
Abstract
2-Opt is probably the most basic local search heuristic for the TSP. This heuristic achieves amazingly good results on “real world” Euclidean instances both with respect to running time and approximation ratio. There are numerous experimental studies on the performance of 2-Opt. However, the theoretical knowledge about this heuristic is still very limited. Not even its worst case running time on 2-dimensional Euclidean instances was known so far. We clarify this issue by presenting, for every \(p\in\mathbb{N}\), a family of L p instances on which 2-Opt can take an exponential number of steps.
Previous probabilistic analyses were restricted to instances in which n points are placed uniformly at random in the unit square [0,1]2, where it was shown that the expected number of steps is bounded by \(\tilde{O}(n^{10})\) for Euclidean instances. We consider a more advanced model of probabilistic instances in which the points can be placed independently according to general distributions on [0,1]d, for an arbitrary d≥2. In particular, we allow different distributions for different points. We study the expected number of local improvements in terms of the number n of points and the maximal density ϕ of the probability distributions. We show an upper bound on the expected length of any 2-Opt improvement path of \(\tilde{O}(n^{4+1/3}\cdot\phi^{8/3})\). When starting with an initial tour computed by an insertion heuristic, the upper bound on the expected number of steps improves even to \(\tilde{O}(n^{4+1/3-1/d}\cdot\phi^{8/3})\). If the distances are measured according to the Manhattan metric, then the expected number of steps is bounded by \(\tilde{O}(n^{4-1/d}\cdot\phi)\). In addition, we prove an upper bound of \(O(\sqrt[d]{\phi})\) on the expected approximation factor with respect to all L p metrics.
Let us remark that our probabilistic analysis covers as special cases the uniform input model with ϕ=1 and a smoothed analysis with Gaussian perturbations of standard deviation σ with ϕ∼1/σ d.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
In the traveling salesperson problem (TSP), we are given a set of vertices and for each pair of distinct vertices a distance. The goal is to find a tour of minimum length that visits every vertex exactly once and returns to the initial vertex at the end. Despite many theoretical analyses and experimental evaluations of the TSP, there is still a considerable gap between the theoretical results and the experimental observations. One important special case is the Euclidean TSP in which the vertices are points in \(\mathbb {R}^{d}\), for some \(d\in\mathbb{N}\), and the distances are measured according to the Euclidean metric. This special case is known to be NP-hard in the strong sense [15], but it admits a polynomial time approximation scheme (PTAS), shown independently in 1996 by Arora [1] and Mitchell [13]. These approximation schemes are based on dynamic programming. However, the most successful algorithms on practical instances rely on the principle of local search and very little is known about their complexity.
The 2-Opt algorithm is probably the most basic local search heuristic for the TSP. 2-Opt starts with an arbitrary initial tour and incrementally improves this tour by making successive improvements that exchange two of the edges in the tour with two other edges. More precisely, in each improving step the 2-Opt algorithm selects two edges {u 1,u 2} and {v 1,v 2} from the tour such that u 1,u 2,v 1,v 2 are distinct and appear in this order in the tour, and it replaces these edges by the edges {u 1,v 1} and {u 2,v 2}, provided that this change decreases the length of the tour. The algorithm terminates in a local optimum in which no further improving step is possible. We use the term 2-change to denote a local improvement made by 2-Opt. This simple heuristic performs amazingly well on “real-life” Euclidean instances like, e.g., the ones in the well-known TSPLIB [17]. Usually the 2-Opt heuristic needs a clearly subquadratic number of improving steps until it reaches a local optimum and the computed solution is within a few percentage points of the global optimum [7].
There are numerous experimental studies on the performance of 2-Opt. However, the theoretical knowledge about this heuristic is still very limited. Let us first discuss the number of local improvement steps made by 2-Opt before it finds a locally optimal solution. When talking about the number of local improvements, it is convenient to consider the state graph. The vertices in this graph correspond to the possible tours and an arc from a vertex v to a vertex u is contained if u is obtained from v by performing an improving 2-Opt step. On the positive side, van Leeuwen and Schoone consider a 2-Opt variant for the Euclidean plane in which only steps are allowed that remove a crossing from the tour. Such steps can introduce new crossings, but van Leeuwen and Schoone [20] show that after O(n 3) steps, 2-Opt finds a tour without any crossing. On the negative side, Lueker [12] constructs TSP instances whose state graphs contain exponentially long paths. Hence, 2-Opt can take an exponential number of steps before it finds a locally optimal solution. This result is generalized to k-Opt, for arbitrary k≥2, by Chandra, Karloff, and Tovey [3]. These negative results, however, use arbitrary graphs that cannot be embedded into low-dimensional Euclidean space. Hence, they leave open the question as to whether it is possible to construct Euclidean TSP instances on which 2-Opt can take an exponential number of steps, which has explicitly been asked by Chandra, Karloff, and Tovey. We resolve this question by constructing such instances in the Euclidean plane. In chip design applications, often TSP instances arise in which the distances are measured according to the Manhattan metric. Also for this metric and for every other L p metric, we construct instances with exponentially long paths in the 2-Opt state graph.
Theorem 1
For every p∈{1,2,3,…}∪{∞} and \(n\in\mathbb {N}=\{1,2,3,\ldots\}\), there is a two-dimensional TSP instance with 16n vertices in which the distances are measured according to the L p metric and whose state graph contains a path of length 2n+4−22.
For Euclidean instances in which n points are placed independently uniformly at random in the unit square, Kern [8] shows that the length of the longest path in the state graph is bounded by O(n 16) with probability at least 1−c/n for some constant c. Chandra, Karloff, and Tovey [3] improve this result by bounding the expected length of the longest path in the state graph by O(n 10logn). That is, independent of the initial tour and the choice of the local improvements, the expected number of 2-changes is bounded by O(n 10logn). For instances in which n points are placed uniformly at random in the unit square and the distances are measured according to the Manhattan metric, Chandra, Karloff, and Tovey show that the expected length of the longest path in the state graph is bounded by O(n 6logn).
We consider a more general probabilistic input model and improve the previously known bounds. The probabilistic model underlying our analysis allows different vertices to be placed independently according to different continuous probability distributions in the unit hypercube [0,1]d, for some constant dimension d≥2. The distribution of a vertex v i is defined by a density function f i :[0,1]d→[0,ϕ] for some given ϕ≥1. Our upper bounds depend on the number n of vertices and the upper bound ϕ on the density. We denote instances created by this input model as ϕ-perturbed Euclidean or Manhattan instances, depending on the underlying metric. The parameter ϕ can be seen as a parameter specifying how close the analysis is to a worst case analysis since the larger ϕ is, the better can worst case instances be approximated by the distributions. For ϕ=1 and d=2, every point has a uniform distribution over the unit square, and hence the input model equals the uniform model analyzed before. Our results narrow the gap between the subquadratic number of improving steps observed in experiments [7] and the upper bounds from the probabilistic analysis. With slight modifications, this model also covers a smoothed analysis, in which first an adversary specifies the positions of the points and after that each position is slightly perturbed by adding a Gaussian random variable with small standard deviation σ. In this case, one has to set \(\phi=1/(\sqrt{2\pi}\sigma)^{d}\).
We prove the following theorem about the expected length of the longest path in the 2-Opt state graph for the three probabilistic input models discussed above. It is assumed that the dimension d≥2 is an arbitrary constant.
Theorem 2
The expected length of the longest path in the 2-Opt state graph
-
(a)
is O(n 4⋅ϕ) for ϕ-perturbed Manhattan instances with n points.
-
(b)
is O(n 4+1/3⋅log(nϕ)⋅ϕ 8/3) for ϕ-perturbed Euclidean instances with n points.
Usually, 2-Opt is initialized with a tour computed by some tour construction heuristic. One particular class is that of insertion heuristics, which insert the vertices one after another into the tour. We show that also from a theoretical point of view, using such an insertion heuristic yields a significant improvement for metric TSP instances because the initial tour 2-Opt starts with is much shorter than the longest possible tour. In the following theorem, we summarize our results on the expected number of local improvements.
Theorem 3
The expected number of steps performed by 2-Opt
-
(a)
is O(n 4−1/d⋅logn⋅ϕ) on ϕ-perturbed Manhattan instances with n points when 2-Opt is initialized with a tour obtained by an arbitrary insertion heuristic.
-
(b)
is O(n 4+1/3−1/d⋅log2(nϕ)⋅ϕ 8/3) on ϕ-perturbed Euclidean instances with n points when 2-Opt is initialized with a tour obtained by an arbitrary insertion heuristic.
In fact, our analysis shows not only that the expected number of local improvements is polynomially bounded but it also shows that the second moment and hence the variance is bounded polynomially for ϕ-perturbed Manhattan instances. For the Euclidean metric, we cannot bound the variance but the 3/2-th moment polynomially.
In [5], we also consider a model in which an arbitrary graph G=(V,E) is given along with, for each edge e∈E, a probability distribution according to which the edge length d(e) is chosen independently of the other edge lengths. Again, we restrict the choice of distributions to distributions that can be represented by density functions f e :[0,1]→[0,ϕ] with maximal density at most ϕ for a given ϕ≥1. We denote inputs created by this input model as ϕ-perturbed graphs. Observe that in this input model only the distances are perturbed whereas the graph structure is not changed by the randomization. This can be useful if one wants to explicitly prohibit certain edges. However, if the graph G is not complete, one has to initialize 2-Opt with a Hamiltonian cycle to start with. We prove that in this model the expected length of the longest path in the 2-Opt state graph is O(|E|⋅n 1+o(1)⋅ϕ). As the techniques for proving this result are different from the ones used in this article, we will present it in a separate journal article.
As in the case of running time, the good approximation ratios obtained by 2-Opt on practical instances cannot be explained by a worst-case analysis. In fact, there are quite negative results on the worst-case behavior of 2-Opt. For example, Chandra, Karloff, and Tovey [3] show that there are Euclidean instances in the plane for which 2-Opt has local optima whose costs are \(\varOmega(\frac{\log n}{\log\log n})\) times larger than the optimal costs. However, the same authors also show that the expected approximation ratio of the worst local optimum for instances with n points drawn uniformly at random from the unit square is bounded from above by a constant. We generalize their result to our input model in which different points can have different distributions with bounded density ϕ and to all L p metrics.
Theorem 4
Let \(p\in\mathbb{N}\cup\{\infty\}\). For ϕ-perturbed L p instances, the expected approximation ratio of the worst tour that is locally optimal for 2-Opt is \(O(\sqrt[d]{\phi})\).
The remainder of the paper is organized as follows. We start by stating some basic definitions and notation in Sect. 2. In Sect. 3, we present the lower bounds. In Sect. 4, we analyze the expected number of local improvements and prove Theorems 2 and 3. Finally, in Sects. 5 and 6, we prove Theorem 4 about the expected approximation factor and we discuss the relation between our analysis and a smoothed analysis.
2 Preliminaries
An instance of the TSP consists of a set V={v 1,…,v n } of vertices (depending on the context, synonymously referred to as points) and a symmetric distance function \(\mathsf {d}\colon V\times V\to\mathbb{R}_{\ge0}\) that associates with each pair {v i ,v j } of distinct vertices a distance d(v i ,v j )=d(v j ,v i ). The goal is to find a Hamiltonian cycle of minimum length. We also use the term tour to denote a Hamiltonian cycle. We define \(\mathbb{N}=\{1,2,3,\ldots\}\), and for a natural number \(n\in\mathbb{N}\), we denote the set {1,…,n} by [n].
A pair (V,d) of a nonempty set V and a function \(\mathsf {d}\colon V\times V\to\mathbb{R}_{\ge0}\) is called a metric space if for all x,y,z∈V the following properties are satisfied:
-
(a)
d(x,y)=0 if and only if x=y (reflexivity),
-
(b)
d(x,y)=d(y,x) (symmetry), and
-
(c)
d(x,z)≤d(x,y)+d(y,z) (triangle inequality).
If (V,d) is a metric space, then d is called a metric on V. A TSP instance with vertices V and distance function d is called metric TSP instance if (V,d) is a metric space.
A well-known class of metrics on \(\mathbb{R}^{d}\) is the class of L p metrics. For \(p\in\mathbb{N}\), the distance d p (x,y) of two points \(x\in\mathbb{R}^{d}\) and \(y\in\mathbb{R}^{d}\) with respect to the L p metric is given by \(\mathsf{d}_{p}(x,y) = \sqrt[p]{|x_{1}-y_{1}|^{p}+\cdots+|x_{d}-y_{d}|^{p}}\). The L 1 metric is often called Manhattan metric, and the L 2 metric is well-known as Euclidean metric. For p→∞, the L p metric converges to the L ∞ metric defined by the distance function d ∞(x,y)=max{|x 1−y 1|,…,|x d −y d |}. A TSP instance (V,d) with \(V\subseteq\mathbb{R}^{d}\) in which d equals d p restricted to V is called an L p instance. We also use the terms Manhattan instance and Euclidean instance to denote L 1 and L 2 instances, respectively. Furthermore, if p is clear from context, we write d instead of d p .
A tour construction heuristic for the TSP incrementally constructs a tour and stops as soon as a valid tour is created. Usually, a tour constructed by such a heuristic is used as the initial solution 2-Opt starts with. A well-known class of tour construction heuristics for metric TSP instances are so-called insertion heuristics. These heuristics insert the vertices into the tour one after another, and every vertex is inserted between two consecutive vertices in the current tour where it fits best. To make this more precise, let T i denote a subtour on a subset S i of i vertices, and suppose v∉S i is the next vertex to be inserted. If (x,y) denotes an edge in T i that minimizes d(x,v)+d(v,y)−d(x,y), then the new tour T i+1 is obtained from T i by deleting the edge (x,y) and adding the edges (x,v) and (v,y). Depending on the order in which the vertices are inserted into the tour, one distinguishes between several different insertion heuristics. Rosenkrantz et al. [18] show an upper bound of ⌈logn⌉+1 on the approximation factor of any insertion heuristic on metric TSP instances. Furthermore, they show that two variants which they call nearest insertion and cheapest insertion achieve an approximation ratio of 2 for metric TSP instances. The nearest insertion heuristic always inserts the vertex with the smallest distance to the current tour (i.e., the vertex v∉S i that minimizes \(\min_{x\in S_{i}}\mathsf {d}(x,v)\)), and the cheapest insertion heuristic always inserts the vertex whose insertion leads to the cheapest tour T i+1.
3 Exponential Lower Bounds
In this section, we answer Chandra, Karloff, and Tovey’s question [3] as to whether it is possible to construct TSP instances in the Euclidean plane on which 2-Opt can take an exponential number of steps. We present, for every \(p\in\mathbb{N}\cup\{\infty\}\), a family of two-dimensional L p instances with exponentially long sequences of improving 2-changes. In Sect. 3.1, we present our construction for the Euclidean plane, and in Sect. 3.2 we extend this construction to general L p metrics.
3.1 Exponential Lower Bound for the Euclidean Plane
In Lueker’s construction [12] many of the 2-changes remove two edges that are far apart in the current tour in the sense that many vertices are visited between them. Our construction differs significantly from the previous one as the 2-changes in our construction affect the tour only locally. The instances we construct are composed of gadgets of constant size. Each of these gadgets has a zero state and a one state, and there exists a sequence of improving 2-changes starting in the zero state and eventually leading to the one state. Let G 0,…,G n−1 denote these gadgets. If gadget G i with i>0 has reached state one, then it can be reset to its zero state by gadget G i−1. The crucial property of our construction is that whenever a gadget G i−1 changes its state from zero to one, it resets gadget G i twice. Hence, if in the initial tour, gadget G 0 is in its zero state and every other gadget is in state one, then for every i with 0≤i≤n−1, gadget G i performs 2i state changes from zero to one as, for i>0, gadget G i is reset 2i times.
Every gadget is composed of 2 subgadgets, which we refer to as blocks. Each of these blocks consists of 4 vertices that are consecutively visited in the tour. For i∈{0,…,n−1} and j∈[2], let \(\mathcal{B}^{i}_{1}\) and \(\mathcal{B}^{i}_{2}\) denote the blocks of gadget G i and let \(A^{i}_{j}\), \(B^{i}_{j}\), \(C^{i}_{j}\), and \(D^{i}_{j}\) denote the four points \(\mathcal{B}^{i}_{j}\) consists of. If one ignores certain intermediate configurations that arise when one gadget resets another one, our construction ensures the following property: The points \(A^{i}_{j}\), \(B^{i}_{j}\), \(C^{i}_{j}\), and \(D^{i}_{j}\) are always visited consecutively in the tour either in the order \(A^{i}_{j} B^{i}_{j} C^{i}_{j} D^{i}_{j}\) or in the order \(A^{i}_{j} C^{i}_{j} B^{i}_{j} D^{i}_{j}\).
Observe that the change from one of these configurations to the other corresponds to a single 2-change in which the edges \(A^{i}_{j}B^{i}_{j}\) and \(C^{i}_{j}D^{i}_{j}\) are replaced by the edges \(A^{i}_{j}C^{i}_{j}\) and \(B^{i}_{j}D^{i}_{j}\), or vice versa. In the following, we assume that the sum \(\mathsf{d}(A^{i}_{j},B^{i}_{j})+\mathsf{d}(C^{i}_{j},D^{i}_{j})\) is strictly smaller than the sum \(\mathsf{d}(A^{i}_{j},C^{i}_{j})+\mathsf{d}(B^{i}_{j},D^{i}_{j})\), and we refer to the configuration \(A^{i}_{j}B^{i}_{j}C^{i}_{j}D^{i}_{j}\) as the short state of the block and to the configuration \(A^{i}_{j}C^{i}_{j}B^{i}_{j}D^{i}_{j}\) as the long state. Another property of our construction is that neither the order in which the blocks are visited nor the order of the gadgets is changed during the sequence of 2-changes. Again with the exception of the intermediate configurations, the order in which the blocks are visited is \(\mathcal{B}^{0}_{1}\mathcal{B}^{0}_{2}\mathcal {B}^{1}_{1}\mathcal{B}^{1}_{2} \cdots \mathcal{B}^{n-1}_{1}\mathcal{B}^{n-1}_{2}\) (see Fig. 1).

