
Abstract
With the ongoing development of distributed hydrological models, flood risk analysis calls for synthetic, gridded precipitation data sets. The availability of large, coherent, gridded re-analysis data sets in combination with the increase in computational power, accommodates the development of new methodology to generate such synthetic data. We tracked moving precipitation fields and classified them using self-organising maps. For each class, we fitted a multivariate mixture model and generated a large set of synthetic, coherent descriptors, which we used to reconstruct moving synthetic precipitation fields. We introduced randomness in the original data set by replacing the observed precipitation fields in the original data set with the synthetic precipitation fields. The output is a continuous, gridded, hourly precipitation data set of a much longer duration, containing physically plausible and spatio-temporally coherent precipitation events. The proposed methodology implicitly provides an important improvement in the spatial coherence of precipitation extremes. We investigate the issue of unrealistic, sudden changes on the grid and demonstrate how a dynamic spatio-temporal generator can provide spatial smoothness in the probability distribution parameters and hence in the return level estimates.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Large-scale flood events cause devastating impact on the human society worldwide (Desai et al. 2015). Stochastic weather generators can be used to generate synthetic weather, by which hypothetical scenarios (i.e. scenarios that have not occurred) can be explored. Flood risk analysis (FRA) based on large sets of synthetic flood event data provides a scientific approach to study the consequence of such flood events (Gouldby et al. 2017). Three different approaches can be distinguished, with an increasing level of complexity.
First, for small and individual regions of interest, weather generators were used on a single-site basis. Eagleson (1972), Hebson and Wood (1982), Cameron et al. (1999) applied a local, event-based, probabilistic analysis, where the single-site was represented by catchment average precipitation. A recent overview in which current weather generators were tested for local weather generation was provided by Vu et al. (2018), exploring different climatic regions individually. They tested local performance only, as they did not include any tests for spatial dependence.
Second, the extension from single-site analysis to multi-site received a lot of attention in the last two decades, addressing the challenge of spatial dependence (Katz et al. 2002). For example, Wilks (1998) described a local daily precipitation generator which they extended to multi-site. Wilby et al. (2003) applied a similar approach, where they separated their gauging stations into sub-regions. Fowler et al. (2005) provided an extension by linking sub-regional multi-site models to capture the historical spatial monthly cross-correlation between the sub-regions. Serinaldi (2009) used copulas for the capturing of spatial dependence. Bárdossy and Pegram (2009), Hundecha et al. (2009), Srikanthan and Pegram (2009), Davison et al. (2012), Zhang et al. (2013), Verdin et al. (2015) provided further extensions or variations of methodology. Serinaldi and Kilsby (2014) describe a method to obtain meta-Gaussian daily precipitation fields for all of Austria, which may be interpreted as a step in which a significant increase in number of sites is considered, outlined on a grid. What these studies have in common is that a set of sites of interest was predefined, where for the probabilistic analysis each site was considered in each time step. We will refer to this type of analysis as ‘static spatio-temporal probabilistic analysis’ (SSTPA). SSTPA assumes that the essence of the physical phenomenon studied can be captured in snapshots, i.e. that images can be defined with relevant values for all locations studied. Keef et al. (2009), Quinn et al. (2019) define events in time series, but then take concurrent values at all other sites. This means events are delineated in time but not in space, i.e. events occurs everywhere in a particular time window, which makes it suitable for SSTPA. None of these precipitation generators of the type SSTPA use spatio-temporal events, which may be explained by the difficulty of incorporating an approach that makes use of spatio-temporal events into a SSTPA (Diederen et al. 2019). An overview of stochastic precipitation generators of the type SSTPA was recently provided by Ailliot et al. (2015).
Third, the contrasting approach of ‘dynamic spatio-temporal probabilistic analysis’ (DSTPA), which we have applied in this manuscript. DSTPA is an event-based approach, where ‘dynamic events’ are conceptualised to be clusters of related data that occur at different locations in space and time with (potentially) time varying spatial extents (and therefore spatially varying durations). Physical phenomena, such as moving precipitation fields, often show a dynamic, progressive behaviour, rather than a static behaviour. Rainfall organization and movement within basins is an essential control of flood response and in particular of hydrograph timing (Tarasova et al. 2019). DSTPA allows dynamic behaviour to be captured, thereby potentially providing a more physically meaningful event definition (OBJ3 that will be formulated in Sect. 2). In addition, for a particular site of interest, moving events allow inference from data occurring outside that particular site, which will be discussed in Sect. 6.2. A number of studies performed (subroutines of) DSTPA. In the study area of droughts, which is inversely related to floods, some studies applied DSTPA several years ago (Andreadis et al. 2005; Corzo Perez et al. 2011). Corzo Perez et al. (2011) studied gridded discharge output from a global hydrological model and captured low discharge anomalies. They connected events in space using an algorithm that looks at neighbouring pixels. The result was a catalogue of observed dynamic events of low discharge. Compared to low discharge anomalies, precipitation fields move around at higher speeds, such that higher resolution data products are required. Within the context of flood related DSTPA, Cowpertwait (1995) extended the single-site pulse process proposed by Rodriguez-Iturbe et al. (1987) to the spatio-temporal Neyman–Scott pulse process (STNSPP). The original concepts in this paper were further extended and developed into a well-established rainfall generator called ‘RainSim’ (Burton et al. 2008). Using RainSim, synthetic, dynamic events are generated from an analytical model (disks of rainfall) and placed in space and time using the STNSPP. Vallam and Qin (2016) concluded that RainSim compares favourably to three other generators (of the type SSTPA) concerning the capturing of spatial dependence.
Recently Vorogushyn et al. (2018) called for new methods in large-scale FRA to enable the capturing of system interactions and feedbacks. Large-scale flood events are usually triggered by extreme precipitation fields with long duration, high intensity or both. Large-scale synthetic precipitation fields can be used to study system interactions and feedbacks, since in the atmosphere there are no direct human interventions such as in catchments, e.g. dikes; dams; reservoirs; changes in land use. Gridded re-analysis data (Saha et al. 2010) may provide the means to develop a next generation of stochastic weather generators of the type DSTPA, since for probabilistic analysis a long record of coherent data is required. This type of modelled input data can eventually be replaced by more direct precipitation observations, such as satellite-derived high-resolution precipitation products (Kidd et al. 2012).
In Sect. 2 we will provide a framework for the stochastic generation of synthetic, event-based, large-scale precipitation data. In Sects. 3–5 we will describe the proposed method and explain the different steps taken and choices made in the analysis. In Sect. 6 we will compare the statistical properties of the synthetic data produced by the dynamic spatio-temporal generator to the observed data. In Sect. 7 we will discuss each step taken in the generation process and discuss some implications of DSTPA.
