
Abstract
Landslides are a serious problem for humans and infrastructure in many parts of Europe. Experts know to a certain degree which parts of the continent are most exposed to landslide hazard. Nevertheless, neither the geographical location of previous landslide events nor knowledge of locations with high landslide hazard necessarily point out the areas with highest landslide risk. In addition, landslides often occur unexpectedly and the decisions on where investments should be made to manage and mitigate future events are based on the need to demonstrate action and political will. The goal of this study was to undertake a uniform and objective analysis of landslide hazard and risk for Europe. Two independent models, an expert-based or heuristic and a statistical model (logistic regression), were developed to assess the landslide hazard. Both models are based on applying an appropriate combination of the parameters representing susceptibility factors (slope, lithology, soil moisture, vegetation cover and other- factors if available) and triggering factors (extreme precipitation and seismicity). The weights of different susceptibility and triggering factors are calibrated to the information available in landslide inventories and physical processes. The analysis is based on uniform gridded data for Europe with a pixel resolution of roughly 30 m × 30 m. A validation of the two hazard models by organizations in Scotland, Italy, and Romania showed good agreement for shallow landslides and rockfalls, but the hazard models fail to cover areas with slow moving landslides. In general, the results from the two models agree well pointing out the same countries with the highest total and relative area exposed to landslides. Landslide risk was quantified by counting the number of exposed people and exposed kilometers of roads and railways in each country. This process was repeated for both models. The results show the highest relative exposure to landslides in small alpine countries such as Lichtenstein. In terms of total values on a national level, Italy scores highest in both the extent of exposed area and the number for exposed population. Again, results agree between the two models, but differences between the models are higher for the risk than for the hazard results. The analysis gives a good overview of the landslide hazard and risk hotspots in Europe and allows a simple ranking of areas where mitigation measures might be most effective.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The public and media focus on landslide hazard and risk in Europe is greatly increased in the immediate aftermath of catastrophes such as the widespread flooding and landsliding in Switzerland and Austria in summer 2005, Messina (Italy) in autumn 2009, or the events in Madeira in January 2010 and southern Italy in February 2010. Besides catastrophic events, numerous landslides occur in Europe each year (EEA 2010; EM-DAT 2003), and experts know to a certain degree which parts of the continent are most exposed to landslide hazard. Nevertheless, landslide events, such as the examples mentioned above, do not necessarily highlight the areas in Europe with the highest landslide risk, as a landslide is not hazardous unless it threatens some elements at risk (Alexander 2004).
Landslide susceptibility and/or hazard has been studied at the global scale by Nadim et al. (2006), NASA (Hong et al. 2007; Kirschbaum et al. 2009) and the World Bank (Dilley et al. 2005). Van Den Eeckhaut and Hervas (2012) present a review on available national landslide databases in Europe and use the data in a new approach to landslide susceptibility for Europe based on logistic regression modeling, Van Den Eeckhaut et al. (2012). On a national or regional scale similar studies were conducted for Cuba (Castellanos Abella and Van Westen 2007), Pakistan (Peduzzi 2010), Serbia (Marjanovic et al. 2011) and Turkey (Nefeslioglu et al. 2011) to mention some recent examples.
The objective of this study is to perform a first-pass analysis of landslide hazard at the European scale to identify the landslide hazard and risk ‘hotspots’: i.e., where hazard and risk are highest. Landslide hazard is estimated by two different models applying an appropriate combination of the parameters representing susceptibility factors (slope, lithology, soil moisture, vegetation cover) and triggering factors (extreme precipitation and seismicity). The intersection of the landslide hazard, population density and infrastructure density map allows identification of areas where potential landslide activity coincides with areas of higher population and/or infrastructure density, thus providing a first-pass estimate of landslide risk ‘hotspots’. The results give an overview over the exposed areas and allows a simple ranking of countries in which the investment of money will yield the highest protective effect for humans and infrastructure. After the introduction and a general section on susceptibility, hazard and risk and the difficulties of assessing them at continental scale, the datasets available for the risk assessment are described before the presentation of the applied models.
Materials and methods
Susceptibility, hazard and risk
Three consecutive assessments have to be combined to achieve an estimate of the risk (i.e., susceptibility, hazard and risk: Hansen 1984; Guzzetti et al. 1999; Glade et al. 2005; Hervás and Bobrowsky 2009). The physical environment in itself gives the basis for the susceptibility to landslides. This category includes the terrain (steep, flat), geology, soils, vegetation and land use. These factors decide if the area has the potential to generate a landslide but do not give any estimate of the likelihood of an event. The likelihood of an event is determined by a trigger. This trigger can be the effect of water (precipitation and snow melt), seismic activity or human activities such as excavation or blasting in or close to the landslide-prone terrain. The most common trigger is heavy rainfall that exceeds the normally experienced rain events in an area (Cepeda et al. 2010).