In the illustration, we use m to denote n−1. Every tour that occurs in the sequence of 2-changes contains the thick edges. For each block, either both solid or both dashed edges are contained. In the former case the block is in its short state; in the latter case the block is in its long state
Due to the aforementioned properties, we can describe every non-intermediate tour that occurs during the sequence of 2-changes completely by specifying for every block if it is in its short state or in its long state. In the following, we denote the state of a gadget G i by a pair (x 1,x 2) with x j ∈{S,L}, meaning that block \(\mathcal{B}^{i}_{j}\) is in its short state if and only if x j =S. Since every gadget consists of two blocks, there are four possible states for each gadget. However, only three of them appear in the sequence of 2-changes, namely (L,L), (S,L), and (S,S). We call state (L,L) the zero state and state (S,S) the one state. In order to guarantee the existence of an exponentially long sequence of 2-changes, the gadgets we construct possess the following property.
Property 5
If, for i∈{0,…,n−2}, gadget G i is in state (L,L) (or (S,L), respectively) and gadget G i+1 is in state (S,S), then there exists a sequence of seven consecutive 2-changes terminating with gadget G i being in state (S,L) (or state (S,S), respectively) and gadget G i+1 in state (L,L). In this sequence only edges of and between the gadgets G i and G i+1 are involved.
We describe in Sect. 3.1.1 how sequences of seven consecutive 2-changes with the desired properties can be constructed. Then we show in Sect. 3.1.2 that the gadgets can be embedded into the Euclidean plane such that all of these 2-changes are improving. If Property 5 is satisfied and if in the initial tour gadget G 0 is in its zero state (L,L) and every other gadget is in its one state (S,S), then there exists an exponentially long sequence of 2-changes in which gadget G i changes 2i times from state zero to state one, as the following lemma shows. An example with three gadgets is also depicted in Fig. 2.

