
Abstract
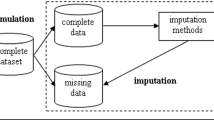
For a long time, missing values are the biggest challenging problem in data mining, machine learning and statistical analysis. In the current scenario, various methods exist to handle the missing values as it’s an important task to discover meaningful information. However, the most frequently used method to handle the missing values in a large dataset is discarding the instances with missing values. In such situation, deletion of instances with missing values causes loss of crucial information, which affects the performance of algorithms. Hence, an intelligent method needs to handle the missing values. In the recent past, the fuzzy and rough set has been widely employed in many applications. In this research work, a Novel Fuzzy C-Means Rough Parameter-based missing value imputation method is proposed with the hybridization of the fuzzy and rough set to handle missing values. The proposed algorithm is capable of handling the situation of uncertainty and vagueness in datasets through rough and fuzzy sets while maintaining vital information. The experimentation has been carried out on three benchmark datasets such as the Dukes’ B colon cancer dataset, the Mice Protein Expression and Yeast datasets to asses the efficacy of the proposed method. It is observed that the proposed method produces improved results than Fuzzy C-Means Centroid-based missing value imputation and Fuzzy C-Means Parameter-based missing value imputation method.










Similar content being viewed by others


References
Rey-del-Castillo P, Cardeñosa J (2012) Fuzzy min-max neural networks for categorical data: application to missing data imputation. Neural Comput Appl 21(6):1349–1362
García-Laencina PJ, Sancho-Gómez JL, Figueiras-Vidal AR (2010) Pattern classification with missing data: a review. Neural Comput Appl 19(2):263–282
Raja PS, Thangavel K (2016) Soft clustering based missing value imputation. In: Annual convention of the Computer Society of India. Springer, Singapore, pp 119–133
Liu ZG, Pan Q, Dezert J, Martin A (2016) Adaptive imputation of missing values for incomplete pattern classification. Pattern Recogn 52:85–95
Amiri M, Jensen R (2016) Missing data imputation using fuzzy-rough methods. Neurocomputing 205:152–164
Tuikkala J, Elo LL, Nevalainen OS, Aittokallio T (2008) Missing value imputation improves clustering and interpretation of gene expression microarray data. BMC Bioinform 9(1):202
Rahman MM, Davis DN (2013) Machine learning-based missing value imputation method for clinical datasets. In: Yang GC, Ao S, Gelman L (eds) IAENG transactions on engineering technologies. Springer, Dordrecht, pp 245–257
Tian J, Yu B, Yu D, Ma S (2014) Missing data analyses: a hybrid multiple imputation algorithm using Gray System Theory and entropy based on clustering. Appl Intell 40(2):376–388
Liao Z, Lu X, Yang T, Wang H (2009) Missing data imputation: a fuzzy K-means clustering algorithm over a sliding window. In: Sixth international conference on fuzzy systems and knowledge discovery, 2009. FSKD’09, vol 3. IEEE, pp 133–137
Luengo J, Sáez JA, Herrera F (2012) Missing data imputation for fuzzy rule-based classification systems. Soft Comput 16(5):863–881
Zhang Y, Kambhampati C, Davis DN, Goode K, Cleland JG (2012) A comparative study of missing value imputation with multiclass classification for clinical heart failure data. In: 2012 9th international conference on fuzzy systems and knowledge discovery (FSKD). IEEE, pp 2840–2844
Stefanowski J, Tsoukias A (2001) Incomplete information tables and rough classification. Comput Intell 17(3):545–566
Pan R, Yang T, Cao J, Lu K, Zhang Z (2015) Missing data imputation by K nearest neighbours based on grey relational structure and mutual information. Appl Intell 43(3):614–632
Luengo J, García S, Herrera F (2012) On the choice of the best imputation methods for missing values considering three groups of classification methods. Knowl Inf Syst 32(1):77–108
Li D, Deogun J, Spaulding W, Shuart B (2004) Towards missing data imputation: a study of fuzzy k-means clustering method. In: International conference on rough sets and current trends in computing. Springer, Berlin, Heidelberg, pp 573–579
Li D, Deogun J, Spaulding W, Shuart B (2005) Dealing with missing data: algorithms based on fuzzy set and rough set theories. In: Peters JF, Skowron A (eds) Transactions on rough sets IV. Springer, Berlin, pp 37–57