2 Methodology
2.1 Observed data set
The data set used in this study is the climate forecast system re-analysis precipitation product (Saha et al. 2010). The data set consists of hourly precipitation rates p with global coverage on a \(0.3125 \times 0.3125\) degree spatial resolution and covers the period of 1979–2010. On a practical level, we have two main reasons for using this data set. First, its global coverage, which allows a coherent approach for large-scale analyses. Second, its hourly temporal resolution. The proposed methodology assumes that the spatial extent of a precipitation event from one time step to the next has overlap, which is more likely to be the case when the temporal resolution is hourly than daily.
Although this data set was derived from a modelled re-analysis data set, we will refer to the used subset of data as ‘observed data’. The data was presented as an average precipitation rate for the next 1–6 h at the 00, 06, 12, 18 h of each day. We calculated the hourly precipitation rate \(p_t\) from the precipitation averages \({\bar{p}}_t\) of previous time steps, e.g. for the precipitation in the n-th hour of a 6 hourly block we used \(p_{n}=n{\bar{p}}_{n}-(n-1){\bar{p}}_{(n-1)}\), where \(n=2,\ldots ,6\).

Spatial domains of the generator (green) and of the FRA to be performed using the generated data (red). As we considered moving precipitation fields, the domain of the generator had to be much larger than the domain of the FRA
With these spatial and temporal resolutions, the volume of data is substantially larger than a typical SSTPA of daily data. Therefore, certain aspects of the proposed methodology are influenced by computational concerns. First, in order to reduce the computational burden, we used a subset of the data set. The spatial extent of the analysis is displayed in Fig. 1. We used all 32 years of data from 1978 to 2010. Second, we present the results based on simplistic choices. We believe more sophisticated approaches could be taken, which would require more computational resources, and we will provide several suggestions for further improvement in Sect. 7.
2.2 Objectives and framework
The aim of this study was to provide a methodology (of the type DSTPA) to generate a large data set of synthetic precipitation. In this study there are three objectives. First, variability should be introduced, which implies that the generated data set should hold a much larger variety of hypothetical (synthetic) events than those contained in the observed data (OBJ1). Second, the statistical patterns in the synthetic set need to agree with that of the observed, i.e. the observed data set should be a likely subset of the synthetic (OBJ2). Third, the synthetic data should be physically plausible (OBJ3).

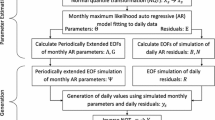
The framework that was used in this analysis. Ovals are data sets, arrows are steps. Data sets in the left column represent 32 years of observed data and in the right column represent 1000 years of synthetic data
Figure 2 shows the the general framework we propose for event-based generation:
-
1.
Event identification in the (32 years of) observed data, providing a catalogue of observed dynamic events; Sect. 3.1.
-
2.
Event description, where descriptors are captured for each event, some of which are used for classification and some for the subsequent steps; Sect. 3.2.
-
3.
Multivariate statistical analysis, where, for each class of events, statistical models are fitted to the observed descriptor sets, from which (1000 years of) synthetic coherent descriptor sets are simulated; Sect. 4.
-
4.
Event reconstruction, where synthetic dynamic events are reconstructed from the combination of observed events and synthetic descriptors, providing a (large) catalogue of synthetic events; Sect. 5.1.
-
5.
Space-time placement (STP) and gap-filling (GF), where synthetic events are placed in a synthetic space-time continuum, after which the gaps between the synthetic events are filled (with smaller, non-event values); Sect. 5.2.
3 Observed data
3.1 Event identification
Dynamic precipitation events were identified using the following procedure. First, a global threshold was set to \(\nu =1.8\,~\hbox{mm h}^{-1}\), based on a trial and error procedure. The threshold needed to be sufficiently high such that clusters of precipitation could be separated into events, and that the resulting events could be assumed to be independent. On the other hand, the threshold should not be too high to ensure a reasonable amount of data (and hence events) are available for fitting a statistical model. A lower threshold would introduce more variability (OBJ1), since a larger part of the observed data set would be included in the catalogue of observed events. Data values below the global threshold were masked (i.e. set to \({\textit{NA}}\)). Second, polygons were captured in (the image of) each time step. Each polygon was assigned an initial unique event ID \(\{{\textit{ID}}_1, {\textit{ID}}_2, \ldots \}\). Third, connections between events were established. Across subsequent time steps, connections were established based on the spatial overlap of events, i.e. a connection was established between \({\textit{ID}}_i\) from time step t and \({\textit{ID}}_j\) from time step \(t+1\) if the two polygons intersected (i.e. overlapped). Implicitly, temporal connections were established over multiple time steps, e.g. event \({\textit{ID}}_i\) at time step t was connected to event \({\textit{ID}}_j\) at time step \(t+1\), which was in turn connected to event \({\textit{ID}}_k\) at \(t+2\), and so on. Fourth, after all connections were established, all (directly and indirectly) connected polygons were merged and defined as one identified event.

A sequence of a few moving observed precipitation events. Eight events are displayed, each represented by a unique colour
Figure 3 shows a sequence of moving precipitation events. The event identification procedure resulted in a catalogue of 196,810 observed events. Similar algorithms have been used for identifying dynamic spatio-temporal events in gridded data sets, e.g. Corzo Perez et al. (2011) identified dynamic events of low discharge anomaly for drought analysis.
3.2 Event description
Classification Using statistical analysis, we will model the statistical properties of the event descriptors in Sect. 4. Instead of performing the statistical analysis over all events in a lumped fashion, we assumed the statistical properties to differ from one class of events to another, hence we applied a classification step.
For the classification procedure, two main decisions had to be made, namely the number of classes and which event descriptors to use for classification. For the former, from a statistical point of view, each class should hold sufficient data to be able to confidently fit joint-distributions, which implies that there should not be too many classes. Although no strict guidelines were available, the multivariate extremal dependence model would benefit from about 500–10,000 events per class. With 196,810 identified events, this implied a range of about 20–400 classes. From a physical point of view (OBJ3), each class should be physically different from the others (i.e. a class could represent hurricanes in region A, thunderstorms in region B, etc.), which implies there should be a sufficient number of classes. We estimated that 196 separate classes should be sufficient to capture physically distinguishable classes. For the latter, we considered a combination of four descriptors. To be able to classify events according to region, we used the spatial centres of gravity of the events (\({\textit{cog}}_x\) and \({\textit{cog}}_y\)). We included two descriptors (\({\textit{rat}}_{P/V}\) and \({\textit{cogV}}_{t}\)) that provided means to distinguish different physical behaviour of the precipitation events (OBJ3). The ratio of the peak precipitation rate divided by the precipitated volume \({\textit{rat}}_{P/V}\) provides an indicator for the heterogeneity of events, where a large value points towards a relatively heterogeneous event and a small value points towards a relatively homogeneous event. The temporal centre of gravity of the precipitated volume \({\textit{cogV}}_{t}\) (normalised, i.e. duration set to 1) provides an indicator of timing of precipitation release of events, where a small value indicates that events showed a large initial release and then slowly decayed, and vice versa. We tested several standard approaches for cluster analysis, including hierarchical cluster analysis, partitional algorithms and self organising maps (SOM); see Wilks (1995) for a comprehensive list of options. For its efficiency in handling large data sets, we finally used self organising maps as proposed by Kohonen (2012).