This figure shows an example with three gadgets. It shows the 15 configurations that these gadgets assume during the sequence of 2-changes, excluding the intermediate configurations that arise when one gadget resets another one. Gadgets that are involved in the transformation from configuration i to configuration i+1 are shown in gray. For example, in the step from the first to the second configuration, the first block \(\mathcal{B}_{1}^{0}\) of gadget G 0 resets the two blocks of gadget G 1. That is, these three blocks follow the sequence of seven 2-changes from Property 5. On the other hand, in the step from the third to the fourth configuration only the first block \(\mathcal{B}_{1}^{2}\) of gadget G 2 is involved. It changes from its long state to its short state by a single 2-change. As this figure shows an example with three gadgets, the total number of 2-changes performed according to Lemma 6 is 23+3−0−14=50. This is indeed the case because 6 of the 14 shown steps correspond to sequences of seven 2-changes while 8 steps correspond to single 2-changes
Lemma 6
If, for i∈{0,…,n−1}, gadget G i is in the zero state (L,L) and all gadgets G j with j>i are in the one state (S,S), then there exists a sequence of 2n+3−i−14 consecutive 2-changes in which only edges of and between the gadgets G j with j≥i are involved and that terminates in a state in which all gadgets G j with j≥i are in the one state (S,S).
Proof
We prove the lemma by induction on i. If gadget G n−1 is in state (L,L), then it can change its state with two 2-changes to (S,S) without affecting the other gadgets. This is true because the two blocks of gadget G n−1 can, one after another, change from their long state \(A^{n-1}_{j}C^{n-1}_{j}B^{n-1}_{j}D^{n-1}_{j}\) to their short state \(A^{n-1}_{j}B^{n-1}_{j}C^{n-1}_{j}D^{n-1}_{j}\) by a single 2-change. Hence, the lemma is true for i=n−1 because 2n+3−(n−1)−14=2.
Now assume that the lemma is true for i+1 and consider a state in which gadget G i is in state (L,L) and all gadgets G j with j>i are in state (S,S). Due to Property 5, there exists a sequence of seven consecutive 2-changes in which only edges of and between G i and G i+1 are involved, terminating with G i being in state (S,L) and G i+1 being in state (L,L). By the induction hypothesis there exists a sequence of (2n+2−i−14) 2-changes after which all gadgets G j with j>i are in state (S,S). Then, due to Property 5, there exists a sequence of seven consecutive 2-changes in which only G i changes its state from (S,L) to (S,S) while resetting gadget G i+1 again from (S,S) to (L,L). Hence, we can apply the induction hypothesis again, yielding that after another (2n+2−i−14) 2-changes all gadgets G j with j≥i are in state (S,S). This concludes the proof as the number of 2-changes performed is 14+2(2n+2−i−14)=2n+3−i−14. □
In particular, this implies that, given Property 5, one can construct instances consisting of 2n gadgets, i.e., 16n points, whose state graphs contain paths of length 22n+3−14>2n+4−22, as desired in Theorem 1.
3.1.1 Detailed Description of the Sequence of Steps
Now we describe in detail how a sequence of 2-changes satisfying Property 5 can be constructed. First, we assume that gadget G i is in state (S,L) and that gadget G i+1 is in state (S,S). Under this assumption, there are three consecutive blocks, namely \(\mathcal{B}^{i}_{2}\), \(\mathcal{B}^{i+1}_{1}\), and \(\mathcal{B}^{i+1}_{2}\), such that the leftmost one \(\mathcal{B}^{i}_{2}\) is in its long state, and the other blocks are in their short states. We need to find a sequence of 2-changes in which only edges of and between these three blocks are involved and after which \(\mathcal {B}^{i}_{2}\) is in its short state and the other blocks are in their long states. Remember that when the edges {u 1,u 2} and {v 1,v 2} are removed from the tour and the vertices appear in the order u 1,u 2,v 1,v 2 in the current tour, then the edges {u 1,v 1} and {u 2,v 2} are added to the tour and the subtour between u 1 and v 2 is visited in reverse order. If, e.g., the current tour corresponds to the permutation (1,2,3,4,5,6,7) and the edges {1,2} and {5,6} are removed, then the new tour is (1,5,4,3,2,6,7). The following sequence of 2-changes, which is also shown in Fig. 3, has the desired properties. Brackets indicate the edges that are removed from the tour.


This figure shows the sequence of seven consecutive 2-changes from Property 5. In each step the thick edges are removed from the tour, and the dotted edges are added to the tour. It shows how block \(\mathcal{B}_{2}^{i}\) switches from its long to its short state while resetting the blocks \(\mathcal{B}_{1}^{i+1}\) and \(\mathcal{B}_{2}^{i+1}\) from their short to their long states. This figure is only schematic and it does not show the actual geometric embedding of the points into the Euclidean plane
Observe that the configurations 2 to 7 do not have the property mentioned at the beginning of this section that, for every block \(\mathcal{B}^{i}_{j}\), the points \(A^{i}_{j}\), \(B^{i}_{j}\), \(C^{i}_{j}\), and \(D^{i}_{j}\) are visited consecutively either in the order \(A^{i}_{j} B^{i}_{j} C^{i}_{j} D^{i}_{j}\) or in the order \(A^{i}_{j} C^{i}_{j} B^{i}_{j} D^{i}_{j}\). The configurations 2 to 7 are exactly the intermediate configurations that we mentioned at the beginning of this section.
If gadget G i is in state (L,L) instead of state (S,L), a sequence of steps that satisfies Property 5 can be constructed analogously. Additionally, one has to take into account that the three involved blocks \(\mathcal{B}^{i}_{1}\), \(\mathcal{B}^{i+1}_{1}\), and \(\mathcal{B}^{i+1}_{2}\) are not consecutive in the tour but that block \(\mathcal{B}^{i}_{2}\) lies between them. However, one can easily verify that this block is not affected by the sequence of 2-changes, as after the seven 2-changes have been performed, the block is in the same state and at the same position as before.
3.1.2 Embedding the Construction into the Euclidean Plane
The only missing step in the proof of Theorem 1 for the Euclidean plane is to find points such that all of the 2-changes that we described in the previous section are improving. We specify the positions of the points of gadget G n−1 and give a rule as to how the points of gadget G i can be derived when all points of gadget G i+1 have already been placed. In our construction it happens that different points have exactly the same coordinates. This is only for ease of notation; if one wants to obtain a TSP instance in which distinct points have distinct coordinates, one can slightly move these points without affecting the property that all 2-changes are improving.
For j∈[2], we choose \(A^{n-1}_{j}=(0,0)\), \(B^{n-1}_{j}=(1,0)\), \(C^{n-1}_{j}=(-0.1,1.4)\), and \(D^{n-1}_{j}=(-1.1,4.8)\). Then \(A^{n-1}_{j}B^{n-1}_{j}C^{n-1}_{j}D^{n-1}_{j}\) is the short state and \(A^{n-1}_{j}C^{n-1}_{j}B^{n-1}_{j}D^{n-1}_{j}\) is the long state because
as
and
We place the points of gadget G i as follows (see Fig. 4):
-
1.
Start with the coordinates of the points of gadget G i+1.
-
2.
Rotate these points around the origin by 3π/2.
-
3.
Scale each coordinate by a factor of 3.
-
4.
Translate the points by the vector (−1.2,0.1).
For j∈[2], this yields \(A^{n-2}_{j}=(-1.2,0.1)\), \(B^{n-2}_{j}=(-1.2,-2.9)\), \(C^{n-2}_{j}=(3,0.4)\), and \(D^{n-2}_{j}=(13.2,3.4)\).

This illustration shows the points of the gadgets G n−1 and G n−2. One can see that G n−2 is a scaled, rotated, and translated copy of G n−1
From this construction it follows that each gadget is a scaled, rotated, and translated copy of gadget G n−1. If one has a set of points in the Euclidean plane that admits certain improving 2-changes, then these 2-changes are still improving if one scales, rotates, and translates all points in the same manner. Hence, it suffices to show that the sequences in which gadget G n−2 resets gadget G n−1 from (S,S) to (L,L) are improving because, for any i, the points of the gadgets G i and G i+1 are a scaled, rotated, and translated copy of the points of the gadgets G n−2 and G n−1.
There are two sequences in which gadget G n−2 resets gadget G n−1 from (S,S) to (L,L): in the first one, gadget G n−2 changes its state from (L,L) to (S,L), in the second one, gadget G n−2 changes its state from (S,L) to (S,S). Since the coordinates of the points in both blocks of gadget G n−2 are the same, the inequalities for both sequences are also identical. The following inequalities show that the improvements made by the steps in both sequences are all positive (see Fig. 3 or the table in Sect. 3.1.1 for the sequence of 2-changes):

This concludes the proof of Theorem 1 for the Euclidean plane as it shows that all 2-changes in Lemma 6 are improving.
3.2 Exponential Lower Bound for L p Metrics
We were not able to find a set of points in the plane such that all 2-changes in Lemma 6 are improving with respect to the Manhattan metric. Therefore, we modify the construction of the gadgets and the sequence of 2-changes. Our construction for the Manhattan metric is based on the construction for the Euclidean plane, but it does not possess the property that every gadget resets its neighboring gadget twice. This property is only true for half of the gadgets. To be more precise, we construct two different types of gadgets which we call reset gadgets and propagation gadgets. Reset gadgets perform the same sequence of 2-changes as the gadgets that we constructed for the Euclidean plane. Propagation gadgets also have the same structure as the gadgets for the Euclidean plane, but when such a gadget changes its state from (L,L) to (S,S), it resets its neighboring gadget only once. Due to this relaxed requirement it is possible to find points in the Manhattan plane whose distances satisfy all necessary inequalities. Instead of n gadgets, our construction consists of 2n gadgets, namely n propagation gadgets \(G_{0}^{P},\ldots,G_{n-1}^{P}\) and n reset gadgets \(G_{0}^{R},\ldots,G_{n-1}^{R}\). The order in which these gadgets appear in the tour is \(G_{0}^{P}G_{0}^{R}G_{1}^{P}G_{1}^{R}\ldots G_{n-1}^{P}G_{n-1}^{R}\).
As before, every gadget consists of two blocks and the order in which the blocks and the gadgets are visited does not change during the sequence of 2-changes. Consider a reset gadget \(G^{R}_{i}\) and its neighboring propagation gadget \(G^{P}_{i+1}\). We will embed the points of the gadgets into the Manhattan plane in such a way that Property 5 is still satisfied. That is, if \(G^{R}_{i}\) is in state (L,L) (or state (S,L), respectively) and \(G^{P}_{i+1}\) is in state (S,S), then there exists a sequence of seven consecutive 2-changes resetting gadget \(G^{P}_{i+1}\) to state (L,L) and leaving gadget \(G^{R}_{i}\) in state (S,L) (or (S,S), respectively). The situation is different for a propagation gadget \(G^{P}_{i}\) and its neighboring reset gadget \(G^{R}_{i}\). In this case, if \(G^{P}_{i}\) is in state (L,L), it first changes its state with a single 2-change to (S,L). After that, gadget \(G^{P}_{i}\) changes its state to (S,S) while resetting gadget \(G^{R}_{i}\) from state (S,S) to state (L,L) by a sequence of seven consecutive 2-changes. In both cases, the sequences of 2-changes in which one block changes from its long to its short state while resetting two blocks of the neighboring gadget from their short to their long states are chosen analogously to the ones for the Euclidean plane described in Sect. 3.1.1. An example with three propagation and three reset gadgets is shown in Fig. 5.

