
Abstract
Little research has been conducted on dogs’ (Canis familiaris) ability to integrate information obtained through different sensory modalities during object discrimination and recognition tasks. Such a process would indicate the formation of multisensory mental representations. In Experiment 1, we tested the ability of 3 Gifted Word Learner (GWL) dogs that can rapidly learn the verbal labels of toys, and 10 Typical (T) dogs to discriminate an object recently associated with a reward, from distractor objects, under light and dark conditions. While the success rate did not differ between the two groups and conditions, a detailed behavioral analysis showed that all dogs searched for longer and sniffed more in the dark. This suggests that, when possible, dogs relied mostly on vision, and switched to using only other sensory modalities, including olfaction, when searching in the dark. In Experiment 2, we investigated whether, for the GWL dogs (N = 4), hearing the object verbal labels activates a memory of a multisensory mental representation. We did so by testing their ability to recognize objects based on their names under dark and light conditions. Their success rate did not differ between the two conditions, whereas the dogs’ search behavior did, indicating a flexible use of different sensory modalities. Little is known about the cognitive mechanisms involved in the ability of GWL dogs to recognize labeled objects. These findings supply the first evidence that for GWL dogs, verbal labels evoke a multisensory mental representation of the objects.
Similar content being viewed by others


Introduction
Search tasks, in which one is requested to find a specific stimulus, may rely on discrimination or recognition. We refer to discrimination when an individual perceives the difference between two (or more) stimuli/objects and expects them to result in different outcomes (Blair et al. 2003). Recognition occurs when the subject identifies a stimulus as one that s/he has previously encountered (Akkerman et al. 2012). Recent studies have confirmed that dogs can discriminate, for example, among visual images (Range et al. 2008), images of dogs from other animal species (Autier-Dérian et al. 2013), human voices (Gábor et al. 2019), and olfactory stimuli (Pinc et al. 2011).
In human infants, visual object discrimination develops earlier than object recognition and it is hypothesized that these two processes involve different neural circuits (Overman et al. 1992). The performance of both human infants (Overman et al. 1992) and dogs (Milgram et al. 1994) in object discrimination and recognition tests suggests that the latter is a more complex task. Moreover, when solving object recognition tasks, dogs require a large number of trials to achieve predetermined learning criteria (Milgram et al. 1994).
According to cognitive computational theories, perceptual information is processed in the mind to form mental representations of the environment (Sternberg 2009). In humans, the information obtained from different perceptual modalities is integrated, leading to the formation of a multisensory mental representation (Lacey et al. 2007). In dogs, studies have shown similar modalities used to develop a multisensory representation of social stimuli. Adachi et al. (2007) argued that dogs form a multisensory representation of their owners. They found that, when tested in a violation of the expectations paradigm, dogs looked longer when the presented face did not match the audio recording that was played. In another study, dogs were presented with women and men while listening to a recording of a human voice. Dogs that lived with both genders looked longer at the person whose gender matched the played recording (Ratcliffe et al. 2014).
Studies on the sensory modalities used by dogs during search tasks reported that dogs showed a tendency to rely on visual information (Bräuer and Belger 2018) or a combination of vision and olfaction to find their target (Polgár et al. 2015). Kaminski et al. (2009) found that while engaging in an object recognition task, some dogs were able to rely purely on visual information, as they identified objects from pictures. Explosive detection dogs were able to find their target under complete darkness, demonstrating that they could discriminate between stimuli by relying only on olfactory cues (Gazit and Terkel 2003). In addition, there is evidence that dogs can use tactile information to categorize objects (van der Zee et al. 2012). However, overall, only a few studies investigate the abilities of dogs to use sensory modalities other than vision and olfaction (Bálint et al. 2020).