Landslides as a natural process present no danger or threat in themselves. For this to happen there must be some form of interaction with humans and/or their activities. The presence of humans, their infrastructure and possessions is usually described as the element at risk or exposure. Once the areas where a landslide hazard exists are identified, the number of people and assets located in these hazard zones as well as their vulnerability, i.e., degree of loss (UNDRO 1979), can be assessed. For example, a wooden shack would be more easily destroyed by a landslide than a solid house with concrete foundations. On the other side, the value of a solid house with concrete foundations would, all other factors being equal, be greater than that of a wooden shack leading to the same risk in terms of economical loss.
The combination of hazard and vulnerability leads to the risk. This can be described in a mathematical way as (Varnes and The International Association of Engineering Geology Commission on Landslides and Other Mass Movements 1984):
with susceptibility × trigger = hazard.
A high quality hazard assessment is a more complex task than assessing susceptibility in terms of models, data availability and resource use. Introducing a trigger creates instant challenges. The information on landslide frequency needed for inclusion in the hazard models is generally obtained from the study of past landslide events. However, detailed historical records are often not available, and if available, the information stored is not always reliable. Precipitation extremes are, for example, often not even captured by the standard meteorological network, which is often configured for synoptic purposes. Another difficulty is that the correct threshold of the amount of rainfall actually needed to produce landslides can be very different from region to region.
Even more challenging than hazard assessment is the study of risk. For a true estimate, one should sum up all the assets that can be destroyed in a landslide event. This can range from a road with cables and pipes to entire houses with their content. On a European scale, this kind of approach is not applicable. Therefore, only two types of elements at risk are considered in this study, the number of people living in landslide exposed areas and the accumulated number of kilometres of national and international roads and railroads. The analysis helps to identify where in Europe the risk hotspots are located and allows comparison of the risk level between the countries included in the analysis.
Input data
A comparative hazard and risk analysis for Europe requires homogeneous datasets. Locally and nationally, detailed maps of population, development index, geology and other relevant information are generally available. They are, unfortunately, of little value for use in a Europe-wide analysis. Often the methods used for creating the maps are different from one country to another and in some cases the methods (e.g., resolution, classification/language, date of document, projection, quality and accuracy, etc.) are not publicly available at all. Local data are, therefore, applicable for the verification of the European model but not as inputs to the model.
Homogenous European datasets are difficult to access, with many datasets only covering the countries within the European Union. The alternatives are global datasets which may lack accuracy and in many cases are not well suited to study differences between European countries. The first challenge for this study was, therefore, to gather the best possible datasets for each input parameter (Table 1).
Topography is a key factor for landslide susceptibility. In flat terrain, the gravitational forces are too weak to move land masses. With increasing inclination, the terrain becomes more susceptible to landsliding. Natural loose geological material is usually stable up to slope angles of 27°. In terrain steeper than 30°, rocks and other loose materials fall continuously and do not create deposits which can form larger landslides. Above 45°, usually only rockfalls and large rock avalanches occur. The applied datasets for the European study are SRTM (2009) (resolution 3 arcsec) with data up to 60°N and GTopo (1996) (resolution 30 arcsec) with data for the northern parts of the continent.
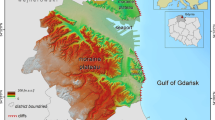
The geology gives information about the strength of the available material that could form a landslide. A European geological map of scale 1:5 million (IGME 5000 2009, BGR, Asch 2003), originally distinguishing 91 classes, was used to classify the type of rock (sediment, igneous, metamorphic) and age of the rock according to its impact on landslide susceptibility (Fig. 1).

Map showing the geology of the study area (IGME 5000, BGR 2005)
Land cover data yields information on the type of surface and its effect on landslide susceptibility. The GLOBECOVER v2.2 data available from ESA (Globcover 2003) has originally 22 different classes of land use and the data was reclassified as input to the ICG and JRC models (Fig. 2).

Map showing the land cover of the study area (Globcover 2003)
Databases of historical landslide events are essential for the calibration and the validation of the model results. Such databases exist in many European countries (Van Den Eeckhaut et al. 2012) but are exceedingly difficult to access. In many cases no national databases, but local collections, often on paper only, are available. Scientific inventories often concentrate on a particular type of landslide and leave out the total picture. For validation of the hazard model in this study, national experience from Romania (Romanian Geological Survey, written communication), inventories from Norway (Jaedicke et al. 2009) and local datasets for the Barcelonnette; France (Flageollet et al. 1999; Remaître 2006; Kappes et al. 2011), Campania; Italy (Catani et al. 2005) and some locations in the UK, particularly in Scotland (Winter et al. 2009; Foster et al. 2012) were used.
Precipitation is a key trigger for landslides with shallow landslides often being released by short time extreme events while deep seated landslides are often triggered by long lasting intense rain fall. Data related to such events are scarce and pose a big challenge to landslide hazard modellers. Currently, European maps are only available for monthly mean precipitation (Rudolf and Schneider 2005). An extreme value analysis was combined with a variance index to model the expected distribution of extreme monthly rainfall.
