
Abstract
This article proposes a reinforcement learning procedure for mobile robot navigation using a latent-like learning schema. Latent learning refers to learning that occurs in the absence of reinforcement signals and is not apparent until reinforcement is introduced. This concept considers that part of a task can be learned before the agent receives any indication of how to perform such a task. In the proposed topological reinforcement learning agent (TRLA), a topological map is used to perform the latent learning. The propagation of the reinforcement signal throughout the topological neighborhoods of the map permits the estimation of a value function which takes in average less trials and with less updatings per trial than six of the main temporal difference reinforcement learning algorithms: Q-learning, SARSA, Q(λ)-learning, SARSA(λ), Dyna-Q and fast Q(λ)-learning. The RL agents were tested in four different environments designed to consider a growing level of complexity in accomplishing navigation tasks. The tests suggested that the TRLA chooses shorter trajectories (in the number of steps) and/or requires less value function updatings in each trial than the other six reinforcement learning (RL) algorithms.












Similar content being viewed by others


Notes
Hierarchical solutions and generalisation methods are other approaches for accelerating RL that are not mentioned in detail in this text.
Neuron and node are interchangeable terms used throughout this text.
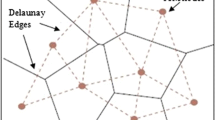
The Delaunay triangulation is the dual of the Voronoi diagram [23]. The Voronoi diagram of a set W = {w 1 , ..., w N } of vectors w i ∈ S is given by N Voronoi cells V i , which is formed by the set of states s ∈ S that are closer to w i than any other w j ∈ S, j≠i. The Delaunay triangulation is the graph obtained if one connects all pairs w i , w j ∈ S whose Voronoi cells share an edge.
In this work the stimulus represents the spatial position of the agent in an environment.
One characteristic of a Delaunay triangulation is that to each triangle can be associated a circle. None of the vectors used as vertices for the triangulation [8] can be found in this circle. If there is a vector in any circle, there is a non-Delaunay edge connected to this point that should be deleted.
A trial is described as a sequence of 4-tuples(s t , a t , r t+1, s t+1 ) generated from an initial random state s 0 until the agent reaches the goal state.
In case of multiple neighbour nodes with the same highest value, one of them is randomly chosen.
The adopted policy is a ε—greedy where the action is selected with probability 1-ε by Eq. 11 and with probability ε by an exploration strategy.
The maximum number of possible actions is eight. They are represented in Fig. 1.
Other exploratory strategies different from the semi-uniform distribution of probability.
References
Arbib MA, Erdi P and Szentagothai J (1998) Neural organization—structure, function and dynamics. Bradford MIT Press, Cambridge, MA
Althoefer K, Krekelberg B, Husmeier D and Seneviratne L (2001) Reinforcement learning in a rule-based navigator for robotic manipulators. Neurocomputing 37:51–70
Atkeson CG, Schaal S (1995) Memory-based neural networks for robot learning. Neurocomputing 9(13):243–269
Blodgett C (1929) The effect of the introduction of reward upon the maze performance of rats. Univ CA Pub Psychol 4:113–134
Dean T, Kaelbling LP, Kirman J and Nicholson A (1995) Planning under time constraints in stochastic domains. Art Intellig 76:35–74
Fritzke B (1994) Growing cell structures—a self-organizing network for unsupervised and supervised learning. Neur Netwks 7(9):1441–1460
Gaussier P, Revel A, Joulain C and Zrehen S (1997) Living in a partially structured environment: how to bypass the limitations of classical reinforcement techniques. Robot Auton Sys 20:225–250
George PL (1991) Automatic mesh generation—application to finite element methods. Wiley, New York
Haykin S (1999) Neural networks—a comprehensive foundation. Prentice Hall, New York
Jockusch J, Ritter H (1999) An instantaneous topological mapping model for correlated stimuli. In: Proceedings of the IJCNN’99, Washington, DC, 10-16 July 1999
Jockusch J (2000). Exploration based on neural networks with applications in manipulator control. Dissertation, University of Bielefeld
Johannet A, Sarda I (1999) Goal-directed behaviours by reinforcement learning. Neurocomputing 28:107–125
Lin L-J (1993) Reinforcement learning for robots using neural networks. Dissertation, Carnegie Mellon University
Kaelbling LP, Littman ML and Moore AW (1996) Reinforcement learning: a survey. J Art Intellig Res 4:237–285
Khatib O (1986) Real-time obstacle avoidance for manipulators and mobile robots. Int J Rob Res 5(1): 90–98
Koenig S, Simmons RG (1996) The effect of representation and knowledge on goal-directed exploration with reinforcement learning algorithms. Mach Learn 22:227–250
