
Abstract
Hierarchical linear models are widely used in many research disciplines and estimation issues for such models are generally well addressed. Design issues are relatively much less discussed for hierarchical linear models but there is an increasing interest as these models grow in popularity. This paper discusses the G-optimality for predicting individual parameters in such models and establishes an equivalence theorem for confirming the G-optimality of an approximate design. Because the criterion is non-differentiable and requires solving multiple nested optimization problems, it is much harder to find and study G-optimal designs analytically. We propose a nature-inspired meta-heuristic algorithm called competitive swarm optimizer (CSO) to generate G-optimal designs for linear mixed models with different means and covariance structures. We further demonstrate that CSO is flexible and generally effective for finding the widely used locally D-optimal designs for nonlinear models with multiple interacting factors and some of the random effects are correlated. Our numerical results for a few examples suggest that G and D-optimal designs may be equivalent and we establish that D and G-optimal designs for hierarchical linear models are equivalent when the models have only a random intercept only. The challenging mathematical question of whether their equivalence applies more generally to other hierarchical models remains elusive.
Similar content being viewed by others

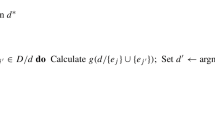
Avoid common mistakes on your manuscript.
1 Introduction
Hierarchical models are widely used to analyze data in various disciplines, such as in psychology, medicine, manufacturing industry and education. Such models are especially appealing for analyzing longitudinal analysis because they allow for the presence of missing data, time-varying or invariant covariates, and subjects measured at different time points. In educational research, hierarchical models are commonly used to evaluate the effectiveness of teaching methods using data from students nested within classrooms and classrooms are nested within schools that use different teaching methods. The distinguishing feature of these models is that they account for both individual-level and population-level effects. In the literature across disciplines, hierarchical models are variously referred to as multilevel models, nested data models, mixed models, random coefficient, random-effects models or random parameter models. In our work, we make no distinction among them and refer to them as statistical models with parameters that vary at one or more levels.
When the experimental settings are under the control of the investigator, design issues arise and they must be carefully addressed for maximal precision in the statistical inference at a minimal cost. The basic questions to answer are given a statistical model defined on a compact design space \({\mathcal {X}}\), an optimality criterion and a fixed amount of resources to take N observations for the study, what are the optimal number of points, where these points are and how many replicates to take at each of these points. We denote these quantities by k, \(x_1,\ldots ,x_k\) and \(n_1,\ldots ,n_k\), respectively where \(n_1+\cdots +n_k=N\). Optimal exact designs are challenging to find and study because there are no theoretical tools for finding them in general and in addition to depending on the design criterion and the model, the optimal exact design also depends on the value of N.
An alternative option is to formulate the design problem to find an optimal approximate design, where we determine k, \(x_1,\ldots ,x_k\) as before, and now the optimal weights defined by \(w_i=n_i/N\in [0,1]\) with \(w_1+\cdots +w_k=1\). In practice, there are implemented by taking rounding each \(Nw_j\) to the nearest integer \([Nw_j]\) and taking \([Nw_j]\) observations at \(x_j,j=1\ldots ,k,\) subject to \([Nw_1]+\cdots +[Nw_k]=N\). Approximate designs were proposed in Kiefer (1959) and they are appealing because when the criterion is a concave functional, there is a theoretical tool called an equivalence theorem for confirming the optimality of an approximate design among all designs on the given design space \({\mathcal {X}}\). There are algorithms with proof of convergence for searching some types of optimal designs and there are also tools to assess the proximity of an approximate design from the optimum without knowing the latter. For these reasons, we focus on approximate designs in the rest of the paper.
A primary interest of our paper is to find G-optimal designs for hierarchical linear models, with G standing for global. These designs are best for estimating the overall response surface with minimal variance across the design space \({\mathcal {X}}\) and so protect against the worst-case scenario. This is unlike the much simpler situation where there is interest in finding an optimal design for estimating the predicted response at a single point. G-optimality is a minimax-type of design criterion, it is non-differentiable and requires at least solving two nested layers of optimization problems over different search spaces. Consequently, even for fixed-effects models, G-optimal designs are among the most difficult to study mathematically. Compounding the optimization problem is that current algorithms for searching optimal designs cannot find G-optimal designs effectively, let alone one with proof of convergence.
The main aims of this paper are to find G-optimal designs for hierarchical linear models, propose a nature-inspired meta-heuristic algorithm to find them and develop an equivalence theorem to confirm the G-optimality of an approximate design for hierarchical linear models. We demonstrate the flexibility and effectiveness of the algorithm for finding G-optimal designs when the mean response is modeled by fractional polynomials and D-optimal designs for hierarchical nonlinear models with multiple interacting factors with possibly correlated random effects. We also establish that D and G-optimal designs for hierarchical linear models are equivalent when the models have only a random intercept only and pose the challenging mathematical question of whether their equivalence applies more generally to other hierarchical models.
The rest of the paper is organized as follows. Section 2 provides the background of hierarchical linear models and recent literature on constructing D-optimal designs for such models. Section 3 establishes an equivalence theorem for G-optimality and Sect. 4 presents G-optimal designs for various types of hierarchical models for relatively simple models. To find G-optimal designs for more complicated models, Sect. 5 introduces a nature-inspired meta-heuristic algorithm called competitive swarm optimizer (CSO) to find G-optimal designs for more complicated hierarchical linear models, such as, when the mean function is a fractional polynomial and the random effects may be correlated. We further show CSO can find locally D-optimal designs for estimating model parameters in a Poisson hierarchical model with multiple factors defined on a user-specified design space \({\mathcal {X}}\) and some random effects are correlated. Section 6 concludes with a discussion of possible equivalence between D and G-optimal designs for linear mixed models.
2 Preliminaries and model specification
This section gives the background, a brief literature review on constructing optimal designs for hierarchical linear models before we describe our statistical models.
2.1 Equivalence theorem
Constructing optimal designs for a given model under a specified criterion is challenging if the model is complex, and more so if the criterion is complicated. An analytical approach for finding optimal designs is limiting and is possible only for simple models with a couple of parameters, see examples in design monographs, such as, Fedorov (1972) and Berger and Wong (2009). A common practice is to find an optimal design under a set of restrictive conditions and hope that the design remains optimal under a broader setup. For instance, one may find the best two-point optimal design for the simple logistic model. Is the same design still optimal among all three-point designs? Equivalence theorem provides an answer, and more generally, is able to confirm whether the design is optimal among all designs of interest.