Seismicity is the second key trigger for landslides. Earthquakes have triggered landslides in many regions of the world, including some of the largest known landslides. The expected peak ground acceleration (PGA) with 475-year return period was available from the Global Seismic Hazard Program, GSHAP (Giardini et al. 2003). In this analysis, separate hazard models were developed for precipitation and seismically triggered landslides.
The consequence of landsliding depends of the presence and amount of human or environmental assets in the affected area. Such assets can be buildings, constructions, roads, railways or other infrastructure, forest, crops and animal life in addition to the humans themselves (GRUMP 2011). There are readily available datasets for major roads and railways for incorporation in the analysis of risk (Fig. 3). Individual buildings cannot be identified at a European scale, but population maps give an indication of the number of people that are exposed to landslide hazard (Fig. 4).

Network of European roads and railways (OpenStreetMap 2009)

Population density in Europe (GRUMP 2011)
Models
Two models were developed separately at the International Centre for Geohazards (ICG) and at the Joint Research Centre (JRC). Both research groups had the same datasets available for their models and the models covered the same study area (i.e., the whole of Europe extending up to the Ural and Caucasus mountains; Figs. 1, 2, 3, 4). The models use two different approaches. While the ICG model is purely expert-based or heuristic, the JRC model uses a statistical technique in the form of logistic regression. Both models assign different weights to each dataset that is used to model the landslide susceptibility and hazard. The resulting hazard maps are then used together with population and infrastructure data to give an estimate of risk.
ICG model
The ICG model is based on the model developed for the global hotspot analysis (Nadim et al. 2006). The model uses topography, geology, land cover, precipitation and seismicity as input parameters and was modified to meet the European datasets available for this study. Each of these input parameters factors are reclassified and the classes are weighted according to geotechnical experience and comparison with landslide inventories.
The hazard maps are divided in precipitation-induced landslide hazard and earthquake-induced landslide hazard. The landslide hazard indices were estimated using the following equations:
where H r and H e are landslide hazard indices for rainfall and earthquake-induced landslides, respectively, S r is the slope factor within a selected grid, S l is lithological (or geological) conditions factor, S v is the vegetation cover factor T p is the precipitation factor, and T s describes the seismic conditions.
The slope factor uses two datasets, the SRTM (<60°N) and GTOPO (>60°N) data which have a different spatial resolution. Therefore, the slope factor, S r, was adjusted to achieve an equal representation of slopes all over Europe (Table 2).
The IGME 5000 Geological map only gives information on the type and age of the lithology. Therefore, the data was reclassified into susceptibility classes taking into account the likelihood for a certain type of rock to produce landslides (Table 3). Young and weak sedimentary deposits have a higher potential for landslides than old hard base rock.
The 22 different classes of land use of the GLOBECOVER v2.2 database have been translated into five categories (scale 1–5) with respect to resistance to landslides. Table 4 shows the range of vegetation factors, S v, for these five categories which are different for precipitation and seismically induced slides (Nadim et al. 2006) is reclassified into urban areas, water bodies, forest and farm land.
Precipitation is derived from global monthly rainfall measurements (Rudolf and Schneider 2005). First, the expected monthly 100 year extreme rainfall was estimated by fitting a Gumbel distribution to the data and a susceptibility factor (T p1) was assigned to the resulting values covering Europe (Table 5).
Second, to accommodate the variability of the precipitation an anomaly factor (T a) was assigned by considering the coefficient of variation CoV (σ/μ; mean divided by standard deviation) of the data. The following range for the anomaly factor is suggested (Table 6) a denotes the smallest value of CoV = σ/μ obtained for the whole globe, and b denotes the largest value of CoV. The values of 'a' and 'b' obtained from the calculations were, respectively, 0.11 and 3.60.
The precipitation trigger factor, T p, was obtained by the equation below:
The variation range for T p is, therefore, 0.8–6.0.
The expected PGA (Giardini et al. 2003) was used for the classification of the seismic trigger factor seismically-induced landslides. The seismic trigger factor, T s, was evaluated from the GSHAP PGA475 data according to Table 7.
Using these input data in Eqs. 4 and 5, results in values of H r = 0–108 (precipitation trigger) and H e = 0–165 (Table 8). The results are then reclassified into three hazard categories, low, medium and high landslide hazard.
The population exposure maps were calculated by counting the amount of people in the respective hazard classes and of the four classes:
The same procedure was applied to count the number of exposed kilometres of roads and railroads. Results are available both on maps and as tables and allow a ranking of the countries.
