
Abstract
Point-level temporal action localization (PTAL) aims to locate action instances in untrimmed videos with only one timestamp annotation for each action instance. Existing methods adopt the localization-by-classification paradigm to locate action boundaries in the temporal class activation map (TCAM) by thresholding, also known as TCAM-based method. However, TCAM-based methods are limited by the gap between classification and localization tasks, since TCAM is generated by a classification network. To address this issue, we propose a re-training framework for the PTAL task, also known as LPR. This framework consists of two stages: pseudo-label generation and re-training. In the pseudo-label generation stage, we propose a feature embedding module based on a transformer encoder to capture global context features and optimize pseudo-labels’ quality by leveraging point-level annotations. In the re-training stage, LPR uses the above pseudo-labels as supervision to locate action instances with a temporal action localization network rather than generating TCAMs. Furthermore, to alleviate the effects of label noise in the pseudo-labels, we propose a joint learning classification module (JLCM) in the re-training stage. This module contains two classification sub-modules that simultaneously predict action categories and are guided by a jointly determined clean set for network training. The proposed framework achieves state-of-the-art localization performance on both the THUMOS’14 and BEOID datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Temporal action localization (TAL) is a fundamental yet challenging task in video understanding, which has significant applications in many areas of daily life, such as video summarization [1, 2], video highlight [3,4,5], anomaly detection [6]. In contrast to video moment localization [7, 8], TAL focuses on detecting action boundaries in videos and identifying the corresponding action categories. Recently, frame-level temporal action localization (FTAL) has achieved remarkable results [9,10,11,12], but the precise frame-level annotations are time-consuming. The video-level temporal action localization (VTAL) requires only lower-cost video category labels for temporal action localization, but its performance is significantly lower than FTAL due to the lack of complete action boundary guidance. To bridge the performance gap between VTAL and FTAL, a point-level temporal action localization (PTAL) setting is introduced [13], in which each action instance is annotated with a single point during training. Figure 1 shows different annotation methods under three different settings.

Comparison among three annotation methods: frame-level, video-level, and point-level. Frame-level needs to precisely annotate each action instance’s action category and boundary position. In contrast, the video-level only needs to give the category of actions that occur in the video. Point-level is the balance between the two; only one point annotation information is needed for each action instance
Existing PTAL methods are based on mining pseudo-labels using point-level annotations and providing extra supervision during training. For example, SF-Net [13] mines the points with high activation values near the point-level annotations as pseudo action labels through a pre-trained network for a few epochs and, at the same time, globally mines background points. Introducing more location information significantly improves the performance of PTAL over VTAL. However, most PTAL methods [13,14,15] still follow the localization-by-classification paradigm similar to VTAL methods, where a video classification network is trained to obtain TCAM and localize action boundaries based on TCAM. Point-level annotations are used as additional supervision to optimize the quality of TCAM. Due to the gap between the classification and localization tasks, TCAM-based methods still have significant room for improvement. Furthermore, in Fig. 2, we provide a detailed account of the gap between the two tasks and explain how this gap leads to performance degradation. As illustrated in Fig. 2, the gap between the two tasks arises from the fact that the classification task requires additional steps such as TCAM generation and post-processing. However, TCAM only focuses on some areas of the action instances and cannot fully identify them, thus leading to decreased performance. On the other hand, existing methods only use point-level annotations to mine pseudo-labels [13, 14] or counting [16], and the additional information hidden in point-level annotations, such as the maximum length of an action, is not utilized. These two issues cause the performance of existing PTAL methods to be unsatisfactory.

The gap between classification and localization. The TCAM-based approach generates TCAM by training a classification model. Then it performs post-processing on TCAM to obtain boundary prediction results (The TCAM-based approach depicted in the figure). In contrast, the localization approach directly outputs boundary predictions (The Our Approach depicted in the figure). Therefore, the gap between classification and localization tasks lies in need for additional TCAM generation and post-processing in classification tasks. Since TCAM focuses more on discriminative segments within action instances, it cannot effectively predict action completeness, affecting the detection performance of the TCAM-based method
To address the abovementioned issue, we propose a novel two-stage re-training framework (LPR). In the first stage, LPR trains a classification network based on point-level annotations and introduces a feature embedding module based on a transformer encoder to capture global context information. During the first stage of training, unlike previous methods [13, 14] that simultaneously mine potential action and background points, LPR only focuses on mining the more critical background information, which has been established as a crucial component in BackTAL [17]. After the first stage of training, LPR generates frame-level pseudo-labels based on the TCAM output from the first stage and optimizes their quality by utilizing the implicit information provided by point-level annotations, such as the coarse position of action instances, counting, and maximum length. In the second stage of LPR, the aforementioned frame-level pseudo-labels are used as supervision signals to train a temporal action localization network rather than a video classification network. However, the pseudo-labels contain a large amount of label noise, and as the training progresses, the model tends to over-fitting the noise data [18]. To this end, in LPR, we propose a joint learning classification module (JLCM) to alleviate the influence of label noise. This module contains two classification sub-modules to predict action categories simultaneously, and the two sub-modules jointly mining the clean set to guide network training. Pseudo-labels outside the clean set are ignored because their inconsistent outputs in the two sub-modules are considered noise information. During inference, only the second stage of LPR is used to localize action boundaries and recognize their action categories, which avoids the complex post-processing of TCAM-based methods and mitigates the performance degradation caused by the gap between classification and localization. Our main contributions are summarized as follows:
-
We propose a novel re-training framework. This framework leverages point-level annotations to generate higher-quality pseudo-labels. Subsequently, a frame-level temporal action localization network is trained based on these pseudo-labels to mitigate the performance gap caused by the classification and localization tasks.
-
In the frame-level temporal action localization network, we design a joint learning classification module to alleviate the impact of label noise in pseudo-labels. This module is based on two classification sub-modules that predict the consistency of action categories to filter a clean set from the pseudo-labels and remove potential label noise.
-
Extensive experiments demonstrate that our method achieves state-of-the-art performance on two popular public datasets.
2 Related work
In this section, we briefly introduce related research on our studied topic, which mainly includes FTAL, VTAL, and PTAL methods.
2.1 Frame-level temporal action localization (FTAL)
FTAL, which requires precise frame-level annotations, has made significant progress [9,10,11, 19,20,21,22]. It can be classified into three types: anchor-based, anchor-free, and mixed, depending on whether anchors are introduced. Anchor-based methods [19, 23] pre-define anchors that may contain action instances, regress the boundaries of the anchors and classify their action category. R-C3D [19], which is the first end-to-end anchor-based method, predicted action instances in a two-stage manner. It first filters proposals that may contain actions among all anchors and further classifies the specific action category of the proposals. Anchor-free methods [9, 10, 20] do not pre-define anchors and directly predict corresponding action instances at each position. SSN [9] first proposed the actionness mechanism to generate proposals. Later, boundary-sensitive network (BSN) [10] decomposed action instances into three forms: starting, actionness, and ending. To pay more attention to action boundary information, AFSD [20] designed a saliency-based refinement module to learn boundary salient information.