Specifically, suppose the given design space \({\mathcal {X}}\) is compact and the optimality criterion is formulated as a concave (or convex) function of approximate designs or, equivalently, as a function of the normalized Fisher Information matrix \({\varvec{M}}(\xi )\). The elements of this matrix are the expectation of the negative of the second derivatives of the log-likelihood function with respect to the parameters. As an example, suppose we have a standard linear regression model with the mean response
where \({\varvec{y}}\) is a univariate function and \({\varvec{\beta }}\) is the \(p\times 1\) vector of unknown parameters. The expectation is over the model errors assumed to have independent normal variates with zero means and constant variance. A direct calculation shows the Fisher Information matrix is proportional to
A typical design goal is find a design so that the estimated \({\varvec{ \beta }}\) has a minimal covariance matrix. The most common design criterion is D-optimality and a D-optimal design satisfies
over all approximate designs on \({\mathcal {X}}\). Here \(|{\varvec{ M}}|\) is the determinant of \({\varvec{ M}}\) and \(\varXi \) is the set of all approximate designs on \({\mathcal {X}}\). After the D-optimal design \(\xi _D\) is found, the worth of another design \(\xi \) in terms of D-optimality is measured by its D-efficiency defined by
Clearly, the above ratio is between 0 and 1 and if it is equal to one half, the interpretation is that the design \(\xi \) has to be replicated twice to do as well as the D-optimal design \(\xi _D\). If \(\xi _D\) in the denominator is replaced by another design \(\xi ^*\), the ratio is the D-efficiency of \(\xi \) relative to \(\xi ^*\). The efficiency or relative efficiency of a design under another criterion is similarly defined.
The function \(ln~|{\varvec{ M}}|\) is concave on \(\varXi \) and using a standard convex analysis argument (Fedorov 1972; Pazman 1986), it can be shown that the equivalence theorem for D-optimality is as follows: \(\xi _D\) is D-optimal if and only if for all \(x\in {\mathcal {X}}\),
The function on the left-hand side of the inequality is frequently called the sensitivity function of the design. As an example, if \({\varvec{f}}(x)^T=(1,x,x^2)\), the design space is \({\mathcal {X}}=[1,3]\) and we want to estimate all the three parameters as accurately as possible. A direct calculation shows the D-optimal design \(\xi _D\) takes equal proportion of observations at \(x=1,x=2\) and \(x=3\) and one can directly verify its sensitivity function satisfies (1).
Each concave functional has a directional derivative which is used to derive its own unique equivalence theorem; see details in design monographs, such as Fedorov (1972) and Berger and Wong (2005). When \({\mathcal {X}}\) is an interval or a two-dimensional space, the optimality of a design can be readily checked by plotting the sensitivity function on the left-hand side of the above inequality across the design space and visually ascertain whether the conditions in the equivalence theorem are satisfied. Equivalence theorems are frequently used to confirm the optimality of an approximate design, and more importantly, to ascertain the efficiency of any approximate design. An example is Wong and Cook (1993), where they proposed an algorithm to find G-optimal designs for fixed-effects linear models and assess the quality of the generated design using an equivalence theorem.
2.2 Brief review of optimal designs
There is a lot of work on finding optimal designs for various models in different fields and most concerned finding D-optimal designs for linear models; see references in Berger and Wong (2005) and those cited below. For nonlinear models, the information matrix depends on the unknown parameters and nominal values are required to replace them in the information matrix before the criterion is optimized. Because the resulting designs depend on the nominal values, they are called locally D-optimal designs and are the simplest to construct for nonlinear models and commonly used in practice when a single best guess for the parameters is available. However, where there are conflicting opinions from experts or prior information from previous studies, locally optimal designs become problematic to implement.
Two common design approaches for such a scenario are to adopt a Bayesian paradigm or a minimax approach. The latter design strategy was used by Berger et al. (2000) where they searched for the best D-optimal design over a plausible set of values for the nominal values. The minimax D-optimal design from Berger et al. (2000) minimizes the maximum inefficiencies that arise from misspecified values in the plausible set; variations of the theme are possible; see Chen et al. (2018). An appeal of this approach is that practitioners are likely able to provide a set of plausible nominal values for the model parameters than having to provide a prior distribution to implement the Bayesian optimal design. A disadvantage of the minimax approach is that minimax optimal designs are both theoretically and numerically more challenging to find than Bayesian optimal designs.
Random-effects models have more complicated equivalence theorems and a limited number of them are available. For instance, Fedorov and Hackl (1972) derived an equivalence theorem to confirm the D-optimality of an approximate design for a random coefficient regression model and Entholzner et al. (2005) obtained optimal or efficient designs for mixed models. Schmelter (2007b) showed that the search for an optimal design for hierarchical linear models could be restricted to the class of group-wise identical individual designs and Schmelter (2007a) noted that optimal designs found in the class of single-group designs remain optimal in a larger class having more group designs. Entholzner et al. (2005), Schmelter (2007a) and Schmelter (2007b) investigated optimal designs under random intercept models, random slope models and random coefficient cubic regression models, respectively. Debusho and Haines (2008) and Debusho and Haines (2011) constructed V- and D-optimal population designs for linear and quadratic regression models with a random intercept term. More recently, Prus and Schwabe (2016b) constructed optimal designs for predicting individual parameters in hierarchical models and called them D-optimal designs. They also extended their work to find interpolation and extrapolation optimal designs for random coefficient regression models in Prus and Schwabe (2016a). Further, Prus (2019) proposed a design criterion called G-optimality for predicting the response surface in hierarchical models and noted technical difficulties in finding such an optimal design, analytically or numerically, for more complicated models.
2.3 Statistical models
Throughout, we denote the jth response from the ith subject by \(y_{ij}\). The hierarchical model is defined on a user-defined compact design space \({\mathcal {X}}\) and given by
where the jth observation from individual i is taken at the experimental setting \(x_{ij}\in {\mathcal {X}}\), n is the number of individuals, \(m_i\) is the number of observations from individual i, \({{\varvec{f}}}= (f_1, \ldots , f_p)^T\) is the vector of known regression functions, and \({\varvec{\beta }}_i = (\beta _{i1}, \ldots , \beta _{ip})^T\) is the individual parameter vector specifying the individual response. The observational errors \(\varepsilon _{ij}\) are assumed to be centred with zero mean and homoscedastic and uncorrelated with common variance var\((\varepsilon _{ij})=\sigma ^2\). We assume that E(\({\varvec{\beta }}_i\))=\({\varvec{\beta }}=(\beta _1, \ldots , \beta _p)^T\) and Cov(\({\varvec{\beta }}_i\))=\(\sigma ^2{\varvec{D}}\) (\(i=1,\ldots ,n\)), where \({\varvec{D}}\) is known, and all \({\varvec{\beta }}_i\)’s are uncorrelated with all \(\varepsilon _{ij}\)’s. We note that the \(p\times p\) matrix \({\varvec{D}}\) can be singular, which happens when some of the individual parameters are non-random.
