
Abstract
The COVID-19 pandemic has opened numerous challenges for scientists to use massive data to develop an automatic diagnostic tool for COVID-19. Since the outbreak in January 2020, COVID-19 has caused a substantial destructive impact on society and human life. Numerous studies have been conducted in search of a suitable solution to test COVID-19. Artificial intelligence (AI) based research is not behind in this race, and many AI-based models have been proposed. This paper proposes a lightweight convolutional neural network (CNN) model to classify COVID and Non_COVID patients by analyzing the hidden features in the X-Ray images. The model has been evaluated with different standard metrics to prove the reliability of the model. The model obtained 98.78%, 93.22%, and 92.7% accuracy in the training, validation, and testing phases. In addition, the model achieved 0.964 scores in the Area Under Curve (AUC) metric. We compared the model with four state-of-art pre-trained models (VGG16, InceptionV3, DenseNet121, and EfficientNetB6). The evaluation results demonstrate that the proposed CNN model is a candidate for an automatic diagnostic tool for the classification of COVID-19 patients using chest X-ray images. This research proposes a technique to classify COVID-19 patients and does not claim any medical diagnosis accuracy.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Digital healthcare and advanced data analytic techniques have changed the way of patient care and diagnosis. Due to the rapid growth in digital healthcare, a massive volume of multimedia healthcare data is being generated [3]. Moreover, medical data is complex and has different forms. As a result, there are numerous challenges for both academia and industry to develop new insights into diseases. Hence, AI-based models, such as machine learning (ML), deep learning (DL), and convolutional neural networks (CNN), are now widely used to handle the massive volume of data to enable accurate and fast medical data analysis and discover unknown features inside the data.
Since the outbreak of COVID-19, it is still a major health concern for society, human life and for healthcare professionals. The COVID-19 pandemic has recently opened numerous challenges for researchers to develop a proper diagnostic tool using massive multimedia data generated from COVID-19 diagnosis. COVID-19 disease is caused by coronavirus infection. Coronavirus infection may cause severe illnesses like Acute Respiratory Syndrome (SARS) and Middle East Respiratory Syndrome (MERS). It is observed that SARS-CoV-2 is the cause of COVID-19 infection. The World Health Organization (WHO) attests that the COVID-19 virus makes open holes in lungs that look similar to honeycomb [34]. WHO has declared COVID-19 as a pandemic within three months of its outbreak. COVID-19 is a serious health risk in many countries. If COVID-19 causes mild respiratory illness, then by taking antibiotics, it can be diagnosed easily. However, if patients have previous health complications (chronic respiratory diseases, diabetes, and cardiovascular diseases), then they suffer more from COVID-19. WHO has reported COVID-19 affected patients’ general symptoms, like mild fever, breath shortness, dry cough, fatigue, pains, and aching throat [32]. In general, Pneumonia is caused by bacterial and viral pathogens. It is observed that the COVID-19 virus is also the cause of some Pneumonia patients. With early diagnosis, it is possible to know whether a patient has Pneumonia or not. Through further investigation, it is possible to know whether the COVID-19 virus caused Pneumonia or not. This is vital to stopping the virus spreading [29]. Among various imaging modalities, chest radiography has high suboptimal sensitivity for vital medical findings [17]. Medical doctors commonly use X-ray imaging to detect Pneumonia since the availability of X-ray machines. X-ray imaging is a standard tool to diagnose chest-related diseases. Analyzing chest X-rays, various diagnoses can be performed, which range from infectious diseases right through to cancer. Therefore, chest X-ray imaging is widely used to detect COVID-19 infection.
It is observed by analyzing chest X-ray images, and medical practitioners can identify the initial stages of COVID-19 and the damage caused in the lungs, mainly in lower lobes and latter sections, with the peripheral and subpleural distribution. Finding important features by examining X-ray images takes a long time and needs expert medical doctors in the chest domain. It is challenging to diagnose COVID-19 patients with this manual and traditional process since every day, thousands of people are being affected by COVID-19. Therefore, a computer-aided diagnostic tool is imperative to detect COVID-19 disease rapidly.