JRC model
In contrast to the ICG model which considered all landslide types, the JRC model considered only landslides of the slide and flow type. The first step in the JRC model consisted of an assessment of landslide susceptibility using logistic regression. In the second step, the resulting classified landslide susceptibility map was then combined with classified precipitation and seismic data, respectively, to obtain two qualitative hazard maps, one for hydrologically-triggered landslides and one for seismically-triggered landslides. In the third step, the risk analysis was similar to the one of the ICG model.
A detailed description of the landslide susceptibility model using ordinary logistic regression (ORL) can be found in Van Den Eeckhaut et al. (2012). Seven independent variables were extracted from available maps (Table 1). For this purpose the maps were resampled to a uniform grid of 30 arcsec (ca. 930 m), i.e., the resolution of the SRTM v2 DEM available for the whole study area. Maps with categorical variables such as the lithological and geological, soil and land cover maps had a high number of classes and were reclassified into 11, 9, 8 and 7 classes, respectively, using expert knowledge.
The binary dependent variable used in the OLR is the presence (1) or absence (0) of a landslide. Rockfalls were not included in the selected sample. From available landslide inventories, a random sample of 100 landslides in Norway, 100 landslides in Campania (Italy) and 50 landslides in the Barcelonnette Basin (France) was extracted. Additionally a landslide inventory created by JRC, containing 972 landslides was used. This inventory is produced in Google Earth. The ca. 1,200 landslides included in the study obviously only represent a very small proportion of the true number of landslides in Europe.
For the OLR, an equal number of ‘landslide-free’ grid cells are needed. The preparation of this dataset is challenging due to the lack of a complete landslide inventory map of Europe. A specific selection procedure was set up to select a representative sample. It was decided, for example, not to extract the sample of landslide-free grid cells uniformly over the selected study area because otherwise more than 80 % of the selected grid cells would be located in flat areas.
OLR describes the relationship between a dichotomous response variable (Y, i.e., the presence or absence of a landslide) and a set of independent variables (x 1, x 2,…, x n ). The independent variables may be continuous or discrete (with dummy variables) and do not need a normal frequency distribution. The logistic response function can be written as (Hosmer and Lemeshow 2000; Allison 2001):
where p is the probability of occurrence of a landslide, α is the intercept and β i is the coefficient for the independent variable x i estimated by maximum likelihood. Equation (4) can be linearized with the following transformation in which the natural logarithm of the odds, log[p/(1 − p)] is linearly related with the independent variables:
During the last decade, OLR has been increasingly used for landslide susceptibility assessment and attention has been paid to objective evaluation and validation of the calibrated models (e.g., Beguería 2006; Van Den Eeckhaut et al. 2006). Also in this study, the obtained logistic regression model was evaluated and validated (with data not used for model calibration) prior to proceeding to the landslide hazard assessment. Confusion matrices and receiver operation characteristic (ROC) curves were produced and analysed (Hosmer and Lemeshow 2000). Analysis of confusion matrices and ROC curves were further useful for the selection of the boundaries of the ten classes in which the final landslide susceptibility map was reclassified. The objective here was to classify a large proportion of the known landslides without classifying a too large proportion of the European territory as highly susceptible.
Several models were calibrated and evaluated. For the finally selected logistic regression model, the area under the ROC curve (AUC) is 0.888, which indicates excellent discrimination of the landslide-affected and landslide-free grid cells in our sample. Hence, the model was able to classify correctly a high proportion of the landslide sample without incorrectly classifying a high proportion of the landslide-free sample.
The stability of the model was further tested by producing ten logistic regression models using each time 75 % of the sample for calibration and the remaining 25 % for validation.
The rainfall information used for hydrologically-triggered landslide hazard assessment is extracted from the same dataset as applied in the ICG model. This map displays 100-year extreme monthly precipitation. The continuous rainfall depths were first classified in six categories (Table 9) and then multiplied with the classified landslide susceptibility map. The resulting hazard map contained 10 × 6 = 60 different hazard classes, which were reclassified in seven hazard classes showing increasing landslide hazard from 1 to 7 (Table 10). In this final rainfall-induced landslide hazard maps class 0 represents lakes.
The seismic information was first classified in nine categories (Table 11). These class boundaries are corresponding with those used by UN/IDNDR personnel who produced the map. Then, the classified GSHAP map was multiplied with the classified landslide susceptibility map. The resulting hazard map contained 9 × 10 = 90 different hazard classes that were reclassified in seven hazard classes showing increasing landslide hazard from 1 to 7. In this final earthquake-induced landslide hazard map, class 0 represents lakes.
Results
The analysis covers 44 countries and the extent of the study is roughly defined according to the physical boundaries of Europe. This area encompasses 9.7 million km2 of land area and 729 million inhabitants. Figures 5 and 6 compare the results from the ICG and JRC models for precipitation-induced and earthquake-induced landslides, respectively. A distinct difference can be observed between the two models, where JRC in general defines larger areas being exposed to landslides than the ICG model. This already shows that classification of landslide zonation maps is subjective and depends on the choice of the experts. The classified hazard map of JRC is definitely more conservative although it does incorporate hotspots of known hazard such as north-west Scotland, which the ICG model does not. One can also see that the parts of Europe exposed to landslide hazard due to seismic activity are much smaller than hazardous areas due to precipitation that triggers slides particularly for the ICG model.