In practice, experiments are usually conducted with identical regimes for all individuals, i.e., all individuals i have the same number \(m_i=m\) of observations at the same values \(x_{ij}=x_j\) of the experimental settings. Such designs are popular because they are simple to implement and analyze (Prus and Schwabe 2016b). In what is to follow, we assume such a setting.
Let \({\varvec{Y}}_i = ({\varvec{Y}}_{i1}, \ldots , {\varvec{Y}}_{im})^T\) be the vector of observations from individual i, let \(\bar{{\varvec{Y}}} = \frac{1}{n}\sum _i^n {\varvec{Y}}_i\) be the average response across all individuals and let \({\varvec{F}} = ({{\varvec{f}}}(x_1), \ldots , {{\varvec{f}}}(x_m))^T\) be the individual \(m\times p\) common design matrix for all individuals. Prus and Schwabe (2016b) showed that the best linear unbiased estimator \(\hat{{\varvec{\beta }}}\) of the population parameter \({\varvec{\beta }}\) is
and the best linear unbiased predictor \(\hat{{\varvec{\beta }}}_i\) of the individual parameter \({\varvec{\beta }}_i\) is a weighted average of the individualized estimate \(\hat{{\varvec{\beta }}}_{i;ind } = ({\varvec{F}}^T{\varvec{F}})^{-1}{\varvec{F}}^T{\varvec{Y}}_i\) based on the observations of subject i only and the estimator \(\hat{{\varvec{\beta }}}\) for the population parameter. Specifically, we have
The quality of the prediction in (4) for \({\varvec{\theta }}=({\varvec{\beta }}^T_1, \ldots , {\varvec{\beta }}^T_n)^T\) may be measured by the mean squared error matrix of \(\hat{{\varvec{\theta }}}=(\hat{{\varvec{\beta }}}^T_1, \ldots , \hat{{\varvec{\beta }}}^T_n)^T\):
Here \({\varvec{I}}_n\) is the \(n\times n\) identity matrix, \({\varvec{J}}_n\) is the \(n\times n\) matrix with all entries equal to 1 and “\(\otimes \)” denotes the Kronecker product of matrices.
3 An equivalence theorem for G-optimality
3.1 G-optimality for predicting individual parameters
The G-optimality criterion was proposed for prediction of the individual parameters in Prus (2019) and a G-optimal design minimizes the maximal prediction mean squared error over the experimental region. The standardized information matrix of an approximate design \(\xi \) for the above model without individual effects is
The matrix \({{\varvec{M}}}(\xi )\) stands for the information obtained per observation and \(m{{\varvec{M}}}(\xi )\) corresponds to the information contributed by the observations at the experimental settings per individual. In this paper, we are only concerned with approximate designs on \({\mathcal {X}}\) with non-singular information matrices and denote this set by \(\varXi \). If \(\xi \in \varXi \), its MSE-matrix in (5) is
where \({\varvec{\varDelta }}=m{\varvec{D}}\). When \({\varvec{D}}\) is non-singular, this expression simplifies to
For predicting purposes, Prus (2019) used model (2) and proposed the G-criterion as the maximal sum of the expected squared differences of the predicted and real response across all individuals with respect to all possible observational settings:
This criterion can be rewritten as
where
In the appendix, we show that the criterion is a convex function on \(\varXi \) and a design that minimizes the G-criterion \(\psi ^\mathrm{pred}_G(\xi )\) over all designs \(\xi \in \varXi \) is G-optimal. The next two analytical results give a lower bound for the function \(\psi ^\mathrm{pred}_G(\xi )\) for any design and an equivalence theorem to confirm the optimality of a design. The technical arguments are deferred to the appendix.
Theorem 1
For any design \(\xi \in \varXi \), we have
An implication of the above theorem is that a design \(\xi ^*\) is G-optimal for model (2) if it satisfies (10) with equality at the support points. In what is to follow, we establish below an equivalence theorem for G-optimality to characterize G-optimal designs.
Theorem 2
For model (2), let \(\xi \in \varXi \), let \({\varvec{\varDelta }}=m{\varvec{D}}\), let \(N(\xi ,{\varvec{\varDelta }})={\varvec{\varDelta }}-{\varvec{\varDelta }}({{\varvec{M}}}^{-1}(\xi )+{\varvec{\varDelta }})^{-1}{\varvec{\varDelta }}\), and let
where \(\mu \) is a probability measure on \({\mathcal {A}}(\xi )\) defined by
with \({{\varvec{M}}}_{{\mathcal {A}}}(\mu )=\int _{{\mathcal {A}}(\xi )}{{\varvec{f}}}(x){{\varvec{f}}}^T(x)d \mu .\)
A design \(\xi ^*\) on \({\mathcal {X}}\) is G-optimal if and only if there exists a probability measure \(\mu ^*\) on \({\mathcal {A}}(\xi ^*)\) such that for all \(x\in {\mathcal {X}}\)
Similar to (1), the function on the left hand side of the inequality is the sensitivity function of the design \(\xi ^*\). The equivalence theorem is more complex than the one for D-optimality because the G-optimality criterion is not differentiable. The theorem has a form similar to those for confirming G-optimal designs for heteroscedastic linear models in Wong and Cook (1993).
In Theorem 2, the probability measure \(\mu ^*\) exists only if the design under investigation is G-optimal, whereupon the inequality becomes an equality at all design points of the optimal design \(\xi ^*\). This follows because if there is a support point x of \(\xi ^*\) such that the inequality in Theorem 2 is strict, then integrating both sides with respect to \(\xi ^*\), we have
implying \(0 < 0\), which is impossible. It follows that all support points of \(\xi ^*\) are roots of the sensitivity function. In the next section, we show how this information is used to generate the G-optimal design.