Today, AI is now an essential tool in medical diagnostics and revolutionizing the healthcare section. It aids physicians to diagnose patients more precisely, predict patients’ future health conditions, and recommend proper treatment [1, 5, 8, 20, 33]. AI will not replace healthcare professionals but acts as an algorithmic computer model to assist medical professionals with difficult diagnoses [10, 24]. Many models have been developed using AI techniques, mainly for medical diagnosis. The models successfully and rapidly identify and predict diseases rapidly. The models also produce better results compared to traditional manual approaches.
Medical image classification plays an essential role in medical treatment. Understanding the features in medical images is very important to diagnose patients correctly. It becomes cumbersome for medical practitioners to understand features from a huge dataset [19]. Therefore, traditional approaches need massive effort to extract and choose classification features.
The convolutional network (CNN) based models, a branch of machine learning methods, has proven their success and potential in medical image classification with huge and complex images [4, 21]. CNN models are now widely used in different image classification problems and have achieved substantial accuracy since 2012 [31]. Some CNN-based models have attained performances better than human experts. For example, CheXNet, a CNN-based model, consists of 121 layers applied on 100,000 frontal-view chest X-rays and has attained an improved performance than four radiologists’ performance. Authors in [15] also proposed a transfer learning model for classifying 108,309 Optical coherence tomography (OCT) images. The model’s weighted average error is the same as the performance of six human experts. Authors in [16] also developed a CNN model to classify chest X-ray images to detect disease. They used 12 different classes of chest X-ray images. The model achieved 86% accuracy. The Authors in [18] developed a deep-learning-based model to detect tuberculosis using a transfer learning approach. The authors also used chest X-ray images, and the model achieved 85.68% accuracy.
The rest of the paper is organized as follows: Sect. 2 discusses works related to work. The materials and methods that are used in this research are discussed in Sect. 3. Section 4 describes the proposed model and presents the evaluation results and comparison results. Section 5 concludes the paper with some future work.
2 Related works
Typically, machine learning-based models mostly rely on skilled medical practitioners in extracting and selecting relevant features. Therefore, researchers use deep learning techniques to develop prediction and detection models [9]. Deep learning models have high capabilities to extract important features from images automatically. Convolutional neural networks are the front runner. Hence, deep learning and DNN techniques are considered mainly at present to extract relevant features for classifying the object of interest automatically. Since the outbreak of COVID-19 numerous CNN based models have been proposed [2, 27, 28]. We now discuss some recent works that used CNN based models for COVID-19 detection and classification.
Authors in [25] presented a CNN model for COVID-19 X-ray image classification. The model also applied Marine Predators Algorithm(MPA) for selecting related features from images. MAP is applied after the CNN model extracts the deep features. The models achieved 98.7% accuracy. Unfortunately, the model is applied to a small dataset that consists of only 200 COVID-19 images and 1675 Non-COVID images.
Authors in [12] applied three pre-trained CNN models (Inception V3, Xception, and ResNeXt ) for classification purposes. The models used 6432 chest- X-ray images. Among the models, Xception obtained the highest accuracy 97.97%. The models used a publicly available Kaggagle dataset consists of 6432 total chest X-ray images.
Authors in [11] combined CNN-based model and traditional machine learning techniques for classifying COVID-19 patients applying the model on X-ray images. Different pre-trained models, such as VGG16, VGG19, ResNet18, ResNet50, ResNet101, are used to extract features, and the Support Vector Machines (SVM) classifier is used for classification. However, the model used a very small dataset. The dataset contains chest X-ray images of 180 COVID-19 patients and 200 healthy patients. The model obtained a low accuracy of 94.7%.
The authors in [23] presented a CNN model to identify COVID-19 patients considering chest X-ray images. The model performed multi-class classification (Normal, Pneumonia, and COVID) and achieved 98.08% accuracy in binary classification and 87.02% in multi-class classification. The DarkNet pre-trained model is used for classification.
The authors in [7] investigated various techniques to implement a CNN model for detecting and classifying COVID-19 cases considering chest X-ray images. The investigation found that advanced image preprocessing shows better performance in the model’s performance. Hence, the authors applied several preprocessing steps, such as taking away unrelated regions, normalizing image contrast-to-noise ratio, and generating pseudo color images, before feeding images to the models.