Few dogs present the rare ability to identify objects based on their verbal labels (Kaminski et al. 2004; Pilley and Reid 2011; Fugazza et al. 2021a, b). We labeled these dogs as Gifted Word Learner (GWL) dogs (Fugazza et al. 2021b). The identification of objects based on their verbal labels can be considered a specific case of object recognition. Just like humans, GWL dogs not only recognize the labeled objects—or categories of objects (Fugazza and Miklosi 2020) as stimuli they have already encountered, but they also identify them among other similarly familiar named objects, based on their verbal labels. It is unknown whether the extreme difference between typical dogs (hereafter, T dogs) that lack this capacity, and GWL dogs rises from differences in the ability to discriminate and/or recognize objects, or whether it derives from constraints related to associating labels to objects (Ramos and Mills 2019).
Language acquisition is not fundamental for forming a cross-modal mental representation of objects, however, familiarization with objects' verbal labels might facilitate the process (Lacey et al. 2007). Therefore, in Experiment 1, we investigated the capacity and sensory modalities used by T and GWL dogs to discriminate objects recently associated with a reward from distractors, under light and dark conditions. Previous studies have shown that dogs form multisensory mental representations of social stimuli and that, in the absence of specific training, they tend to rely on vision or vision and olfaction during search tasks. We, therefore, hypothesized that depending on the environmental constraints, the dogs will rely on different sensory modalities, and will successfully discriminate the objects used in this test. More specifically, we hypothesized that under the conditions tested in this experiment dogs will mostly rely on vision, when possible, but they will successfully switch to using other sensory modalities in the dark. Thus, we predicted that their searching behavior, but not their overall success rate, will differ between light and dark conditions. Based on the evidence of typical dogs’ discrimination capacities (Affenzeller et al. 2017; Milgram et al. 2005), we expected that both GWL and T dogs would solve the discrimination task. However, as it is not clear to which extent the verbal labels of the objects influence their mental representations, the two groups may differ in their searching behavior.
In Experiment 2, we utilized the GWL dogs' pre-existing vocabulary of object names to examine whether the object verbal label elicits the recall of a multisensory mental representation. We hypothesized that upon hearing the verbal label of an object, the GWL dogs recall a specific multisensory mental representation so that their recognition capacity is not affected by the lack of visual information. Hence, we predicted that, when searching for a named object, their success rate does not differ between light and dark conditions, while the sensory modalities used to recognize it do.
Materials and methods
Experiment 1
Subjects
We tested 14 dogs, 10 of which were typical (T) family dogs (5 males, 5 females, age = 2.8 years ± 1.8) and 3 were GWL dogs (1 male, 2 females, age = 2.9 years ± 2.8). The T dogs were from various breeds (5 Border Collies, 1 Pinscher, 1 Labrador-poodle cross, 1 mongrel, 1 Australian Shepherd, and 1 Border Terrier). They were selected based on their owners' reports that they were motivated to retrieve toys but did not have knowledge of object names or experience in scent detection. The GWL dogs participating were all Border Collies. These dogs (Max, Gaia, and Nalani) had participated in a previous study (Fugazza et al. 2021b) and proved to know the names of more than 20 dog toys (for the methods and results see Fugazza et al. 2021b).
Procedure
Location 1 GWL dog and 10 T dogs were tested at the Department of Ethology at ELTE University, Budapest, Hungary. The dogs were familiar with this location as they had participated in previous, unrelated experiments. 3 of the GWL dogs were tested at their homes (Whisky in Norway, Nalani in Nederland, Gaia in Brazil) using an experimental setup that was like the one available in the lab (see setup section below).
Setup The experimenter (E) and the dog owner (O) stood with the dog in one room (owner room) while the toys were placed in an adjacent room (toys room). A corridor connected the two rooms and heavy curtains were hung in both openings of the corridor. These curtains prevented light from the owner's room from entering the toy room. All the windows in the toy room were covered with multiple layers of dark nylon sheets to prevent external light from entering the room (Fig. 1).