Density plots of the (normalised) descriptors used for classification. A sample of 8 different classes is displayed. \({\textit{cog}}_x\) and \({\textit{cog}}_y\) are the spatial centres of gravity, \({\textit{cogV}}_t\) is the temporal centre of gravity of the volume, \({\textit{rat}}_{P/V}\) is the ratio of peak over volume
Figure 4 shows a sample of the resulting classes. Although different classes may exhibit similar distributions in a subset of the four descriptors, the classes were defined to ensure the joint distribution of the full set of descriptors are statistically distinguishable between one class and another.
Multivariate descriptor sets Having completed the classification, we performed statistical analysis for each class of events separately. Where the choice of descriptors for classification depended on their ability to produce distinct classes of comparable events, the choice of descriptors to which to apply statistical analysis depended on the reconstruction procedure, which will be discussed in Sect. 5.1. Therefore, the descriptors used for the statistical analysis were not the same as the descriptors used for classification. For all classes we used the same event descriptors: volume \(V~[\hbox{m}^{3}]\), which is the sum of all precipitation in the event; peak \(P~[\hbox{m h}^{-1}]\), which is the maximum precipitation rate in the event; and spatio-temporal extent \(E~[\hbox{m}^2~\hbox{h}]\), which is the sum of spatial extent of all time steps in the event (i.e. if an event occurs at a particular grid cell for 3 h, the spatial extent of that grid cell is counted three times).
The event description procedure resulted in 196 matrices of observed descriptors with three columns (P, V, E), one for each class, with a variable number of rows per matrix equal to the number of observed events belonging to the respective class.
In order to align with the corresponding literature in statistical models for multivariate extreme values, in the next Sect. 4 columns of these matrices will be referred to as margins and the large values in each column will be referred to as the upper tails of the marginal distributions.
4 Multivariate statistics
4.1 Joint distribution model
To model the joint distributions of event descriptors within each separate class, we adopted a copula-like method (Genest and Favre 2007; Nelsen 2007), whereby the multivariate distribution was decomposed to the marginal distribution and the dependence structure. This involved fitting a univariate probability distribution for each margin as well as fitting models to capture the dependence structure between different margins. We were particularly concerned with extreme events, where one or a few of the descriptors were very large. This was reflected in the proposed approach for both the marginal and the dependence model.
Marginal distributions We used a mixture model for the marginal distributions, assuming values above a large threshold to follow a Generalised Pareto Distribution (GPD), where values below were captured by the empirical distribution. This type of mixture model is considered suitable for situations where attention is mostly focussed on the extrapolation of the distribution into high quantiles. A mixture model has been used for various applications of environmental data modelling (Lamb et al. 2010; Wyncoll and Gouldby 2015). Scarrott and MacDonald (2012) provided a detailed description regarding the formulation of threshold-based mixture models.
The GPD for the upper tail of each descriptor (i.e. each column of the observed descriptor matrix) was fitted using likelihood-based inference (Coles et al. 2001). Based on standard threshold diagnosis suggested by Coles et al. (2001), we deemed the 90% quantile as a reasonable threshold for fitting the GPD. This threshold was sufficiently high so that the limiting properties of the tail distribution could be approximated by the GPD and not too high that the variance of the GPD parameter estimation was prohibitive. With three event descriptors and 196 classes, the upper tail distributions were captured with 588 marginal GPDs.

D and p are standard Kolmogorov–Smirnov statistics, which were used to test the quality of the GPDs fitted to the marginals of the spatio-temporal descriptors
Figure 5 shows quality tests of the marginal GPD-fits, where we compared the empirical quantiles and probabilities against the modelled using standard Kolmogorov–Smirnov statistics. Overall, reasonable GPD fits were obtained.
Dependence structure Similar to the marginal model, we captured the dependence structure using a multi-dimensional mixture of two models. Such a multi-dimensional mixture was used previously by Bortot et al. (2000), who modelled coastal variables. First, we modelled the lower part of the distribution using a kernel density distribution (Silverman 2018), as there was no obvious choice of a parametric model to describe the dependence in this region. The use of the kernel bandwidth (rather than direct re-sampling) enabled us to draw values that were broadly similar but not identical to the observed data. Second, we modelled the upper tail region (i.e. where one or multiple variables were large) by a dedicated multivariate extremal dependence model proposed by Heffernan and Tawn (2004) (hereafter referred to as ‘HT04’). The advantage of this approach is that HT04, for the tail region, is much more flexible in terms of capturing different types of extremal dependence (Ledford and Tawn 1996). In addition, the estimation of the model parameters does not suffer from the curse of dimensionality, whereby the number of observation data available for fitting the model decreases dramatically as the dimension of the problem grows. The original HT04 model was proposed for the conditional distribution of all variables \(X_i\) where \(i=1,2,\ldots ,d\) given one of the variable is above a large threshold. More specifically, if we transform the marginal distribution of each variable \(X_i\) to a standard Laplace distribution, denoting the transformed variables as \(Y_i\), we have \(Y_{-i}| Y_i=y_i ~ a_{-i}y_i + y_i^b{-i}\cdot Z_{-i}\) for all values \(y_i>u\) and \(i \in \{1, 2, \ldots , d\}\), where the \((d-1)\)-dimension random variable \(Y_{-i}\) represents all but the i-th margin of the original full joint distribution; parameter \(a_{-i}\) and \(b_{-i}\) are the location and scale parameter vector of length \((d-1)\); the \((d-1)\)-dimensional random variable \(Z_{-i}\) is a non-degenerate multivariate distribution that is independent of the value of \(Y_i\), referred to as the residual distribution; and constant u is a high threshold above which the HT04 structure is assumed to apply with negligible error.
The lower part of the joint distribution was captured using a multivariate kernel density based on Scott’s rule-of-thumb choice of optimal bandwidth (Silverman 2018). This was an improvement over the original rule-of-thumb proposed in Silverman (1986). We performed the pairwise estimation of the HT04 parameters based on pseudo-likelihood, separately for each class of precipitation events. Due to the complexity of the method, readers are advised to refer to the original paper for detailed steps in fitting the model. Similar to Heffernan and Tawn (2004), we partitioned the joint upper tail area, where multiple margins exceeded the threshold, into subspaces such that the conditioning margin \(Y_i\) in the above formulation was always the largest margin in terms of quantile probability. We used equal thresholds for all directions of conditioning as we did not find substantial improvement in model fitting by allowing the threshold to be variable for different conditioning margins. The final threshold of choice was the 95% quantile of the Laplace distribution, based on the consideration of number of data points available above the threshold as well as the outcome of tests of independence between the residual distribution \(Z_{-i}\) and the values of the conditioning margin \(y_i\).
