
Abstract
Consider the problem of minimizing the expected value of a cost function parameterized by a random variable. The classical sample average approximation method for solving this problem requires minimization of an ensemble average of the objective at each step, which can be expensive. In this paper, we propose a stochastic successive upper-bound minimization method (SSUM) which minimizes an approximate ensemble average at each iteration. To ensure convergence and to facilitate computation, we require the approximate ensemble average to be a locally tight upper-bound of the expected cost function and be easily optimized. The main contributions of this work include the development and analysis of the SSUM method as well as its applications in linear transceiver design for wireless communication networks and online dictionary learning. Moreover, using the SSUM framework, we extend the classical stochastic (sub-)gradient method to the case of minimizing a nonsmooth nonconvex objective function and establish its convergence.




Similar content being viewed by others
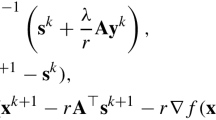


Notes
The family of functions \(\mathcal {F}\) is uniformly equicontinuous over the set \({\mathcal {X}}\) if for every \(\epsilon >0\), there exists a \(\delta >0\) such that \(|f(x) - f(y)| <\epsilon , \;\forall f \in \mathcal {F}\) and for all \(x ,y \in {\mathcal {X}}\) with \(|x - y| <\delta \).
References
Plambeck, E.L., Fu, B.R., Robinson, S.M., Suri, R.: Sample-path optimization of convex stochastic performance functions. Math. Program. 75(2), 137–176 (1996)
Robinson, S.M.: Analysis of sample-path optimization. Math. Oper. Res. 21(3), 513–528 (1996)
Healy, K., Schruben, L.W.: Retrospective simulation response optimization. In: Proceedings of the 23rd Conference on Winter Simulation, pp. 901–906. IEEE Computer Society (1991)
Rubinstein, R.Y., Shapiro, A.: Optimization of static simulation models by the score function method. Math. Comput. Simul. 32(4), 373–392 (1990)
Rubinstein, R.Y., Shapiro, A.: Discrete Event Systems: Sensitivity Analysis and Stochastic Optimization by the Score Function Method, vol. 346. Wiley, New York (1993)
Shapiro, A.: Monte carlo sampling methods. Handb. Oper. Res. Manag. Sci. 10, 353–426 (2003)
Shapiro, A., Dentcheva, D., Ruszczyński, A.: Lectures on Stochastic Programming: Modeling and Theory, vol. 9. Society for Industrial and Applied Mathematics, Philadelphia (2009)
Kim, S., Pasupathy, R., Henderson, S.: A guide to sample average approximation In: Fu, M.C. (ed.) Handbook of Simulation Optimization, pp. 207–243. Springer, New York (2015)
Razaviyayn, M., Hong, M., Luo, Z.Q.: A unified convergence analysis of block successive minimization methods for non-smooth optimization. arXiv preprint, arXiv:1209.2385 (2012)
Yuille, A.L., Rangarajan, A.: The concave–convex procedure. Neural Comput. 15, 915–936 (2003)
Borman, S.: The expectation maximization algorithm—a short tutorial. Unpublished paper http://ftp.csd.uwo.ca/faculty/olga/Courses/Fall2006/Papers/EM_algorithm.pdf
Dempster, A.P., Laird, N.M., Rubin, D.B.: Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 39, 1–38 (1977)
Fristedt, B.E., Gray, L.F.: A Modern Approach to Probability Theory. Birkhuser, Boston (1996)
Dunford, N., Schwartz, J.T.: Linear Operators. Part 1: General Theory. Interscience Publications, New York (1958)
Bastin, F., Cirillo, C., Toint, P.L.: Convergence theory for nonconvex stochastic programming with an application to mixed logit. Math. Program. 108(2–3), 207–234 (2006)
Larsson, E., Jorswieck, E.: Competition versus cooperation on the MISO interference channel. IEEE J. Sel. Areas Commun. 26, 1059–1069 (2008)
Razaviyayn, M., Luo, Z.Q., Tseng, P., Pang, J.S.: A stackelberg game approach to distributed spectrum management. Math. Program. 129, 197–224 (2011)
Bengtsson, M., Ottersten, B.: Handbook of antennas in wireless communications. In: Godara, L.C. (ed.) Optimal and Suboptimal Transmit Beamforming, CRC, Boco Raton (2001)