Kohonen T (1984) Self-organization and associative memory. Springer, Berlin Heidelberg New York
Kohonen T (2001) Self-organizing maps. Springer, Berlin Heidelberg New York
Kortenkamp D, Bonasso RP and Murphy R (1998) Artificial intelligence and mobile robots. AAAI Press / MIT Press, Cambridge, MA
Leonard JJ, Durrant-White HF (1991) Mobile robot localization by tracking geometric beacons. IEEE Trans Robot Automat 7(3):376–382
Linhares A (1998) State-space search strategies gleaned from animal behavior: a traveling salesman experiment. Biol Cybern 78:167–173
Mahadevan S, Connell J (1992) Automatic programming of behavior-based robots using reinforcement learning. Art Intellig 55:311–365
Martinetz T, Schulten K (1994) Topology representing networks. Neur Netwks 7(3):507–522
Moore AW, Atkeson CG (1993) Prioritized sweeping: reinforcement learning with less data and less time. Mach Learn 13:103–130
Muller RU, Stead M and Pach J (1996) The hippocampus as a cognitive graph. J Gen Physiol 7:663–694
Nolfi S (2002) Power and limits of reactive agents. Neurocomputing 42:119–145
O’Keefe J, Dostrovsky J (1971) The hippocampus as a spatial map. Preliminary evidence from unit activity in the freely moving rat. Expedr Brain Res 34:171–175
O’Keefe J, Nadel L (1978) The hippocampus as a cognitive map. Claredon Press, Oxford, UK
O’Keefe J, Burgess N, Donnett JG, Jeffery KJ and Maguire EA (1998) Place cells, navigational accuracy, and the human hippocampus. Phil Trans Roy Soc Lond Series B-Biol Sci 353(1373):1333–1340
Peng J, Williams RJ (1993) Efficient learning and planning within the Dyna framework. Adapt Behav 1(4):437–454
Peng J, Williams RJ (1996) Incremental multi-step Q-learning. Mach Learn 22:283–290
Rummery GA (1995) Problem solving with reinforcement learning. Dissertation, Cambridge University
Sutton RS (1988) Learning to predict by the methods of temporal differences. Mach Learn 3:9-44
Sutton RS (1991) Dyna, an integrated architecture for learning, planning, and reacting. SIGART Bullet 2:160–163
Sutton RS, Barto A (1998) Introduction to reinforcement learning. MIT Press / Bradford Books, Cambridge, MA
Smith JNM (1974) Food searching behavior of two European thrushes—adaptiveness of search patterns. Behaviour 49:1-61
Tchernichovski O, Benjamini Y and Golani I (1998) The dynamics of long-term exploration in rat. Part I—a phase-plane analysis of the relationship between location and velocity. Biol Cybern 78:423–432
Tchernichovski O, Benjamini Y (1998) The dynamics of long-term exploration in rat. Part II—an analytical model of the kinematic structure of rat exploratory behavior. Biol Cybern 78:433–440
Tesauro G (1995) Temporal differences learning and TD-Gammon. Comm ACM 38:58–68
Thrun S, Moeller K and Linden A (1991) Planning with an adaptive world model. In: Touretzky D, Lippmann R (eds) Advances in neural information processing systems (NIPS) 3, Morgan Kaufmann, San Mateo, CA
Thrun SB (1992) Efficient exploration in reinforcement learning. Technical Report CMU-CS-92–102, Carnegie Mellon University
Tolman EC (1948) Cognitive maps in rats and men. Psychol Rev 55:189–208
Tolman EC, Honzik CH (1930) Insight in rats. Univ CA Pub Psychol 4:215–232
Touzet C (1997) Neural reinforcement learning for behaviour synthesis. Robot Auton Sys 22(3–4):251–281
Trullier O, Wiener S, Berthoz A and Meyer JA (1997) Biologically-based artificial navigation systems: review and prospects. Prog Neurobiol 51(5):483–544
Trullier O, Meyer J-A (2000) Animate navigation using a cognitive graph. Biol Cybern 83:271–285
Voicu H, Schmajuk N (2002) Latent learning, shortcuts and detours: a computational model. Behav Process 59:67–86
Xiao J, Michalewicz Z, Zhang L and Trojanowski K (1997) Adaptative evolutionary planner/navigator for mobile robots. IEEE Trans Evolut Comput 1(1):18–28
Watkins CJCH (1989) Learning from delayed rewards. Dissertation, Cambridge University
Wiering M, Schimidhuber J (1998) Fast online Q(λ). Mach Learn 33:105–115
Wyatt J (1997) Exploration and inference in learning from reinforcement. Dissertation, University of Edinburgh
Zalama E, Gaudiano P and Coronado JL (1995) A real-time, unsupervised neural network for the low-level control of a mobile robot in a nonstationary environment. Neur Netwks 8(1):103–123
Zeller M, Sharma R and Schulten K (1997) Motion planning of a pneumatic robot using a neural network. IEEE Contr Sys Mag 17:89–98
Zelinsky A (1992) A mobile robot exploration algorithm. IEEE Trans Robot Automat 8(6):707–717
Acknowledgements
This work was supported by FAPESP grant #98/12700-5. The authors also thank the reviewers for their helpful comments.
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article
Cite this article
Braga, A.P.S., Araújo, A.F.R. A topological reinforcement learning agent for navigation. Neural Comput & Applic 12, 220–236 (2003). https://doi.org/10.1007/s00521-003-0385-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-003-0385-9