4 G-optimal designs
We now provide examples of G-optimal designs for several types of linear mixed models and use Theorem 2 to confirm their optimality. Here and in the rest of the paper, to fix ideas, we assume that \(n = 10, m = 5\) but other values for n and m can be similarly used. The first example is relatively simple and a formula for the G-optimal is available. When the model is slightly generalized to two additive factors with uncorrelated random factors and no intercept term, an analytical description for the G-optimal design for two-parameter models is no longer possible and numerical methods must be used. The implication is that G-optimal designs are difficult to find and they have to be found numerically. This motivates us to use competitive swarm optimizer (CSO) to find G-optimal designs and note that some of the results in this section are found by CSO.
4.1 Examples
4.1.1 G-optimal design for the simple linear model with a random slope
Suppose we wish to find the G-optimal design for model (2) with \(p = 2\) and \({{\varvec{f}}}(x) = (1, x)^T\) on the experimental region \({\mathcal {X}}= [0,1]\). The model is
and we assume that the slope parameter \(\beta _{i2}\) is random with mean \(\beta _2\) and the dispersion matrix is diagonal and equal to \(\sigma ^2{\varvec{D}} = diag~(0, \mathrm{d}\sigma ^2)\).
Let \(\delta =md\) and let \(\xi ^*_w\) be the two-point design supported at 0 and 1 with weight at 1 equal to \(w^*\). A direct application of Theorem 2 shows that the G-optimal design for model (12) has
and for the design \(\xi _w^*\), (9) becomes
This maximum of this function is attained at \(x=0\) and \(x=1\) and so \( {\mathcal {A}}(\xi _w^*)=\left\{ 0,1\right\} .\) Let \(\mu ^*\) be the two-point probability measure defined on \( {\mathcal {A}}(\xi _w^*)\) supported at 0 and 1 and its weight at 1 is
The sensitivity function of the design \(\xi _w^*\) in terms of \(w_{\mu }\) and \(w^*\) is
with a maximum value of \({(1-w_{\mu })}/{(w^* - 1)^2}\) at \(x=0\) and \(x=1\). This value can be shown to equal to
and so by Theorem 2, the design \(\xi _w^*\) is G-optimal.
4.1.2 G-optimal designs for a two additive factor model without an intercept
Regression models with no intercept are quite common and they either arise naturally or from constraints imposed on the variables, see for example, Huang et al. (1995). For such a model with two additive random factors, we have
where \((x_{1j}, x_{2j})\in {\mathcal {X}}=[0, 1]^2\). The dispersion matrix of \({\varvec{\beta }}_i=(\beta _{i1},\beta _{i2})^T\) is diagonal and equal to \(\sigma ^2{\varvec{D}} = diag~(d_1\sigma ^2, d_2\sigma ^2)\). To find G-optimal designs, first consider designs of the form
and let \(\mu _w\) be the associated probability measure on \(A(\xi _w)\) defined by
The table below shows the optimal weights \(\xi ^*_w\) and the weights of the measure \(\mu ^*_w\) for model (16) for selected values of \(d_1\) and \( d_2.\) These designs have been verified to be numerically G-optimal by Theorem 2.
\(d_1\) | \(d_2\) | \(w_1^*\) | \(w_2^*\) | \(w_3^*\) | \(w_{\mu 1}^*\) | \(w_{\mu 2}^*\) | \( w_{\mu 3}^*\) |
|---|---|---|---|---|---|---|---|
1 | 1 | 0.2788 | 0.2788 | 0.4423 | 0.3272 | 0.3272 | 0.3456 |
5 | 0.2312 | 0.3674 | 0.4014 | 0.3268 | 0.3355 | 0.3377 | |
10 | 0.2251 | 0.3789 | 0.3960 | 0.3269 | 0.3361 | 0.3371 | |
5 | 1 | 0.3674 | 0.2312 | 0.4014 | 0.3355 | 0.3268 | 0.3377 |
5 | 0.3215 | 0.3215 | 0.3569 | 0.3331 | 0.3331 | 0.3337 | |
10 | 0.3156 | 0.3333 | 0.3511 | 0.3331 | 0.3333 | 0.3336 | |
10 | 1 | 0.3789 | 0.2251 | 0.3960 | 0.3361 | 0.3269 | 0.3371 |
5 | 0.3333 | 0.3156 | 0.3511 | 0.3333 | 0.3331 | 0.3336 | |
10 | 0.3274 | 0.3274 | 0.3452 | 0.3333 | 0.3333 | 0.3334 |
4.1.3 G-optimal designs for quadratic and fractional polynomial mixed models
We show here that even for a relatively simple mixed model, an analytic description of the G-optimal design can be problematic. We consider two linear mixed models with independent errors \(\epsilon _{ij}\) having zero means and common variance. These two models are
and
Model (17) is quadratic and model (18) is an example of a fractional polynomial, which is increasingly used in the biomedical sciences to model a univariate continuous response. Fractional polynomial models were proposed by Royston and Altman (1994) who showed that they are more effective for modeling a continuous outcome than using polynomials (Royston et al. 1999; Royston and Sauerbrei 2008). We recall a fractional polynomial (FP) is given by \(\phi _m(x;\mathbf {\alpha },{\mathbf {p}})=\alpha _0+\sum _{j=1}^t \alpha _j H_j(x)\), where \(\alpha _j\) are the real-valued coefficients and \(H_j(x)\) are defined sequentially, \(H_1(x)=x^{(p_1)}\),
The powers are given by the Box-Tidwell transformation with \(x^{(p_j)}=x^{p_j}\) if \(p_j\ne 0\), otherwise \(x^{(0)}=\ln [x]\) and for practical applications, ‘powers’ in a FP are selected from the set \({\mathcal {P}}=\{-2,-1,-0.5,0,0.5,1,2, \ldots ,\max (3,t)\}\) (Royston and Altman 1994). Many software statistical packages now provide an option for fitting FP models, suggesting that FP models are gaining recognition as a modelling tool in statistics. Interestingly, optimal designs for FP models have never been reported in the literature.
There are no closed-form descriptions for the optimal designs for these two relatively simple models with random effects. A practical way is to find them using an algorithm. There are many traditional algorithms for generating many types of optimal designs and our experience is that many of them do not work well in such a setting where the criterion is not differentiable and the optimization problem has two levels. To this end, we use a meta-heuristic algorithm called competitive swarm optimizer to find the optimal designs.
5 Competitive swarm optimizer
An analytical approach is generally unable to determine a G-optimal design and we need an effective algorithm to generate a G-optimal design, or search for a design with sufficiently high G-efficiency for practical applications. The last few G-optimal designs in Sect. 4 were found by an algorithm that we now describe.