Shi, C., Berry, R.A., Honig, M.L.: Local interference pricing for distributed beamforming in MIMO networks. In: Military Communications Conference, MILCOM, pp. 1–6 (2009)
Kim, S.J., Giannakis, G.B.: Optimal resource allocation for MIMO ad hoc cognitive radio networks. IEEE Trans. Inf. Theory 57, 3117–3131 (2011)
Shi, Q., Razaviyayn, M., Luo, Z.Q., He, C.: An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel. IEEE Trans. Signal Process. 59, 4331–4340 (2011)
Razaviyayn, M., Sanjabi, M., Luo, Z.Q.: Linear transceiver design for interference alignment: complexity and computation. IEEE Trans. Inf. Theory 58, 2896–2910 (2012)
Scutari, G., Facchinei, F., Song, P., Palomar, D.P., Pang, J.S.: Decomposition by partial linearization: parallel optimization of multi-agent systems. arXiv preprint, arXiv:1302.0756 (2013)
Scutari, G., Palomar, D.P., Facchinei, F., Pang, J.S.: Distributed dynamic pricing for mimo interfering multiuser systems: a unified approach. In: 2011 5th International Conference on Network Games, Control and Optimization (NetGCooP), pp. 1–5 (2011)
Hong, M., Luo, Z.Q.: Signal processing and optimal resource allocation for the interference channel. arXiv preprint, arXiv:1206.5144 (2012)
Wajid, I., Eldar, Y.C., Gershman, A.: Robust downlink beamforming using covariance channel state information. In: IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, pp. 2285–2288 (2009)
Vucic, N., Boche, H.: Downlink precoding for multiuser MISO systems with imperfect channel knowledge. In: IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, pp. 3121–3124 (2008)
Song, E., Shi, Q., Sanjabi, M., Sun, R., Luo, Z.Q.: Robust SINR-constrained MISO downlink beamforming: When is semidefinite programming relaxation tight? In: IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, pp. 3096–3099 (2011)
Tajer, A., Prasad, N., Wang, X.: Robust linear precoder design for multi-cell downlink transmission. IEEE Trans. Signal Process. 59, 235–251 (2011)
Shenouda, M., Davidson, T.N.: On the design of linear transceivers for multiuser systems with channel uncertainty. IEEE J. Sel. Areas Commun. 26, 1015–1024 (2008)
Li, W.C., Chang, T.H., Lin, C., Chi, C.Y.: Coordinated beamforming for multiuser miso interference channel under rate outage constraints. IEEE Trans. Signal Process. 61(5), 1087–1103 (2013)
Negro, F., Ghauri, I., Slock, D.: Sum rate maximization in the noisy MIMO interfering broadcast channel with partial CSIT via the expected weighted MSE. In: International Symposium on Wireless Communication Systems, ISWCS, pp. 576–580 (2012)
Razaviyayn, M., Baligh, H., Callard, A., Luo, Z.Q.: Joint transceiver design and user grouping in a MIMO interfering broadcast channel. In: 45th Annual Conference on Information Sciences and Systems (CISS) pp. 1–6 (2011)
Shi, Q., Razaviyayn, M., Luo, Z.Q., He, C.: An iteratively weighted MMSE approach to distributed sum-utility maximization for a MIMO interfering broadcast channel. IEEE Trans. Signal Process. 59, 4331–4340 (2011)
Guo, D., Shamai, S., Verdú, S.: Mutual information and minimum mean-square error in Gaussian channels. IEEE Trans. Inf. Theory 51(4), 1261–1282 (2005)
Sampath, H., Stoica, P., Paulraj, A.: Generalized linear precoder and decoder design for MIMO channels using the weighted MMSE criterion. IEEE Trans. Commun. 49(12), 2198–2206 (2001)
Hong, M., Sun, R., Baligh, H., Luo, Z.Q.: Joint base station clustering and beamformer design for partial coordinated transmission in heterogeneous networks. IEEE J. Sel. Areas Commun. 31(2), 226–240 (2013)
3GPP TR 36.814. In: http://www.3gpp.org/ftp/specs/archive/36_series/36.814/
Yousefian, F., Nedić, A., Shanbhag, U.V.: On stochastic gradient and subgradient methods with adaptive steplength sequences. Automatica 48(1), 56–67 (2012)
Razaviyayn, M., Sanjabi, M., Luo, Z.Q.: A stochastic weighted MMSE approach to sum rate maximization for a MIMO interference channel. In: IEEE 14th Workshop on Signal Processing Advances in Wireless Communications (SPAWC), pp. 325–329 (2013)
