
Abstract
We propose techniques for processing SPARQL queries over a large RDF graph in a distributed environment. We adopt a “partial evaluation and assembly” framework. Answering a SPARQL query Q is equivalent to finding subgraph matches of the query graph Q over RDF graph G. Based on properties of subgraph matching over a distributed graph, we introduce local partial match as partial answers in each fragment of RDF graph G. For assembly, we propose two methods: centralized and distributed assembly. We analyze our algorithms from both theoretically and experimentally. Extensive experiments over both real and benchmark RDF repositories of billions of triples confirm that our method is superior to the state-of-the-art methods in both the system’s performance and scalability.
















Similar content being viewed by others

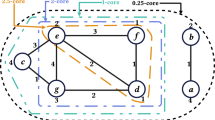

Notes
The statistic is reported in http://stats.lod2.eu/.
\(f_j(v)=NULL\) means that vertex v in query Q is not matched in local partial match \(PM_j\). It is formally defined in Definition 6 condition (2)
In this paper, we use “\(\leftarrow \)” to denote the assignment operator.
An algorithm is called fixed-parameter tractable for a problem of size l, with respect to a parameter n, if it can be solved in time O(f(n)g(l)), where f(n) can be any function but g(l) must be polynomial [10].
When we find local partial matches in fragment \(F_i\) and send them to join, we tag which vertices in local partial matches are internal vertices of \(F_i\).
We underline all extended vertices in serialization vectors.
A problem is said to have optimal substructure if an optimal solution can be constructed efficiently from optimal solutions of its subproblems [9]. This property is often used in dynamic programming formulations.
Note that, in this example, their cost values are the same, but they are possible to be different.
We use ANTRL v3’s grammar which is an implementation of the SPARQL grammar’s specifications. It is available at http://www.antlr3.org/grammar/1200929755392/.
A triple pattern t is a “selective triple pattern” if it has no more than 100 matches in RDF graph G
References
Abadi, D.J., Marcus, A., Madden, S., Hollenbach, K.: SW-store: a vertically partitioned DBMS for semantic web data management. VLDB J. 18(2), 385–406 (2009)
Aluç, G., Hartig, O., Özsu, M.T., Daudjee, K.: Diversified stress testing of RDF data management systems. In: Proceedings of 13th International Semantic Web Conference, pp 197–212 (2014)
Astrahan, M.M., Blasgen, H.W., Chamberlin, D.D., Eswaran, K.P., Gray, J.N., Griffiths, P.P., King, W.F., Lorie, R.A., Mehl, J.W., Putzolu, G.R., Traiger, I.L., Wade, B.W., Watson, V.: System R: relational approach to database management. ACM Trans. Database Syst. 1, 97–137 (1976)
Atre, M.: Left Bit Right: for SPARQL join queries with OPTIONAL patterns (left-outer-joins). In: Proceedings of ACM SIGMOD International Conference on Management of Data, pp 1793–1808 (2015)
Atre, M., Chaoji, V., Zaki, M.J., Hendler, J.A.: Matrix “bit” loaded: a scalable lightweight join query processor for RDF data. In: Proceedings of 19th International World Wide Web Conference, pp 41–50 (2010)
Buneman, P., Cong, G., Fan, W., Kementsietsidis, A.: Using partial evaluation in distributed query evaluation. In: Proceedings of 32nd International Conference on Very Large Data Bases, pp 211–222 (2006)
Cong, G., Fan, W., Kementsietsidis, A.: Distributed query evaluation with performance guarantees. In: Proceedings of ACM SIGMOD International Conference on Management of Data, pp 509–520 (2007)
Cong, G., Fan, W., Kementsietsidis, A., Li, J., Liu, X.: Partial evaluation for distributed XPath query processing and beyond. ACM Trans. Database Syst. 37(4), 32 (2012)