Landslide hazard caused by precipitation (results from the ICG model left, from the JRC model right). Red circles show possible hotspots

Landslide hazard caused by seismicity (results from the ICG model left, from the JRC model right). Red circles show possible hotspots
Precipitation-induced landslides cover to some degree all mountainous areas in Europe, while the earthquake-induced landslides are much more concentrated in the south-eastern part of Europe and Iceland, where the seismic hazard is known to be high. The main mountain ranges are well reproduced and the results look reasonable at a European scale.
The resulting hazard maps were then used to validate the model. National authorities and experts in Romania, Italy, France and Scotland were asked a set of questions if the performance of the model results represent the landslide situation in their countries. The results show that the models work well on a national to regional scale. However, they fail to recognise local scale patterns in individual basins or areas. Agreement was found to be good for fast moving landslides of flow type and debris flows. Nevertheless, the models fail to identify areas where slow moving landslides are the biggest concern. Figure 7 shows an example from the Campania region in Italy. Here the northern part with relatively steep terrain fits well, while more gentle terrain in the central part of the basin are not well represented by the model.

Good fit (in green) and bad fit (in red) between the susceptibility map of the Arno river basin and the ICG precipitation hazard map
For precipitation-induced landslides, the results from the hazard model were used to estimate the exposure of population and infrastructure to the hazard. For this purpose the affected land areas, number of people and kilometres of roads and railways were counted for each of the 44 countries in this study.
In the following paragraphs the results from the two models will be mentioned side by side for the ICG/JRC model respectively. Looking at all 44 countries, a total number of 167,000/255,000 km2 are exposed to medium or high landslide hazard. This is 1.7/2.6 % of the land area of Europe. In these areas live 8.2/15.4 million people, which represents 1.1/2.1 % of the total population of Europe. Focusing on the areas with high hazard, one finds 17,000/84,000 km2 and 1.3/3.7 million people exposed (0.2/0.5 %).
The hazard maps in Fig. 5 show the areas of highest hazard represented by the mountain regions of the Pyrenees, northern and south eastern Alps, Italy, the Balkan, western Norway and Iceland. On the other hand, the European exposure maps in Fig. 8 show the highest exposure in the densely populated areas around cities that are surrounded by mountains, such as Barcelona, Lisbon and Rome. The exposure map clearly shows that the highest level of risk is not necessary correlated to the hazard but much more dependent on the distribution of population in Europe. This is in agreement with statement of Alexander (2004) that in many cases the consequences determine the losses to a greater degree than does the hazard.

Exposure map for Europe (results from the ICG model left, from the JRC model right). Possible hotspots marked in green

Total and relative exposed area (km2) in the countries within the study area. Top red, ICG bottom blue JRC. Only the top 15 countries (of 44) are shown in each case
Ranking countries by exposed land area (i.e., relative exposure), one finds that Lichtenstein is the country with the highest percentage of exposed land area (40 %), while Italy features the most terrain exposed to landslide hazard in total numbers (20,000 km2, Fig. 9).

Total and relative exposed people (millions) in the countries within the study area Top ICG orange, bottom JRC purple. Only the top 15 countries (of 44) are shown in each case
The countries with the highest level of exposed people can be found in the mountainous areas (Fig. 10). Small countries like Montenegro and Liechtenstein score high on risk as a large portion of their population actually live in the mountains. Italy has the highest total number of exposed people, but due to large areas of low or negligible landslide risk in the country, Italy moves down to ninth place on the list of countries ranked by relative exposure (exposed divided by total population). In total numbers Italy has more than 2.3/3.5 million (ICG/JRC) people living in landslide terrain (Fig. 10). That is nearly 20 % of the total amount of people exposed in Europe.
The ten countries with the highest number of exposed people represent 77/78 % of the total number of people exposed to landslides in Europe. On the other end of the scale are the countries with little topography (e.g., the Netherlands, Latvia) or countries where the mountainous areas are not inhabited (e.g., Finland).
Looking at the ICG results in terms of exposed infrastructure, Italy tops the list of countries both for roads (6,597 km) and railways (2,274 km). Second is France while Germany is in fourth place (Fig. 11). Relative to the total length of roads and railways, the smaller countries again score highest with Montenegro and Liechtenstein on top of the list. In Greece 10 % of the roads are exposed and in Switzerland around 9 % are exposed. In Montenegro almost 40 % of the 187 km of railways are exposed while in Switzerland 9 % of its total 4,600 km is exposed. The JRC data shows a slightly different ranking of the countries, but the general impression is the same. Looking at Europe as a whole, 31,000/42,000 km (2.6 % ICG/3.3 % JRC) of the road network and 13,000/18,500 km (1.8/2.5 %) of the railways are exposed to landslide hazard. A summary and comparison of the results are given in Table 12.