Luo, Z.Q., Zhang, S.: Dynamic spectrum management: complexity and duality. IEEE J. Sel. Top. Signal Process. 2(1), 57–73 (2008)
Weeraddana, P.C., Codreanu, M., Latva-aho, M., Ephremides, A., Fischione, C.: Weighted Sum-Rate Maximization in Wireless Networks: A Review. Now Publishers, Hanover (2012)
Christensen, S.S., Agarwal, R., Carvalho, E., Cioffi, J.M.: Weighted sum-rate maximization using weighted MMSE for MIMO-BC beamforming design. IEEE Trans. Wirel. Commun. 7(12), 4792–4799 (2008)
Schmidt, D.A., Shi, C., Berry, R.A., Honig, M.L., Utschick, W.: Minimum mean squared error interference alignment. In: Forty-Third Asilomar Conference on Signals, Systems and Computers, pp. 1106–1110 (2009)
Negro, F., Shenoy, S.P., Ghauri, I., Slock, D.T.: On the MIMO interference channel. In: Information Theory and Applications Workshop (ITA), 2010, pp. 1–9 (2010)
Shin, J., Moon, J.: Weighted sum rate maximizing transceiver design in MIMO interference channel. In: Global Telecommunications Conference (GLOBECOM), pp. 1–5 (2011)
Razaviyayn, M., Baligh, H., Callard, A., Luo, Z.Q.: Joint transceiver design and user grouping in a MIMO interfering broadcast channel. In: 45th Annual Conference on Information Sciences and Systems (CISS), pp. 1–6 (2011)
Aharon, M., Elad, M., Bruckstein, A.: K-SVD: design of dictionaries for sparse representation. Proc. SPARS 5, 9–12 (2005)
Lewicki, M.S., Sejnowski, T.J.: Learning overcomplete representations. Neural Comput. 12(2), 337–365 (2000)
Mairal, J., Bach, F., Ponce, J., Sapiro, G.: Online learning for matrix factorization and sparse coding. J. Mach. Learn. Res. 11, 19–60 (2010)
Bertsekas, D.P.: Nonlinear Programming, 2nd edn. Athena-Scientific, Belmont (1999)
Razaviyayn, M., Tseng, H.W., Luo, Z.Q.: Dictionary learning for sparse representation: Complexity and algorithms. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5247–5251 (2014)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. Stat. 22, 400–407 (1951)
Kiefer, J., Wolfowitz, J.: Stochastic estimation of the maximum of a regression function. Ann. Math. Stat. 23(3), 462–466 (1952)
Nemirovski, A., Juditsky, A., Lan, G., Shapiro, A.: Robust stochastic approximation approach to stochastic programming. SIAM J. Optim. 19(4), 1574–1609 (2009)
Koshal, J., Nedić, A., Shanbhag, U.V.: Regularized iterative stochastic approximation methods for stochastic variational inequality problems. IEEE Trans. Autom. Control 58(3), 594–609 (2013)
Nemirovsky, A.S., Yudin, D.B.: Problem Complexity and Method Efficiency in Optimization. Wiley, New York (1983)
Chung, K.L.: On a stochastic approximation method. Ann. Math. Stat. 25, 463–483 (1954)
Ermoliev, Y.: stochastic quasigradient methods and their application to system optimization. Stoch. Int. J. Probab. Stoch. Process. 9(1–2), 1–36 (1983)
Amari, S.: A theory of adaptive pattern classifiers. IEEE Trans. Electron. Comput. 16(3), 299–307 (1967)
Wijnhoven, R., With, P.H.N.D.: Fast training of object detection using stochastic gradient descent. In: Proceedings of IEEE International Conference on Pattern Recognition (ICPR), pp. 424–427 (2010)
Grippo, L.: Convergent on-line algorithms for supervised learning in neural networks. IEEE Trans. Neural Netw. 11(6), 1284–1299 (2000)
Mangasarian, O.L., Solodov, M.V.: Serial and parallel backpropagation convergence via nonmonotone perturbed minimization. Optim. Methods Softw. 4(2), 103–116 (1994)
Luo, Z.Q.: On the convergence of the LMS algorithm with adaptive learning rate for linear feedforward networks. Neural Comput. 3(2), 226–245 (1991)
Luo, Z.Q., Tseng, P.: Analysis of an approximate gradient projection method with applications to the backpropagation algorithm. Optim. Methods Softw. 4(2), 85–101 (1994)
Bottou, L.: Online learning and stochastic approximations. In: On-Line Learning in Neural Networks, vol. 17(9) (1998)
Bertsekas, D.P.: A new class of incremental gradient methods for least squares problems. SIAM J. Optim. 7(4), 913–926 (1997)