This figure shows an example with three propagation and three reset gadgets. It shows the first 16 configurations that these gadgets assume during the sequence of 2-changes, excluding the intermediate configurations that arise when one gadget resets another one. Gadgets that are involved in the transformation from configuration i to configuration i+1 are shown in gray. For example, in the step from the first to the second configuration, the first block \(\mathcal {B}_{1}^{P,0}\) of the first propagation gadget \(G_{0}^{P}\) switches from its long to its short state by a single 2-change. Then in the step from the second to the third configuration, the second block \(\mathcal{B}_{2}^{P,0}\) of the first propagation gadget \(G_{0}^{P}\) resets the two blocks of the first reset gadget \(G_{0}^{R}\). That is, these three blocks follow the sequence of seven 2-changes from Property 5
In the initial tour, only gadget \(G^{P}_{0}\) is in state (L,L) and every other gadget is in state (S,S). With similar arguments as for the Euclidean plane, we can show that gadget \(G_{i}^{R}\) is reset from its one state (S,S) to its zero state (L,L) 2i times and that the total number of steps is 2n+4−22.
3.2.1 Embedding the Construction into the Manhattan Plane
As in the construction in the Euclidean plane, the points in both blocks of a reset gadget \(G_{i}^{R}\) have the same coordinates. Also in this case one can slightly move all the points without affecting the inequalities if one wants distinct coordinates for distinct points. Again, we choose points for the gadgets \(G_{n-1}^{P}\) and \(G_{n-1}^{R}\) and describe how the points of the gadgets \(G_{i}^{P}\) and \(G_{i}^{R}\) can be chosen when the points of the gadgets \(G_{i+1}^{P}\) and \(G_{i+1}^{R}\) are already chosen. For j∈[2], we choose \(A^{n-1}_{R,j}=(0,1)\), \(B^{n-1}_{R,j}=(0,0)\), \(C^{n-1}_{R,j}=(-0.7,0.1)\), and \(D^{n-1}_{R,j}=(-1.2,0.08)\). Furthermore, we choose \(A^{n-1}_{P,1}=(-2,1.8)\), \(B^{n-1}_{P,1}=(-3.3,2.8)\), \(C^{n-1}_{P,1}=(-1.3,1.4)\), \(D^{n-1}_{P,1}=(1.5,0.9)\), \(A^{n-1}_{P,2}=(-0.7,1.6)\), \(B^{n-1}_{P,2}=(-1.5,1.2)\), \(C^{n-1}_{P,2}=(1.9,-1.5)\), and \(D^{n-1}_{P,2}=(-0.8,-1.1)\).
Before we describe how the points of the other gadgets are chosen, we first show that the 2-changes within and between the gadgets \(G_{n-1}^{P}\) and \(G_{n-1}^{R}\) are improving. For j∈[2], \(A^{n-1}_{R,j}B^{n-1}_{R,j}C^{n-1}_{R,j}D^{n-1}_{R,j}\) is the short state because

In the 2-change in which \(G_{n-1}^{P}\) changes its state from (L,L) to (S,L) the edges \(A^{n-1}_{P,1},C^{n-1}_{P,1}\) and \(B^{n-1}_{P,1},D^{n-1}_{P,1}\) are replaced with the edges \(A^{n-1}_{P,1},B^{n-1}_{P,1}\) and \(C^{n-1}_{P,1},D^{n-1}_{P,1}\). This 2-change is improving because

The 2-changes in the sequence in which \(G_{n-1}^{P}\) changes its state from (S,L) to (S,S) while resetting \(G_{n-1}^{R}\) are chosen analogously to the ones shown in Fig. 3 and in the table in Sect. 3.1.1. The only difference is that the involved blocks are not \(\mathcal{B}^{i}_{2}\), \(\mathcal{B}^{i+1}_{1}\), and \(\mathcal {B}^{i+1}_{2}\) anymore, but the second block of gadget \(G_{n-1}^{P}\) and the two blocks of gadget \(G_{n-1}^{R}\), respectively. This gives rise to the following equalities that show that the improvements made by the 2-changes in this sequence are all positive:

Again, our construction possesses the property that each pair of gadgets \(G_{i}^{P}\) and \(G_{i}^{R}\) is a scaled and translated version of the pair \(G_{n-1}^{P}\) and \(G_{n-1}^{R}\). Since we have relaxed the requirements for the gadgets, we do not even need rotations here. We place the points of \(G_{i}^{P}\) and \(G_{i}^{R}\) as follows:
-
1.
Start with the coordinates specified for the points of gadgets \(G_{i+1}^{P}\) and \(G_{i+1}^{R}\).
-
2.
Scale each coordinate by a factor of 7.7.
-
3.
Translate the points by the vector (1.93,0.3).
For j∈[2], this yields \(A^{n-2}_{R,j}=(1.93,8)\), \(B^{n-2}_{R,j}=(1.93,0.3)\), \(C^{n-2}_{R,j}=(-3.46, 1.07)\), and \(D^{n-2}_{R,j}=(-7.31,0.916)\). Additionally, it yields \(A^{n-2}_{P,1}=(-13.47,14.16)\), \(B^{n-2}_{P,1}=(-23.48,21.86)\), \(C^{n-2}_{P,1}=(-8.08,11.08)\), \(D^{n-2}_{P,1}=(13.48,7.23)\), \(A^{n-2}_{P,2}=(-3.46, 12.62)\), \(B^{n-2}_{P,2}=(-9.62,9.54)\), \(C^{n-2}_{P,2}=(16.56,-11.25)\), and \(D^{n-2}_{P,2}=(-4.23, -8.17)\).
As in our construction for the Euclidean plane, it suffices to show that the sequences in which gadget \(G^{R}_{n-2}\) resets gadget \(G^{P}_{n-1}\) from (S,S) to (L,L) are improving because, for any i, the points of the gadgets \(G^{R}_{i}\) and \(G^{P}_{i+1}\) are a scaled and translated copy of the points of the gadgets \(G^{R}_{n-2}\) and \(G^{P}_{n-1}\). The 2-changes in these sequences are chosen analogously to the ones shown in Fig. 3 and in the table in Sect. 3.1.1. The only difference is that the involved blocks are not \(\mathcal{B}^{i}_{2}\), \(\mathcal{B}^{i+1}_{1}\), and \(\mathcal {B}^{i+1}_{2}\) anymore, but one of the blocks of gadget \(G^{R}_{n-2}\) and the two blocks of gadget \(G^{P}_{n-1}\), respectively. As the coordinates of the points in the two blocks of gadget \(G^{R}_{n-2}\) are the same, the inequalities for both sequences are also identical. The improvements made by the steps in both sequences are

This concludes the proof of Theorem 1 for the Manhattan metric as it shows that all 2-changes are improving.
Let us remark that this also implies Theorem 1 for the L ∞ metric because distances with respect to the L ∞ metric coincide with distances with respect to the Manhattan metric if one rotates all points by π/4 around the origin and scales every coordinate by \(1/\sqrt{2}\).
3.2.2 Embedding the Construction into General L p Metrics
It is also possible to embed our Manhattan construction into the L p metric for \(p\in\mathbb{N}\) with p≥3. For j∈[2], we choose \(A^{n-1}_{R,j}=(0,1)\), \(B^{n-1}_{R,j}=(0,0)\), \(C^{n-1}_{R,j}=(3.5,3.7)\), and \(D^{n-1}_{R,j}=(7.8,-3.2)\). Moreover, we choose \(A^{n-1}_{P,1}=(-2.5,-2.4)\), \(B^{n-1}_{P,1}=(-4.7,-7.3)\), \(C^{n-1}_{P,1}=(-8.6,-4.6)\), \(D^{n-1}_{P,1}=(3.7,9.8)\), \(A^{n-1}_{P,2}=(3.2,2)\), \(B^{n-1}_{P,2}=(7.2,7.2)\), \(C^{n-1}_{P,2}=(-6.5,-1.6)\), and \(D^{n-1}_{P,2}=(-1.5,-7.1)\). We place the points of \(G_{i}^{P}\) and \(G_{i}^{R}\) as follows:
-
1.
Start with the coordinates specified for the points of gadgets \(G_{i+1}^{P}\) and \(G_{i+1}^{R}\).
-
2.
Rotate these points around the origin by π.
-
3.
Scale each coordinate by a factor of 7.8.
-
4.
Translate the points by the vector (7.2,5.3).
For j∈[2], this yields \(A^{n-2}_{R,j}=(7.2,-2.5)\), \(B^{n-2}_{R,j}=(7.2,5.3)\), \(C^{n-2}_{R,j}=(-20.1, -23.56)\), and \(D^{n-2}_{R,j}=(-53.64,30.26)\). Additionally, it yields \(A^{n-2}_{P,1}=(26.7,24.02)\), \(B^{n-2}_{P,1}=(43.86,62.24)\), \(C^{n-2}_{P,1}=(74.28,41.18)\), \(D^{n-2}_{P,1}=(-21.66,-71.14)\), \(A^{n-2}_{P,2}=(-17.76,-10.3)\), \(B^{n-2}_{P,2}=(-48.96,-50.86)\), \(C^{n-2}_{P,2}=(57.9,17.78)\), and \(D^{n-2}_{P,2}=(18.9,60.68)\).
It needs to be shown that the distances of these points when measured according to the L p metric for any \(p\in\mathbb{N}\) with p≥3 satisfy all necessary inequalities, that is, all 16 inequalities that we have verified in the previous section for the Manhattan metric. Let us start by showing that for j∈[2], \(A^{n-1}_{R,j}B^{n-1}_{R,j}C^{n-1}_{R,j}D^{n-1}_{R,j}\) is the short state. For this, we have to prove the following inequality for every \(p\in\mathbb{N}\) with p≥3:

For p=∞, the inequality is satisfied as the left side equals 3.4 when distances are measured according to the L ∞ metric. In order to show that the inequality is also satisfied for every \(p\in\mathbb{N}\) with p≥3, we analyze by how much the distances d p deviate from the distances d ∞. For \(p\in\mathbb{N}\) with p≥3, we obtain
Hence,
which proves that \(A^{n-1}_{R,j}B^{n-1}_{R,j}C^{n-1}_{R,j}D^{n-1}_{R,j}\) is the short state for every \(p\in\mathbb{N}\) with p≥3.
Next we argue that also the 2-change in which \(G_{n-1}^{P}\) changes its state from (L,L) to (S,L) is improving. For this, the following inequality needs to be verified for every \(p\in\mathbb{N}\) with p≥3:

As before, we obtain for \(p\in\mathbb{N}\) with p≥3
and
This implies for \(p\in\mathbb{N}\) with p≥3

which proves that the 2-change in which \(G_{n-1}^{P}\) changes its state from (L,L) to (S,L) is improving for every \(p\in\mathbb{N}\) with p≥3.
Next we show that the improvements made by the 2-changes in the sequence in which \(G_{n-1}^{P}\) changes its state from (S,L) to (S,S) while resetting \(G_{n-1}^{R}\) are positive. For this we need to verify the following inequalities for every \(p\in\mathbb{N}\) with p≥3 (observe that these are exactly the same inequalities that we have verified in Sect. 3.2.1 for the Manhattan metric):

These inequalities can be checked in the same way as Inequality (3.1). Details can be found in Appendix A.
It remains to be shown that the sequences in which gadget \(G^{R}_{n-2}\) resets gadget \(G^{P}_{n-1}\) from (S,S) to (L,L), are improving. As the coordinates of the points in the two blocks of gadget \(G^{R}_{n-2}\) are the same, the inequalities for both sequences are also identical. We need to verify the following inequalities:

These inequalities can be checked in the same way as Inequality (3.1) was checked; see the details in Appendix A.
4 Expected Number of 2-Changes
We analyze the expected number of 2-changes on random d-dimensional Manhattan and Euclidean instances, for an arbitrary constant dimension d≥2. One possible approach for this is to analyze the improvement made by the smallest improving 2-change: If the smallest improvement is not too small, then the number of improvements cannot be large. This approach yields polynomial bounds, but in our analysis, we consider not only a single step but certain pairs of steps. We show that the smallest improvement made by any such pair is typically much larger than the improvement made by a single step, which yields better bounds. Our approach is not restricted to pairs of steps. One could also consider sequences of steps of length k for any small enough k. In fact, for general ϕ-perturbed graphs with m edges, we consider sequences of length \(\sqrt{\log{m}}\) in [5]. The reason why we can analyze longer sequences for general graphs is that these inputs possess more randomness than ϕ-perturbed Manhattan and Euclidean instances because every edge length is a random variable that is independent of the other edge lengths. Hence, the analysis for general ϕ-perturbed graphs demonstrates the limits of our approach under optimal conditions. For Manhattan and Euclidean instances, the gain of considering longer sequences is small due to the dependencies between the edge lengths.
4.1 Manhattan Instances
In this section, we analyze the expected number of 2-changes on ϕ-perturbed Manhattan instances. First we prove a weaker bound than the one in Theorem 2 in a slightly different model. In this model the position of a vertex v i is not chosen according to a density function f i :[0,1]d→[0,ϕ], but instead each of its d coordinates is chosen independently. To be more precise, for every j∈[d], there is a density function \(f_{i}^{j}\colon[0,1] \to[0,\phi]\) according to which the jth coordinate of v i is chosen.
The proof of this weaker bound illustrates our approach and reveals the problems one has to tackle in order to improve the upper bounds. It is solely based on an analysis of the smallest improvement made by any of the possible 2-Opt steps. If with high probability every 2-Opt step decreases the tour length by an inverse polynomial amount, then with high probability only polynomially many 2-Opt steps are possible before a local optimum is reached. In fact, the probability that there exists a 2-Opt step that decreases the tour length by less than an inverse polynomial amount is so small that (as we will see) even the expected number of possible 2-Opt steps can be bounded polynomially.
Theorem 7
Starting with an arbitrary tour, the expected number of steps performed by 2-Opt on ϕ-perturbed Manhattan instances with n vertices is O(n 6⋅logn⋅ϕ) if the coordinates of every vertex are drawn independently.
Proof
We will see below that, in order to prove the desired bound on the expected convergence time, we only need two simple observations. First, the initial tour can have length at most dn as the number of edges is n and every edge has length at most d. And second, every 2-Opt step decreases the length of the tour by an inverse polynomial amount with high probability. The latter can be shown by a union bound over all possible 2-Opt steps. Consider a fixed 2-Opt step S, let e 1 and e 2 denote the edges removed from the tour in step S, and let e 3 and e 4 denote the edges added to the tour. Then the improvement Δ(S) of step S can be written as
Without loss of generality let e 1=(v 1,v 2) be the edge between the vertices v 1 and v 2, and let e 2=(v 3,v 4), e 3=(v 1,v 3), and e 4=(v 2,v 4). Furthermore, for i∈{1,…4}, let \(x^{i}\in\mathbb{R}^{d}\) denote the coordinates of vertex v i . Then the improvement Δ(S) of step S can be written as
Depending on the order of the coordinates, Δ(S) can be written as some linear combination of the coordinates. If, e.g., for all i∈[d], \(x^{1}_{i}\ge x^{2}_{i}\ge x^{3}_{i}\ge x^{4}_{i}\), then the improvement Δ(S) can be written as \(\sum_{i=1}^{d}(-2x^{2}_{i}+2x^{3}_{i})\). There are (4!)d such orders and each one gives rise to a linear combination of the \(x_{i}^{j}\)’s with integer coefficients.
For each of these linear combinations, the probability that it takes a value in the interval (0,ε] is bounded from above by εϕ. To see this, we distinguish between two cases: If all coefficients in the linear combination are zero then the probability that the linear combination takes a value in the interval (0,ε] is zero. If at least one coefficient is nonzero then we can apply the principle of deferred decisions (see, e.g., [14]). Let \(x_{i}^{j}\) be a variable that has a nonzero coefficient α and assume that all random variables except for \(x_{i}^{j}\) are already drawn. Then, in order for the linear combination to take a value in the interval (0,ε], the random variable \(x_{i}^{j}\) has to take a value in a fixed interval of length ε/|α|. As the density of \(x_{i}^{j}\) is bounded from above by ϕ and α is a nonzero integer, the probability of this event is at most εϕ.
Since Δ(S) can only take a value in the interval (0,ε] if one of the linear combinations takes a value in this interval, the probability of the event Δ(S)∈(0,ε] can be upper bounded by (4!)d εϕ.
Let Δ min denote the improvement of the smallest improving 2-Opt step S, i.e., Δ min=min{Δ(S)∣Δ(S)>0}. We can estimate Δ min by a union bound, yielding
as there are at most n 4 different 2-Opt steps. Let T denote the random variable describing the number of 2-Opt steps before a local optimum is reached. Observe that T can only exceed a given number t if the smallest improvement Δ min is less than dn/t, and hence
Since there are at most n! different TSP tours and none of these tours can appear twice during the local search, T is always bounded by n!. Altogether, we can bound the expected value of T by
Since we assumed the dimension d to be a constant, bounding the n-th harmonic number by ln(n)+1 and using ln(n!)=O(nlogn) yields
□
The bound in Theorem 7 is only based on the smallest improvement Δ min made by any of the 2-Opt steps. Intuitively, this is too pessimistic since most of the steps performed by 2-Opt yield a larger improvement than Δ min. In particular, two consecutive steps yield an improvement of at least Δ min plus the improvement \(\varDelta_{\min}'\) of the second smallest step. This observation alone, however, does not suffice to improve the bound substantially. Instead, we show in Lemma 8 that we can regroup the 2-changes to pairs such that each pair of 2-changes is linked by an edge, i.e., one edge added to the tour in the first 2-change is removed from the tour in the second 2-change. Then we analyze the smallest improvement made by any pair of linked 2-Opt steps. Obviously, this improvement is at least \(\varDelta_{\min}+\varDelta_{\min}'\) but one can hope that it is much larger because it is unlikely that the 2-change that yields the smallest improvement and the 2-change that yields the second smallest improvement form a pair of linked steps. We show that this is indeed the case and use this result to prove the bound on the expected length of the longest path in the state graph of 2-Opt on ϕ-perturbed Manhattan instances claimed in Theorem 2.
4.1.1 Construction of Pairs of Linked 2-Changes
Consider an arbitrary sequence of length t of consecutive 2-changes. The following lemma guarantees that the number of disjoint linked pairs of 2-changes in every such sequence increases linearly with the length t.
Lemma 8
In every sequence of t consecutive 2-changes, the number of disjoint pairs of 2-changes that are linked by an edge, i.e., pairs such that there exists an edge added to the tour in the first 2-change of the pair and removed from the tour in the second 2-change of the pair, is at least t/3−n(n−1)/4.
Proof
Let S 1,…,S t denote an arbitrary sequence of consecutive 2-changes. The sequence is processed step by step and a list \(\mathcal{L}\) of disjoint linked pairs of 2-changes is created. Assume that the 2-changes S 1,…,S i−1 have already been processed and that now 2-change S i has to be processed. Assume further that in step S i the edges e 1 and e 2 are exchanged with the edges e 3 and e 4 (for the following argument it is not important which of the two incoming edges we call e 3 and which we call e 4). Let j denote the smallest index with j>i such that edge e 3 is removed from the tour in step S j if such a step exists, and let j′ denote the smallest index with j′>i such that edge e 4 is removed from the tour in step S j′ if such a step exists. If the index j is defined, the pair (S i ,S j ) is added to the constructed list \(\mathcal{L}\). If the index j is not defined but the index j′ is defined, the pair (S i ,S j′) is added to the constructed list \(\mathcal{L}\). After that, both steps S j and S j′ (if defined) are removed from the sequence of 2-changes, that is, they are not processed in the following in order to guarantee disjointness of the pairs in \(\mathcal{L}\). Also step S i is removed from the sequence of 2-changes as it is completely processed. See Fig. 6 for an example of this process.