With three descriptors and 196 classes, the dependence structure was captured with 196 multivariate kernel densities (one for each class) and 588 HT04 models (one for each conditioning descriptor in each class).

Pair-wise plots of the observed descriptor matrix and the synthetic descriptor matrix of class 6. Purple (dark) is the observed and yellow (light) is the simulated. \(V~[\hbox{m}^{3}]\) is the sum of all precipitation, \(P~[\hbox{m h}^{-1}]\) is the maximum precipitation rate and \(E~[\hbox{m}^2~\hbox{h}]\) is the spatio-temporal extent. In the diagonal, distributions of observed and synthetic descriptors are compared using box-plots. Below the diagonal, pair-wise scatter plots are displayed. Above the diagonal, pair-wise correlations are displayed
4.2 Simulation
Similar to the model fitting, the simulation of the synthetic data was performed for each class of precipitation events separately. First, we sampled \(n_{{\textit{syn}}}=n_{{\textit{obs}}}{T_{{\textit{syn}}}}/{T_{{\textit{obs}}}}\) descriptor sets from the multivariate kernel density distribution, where \(n_{{\textit{obs}}}\) is the observed number of events in the class and T is the total duration of the respective data set. With the space-time placement procedure in mind, which will be discussed in Sect. 5.2, we chose to sample exactly \(n_c=31\) synthetic descriptor sets from each observed, such that we simulated about 1000 years worth of synthetic event descriptors from 32 years of observed. Second, we selected the synthetic descriptor sets in which the largest marginal cumulative probability exceeded the threshold \(p_{qu}=0.99\) and replaced them with simulated descriptor sets drawn from the corresponding HT04 model (conditional on the largest margin). As suggested by Heffernan and Tawn (2004) we used a re-sampling method to draw samples from the residual distribution \(Z_{-i}\) in the HT04 model. With the reconstruction procedure in mind, which will be discussed in Sect. 5.1, this resampling scheme ensured that each synthetic descriptor set had a corresponding observed set. Third, we transformed the marginals of the synthetic descriptors to respect the mixed distributions fitted to the observed marginals. This implies that we forced the synthetic marginals to have the exact same distribution as the corresponding observed marginals. However, by forcing this transformation we slightly distorted the dependence structure.
Figure 6 shows that with the synthetic descriptor sets a much wider variety of events was explored than with the observed (OBJ1) and that the observed descriptors were a likely subset of the synthetic (OBJ2), with similar correlations and identical marginal distributions (boxplots). With one synthetic matrix for each observed matrix, the simulation procedure resulted in 196 synthetic matrices, in which each row was a complete synthetic descriptor set and where each synthetic matrix had 31 times as many rows as the observed from the corresponding class.
5 Synthetic data
5.1 Event reconstruction
For the reconstruction of each individual synthetic event, we used several pieces of information: the set of synthetic descriptors; the connected set of observed descriptors, from which the synthetic descriptors were sampled using the statistical models; the observed event, corresponding to the observed descriptor set, which was used as a starting point for reconstruction; and the continuous observed data set, to be able to assign values to synthetically expanded events.
We applied the following procedure. For each synthetic descriptor set, we started from the observed event corresponding to the observed descriptor set from which the synthetic set was re-sampled. First, we adjusted the spatio-temporal extent of the observed event, changing it from the observed extent \(E_{{\textit{obs}}}\) to the synthetic extent \(E_{{\textit{syn}}}\). If \(E_{{\textit{syn}}}<E_{{\textit{obs}}}\), we ranked the coordinates of the observed event by value and kept removing the coordinate with the smallest value until the extent was reduced to the target value of \(E_{{\textit{syn}}}\). If \(E_{{\textit{syn}}}>E_{{\textit{obs}}}\), we kept adding neighbouring coordinates around the boundary of the observed event until the extent reached the target value of \(E_{{\textit{syn}}}\). Each round of addition was performed randomly such that all neighbouring coordinates on sharing the boundary with the event extend had an equal probability to be added. Second, within the extended or reduced extent, we obtained the original observed volumes for a given grid cell X by multiplying the precipitation rate with the spatial extent of the grid cell. We constructed the synthetic volumes for this grid cell Y using
where
with
and
where \(m_{x}=\min (x)\), \(M_{x}=\max (x)\), \(\mu _{x}={\textit{mean}}(x)\). This calculation preserves the shape of the distribution of the observed volumes with the mean and peak updated from \(\mu _x\) to \(\mu _y\) and from \(M_x\) to \(M_y\) respectively. Finally, we transformed the synthetic volumes per grid-cell back to precipitation rates using the spatial extent of the grid-cells.

Reconstruction of synthetic events corresponding to the synthetic descriptor sets displayed in Table 1. \({\textit{sum}}(p) [m]\) is the synthetic event precipitation summed per grid-cell. a The original observed event. b Synthetic event 1, for which the observed event is reduced in magnitude. c Synthetic event 2, for which the observed event is increased in magnitude
Figure 7 demonstrates two examples of the reconstruction of a synthetic event. Two sets of synthetic descriptors and the connected observed descriptor set are displayed in Table 1. The observed event, with corresponding set of observed descriptors \(D_{{\textit{obs}}}\), is displayed in Fig. 7a. The first synthetic event, with corresponding set of synthetic descriptors \(D_{{\textit{syn}}1}\), is displayed in Fig. 7b, which demonstrates a reduction in magnitude. The second synthetic event, with corresponding set of synthetic descriptors \(D_{{\textit{syn}}2}\), is displayed in Fig. 7c, which demonstrates an increase in magnitude.
With 31 synthetic events reconstructed from every observed, the reconstruction procedure resulted in a catalogue of 6.101.110 synthetic events.
5.2 Space-time placement and gap filling
To form a 1000-year continuous gridded time series using the catalogue of synthetic events, we applied the following procedure. We stacked 31 repetitions of the 32-year observed time series data in order. For each repetition of an observed event, we randomly sampled (without replacement) a corresponding synthetic event and replaced the observed event, both extent and precipitation intensity, with that of the synthetic event. By design (see Sect. 4.2), the number of corresponding synthetic events for each observed event was precisely 31, which meant that all synthetic events were used exactly once. In particular, when the replacing synthetic footprint was larger than that of the observed event, we still overwrote the values in those coordinates that were not covered in the observed event. If the replacing synthetic footprint was smaller, we retained the smallest value and transformed all other values linearly such that the largest value equalled the global threshold of event identification used in Sect. 3.1.