Bertsekas, D.P., Tsitsiklis, J.N.: Parallel and Distributed Computation: Numerical Methods, 2nd edn. Athena-Scientific, Belmont (1999)
Tsitsiklis, J., Bertsekas, D.P., Athans, M.: Distributed asynchronous deterministic and stochastic gradient optimization algorithms. IEEE Trans. Autom. Control 31(9), 803–812 (1986)
Bertsekas, D.P.: Distributed asynchronous computation of fixed points. Math. Program. 27(1), 107–120 (1983)
Ermol’ev, Y.M., Norkin, V.I.: Stochastic generalized gradient method for nonconvex nonsmooth stochastic optimization. Cybern. Syst. Anal. 34(2), 196–215 (1998)
Bertsekas, D.P., Tsitsiklis, J.N.: Gradient convergence in gradient methods with errors. SIAM J. Optim. 10(3), 627–642 (2000)
Bertsekas, D.P.: Incremental gradient, subgradient, and proximal methods for convex optimization: a survey. In: Optimization for Machine Learning 2010, pp. 1–38 (2011)
Tseng, P.: An incremental gradient(-projection) method with momentum term and adaptive stepsize rule. SIAM J. Optim. 8(2), 506–531 (1998)
George, A.P., Powell, W.B.: Adaptive stepsizes for recursive estimation with applications in approximate dynamic programming. Mach. Learn. 65(1), 167–198 (2006)
Broadie, M., Cicek, D., Zeevi, A.: General bounds and finite-time improvement for the Kiefer–Wolfowitz stochastic approximation algorithm. Oper. Res. 59(5), 1211–1224 (2011)
Nesterov, Y.: Primal-dual subgradient methods for convex problems. Math. Program. 120(1), 221–259 (2009)
Xiao, L.: Dual averaging methods for regularized stochastic learning and online optimization. J. Mach. Learn. Res. 11, 2543–2596 (2010)
Shalev-Shwartz, S., Tewari, A.: Stochastic methods for \(\ell _1\)-regularized loss minimization. J. Mach. Learn. Res. 12, 1865–1892 (2011)
Fisk, D.L.: Quasi-martingales. Trans. Am. Math. Soc. 120, 369–389 (1965)
Van der Vaart, A.W.: Asymptotic Statistics, vol. 3. Cambridge University Press, Cambridge (2000)
Hewitt, E., Savage, L.J.: Symmetric measures on cartesian products. Trans. Am. Math. Soc. 80, 470–501 (1955)
Bonnans, J.F., Shapiro, A.: Perturbation Analysis of Optimization Problems. Springer, New York (2000)
Acknowledgments
The authors are grateful to Maury Bramson of the University of Minnesota for valuable discussions.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Proof of Lemma 1
First of all, it can be observed that \({\hat{f}}_1^r(x^r) - f_1^r(x^r) = {\hat{f}}^r(x^r) - f^r(x^r)\) according to the definition of the functions \({\hat{f}}(\cdot )\) and \(f(\cdot )\). Therefore it suffices to show that \(\lim _{r\rightarrow \infty } {\hat{f}}^r(x^r) - f^r(x^r)=0,\;\mathrm{almost \;surely}\). The proof of this fact requires the use of quasi martingale convergence theorem [80], much like the convergence proof of online learning algorithms [50, Proposition 3]. In particular, we will show that the sequence \(\{{\hat{f}}^r(x^r)\}_{r=1}^{\infty }\) converges almost surely. Notice that
where the last equality is due to the assumption A1 and the inequality is due to the update rule of the SSUM algorithm. Taking the expectation with respect to the natural history yields
where (44) is due to the assumption A2 and (45) follows from the definition of \(\Vert \cdot \Vert _\infty \). On the other hand, the Donsker theorem (see [50, Lemma 7] and [81, Chapter 19]) implies that there exists a constant k such that
Combining (45) and (46) yields
where \((a)_+ \triangleq \max \{0,a\}\) is the projection to the non-negative orthant. Summing (47) over r, we obtain
where \(M \triangleq \sum _{r=1}^\infty \frac{k}{r^{3/2}}\). The equation (48) combined with the quasi-martingale convergence theorem (see [80] and [50, Theorem 6]) implies that the stochastic process\(\{{\hat{f}}^r(x^r) + \bar{g}\}_{r=1}^{\infty }\) is a quasi-martingale with respect to the natural history \(\{\mathcal {F}^r\}_{r=1}^{\infty }\) and \({\hat{f}}^r(x^r)\) converges. Moreover, we have
Next we use (49) to show that \(\sum _{r=1}^\infty \frac{{\hat{f}}^r(x^r) - f^r(x^r)}{r+1} <\infty ,\; \mathrm{almost\;surely}\). To this end, let us rewrite (43) as