The experimental setup. a The dog, its owner, and experimenters were positioned in the owner's room; b Two sets of heavy curtains (dotted lines) were hung at both openings of the corridor to prevent light from the owner's room from entering the toys room; c The toys were positioned out of the owners view in the toys room. Measurements in the figure are from the laboratory of ELTE University. For the two GWL dogs that were tested at their owners' homes, the experimental setup was identical, but the room measurements were different (see appendices)
Objects For all dogs, the same 10 unfamiliar objects (dog toys) were used during the experiment. The toys were of different shapes, sizes, materials, and colors (see Fig. 1 in the supplementary material). For each dog, E randomly divided the 10 toys into two sets and randomly selected a toy out of each set to serve as a target toy (target toys 1 and 2). The additional four toys in each set served as distractor objects. The allocation of the toys to serve as a target or a distractor was random across dogs (a toy that served as a target toy for one dog served as a distractor for a different dog).
Training E gave the target toy to the owner (target toy 1). O then played with it with the dog, occasionally placing it among the 4 other distractor toys, and rewarding the dog with praise, play, and/or food, when it retrieved it. The training duration was between 5 and 10 min. For a detailed description of the training procedure, see appendices.
After the training, the dog received a 5-min break and continued to the light baseline test to assess the training success (see below). The same target toy was also used in the dark condition (see Dark condition below). After the dog completed both conditions, on a separate testing occasion, the whole process was repeated using a different target toy (toy 2). 1 day to two weeks elapsed between the two testing occasions, depending on the owners’ availability. For each subject, the toys were randomly assigned to serve as toys 1, 2, or distractors. Overall, each dog was tested twice in the light baseline (once with toy 1 and once with toy 2) and twice in the dark condition (once with toy 1 and once with toy 2). For pictures of the toys see Fig. 1 in the supplementary material.
Light condition
Testing procedure The dogs were requested to retrieve the target toy when it was placed among 4 other toys used as distractors during the training stage. The toys were randomly scattered on the floor in an area of about 1.5 m in diameter. In each trial, O asked the dog to fetch the target toy (e.g., “Go get it!”). The test consisted of 10 trials. After every successful trial, the dog was rewarded by playing with the retrieved toy, praise, and/ or food, then E took the toy back to the toys’ room and shuffled all the toys on the floor. If the dog made an incorrect choice, O did not reward the dog and gave the retrieved toy back to E, who repeated the procedure described above. If the dog failed to retrieve the correct toy in 7/10 trials, it repeated the pretraining stage with a different target toy.
Dark condition
Setup and testing procedure The test setup and procedure were identical to the light baseline but the lights in the corridor and the toys’ room were turned off. When the dog passed from one room to the other, the curtains hanging at the entrances of the room prevented the transmission of light. Light measurements conducted with Luxmeter (VOLTCRAFT MS-1300®) confirmed that there was complete darkness (lux = 0) in the toys’ room.
Data collection
The tests were recorded using an infrared video camera (Sony® Exmor R Balanced Optical Steady Shot 30X). The footage was coded using Solomon Coder beta 19.08.02 (Copyright © 2010 András Péter; http://solomoncoder.com, Eötvös Loránd University, Budapest, Hungary). The dogs' correct or incorrect object choices were marked for all trials. In addition, the behavior of the dogs in the toys room was coded. As behavioral coding was time-consuming, for each dog, we coded the first and the last three trials of each condition, using the following behavioral variables (see also Supplementary video).
Object choice We considered a toy to be chosen by the dog when it exited the toy room with it in its mouth. We coded this as a binary variable: 1 = the dog selected the correct object; 0 = the dog did not select the correct object.
Search The dog oriented its head towards the floor, carrying the head in line with the shoulder blades or lower. If the dog picked up a toy, lifted the head higher than the shoulder blades, or stopped orienting towards the floor and the toys, the measurement of this behavior was interrupted until the dog resumed the searching position described above. We measured the duration of this behavior.
Sniffing The dog’s sniffing behavior was coded every time that the sound of the dog inhaling through the nostrils was heard by the coders. This behavior was coded only when the dog was also engaged in search behavior. For this behavior, we measured the frequency and duration.
Straight approach The dog entered the toy room and moved towards a toy in a straight line, without diverting the head to the sides, until picking up the toy. We measured the frequency of straight approaches.
Picking up an object The dog picked up an object with its mouth. We measured latency to pick the object up from the moment the dog entered the toy room. Picking an object up also marked the end of the searching behavior, unless the dog dropped the toy and kept searching.