The space-time placement and gap gilling procedure resulted in a gridded, 1000-year continuous time series for the entire modelled region (Fig. 1), with a discontinuity in between the subsequent blocks.
6 Observed versus synthetic data
6.1 Extreme values
The statistical properties of the synthetic data should be compared with the observed, since the observed data should be a likely subset of the synthetic (OBJ2). Within the context of flood risk analysis, we considered the local distributions of extreme values to be the most relevant statistical property; additional checks can be found in “Appendix A”. Where Hundecha et al. (2009), Srikanthan and Pegram (2009), Cowpertwait et al. (2013) used annual maxima, we fitted GPDs to the peaks-over-threshold (POT), based on the standard approach summarised in Coles et al. (2001). First, we applied the GPD fitting procedure to the observed time series of 32 years (‘direct approach’) and, second, we applied the GPD fitting procedure to the generated synthetic time series of 1000 years (‘generator approach’). For each grid cell in both approaches: the same POT threshold and runs parameter were used; the same GPD threshold (i.e. location parameter) was used; the GPD fit was based on maximum likelihood estimation (MLE). As a means to assess the statistical properties of the extreme values, we used return level estimates (RLE). RLE were calculated from the GPD fits for both approaches.

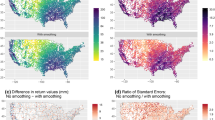
Comparing the direct approach and the generator approach. a GPD scale parameter, b GPD shape parameter and RLE of p \((\hbox{m h}^{-1})\) for return periods of c 10 years and of d 10,000 years
Figure 8a and b show that the generator approach produced more spatially smooth scale and shape parameters than the direct approach. Expectations of smooth GPD parameters were formulated by several authors (Gilleland et al. 2006; Cooley et al. 2007; Sharkey and Winter 2017). However, in order to obtain spatial coherence, they forced spatial smoothness of GPD parameters using Bayesian statistics, whereas we fitted each GPD independent of neighbouring pixels, only using MLE per pixel.
Figure 8c and d show a comparison of RLE in the British Isles (BI), with return periods of respectively 10 and 10,000 years. First, it can be observed that the generator approach suggests slightly higher RLE on average. Potentially, a few extreme events may have largely influenced (upwards) the extrapolation of the tail distribution for particular grid-cells, whereas nearby grid-cells with similar physical conditions were not affected. Second, it can be observed that the generator approach provides a smoother spatial pattern of RLE than the direct approach. The difference in smoothness for the RLE is not as clear as in the GPD parameters, since the GPD parameters can compensate each other to fit to particular RLE. It becomes more clear for higher return periods.
Drastic changes in the GPD parameters and RLE of the direct approach from one grid cell to the next may be due to the (relative) sparsity of extreme precipitation events per grid cell. Specifically, in regions were such effects can be expected to be relevant, e.g. tropical cyclones in the Caribbean region, we expect DSTPA significant differences between RLE obtained when using a local approach and when using DSTPA. Even smoother maps of RLE may be expected when the space-time placement method is improved with the extensions proposed in Sect. 7 of altering pathways and location of occurrence of events.
The direct approach makes use of much smaller sample, and is therefore subject to (more) sampling uncertainty. The generator approach makes use of an extra step (the generation process), which holds additional uncertainty. Therefore, we can not judge at this stage which approach holds larger uncertainty. Furthermore, it is important to note that we did not expect these two sets of values to be identical and that modelled distributions are used in both approaches, so that neither can be used as reference truth. However, we do think that the spatial smoothness should provide additional confidence in the value of the dynamic, spatio-temporal generator.
6.2 Dynamic spatio-temporal expansion of information
For local FRA (direct approach), the information used is only the information at a particular location. One of the main sources of uncertainty in risk analysis is the limited sample of observed data. As a result, local distributions may have tails that are too light, too heavy, or it may be difficult to fit distributions when limited samples suffer from ‘black swans’, which are observed occurrences of highly unlikely events in a (relatively) small sample of observations (Taleb 2007). This raises a discussion about ‘light or heavy tails’, i.e. the hypothesis that local distributions may have a lighter or a heavier tail than is to be expected from the most likely distribution fitted to the limited sample of observed data, which is connected to the spatial smoothness of distribution parameters.
To expand a (relatively small) sample of locally observed data, Merz and Blöschl (2008) provided a framework for expansion of information (EOI) in which they outline three main types: temporal, spatial and causal. We did use EOI, but none of the three listed above. To understand what type of EOI we did use, we traced back which evidence (observed data) was used to obtain the RLE. Two approaches to obtain RLE were described in Sect. 6.1; the direct approach and the generator approach. The temporal length in the direct approach was 32 years (of observed data), whereas the temporal length in the generator approach was 1000 years (of synthetic data). The spatial extent for both approaches was the same (BI). However, the synthetic data was generated using the DSTPA described in Sects. 3–5, in the procedure of which observed data outside the BI was used.

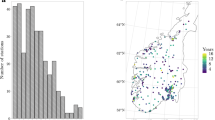
Per grid-cell, the number of time steps (\({\textit{nTstep}}\)) is displayed, which was obtained by summing the time steps of a a single event that travels from the east coast of the US to the BI, and b all observed events which have at least one time step in the BI, which outlines an impression of the region that influences the RLE of the BI using DSTPA
Figure 9a show an example of a precipitation event that started close to the east coast of the United States (US) and travelled all the way to the BI and beyond. Since all data points in this observed event were used to generate synthetic events, the data points close to the US (marginally) influenced the RLE in the BI.
Figure 9b show the spatial extent of all observed events used by the generator for the generation of the synthetic time series within the BI, providing a first order impression of the region of influence of RLE in the BI. We took the subset of observed events which have at least one time step (i.e. one point in x, y, t of precipitation) within the extent of the BI (red square). If synthetic events would be reconstructed from observed events by changing the precipitation rates only (i.e. no changes in spatio-temporal extent, no movement of the centres of gravity of events and no STPP), this would be the data that influences RLE in the BI. From this subset of events, we counted the number of time steps \({\textit{nTstep}}\) per grid-cell. As can be observed, with the generator approach many data points observed outside the BI were used to obtain RLE in the BI. Note that Fig. 9 is for illustrative purposes only, as the result is highly dependent on the event identification procedure described in Sect. 3.1. A higher global threshold for event identification would lead to a smaller extent, and vice versa.