Besides proposing custom CNN models, many researchers have proposed CNN models applying pre-trained models to classify chest X-ray images for COVID and Non-COVID cases. Five pre-trained models, for example (ResNet50, ResNet101, ResNet152, InceptionV3 and Inception-ResNetV2) were used. Authors in [22] observed that the ResNet50 model achieved the highest classification accuracy of 96.1%.
Authors in [26] proposed a model combining SVM and ResNet50 pre-trained model to classify COVID-19 affected chest X-Ray images. The model achieved 95.38% classification accuracy.
Authors in [6] evaluated three pre-trained CNN models (EfficientNetB0, VGG16, and InceptionV3) to differentiate normal and COVID-19 impacted patients by viral Pneumonia. The models achieved an average of 92.93% accuracy and 94.79% in sensitivity. However, our model achieved 96% accuracy.
Authors in [13] have compared Inception V3, Xception, and ResNeXt pre-trained models to classify normal and COVID-19 affected patients using chest X-Ray scans images. The Xception model achieved the best accuracy of 97.97% in classification.
3 Materials and methods
We considered a large X-Ray image dataset related to COVID-19 patients that is publicly available in [30]. The dataset is the result of some augmentation methods. The dataset has 9407 X-Ray and 8054 CT images. In X-Ray images, there are 5493 Non-COVID and 3914 COVID cases. Figure 1 shows sample images of COVID and Non-COVID cases in the dataset. Figure 2 presents COVID and Non-COVID class ratio and the number of images in the dataset. The images have various sizes. The Fig. 3 depicts the five most frequency of different sizes of the images. In the dataset, there are 3396 different sizes of images. There are 4786 images with the dimensions \(1024\times 1024\times 3\) as shown in Fig. 3. Therefore, the image size has high variations. Moreover, the dataset is not balanced. Notice that the images have different noises. Therefore, a special pre-processing mechanism is required.

Sample of X-Ray images (COVID and Non-COVID cases

Dataset of COVID and Non-COVID cases distributions

Image size distribution
3.1 Prepossessing
Through exploratory data analysis, we observe that many images have noses, some are out of focus, and the dataset has a large variation of image shape. Gaussian blurring is generally applied to reduce noise in images. It works as a non-uniform low-pass filter, retaining spatial frequency with a low value while reducing image noise and reducing minimum details. In Gaussian blurring, a special kernel, named, Gaussian kernel, is employed over images. The formula of Gaussian blurring is shown below: Eq. 1.
where \(\sigma\) denotes the standard deviation of the distribution. The positions of the indices are denoted by p and q. \(\sigma\) controls the variance of Gaussian distribution around a mean, which identifies the outcome of blurring a pixel’s neighbors. In this paper, Gaussian blurring is applied to minimize the noise in images. Figure 4 depicts the effect of Gaussian blurring in two sample images (COVID and Non-COVID) cases. From the images, it is apparent that some essential features are clearer after applying the Gaussian blurring method.

COVID and Non-COVID images with Gaussian Blur
4 Proposed model

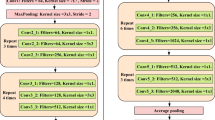
Proposed CNN model
This paper presents a light-weight shallow CNN model for classifying COVID and Non-COVID cases from a large X-Ray image dataset. Figure 5 shows the proposed model. The model has two pairs of 2D convolutional layers. The first pair has 32 filters with a \(3\times 3\) kernel. The model employs a MaxPooling2D layer after each 2D convolutional layer. A Max pooling layer is used to downsample the output of a Conv2D by considering the maximum value as defined by the pooling window size in every dimension of the features axis. The window moves by the defined strides in each dimension. The second 2D convolutional layer has 64. The model also applies the Dropout regularization technique after each pair of convolutional layers.
The dropout technique randomly selects neurons and ignores them during the model’s training. The dropped neurons’ involvement in the activation of downstream neurons is omitted for a while in the forward pass and the weights are not considered for the neurons during the backward pass. The model applies a 20% dropout after each pair of convolutional layers. The model also applies 50% after the fully connected layer. There are 64 neurons in the fully connected layer. The “relu” activation function is considered after each convolutional layer. The prediction layer employs the Sigmoid activation function since the model classifies two classes, COVID and non-COVID.