Nature-inspired meta-heuristic algorithms are commonly used in engineering and computer science to tackle hard-to-solve optimization problems (Yang 2010). Examples are particle swarm optimization (PSO), differential evolutionary (DE), cuckoo search (CS) and imperialist competitive algorithm (ICA). Their main appeal is that they are general purpose optimization tools, they tend to be assumptions-free, easy to implement and use and frequently able to find high-quality solutions quickly. Their meteoric rise in popularity is well documented in Whitacre (2011a, 2011b) with reasons. Recently, Chen et al. (2018), Phoa et al. (2016), Kim and Wong (2018), Masoudi et al. (2019), and Storn and Price (1997) used meta-heuristic algorithms to tackle different types of optimal design problems. For example, Chen et al. (2018) applied a version of PSO to find standardized maximin optimal designs for several enzyme-kinetic inhibition models by solving multilevel nested optimization problems over different types of search spaces, and Kim and Wong (2018) likewise applied PSO and solved an adaptive clinical trial design problem by solving a complex discrete optimization problem by determining the optimal choice of ten integers with multiple constraints.
Evolutionary algorithms are continuously evolving and nature-inspired meta-heuristic algorithms are a major component of evolutionary algorithms. Competitive swarm optimizer (CSO) is popular because many simulation results in the literature show that it either outperforms or is competitive with several state-of-the-art evolutionary algorithms. This conclusion was arrived at after comparing CSO’s performance with several state-of-the-art evolutionary algorithms using a variety of benchmark functions with dimensions up to 5000 (Cheng and Jin 2014; Zhou et al. 2016; Sun et al. 2018; Mohapatra et al. 2017; Zhang et al. 2016). They showed that CSO was frequently not only the winner but also required significantly less run time. CSO has also been successfully applied to solve many different types of complex optimization problems; see, for example, Gu et al. (2018), Kumarappan and Arulraj (2016) and Xiong and Shi (2018).
CSO was initially proposed by Cheng and Jin (2014) to tackle the premature convergence issue met by many evolutionary algorithms. CSO first generates a swarm of n particles at positions \({\mathbf {x}}_1, \ldots , {\mathbf {x}}_n\) with random velocities \({\mathbf {v}}_1, \ldots , {\mathbf {v}}_n\) in \(\varvec{\varOmega }\). In each iteration, we randomly divide them into \(\left\lfloor \frac{n}{2} \right\rfloor \) pairs and compare their objective function values. If we have a minimization problem, at iteration t, we compare each pair of particles \({\mathbf {x}}^t_i\) and \({\mathbf {x}}^t_j\) and identify \({\mathbf {x}}^t_i\) as the winner and \({\mathbf {x}}^t_j\) as the loser if the objective function has a smaller value at \({\mathbf {x}}^t_i\) than at \({\mathbf {x}}^t_j\). Winner retains status quo and the loser learns from the winner. The two defining equations for CSO are
where \({\mathbf {R}}_1, {\mathbf {R}}_2, {\mathbf {R}}_3\) are all random vectors whose elements are drawn from U(0, 1); operation \(\otimes \) also represents element-wise multiplication; vector \(\bar{{\mathbf {x}}}^t\) is simply the swarm center at iteration t; social factor \(\gamma \) controls the influence of the neighboring particles to the loser and a large value is helpful for enhancing the swarm diversity (but possibly impacts convergence rate). This process iterates until some stopping criteria are met. Algorithm 1 displays a pseudo code of CSO.

The tuning parameters we used in the CSO algorithm for finding the optimal designs are similar to those suggested by Cheng and Jin (2014). For example, because the optimization problems we have dimensions fewer than 100, we set \(\gamma = 0\) and used 128 particles in the search. This is because the examples to follow have about 100 variables or fewer to optimize. The maximum number of iterations for each search was set to be 350. For our examples, the algorithm typically converges in 200 or fewer iterations or less than 1 second of CPU time. The hardware we used is a Windows PC with 3.20GHz Intel i7-8700 CPU, 32GB DDR4 2666MHz memory and 512G SSD storage. Here convergence means that successive values of the objective function do not differ by less than \(10^{-6}\) in absolute value. On average, we observe that each search usually converged in 200 or fewer iterations.
5.1 Application of CSO to find G-optimal designs
To search for a G-optimal design, we set up a two-layer optimization structure for min-max the objective function. The inner optimization step is a low-dimensional maximization problem represented in formula (9) and the outer loop is to minimize formula (8), which, in our cases, is a multi-dimensional function with less than 100, or more specifically, around 10–20 variables to optimize. Accordingly, we set \(\gamma =0\), 32 particles, 128 iterations for the inner optimization and \(\gamma = 0\), 128 particles and 200 iterations for the outer optimization task. During the search, the target matrix may sometimes become singular or close to being singular and affect the floating-point calculation accuracy. We found adding a diagonal matrix with very small positive diagonal elements to the original matrix can make inverting an ill-conditioned matrix more stable. In our work, we set \({\varvec{ M}}^*= {\varvec{M}} + 0.0000001 \times {\mathbf {I}}.\)
After finding a design \(\xi ^*\), we determine its answering set \({\mathcal {A}}(\xi ^*)\) and the probability measure \(\mu ^*\) that meet the conditions in the equivalence theorem. To efficiently find all x’s that maximize \(\phi (x, \xi ^*)\), we suggest to split the design space into two or more subspaces and then run CSO on each subspace to search for all x’s that maximize \(\phi (x, \xi ^*)\). For instance, if the design space \({\mathcal {X}} = [0, 1]\), we may split the search space into [0, 0.5] and [0.5, 1]. There are no firm rules for the number of subspaces and our suggestion is to first try with two subspaces, then aggregate all such points to obtain \({\mathcal {A}}(\xi ^*)\). We then sequentially increase the number of subspaces and stop the process when splitting the design space into more subspace does not enlarge the size of \({\mathcal {A}}(\xi ^*)\).
To find the probability measure \(\mu ^*\) that meets the conditions in the equivalence theorem, we proceed iteratively as follows. For each generated design \(\xi \) from the algorithm, we first determine elements \(a_1,a_2,\ldots ,a_k\) in \(A(\xi )\) and find a candidate \(\mu \) for \(\mu ^*\) among probability measures supported at the k points. There are 2k variables in the pairs \((a_i,w_i)\), where \(w_i\) is the weight of \(\mu \) at \(a_i, i=1, \ldots , k\). Since the support points of \(\mu ^*\) must be roots of the sensitivity function when \(\xi \) is optimal, one may apply CSO to minimize the following function with respect to the variable weights \(w_i\):
We note that in (19), for each design \(\xi \), we have to first find x that maximizes \(\phi _G(x,\xi )\). This can be done by calling CSO again to tackle this optimization problem. However, after a lot of experiments, we find that only minimizing the second term in (19) frequently suffices to determine \(\mu \), i.e. we suggest given a design, first find \(\mu \) by simply minimizing
before solving the more complicated problem (19) to determine \(\mu ^*\). We ran CSO with \(\phi =0.05\), 64 particles for 1200 iterations. We stop the algorithm if and when the objective value attains a small user pre-specified value of, say, \(10^{-5}\).