So, for each location, the generator approach makes use of more observed data than the local time series (per pixel). Therefore, as compared to traditional local probabilistic analysis, EOI is implied. It is not temporal EOI, since the generator is based on the 32 years of observed data, i.e. no additional temporal evidence is used. It is different from spatial EOI in that the additional information is not directly included from neighbouring sites, but is included based on the movement of events in space and time. I.e. space is not substituted for time, as they cannot be disentangled, but space and time are considered jointly (hence dynamic). These differences introduce a new concept: ‘dynamic expansion of information’.
7 Discussion and recommendations
7.1 Event identification
There is no commonly agreed definition of events - what some may consider to be a single event, could be considered to be multiple events by others. The general idea is to connect and separate according to a preconceived, subjective idea of what an event is, although this is likely to be an iterative procedure. For future research, we have several recommendations. First, physical arguments should be incorporated in the event identification procedure. Second, the event identification method should be compatible with the reconstruction method such that any reconstructed events should be identified in its exact extent. The current reconstruction algorithm may cause parts of the events to break off when the synthetic event extent is reduced. Third, from the dynamic spatio-temporal idea that events are physical phenomena that travel, we recommend that pathways are incorporated in the event identification procedure, e.g. a single event may have to be split into two events if sub-clusters of the event can be distinguished that (at some point in time) move into or arrive from distinctly different directions.
7.2 Classification
We deem a robust classification method should account for the difference between precipitation events in their statistical properties as well as their physical chraracteristics. Statistical cluster analysis should incorporate physical descriptors about the class of events, whereas physical descriptors about event classes could probably be refined based on the results of the statistical classification method. We recommend performing this analysis as an iterative process. We expect seasonality to be an effective descriptor for classification and recommend future research to consider descriptors such as month of occurrence (Hundecha et al. 2009) or season (Svensson et al. 2013).
7.3 HT04
In this study, we chose 196 classes, each of which had 3 marginals, providing a total of 588 marginal distributions. We expect that follow-up studies will formulate a larger number of classes and, for each class, describe events more accurately with a larger number of descriptors (which makes sense when more advanced reconstruction methods are developed that would make use of more descriptors). Therefore, with an expected increase in number of classes considered and an expected expansion of the dimensionality of the matrix in each class, HT04 will be a very practical model and is recommended to be used in follow-up studies.
7.4 Event reconstruction
Events were reconstructed using peak P, volume V and extent E. This was done similarly for each class of events. When the synthetic event required a reduction in extent as compared to the observed (\(E_{{\textit{syn}}}<E_{{\textit{obs}}}\)), the used procedure for the reduction in spatio-temporal extent (using the method of largest values) led to an issue. A single synthetic event could turn out to comprise multiple non-connected clusters of data; Fig. 7b. So what should become a single synthetic event, could potentially be split into multiple synthetic events, when handling the same event identification procedure as applied to the observed data. Vice versa, when generating synthetic events by growing the extent of the observed and when placing the synthetic events in a synthetic space-time continuum at their original locations, occasionally separate synthetic events were merged. For future research, we recommend that these issues are taken into account, since ideally the event definition should be consistent for both observed and synthetic events. In conjunction with improved event identification and classification methodology, we recommend that more advanced (i.e. realistic) reconstruction methods be developed. Potentially, a different selection of descriptors can be used for each class. Examples of descriptors to include for reconstruction could be: (object) orientation, for which principal component analysis could be used; moments; duration; etcetera.
7.5 Space-time placement and gap filling
A parsimonious method was implemented for the space-time placement of synthetic events, by which copies of the observed data set were created in which the observed events were replaced by synthetic events based on their original location of occurrence. For the analysis to introduce randomness concerning the ‘when and where’ that event may occur, we have several recommendations. First, pathways of events could be altered. When considering the moving precipitation fields as 3-dimensional objects (in x,y,t), this corresponds to an altering of the orientation of the objects and an altering of the shape of the objects, where the centre of gravity (in x,y,t) remains the same. Second, the centre of gravity of events could stochastically be moved around. The farther events are moved from their original location of occurrence, the more likely that events would start to overlap and the more likely that the general atmospheric pattern would be disturbed. Third, as a more rigorous version of the second option, a spatio-temporal point process (STPP) could applied, in which the catalogue of synthetic events could be used to build continuous data starting from an empty synthetic space-time continuum. E.g. Cowpertwait et al. (2013) apply a flexible STPP, in which ‘independent superposed point processes are used to allow for different storm types (e.g. convective and stratiform).’ However, if an STPP is applied to large-scale precipitation events, the challenge arises to place the synthetic events in space and time in such a way that the large-scale atmospheric patterns are well simulated. We expect this to pose a significant challenge for the event-based approach.
7.6 Compound events
Finally, we would like to point out that the methodology presented could relatively easily be extended to handle multiple ‘compound’ variables (Leonard et al. 2014; Ridder et al. 2018; Samuels 2018). The key difference between the generation procedure for a single variable (e.g. precipitation only) and for compound variables (e.g. precipitation and low pressure) would be in the event identification procedure. Particular types of events, e.g. tropical cyclones, could potentially be relatively clearly delineated in both a single and a compound variable framework. However, in a compound variable framework, (relatively large) low pressure systems may lead to the merging of precipitation clusters, which, when considered in a single variable framework, would be considered separate events. For future research, we recommend that studies of compound variables make use of the framework and methodology presented here.
8 Conclusions
A framework for event-based, dynamic spatio-temporal probabilistic analysis was proposed. Under the framework, a specific suite of models and methods were proposed and tested for generating synthetic gridded hourly precipitation time series with the potential of global coverage. The generated synthetic data comprised a much larger variety of dynamic spatio-temporal events than the observed (OBJ1). The statistical patterns of the synthetic descriptors of the dynamic spatio-temporal events showed good agreement with the observed (OBJ2). Physical concepts were included in the procedures of dynamic event identification and classification (OBJ3).
Making use of standard methods of local, event-based, probabilistic analysis, the synthetic data set (generator approach) was compared to the observed data set (direct approach). The generator approach provided smoother spatial patterns of extremes, which were very pronounced for the GPD parameters and somewhat less pronounced, but still significant, for the return level estimates. This spatial pattern has the potential to provide insight into light and heavy tail behaviour of local distributions, making use of the newly introduced concept of ‘dynamic expansion of information’.