Mouthing The dog chewed a toy or shook it. We measured the duration of mouthing. This variable was included as an indication of the use of tactile and gustatory senses.
Twenty percent of the data was coded by an independent coder to determine inter-rater agreement.
Data analysis
For the behavioral analysis, we coded the object choice and straight approach as separate binary responses (i.e., 1 = correct choice or straight approach, 0 = incorrect choice or not straight approach). The durations and latencies were measured in seconds. Statistical analyses were carried out in the R environment (R Core Team 2019). The latency to picking up an object was analyzed in Cox Mixed Models (CMM). The probability of correct choice (binary response) in Experiment 1 was analyzed using a binomial test, with the chance level set at 0.2 as there were always 5 toys to choose from. The subsequent analyses of all other behavioral responses described above included the first 3 and last 3 trials. Cronbach’s alpha was used to assess the inter-observer reliability of the two independent coders (DeVellis 1991). Behavioral responses were analyzed in separate Linear Mixed Models (LMM, for durations and frequencies, Pinheiro et al. 2019) and binomial Generalized Linear Mixed Models (GLMM, for binary responses; Bates et al. 2014). Initial models included ‘trial’ (factor with 6 levels: 1–3 and 8–10) and ‘dog group’ (factor with two levels: T and GWL dogs). Since there was no difference between the first and last trials and the two dog groups did not differ in any of the response variables (see “Results”), both explanatory variables were excluded from the final models. GLMMs included condition (Light or Dark) and toy (1 and 2) as explanatory variables. Finally, the dogs’ names were used as random effect in the model.
Results
Inter-rater agreement was excellent for all the variables (Cronbach’s alpha, all variables > 0.9)
All dogs, except for one T dog (Scotch), reached the a priori set criterion in the light baseline test (7/10 correct trials) after the first attempt. Scotch succeeded after repeating the training and the test with a new object (binomial test, p < 0.05, Table S1 in the Supplementary material). All dogs were individually successful well above chance level (binomial tests, all p < 0.05, Table S1 in the supp. mat.) in both light baseline and dark conditions, with both toys 1 and 2 (Fig. 2a).

a Mean success rate (± SD) of all dogs (irrespective of type, i.e., GWL or T) in choosing the correct toy in light and dark conditions. Separate bars illustrate success toys 1 and 2. The dashed line represents the chance level at 20%. b The mean time spent searching (± SD, in seconds) in the two conditions. c Percentage of searching time spent sniffing (± SD) in the light and dark conditions. Significance (GLMM, p < 0.05) is indicated with *
The dogs’ success rate was always above chance (z = 7.899, p < 0.001) and there was no difference between the two groups (χ2 = 0.701, df = 1, p = 0.791). GWL and T dogs did not differ significantly in their behavioral response between the beginning (first 3 trials) and the end (last 3 trials) of the test (χ2 = 4.616, df = 5, p = 0.465). In addition, the two groups did not differ in any of the other response variables (LRT of dog group, LMM of frequency of sniffing: χ2 = 0.051, df = 1, p = 0.820; GLMM of frequency of straight approach: χ2 = 0.074, df = 1, p = 0.785; CMM of latency to pick up the toy: χ2 = 1.33, df = 1, p = 0.249; LMM of duration of sniffing χ2 = 0.923, df = 1, p = 0.337, searching χ2 = 0.359, df = 1, p = 0.549; and mouthing χ2 = 0.262, df = 1, p = 0.608), hence we analyzed results of all dogs together, irrespective of dog type. Accuracy in choosing the target toy was not influenced by the condition (χ2 = 0.239, p = 0.625). There was an order effect related to the success rate: dogs showed a higher success rate with Toy 2 – i.e., the toy used in the second instance (χ2 = 5.473, df = 1, p = 0.01). Although, there was never a significant difference between toy 1 and toy 2 in relation with the other behavioral variables (all p-values > 0.05). Thus, we also discarded this variable from the model.