From the output of the Sigmoid function, we consider the average loss as the loss and validate with labels exceeding 0.5 as T and F otherwise, which is defined as below:
The Root Mean Square Propagation (RMSprop) optimizer is used by the model. The RMSprop optimizer reduces oscillations and changes the learning rate dynamically. Besides, the RMSprop optimizer picks a suitable learning rate for each parameter. The following equation defines the update.
For each parameter \(w_j\)
where, \(\mu\) denotes initial learning, \(v_t\) denotes exponential average of squares of gradients, and gradient at time t of \(w_j\) is denoted by \(g_t\). Moreover, Adam optimizer, links RMSprop and momentum’s heuristics. The following equation shows the calculation.
For each parameter \(w_j\)
Here \(w_j\) and \(g_t\) gradient at time t along \(w_j\), \(_t\) an exponential average of squares of gradients along \(w_j\), \(\beta _{1},\beta _{2}\) are hyperparameters. The Sigmoid activation function is used by the model as the prediction layer and is generally considered for binary classification problems. The function generates output values between 0 and 1 from any real input value. It has different features of activation functions and is a non-linear function, incessantly differentiable, monotonous. The Sigmoid function outputs a fixed range of output. The Sigmod function is shown below:
The model is trained using the parameters as shown in Table 1.
4.1 Performance analysis
We have evaluated the performance of the proposed model in three phases: (i) training (ii) validation, and (iii) testing. First, the dataset is divided into two sets, a training set of 70% and a testing set of 30%. Again, the training set is divided into a training set: 80% and the validation set: 20%. Table 2 shows the dataset size of each split.
Initially, the original dataset consists of 9407 X-Ray images. After the split training dataset has 5268, the validation dataset has 1316, and the test dataset has 2823 images. The model is trained for 50 epochs. However, we consider two Callbacks APIs: Early Stopping (EarlyStopping) and Reduce on Loss Plateau Decay (ReduceLROnPlateau) [14] with parameters patience = 3, factor = 0.5, and minimum learning rate, min_lr = 0.00001. The Factor parameter is a multiplier that decreases the learning rate as \(\text {lr} = \text {lr}*\text {factor} = \lambda\). The patience parameter implies the epochs number without improvement, after which the learning rate decreases. EarlyStopping callback is used for model’s early stopping. Meanwhile, ReduceLROnPlateau callback reduces the learning rate if a metric does now improve during training. Figure 6 presents the accuracy and loss of the model during training and validation. From the graph in Fig. 6, we observe that training and validation accuracy follow the same pattern. It indicates that the model is not overfitting. Usually, two techniques, (i) cross-validation and (ii) image augmentation, are applied to resolve overfitting problems of a model. The techniques are used if the size of a dataset is small. Fortunately, the dataset that is used is large. Moreover, using the proper augmentation technique, several images are generated from the original X-Ray images. Hence, no particular solution is needed for the overfitting problem. While in the loss graph, there are few spikes in the validation loss, but it is very much nearer to the training loss. Hence, the model generalizes better.

Training and validation accuracy and loss
Evaluation of a model is a very important phase to prove the validity of the model. A model may give satisfying accuracy in a metric, e.g., accuracy but may obtain poor outcomes against other metrics, like precision, recall, F1-sore, AUC, etc. Mainly, we consider accuracy metrics for evaluating the model’s performance. However, this is not enough to justify the model’s performance. Hence, we evaluated the proposed model with other standard metrics, such as precision, F1-score, recall, AUC, and confusion matrix. We now discuss these metrics.
Classification Accuracy is the percentage of correct predictions to the size of input samples. The precision metric of a model defines the fraction of the correctly positive predictions and the size of actual positive samples. The Recall metric is the fraction of the correctly positive predictions and the size of samples that are supposed to be predicted as positive. The F1 score evaluates a model’s accuracy using testdata. It is the harmonic meaning between precision and recall. This metric demonstrates how accurate and robust a model is. The larger the F1 score validates the better performance of a model.