References
Ailliot P, Allard D, Monbet V, Naveau P (2015) Stochastic weather generators: an overview of weather type models. J Soc Fr Statistique 156(1):101–113
Andreadis KM, Clark EA, Wood AW, Hamlet AF, Lettenmaier DP (2005) Twentieth-century drought in the conterminous united states. J Hydrometeorol 6(6):985–1001. https://doi.org/10.1175/JHM450.1
Bárdossy A, Pegram G (2009) Copula based multisite model for daily precipitation simulation. Hydrol Earth Syst Sci 13(12):2299–2314. https://doi.org/10.5194/hess-13-2299-2009
Bortot P, Coles S, Tawn J (2000) The multivariate gaussian tail model: an application to oceanographic data. J R Stat Soc Ser C (Appl Stat) 49(1):31–049. https://doi.org/10.1111/1467-9876.00177
Burton A, Kilsby CG, Fowler H, Cowpertwait P, O’connell P (2008) Rainsim: a spatial-temporal stochastic rainfall modelling system. Environ Model Softw 23(12):1356–1369. https://doi.org/10.1016/j.envsoft.2008.04.003
Cameron D, Beven K, Tawn J, Blazkova S, Naden P (1999) Flood frequency estimation by continuous simulation for a gauged upland catchment (with uncertainty). J Hydrol 219(3):169–187. https://doi.org/10.1016/S0022-1694(99)00057-8
Coles S, Bawa J, Trenner L, Dorazio P (2001) An introduction to statistical modeling of extreme values, vol 208. Springer, Berlin. https://doi.org/10.1007/978-1-4471-3675-0
Cooley D, Nychka D, Naveau P (2007) Bayesian spatial modeling of extreme precipitation return levels. J Am Stat Assoc 102(479):824–840. https://doi.org/10.1198/016214506000000780
Corzo Perez G, Van Huijgevoort M, Voß F, Van Lanen H (2011) On the spatio-temporal analysis of hydrological droughts from global hydrological models. Hydrol Earth Syst Sci 15(9):2963–2978. https://doi.org/10.5194/hess-15-2963-2011
Cowpertwait PS (1995) A generalized spatial-temporal model of rainfall based on a clustered point process. Proc R Soc Lond A 450(1938):163–175. https://doi.org/10.1098/rspa.1995.0077
Cowpertwait P, Ocio D, Collazos G, de Cos O, Stocker C (2013) Regionalised spatiotemporal rainfall and temperature models for flood studies in the Basque country, Spain. Hydrol Earth Syst Sci. https://doi.org/10.5194/hess-17-479-2013
Davison AC, Padoan SA, Ribatet M et al (2012) Statistical modeling of spatial extremes. Stat Sci 27(2):161–186. https://doi.org/10.1214/11-STS376
Desai B, Maskrey A, Peduzzi P, De Bono A, Herold C (2015) Making development sustainable: the future of disaster risk management. Glob Assess Rep Disaster Risk Reduct 910:333.7–333.9
Diederen D, Liu Y, Gouldby B, Diermanse F, Vorogushyn S (2019) Stochastic generation of spatially coherent river discharge peaks for continental event-based flood risk assessment. Nat Hazards Earth Syst Sci 19(5):1041–1053. https://doi.org/10.5194/nhess-19-1041-2019
Eagleson PS (1972) Dynamics of flood frequency. Water Resour Res 8(4):878–898. https://doi.org/10.1029/WR008i004p00878
Fowler H, Kilsby C, O’connell P, Burton A (2005) A weather-type conditioned multi-site stochastic rainfall model for the generation of scenarios of climatic variability and change. J Hydrol 308(1–4):50–66. https://doi.org/10.1016/j.jhydrol.2004.10.021
Genest C, Favre AC (2007) Everything you always wanted to know about copula modeling but were afraid to ask. J Hydrol Eng 12(4):347–368. https://doi.org/10.1061/(ASCE)1084-0699(2007)12:4(347)
Gilleland E, Nychka D, Schneider U (2006) Spatial models for the distribution of extremes. In: Hierarchical modelling for the environmental sciences: statistical methods and applications. Oxford University Press on Demand, pp 170–183, https://doi.org/10.1086/523192
Gouldby B, Wyncoll D, Panzeri M, Franklin M, Hunt T, Hames D, Tozer N, Hawkes P, Dornbusch U, Pullen T (2017) Multivariate extreme value modelling of sea conditions around the coast of england. Proc Inst Civ Eng Marit Eng 170(1):3–20. https://doi.org/10.1680/jmaen.2016.16
Hebson C, Wood EF (1982) A derived flood frequency distribution using horton order ratios. Water Resour Res 18(5):1509–1518. https://doi.org/10.1029/WR018i005p01509
Heffernan JE, Tawn JA (2004) A conditional approach for multivariate extreme values (with discussion). J R Stat Soc Ser B (Stat Methodol) 66(3):497–546. https://doi.org/10.1111/j.1467-9868.2004.02050.x
Hundecha Y, Pahlow M, Schumann A (2009) Modeling of daily precipitation at multiple locations using a mixture of distributions to characterize the extremes. Water Resour Res. https://doi.org/10.1029/2008WR007453
Katz RW, Parlange MB, Naveau P (2002) Statistics of extremes in hydrology. Adv Water Resour 25(8–12):1287–1304. https://doi.org/10.1016/S0309-1708(02)00056-8
Keef C, Tawn J, Svensson C (2009) Spatial risk assessment for extreme river flows. J R Stat Soc Ser C (Appl Stat) 58(5):601–618. https://doi.org/10.1111/j.1467-9876.2009.00672.x
Kidd C, Bauer P, Turk J, Huffman G, Joyce R, Hsu KL, Braithwaite D (2012) Intercomparison of high-resolution precipitation products over northwest europe. J Hydrometeorol 13(1):67–83. https://doi.org/10.1175/JHM-D-11-042.1
Kohonen T (2012) Self-organization and associative memory, vol 8. Springer, Berlin. https://doi.org/10.1007/978-3-642-88163-3
Lamb R, Keef C, Tawn J, Laeger S, Meadowcroft I, Surendran S, Dunning P, Batstone C (2010) A new method to assess the risk of local and widespread flooding on rivers and coasts. J Flood Risk Manag 3(4):323–336. https://doi.org/10.1111/j.1753-318X.2010.01081.x
Ledford AW, Tawn JA (1996) Statistics for near independence in multivariate extreme values. Biometrika 83(1):169–187. https://doi.org/10.1093/biomet/83.1.169
Leonard M, Westra S, Phatak A, Lambert M, van den Hurk B, McInnes K, Risbey J, Schuster S, Jakob D, Stafford-Smith M (2014) A compound event framework for understanding extreme impacts. Wiley Interdiscip Rev Clim Change 5(1):113–128. https://doi.org/10.1002/wcc.252
Merz R, Blöschl G (2008) Flood frequency hydrology: 1. Temporal, spatial, and causal expansion of information. Water Resour Res. https://doi.org/10.1029/2007WR006745
Nelsen RB (2007) An introduction to copulas. Springer, Berlin. https://doi.org/10.1007/0-387-28678-0
Quinn N, Bates PD, Neal J, Smith A, Wing O, Sampson C, Smith J, Heffernan J (2019) The spatial dependence of flood hazard and risk in the United States. Water Resour Res. https://doi.org/10.1029/2018WR024205