There was a significant difference between conditions, with dogs spending more time searching (χ2 = 122.92, df = 1, p < 0.001; Fig. 2b) and longer latency to pick up the toy in the dark (χ2 = 53.393, df = 1, p < 0.001). The duration of mouthing did not differ between conditions (χ2 = 1.653, df = 1, p = 0.197). The condition also affected the frequency of straight approach, which never occurred in the dark (χ2 = 75.394, df = 1, p < 0.001).
The proportion of searching time spent sniffing was different between conditions, with the dogs spending more time sniffing while searching in the dark (χ2 = 18.989, df = 1, p < 0.001; Fig. 2c).
Experiment 2
Subjects
The 3 GWL dogs tested in experiment 1 were also tested in this experiment, as well as an additional female Border Collie (Whisky, 4.4 years old).
Procedure
Location and setup The location and setup were as described for experiment 1.
Objects Each of the GWL dogs possessed a collection of familiar and named dog toys. The 4 dogs’ knowledge of these object names was confirmed in Fugazza et al. (2021b). For each dog, 20 of these toys were randomly chosen and scattered on the floor in a surface area of about 3 m in diameter.
Light condition
Procedure E instructed O to ask the dog to retrieve a toy by pronouncing the toy’s name. The dog then left the owner's room and entered the toy room to select a toy. If the dog successfully retrieved the correct toy, it was rewarded with play, praise, and food. If the dog made a mistake, the trial was repeated but the results of the repeated trials were not included in the analysis of the success rate. If the dog made another consecutive mistake, E instructed O to proceed with the next trial. The order of the toys was randomly determined. After every five trials, E placed 5 additional randomly selected toys on the floor. This way, the number of toys from which the dog could choose always varied between 20 and 16.
Dark condition
The test was identical to the light baseline test, but the lights in the toys’ room and corridor were turned off.
Data collection
The dog's correct or incorrect choice was coded in all trials. The behavioral variables described for experiment 1 were also coded in experiment 2 for all trials.
Data analysis
Statistical analysis was carried out similarly to that of Experiment 1, except that, for the analysis of the success rate, the chance level was conservatively set at 0.06 because the total number of toys available ranged between 16 and 20.
Results
Inter-rater agreement was again excellent for all the variables (Cronbach’s alpha, all variables > 0.9).
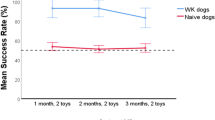
The GWL dogs successfully selected the correct toy in both light and dark conditions (binomial test, all p < 0.05, Table S2 in the supplementary material), with no significant difference between the two (GLMM: χ2 = 2.049, df = 1, p = 0.152; Fig. 3a).

a The bars show the mean success rate (± SD) of the GWL dogs in both conditions. The dashed line represents the chance level (6%, determined based on the lowest number of toys present for the dogs to select from). b The mean time spent searching (± SD, in seconds) in the two conditions. c Percentage of searching time (± SD) spent sniffing in the light and dark conditions. Significance (GLMM, p = 0.05) is indicated with *
The GWL dogs spent more time searching for the named toys in the dark condition compared to the light baseline (χ2 = 9.255, p < 0.001; Fig. 3b); There was no significant difference between conditions for the latency to pick up the toy (χ2 = 0.152, p = 0.696), and duration of mouthing (χ2 = 0.046, p = 0.831).
We did not observe any straight approach in the dark condition, while we observed straight approaches in 15 trials out of 80 (1 for Gaia, 2 for Max, 4 for Nalani, and 8 for Whisky) in the light baseline.
The proportion of searching time spent sniffing was different between conditions with the dogs spending more time sniffing while searching in the dark (χ2 = 3.671, df = 1, p < 0.05; Fig. 3c).
General discussion
While the dogs' success in both experiments did not differ between conditions, our detailed behavioral analysis revealed that, when searching in the dark, dogs spent a longer time actively searching and sniffed more.
These findings indicate that dogs integrated information perceived through different sensory modalities and that, while vision was among the preferred modality for identifying the objects tested in this experiment, dogs can spontaneously and successfully revert to using only other senses if visual information is not available. By doing so, dogs present a flexible use of different sensory modalities (see also Szetei et al. 2003; Polgár et al. 2015).