Area Under Curve (AUC) is another important and commonly used metric to assess the performance of a model. Usually, AUC is considered in a binary classifier model. The AUC metric defines the probability that a model classifies an arbitrarily chosen positive sample greater than an arbitrarily chosen negative sample. To obtain an AUC score, False Positive Rate (FPR) and True Positive Rate (TPR), having scores within [0, 1], need to be calculated. A higher AUC score proves the better performance of a model. FPR and TPR are calculated at different thresholds and are demonstrated using a graph.
The Precision-Recall Curve (PRC) demonstrates the association between precision and recall values for each possible cut-off. PRC is a plot of the precision (y-axis) and the recall (x-axis) for different probability thresholds. Generally, a model’s performance is better if the PRC is closer to the top right corner. In an ideal model, PRC goes over the top right corner, demonstrating 100% precision and 100% recall.

Precision, recall, and F1 scores of the proposed model

AUC and PRC scores
As shown in Table 3, the model achieved 98.78% and 93.22% accuracy in training validation phases. Meanwhile, the model achieved 92.7% accuracy on the testdata set. The results show that the model does not overfit or underfit. Moreover, the model scored 0.91 in precision, recall, and F1-score metrics. Figure 7 shows these scores. The model shows an excellent result in AUC and PRC scores, which are 0.964 and .94, respectively. Figure 8 shows the AUC and PRC scores. All the results are summarized in Table 4
The model is also evaluated with a confusion matrix to observe the behavior of the model w.r.t to True Positive (TP), False Positive (FP), True Negative (TN), and False Negative (FN) scores in classifying COVID and Non-COVID classes. Figure 9 shows the scores that the model produces applying to the test dataset. We observe from the matrix that the model correctly classified 682 cases from 1633 Non-COVID and wrongly classified 103 as COVID cases. The model also classified 1087 COVID cases from 1190 COVID cases and wrongly classified 103 as Non-COVID cases. The result proves that the model performs pretty well in classification.

Confusion matrix score of the proposed model
Nowadays, classification models have further progressed with the introduction of the transfer learning approach. The transfer learning approach allows leveraging knowledge, such as features, weights, etc., from pre-existing models to our classification problem trained over a large dataset. It also handles problems with the problem of training a custom model with a small size of dataset. For example, in the computer vision domain, particular features in low-level, such as edges, corners, shapes, and intensity, are possible to share across classification problems. Hence, it enables knowledge transfer. The essential condition of transfer learning is the existence of models that work fine on source tasks. Luckily, various state-of-the-art deep learning models, called pre-trained models, are available openly so that others can use the knowledge of these models. These pre-trained models contain millions of parameters/weights that the models obtained while being trained over a huge image dataset. Deep learning models consist of layered architecture that learn various features at various layers. Finally, the layers are connected to a fully connected layer to achieve the final classification outcome. Hence, the layered architecture allows us to use a pre-trained model (VGG16, InceptionV3, Xception, ResNet50, etc.) to remove its final layer as a fixed feature extractor other tasks.
This research compares the proposed model’s performance with the four state-of-art pre-trained models (VGG16, InceptionV3, DenseNe121, and EfficientNetB6) applied on the same dataset. In the last few years, several pre-trained models have been proposed. These four models are usually studied to assess any proposed model. Consequently, we also judged these four models. Table 5 shows the comparison results.
Among the pre-trained models, only the VGG16 model shows good performance. The proposed model shows almost the same results as the VGG16 model. However, the proposed model is light, very few convolutional layers, and a lesser number of parameters.
5 Conclusion
This paper proposed a small-sized CNN model for COVID and Non-COVID patients classification using X-Ray images. The CNN model has only four 2D convolutional layers and one fully connected layer. The proposed model obtains good results in all standard metrics during the training, validation, and testing phases. Hence, the model is not overfitting. The model achieved 92.7% accuracy on the test dataset. The test dataset contains 2823 COVID and Non-COVID X-Ray images. The model also achieved a 0.93 score in precision and recall metrics. Moreover, the model obtained a 0.94 score in the AUC metric. We also compare the proposed model with some pre-trained models. The model also outperformed some pre-trained models in performances. In the future, we plan to apply other proposed classification models and find out essential features from x-Ray images to improve the model’s accuracy. The model will be tested on other open datasets and look for performance improvement.