Total and relative exposed infrastructure in the countries within the study area. Top ICG dark blue , bottom JRC light blue. Only the top 15 countries (of 44) are shown in each case
Discussion
The results from the two models represent the landslide situation in Europe reasonably well. They identify the main hotspots both for hazard and risk. Recalling that the study takes a rather coarse approach, the results could be compared to much more detailed studies at national and regional scales. In absolute numbers, the JRC model identifies twice the exposed area, people or infrastructure kilometres compared to the ICG results. This is most likely caused by the two different approaches of a purely heuristic and a statistical regression approach on the other hand. Compared to national totals of area, population or infrastructure kilometres, differences between the models are within a few percent. This is promising and shows that the two different approaches give similar answers to the task of identifying European hotspots.
The main challenge for a uniform landslide hazard and risk analysis for Europe is the selection of the most appropriate input data. The applied datasets could be improved in many respects. For example, resolution could be improved and data holes could be filled; in addition many of the datasets are overdue for updating. The models depend mainly on terrain steepness, focusing the hotspots to the mountainous areas in Europe. New precipitation datasets with higher resolution in space and time are under development (Haylock et al. 2008) and will improve the hazard models significantly by including a quantification of the likelihood of extreme precipitation events. Also, data on the thickness of soils and geological deposits would improve the estimation of landslide susceptibility especially in less steep terrain, where the models’ terrain factor does not indicate a hazard to exist. For the validation of the model results, a European landslide inventory is essential but not existing.
Landslide hazard can be mitigated by both physical countermeasures (such as slope stabilisation, reforestation and water management) and non-physical countermeasures (such as evacuations and road closures). Many known landslide areas in Europe already have such warning and other mitigation systems in place. As the collection of physical data at a European scale is close to impossible, this is not considered for the model used in this analysis resulting in overestimation of the risk for areas with mitigation measures in place. As an alternative to mapping the areas with mitigation in Europe, the human development index could be used for Europe as a measure for the ability to manage the landslide hazard in a given area and situation.
The results from the models were tested and validated in Italy, Norway, Romania, and UK. Both areas, where the models perform well and areas where the agreement is poor, were identified quantitatively using landslide location data for Italy, Norway, and the UK (local analysis) and qualitatively using expert knowledge for Romania and UK (national analysis). For precipitation-induced slides, the four countries reported good agreement between the model results and observed landslide events at a national scale. However, more detailed studies at regional and local scales show discrepancies. In both Norway and Romania this is found in areas with less steep terrain and geological settings that are not represented by the available geological map (marine and fluvial settings). Torrents and shallow landslides seem to be well represented in all areas. Also rockfalls are reproduced reasonably well by the models, even though the JRC model was not specifically designed for these types of landslide.
The areas exposed to hazard from earthquake-induced landslides are generally well represented by the ICG and JRC models. However, probably the JRC model overestimates the hazard in Northern Europe (e.g., UK). Romania reports a decreasing fit in less steep areas with complex geology. In steep mountain areas the results fit well. In Italy, the seismic-induced landslide maps give good results at a national scale and the results are adequate for a European study. Problems arise at a local scale, where complex geological sedimentary settings cause landslide hazards in more gently-sloping terrain.
To achieve a picture of the risk hotspots in Europe, the exposure of both population and infrastructure to landslides was calculated. Although absolute numbers have to be analysed with care, the results clearly point to Italy and Spain being the countries with the largest number of people exposed. However, relative to the total population, small alpine countries such as Lichtenstein show the highest exposure. It is suggested from experience that areas with a higher risk also have a higher resilience and have well established risk mitigation strategies in place. However, areas in the middle of the risk scale are often the areas that are less frequently affected by landslides and where the consequences, often due to a lack of planned management and mitigation measures, are most severe.
The comparison of the ICG and JRC models shows that the differences between the models are not too large. They range mostly within 5–10 % of the total area or population in a country. Considering the relatively coarse nature of the analysis, and taking into account that each analysis was undertaken at a different resolution, this is a promising trend. Nevertheless, it should be mentioned that the differences are largest in the mountainous countries such as Norway, Switzerland and Slovenia. Here, the different weighting of terrain may play a role. This difference also shows that countries with a generally high exposure need to assess the hazard and risk in more detail at a national level.
The ranking of the most exposed countries both in total and relative numbers is similar from the two models. The first five countries agree well between the models, such that the selection of hotspots is possible (Figs. 6, 7). Italy is the country with the highest exposure according to both models. Here, the combination of high population density and large areas with moderate to high landslide hazard yields large numbers of exposed people and infrastructure.
