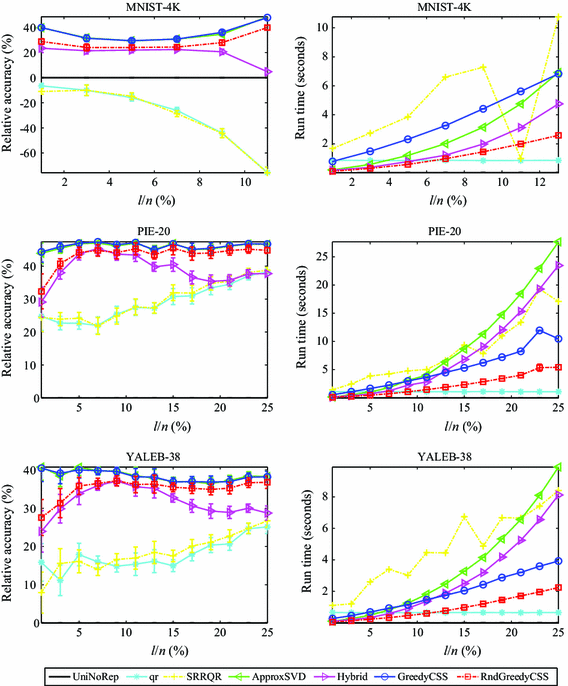
The relative accuracy measures and run times of different column-based low-rank approximations \(\tilde{A}_{\mathcal {S}}\) for the MNIST-4K, PIE-20 and YaleB-38 data sets
The MATLAB functions anova1 and multcompare were used.
Table 2 The relative accuracy of the best performing CSS methods for the Reuters-21578, Reviews and LA1 data sets Table 3 The relative accuracy of the best performing CSS methods for the MNIST-4K, PIE-20 and YaleB-38 data sets Amazon Elastic Compute Cloud (EC2): http://aws.amazon.com/ec2.
Mahout is an Apache project for implementing Machine Learning algorithms on Hadoop. See http://mahout.apache.org/.


References
Achlioptas D (2003) Database-friendly random projections: Johnson-Lindenstrauss with binary coins. J Comput Syst Sci 66(4):671–687
Bischof C, Quintana-Ortí G (1998) Computing rank-revealing QR factorizations of dense matrices. ACM Trans Math Softw 24(2):226–253
Boutsidis C, Drineas P, Magdon-Ismail M (2011) Near optimal column-based matrix reconstruction. In: Proceedings of the 52nd annual IEEE symposium on foundations of computer science (FOCS’11), pp 305–314
Boutsidis C, Mahoney MW, Drineas P (2008a) An improved approximation algorithm for the column subset selection problem, CoRR abs/0812.4293
Boutsidis C, Mahoney MW Drineas P (2008b) Unsupervised feature selection for principal components analysis. In Li Y, Liu B, Sarawagi S (eds) Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’08). ACM, New York, pp 61–69
Boutsidis C, Mahoney MW, Drineas P (2009) An improved approximation algorithm for the column subset selection problem. In: Proceedings of the 20th annual ACM-SIAM symposium on discrete algorithms (SODA’09), pp 968–977
Boutsidis C, Sun J, Anerousis N (2008) Clustered subset selection and its applications on it service metrics. In: Proceedings of the 17th ACM conference on information and knowledge management (CIKM’08), pp 599–608
Cai D, Zhang C, He X (2010) Unsupervised feature selection for multi-cluster data. In: Proceedings of the 16th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’10). ACM, New York, NY, pp 333–342
Çivril A, Magdon-Ismail M (2008) Deterministic sparse column based matrix reconstruction via greedy approximation of SVD. In: Proceedings of the 19th international symposium on algorithms and computation (ISAAC’08). Springer, New York, pp 414–423
Çivril A, Magdon-Ismail M (2012) Column subset selection via sparse approximation of SVD. Theoret Comput Sci 421:1–14
Chan T (1987) Rank revealing QR factorizations. Linear Algebra Appl 88:67–82
Chen W-Y, Song Y, Bai H, Lin C-J, Chang E (2011) Parallel spectral clustering in distributed systems. IEEE Trans Pattern Anal Mach Intell 33(3):568–586
Cui Y, Dy J (2008) Orthogonal principal feature selection, the sparse optimization and variable selection workshop at the international conference on machine learning (ICML)
Dasgupta S, Gupta A (2003) An elementary proof of a theorem of Johnson and Lindenstrauss. Random Struct Algorithms 22(1):60–65
Dean J, Ghemawat S (2008) MapReduce: simplified data processing on large clusters. Commun ACM 51(1):107–113
Deerwester S, Dumais S, Furnas G, Landauer T, Harshman R (1990) Indexing by latent semantic analysis. J Am Soc Inform Sci Technol 41(6):391–407
Deshpande A, Rademacher L (2010) Efficient volume sampling for row/column subset selection. In: Proceedings of the 51st annual IEEE symposium on foundations of computer science (FOCS’10), pp 329–338