The CSO-generated designs for the next few examples were found by optimizing (20) and we confirm their G-optimality via the equivalence theorem. On average, the CPU time required to solve (20) was about 5 seconds or less for our examples and we expect a longer time is required to solve (19). This suggests that if we want to find G-optimal designs for more complicated problems, an efficient strategy to find G-optimal designs is to first solve the simpler optimization problem in (20) before solving (19).
The next few tables list CSO-generated designs for various linear mixed models with different assumptions on the covariance structure of the random effects and their G-optimality criterion values. We display the sensitivity plot of each CSO-generated design across the design space and it confirms the G-optimality of the CSO-generated design. All parameters for the design problems, such as the design space, the elements in the covariance matrix \({\varvec{D}}\), n and m are chosen randomly for illustrative purposes. The error variance \(\sigma ^2\) is a nuisance parameter and does not affect the optimization process, so we set \(\sigma ^2=1\) in all examples.




5.2 CSO-generated locally D-optimal designs for Poisson models with mixed factors
This subsection demonstrates the utility and flexibility of CSO to find other types of optimal designs, such as locally D-optimal designs for estimating parameters in a Poisson regression model with possibly interacting factors and some factors are random.
Poisson models are commonly used to study count data in a regression setting even though they have restrictive assumptions, such as, requiring the mean and variance of the response to be equal. Negative binomial regression models extend Poisson models when the variance is larger or smaller than the mean response. These models are frequently used in clinical trials when the primary outcome is a count variable, such as the number of falls by an elderly patient, or number of CT scans received in the last three months or modeling the numbers of insurance claims and results. Walters (2007a, 2007b) used a negative binomial regression model to account for the number of aggressive incident reports in the following 12 months after subjects were put in an institutional correction center. Like all meta-heuristic algorithms, they can be modified to search for an optimum more effectively for specific problems. An enhanced version of CSO algorithm is available to find various types of optimal designs for the negative binomial regression models (Zhang et al. 2020).
Locally D-optimal designs for two-factor mixed Poisson models with an intercept term have been reported for two models, one with and the other without an interaction term. By using the quasi-information matrix defined in Niaparast and Schwabe (2013) and assuming that the random effects are uncorrelated, i.e., the covariance matrix is diagonal, Naderi et al. (2018) provided theoretical details for finding minimally supported D-optimal designs, including an equivalence theorem to confirm the D-optimality of an approximate design. We recall that minimally supported designs have the number of support points equal to the number of parameters in the mean function and so cannot be used to perform a lack of fit test to check model adequacy. Thus their approach can be restrictive in practice and it is also not clear whether their numerical procedure works for finding D-optimal designs when the model has more interacting factors with random effects or under another design criterion.
We applied CSO and found the same locally D-optimal designs in Tables 1, 2 and 3 of Naderi et al. (2018) for different models with various numbers of uncorrelated random coefficients. The next two sets of results in Tables 5 and 6 show that CSO-generated designs for a model with two interacting factors when the random effects are uncorrelated or correlated. The accompanying plots in Figs. 5 and 6 display their sensitivity plots and they confirm the CSO-generated designs are locally D-optimal. Interestingly, the results show different design spaces can produce D-optimal designs that are not minimally supported.
The usefulness of the CSO algorithm can also be seen when we applied it find D-optimal designs for mixed models when some random coefficients are correlated and able to find D-optimal designs that may not be minimally supported. We demonstrate using two Poisson models,one with four and the other with five mixed factors and both have some interaction terms. This is helpful because the bulk of theoretical optimal designs in the literature for nonlinear models have only a couple of additive factors and numerical results for models with interaction terms are also very limited.
For the model with four factors, we assume that
the covariance matrix is \({\varvec{D}} = diag(0.5, 2.2, 1, 1, 0, 0, 1.3, 0.7)\) and the coefficients in the linear predictor function is \(\varvec{\beta } = (1, 2, 3, -3, -1, -2, 1, 3)\). The 12-point CSO-generated design \(\xi ^4\) is shown below and criterion value is \(-4.300\). Here and elsewhere, the last row in the design for a multi-factor model shows the mass of the design point above it.

The sensitivity function of the CSO-generated design under the D-optimality criterion for the two-factor Poisson model with an interaction term and uncorrelated random effects shown in Table 5

The sensitivity function of the CSO-generated design under the D-optimality criterion for a two-factor Poisson model with an interaction term and correlated random effects shown in Table 6
The second example concerns a Poisson regression model with five factors (\(x_1,\ldots , x_5\)) and three interaction terms (\(x_1x_2, x_1x_3, x_3x_5\)) defined on \([-1, 1]^5\). As an illustrative example, suppose the covariance matrix is
and the nominal coefficients in the linear predictor function \(\varvec{\beta } = (1.0, 2.0, 3.0, -3.0, -1.0, -2.0, 0.2, 0.5, -0.5)\). The criterion value of the 12-point CSO-generated is \(-13.640\) and the design \(\xi ^{5}\) is shown below. This is a more complicated model and as expected, CSO, like other meta-heuristic algorithms, can also encounter problems when the optimization problem becomes more complex. Convergence and numerical stability issues can arise and repeated reruns of the algorithm with different tuning parameters and swarm size did not produce an optimal design, which is the case here.
A common strategy to try to overcome the above problem is to hybridize the algorithm with another algorithm, such that the hybridized version performs better than either of the algorithms. Another option is to use the equivalence theorem to derive an efficiency lower bound for the generated approximate design without knowing the optimum (Pazman 1986). For D-efficiency, the lower bound depends on the maximum value of the sensitivity function of the design. Since CSO is a stochastic algorithm and depends on the initial design and choice of tuning parameters, we ran the algorithm multiple times and reported the minimum of the D-efficiency of the generated design. For this example, the CSO generated design is \(\xi ^{5}\) and its computed minimum D-efficiency is \(88\%\), which may suffice in practice.