Using the fact that \({\hat{f}}^r(x^r) \ge f^r(x^r),\;\forall \ r\) and summing (50) over all values of r, we have
Notice that the first term in the right hand side is finite due to (49). Hence in order to show \(\sum _{r=1}^\infty \frac{{\hat{f}}^r(x^r) - f^r(x^r)}{r+1}<\infty ,\;\mathrm{almost\;surely}\), it suffices to show that \(\sum _{r=1}^\infty \frac{\Vert f-f^r\Vert _\infty }{r+1} < \infty ,\;\mathrm{almost\;surely}\). To show this, we use the Hewitt-Savage zero-one law; see [82, Theorem 11.3] and [13, Chapter 12, Theorem 19]. Let us define the event
It can be checked that the event \(\mathcal {A}\) is permutable, i.e., any finite permutation of each element of \(\mathcal {A}\) is inside \(\mathcal {A}\); see [82, Theorem 11.3] and [13, Chapter 12, Theorem 19]. Therefore, due to the Hewitt-Savage zero-one law [82], probability of the event \(\mathcal {A}\) is either zero or one. On the other hand, it follows from (46) that there exists \(M'>0\) such that
Using Markov’s inequality, (52) implies that
Hence combining this result with the result of the Hewitt-Savage zero-one law, we obtain \(Pr(\mathcal {A}) =1\); or equivalently
As a result of (51) and (53), we have
On the other hand, it follows from the triangle inequality that
and
where (56) is due to the assumption B3 (with \(\kappa =(K+K') \)); (57) follows from the assumption B6, and (58) will be shown in Lemma 2. Similarly, one can show that
It follows from (55), (58), and (59) that
Let us fix a random realization \(\{\xi ^r\}_{r=1}^\infty \) in the set of probability one for which (54) and (60) hold. Define
Clearly, \(\varpi ^r \ge 0\) and \(\sum _r \frac{\varpi ^r}{r}<\infty \) due to (54). Moreover, it follows from (60) that \(|\varpi ^{r+1}-\varpi ^r| < \frac{\tau }{r}\) for some constant \(\tau >0\). Hence Lemma 3 implies that
which is the desired result. \(\square \)
Lemma 2
\(\Vert x^{r+1} - x^r\Vert = \mathcal {O}(\frac{1}{r}).\)
Proof
The proof of this lemma is similar to the proof of [50, Lemma 1]; see also [83, Proposition 4.32]. First of all, since \(x^r\) is the minimizer of \({\hat{f}}^r(\cdot )\), the first order optimality condition implies
Hence, it follows from the assumption A3 that
On the other hand,
where (62) follows from the fact that \(x^{r+1}\) is the minimizer of \({\hat{f}}^{r+1}(\cdot )\), the second inequality is due to the definitions of \({\hat{f}}^r\) and \({\hat{f}}^{r+1}\), while (63) is the result of the assumptions B3 and B5. Combining (61) and (63) yields the desired result. \(\square \)
Lemma 3
Assume \(\varpi ^r > 0\) and \(\sum _{r=1}^\infty \frac{\varpi ^r}{r} <\infty \). Furthermore, suppose that \(|\varpi ^{r+1}-\varpi ^r| \le {\tau }/{r}\) for all r. Then \(\lim _{r\rightarrow \infty } \varpi ^r = 0\).
Proof
Since \(\sum _{r=1}^{\infty } \frac{\varpi ^r}{r} < \infty \), we have \(\liminf _{r \rightarrow \infty } \varpi ^r = 0\). Now, we prove the result using contradiction. Assume the contrary so that
for some \(\epsilon >0\). Hence there should exist subsequences \(\{m_j\}\) and \(\{n_j\}\) with \(m_j\le n_j<m_{j+1},\forall \ j\) so that
On the other hand, since \(\sum _{r=1}^{\infty } \frac{\varpi ^r}{r} < \infty \), there exists an index \(\bar{r}\) such that
Therefore, for every \(r_0 \ge \bar{r}\) with \(m_j \le r_0 \le n_j-1\), we have
where the equation (69) follows from (65), and (70) is the direct consequence of (67). Hence the triangle inequality implies
for any \(r_0 \ge \bar{r}\), which contradicts (64), implying that
\(\square \)
Rights and permissions
About this article

Cite this article
Razaviyayn, M., Sanjabi, M. & Luo, ZQ. A Stochastic Successive Minimization Method for Nonsmooth Nonconvex Optimization with Applications to Transceiver Design in Wireless Communication Networks. Math. Program. 157, 515–545 (2016). https://doi.org/10.1007/s10107-016-1021-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-016-1021-7