Conclusion
Landslide hazard and risk in Europe were estimated using a method based on homogenous European or global data for Europe. The method proved to be successful in producing a dataset that allows a comparison of the European countries and the definition of hazard and risk hotspots. The results show that hazard and exposure related to landslides is widely distributed. Some European countries are mostly unaffected by this natural phenomena, while landslides seriously affect daily life in many other countries. Italy has the highest number of people exposed to landslide hazard. On the other hand, Italy is a country well experienced in mitigating landslide risk. In other countries such as Romania, where the majority of the exposed people live in low or medium hazard areas, landslides events are less common and, therefore, catch local people and authorities unprepared, thereby causing greater damage.
It is estimated that in the range of 1.3–3.6 million Europeans live in areas with high landslide hazard. In addition to the people directly threatened in their homes, 8,000–20,000 km of roads and railways are exposed to high hazards causing additional direct threats to life and economic assets as well as problems for emergency response and recovery operations.
The applied methods yield only rough estimates and can easily be improved by acquiring new and better datasets. Especially for the precipitation trigger, lithology and soil cover, new datasets with a higher resolution would improve the models significantly. Also the inclusion of additional landslide locations and of information on their history would allow better calibration of landslide susceptibility and hazard models. Although currently available in many national landslide databases, this information is unfortunately difficult to access. The establishment of a European landslide database should a major goal for future European projects. On the other hand, the validation in four countries with various topographical, lithological and climatological conditions shows good results at a national scale. Therefore, it can be concluded that in total, the results represent the landslide hazard and risk in Europe reasonably well. On a local scale, the models fail to reproduce the landslide pattern. The results should be used at a maximum regional scale.
References
Alexander D (2004) Natural hazards on an unquiet earth. In: Matthews J, Herbert D (eds) Unifying geography, shared future. Common Heritage, Routledge, pp 266–282
Allison PD (2001) Logistic regression using the SAS system: theory and application. Wiley Interscience, New York, p 288
Asch K (2003) The 1:5 million international geological map of Europe and adjacent areas: development and implementation of a GIS-enabled concept. In: Geologisches Jahrbuch III SA, Hannover BGR (eds) Schweitzerbart. Stuttgart, p 190
Beguería S (2006) Validation and evaluation of predictive models in hazard assessment and risk management. Nat Hazards 37(3):315–329
Castellanos Abella EA, Van Westen CJ (2007) Generation of a landslide risk index map for Cuba using spatial multi-criteria evaluation. Landslides 4:311–325
Catani F, Casagli N, Ermini L, Righini G, Menduni G (2005) Landslide hazard and risk mapping at catchment scale 2005 Arno River basin. Landslides 2(4):329–342
Cepeda J, Hoeg K, Nadim F (2010) Landslide-triggering rainfall thresholds: a conceptual framework. Q J Eng Geol Hydrogeol 43:69–84
Dilley M, Chen RS, Deichmann U, Lerner-Lam AL, Arnold M (2005) Natural disaster hotspots—a global risk analysis. Report International Bank for Reconstruction and Development/The World Bank and Columbia University, p 132
EEA (2010) Mapping the impacts of natural hazards and technological accidents in Europe: an overview of the last decade. European Environmental Agency Technical report 13. Office for Official Publications of the European Union, Luxembourg
EM-DAT (2003) The OFDA/CRED international disaster database. Université Catholique de Louvain, Brussels. www.em-dat.net
Flageollet JC, Maquaire O, Martin B, Weber D (1999) Landslides and climatic conditions in the Bracelonnette and Vars basins (Southern French Alps, France). Geomorphology 30(1–2):65–78
Foster C, Pennington CVL, Culshaw MG, Lawrie K (2012) The national landslide database of Great Britain: development, evolution and applications. Environ Earth Sci 66(3):941–953
Giardini D, Grünthal G, Shedlock K, Zhang P (2003) The GSHAP global seismic hazard map. In: Lee W, Kanamori H, Jennings P (eds) International handbook of earthquake and engineering seismology. IASPEI, Academic press, London
Glade T, Anderson M, Crozier M (2005) Landslide hazard and risk. Wiley, London, p 802
Global Land Cover 2000 database (2003) European Commission, Joint Research Centre. http://gem.jrc.ec.europa.eu/products/glc2000/glc2000.php