The occasional straight approaches observed only in the light baseline suggest that, when visual information is available, dogs can also identify the object from a distance. However, most often, dogs tended to search among the different objects from a closer distance. This indicates the use of close-range vision and also, potentially, other sensory modalities, including not only olfaction but also touch—as we found very few and short occurrences of sniffing in the light baseline. Our results are consistent with the findings of Bräuer and Belger (2018), who observed that sniffing behavior increased the latency of approaching and decreased the number of direct approaches towards a target object.
Humans can rely on tactile information when visual input is limited (Lacey et al. 2007). Nevertheless, our results did not reveal differences in the time spent by the dogs exploring the toys with their mouth (i.e., mouthing behavior) between conditions in both experiments. This may indicate that these senses are equally used, irrespectively of the illumination, or that they are not relied on at all in object search. However, dogs may also display behaviors other than what we defined as “mouthing” when using tactile or gustatory senses, such as using their noses or whiskers. Thus, we do not exclude that these sensory modalities may have been used differently in the two experimental conditions by the dogs. In addition, dogs often mouth toys as part of their play behavior. It could, therefore, be that the definition of this behavioral variable was not sensitive enough to reflect the use of tactile sensation.
In Experiment 1, all dogs displayed a high success rate, that did not differ between conditions. This demonstrates that both T and GWL dogs can discriminate between a target object, associated with a reward during the immediately preceding training, and distractor objects. These findings are in agreement with previous studies reporting on dogs’ ability to perform object discrimination tasks (Milgram et al. 1994; Head et al. 1998; Tapp et al. 2004) and expand those to situations of limited sensory information. Our finding that although the dogs’ success rate in Experiment 1 was already above chance when tested on the first toy (i.e., toy 1), their performance increased when tested again (i.e., on toy 2), could be attributed to the dogs becoming experienced in the task and familiar with the test situation during the experiments (Hunter and Kamil 1971). Similarly, Bräuer and Belger (2018), described that dogs’ latency of finding a target object decreased as their experience in the task increased.
We did not find differences between the success rate of T and GWL dogs in the object discrimination task, nor did we observe differences in their searching behavior. This suggests that the extreme difference between the ability of GWL and T dogs to recognize objects based on their labels (Fugazza et al. 2021a, b) does not result from differences in object discrimination capacities.
While in Experiment 1, the two groups of dogs discriminated rewarded from non-rewarded objects, in Experiment 2, the objects from which the GWL dogs had to select were all familiar objects. Thus, this is a specific complex case of object recognition that cannot be solved by simply relying on familiarity. The GWL dogs' success in recognizing these objects according to their verbal labels did not differ between dark and light conditions. Ganea (2005) described how, after hearing the names of familiar objects, 14-month-old infants started to search for them and found the objects, thereby demonstrating that the objects’ verbal labels led to the retrieval of the object’s representation. When tested in the object recognition task, GWL dogs demonstrated that they can recognize familiar objects under limited sensory inputs, thereby demonstrating that they have formed a multisensory mental representation of the object (Lacey and Sathian 2011, for review). Moreover, the GWL dogs’ success in retrieving the named toys shows that for each object verbal label, they form a specific multisensory mental representation, enabling them to recognize the correct toy even when it is placed among other labeled objects in the dark. In other words, for GWL dogs, hearing an object’s verbal label evokes a mental representation of the object.
To summarize, we found that, in the absence of formal training, dogs mostly rely on proximate vision and, potentially, touch sense in object discrimination and recognition tasks but can switch to using only other sensory modalities when vision is not possible. Dogs spontaneously encode different features of the objects, leading to the construction of multisensory mental representations. In the case of GWL dogs, a memory of the multisensory representation is evoked by hearing the objects' verbal labels as they perform complex object recognition tasks.