Anchor-free methods perform better on short and large action instances due to their flexibility, while pre-defined anchors make anchor-based methods more stable and perform better on medium-length action instances. Mixed methods [21, 22] merge anchor-based and anchor-free methods to achieve higher performance on all length groups of action instances. PCAD [21] follows R-C3D’s end-to-end design and supplemented actionness proposals in the proposal generation stage to improve proposal quality. In contrast, MGG [22] refined the localization results of anchor-based methods using the probabilities of starting and ending.
2.2 Video-level temporal action localization (VTAL)
During the training phase, VTAL only requires action category labels, which reduces annotation costs. Most existing methods [24,25,26,27,28,29] treat VTAL as a multiple instance learning (MIL) problems, using the localization-by-classification paradigm to locate action instances. These methods train a video classifier to obtain TCAM, then use a thresholding method on TCAM to generate action instances. UntrimmedNet [24], the first VTAL method, located actions using a classification module and a selection module. Subsequently, STPN [25] designed an attention module to improve the quality of TCAM. CMCS [26] models action completeness through a multi-branch network. Better TCAM requires the supervision of background frames. Therefore BaS-Net [27] proposed a supplementary background class that allows the network to suppress activation values on background frames and improve performance through weight sharing between two branches. Moreover, Huifen et al. [29] utilized spatial-temporal correlation learning and action-background joint attention to identify action and background segments. However, existing TCAM-based methods ignored the temporal structure of intra- and inter-segments. ASM-Loc [28] captured temporal dependencies by focusing on intra- and inter-segment relationships to improve performance. Unfortunately, due to the lack of frame-level annotations, VTAL is all troubled by serious false positives and trivial action segments [26, 27], which cause inferior performance.
2.3 Point-level temporal action localization (PTAL)
Point-level annotations have gradually gained attention from the community to balance between frame-level and video-level annotations. Usually, point-level annotations are used from the perspective of task transfer or pseudo-label generation. For example, DC [16] decomposed PTAL into two sub-tasks of counting and localization based on point-level annotations, each of which can be considered weakly supervised. Unlike DC, SF-Net [13], LAC [14], and PCL [30] focused on pseudo-label generation. SF-Net [13] first trained a classification network with fewer epochs and then mined pseudo-labels based on the score output from that network. These pseudo-labels were then combined with point-level annotations for further training of the classification network. In contrast, LAC [14] treated pseudo-label generation as a sequence-matching problem and learned action completeness by comparing action instances and backgrounds. Unlike the static pseudo-label generation method of SF-Net, PCL [30] dynamically updated pseudo-labels by decoupling pseudo-label generation and frame label prediction. Recently, CRRC-Net [15] proposed a co-supervised feature learning module to leverage complementary information across different modalities. A probabilistic pseudo-label mining module was proposed for more reliable classification learning. Unlike annotated point on each action instance, BackTAL [17] annotated point on the background segment between two action instances, and the background point-level annotations can achieve higher performance because it can provide more precise background information to suppress the action probability of background points.
Existing PTAL methods have achieved significant performance improvements. However, the gap between classification and localization tasks has affected the performance of TCAM-based methods. The two-stage framework based on re-training has been widely used in weakly supervised semantic segmentation (WSSS) [31, 32] and proved to be superior to the one-stage method (CAM-based). It can be described as (1) training a pseudo-mask generator with image labels and (2) training a fully-supervised semantic segmentation with the generated pseudo-mask. However, the existing methods for PTAL tasks still use the TCAM-based one-stage method to locate action instances. In this paper, we propose a two-stage re-training framework for PTAL tasks for the first time, which significantly improves performance while making better use of point-level annotations.

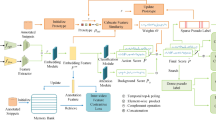
Framework of LPR. During training, LPR consists of two stages: pseudo-label generation and re-training. In the pseudo-label generation stage, a MIL-based video classification network is trained to generate TCAM. Based on TCAM and point-level annotations, high-quality frame-level pseudo-labels are generated. In the re-training stage, the temporal action localization network is trained with the generated pseudo-labels as supervision. During inference, LPR directly uses the trained model from the re-training stage to locate action instances
3 Proposed method
In this section, we provide a comprehensive overview of the problem setting, followed by a detailed explanation of our re-training framework setup. Finally, we elucidate the inference process of our model.
3.1 Problem setting
Given an input video \({\mathcal {V}}\) containing \({\hat{T}}\)-frame, it is divided into T snippets, where each snippet contains 16 consecutive frames. \({\mathcal {V}}\)’s feature is pre-extracted on each snippet and denoted as \({\mathcal {X}} \in {\mathbb {R}}^{T \times D}\), where D is the feature dimension. The frame-level annotations for each action instance are provided, i.e., \({\mathcal {Y}}=\{(y_i, s_i, e_i)\}_{i=1}^{M}\), where M is the number of action instances. Specially, \(y_i \in {\mathbb {R}}^C\) is the action category label indicating C action categories; \(s_i \in {\mathbb {R}}\) and \(e_i \in {\mathbb {R}}\) are the starting and ending positions at \({\mathcal {X}}\). The action category label \(y_i\) is a binary vector with \(y_i[c] = 1\) if i-th action instance contains c-th action category, otherwise \(y_i[c] = 0\). TAL aims to design a model that predicts \({\mathcal {Y}}\) from the input feature \({\mathcal {X}}\).
In this paper, we consider the point-level setting as proposed in [13,14,15, 30, 33]. Concretely, for ith action instance in \({\mathcal {V}}\), only single point \((y_i,t_i)\) is annotated, where \(s_i \le t_i \le e_i\). The final annotation is denoted as \({\mathcal {Y}}_\textrm{pl} = \{(y_i,t_i)\}_{i=1}^M\). For comparison, the frame-level setting provides \((y_i, s_i, e_i)\) for i-th action instance, and the video-level setting provides the category label \(y_\textrm{vid}\) for the whole video. \(y_\textrm{vid} \in {\mathbb {R}}^C\) can be easy obtained by aggregating the point-level annotations, \(y_\textrm{vid}[c] = {\mathbb {I}}[\sum _{i=1}^{M}y_i[c] > 0]\), where \({\mathbb {I}}[\cdot ]\) is the indicator function.
3.2 Re-training framework
Our re-training framework breaks away from the traditional localization-by-classification paradigm by representing PTAL through two stages: pseudo-label generation and re-training. This approach helps alleviate the inferior performance caused by the task gap between classification and localization. The diagram of our framework is shown in Fig. 3.
3.2.1 Pseudo-label generation stage
Pseudo-label generation aims to train a video classification network. This network is used to generate frame-level pseudo-labels based on point-level annotations. As shown in pseudo-label generation stage of Fig. 3, this stage mainly includes feature embedding and video classification modules.
