
Abstract
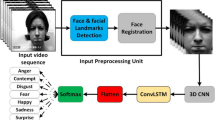
We propose an algorithm that enhances convolutional long short-term memory (ConvLSTM), i.e., Enhanced ConvLSTM, by adding skip connections to spatial and temporal directions and temporal gates to conventional ConvLSTM to suppress gradient vanishing and use information that is older than the previous frame. We also propose a method that uses this algorithm to automatically recognize facial expressions from videos. The proposed facial expression recognition method consists of two Enhanced ConvLSTM streams. We conducted two experiments using eNTERFACE05 database and CK+. First, we conducted an ablation study to investigate the effectiveness of adding spatial and temporal skip connections and temporal gates to ConvLSTM. Ablation studies have shown that adding skip connections to spatial and temporal and temporal gates to conventional ConvLSTM provides the greatest performance gains. Second, we compared the accuracies of the proposed method and state-of-the-art methods. In an experiment comparing the proposed method and state-of-the-art methods, the accuracy of the proposed method was 49.26% on eNTERFACE05 database and 95.72% on CK+. Our proposed method shows superior performance compared to the state-of-the-art methods on eNTERFACE05.








Similar content being viewed by others


References
Ekman P, Friesen WV (1971) Constants across cultures in the face and emotion. J Personal Soc Psychol 17(2):124
Bartlett MS, Littlewort G, Fasel I, Movellan JR (2003) Real time face detection and facial expression recognition: development and applications to human computer interaction. In 2003 conference on computer vision and pattern recognition workshop, vol 5. IEEE, pp 53–53
Ekman P, Friesen WV (1986) A new pan-cultural facial expression of emotion. Motiv Emot 10(2):159–168
Ambadar Z, Schooler JW, Cohn JF (2005) Deciphering the enigmatic face: the importance of facial dynamics in interpreting subtle facial expressions. Psychol Sci 16(5):403–410
Chao W-L, Ding J-J, Liu J-Z (2015) Facial expression recognition based on improved local binary pattern and class-regularized locality preserving projection. Signal Process 117:1–10
Liu P, Han S, Meng Z, Tong Y (2014) Facial expression recognition via a boosted deep belief network. In: 2014 IEEE conference on computer vision and pattern recognition, pp 1805–1812
De la Torre Frade F, Chu W-S, Xiong X, Carrasco F V, Ding X, Cohn J (2015) Intraface. In: Automatic face and gesture recognition
Mollahosseini A, Chan D, Mahoor MH (2016) Going deeper in facial expression recognition using deep neural networks. In: 2016 IEEE winter conference on applications of computer vision (WACV). IEEE, pp 1–10
Lopes AT, de Aguiar E, De Souza AF, Oliveira-Santos T (2017) Facial expression recognition with convolutional neural networks: coping with few data and the training sample order. Pattern Recognit 61:610–628
Ding H, Zhou SK, Chellappa R (2017) Facenet2expnet: regularizing a deep face recognition net for expression recognition. In: 2017 12th IEEE international conference on automatic face and gesture recognition (FG 2017). IEEE, pp 118–126
Mansoorizadeh M, Charkari NM (2010) Multimodal information fusion application to human emotion recognition from face and speech. Multimed Tools Appl 49(2):277–297
Bejani M, Gharavian D, Charkari NM (2014) Audiovisual emotion recognition using ANOVA feature selection method and multi-classifier neural networks. Neural Comput Appl 24(2):399–412
Zhalehpour S, Onder O, Akhtar Z, Erdem CE (2017) Baum-1: a spontaneous audio-visual face database of affective and mental states. IEEE Trans Affect Comput 8(3):300–313
Khorrami P, Le Paine T, Brady K, Dagli C, Huang TS (2016) How deep neural networks can improve emotion recognition on video data. In: 2016 IEEE international conference on image processing (ICIP), pp 619–623
Pan X, Ying G, Chen G, Li H, Li W (2019) A deep spatial and temporal aggregation framework for video-based facial expression recognition. IEEE Access 7:48807–48815
Hara K, Kataoka H, Satoh Y (2017) Learning spatio-temporal features with 3d residual networks for action recognition. In: Proceedings of the IEEE international conference on computer vision, pp 3154–3160