References
Adachi I, Kuwahata H, Fujita K (2007) Dogs recall their owner’s face upon hearing the owner’s voice. Anim Cogn 10:17–21. https://doi.org/10.1007/s10071-006-0025-8
Affenzeller N, Palme R, Zulch H (2017) Playful activity post-learning improves training performance in Labrador Retriever dogs (Canis lupus familiaris). Physiol Behav 168:62–73. https://doi.org/10.1016/j.physbeh.2016.10.014
Akkerman S, Blokland A, Reneerkens O et al (2012) Object recognition testing: Methodological considerations on exploration and discrimination measures. Behav Brain Res 232:335–347. https://doi.org/10.1016/j.bbr.2012.03.022
Autier-Dérian D, Deputte BL, Chalvet-Monfray K et al (2013) Visual discrimination of species in dogs (Canis familiaris). Anim Cogn 16:637–651. https://doi.org/10.1007/s10071-013-0600-8
Bálint A, Andics A, Gácsi M et al (2020) Dogs can sense weak thermal radiation. Sci Rep 10:3736. https://doi.org/10.1038/s41598-020-60439-y
Bates D, Mächler M, Bolker B, Walker S (2014) Fitting linear mixed-effects models using lme4. arXiv Prepr arXiv 1406.5823
Blair CAJ, Blundell P, Galtress T et al (2003) Discrimination between outcomes in instrumental learning: Effects of preexposure to the reinforcers. Q J Exp Psychol 56B:253–265. https://doi.org/10.1080/02724990244000241
Bräuer J, Belger J (2018) A ball is not a Kong: Odor representation and search behavior in domestic dogs (Canis familiaris) of different education. J Comp Psychol 132:189–199. https://doi.org/10.1037/com0000115
DeVellis R (1991) Scale development: theory and applications. Sage Publications, Thousand Oaks
Fugazza C, Andics A, Magyari L et al (2021a) Rapid learning of object names in dogs. Sci Rep 11:2222. https://doi.org/10.1038/s41598-021-81699-2
Fugazza C, Dror S, Sommese A et al (2021b) Word learning dogs (Canis familiaris) provide an animal model for studying exceptional performance. Sci Rep 11:14070. https://doi.org/10.1038/s41598-021-93581-2
Gábor A, Kaszás N, Miklósi Á et al (2019) Interspecific voice discrimination in dogs. Biol Futur 70:121–127. https://doi.org/10.1556/019.70.2019.15
Ganea PA (2005) Contextual factors affect absent reference comprehension in 14-month-olds. Child Dev 76:989–998. https://doi.org/10.1111/j.1467-8624.2005.00892.x
Gazit I, Terkel J (2003) Domination of olfaction over vision in explosives detection by dogs. Appl Anim Behav Sci 82:65–73. https://doi.org/10.1016/S0168-1591(03)00051-0
Head E, Callahan H, Muggenburg BA et al (1998) Visual-discrimination learning ability and β-amyloid accumulation in the dog. Neurobiol Aging 19:415–425. https://doi.org/10.1016/S0197-4580(98)00084-0
Hunter MW, Kamil AC (1971) Object-discrimination learning set and hypothesis behavior in the northern bluejay (Cynaocitta cristata). Psychon Sci 22:271–273. https://doi.org/10.3758/BF03335950
Kaminski J, Tempelmann S, Call J, Tomasello M (2009) Domestic dogs comprehend human communication with iconic signs. Dev Sci 12:831–837. https://doi.org/10.1111/j.1467-7687.2009.00815.x
Kaminski J, Call J, Fischer J (2004) Word learning in a domestic dog: evidence for “Fast Mapping.” Science 304:1682–1683. https://doi.org/10.1016/j.bandl.2009.11.002
Lacey S, Sathian K (2011) Multisensory object representation Insights from studies of vision and touch. In: Green AM, Chapman CE, Kalaska JF, Lepore F (eds) Progress in brain research, 1st edn. Elsevier, Amsterdam, pp 165–176
Lacey S, Campbell C, Sathian K (2007) Vision and touch: multiple or multisensory representations of objects? Perception 36:1513–1521. https://doi.org/10.1068/p5850
Milgram NW, Head E, Weiner E, Thomas E (1994) Cognitive functions and aging in the dog: acquisition of nonspatial visual tasks. Behav Neurosci 108:57–68. https://doi.org/10.1037//0735-7044.108.1.57