Cormen, T.H., Leiserson, C.E., Rivest, R.L., Stein, C.: Introduction to Algorithms, 3rd edn. MIT Press, Cambridge (2009)
Downey, R.G., Fellows, M.R., Vardy, A., Whittle, G.: The parametrized complexity of some fundamental problems in coding theory. SIAM J. Comput. 29(2), 545–570 (1999)
Dyer, M.E., Greenhill, C.S.: The complexity of counting graph homomorphisms. Random Struct. Algorithms 17(3–4), 260–289 (2000)
Fan, W., Li, J., Ma, S., Tang, N., Wu, Y., Wu, Y.: Graph pattern matching: from intractable to polynomial time. Proc. VLDB Endow. 3(1), 264–275 (2010)
Fan, W., Wang, X., Wu, Y.: Performance guarantees for distributed reachability queries. Proc. VLDB Endow. 5(11), 1304–1315 (2012)
Fan, W., Wang, X., Wu, Y., Deng, D.: Distributed graph simulation: impossibility and possibility. Proc. VLDB Endow. 7(12), 1083–1094 (2014)
Galarraga, L., Hose, K., Schenkel, R.: Partout: a distributed engine for efficient RDF processing. In: Proceedings of 23rd International World Wide Web Conference (Companion Volume), pp 267–268 (2014)
Görlitz, O., Staab, S.: SPLENDID: SPARQL endpoint federation exploiting VOID descriptions. In: Proceedings of ISWC 2011 Workshop on Consuming Linked Data (2011)
Guo, Y., Pan, Z., Heflin, J.: LUBM: a benchmark for OWL knowledge base systems. J. Web Semant. 3(2–3), 158–182 (2005)
Gurajada, S., Seufert, S., Miliaraki, I., Theobald, M.: TriAD: a distributed shared-nothing RDF engine based on asynchronous message passing. In: Proceedings of ACM SIGMOD International Conference on Management of Data, pp 289–300 (2014)
Harth, A., Hose, K., Karnstedt, M., Polleres, A., Sattler, K., Umbrich, J.: Data summaries for on-demand queries over linked data. In: Proceedings of 19th International World Wide Web Conference, pp 411–420 (2010)
Hartig, O., Özsu, M.T.: Linked data query processing (Tutorial). In: Proceedings of 30th International Conference on Data Engineering, pp 1286–1289 (2014)
Hose, K., Schenkel, R.: WARP: Workload-aware replication and partitioning for RDF. In: Proceedings of Workshops of 29th International Conference on Data Engineering, pp 1–6 (2013)
Huang, J., Abadi, D.J., Ren, K.: Scalable SPARQL querying of large RDF graphs. Proc. VLDB Endow. 4(11), 1123–1134 (2011)
Husain, M.F., McGlothlin, J.P., Masud, M.M., Khan, L.R., Thuraisingham, B.M.: Heuristics-based query processing for large RDF graphs using cloud computing. IEEE Trans. Knowl. Data Eng. 23(9), 1312–1327 (2011)
Jones, N.D.: An introduction to partial evaluation. ACM Comput. Surv. 28(3), 480–503 (1996)
Kaoudi, Z., Manolescu, I.: RDF in the clouds: a survey. VLDB J. 24(1), 67–91 (2015)
Karypis, G., Kumar, V.: Analysis of multilevel graph partitioning. In: Proceedings of ACM/IEEE Conference on Supercomputing. Article No. 29 (1995)
Khadilkar, V., Kantarcioglu, M., Thuraisingham, B. M., Castagna, P.: Jena-HBase: A distributed, scalable and efficient RDF triple store. In: Proceedings of International Semantic Web Conference Posters & Demos Track (2012)
Lee, K., Liu, L.: Scaling queries over big RDF graphs with semantic hash partitioning. Proc. VLDB Endow. 6(14), 1894–1905 (2013)
Lee, K., Liu, L., Tang, Y., Zhang, Q., Zhou, Y.: Efficient and customizable data partitioning framework for distributed big RDF data processing in the cloud. In: Proceedings of IEEE 6th International Conference on Cloud Computing, pp 327–334 (2013)
Li, F., Ooi, B.C., Özsu, M.T., Wu, S.: Distributed data management using MapReduce. ACM Comput. Surv. 46(3), 31 (2014)
Ma, S., Cao, Y., Huai, J., Wo, T.: Distributed graph pattern matching. In: Proceeding of 21st International World Wide Web Conference, pp 949–958 (2012)