Feature embedding module Although pre-extracted feature \({\mathcal {X}}\) captures local spatio-temporal information within 16 frames, it does not provide the necessary global context information required for PTAL. To overcome this limitation, LPR employs the self-attention mechanism [34] to learn the global context. Specifically, we set the Q/K/V of the transformer encoder as \({\mathcal {X}}/{\mathcal {X}}/{\mathcal {X}}\). The transformer encoder can be expressed mathematically as:
where \(W_Q\), \(W_K\), \(W_V\) are learnable parameters. The MLP has one fully-connected (FC) layer with residual skip connection, and layer norm (LN) [35] is used to normalize the features before the MLP output. Recent studies have found that adding a convolutional layer before the transformer block is advantageous for aggregating local contextual information and improving the stability of transformer training [36]. Thus, we adopt a Conv1D layer at the beginning of the feature embedding module to model local features.
Video classification module This module uses the structure of Conv1D-ReLU-Conv1D to predict the action category \({\mathcal {P}}_\textrm{point} \in {\mathbb {R}}^{T \times (C + 1)}\) of input \({\mathcal {X}}^\textrm{emb}\), also known as TCAM. Moreover, \(p_\textrm{point}[t,c]\) is denoted by the probability of the cth category at the tth snippet. The video category score is obtained by aggregating \({\mathcal {P}}_\textrm{point}\). For aggregation, we utilize temporal top-k pooling [14, 17]. The probability \(p_\textrm{vid}[c]\) of the occurrence of the cth action in the video can be represented mathematically as:
where \({\mathcal {S}}\) is defined as the k largest values of \({\mathcal {P}}_\textrm{point}[:,c]\) and k is the number used for aggregation.
Background mining As mentioned in BackTAL [17], the background points are crucial for the PTAL task. In our approach, we mine pseudo-background points from the predicted probability for the background category \({\mathcal {P}}_\textrm{point}[:, C+1]\). Specifically, for the segment between two adjacent annotations in \({\mathcal {Y}}_\textrm{pl}\), we select all points whose probabilities in \({\mathcal {P}}_\textrm{point}[:, C+1]\) greater than the threshold \(\lambda _\textrm{bg}\) as background points. By mining segments between all adjacent annotations in the video, we finally obtain a set of pseudo-background labels denoted as \({\mathcal {Y}}_\textrm{pl}^\textrm{bg} = \{(y_i,t_i)\}_{i=1}^{M_\textrm{bg}}\), where \(y_i[:C+1]=0\), \(y_i[C+1]=1\), and \(M_\textrm{bg}\) represents the number of identified pseudo-background points.
Loss function Our pseudo-label generation stage includes two loss functions using video-level and point-level annotations, respectively. As mentioned above, the video-level annotations \(y_\textrm{vid}[c]\) can be obtained by \({\mathcal {Y}}_\textrm{pl}\) aggregation. Video-level loss is calculated using binary cross-entropy:
Point-level loss is also calculated by binary cross-entropy. In addition, we use focal loss [37] to alleviate the sample imbalance in the model training. Mathematically, we have the loss at action points:
Similarly, for pseudo-background points, we use \({\mathcal {Y}}_\textrm{pl}^\textrm{bg}\) to supervise and calculate the pseudo-background points loss \({\mathcal {L}}_\textrm{point}^\textrm{bg}\). Our point-level loss is defined as the sum of the losses of action and pseudo-background points:
During the pseudo-label generation stage training, the video-level loss and point-level loss jointly supervise the classification model to improve the quality of the final TCAM. Mathematically, we have:
Pseudo-label generation To generate the pseudo-label for re-training, we first determine which action categories need to be located according to \(y_\textrm{vid}\). In particular, we only retain the categories in \(y_\textrm{vid}\) greater than 0. And then, only for the remaining action categories, we follow the existing methods [14] and use the threshold value \(\lambda _\textrm{pl}\) to get candidate segments on the category prediction score \({\mathcal {P}}_\textrm{point}\). For each candidate segment, the outer-inner-contrast score [14, 26] is used to calculate its corresponding confidence score. Especially in order to improve the quality of candidate segments, we set multiple values for \(\lambda _\textrm{pl}\) and use non-maximum suppression (NMS) to remove segments with high overlap.
Furthermore, we use point-level annotations to optimize the quality of candidate segments. For the input video \({\mathcal {V}}\), we first compute the maximum length \(t_{\max }\) of action instances based on its point-level annotations \({\mathcal {Y}}_\textrm{pl}\). We then exclude all the segments with a duration greater than \(t_{\max }\) or a confidence score lower than \(\lambda _\textrm{vid}\). To improve the recall of candidate segments, we add new segments to candidate segments based on point-level annotations. When a point annotation \(\{y_i, t_i\}\) does not belong to any candidate segment, we set its corresponding \(\{y_i, t_i - 0.5, t_i + 0.5\}\) as a new segment. We further denote candidate segments as pseudo frame-level annotations \(\hat{{\mathcal {Y}}} = \{({\hat{y}}_i, {\hat{s}}_i, {\hat{e}}_i)\}_{i=1}^{{\hat{M}}}\).

The framework of the re-training model. The re-training model follows the standard anchor-free framework, including the backbone, neck, and head components. We adopt the backbone and neck settings of ActionFormer [12], while designing a joint learning classification module that is robust to label noise in the head
3.2.2 Re-training stage
Re-training stage aims to train a frame-level temporal action localization model supervised by \(\hat{{\mathcal {Y}}}\), to locate the action instance directly instead of post-processing after generating TCAM. In this stage, our base model is followed by an anchor-free style, including classification and regression modules. At the same time, to solve the label noise problem in \(\hat{{\mathcal {Y}}}\), a joint learning classification module is proposed to replace the classification module in the base model. Our re-training model is shown in Fig. 4.
Base model Our base model is built upon the anchor-free approach in FTAL, which is based on the key idea of classifying each snippet as either an action or a background and further regressing the offset between the current snippet and the boundary of the action. Mathematically, we have:
where f represents our base model, and \(p_t^a \in {\mathbb {R}}^C\) represents the output of C binary classifiers on the snippet t. The offsets of the snippet t to the starting and ending of the action are represented by \(d_t^s\) and \(d_t^e\), respectively. Specifically, when t is classified as background, \(d_t^s\) and \(d_t^e\) are undefined. Formally, Eq. 7 considers each snippet t in the video feature \({\mathcal {X}}\) as a potential action, identifies its action category \(a_t\), and regresses the offsets of the action boundaries relative to t (\(d_t^s\) and \(d_t^e\)) when an action appears in snippet t. The action localization results can be easily decoded from \(\bar{{\mathcal {Y}}}\) as follows:
Our base model follows the classic anchor-free model design and mainly consists of the backbone, neck, and head components. The backbone and neck follow the standard design of ActionFormer [12], which has achieved the current state-of-the-art results. Especially the head mainly consists of two modules: the classification module and the regression module. These two modules use the same network structure of Conv1D-ReLU-Conv1D-ReLU, and finally use different Conv1D layer with dimensions of C and 2, respectively, to predict the action category and boundary offset.