Milgram NW, Head E, Zicker SC et al (2005) Learning ability in aged beagle dogs is preserved by behavioral enrichment and dietary fortification: a two-year longitudinal study. Neurobiol Aging 26:77–90. https://doi.org/10.1016/j.neurobiolaging.2004.02.014
Overman W, Bachevalier J, Turner M, Peuster A (1992) Object recognition versus object discrimination: comparison between human infants and infant monkeys. Behav Neurosci 106:15–29. https://doi.org/10.1037/0735-7044.106.1.15
Pilley JW, Reid AK (2011) Border collie comprehends object names as verbal referents. Behav Processes 86:184–195. https://doi.org/10.1016/j.beproc.2010.11.007
Pinc L, Bartoš L, Reslová A, Kotrba R (2011) Dogs Discriminate Identical Twins. PLoS ONE 6:e20704. https://doi.org/10.1371/journal.pone.0020704
Pinheiro J, Bates D, DebRoy S, et al (2019) Linear and Nonlinear Mixed Effects Models. In: R Packag. version. https://cran.r-project.org/package=nlme . Accessed 30 Jul 2019
Polgár Z, Miklósi Á, Gácsi M (2015) Strategies used by pet dogs for solving olfaction-based problems at various distances. PLoS ONE 10:1–15. https://doi.org/10.1371/journal.pone.0131610
R Core Team (2019) R: a language and environment for statistical computing
Ramos D, Mills DS (2019) Limitations in the learning of verbal content by dogs during the training of OBJECT and ACTION commands. J Vet Behav 31:92–99. https://doi.org/10.1016/j.jveb.2019.03.011
Range F, Aust U, Steurer M, Huber L (2008) Visual categorization of natural stimuli by domestic dogs. Anim Cogn 11:339–347. https://doi.org/10.1007/s10071-007-0123-2
Ratcliffe VF, McComb K, Reby D (2014) Cross-modal discrimination of human gender by domestic dogs. Anim Behav 91:127–135. https://doi.org/10.1016/j.anbehav.2014.03.009
Sternberg RJ (2009) Cognitive psychology. Cognitive psychology, 5th edn. Wadsworth Publishing, USA, pp 74–121
Szetei V, Miklósi Á, Topál J, Csányi V (2003) When dogs seem to lose their nose: an investigation on the use of visual and olfactory cues in communicative context between dog and owner. Appl Anim Behav Sci 83:141–152. https://doi.org/10.1016/S0168-1591(03)00114-X
Tapp PD, Siwak CT, Head E et al (2004) Concept abstraction in the aging dog: Development of a protocol using successive discrimination and size concept tasks. Behav Brain Res 153:199–210. https://doi.org/10.1016/j.bbr.2003.12.003
van der Zee E, Zulch H, Mills D (2012) Word generalization by a dog (Canis familiaris): is shape important ? PLoS One. https://doi.org/10.1371/journal.pone.0049382
Acknowledgements
We thank Ákos Pogány for his advice on data analysis. We are immensely grateful to the owners who participated with their dogs in this experiment.
Funding
Open access funding provided by Eötvös Loránd University. This study was supported by the National Brain Research Program (2017-1.2.1-NKP-2017-00002). Á.M. received funding from MTA-ELTE Comparative Ethology Research Group (MTA01 031).
Author information
Authors and Affiliations
Contributions
The study was conceived by CF; data collection was carried out by SD, AS, AT, and CF; data analysis was carried out by AS; the manuscript was drafted by SD and AS and revised by all authors.
Corresponding authors
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Ethics approval and consent
Ethical permission for conducting this study was obtained from The Institutional Committee of Eötvös Loránd University (N. PE/EA/691-5/2019) and covered both experiments described in this study. All owners gave informed consent to participate in the study with their dogs.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary file2 (MP4 9477 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dror, S., Sommese, A., Miklósi, Á. et al. Multisensory mental representation of objects in typical and Gifted Word Learner dogs. Anim Cogn 25, 1557–1566 (2022). https://doi.org/10.1007/s10071-022-01639-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10071-022-01639-z