For models with three or more factors, like in the last two examples, the CSO-generated designs appear to be D-optimal or highly D-efficient. Unlike previous examples, the sensitivity functions are now high dimensional and so it is difficult to plot them and visually appreciate their features. One can discretize the design space using a fine grid evaluate the values of their sensitivity function at every grid point but this can be time-consuming. Another way is to apply CSO to optimize the multi-dimensional sensitivity function and confirm all peaks occur at the design points of the CSO-generated design. We chose the latter option and have verified that the CSO-generated design \(\xi ^4\) is numerically optimal and \(\xi ^{5}\) is not.
5.3 Are D and G-optimal designs equivalent for hierarchical linear models?
It is well known that for regression models with homoscedastic errors, the D and G-optimal approximate designs are equivalent (Kiefer and Wolfowitz 1960). The two optimality criteria look different and have different purposes and so it is an intriguing result. Does the equivalence of the two types of designs apply when we have linear mixed regression models?
Let \({\varvec{J}}_n\) be the n-dimensional square matrix whose elements are all ones, let \(\varvec{\varDelta } = m{\varvec{D}}\), and let \(\otimes \) denote the Kronecker product. D-optimal design for model (2) minimizes the log \(|\hbox {MSE}(\xi )|\) where
Tables 7 and 8 display CSO-generated designs for the D and G-optimality criteria on different settings for the mixed quadratic model with random components having various covariance matrices. Tables 9 and 10 show corresponding results for a fractional polynomial model with random components having various covariance matrices. The numerical results suggest that D and G-optimal designs for these models are almost equivalent since their D and G-efficiencies relative to the other are all very close to 1. Additional numerical results not shown here for space consideration, for other models we have investigated with more polynomial or fractional polynomial terms and different types of covariance structures also show that the two types of optimal designs have relative efficiencies very close to 1.
Our numerical results in the tables suggest that the celebrated theorem of Kiefer and Wolfowitz may also apply to hierarchical linear models, but a general proof is elusive at this time. However, we are able to show the equivalence of the two types of designs holds for hierarchical linear models when they contain only a random intercept. To see this, we recall D-optimality discussed in Prus and Schwabe (2016b) for the hierarchical linear model (2). Assuming that the dispersion matrix \({{\varvec{D}}}\) has rank q, the D-criterion for prediction is the logarithm of the product of the \((n-1)q+p\) largest eigenvalues of the MSE-matrix:
where \(\lambda _1(\xi ,{\varvec{\varDelta }}),\ldots ,\lambda _q(\xi ,{\varvec{\varDelta }}) \) are the q largest eigenvalues of \({{\varvec{N}}}(\xi ,{\varvec{\varDelta }})={\varvec{\varDelta }}- {\varvec{\varDelta }}({\varvec{{{\varvec{M}}}}}^{-1}(\xi )+{\varvec{\varDelta }})^{-1}{\varvec{\varDelta }}\). Corollary 6 of Prus and Schwabe (2016b) used this definition and gave an equivalence theorem for D-optimality, and showed that the D-optimal design in the fixed-effects model is also D-optimal for prediction in the random intercept model.
We next consider using the G-optimal design for prediction in a hierarchical linear model with a random intercept. Assume \(f_1(x)\equiv 1\) in model (2). The dispersion matrix \({{\varvec{D}}}\) can be written as \({{\varvec{D}}}=d{{\varvec{e}}}_1{{\varvec{e}}}_1^T\), where \({{\varvec{e}}}_1=(1, 0, \ldots , 0)^T\) denotes the first unit vector in \({\mathbb {R}}^p\). For an approximate design \(\xi \in \varXi \), the MSE-matrix for prediction in this random-intercepts model is
where \(\delta =md\) as defined in (13).
It follows that the lower bound in (10) is
which does not depend on \(\xi \). If \(\xi ^*\) is D-optimal for the fixed-effects model, we have
and it follows that the design \(\xi ^*\) is G-optimal for prediction of individual parameters. Therefore, the D-optimal and G-optimal designs are equivalent for prediction in the random-intercept model.
6 Conclusions
G-optimal designs are challenging to determine and study because the criterion is not differentiable and they require solving two or more layers of nested optimization problems over different spaces. However, the criterion is compelling and should appeal to researchers interested to design an experiment to estimate the overall response surface. To facilitate greater use of such designs for linear models with random effects, we proposed an effective meta-heuristic algorithm call CSO to find G-optimal designs and developed an equivalence theorem to confirm whether a design is G-optimal.
Additionally, we showed CSO is flexible and can also search for locally D-optimal designs for Poisson mixed regression models with several interacting factors, where some random effects may be correlated. We also provide R-codes freely and the interested reader can request them from the third author.