Label noise in the pseudo-labels. Due to the absence of frame-level annotations, noise exists in the pseudo-labels generated based on point-level annotations. These noises can mislead the base model during re-training, affecting the localization performance
Joint learning classification module (JLCM) Due to the lack of frame-level annotations under the point-level setting, one possible approach to training the base model is to use the pseudo-labels \(\hat{{\mathcal {Y}}}\) generated in the pseudo-label generation stage as the supervisory signal. However, as shown in Fig. 5, some erroneously labeled areas exist in the pseudo-labels when compared with the ground-truth frame-level annotations. We denote these regions as label noise. During the training process, such label noise provides incorrect guidance to the model, leading to a reduction in performance. The impact of label noise on model training has been demonstrated in related work [18]. To mitigate the impact of label noise, following the methodology proposed in JoCoR [38], we designed a novel joint learning classification module (JLCM) to alleviate the interference of label noise from \(\hat{{\mathcal {Y}}}\) on our re-training base model. The JLCM comprises two classification sub-modules, namely sub-module-1 and sub-module-2. These sub-modules work together through joint learning to remove label noise from the pseudo-labels \(\hat{{\mathcal {Y}}}\), thereby obtaining a clean set for training the base model.

The generation process of the clean set. Sub-module-1 and sub-module-2 predict the class scores for each snippet individually (for clarity, at classification score, we use numbers 1–10 in the figure to represent ten snippets and omit the predicted values for other snippets). Subsequently, the prediction inconsistency scores \(p_u\) are calculated, with a higher inconsistency score indicating a greater likelihood of noise in the snippet. Finally, we select all snippets whose inconsistency score is below the threshold as the clean set
In Fig. 6, we illustrate the generation process of the clean set. Definition of \(p_{j1} \in {\mathbb {R}}^{T \times C}\) and \(p_{j2} \in {\mathbb {R}}^{T \times C}\) as the predicted outputs of two JLCM sub-modules, we leverage joint learning to identify the snippets with high confidence in pseudo-labels from all snippets, called clean set. Specifically, we first calculate the prediction inconsistency \(p_u = \textrm{abs}(p_{j1} - p_{j2})\). Here, a higher score of \(p_u[t, c]\) indicates a greater likelihood of noise in snippet t, since the two sub-modules display high inconsistency in their predictions on this snippet. During training, we exclude snippets with a high probability of noise from all snippets. The remaining snippets are considered as the clean set. More specifically, the clean set consists of the top \((\lambda _u \times 100)\%\) of snippets with the lowest inconsistency scores. \(\lambda _u\) is utilized to control the number of snippets in the clean set. After obtaining the clean set, we refrain from computing classification loss for those snippets that do not belong to the clean set to minimize the interference of label noise in action classification. Since these snippets that do not belong to the clean set are considered label noise, in Sect. 4.5.2, we visualized the results of the clean set during the training process and confirmed the ability of JLCM to identify most of the label noise.
Loss function During the re-training stage, we adopt the training approach of ActionFormer [12] and utilize the focal loss [37] to compute \({\mathcal {L}}_{c1}\) and \({\mathcal {L}}_{c2}\) for the joint learning classification module. For the regression module, we employ the DIoU Loss [39] to calculate \({\mathcal {L}}_{r}\). Notably, unlike ActionFormer, we only compute \({\mathcal {L}}_{c1}\) and \({\mathcal {L}}_{c2}\) on snippets belonging to the clean set, while we compute \({\mathcal {L}}_{r}\) on non-background snippets in the clean set. The final loss was computed using the following equation:
where \(T_{+}\) is the number of snippets in clean set.
3.3 Inference
During inference, we only use the re-training stage to locate action instances. Firstly, we aggregate the action category predictions:
And then, using Eq. 2, we calculate the video-level action prediction score \(p_\textrm{vid}\) on \(p_j\). Specifically, if \(p_\textrm{vid}[c] > \lambda _{c1}\), we locate all possible action instances \(\{(c, s_t^{'}, e_t^{'})\}_{t \subset T_p}\) on category c. Here, \(T_p\) is the set of all snippets where the probability of category c on \(p_{j}\) is greater than \(\lambda _{c2}\). We further denote \(p_{j}[t,c]\) as the confidence score of the tth snippet’s action instance \((c, s_t^{'}, e_t^{'})\). After locating all possible categories, we use non-maximum suppression (NMS) to filter out highly overlapping action instances and obtain the final localization results.
4 Experimental results
In this section, we first introduce the datasets, evaluation metrics, and implementation details used in this paper. Subsequently, extensive experiments are conducted to compare the performance of LPR with existing PTAL methods. Moreover, ablation studies are conducted to verify the effectiveness of each component in our LPR. Finally, we perform further error analysis and report qualitative results.
4.1 Datasets and evaluation metrics
To ensure the fairness of the results, we use the point-level annotations provided by SF-Net [13] during the training phase and conduct experiments on the following two datasets.
THUMOS’14 [40] contains 413 videos annotated with 20 action categories. As a convention, we train LPR on 200 videos from the validation set and evaluate its performance on 213 videos from the test set. In the point-level annotations provided by SF-Net [13], THUMOS’14 has a total of 3007 annotations during training, which means that each video, on average, contains 15 action instances. Due to the wide variation in action and video lengths, THUMOS’14 is a highly challenging dataset. BEOID [41] annotates 34 classes in 58 videos, with an average duration of 60 seconds per video, and an average of 12.5 action instances per video. Following standard settings [13, 16], we split the training and test sets in an 8:2 ratio, with 594 point-level annotations provided by SF-Net in the training set.
Evaluation metrics To evaluate the performance of our model, we adopted the standard settings [9, 10, 12,13,14] and calculated mean average precision (mAP) at different temporal intersections over union (tIoU) thresholds. The tIoU is determined by calculating the intersection over the union between two action boundaries. The mAP computes the mean of average precision scores across all action categories for a specific tIoU threshold. Smaller tIoU thresholds reflect the model’s ability to detect actions, while larger tIoU thresholds measure the completeness of action instance prediction.
4.2 Implementation details
This section provides a detailed account of the implementation process for the LPR model, covering the hyper-parameter settings and other relevant factors for training and inference.
Model details We utilize a two-stream I3D network [42] pre-trained on Kinetics-400 [42] as the snippet feature extractor in Sect. 3.1, which yields spatio-temporal features of dimension \(D=2048\). In the Conv1D layer of the feature embedding module, we set the dimension to 512 to reduce the computational cost of the transformer block while extracting local video features. For the transformer block, we use multi-head attention with the number of heads set to 4. In the video classification module of the pseudo-label generation stage, we set the kernel size, stride, padding, and dimension of the first Conv1D to 3, 1, 1, and 2048, respectively, and those of the second Conv1D to 1, 1, 0, and \(C+1\), respectively, where C is the number of categories. In the re-training stage, the kernel size, stride, and padding of all Conv1D layers in our re-training model are set to 3, 1, and 1, respectively. Except for the last prediction layer, the dimension of all Conv1D layers is set to 512. In the joint learning classification module, both sub-modules adopt an identical structure: Conv1D-ReLu-Conv1D-ReLu-Conv1D, where the kernel size, stride, and padding of each Conv1D are set to 3, 1, and 1, respectively. The dimension of sub-module-1 is set to 512, while that of sub-module-2 is set to 256. Additionally, different initialization methods are utilized for the two sub-modules to ensure they can effectively recognize noise. Specifically, the norm initialization std for sub-module-1 and sub-module-2 were set to 0.01 and 0.03, respectively.