This figure shows an example of how the list \(\mathcal{L}\) is generated. The considered sequence consists of the five 2-changes S 1, S 2, S 3, S 4, S 5, where ⋅ is used as placeholder for mutually different edges that are different from all the e i . First all 2-changes are unprocessed. Then S 1 gets processed (i=1). According to the definitions, we have j=3 and j′=4. Hence, we add the pair (S 1,S 3) to the list \(\mathcal{L}\) and remove S 1, S 3, and S 4 from the sequence of 2-changes, leaving only the steps S 2 and S 5. Then we process S 2 for which j is undefined and j′=5
If one 2-change S i is processed, it excludes at most two other 2-changes from being processed (S j and S j′). Hence, the number of pairs added to \(\mathcal{L}\) is at least t/3−n(n−1)/4 because there can be at most \(\lfloor \binom{n}{2}/2\rfloor=\lfloor n(n-1)/4\rfloor\) steps S i for which neither j nor j′ is defined. □
Consider a fixed pair of 2-changes linked by an edge. Without loss of generality assume that in the first step the edges {v 1,v 2} and {v 3,v 4} are exchanged with the edges {v 1,v 3} and {v 2,v 4}, for distinct vertices v 1,…,v 4. Also without loss of generality assume that in the second step the edges {v 1,v 3} and {v 5,v 6} are exchanged with the edges {v 1,v 5} and {v 3,v 6}. However, note that the vertices v 5 and v 6 are not necessarily distinct from the vertices v 2 and v 4. We distinguish between three different types of pairs.
-
pairs of type 0: |{v 2,v 4}∩{v 5,v 6}|=0. This case is illustrated in Fig. 7.
Fig. 7 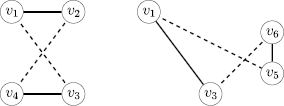
A pair of type 0
-
pairs of type 1: |{v 2,v 4}∩{v 5,v 6}|=1. We can assume w.l.o.g. that v 2∈{v 5,v 6}. We have to distinguish between two subcases: (a) The edges {v 1,v 5} and {v 2,v 3} are added to the tour in the second step. (b) The edges {v 1,v 2} and {v 3,v 5} are added to the tour in the second step. These cases are illustrated in Fig. 8.
Fig. 8 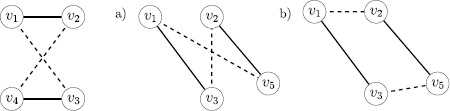
Pairs of type 1
-
pairs of type 2: |{v 2,v 4}∩{v 5,v 6}|=2. The case v 2=v 5 and v 4=v 6 cannot appear as it would imply that in the first step the edges {v 1,v 2} and {v 3,v 4} are exchanged with the edges {v 1,v 3} and {v 2,v 4}, and that in the second step the edges {v 1,v 3} and {v 2,v 4} are again exchanged with the edges {v 1,v 2} and {v 3,v 4}. Hence, one of these 2-changes cannot be improving, and for pairs of this type we must have v 2=v 6 and v 4=v 5.


When distances are measured according to the Euclidean metric, pairs of type 2 result in vast dependencies and hence the probability that there exists a pair of this type in which both steps are improvements by at most ε with respect to the Euclidean metric cannot be bounded appropriately. In order to reduce the number of cases we have to consider and in order to prepare for the analysis of ϕ-perturbed Euclidean instances, we exclude pairs of type 2 from our probabilistic analysis by leaving out all pairs of type 2 when constructing the list \(\mathcal{L}\) in the proof of Lemma 8.
We only need to show that there are always enough pairs of type 0 or 1. Consider two steps S i and S j with i<j that form a pair of type 2. Assume that in step S i the edges {v 1,v 2} and {v 3,v 4} are replaced by the edges {v 1,v 3} and {v 2,v 4}, and that in step S j these edges are replaced by the edges {v 1,v 4} and {v 2,v 3}. Now consider the next step S l with l>j in which the edge {v 1,v 4} is removed from the tour, if such a step exists, and the next step S l′ with l′>j in which the edge {v 2,v 3} is removed from the tour if such a step exists. Observe that neither (S j ,S l ) nor (S j ,S l′) can be a pair of type 2 because otherwise the improvement of one of the steps S i , S j , and S l , or of one of the steps S i , S j , and S l′, respectively, must be negative. In particular, we must have l≠l′.
If we encounter a pair (S i ,S j ) of type 2 in the construction of the list \(\mathcal{L}\), we mark step S i as being processed without adding a pair of 2-changes to \(\mathcal{L}\) and without removing S j from the sequence of steps to be processed. Let x denote the number of pairs of type 2 that we encounter during the construction of the list \(\mathcal{L}\). Our argument above shows that the number of pairs of type 0 or 1 that are added to \(\mathcal{L}\) is at least x−n(n−1)/4. This implies t≥x+(x−n(n−1)/4) and x≤t/2+n(n−1)/8. Hence, the number of relevant steps reduces from t to t′=t−x≥t/2−n(n−1)/8. Using this estimate in Lemma 8 yields the following lemma.
Lemma 9
In every sequence of t consecutive 2-changes the number of disjoint pairs of 2-changes of type 0 or 1 is at least t/6−7n(n−1)/24.
4.1.2 Analysis of Pairs of Linked 2-Changes
The following lemma gives a bound on the probability that there exists a pair of type 0 or 1 in which both steps are small improvements.
Lemma 10
In a ϕ-perturbed Manhattan instance with n vertices, the probability that there exists a pair of type 0 or type 1 in which both 2-changes are improvements by at most ε is O(n 6⋅ε 2⋅ϕ 2).
Proof
First, we consider pairs of type 0. We assume that in the first step the edges {v 1,v 2} and {v 3,v 4} are replaced by the edges {v 1,v 3} and {v 2,v 4} and that in the second step the edges {v 1,v 3} and {v 5,v 6} are replaced by the edges {v 1,v 5} and {v 3,v 6}. For j∈[6], let \(x^{j}_{i}\in\mathbb{R}^{d}\), i=1,2,…,d, denote the d coordinates of vertex v j . Furthermore, let Δ 1 denote the (possibly negative) improvement of the first step and let Δ 2 denote the (possibly negative) improvement of the second step. The random variables Δ 1 and Δ 2 can be written as
and
For any fixed order of the coordinates, Δ 1 and Δ 2 can be expressed as linear combinations of the coordinates with integer coefficients. For i∈[d], let σ i denote an order of the coordinates \(x_{i}^{1},\ldots,x_{i}^{6}\), let σ=(σ 1,…,σ d ), and let \(\varDelta_{1}^{\sigma }\) and \(\varDelta_{2}^{\sigma}\) denote the corresponding linear combinations. We denote by \(\mathcal{A}\) the event that both Δ 1 and Δ 2 take values in the interval (0,ε], and we denote by \(\mathcal {A}^{\sigma}\) the event that both linear combinations \(\varDelta_{1}^{\sigma}\) and \(\varDelta_{2}^{\sigma}\) take values in the interval (0,ε]. Obviously \(\mathcal{A}\) can only occur if for at least one σ, the event \(\mathcal{A}^{\sigma}\) occurs. Hence, we obtain
Since there are (6!)d different orders σ, which is constant for constant dimension d, it suffices to show that for every tuple of orders σ, the probability of the event \(\mathcal{A}^{\sigma}\) is bounded from above by O(ε 2 ϕ 2). Then a union bound over all possible pairs of linked 2-changes of type 0 (there are fewer than n 6 of them) and all possible orders σ (there is a constant number of them) yields the lemma for pairs of type 0.
We divide the set of possible pairs of linear combinations \((\varDelta_{1}^{\sigma},\varDelta_{2}^{\sigma})\) into three classes. We say that a pair of linear combinations belongs to class A if at least one of the linear combinations equals 0, we say that it belongs to class B if \(\varDelta_{1}^{\sigma}=-\varDelta_{2}^{\sigma}\), and we say that it belongs to class C if \(\varDelta_{1}^{\sigma}\) and \(\varDelta_{2}^{\sigma}\) are linearly independent. For tuples of orders σ that yield pairs from class A, the event \(\mathcal{A}^{\sigma}\) cannot occur because the value of at least one linear combination is 0. For tuples σ that yield pairs from class B, the event cannot occur either because either \(\varDelta _{1}^{\sigma}\) or \(\varDelta_{2}^{\sigma}=-\varDelta_{1}^{\sigma}\) is at most 0. For tuples σ that yield pairs from class C, we can apply Lemma 20 from Appendix B, which shows that the probability of the event \(\mathcal{A}^{\sigma}\) is bounded from above by (εϕ)2. Hence, we only need to show that every pair \((\varDelta_{1}^{\sigma},\varDelta_{2}^{\sigma})\) of linear combinations belongs either to class A, B, or C.
Consider a fixed tuple σ=(σ 1,…,σ d ) of orders. We split \(\varDelta_{1}^{\sigma}\) and \(\varDelta_{2}^{\sigma}\) into d parts that correspond to the d dimensions. To be precise, for j∈[2], we write \(\varDelta_{j}^{\sigma}=\sum_{i\in[d]}X^{\sigma_{i},i}_{j}\), where \(X^{\sigma_{i},i}_{j}\) is a linear combination of the variables \(x^{1}_{i},\ldots,x^{6}_{i}\). As an example let us consider the case d=2, let the first order σ 1 be \(x^{1}_{1}\le x^{2}_{1}\le x^{3}_{1}\le x^{4}_{1}\le x^{5}_{1}\le x^{6}_{1}\), and let the second order σ 2 be \(x^{6}_{2}\le x^{5}_{2}\le x^{4}_{2}\le x^{3}_{2}\le x^{2}_{2}\le x^{1}_{2}\). Then we get
and
If, for one i∈[d], the pair \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma _{i},i})\) of linear combinations belongs to class C, then also the pair \((\varDelta_{1}^{\sigma},\varDelta_{2}^{\sigma})\) belongs to class C because the sets of variables occurring in \(X_{j}^{\sigma_{i},i}\) and \(X_{j}^{\sigma_{i'},i'}\) are disjoint for i≠i′. If for all i∈[d] the pair of linear combinations \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma_{i},i})\) belongs to class A or B, then also the pair \((\varDelta_{1}^{\sigma},\varDelta_{2}^{\sigma})\) belongs either to class A or B. Hence, the following lemma directly implies that \((\varDelta_{1}^{\sigma},\varDelta_{2}^{\sigma})\) belongs to one of the classes A, B, or C.
Lemma 11
For pairs of type 0 and for i∈[d], the pair of linear combinations \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma_{i},i})\) belongs either to class A, B, or C.
Proof
Assume that the pair \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma_{i},i})\) of linear combinations is linearly dependent for a fixed order σ i . Observe that this can only happen if the sets of variables occurring in \(X_{1}^{\sigma_{i},i}\) and \(X_{2}^{\sigma_{i},i}\) are the same. Hence, it can only happen if the following two conditions occur.
-
\(X_{1}^{\sigma_{i},i}\) does not contain \(x^{2}_{i}\) or \(x_{i}^{4}\). If \(x^{3}_{i}\ge x_{i}^{4}\), it must be true that \(x^{2}_{i}\ge x_{i}^{4}\) in order for \(x_{i}^{4}\) to cancel out. Then, in order for \(x_{i}^{2}\) to cancel out, it must be true that \(x^{2}_{i}\ge x_{i}^{1}\). If \(x^{3}_{i}\le x_{i}^{4}\), it must be true that \(x^{2}_{i}\le x_{i}^{4}\) in order for \(x_{i}^{4}\) to cancel out. Then, in order for \(x_{i}^{2}\) to cancel out, it must be true that \(x^{2}_{i}\le x_{i}^{1}\).
Hence, either \(x^{3}_{i}\ge x_{i}^{4}\), \(x^{2}_{i}\ge x_{i}^{4}\), and \(x^{2}_{i}\ge x_{i}^{1}\), or \(x^{3}_{i}\le x_{i}^{4}\), \(x^{2}_{i}\le x_{i}^{4}\), and \(x^{2}_{i}\le x_{i}^{1}\).
-
\(X_{2}^{\sigma_{i},i}\) does not contain \(x^{5}_{i}\) or \(x^{6}_{i}\). If \(x^{5}_{i}\ge x^{6}_{i}\), it must be true that \(x^{3}_{i}\ge x^{6}_{i}\) in order for \(x^{6}_{i}\) to cancel out, and it must be true that \(x^{5}_{i}\ge x_{i}^{1}\) in order for \(x^{5}_{i}\) to cancel out. If \(x^{5}_{i}\le x^{6}_{i}\), it must be true that \(x^{3}_{i}\le x^{6}_{i}\) in order for \(x^{6}_{i}\) to cancel out, and it must be true that \(x^{5}_{i}\le x_{i}^{1}\) in order for \(x^{5}_{i}\) to cancel out.
Hence, either \(x^{5}_{i}\ge x^{6}_{i}\), \(x^{3}_{i}\ge x^{6}_{i}\), and \(x^{5}_{i}\ge x_{i}^{1}\), or \(x^{5}_{i}\le x^{6}_{i}\), \(x^{3}_{i}\le x^{6}_{i}\), and \(x^{5}_{i}\le x_{i}^{1}\).
Now we choose an order such that \(x^{2}_{i}\), \(x_{i}^{4}\), \(x^{5}_{i}\), and \(x^{6}_{i}\) cancel out. We distinguish between the cases \(x_{i}^{1}\ge x_{i}^{3}\) and \(x_{i}^{3}\ge x_{i}^{1}\).
- \(x_{i}^{1}\ge x_{i}^{3}\)::
-
In this case, we can write \(X_{1}^{\sigma _{i},i}\) as