Rahman MG, Islam MZ (2016) Missing value imputation using a fuzzy clustering-based EM approach. Knowl Inf Syst 46(2):389–422
Tang J, Zhang G, Wang Y, Wang H, Liu F (2015) A hybrid approach to integrate fuzzy C-means based imputation method with genetic algorithm for missing traffic volume data estimation. Transp Res Part C Emerg Technol 51:29–40
García-Laencina PJ, Sancho-Gómez JL, Figueiras-Vidal AR, Verleysen M (2008) K-nearest neighbours based on mutual information for incomplete data classification. In: ESANN, pp 37–42
Aydilek IB, Arslan A (2013) A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inf Sci 233:25–35
Zhang L, Lu W, Liu X, Pedrycz W, Zhong C (2016) Fuzzy c-means clustering of incomplete data based on probabilistic information granules of missing values. Knowl Based Syst 99:51–70
Luengo J, García S, Herrera F (2010) A study on the use of imputation methods for experimentation with Radial Basis Function Network classifiers handling missing attribute values: the good synergy between RBFNs and EventCovering method. Neural Netw 23(3):406–418
Peters G, Lampart M (2006) A partitive rough clustering algorithm. In: International conference on rough sets and current trends in computing. Springer, Berlin, pp 657–666
Panda S, Sahu S, Jena P, Chattopadhyay S (2012) Comparing fuzzy-C means and K-means clustering techniques: a comprehensive study. In: Wyld D, Zizka J, Nagamalai D (eds) Advances in computer science, engineering & applications. Springer, Berlin, pp 451–460
Zadeh LA (1968) Probability measures of fuzzy events. J Math Anal Appl 23(2):421–427
Dunn JC (1973) A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. Journal of Cybernetics 3(3):32–57 https://doi.org/10.1080/01969727308546046
Hathaway RJ, Bezdek JC (2001) Fuzzy c-means clustering of incomplete data. IEEE Trans Syst Man Cybern Part B (Cybernetics) 31(5):735–744
Pawlak Z (1982) Rough sets. Int J Parallel Program 11(5):341–356
Pawlak Z (1998) Rough set theory and its applications to data analysis. Cybern Syst 29(7):661–688
Bonikowski Z, Bryniarski E, Wybraniec-Skardowska U (1998) Extensions and intentions in the rough set theory. Inf Sci 107(1–4):149–167
Liang J, Shi Z (2004) The information entropy, rough entropy and knowledge granulation in rough set theory. Int J Uncertain Fuzziness Knowl Based Syst 12(01):37–46
Peters G, Lampart M, Weber R (2008) Evolutionary rough k-medoid clustering. In: Peters JF, Skowron A (eds) Transactions on rough sets VIII. Springer, Berlin, pp 289–306
Peters G (2005) Outliers in rough k-means clustering. In: International conference on pattern recognition and machine intelligence. Springer, Berlin, Heidelberg, pp 702–707
Lingras P, Peters G (2011) Rough clustering. Wiley Interdiscip Rev Data Min Knowl Discov 1(1):64–72
Wang Y, Jatkoe T, Zhang Y, Mutch MG, Talantov D, Jiang J, Atkins D (2004) Gene expression profiles and molecular markers to predict recurrence of Dukes’ B colon cancer. J Clin Oncol 22(9):1564–1571
https://archive.ics.uci.edu/ml/datasets/Mice+Protein+Expression
Crespo Turrado C, Sánchez Lasheras F, Calvo-Rollé JL, Piñón-Pazos AJ, de Cos Juez FJ (2015) A new missing data imputation algorithm applied to electrical data loggers. Sensors 15(12):31069–31082
Sim J, Lee JS, Kwon O (2015) Missing values and optimal selection of an imputation method and classification algorithm to improve the accuracy of ubiquitous computing applications. Math Probl Eng 2015:538613
Bertsimas D, Pawlowski C, Zhuo YD (2017) From predictive methods to missing data imputation: an optimization approach. J Mach Learn Res 18(1):7133–7171
Raja PS, Thangavel K (2019) Missing value imputation using unsupervised machine learning techniques. Soft Comput. https://doi.org/10.1007/s00500-019-04199-6
Acknowledgements
Authors would like to thank UGC, New Delhi, for the financial support received under UGC Rajiv Gandhi National Fellowship (F1-17.1/2016-17/RGNF-2015-17-SC-TAM-28324) and UGC-SAP No. F.5-6/2018/DRS-II (SAP-II). The authors extend their sincere thanks to the anonymous referees for their suggestions to improve the paper.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Raja, P.S., Sasirekha, K. & Thangavel, K. A Novel Fuzzy Rough Clustering Parameter-based missing value imputation. Neural Comput & Applic 32, 10033–10050 (2020). https://doi.org/10.1007/s00521-019-04535-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-019-04535-9