Availability of data and material
Data used for this experiment is open-source data taken from https://data.mendeley.com/datasets/8h65ywd2jr/3.
Code availability
The experimental code is available on request.
References
Abdulsalam, Y., Hossain, M.S.: COVID-19 networking demand: an auction-based mechanism for automated selection of edge computing services. IEEE Trans. Netw. Sci. Eng. (2020). https://doi.org/10.1109/TNSE.2020.3026637
Alanazi, S.A., Kamruzzaman, , et al.: Measuring and preventing COVID-19 using the sir model and machine learning in smart health care. J. Healthc. Eng. 2020(8857), 346 (2020). https://doi.org/10.1155/2020/8857346
Amin, S.U., et al.: Cognitive smart healthcare for pathology detection and monitoring. IEEE Access 7, 10745–10753 (2019)
Amin, S.U., et al.: Deep learning for EEG motor imagery classification based on multi-layer CNNs feature fusion. Futur. Gener. Comput. Syst. 101, 542–554 (2019b)
Awal, M.A., et al.: A novel bayesian optimization-based machine learning framework for COVID-19 detection from inpatient facility data. IEEE Access 9, 10263–10281 (2021). https://doi.org/10.1109/ACCESS.2021.3050852
Gaur, L., Bhatia, U., Jhanjhi, N.Z., Muhammad, G., Masud, M.: Medical image-based detection of COVID-19 using deep convolution neural networks. Multimed. Syst. (2021). https://doi.org/10.1007/s00530-021-00794-6
Heidari, M., Kandehei, M., et al.: Improving the performance of CNN to predict the likelihood of covid-19 using chest X-Ray images with preprocessing algorithms. Int. J. Med. Inform. 144, 104284–104284 (2020). https://doi.org/10.1016/j.ijmedinf.2020.104284
Hossain, M.S.: Cloud-supported cyber-physical localization framework for patients monitoring. IEEE Syst. J. 11(1), 118–127 (2017). https://doi.org/10.1109/JSYST.2015.2470644
Hossain, M.S., Muhammad, G.: Emotion recognition using deep learning approach from audio-visual emotional big data. Inf. Fusion 49, 69–78 (2019)
Hossain, M.S., Muhammad, G., Guizani, N.: Explainable AI and mass surveillance system-based healthcare framework to combat COVID-19 like pandemics. IEEE Network 34(4), 126–132 (2020). https://doi.org/10.1109/MNET.011.2000458
Ismael, A.M., Şengör, A.: Deep learning approaches for COVID-19 detection based on chest X-Ray images. Expert Syst. Appl. 164(114), 054 (2021). https://doi.org/10.1016/j.eswa.2020.114054
Jain, R., Gupta, M., et al.: Deep learning based detection and analysis of COVID-19 on chest X-Ray images. Appl. Intell. (2020). https://doi.org/10.1007/s10489-020-01902-1
Jain, R., Gupta, M., Taneja, S., Hemanth, D.J.: Deep learning based detection and analysis of COVID-19 on chest X-Ray images. Appl. Intell. 51(3), 1690–1700 (2021). https://doi.org/10.1007/s10489-020-01902-1
Keras. Reducelronplateau (2021). https://keras.io/api/callbacks/reduce_lr_on_plateau/
Kermany, D.S., Goldbaum, M., et al.: Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 172(5), 1122-1131.e9 (2018). https://doi.org/10.1016/j.cell.2018.02.010
Kesim E., Dokur, Z., Olmez, T.: X-Ray chest image classification by a small-sized convolutional neural network. In: 2019 Scientific Meeting on Electrical-Electronics Biomedical Engineering and Computer Science (EBBT), pp 1–5 (2019) https://doi.org/10.1109/EBBT.2019.8742050
Khan, A.N., Al-Jahdali, H., Al-Ghanem, S., Gouda, A.: Reading chest radiographs in the critically ill (part II): radiography of lung pathologies common in the ICU patient. Ann. Thoracic Med. 4(3), 149–157 (2009). https://doi.org/10.4103/1817-1737.53349
Liu, C., Cao, Y., Alcantara, M., et al.: Tx-CNN: detecting tuberculosis in chest X-Ray images using convolutional neural network. In: 2017 IEEE International Conference on Image Processing (ICIP), pp 2314–2318 (2017). https://doi.org/10.1109/ICIP.2017.8296695