Training details During model training, the pseudo-label generation stage is trained on the THUMOS’14/BEOID dataset for 1000/600 iterations with a learning rate of \(1e-4\), and the learning rate is reduced to \(1e-5\) at iteration 600/400. We set \(\lambda _\textrm{bg} = 0.95\) to mine the background points and set \(k = \lfloor \frac{T}{8} \rfloor\) to aggregate the video action score. When generating pseudo-labels, \(\lambda _\textrm{vid}\) is set to 0.55, and \(\lambda _\textrm{pl}\) is set to 0.025 to 0.225 with an interval of 0.025. The NMS threshold is set to 0.6 at this time. In the re-training stage, the model is trained on the THUMOS’14/BEOID dataset for 30/80 epochs with a learning rate of \(1e-5\), and a warm-up period of 10/20 epochs is used at the beginning of training. During the training of the re-training model, \(\lambda _u\) is set to \((1 - 0.1 \times \frac{\textrm{cur}\_\textrm{epoch} + 1}{\textrm{total}\_\textrm{epochs}})\) to filter out the clean set, where \(\textrm{cur}\_\textrm{epoch}\) represents the number of epochs in the current training stage, while \(total\_epoch\) refers to the total number of epochs for the training process.
Inference details During model inference on the THUMOS’14 and BEOID datasets, \(\lambda _{c1}\) is set to 0.1 and 0.03 to determine the video-level action categories. And then, \(\lambda _{c2}\) is set to 0.1 on both datasets to extract snippets containing actions. Finally, the NMS threshold is set to 0.5.
4.3 Comparison with state-of-the-art methods
Table 1 compares the performance of our LPR with the state-of-the-art methods on the THUMOS’14 dataset under different tIoU thresholds. LPR achieved the best average performance in all AVG mAP groups compared to other PTAL methods. Specifically, we observed significant improvements of \(8.9 \%\), \(6.9 \%\), and \(7.3 \%\) in AVG mAP (0.1 : 0.5), AVG mAP (0.3 : 0.7), and AVG mAP (0.1 : 0.7), respectively, compared to the state-of-the-art PTAL methods. This reveals that LPR’s two-stage re-training framework is superior to the traditional localization-by-classification paradigm. We attribute the aforementioned experimental phenomena to the following factors: LAC [14] generates dense pseudo-labels based on point-level annotations to guide the training of temporal action localization, while CRRC-Net [15] uses point-level annotations to mine pseudo-training samples for feature contrastive learning. These point-level utilization methods cannot fully explore all potential action points, leading to their limited ability to detect actions. In contrast, our LPR mining pseudo-labels by recalling more action points at multiple thresholds and subsequently re-trains a temporal action localization model with more optimal pseudo-label information, significantly improving LPR’s ability to detect actions. At low tIoU thresholds of 0.1–0.4, LPR surpasses state-of-the-art performance by approximately \(10 \%\) mAP, demonstrating LPR’s superior ability to detect actions. Moreover, LPR significantly outperformed VTAL methods in all tIoU thresholds, which demonstrates that the coarse action position information provided by point-level annotations leads to significant gains in locating action instances, even compared to video-level annotations with similar annotation time cost [13]. Furthermore, LPR greatly reduces the performance gap compared to frame-level annotations, which require precise action boundary annotations. For example, compared to E2E-TAD [43], LPR only has a \(2.2 \%\) mAP gap in AVG mAP (0.3 : 0.7), which also demonstrates the significant advantage of point-level annotations in reducing annotation time cost while minimizing performance degradation. Specifically, LPR demonstrates characteristics that have never been shown before in previous VTAL and FTAL methods. LPR’s performance exceeds that of FTAL methods at low tIoU thresholds, surpassing E2E-TAD by \(7.2 \%\) mAP at 0.3 tIoU and \(3.5 \%\) mAP at 0.4 tIoU. However, compared to frame-level annotations, point-level annotations still have a significant performance gap with the FTAL method at high tIoU thresholds due to the lack of precise action boundary annotations. For instance, performance gaps of \(7.9 \%\) and \(13.2 \%\) at tIoU thresholds of 0.6 and 0.7, respectively.
Table 2 presents the same experimental findings on the BEOID dataset. Due to its strong ability to detect actions, LPR significantly outperforms the state-of-the-art at low tIoU thresholds. Concretely, compared with state-of-the-art, LPR obtains \(10.2\%\) and \(13.9\%\) performance gains for mAP@tIoU \(= 0.3\) and mAP@tIoU \(= 0.4\). For a high tIoU threshold (tIoU \(=0.7\)), LPR achieves comparable localization performance to the state-of-the-art PCL method (\(24.1\%\) vs. \(26.9\%\)).
Based on the performance comparison of the above two benchmarks, our proposed LPR method consistently outperforms existing PTAL methods, which essentially demonstrates the effectiveness of LPR.
4.4 Ablation studies
In this section, we conducted many ablation studies to confirm the efficacy of each component in our LPR. Specifically, we performed ablation studies on components such as feature embedding module, background mining, re-training stage.
Feature embedding module Based on pre-extracted features, existing methods [13, 14] use the Conv1D layer to build a classification network that outputs TCAM for action localization. However, Conv1D cannot efficiently obtain global contextual information. To this end, we propose a feature embedding module that extracts global contextual information using a transformer encoder before the classification network. To verify the effectiveness of our feature embedding module, we conducted extensive experiments on the THUMOS’14 dataset, and the detailed results are shown in Table 3. Comparing the first and fourth columns in Table 3, when LPR only w/o the feature embedding module, the performance of LPR drops, with a decrease of \(3\%\) in AVG mAP (0.1 : 0.7). Meanwhile, as shown in columns two and three of Table 3, when LPR removes the re-training module and only measures the performance of the pseudo-label generation stage, the addition of the feature embedding module also can improve the performance by \(0.6\%\) in AVG mAP (0.1 : 0.7). The stable performance improvement brought by the feature embedding module under various LPR model settings proves its effectiveness.
Background mining Point-level annotations lack background annotation, which is crucial for localizing actions. Therefore, most methods are mining pseudo-background points through the classification network output. For example, SF-Net [13] initializes the network with a few epochs and then mines the potential background and action points based on the initial network for further training. LAC [14] predicts action and background probabilities separately, then mining pseudo-labels while measuring completeness. Our method uses a simple dynamic way to mine the background. We directly predict the probabilities of all actions and backgrounds and select the snippets with background probability values greater than the threshold between two point-level annotations as background. Meanwhile, we conducted a large number of experiments on the THUMOS’14 dataset to verify that even such a simple way of mining is still effective for the PTAL task. As shown in column 1 and 6 of Table 3, when LPR only w/o background mining, the performance drops significantly, with an \(19\%\) mAP drop in AVG mAP (0.1 : 0.7). When only measuring the performance of the pseudo-label generation stage, the same phenomenon occurs, with a \(22\%\) AVG mAP (0.1 : 0.7) drop in column 2 and 5 of Table 3. From the above experiments, we can conclude that the background region is crucial for the PTAL task. Although LPR uses simple dynamic background mining, it is still very effective.