Tran D, Ray J, Shou Z, Chang SF, Paluri M (2017) Convnet architecture search for spatiotemporal feature learning. arXiv:1708.05038
Hara K, Kataoka H, Satoh Y (2018) Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6546–6555
Shi X, Chen Z, Wang H, Yeung D-Y, Wong W, Woo WC (2015) Convolutional LSTM network: a machine learning approach for precipitation nowcasting. In: Cortes C, Lawrence ND, Lee DD, Sugiyama M, Garnett R (eds) Advances in neural information processing systems, vol 28. Curran Associates, Inc, pp 802–810
Lucey P, Cohn JF, Kanade T, Saragih J, Ambadar Z, Matthews I (2010) The extended cohn-kanade dataset (ck+): a complete dataset for action unit and emotion-specified expression. In: 2010 IEEE computer society conference on computer vision and pattern recognition—workshops, pp 94–101
Martin O, Kotsia I, Macq B, Pitas I (2006) The enterface’05 audio-visual emotion database. In: 22nd international conference on data engineering workshops (ICDEW’06). IEEE, pp 8–8
Pantic M, Valstar M, Rademaker R, Maat L (2005) Web-based database for facial expression analysis. In: 2005 IEEE international conference on multimedia and expo, p 5
Caba Heilbron F, Escorcia V, Ghanem B, Carlos Niebles J (2015) Activitynet: a large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 961–970
Soomro K, Zamir AR, Shah M (2012) Ucf101: a dataset of 101 human actions classes from videos in the wild. arXiv:1212.0402
Kay W, Carreira J, Simonyan K, Zhang B, Hillier C, Vijayanarasimhan S, Viola F, Green T, Back T, Natsev P et al (2017) The kinetics human action video dataset. arXiv:1705.06950
Wang Y, Jiang L, Yang MH, Li LJ, Long M, Fei-Fei L (2019) Eidetic 3d lstm: a model for video prediction and beyond. In: ICLR
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556
Gers FA, Schmidhuber E (2001) LSTM recurrent networks learn simple context-free and context-sensitive languages. IEEE Trans Neural Netw 12(6):1333–1340
Wu Y, He K (2018) Group normalization. In: Proceedings of the European conference on computer vision (ECCV), pp 3–19
Baltrusaitis T, Zadeh A, Lim YC, Morency LP (2018) Openface 2.0: facial behavior analysis toolkit. In: 2018 13th IEEE international conference on automatic face and gesture recognition (FG 2018). IEEE, pp 59–66
Farnebäck G (2003) Two-frame motion estimation based on polynomial expansion. In: Scandinavian conference on Image analysis. Springer, pp 363–370
Liu M, Shan S, Wang R, Chen X (2014) Learning expressionlets on spatio-temporal manifold for dynamic facial expression recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1749–1756
Kuo CM, Lai SH, Sarkis M (2018) A compact deep learning model for robust facial expression recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 2121–2129
Meng D, Peng X, Wang K, Qiao Y (2019) Frame attention networks for facial expression recognition in videos. In: 2019 IEEE international conference on image processing (ICIP). IEEE, pp 3866–3870
Zhang K, Huang Y, Yong D, Wang L (2017) Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans Image Process 26(9):4193–4203
Jung H, Lee S, Yim J, Park S, Kim J (2015) Joint fine-tuning in deep neural networks for facial expression recognition. In: Proceedings of the IEEE international conference on computer vision, pp 2983–2991
Cai J, Meng Z, Khan AS, Li Z, O’Reilly J, Tong Y (2018) Island loss for learning discriminative features in facial expression recognition. In: 2018 13th IEEE international conference on automatic face and gesture recognition (FG 2018). IEEE, pp 302–309
Sikka K, Sharma G, Bartlett M (2016) Lomo: latent ordinal model for facial analysis in videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5580–5589
Acknowledgements
This research was partially supported by the Center of Innovation Program (Grant No. JPMJCE1314) from the Japan Science and Technology Agency (JST).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Miyoshi, R., Nagata, N. & Hashimoto, M. Enhanced convolutional LSTM with spatial and temporal skip connections and temporal gates for facial expression recognition from video. Neural Comput & Applic 33, 7381–7392 (2021). https://doi.org/10.1007/s00521-020-05557-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-05557-4