Neumann, T., Weikum, G.: RDF-3X: a RISC-style engine for RDF. Proc. VLDB Endow. 1(1), 647–659 (2008)
Papailiou, N., Konstantinou, I., Tsoumakos, D., Koziris, N.: \(\text{ H }_{{\rm 2}}\)RDF: adaptive query processing on RDF data in the cloud. In: Proceedings of 21st International World Wide Web Conference (Companion Volume), pp 397–400 (2012)
Papailiou, N., Tsoumakos, D., Konstantinou, I., Karras, P., Koziris, N.: \(\text{ H }_{{\rm 2}}\)RDF+: an efficient data management system for big RDF graphs. In: Proceeding of ACM SIGMOD International Conference on Management of Data, pp 909–912 (2014)
Pérez, J., Arenas, M., Gutierrez, C.: Semantics and complexity of SPARQL. ACM Trans. Database Syst. 34(3), 2009
Quilitz, B., Leser, U.: Querying Distributed RDF Data Sources with SPARQL. In: Proceeding of 5th European Semantic Web Conference, pp 524–538 (2008)
Rohloff, K., Schantz, R. E.: High-performance, massively scalable distributed systems using the MapReduce software framework: the shard triple-store. In: Proceeding of International Workshop on Programming Support Innovations for Emerging Distributed Applications, Article No. 4 (2010)
Saleem, M., Ngomo, A. N.: HiBISCuS: Hypergraph-based source selection for sparql endpoint federation. In: Proceeding of 11th Extended Semantic Web Conference, pp 176–191 (2014)
Saleem, M., Padmanabhuni, S.S., Ngomo, A.N., Iqbal, A., Almeida, J.S., Decker, S., Deus, H.F.: TopFed: TCGA tailored federated query processing and linking to LOD. J. Biomed. Semant. 5, 47 (2014)
Schmachtenberg, M., Bizer, C., Paulheim, H.: Adoption of best data practices in different topical domains. In: Proceeding of 13th International Semantic Web Conference, pp 245–260 (2014)
Schmidt, M., Görlitz, O., Haase, P., Ladwig, G., Schwarte, A., Tran, T.: FedBench: A benchmark suite for federated semantic data query processing. In: Proceeding of 10th International Semantic Web Conference, pp 585–600 (2011)
Schwarte, A., Haase, P., Hose, K., Schenkel, R., Schmidt, M.: FedX: Optimization techniques for federated query processing on linked data. In: Proceeding of 10th International Semantic Web Conference, pp 601–616 (2011)
Shang, H., Zhang, Y., Lin, X., Yu, J.X.: Taming verification hardness: an efficient algorithm for testing subgraph isomorphism. Proc. VLDB Endow. 1(1), 364–375 (2008)
Shao, B., Wang, H., Li, Y.: Trinity: a distributed graph engine on a memory cloud. In: Proceeding of ACM SIGMOD International Conference on Management of Data, pp 505–516 (2013)
Valiant, L.G.: A bridging model for parallel computation. Commun. ACM 33(8), 103–111 (1990)
Wang, L., Xiao, Y., Shao, B., Wang, H.: How to partition a billion-node graph. In: Proceeding of 30th International Conference on Data Engineering, pp 568–579 (2014)
Zeng, K., Yang, J., Wang, H., Shao, B., Wang, Z.: A distributed graph engine for web scale RDF data. Proc. VLDB Endow. 6(4), 265–276 (2013)
Zhang, X., Chen, L., Tong, Y., Wang, M.: EAGRE: towards scalable I/O efficient SPARQL query evaluation on the cloud. In: Proceeding of 29th International Conference on Data Engineering, pp 565–576 (2013)
Zhang, X., Chen, L., Wang, M.: Towards efficient join processing over large RDF graph using mapreduce. In: Proceeding of 24th International Conference on Scientific and Statistical Database Management, pp 250–259 (2012)
Zou, L., Özsu, M.T., Chen, L., Shen, X., Huang, R., Zhao, D.: gStore: a graph-based SPARQL query engine. VLDB J. 23(4), 565–590 (2014)
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Peng, P., Zou, L., Özsu, M.T. et al. Processing SPARQL queries over distributed RDF graphs. The VLDB Journal 25, 243–268 (2016). https://doi.org/10.1007/s00778-015-0415-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-015-0415-0