Re-training stage In LPR, we proposed for the first time a re-training framework for PTAL tasks. Therefore, we conducted extensive experiments on the THUMOS’14 dataset to demonstrate the effectiveness of re-training. Comparing the first and second columns in Table 3, it can be observed that when re-training is removed from LPR, the performance decreases \(13.9\%\) AVG mAP (0.1 : 0.7). Moreover, as shown in the third and fourth columns, and the fifth and sixth columns in Table 3, re-training can bring significant performance improvements for LPR under different settings. The experiments above demonstrate that our proposed re-training stage can efficiently improve the performance of PTAL tasks.
Extensive experiments were also conducted on the BEOID dataset, and the results are shown in Table 4. The conclusions of the ablation experiments on the BEOID dataset are consistent with those on the THUMOS’14 dataset. The ablation experiments on both datasets verified each component’s effectiveness in LPR and demonstrated their excellent robustness.
Ablation study on \(\lambda _u\) In JLCM, we utilize the hyperparameter \(\lambda _u\) to obtain the clean set. As described in Sect. 4.2, we dynamically set \(\lambda _u\) as a function of the training epochs. In Table 5, we compare the performance of fixed and dynamic values of \(\lambda _u\) on the THUMOS’14 dataset. When \(\lambda _u = 1.0\), which means the clean set consists of all the snippets, label noise interrupts the training process and thus yields lower performance than our dynamic value. Moreover, when \(\lambda _u = 0.9\), signifying that the clean set contains \(90\%\) of all snippets, the performance deteriorates due to the loss of many snippets that are not labeled as noise. This is because, during the initial training stages, the two sub-modules of JLCM have not yet fully fit the data and thus cannot filter out noise snippets effectively. Therefore, we dynamically set \(\lambda _u\) to select more snippets for the clean set in the early stage of training, ensuring that all non-noise snippets participate in the training. As the model gradually fits the data, we reduce the size of the clean set by decreasing \(\lambda _u\) as a function of the epoch to exclude noise interference in later training stages. Although this dynamic setting method performs similarly to \(\lambda _u = 0.95\) at low tIoU thresholds, it exhibits outstanding performance at high tIoU thresholds. This raises the AVG mAP by \(0.3\%\) compared with \(\lambda _u = 0.95\).
Ablation study on \(\lambda _\textrm{bg}\) The hyperparameter \(\lambda _\textrm{bg}\) is utilized to mine possible background snippets at Sect. 3.2.1. To verify the influence of \(\lambda _\textrm{bg}\) on our proposed method, we conducted extensive ablation experiments on the THUMOS’14 dataset, and the results are presented in Table 6. As shown in Table 6, when \(\lambda _\textrm{bg}\) is set to 0.93 or 0.95, the AVG mAP of generated pseudo-labels is comparable. However, for a higher tIoU threshold, the mAP with \(\lambda _\textrm{bg} = 0.95\) is higher than that with \(\lambda _\textrm{bg} = 0.93\). This phenomenon results in a higher AVG mAP with \(\lambda _\textrm{bg} = 0.95\) than with \(\lambda _\textrm{bg} = 0.93\) (\(61.1\%\,vs.\,60.3\%\)) after re-training.
Ablation study on \(\lambda _\textrm{pl}\) The hyperparameter \(\lambda _\textrm{pl}\) is utilized in Sect. 3.2.1 to generate pseudo-labels based on TCAM. As shown in Table 7, we conducted ablation experiments on \(\lambda _{pl}\) to verify its impact on model performance on the THUMOS’14 dataset. As indicated by Table 7, when \(\lambda _{pl}\) is uniformly sampled with a step size of 0.025 between 0.025 and 0.225, the highest quality of pseudo-labels is generated, resulting in an AVG mAP of \(61.1\%\). Increasing the step size to 0.05 may decrease the boundary accuracy of some action instances in the pseudo-labels, leading to a decrease in AVG mAP to \(60.9\%\). Similarly, changing the start and end values of the sampling range also leads to a certain degree of quality reduction in the pseudo-labels, resulting in a decrease in the final AVG mAP.
Ablation study on \(\lambda _\textrm{vid}\) In Sect. 3.2.1, the hyperparameter \(\lambda _\textrm{vid}\) filters out low-quality pseudo-labels based on confidence scores. We conducted extensive ablation experiments on this hyperparameter on the THUMOS’14 dataset, and the results are presented in Table 8. As indicated by Table 8, the pseudo-labels with \(\lambda _\textrm{vid} = 0.55\) can better supervise the re-training stage, leading to the best performance (AVG mAP: \(61.1\%\)). Lowering \(\lambda _\textrm{vid}\) results in a higher number of pseudo-labels, introducing a large amount of noise and gradually decreasing AVG mAP, as shown in Table 8. Similarly, increasing \(\lambda _\textrm{vid}\) may omit the pseudo-labels of some action instances. With an increase in \(\lambda _\textrm{vid}\), AVG mAP gradually decreases.
Ablation on \(\lambda _{c1}\) and \(\lambda _{c2}\) During inference, \(\lambda _{c1}\) is used to locate all action categories in the video, while \(\lambda _{c2}\) is used to locate possible snippets that could be actions. To investigate the impact of these two hyperparameters on the final performance, we conducted ablation experiments on the THUMOS’14 dataset separately for \(\lambda _{c1}\) and \(\lambda _{c1}\), and the results are presented in Tables 9 and 10, respectively. As shown in Table 9, the best overall performance in terms of AVG mAP was achieved when \(\lambda _{c1} = 0.10\). Increasing \(\lambda _{c1}\) tends to ignore certain actions when multiple actions occur in a video, leading to reduced performance. Lowering \(\lambda _{c1}\) may include actions not occurring in the video, negatively impacting performance. In Table 10, it can be observed that as \(\lambda _{c2}\) increases to 0.2 and 0.3, the performance decreases. This is because larger \(\lambda _{c2}\) values tend to skip some action snippets resulting in incomplete detection results. The performance remains constant when \(\lambda _{c2} = 0.1\). However, smaller \(\lambda _{c2}\) would increase the number of action instances during NMS, which may affect the inference speed. Therefore, we set our \(\lambda _{c2}\) to 0.1.

Background mining analysis. From the visualization of background probabilities during the training process in the figure and the frame-level labels of two corresponding action instances, it can be observed that, given a certain threshold, snippets belonging to the action will not be considered part of the background. Meanwhile, most of the valid background snippets can be discovered based on the threshold. Even though this approach may not identify all the snippets belonging to the background, these discovered background snippets are still beneficial for model training
4.5 Analysis
In this section, we carried out a visualization analysis of the results of both background mining and joint learning classification modules during the training process to verify if these two modules work as described in earlier sections.