Masud, M., Hossain, M.S., Alamri, A.: Data interoperability and multimedia content management in e-health systems. IEEE Trans. Inf. Technol. Biomed. 16(6), 1015–1023 (2012). https://doi.org/10.1109/TITB.2012.2202244
Masud, M., Gaba, G.S., Alqahtani, S., Muhammad, G., Gupta, B.B., Kumar, P., Ghoneim, A.: A lightweight and robust secure key establishment protocol for internet of medical things in COVID-19 patients care. IEEE Internet Things J. (2020). https://doi.org/10.1109/JIOT.2020.3047662
Muhammad, G., et al.: EEG-based pathology detection for home health monitoring. IEEE J. Sel. Areas Commun. 39(2), 603–610 (2021)
Narin, A., Kaya, C., Pamuk, Z.: Automatic detection of coronavirus disease (COVID-19) using X-Ray images and deep convolutional neural networks. 1–14 (2020). https://doi.org/10.1007/s10044-021-00984-y
Ozturk, T., Talo, M., Yildirim, E.A., et al.: Automated detection of COVID-19 cases using deep neural networks with X-Ray images. Comput. Biol. Med. 121(103), 792 (2020). https://doi.org/10.1016/j.compbiomed.2020.103792
Rahman, M.A., Alrajeh, N.A., et al.: B5g and explainable deep learning assisted healthcare vertical at the edge: COVID-19 perspective. IEEE Network 34(4), 98–105 (2020). https://doi.org/10.1109/MNET.011.2000353
Sahil, A., Ewees, D.: COVID-19 image classification using deep features and fractional-order marine predators algorithm. Sci. Rep. 10(29), 153–164 (2020). https://doi.org/10.1038/s41598-020-71294-2
Sethy, P., Behra, S.: Detection of coronavirus disease (COVID-19) based on deep features. (2020). https://doi.org/10.20944/preprints202003.0300.v1
Shorfuzzaman, M., Hossain, M.S.: Metacovid: a siamese neural network framework with contrastive loss for n-shot diagnosis of COVID-19 patients. Pattern Recogn. 113(2021), 107700 (2021). https://doi.org/10.1016/j.patcog.2020.107700
Shorfuzzaman, M., Masud, M.: On the detection of COVID-19 from chest X-Ray images using CNN-based transfer learning. Comput. Mater. Continua 64(3), 1359–1381 (2020). https://doi.org/10.32604/cmc.2020.011326
Shorfuzzaman, M., Hossain, M.S., Alhamid, M.F.: Towards the sustainable development of smart cities through mass video surveillance: A response to the COVID-19 pandemic. Sustain. Cities Soc. 64(2021), article no. 102582
Walid, ES., Fathi, AES.: Extensive and augmented COVID-19 X-Ray and CT chest images dataset (2020)
Hossain, M.S., et al. : Applying Deep Learning for Epilepsy Seizure Detection and Brain Mapping Visualization. ACM Trans. Multimedia Comput. Commun. Appl. 15,17 (2019), article no. 10. https://doi.org/10.1145/3241056
WHO. Coronavirus overview, prevention and symptoms. (2020) https://www.who.int/emergencies/diseases/novel-coronavirus-2019. Accessed 20 Nov 2020
Yang, X., Zhang, T., et al.: Deep relative attributes. IEEE Trans. Multimed. 18(9), 1832–1842 (2016). https://doi.org/10.1109/TMM.2016.2582379
Zhang, W.: Imaging changes of severe COVID-19 pneumonia in advanced stage. Intensive Care Med. 5(46), 841–843 (2020). https://doi.org/10.1007/s00134-020-05990-y
Acknowledgements
The authors are grateful to Taif university for funding this research through Taif University Research Supporting Project Number (TURSP-2020/10), Taif University, Taif, Saudi Arabia.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Masud, M. A light-weight convolutional Neural Network Architecture for classification of COVID-19 chest X-Ray images. Multimedia Systems 28, 1165–1174 (2022). https://doi.org/10.1007/s00530-021-00857-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-021-00857-8