Since we have argued above that either \(x^{3}_{i}\ge x_{i}^{4}\), \(x^{2}_{i}\ge x_{i}^{4}\), and \(x^{2}_{i}\ge x_{i}^{1}\), or \(x^{3}_{i}\le x_{i}^{4}\), \(x^{2}_{i}\le x_{i}^{4}\), and \(x^{2}_{i}\le x_{i}^{1}\), we obtain that either
$$X_1^{\sigma_i,i} = \bigl(x^2_i-x^1_i \bigr)+\bigl(x^3_i-x^4_i\bigr)- \bigl(x^1_i-x^3_i\bigr)- \bigl(x^2_i-x^4_i\bigr) = -2x^1_i+2x^3_i $$or
$$X_1^{\sigma_i,i} = \bigl(x^1_i-x^2_i \bigr)+\bigl(x^4_i-x^3_i\bigr)- \bigl(x^1_i-x^3_i\bigr)- \bigl(x^4_i-x^2_i\bigr) = 0. $$We can write \(X_{2}^{\sigma_{i},i}\) as

Since we have argued above that either \(x^{5}_{i}\ge x^{6}_{i}\), \(x^{3}_{i}\ge x^{6}_{i}\), and \(x^{5}_{i}\ge x_{i}^{1}\), or \(x^{5}_{i}\le x^{6}_{i}\), \(x^{3}_{i}\le x^{6}_{i}\), and \(x^{5}_{i}\le x_{i}^{1}\), we obtain that either
$$X_2^{\sigma_i,i} = \bigl(x^1_i-x^3_i \bigr)+\bigl(x^5_i-x^6_i\bigr)- \bigl(x^5_i-x^1_i\bigr)- \bigl(x^3_i-x^6_i\bigr) = 2x^1_i-2x^3_i $$or
$$X_2^{\sigma_i,i} = \bigl(x^1_i-x^3_i \bigr)+\bigl(x^6_i-x^5_i\bigr)- \bigl(x^1_i-x^5_i\bigr)- \bigl(x^6_i-x^3_i\bigr) = 0. $$In summary, the case analysis shows that \(X_{1}^{\sigma_{i},i} \in\{ 0,-2x_{i}^{1}+2x^{3}_{i}\}\) and \(X_{2}^{\sigma_{i},i} \in\{0,2x_{i}^{1}-2x^{3}_{i}\}\). Hence, in this case the resulting pair of linear combinations belongs either to class A or B.
- \(x_{i}^{3}\ge x_{i}^{1}\)::
-
In this case, we can write \(X_{1}^{\sigma _{i},i}\) as

Since we have argued above that either \(x^{3}_{i}\ge x_{i}^{4}\), \(x^{2}_{i}\ge x_{i}^{4}\), and \(x^{2}_{i}\ge x_{i}^{1}\), or \(x^{3}_{i}\le x_{i}^{4}\), \(x^{2}_{i}\le x_{i}^{4}\), and \(x^{2}_{i}\le x_{i}^{1}\), we obtain that either
$$X_1^{\sigma_i,i} = \bigl(x^2_i-x^1_i \bigr)+\bigl(x^3_i-x^4_i\bigr)- \bigl(x^3_i-x^1_i\bigr)- \bigl(x^2_i-x^4_i\bigr) = 0 $$or
$$X_1^{\sigma_i,i} = \bigl(x^1_i-x^2_i \bigr)+\bigl(x^4_i-x^3_i\bigr)- \bigl(x^3_i-x^1_i\bigr)- \bigl(x^4_i-x^2_i\bigr) = 2x^1_i-2x^3_i. $$We can write \(X_{2}^{\sigma_{i},i}\) as

Since we have argued above that either \(x^{5}_{i}\ge x^{6}_{i}\), \(x^{3}_{i}\ge x^{6}_{i}\), and \(x^{5}_{i}\ge x_{i}^{1}\), or \(x^{5}_{i}\le x^{6}_{i}\), \(x^{3}_{i}\le x^{6}_{i}\), and \(x^{5}_{i}\le x_{i}^{1}\), we obtain that either
$$X_2^{\sigma_i,i} = \bigl(x^3_i-x^1_i \bigr)+\bigl(x^5_i-x^6_i\bigr)- \bigl(x^5_i-x^1_i\bigr)- \bigl(x^3_i-x^6_i\bigr) = 0 $$or
$$X_2^{\sigma_i,i} = \bigl(x^3_i-x^1_i \bigr)+\bigl(x^6_i-x^5_i\bigr)- \bigl(x^1_i-x^5_i\bigr)- \bigl(x^6_i-x^3_i\bigr) = -2x^1_i+2x^3_i. $$In summary, the case analysis shows that \(X_{1}^{\sigma_{i},i} \in\{ 0,2x^{1}_{i}-2x^{3}_{i}\}\) and \(X_{2}^{\sigma_{i},i} \in\{0,-2x^{1}_{i}+2x^{3}_{i}\}\). Hence, also in this case the resulting pair of linear combinations belongs either to class A or B. □




Now we consider pairs of type 1(a). Using the same notation as for pairs of type 0, we can write the improvement Δ 2 as
Again we write, for j∈[2], \(\varDelta_{j}^{\sigma}=\sum_{i\in [d]}X^{\sigma_{i},i}_{j}\), where \(X^{\sigma_{i},i}_{j}\) is a linear combination of the variables \(x^{1}_{i},\ldots,x^{6}_{i}\). Compared to pairs of type 0, only the terms \(X^{\sigma_{i},i}_{2}\) are different, whereas the terms \(X^{\sigma_{i},i}_{1}\) do not change.
Lemma 12
For pairs of type 1(a) and for i∈[d], the pair \((X_{1}^{\sigma _{i},i},X_{2}^{\sigma_{i},i})\) of linear combinations belongs either to class A, B, or C.
Proof
Assume that the pair \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma_{i},i})\) is linearly dependent for a fixed order σ i . Observe that this can only happen if the sets of variables occurring in \(X_{1}^{\sigma_{i},i}\) and \(X_{2}^{\sigma_{i},i}\) are the same. Hence, it can only happen if the following two conditions occur.
-
\(X_{1}^{\sigma_{i},i}\) does not contain \(x_{i}^{4}\). If \(x^{3}_{i}\ge x_{i}^{4}\), it must be true that \(x^{2}_{i}\ge x_{i}^{4}\) in order for \(x_{i}^{4}\) to cancel out. If \(x^{3}_{i}\le x_{i}^{4}\), it must be true that \(x^{2}_{i}\le x_{i}^{4}\) in order for \(x_{i}^{4}\) to cancel out.
Hence, either \(x^{3}_{i}\ge x^{4}_{i}\) and \(x^{2}_{i}\ge x^{4}_{i}\), or \(x^{3}_{i}\le x^{4}_{i}\) and \(x^{2}_{i}\le x^{4}_{i}\).
-
\(X_{2}^{\sigma_{i},i}\) does not contain \(x^{5}_{i}\). If \(x^{2}_{i}\ge x^{5}_{i}\), it must be true that \(x^{1}_{i}\ge x_{i}^{5}\) in order for \(x^{5}_{i}\) to cancel out. If \(x^{2}_{i}\le x^{5}_{i}\), it must be true that \(x^{1}_{i}\le x_{i}^{5}\) in order for \(x^{5}_{i}\) to cancel out.
Hence, either \(x^{2}_{i}\ge x^{5}_{i}\) and \(x_{i}^{1}\ge x^{5}_{i}\), or \(x^{2}_{i}\le x^{5}_{i}\) and \(x_{i}^{1}\le x^{5}_{i}\).
Now we choose an order such that \(x_{i}^{4}\) and \(x^{5}_{i}\) cancel out. We distinguish between the following cases.
- \(x_{i}^{1}\ge x_{i}^{3}\)::
-
In this case, we can write \(X_{1}^{\sigma _{i},i}\) as

Since we have argued above that either \(x^{3}_{i}\ge x^{4}_{i}\) and \(x^{2}_{i}\ge x^{4}_{i}\), or \(x^{3}_{i}\le x^{4}_{i}\) and \(x^{2}_{i}\le x^{4}_{i}\), we obtain that either

or

We can write \(X_{2}^{\sigma_{i},i}\) as

Since we have argued above that either \(x^{2}_{i}\ge x^{5}_{i}\) and \(x_{i}^{1}\ge x^{5}_{i}\), or if \(x^{2}_{i}\le x^{5}_{i}\) and \(x_{i}^{1}\le x^{5}_{i}\), we obtain that either

or

In summary, the case analysis shows that \(X_{1}^{\sigma_{i},i} \in\{ 0,-2x_{i}^{1}+2x_{i}^{2}, -2x_{i}^{1}+2x_{i}^{3},-2x_{i}^{2}+2x_{i}^{3}\}\) and \(X_{2}^{\sigma_{i},i} \in\{0,2x^{1}_{i}-2x^{2}_{i},2x^{1}_{i}-2x^{3}_{i}, 2x^{2}_{i}-2x^{3}_{i}\} \). Hence, in this case the resulting pair of linear combinations belongs either to class A, B, or C.
- \(x_{i}^{1}\le x_{i}^{3}\)::
-
In this case, we can write \(X_{1}^{\sigma _{i},i}\) as