Ridder N, de Vries H, Drijfhout S (2018) The role of atmospheric rivers in compound events consisting of heavy precipitation and high storm surges along the dutch coast. Nat Hazards Earth Syst Sci 18(12):3311–3326. https://doi.org/10.5194/nhess-18-3311-2018
Rodriguez-Iturbe I, Cox DR, Isham V (1987) Some models for rainfall based on stochastic point processes. Proc R Soc Lond A 410(1839):269–288. https://doi.org/10.1098/rspa.1987.0039
Saha S, Moorthi S, Pan HL, Wu X, Wang J, Nadiga S, Tripp P, Kistler R, Woollen J, Behringer D et al (2010) The ncep climate forecast system reanalysis. Bull Am Meteorol Soc 91(8):1015–1058. https://doi.org/10.1175/2010BAMS3001.1
Samuels P (2018) Flooding and multi-hazards. J Flood Risk Manag 11:S557–S558. https://doi.org/10.1111/jfr3.12341
Scarrott C, MacDonald A (2012) A review of extreme value threshold estimation and uncertainty quantification. REVSTAT-Stat J 10(1):33–60
Serinaldi F (2009) Copula-based mixed models for bivariate rainfall data: an empirical study in regression perspective. Stoch Env Res Risk Assess 23(5):677–693. https://doi.org/10.1007/s00477-008-0249-z
Serinaldi F, Kilsby CG (2014) Simulating daily rainfall fields over large areas for collective risk estimation. J Hydrol 512:285–302. https://doi.org/10.1016/j.jhydrol.2014.02.043
Sharkey P, Winter HC (2017) A Bayesian spatial hierarchical model for extreme precipitation in great Britain. ArXiv preprint arXiv:171002091, https://doi.org/10.1002/env.2529
Silverman BW (1986) Density estimation for statistics and data analysis. Chapman & Hall, London
Silverman BW (2018) Density estimation for statistics and data analysis. Routledge, Abingdon. https://doi.org/10.1201/9781315140919
Srikanthan R, Pegram GG (2009) A nested multisite daily rainfall stochastic generation model. J Hydrol 371(1–4):142–153. https://doi.org/10.1016/j.jhydrol.2009.03.025
Svensson C, Kjeldsen TR, Jones DA (2013) Flood frequency estimation using a joint probability approach within a monte carlo framework. Hydrol Sci J 58(1):8–27. https://doi.org/10.1080/02626667.2012.746780
Taleb NN (2007) The black swan: the impact of the highly improbable, vol 2. Random House, New York
Tarasova L, Merz R, Kiss A, Basso S, Blöschl G, Merz B, Viglione A, Plötner S, Guse B, Schumann A, Fischer S, Ahrens B, Anwar F, Bárdossy A, Bühler P, Haberlandt U, Kreibich H, Krug A, Lun D, Müller-Thomy H, Pidoto R, Primo C, Seidel J, Vorogushyn S, Wietzke L (2019) Causative classification of river flood events. Wiley Interdiscip Rev Water. https://doi.org/10.1002/wat2.1353
Vallam P, Qin XS (2016) Multi-site rainfall simulation at tropical regions: a comparison of three types of generators. Meteorol Appl 23(3):425–437. https://doi.org/10.1002/met.1567
Verdin A, Rajagopalan B, Kleiber W, Katz RW (2015) Coupled stochastic weather generation using spatial and generalized linear models. Stoch Env Res Risk Assess 29(2):347–356. https://doi.org/10.1007/s00477-014-0911-6
Vorogushyn S, Bates PD, de Bruijn K, Castellarin A, Kreibich H, Priest S, Schröter K, Bagli S, Blöschl G, Domeneghetti A et al (2018) Evolutionary leap in large-scale flood risk assessment needed. Wiley Interdiscip Rev Water 5(2):e1266. https://doi.org/10.1002/wat2.1266
Vu TM, Mishra AK, Konapala G, Liu D (2018) Evaluation of multiple stochastic rainfall generators in diverse climatic regions. Stoch Env Res Risk Assess 32(5):1337–1353. https://doi.org/10.1007/s00477-017-1458-0
Wilby R, Tomlinson O, Dawson C (2003) Multi-site simulation of precipitation by conditional resampling. Clim Res 23(3):183–194. https://doi.org/10.3354/cr023183
Wilks DS (1995) Chapter 9 methods for multivariate data. In: Statistical methods in the atmospheric sciences, international geophysics, vol 59. Academic Press, pp 359–428, https://doi.org/10.1016/S0074-6142(06)80045-8
Wilks D (1998) Multisite generalization of a daily stochastic precipitation generation model. J Hydrol 210(1–4):178–191. https://doi.org/10.1016/S0022-1694(98)00186-3
Wyncoll D, Gouldby B (2015) Integrating a multivariate extreme value method within a system flood risk analysis model. J Flood Risk Manag 8(2):145–160. https://doi.org/10.1111/jfr3.12069
Zhang Q, Li J, Singh VP, Xu CY (2013) Copula-based spatio-temporal patterns of precipitation extremes in china. Int J Climatol 33(5):1140–1152. https://doi.org/10.1002/joc.3499
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research is part of the ‘System-Risk’ project and has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie Grant agreement No. 676027. DD completed this work whilst registered for a PhD at the Open University Affiliated Research Centre at HR Wallingford Ltd.
Appendix A
Appendix A
To check for additional statistical patterns, we took a subset of locations outlined on a grid in the BI; Fig. 10).

Subset of locations for comparison of statistical patterns
Figure 11 shows spatial correlations, using monthly and weekly maxima. Generally, the generator reproduces the spatial correlations very well. However, this was expected using the simple space-time placement process used, described in Sect. 5.2. We recommend that, when more variability is introduced using one of the several options listed in Sect. 7, these patterns are closely monitored.

Correlation (Spearman) matrices of monthly and weekly maxima
Figure 12 shows auto-correlations (up to 5-th order), using weekly, monthly and yearly maxima. Weekly and monthly auto-correlations are fairly well reproduced by the generator, which, again, was expected using the space-time placement process. Yearly auto-correlations are not well reproduced, where some individual values show potentially significant auto-correlation. We did not implement any measures to capture inter-annual variability, so we failed to capture these patterns. However, we think that, due to the large variation between different orders of time lags, these yearly auto-correlations are largely spurious and that it is therefore questionable whether they should be captured.

Auto-correlation (Spearman) for yearly, monthly and weekly maxima, from first up to fifth order
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Diederen, D., Liu, Y. Dynamic spatio-temporal generation of large-scale synthetic gridded precipitation: with improved spatial coherence of extremes. Stoch Environ Res Risk Assess 34, 1369–1383 (2020). https://doi.org/10.1007/s00477-019-01724-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-019-01724-9