Deshpande A, Rademacher L, Vempala S, Wang G (2006a) Matrix approximation and projective clustering via volume sampling. Theory Comput 2(1):225–247
Deshpande A, Rademacher L, Vempala S, Wang G (2006b) Matrix approximation and projective clustering via volume sampling. In: Proceedings of the 17th annual ACM-SIAM symposium on discrete algorithms (SODA’06). ACM, New York, NY, pp 1117–1126
Drineas P, Frieze A, Kannan R, Vempala S, Vinay V (2004) Clustering large graphs via the singular value decomposition. Mach Learn 56(1–3):9–33
Drineas P, Kannan R, Mahoney M (2007) Fast Monte Carlo algorithms for matrices II: computing a low-rank approximation to a matrix. SIAM J Comput 36(1):158–183
Drineas P, Mahoney M, Muthukrishnan S (2006) Subspace sampling and relative-error matrix approximation: column-based methods. Approximation, randomization, and combinatorial optimization. Algorithms and techniques. Springer, Berlin, pp 316–326
Elgohary A, Farahat AK, Kamel MS, Karray F (2013) Embed and conquer: scalable embeddings for kernel k-means on mapreduce, CoRR abs/1311.2334
Elsayed T, Lin J, Oard DW (2008) Pairwise document similarity in large collections with MapReduce. In: Proceedings of the 46th annual meeting of the association for computational linguistics on human language technologies: short Papers (HLT’08), pp 265–268
Ene A, Im S, Moseley B (2011) Fast clustering using MapReduce. In: Proceedings of the 17th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’11), pp 681–689
Farahat A, Elgohary A, Ghodsi A, Kamel M (2013) Distributed column subset selection on MapReduce. In: Proceedings of the 13th IEEE international conference on data mining (ICDM’13), pp 171–180
Farahat AK, Ghodsi A, Kamel MS (2011) An efficient greedy method for unsupervised feature selection. In: Proceedings of the 11th IEEE international conference on data mining (ICDM’11), pp 161–170
Farahat AK, Ghodsi A, Kamel MS (2013) Efficient greedy feature selection for unsupervised learning. Knowl Inf Syst 35(2):285–310
Frieze A, Kannan R, Vempala S (1998) Fast Monte-Carlo algorithms for finding low-rank approximations. In: Proceedings of the 39th annual IEEE symposium on foundations of computer science (FOCS’98), pp 370–378
Golub G, Van Loan C (1996) Matrix computations, 3rd edn. Johns Hopkins University Press, Baltimore
Gu M, Eisenstat SC (1996) Efficient algorithms for computing a strong rank-revealing QR factorization. SIAM J Sci Comput 17(4):848–869
Guruswami V, Sinop AK (2012) Optimal column-based low-rank matrix reconstruction. In: Proceedings of the 21st annual ACM-SIAM symposium on discrete algorithms (SODA’12), pp 1207–1214
Halko N, Martinsson P-G, Shkolnisky Y, Tygert M (2011) An algorithm for the principal component analysis of large data sets. SIAM J Sci Comput 33(5):2580–2594
He X, Cai D, Niyogi P (2005) Laplacian score for feature selection, advances in neural information processing systems 18 (NIPS’05). MIT Press, Cambridge, MA
He X, Yan S, Hu Y, Niyogi P, Zhang H (2005) Face recognition using Laplacianfaces. IEEE Trans Pattern Anal Mach Intell 27(3):328–340
Hogg RV, Ledolter J (1987) Engineering statistics, vol 358. MacMillan, New York
Jain AK, Dubes RC (1988) Algorithms for clustering data. Prentice-Hall Inc, Upper Saddle River, NJ
Jolliffe I (2002) Principal component analysis, 2nd edn. Springer, New York
Kang U, Tsourakakis C, Appel A, Faloutsos C, Leskovec J (2008) Hadi: fast diameter estimation and mining in massive graphs with hadoop, CMU-ML-08-117