4.5.1 Background mining analysis
In Sect. 3.2.1, we utilize background mining to identify potential background snippets, which provide background supervision and significantly improve the quality of pseudo-labels, leading to enhanced performance of the re-training model. As shown in Table 3, incorporating background mining boosts AVG mAP (0.1 : 0.7) from 42.1 to \(61.1\%\). In Fig. 7, we visualize the specific snippet regions discovered by background mining during the training process. As depicted, snippets corresponding to the two action instances tend to have lower background scores, indicating that they are not identified as background snippets. On the other hand, within true background regions, most of the snippets’ background scores exceed the threshold and are detected as background snippets. Significantly, even though the two action instances shown in the figure are close, many of the snippets within the background region between them are still identified as background snippets. This phenomenon guarantees the quality of the final generated pseudo-labels and significantly elevates the AVG mAP of the re-training model.
4.5.2 Joint learning analysis
In Fig. 8, we visualize the results of selecting the clean set during training. The figure shows that the blue curve represents the inconsistency score \(p_u\) calculated by the two sub-modules in JLCM. The nine red dots correspond to the pseudo-labels of nine snippets, where the first three have no corresponding frame-level ground truth and are therefore regarded as noise. It can be observed that the clean set effectively filters out most of the snippets corresponding to the noise by setting a threshold value, thus reducing their impact on model training. Although the clean set also filters out some non-noise background snippets, a more precise clean set is more beneficial for model training than adding label noise.

Visualization of clean set selection during training. In the figure, \(p_u\) represents the predicted inconsistency score, while the nine red dots correspond to the inconsistency scores of the pseudo-labels. Among them, the first three red dots correspond to snippets without frame-level ground truth and are therefore considered noise. It can be observed that using a threshold value for selecting the clean set effectively filters out most of the noise. Although the clean set also filters out some non-noise background snippets, the more precise labels in the clean set are more beneficial for model training (colour figure online)
4.6 Further error analysis
We utilized the tools provided by [49] to perform further analysis of our results on the THUMOS’14 dataset.
Metrics In [49], several metrics were defined for the THUMOS’14 dataset, including #instances, length, and coverage. The #instances represent the number of instances of the same class in a video and are divided into four groups: Extra Small (XS: 1); Small (S: [2, 40]); Medium (M: [40, 80]); Large (L: \(> 80\)). Length represents the absolute length of action and is divided into five length groups in [49]: Extra Small (XS: (0, 3]), Small (S: (3, 6]), Medium (M: (6, 12]), Long (L: (12, 18]), and Extra Long (XL: \(> 18\)). Coverage is defined as the relative length of action and is also divided into five groups: Extra Small (XS: (0, 0.02]), Small (S: (0.02, 0.04]), Medium (M: (0.04, 0.06]), Large (L: (0.06, 0.08]), and Extra Large (XL: (0.08, 1.0]).

False negative (FN) profiling of our results on THUMOS’14
False negative profiling Figure 9 illustrates the false negative (FN) rates across different groups. LPR only performs well in the coverage groups of S and L, while the FN rates in the other coverage groups are relatively high, especially in the XS and XL groups. Similar characteristics are also observed in terms of length and #instances. In videos, very short or very long actions naturally present greater difficulty in localizing action boundaries, and a large number of action instances in a video also pose a challenge for complete localization.

Sensitivity analysis of our results on THUMOS’14

False positive (FP) profiling of out results on THUMOS’14
Sensitivity analysis Figure,10 presents the normalized mAP (left) and the variance of mAP over different categories (right) of LPR under different metrics at tIoU \(=0.5\). LPR exhibits similar results to false negative profiling, with poor performance on very short or very long action instances. Especially, LPR’s performance drops significantly when action instances fall under the XL group. Furthermore, LPR shows robustness in coverage and #instances, as indicated by their small variances. However, LPR’s robustness in length is poor, mainly due to the poor performance in the XL length group. Based on the above analysis and the analysis on false negative profiling, it can be concluded that the main factor affecting LPR’s performance is the difficulty in localizing longer action instances. We speculate that the main reason for this phenomenon is that some segments of longer action instances have low discriminability and tend to be localized as multiple sub-segments rather than a complete action instance under LPR.
False positive profiling Figure 11 presents the breakdown of false positive (FP) errors when considering the predictions for the top-10 ground truth (left) and the improvement of performance by removing errors of different types (right). From the figure, we can observe that the main error types of LPR are localization error and background error, among which the localization error is the most significant type. This indicates that although LPR has shown a significant performance improvement compared to the state-of-the-art, there are still many areas for improvement in boundary accuracy. LPR can detect actions well, but how to better locate the boundaries should be further explored in the future.
4.7 Qualitative results
In order to demonstrate the effectiveness of our LPR method more intuitively, we qualitatively compared LAC [14] and LPR on THUMOS’14 dataset, as shown in Fig. 12. It can be seen that LAC tends to locate larger regions to cover the ground truth. Specifically, when action instances are close to each other, LAC may predict them as one action instance. In contrast, our LPR can locate the instances more accurately. Even when the instances are close to each other, LPR can still predict each instance accurately.