Change history
29 July 2022
A Correction to this paper has been published: https://doi.org/10.1007/s00500-022-07374-4
References
Berger M, Wong WK (2005) Applied optimal designs. Wiley, Hoboken
Berger M, Wong WK (2009) An introduction to optimal designs with applications to social and biomedical research. Wiley, Hoboken
Berger M, King CY, Wong WK (2000) Minimax \({D}\)-optimal designs for item response theory models. Psychometrika 65(3):377–390
Chen RB, Chen PY, Wong WK (2018) Standardized maximin \({D}\)-optimal designs for pharmacological models via particle swarm optimization techniques. Chemom Intell Lab Syst 169:79–86
Cheng R, Jin Y (2014) A competitive swarm optimizer for large scale optimization. IEEE Trans Cybern 45(2):191–204
Debusho LK, Haines LM (2008) \({V}\) and \({D}\)-optimal population designs for the simple linear regression model with a random intercept term. J Stat Plan Inference 138(4):1116–1130
Debusho LK, Haines LM (2011) \({D}\) and \({V}\)-optimal population designs for the quadratic regression model with a random intercept term. J Stat Plan Inference 141(2):889–898
Entholzner M, Benda N, Schmelter T, Schwabe R (2005) A note on designs for estimating population parameters. Biom Lett Listy Biom 42:25–41
Fedorov V (1972) Optimal theory of experimental designs. Academic Press, Cambridge
Fedorov V, Hackl P (1972) Model-oriented design of experiments. Springer, New York
Gu S, Cheng R, Jin Y (2018) Feature selection for high-dimensional classification using a competitive swarm optimizer. Soft Comput 22(3):811–822
Huang MNL, Chang F-C, Wong WK (1995) D-optimal designs for polynomial regression without an intercept. Stat Sin 5(2):441–458
Kiefer J (1959) Optimum experimental designs. J R Stat Soc Ser B (Methodol) 21(2):272–304
Kiefer J, Wolfowitz J (1960) The equivalence of two extremum problems. Can J Math 12:363–366
Kim S, Wong WK (2018) Extended two-stage adaptive designs with three target responses for phase ii clinical trials. Stat Methods Med Res 27(12):3628–3642
Kumarappan N, Arulraj R (2016) Optimal installation of multiple dg units using competitive swarm optimizer (cso) algorithm. In: 2016 IEEE Congress on evolutionary computation (CEC). IEEE, pp 3955–3960
Masoudi E, Holling H, Duarte BP, Wong WK (2019) A metaheuristic adaptive cubature based algorithm to find bayesian optimal designs for nonlinear models. J Comput Graph Stat 28(4):861–876
Mohapatra P, Das KN, Roy S (2017) A modified competitive swarm optimizer for large scale optimization problems. Appl Soft Comput 59:340–362
Naderi D, Niaparast M, Zangenehmehr A (2018) D-optimal designs for multiple poisson regression model with random coefficients. Asian Res J Math 9(1):1–11
Niaparast M, Schwabe R (2013) Optimal design for quasi-likelihood estimation in poisson regression with random coefficients. J Stat Plan Inference 143(2):296–306
Pazman A (1986) Foundations of optimum experimental designs. Springer, Berlin
Phoa FKH, Chen R-B, Wang W, Wong WK (2016) Optimizing two-level supersaturated designs using swarm intelligence techniques. Technometrics 58(1):43–49
Prus M (2019) Various optimality criteria for the prediction of individual response curves. Stat Probab Lett 146:36–41
Prus M, Schwabe R (2016a) Interpolation and extrapolation in random coefficient regression models: optimal design for prediction. In: mODa 11-advances in model-oriented design and analysis. Springer, pp 209–216
Prus M, Schwabe R (2016b) Optimal designs for the prediction of individual parameters in hierarchical models. J R Stat Soc Ser B (Stat Methodol) 78(1):175–191
Royston P, Altman DG (1994) Regression using fractional polynomials of continuous covariates: parsimonious parametric modelling. J R Stat Soc Ser C (Appl Stat) 43(3):429–453
Royston P, Sauerbrei W (2008) Multivariable model-building: a pragmatic approach to regression analysis based on fractional polynomials for modelling continuous variables, vol 777. Wiley, Hoboken
Royston P, Ambler G, Sauerbrei W (1999) The use of fractional polynomials to model continuous risk variables in epidemiology. Int J Epidemiol 28(5):964–974
Schmelter T (2007a) Considerations on group-wise identical designs for linear mixed models. J Stat Plan Inference 137(12):4003–4010
Schmelter T (2007b) The optimality of single-group designs for certain mixed models. Metrika 65(2):183–193
Storn R, Price K (1997) Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces. J Glob Optim 11(4):341–359
Sun C, Ding J, Zeng J, Jin Y (2018) A fitness approximation assisted competitive swarm optimizer for large scale expensive optimization problems. Memet Comput 10(2):123–134
Walters GD (2007a) Predicting institutional adjustment with the lifestyle criminality screening form and the antisocial features and aggression scales of the pai. J Pers Assess 88(1):99–105
Walters GD (2007b) Using \({P}\)oisson class regression to analyze count data in correctional and forensic psychology: a relatively old solution to a relatively new problem. Crim Justice Behav 34(12):1659–1674
Whitacre JM (2011a) Recent trends indicate rapid growth of nature-inspired optimization in academia and industry. Computing 93(2–4):121–133
Whitacre JM (2011b) Survival of the flexible: explaining the recent popularity of nature-inspired optimization within a rapidly evolving world. Computing 93(2–4):135–146
Wong WK, Cook RD (1993) Heteroscedastic G-optimal designs. J R Stat Soc Ser B (Methodol) 55(4):871–880
Xiong G, Shi D (2018) Orthogonal learning competitive swarm optimizer for economic dispatch problems. Appl Soft Comput 66:134–148
Yang XS (2010) Nature-inspired metaheuristic algorithms. Luniver Press, Beckington
Zhang WX, Chen WN, Zhang J (2016) A dynamic competitive swarm optimizer based-on entropy for large scale optimization. In: 2016 eighth international conference on advanced computational intelligence (ICACI). IEEE, pp 365–371
Zhang Z, Wong WK, Tan KC (2020) Competitive swarm optimizer with mutated agents for finding optimal designs for nonlinear regression models with multiple interacting factors. Memet Comput 12(3): 219–233
Zhou J, Fang W, Wu X, Sun J, Cheng S (2016) An opposition-based learning competitive particle swarm optimizer. In: 2016 IEEE Congress on evolutionary computation (CEC). IEEE, pp 515–521
Acknowledgements
Dr. Liu and Dr. Yue were partially supported by the National Natural Science Foundation of China under Grants 11871143 and 11971318. Dr. Wong and Dr. Zhang were partially supported by a grant from the National Institute of General Medical Sciences of the National Institutes of Health under Award Number R01GM107639. The content is solely the responsibility of the authors and does not necessarily represent the official views of the funding sources.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original article has been updated: Due to licence tag update.
Appendix
Appendix
In this appendix, we show that the G-optimality criterion is a convex function and provide proofs for Theorems 1 and 2.
To show the G-optimality criterion is convex, we first let \(\xi _{\alpha }=\alpha \xi +(1-\alpha ){\bar{\xi }}, 0<\alpha <1\), where \(\xi \) and \({\bar{\xi }}\) are any two approximate designs in \(\varXi \) and \(\alpha \in [0,1]\). Then we have
and
It follows that
which implies that
This completes the argument that the G-optimality criterion is a convex functional.
Proof of Theorem 1
For any design \(\xi \in \varXi \), from (9), we have
Consequently,
which proves Theorem 1. \(\square \)
Proof of Theorem 2
For the G-optimal criterion in (9), let \(\nabla \phi (x,\xi )\) be the \(p\times p\) matrix with elements given by
A direct calculation shows that
where \(E_{ij}\) is the matrix with 1 in the (i, j)th position and zeros elsewhere and \({{\varvec{e}}}_j\) is the j th standard basis for \(R^p\). It follows that
and
\(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, X., Yue, R., Zhang, Z. et al. G-optimal designs for hierarchical linear models: an equivalence theorem and a nature-inspired meta-heuristic algorithm. Soft Comput 25, 13549–13565 (2021). https://doi.org/10.1007/s00500-021-06061-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-06061-0