Karloff H, Suri S, Vassilvitskii S (2010) A model of computation for MapReduce. In: Proceedings of the 21st annual ACM-SIAM symposium on discrete algorithms (SODA’10), pp 938–948
Karypis G (2003) CLUTO—a clustering toolkit, rechnical report #02-017. University of Minnesota, Department of Computer Science
Kaufman L, Rousseeuw P (1987) Clustering by means of medoids. Department of Mathematics and Informatics,Technical report, Technische Hogeschool, Delft (Netherlands)
Lee K, Ho J, Kriegman D (2005) Acquiring linear subspaces for face recognition under variable lighting. IEEE Trans Pattern Anal Mach Intell 27(5):684–698
Lewis D (1999) Reuters-21578 text categorization test collection distribution 1.0
Lewis DD, Yang Y, Rose TG, Li F (2004) Rcv1: a new benchmark collection for text categorization research. J Mach Learn Res 5:361–397
Li P, Hastie TJ, Church KW (2006) Very sparse random projections. In: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining (KDD’06), pp 287–296
Lu Y, Cohen I, Zhou X, Tian Q (2007) Feature selection using principal feature analysis. In: Proceedings of the 15th international conference on multimedia. ACM, New York, NY, pp 301–304
Lütkepohl H (1996) Handbook of matrices. Wiley, New Jersey
Masaeli M, Yan Y, Cui Y, Fung, G, Dy J (2010) Convex principal feature selection. In: Proceedings of SIAM international conference on data mining (SDM), pp 619–628
Meng X, Mahoney M (2013) Robust regression on mapreduce. In: Proceedings of the 30th international conference on machine learning (ICML-13), pp 888–896
Mitra P, Murthy C, Pal S (2002) Unsupervised feature selection using feature similarity. IEEE Trans Pattern Anal Mach Intell 24(3):301–312
Pan C (2000) On the existence and computation of rank-revealing LU factorizations. Linear Algebra Appl 316(1):199–222
Sim T, Baker S, Bsat M (2003) The CMU pose, illumination, and expression database. IEEE Trans Pattern Anal Mach Intell 25(12):1615–1618
Singh S, Kubica J, Larsen S, Sorokina D (2009) Parallel large scale feature selection for logistic regression. Proceedings of the SIAM international conference on data mining, pp 1171–1182
Torralba A, Fergus R, Freeman W (2008) 80 Million tiny images: a large data set for nonparametric object and scene recognition. IEEE Trans Pattern Anal Mach Intell 30(11):1958–1970
White T (2009) Hadoop: the definitive guide, 1st edn. O’Reilly Media Inc, Sebastopol
Wolf L, Shashua A (2005) Feature selection for unsupervised and supervised inference: the emergence of sparsity in a weight-based approach. J Mach Learn Res 6:1855–1887
Xiang J, Guo C, Aboulnaga A (2013) Scalable maximum clique computation using mapreduce. IEEE 29th international conference on data engineering (ICDE), 2013 , pp 74–85
Zhao Z, Liu H (2007) Spectral feature selection for supervised and unsupervised learning. In: Proceedings of the 24th international conference on machine learning (ICML’07). ACM, New York, NY, pp 1151–1157
Author information
Authors and Affiliations
Corresponding author
Additional information
A preliminary version of this paper appeared as [26].
This work was completed while the second author was at the University of Waterloo.
Rights and permissions
About this article

Cite this article
Farahat, A.K., Elgohary, A., Ghodsi, A. et al. Greedy column subset selection for large-scale data sets. Knowl Inf Syst 45, 1–34 (2015). https://doi.org/10.1007/s10115-014-0801-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-014-0801-8