GRUMP (2011) Global rural–urban mapping project, version 1 (GRUMPv1): population density grid. NASA Socioeconomic Data and Applications Center (SEDAC), Palisades. Center for International Earth Science Information Network (CIESIN)/Columbia University, International Food Policy Research Institute (IFPRI), The World Bank, and Centro Internacional de Agricultura Tropical (CIAT). http://sedac.ciesin.columbia.edu/data/set/grump-v1-population-density
GTopo (1996) Topography data in 30 arcsec resolution. http://eros.usgs.gov/#/Find_Data/Products_and_Data_Available/gtopo30_info
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 31:181–216
Hansen A (1984) Landslide hazard analysis. In: Brunsden D, Prior DB (eds) Slope instability. Wiley, New York, pp 523–602
Haylock MR, Hofstra N, Klein Tank AMG, Klok EJ, Jones PD, New M (2008) A European daily high-resolution gridded dataset of surface temperature and precipitation. J Geophys Res (Atmos) 113:D20119
Hervás J, Bobrowsky P (2009) Mapping: inventories, susceptibility, hazard and risk. In: Sassa K, Canuti P (eds) Landslides—disaster risk reduction. Springer, Berlin, pp 321–349
Hong Y, Adler R, Huffman G (2007) Use of satellite remote sensing data in the mapping of global landslide susceptibility. Nat Hazards 43:245–256
Hosmer and Lemeshow (2000) Applied logistic regression. Wiley, New York
IGME 5000 (2009) Geological map of Europe. http://www.bgr.bund.de/
Jaedicke C, Lied K, Kronholm K (2009) Integrated database for rapid mass movements in Norway. Nat Hazards Earth Syst Sci 9:469–479
Kappes MS, Malet J-P, Remaître A, Horton P, Jaboyedoff M, Bell R (2011) Assessment of debris-flow susceptibility at medium-scale in the Barcelonnette Basin, France. Nat Hazards Earth Syst Sci 11:627–641
Kirschbaum DB, Adler R, Hong Y, Lerner-Lam A (2009) Evaluation of a preliminary satellite-based landslide hazard algorithm using global landslide inventories. Nat Hazards Earth Syst Sci 9:673–686
Marjanovic M, Kovacevic M, Bajat B, Vozenilek V (2011) Landslide susceptibility assessment using SVM machine learning algorithm. Eng Geol 123:225–234
Nadim F, Kjekstad O, Peduzzi P, Herold C, Jaedicke C (2006) Global landslide and avalanche hotspots. Landslides 3(2):159–174
Nefeslioglu HA, Gokceoglu C, Sonmez H, Gorum T (2011) Medium-scale hazard mapping for shallow landslide initiation: the Buyukkoy catchment area (Cayeli, Rize, Turkey). Landslides 8:459–483
OpenStreetMap (2009). http://www.openstreetmap.org
Peduzzi P (2010) Landslides and vegetation cover in the 2005 North Pakistan earthquake: a GIS and statistical quantitative approach. Nat Hazards Earth Syst Sci 10:623–640
Remaître A (2006) Morphologie et dynamique des laves torrentielles: applications aux torrents des Terres Noires du bassin de Barcelonnette (Alpes du Sud). University of Caen-Basse-Normandie, Caen, France
Rudolf, B, Schneider U (2005) Calculation of gridded precipitation for the global land-surface using in-situ gauge observations. In: Proceedings of the 2nd workshop of the international precipitation working group
SRTM (2009) Topography data in 3 arcsec resolution. http://srtm.csi.cgiar.org/
UNDRO (United Nations Disaster Relief Coordinator) (1979) Natural disasters and vulnerability analysis. Report of expert group meeting (9–12 July 1979). UNDRO, Geneva, p 49
Van Den Eeckhaut M, Hervas J (2012) State of the art of national landslide databases in Europe and their potential for hazard and risk assessment. Geomorphology 139–140:545–558
Van Den Eeckhaut M, Vanwalleghem T, Poesen J, Govers G, Verstraeten G, Vandekerckhove L (2006) Prediction of landslide susceptibility using rare events logistic regression: a case-study in the Flemish Ardennes, Belgium. Geomorphology 76:392–410
Van Den Eeckhaut M, Jaedicke C, Hervás J, Malet JP, Nadim F (2012) Statistical modelling of Europe-wide landslide susceptibility using limited landslide inventory data. Landslides 9:357–369
Varnes DJ, The International Association of Engineering Geology Commission on Landslides and Other Mass Movements (1984) Landslide hazard zonation: a review of principles and practice. Natural Hazards, vol 3. United nations educational scientific and cultural organization [60 pages]
Winter MG, Macgregor F, Shackman L (eds) (2009) Scottish road network landslides study: implementation. Transport Scotland, Edinburgh
Acknowledgments
The study was financed by the Safeland project within the 7th Framework Program Cooperation Theme 6 Environment (including climate change) Sub-Activity 6.1.3 Natural Hazards. Additional funding was given by the NGI publication fund. The team is grateful for the data access that was provided by several agencies and organizations. Special thanks go to Kari Sletten (Norwegian Geological Survey), and Prof. Luciano Picarelli and Tonino Santo (AMRA S.c.a.r.l., Naples, Italy) for providing landslide inventory data for Norway and the Campania region, respectively.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Jaedicke, C., Van Den Eeckhaut, M., Nadim, F. et al. Identification of landslide hazard and risk ‘hotspots’ in Europe. Bull Eng Geol Environ 73, 325–339 (2014). https://doi.org/10.1007/s10064-013-0541-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10064-013-0541-0