Qualitative comparison with LAC [14] and our LPR on THUMOS’14
5 Conclusion
In this paper, we propose a re-training framework, called LPR, for the first time for the PTAL task. LPR consists of two stages: pseudo-label generation and re-training. In the pseudo-label generation stage, LPR fully uses the implicit information provided by point-level annotations to generate efficient frame-level pseudo-labels. In the re-training stage, the temporal action localization network is trained to recognize action categories while localizing action boundaries using the generated frame-level pseudo-labels. We further propose a joint learning classification module in the re-training stage to alleviate the interference of label noise during the training process. Extensive experiments on two benchmarks demonstrate the effectiveness of LPR.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
References
Apostolidis, E., Adamantidou, E., Metsai, A.I., Mezaris, V., Patras, I.: Video summarization using deep neural networks: a survey. Proc. IEEE 109(11), 1838–1863 (2021)
Derdiyok, S., Patlar Akbulut, F.: Biosignal based emotion-oriented video summarization. Multimed. Syst. (2023). https://doi.org/10.1007/s00530-023-01071-4
Yeh, M.-C., Tsai, Y.-W., Hsu, H.-C.: A content-based approach for detecting highlights in action movies. Multimed. Syst. (2015). https://doi.org/10.1007/s00530-015-0457-6
Khan, A., Rao, Y., Shao, J.: Enet: event based highlight generation network for broadcast sports videos. Multimed. Syst. (2022). https://doi.org/10.1007/s00530-022-00978-8
Shingrakhia, H., Patel, H.: Emperor penguin optimized event recognition and summarization for cricket highlight generation. Multimed. Syst. (2020). https://doi.org/10.1007/s00530-020-00684-3
Sultani, W., Chen, C., Shah, M.: Real-world anomaly detection in surveillance videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6479–6488 (2018)
Liu, M., Wang, X., Nie, L., Tian, Q., Chen, B., Chua, T.-S.: Cross-modal moment localization in videos. In: Proceedings of the 26th ACM International Conference on Multimedia, pp. 843–851 (2018)
Liu, M., Nie, L., Wang, Y., Wang, M., Rui, Y.: A survey on video moment localization. ACM Comput. Surv. 55(9), 1–37 (2023)
Zhao, Y., Xiong, Y., Wang, L., Wu, Z., Tang, X., Lin, D.: Temporal action detection with structured segment networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2914–2923 (2017)
Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: Bsn: boundary sensitive network for temporal action proposal generation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
Xu, M., Zhao, C., Rojas, D.S., Thabet, A., Ghanem, B.: G-tad: sub-graph localization for temporal action detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10156–10165 (2020)
Zhang, C.-L., Wu, J., Li, Y.: Actionformer: localizing moments of actions with transformers. In: European Conference on Computer Vision, pp. 492–510 (2022). Springer
Ma, F., Zhu, L., Yang, Y., Zha, S., Kundu, G., Feiszli, M., Shou, Z.: Sf-net: single-frame supervision for temporal action localization. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16, pp. 420–437 (2020). Springer
Lee, P., Byun, H.: Learning action completeness from points for weakly-supervised temporal action localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 13648–13657 (2021)
Fu, J., Gao, J., Xu, C.: Compact representation and reliable classification learning for point-level weakly-supervised action localization. IEEE Trans. Image Process. 31, 7363–7377 (2022)
Ju, C., Zhao, P., Chen, S., Zhang, Y., Wang, Y., Tian, Q.: Divide and conquer for single-frame temporal action localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 13455–13464 (2021)
Yang, L., Han, J., Zhao, T., Lin, T., Zhang, D., Chen, J.: Background-click supervision for temporal action localization. IEEE Trans. Pattern Anal. Mach. Intell. 44(12), 9814–9829 (2021)
Zhang, C., Bengio, S., Hardt, M., Recht, B., Vinyals, O.: Understanding deep learning (still) requires rethinking generalization. Commun. ACM 64(3), 107–115 (2021)
Xu, H., Das, A., Saenko, K.: R-c3d: region convolutional 3d network for temporal activity detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 5783–5792 (2017)
Lin, C., Xu, C., Luo, D., Wang, Y., Tai, Y., Wang, C., Li, J., Huang, F., Fu, Y.: Learning salient boundary feature for anchor-free temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3320–3329 (2021)
Fang, Z., Zhu, S., Yu, J., Tian, Q.: Pcpcad: proposal complementary action detector. In: 2019 IEEE International Conference on Multimedia and Expo (ICME), pp. 424–429 (2019). IEEE
Liu, Y., Ma, L., Zhang, Y., Liu, W., Chang, S.-F.: Multi-granularity generator for temporal action proposal. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3604–3613 (2019)
Cheng, F., Bertasius, G.: Tallformer: temporal action localization with a long-memory transformer. In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIV, pp. 503–521 (2022). Springer
Wang, L., Xiong, Y., Lin, D., Van Gool, L.: Untrimmednets for weakly supervised action recognition and detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4325–4334 (2017)
Nguyen, P., Liu, T., Prasad, G., Han, B.: Weakly supervised action localization by sparse temporal pooling network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6752–6761 (2018)
Liu, D., Jiang, T., Wang, Y.: Completeness modeling and context separation for weakly supervised temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1298–1307 (2019)
Lee, P., Uh, Y., Byun, H.: Background suppression network for weakly-supervised temporal action localization. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 11320–11327 (2020)
He, B., Yang, X., Kang, L., Cheng, Z., Zhou, X., Shrivastava, A.: Asm-loc: action-aware segment modeling for weakly-supervised temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13925–13935 (2022)
Xia, H., Zhan, Y., Cheng, K.: Spatial-temporal correlations learning and action-background jointed attention for weakly-supervised temporal action localization. Multimed. Syst. 28(4), 1529–1541 (2022)
Li, P., Cao, J., Ye, X.: Prototype contrastive learning for point-supervised temporal action detection. Expert Syst. Appl. 213, 118965 (2023)
Qin, J., Wu, J., Xiao, X., Li, L., Wang, X.: Activation modulation and recalibration scheme for weakly supervised semantic segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 2117–2125 (2022)
Lee, J., Kim, E., Yoon, S.: Anti-adversarially manipulated attributions for weakly and semi-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4071–4080 (2021)
Ju, C., Zhao, P., Zhang, Y., Wang, Y., Tian, Q.: Point-level temporal action localization: bridging fully-supervised proposals to weakly-supervised losses (2020). arXiv:2012.08236
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in Neural Information Processing Systems, vol. 30 (2017)
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization (2016). arXiv:1607.06450
Xiao, T., Singh, M., Mintun, E., Darrell, T., Dollár, P., Girshick, R.: Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 34, 30392–30400 (2021)
Lin, T.-Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988 (2017)
Wei, H., Feng, L., Chen, X., An, B.: Combating noisy labels by agreement: a joint training method with co-regularization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13726–13735 (2020)
Zheng, Z., Wang, P., Liu, W., Li, J., Ye, R., Ren, D.: Distance-iou loss: faster and better learning for bounding box regression. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 12993–13000 (2020)
Idrees, H., Zamir, A.R., Jiang, Y.-G., Gorban, A., Laptev, I., Sukthankar, R., Shah, M.: The thumos challenge on action recognition for videos “in the wild’’. Comput. Vis. Image Underst. 155, 1–23 (2017)
Calway, A., Mayol-Cuevas, W., Damen, D., Haines, O., Leelasawassuk, T.: Discovering task relevant objects and their modes of interaction from multi-user egocentric video. In: BMVC, pp. 30–1 (2015)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6299–6308 (2017)
Liu, X., Bai, S., Bai, X.: An empirical study of end-to-end temporal action detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20010–20019 (2022)
Li, J., Yang, T., Ji, W., Wang, J., Cheng, L.: Exploring denoised cross-video contrast for weakly-supervised temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19914–19924 (2022)
Zhao, Y., Zhang, H., Gao, Z., Gao, W., Wang, M., Chen, S.: A novel action saliency and context-aware network for weakly-supervised temporal action localization. IEEE Trans. Multimed. (2023)
Zhou, J., Wu, Y.: Temporal feature enhancement dilated convolution network for weakly-supervised temporal action localization. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 6028–6037 (2023)
Moltisanti, D., Fidler, S., Damen, D.: Action recognition from single timestamp supervision in untrimmed videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9915–9924 (2019)
Ju, C., Zhao, P., Zhang, Y., Wang, Y., Tian, Q.: Point-level temporal action localization: bridging fully-supervised proposals to weakly-supervised losses (2020). arXiv:2012.08236
Alwassel, H., Heilbron, F.C., Escorcia, V., Ghanem, B.: Diagnosing error in temporal action detectors. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 256–272 (2018)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by A. Liu.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fang, Z., Fan, J. & Yu, J. LPR: learning point-level temporal action localization through re-training. Multimedia Systems 29, 2545–2562 (2023). https://doi.org/10.1007/s00530-023-01128-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-023-01128-4