Since we have argued above that either \(x^{3}_{i}\ge x^{4}_{i}\) and \(x^{2}_{i}\ge x^{4}_{i}\), or \(x^{3}_{i}\le x^{4}_{i}\) and \(x^{2}_{i}\le x^{4}_{i}\), we obtain that either

or

We can write \(X_{2}^{\sigma_{i},i}\) as

Since we have argued above that either \(x^{2}_{i}\ge x^{5}_{i}\) and \(x_{i}^{1}\ge x^{5}_{i}\), or \(x^{2}_{i}\le x^{5}_{i}\) and \(x_{i}^{1}\le x^{5}_{i}\), we obtain that either

or

In summary, the case analysis shows that \(X_{1}^{\sigma_{i},i} \in\{ 0,2x^{1}_{i}-2x^{2}_{i}, 2x^{1}_{i}-2x^{3}_{i},2x_{i}^{2}-2x_{i}^{3}\}\) and \(X_{2}^{\sigma_{i},i} \in\{ 0,-2x^{1}_{i}+2x^{2}_{i},-2x^{1}_{i}+2x^{3}_{i}, -2x^{2}_{i}+2x^{3}_{i}\}\). Hence, in this case the resulting pair of linear combinations belongs either to class A, B, or C. □












Finally we consider pairs of type 1(b). Using the same notation as before, we can write the improvement Δ 2 as
Again we write, for j∈[2], \(\varDelta_{j}^{\sigma}=\sum_{i\in [d]}X^{\sigma_{i},i}_{j}\), where \(X^{\sigma_{i},i}_{j}\) is a linear combination of the variables \(x^{1}_{i},\ldots,x^{6}_{i}\). And again only the terms \(X^{\sigma_{i},i}_{2}\) are different from before.
Lemma 13
For pairs of type 1(b) and for i∈[d], the pair of linear combinations \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma_{i},i})\) belongs either to class A, B, or C.
Proof
Using the same notation as for pairs of type 0, we can write the improvement Δ 2 as
Assume that the pair \((X_{1}^{\sigma_{i},i},X_{2}^{\sigma_{i},i})\) is linearly dependent for a fixed order σ i . Observe that this can only happen if the sets of variables occurring in \(X_{1}^{\sigma_{i},i}\) and \(X_{2}^{\sigma_{i},i}\) are the same. Hence, it can only happen if the following two conditions occur.
-
\(X_{1}^{\sigma_{i},i}\) does not contain \(x_{i}^{4}\). We have considered this condition already for pairs of type 1(a) and showed that either \(x^{3}_{i}\ge x^{4}_{i}\) and \(x^{2}_{i}\ge x^{4}_{i}\), or \(x^{3}_{i}\le x^{4}_{i}\) and \(x^{2}_{i}\le x^{4}_{i}\).
-
\(X_{2}^{\sigma_{i},i}\) does not contain \(x^{5}_{i}\). If \(x^{2}_{i}\ge x^{5}_{i}\), it must be true that \(x^{3}_{i}\ge x_{i}^{5}\) in order for \(x^{5}_{i}\) to cancel out. If \(x^{2}_{i}\le x^{5}_{i}\), it must be true that \(x^{3}_{i}\le x_{i}^{5}\) in order for \(x^{5}_{i}\) to cancel out.
Hence, either \(x^{2}_{i}\ge x^{5}_{i}\) and \(x_{i}^{3}\ge x^{5}_{i}\), or \(x^{2}_{i}\le x^{5}_{i}\) and \(x_{i}^{3}\le x^{5}_{i}\).
Now we choose an order such that \(x_{i}^{4}\) and \(x^{5}_{i}\) cancel out. We distinguish between the following cases.
- \(x_{i}^{1}\ge x_{i}^{3}\)::
-
We have argued already for pairs of type 1(a) that in this case \(X_{1}^{\sigma_{i},i} \in\{ 0,-2x_{i}^{1}+2x_{i}^{2},-2x_{i}^{1}+2x_{i}^{3},-2x_{i}^{2}+2x_{i}^{3}\}\).
We can write \(X_{2}^{\sigma_{i},i}\) as

Since we have argued above that either \(x^{2}_{i}\ge x^{5}_{i}\) and \(x_{i}^{3}\ge x^{5}_{i}\), or \(x^{2}_{i}\le x^{5}_{i}\) and \(x_{i}^{3}\le x^{5}_{i}\), we obtain that either

or

In summary, the case analysis shows that \(X_{1}^{\sigma_{i},i} \in\{ 0,-2x_{i}^{1}+2x_{i}^{2}, -2x_{i}^{1}+2x_{i}^{3},-2x_{i}^{2}+2x_{i}^{3}\}\) and \(X_{2}^{\sigma_{i},i} \in\{0,2x_{i}^{1}-2x_{i}^{2},2x_{i}^{1}-2x_{i}^{3}, 2x_{i}^{2}-2x_{i}^{3}\} \). Hence, in this case the resulting pair of linear combinations belongs either to class A, B, or C.
- \(x_{i}^{1}\le x_{i}^{3}\)::
-
We have argued already for pairs of type 1(a) that in this case \(X_{1}^{\sigma_{i},i} \in\{0,2x^{1}_{i}-2x^{2}_{i},2x^{1}_{i}-2x^{3}_{i},2x_{i}^{2}-2x_{i}^{3}\}\).
We can write \(X_{2}^{\sigma_{i},i}\) as

Since we have argued above that either \(x^{2}_{i}\ge x^{5}_{i}\) and \(x_{i}^{3}\ge x^{5}_{i}\), or \(x^{2}_{i}\le x^{5}_{i}\) and \(x_{i}^{3}\le x^{5}_{i}\), we obtain that either

or

In summary, the case analysis shows that \(X_{1}^{\sigma_{i},i} \in\{ 0,2x^{1}_{i}-2x^{2}_{i}, 2x^{1}_{i}-2x^{3}_{i},2x_{i}^{2}-2x_{i}^{3}\}\) and \(X_{2}^{\sigma_{i},i} \in\{ 0,-2x^{1}_{i}+2x^{2}_{i},-2x^{1}_{i}+2x^{3}_{i}, -2x^{2}_{i}+2x^{3}_{i}\}\). Hence, in this case the resulting pair of linear combinations belongs either to class A, B, or C. □






We have argued above that for tuples σ of orders that yield pairs from class A or B, the event \(\mathcal{A}^{\sigma}\) cannot occur. For tuples σ that yield pairs from class C, we can apply Lemma 20 from Appendix B, which shows that the probability of the event \(\mathcal{A}^{\sigma}\) is bounded from above by (εϕ)2. As we have shown that every tuple yields a pair from class A, B, or C, we can conclude the proof of Lemma 10 by a union bound over all pairs of linked 2-changes of type 0 and 1 and all tuples σ. As these are O(n 6), the lemma follows. □
4.1.3 Expected Number of 2-Changes
Based on Lemmas 9 and 10, we are now able to prove part (a) of Theorem 2.
Proof of Theorem 2(a)
Let T denote the random variable that describes the length of the longest path in the state graph. If T≥t, then there must exist a sequence S 1,…,S t of t consecutive 2-changes in the state graph. We start by identifying a set of linked pairs of type 0 and 1 in this sequence. Due to Lemma 9, we know that we can find at least z=t/6−7n(n−1)/24 such pairs. Let \(\varDelta_{\min}^{*}\) denote the smallest improvement made by any pair of improving 2-Opt steps of type 0 or 1. If T≥t, then \(\varDelta _{\min }^{*}\le\frac{dn}{z}\) as the initial tour has length at most dn and every linked pair of type 0 or 1 decreases the length of the tour by at least \(\varDelta_{\min}^{*}\). For t>2n 2, we have z=t/6−7n(n−1)/24>t/48 and hence due to Lemma 10,
Using the fact that probabilities are bounded from above by one, we obtain
Since T cannot exceed n!, this implies the following bound on the expected number of 2-changes:

This concludes the proof of part (a) of the theorem. □
Chandra, Karloff, and Tovey [3] show that for every metric that is induced by a norm on \(\mathbb{R}^{d}\), and for any set of n points in the unit hypercube [0,1]d, the optimal tour visiting all n points has length O(n (d−1)/d). Furthermore, every insertion heuristic finds an O(logn)-approximation [18]. Hence, if one starts with a solution computed by an insertion heuristic, the initial tour has length O(n (d−1)/d⋅logn). Using this observation yields part (a) of Theorem 3:
Proof of Theorem 3(a)
Since the initial tour has length O(n (d−1)/d⋅logn), we obtain for an appropriate constant c and t>2n 2,

where the equality follows from Lemma 10. This yields

□
4.2 Euclidean Instances
In this section, we analyze the expected number of 2-changes on ϕ-perturbed Euclidean instances. The analysis is similar to the analysis of Manhattan instances in the previous section; only Lemma 10 needs to be replaced by the following equivalent version for the L 2 metric, which will be proved later in this section.
Lemma 14
For ϕ-perturbed L 2 instances, the probability that there exists a pair of type 0 or type 1 in which both 2-changes are improvements by at most ε≤1/2 is bounded by O(n 6⋅ϕ 5⋅ε 2⋅log2(1/ε))+O(n 5⋅ϕ 4⋅ε 3/2⋅log(1/ε)).
The bound that this lemma provides is slightly weaker than its L 1 counterpart, and hence also the bound on the expected running time is slightly worse for L 2 instances. The crucial step to proving Lemma 14 is to gain a better understanding of the random variable that describes the improvement of a single fixed 2-change. In the next section, we analyze this random variable under several conditions, e.g., under the condition that the length of one of the involved edges is fixed. With the help of these results, pairs of linked 2-changes can easily be analyzed. Let us mention that our analysis of a single 2-change yields a bound of O(n 7⋅log2(n)⋅ϕ 3) for the expected number of 2-changes. For Euclidean instances in which all points are distributed uniformly at random over the unit square, this bound already improves the best previously known bound of O(n 10⋅logn).
4.2.1 Analysis of a Single 2-Change
We analyze a 2-change in which the edges {O,Q 1} and {P,Q 2} are exchanged with the edges {O,Q 2} and {P,Q 1} for some vertices O, P, Q 1, and Q 2. In the input model we consider, each of these points has a probability distribution over the unit hypercube according to which it is chosen. In this section, we consider a simplified random experiment in which O is chosen to be the origin and P, Q 1, and Q 2 are chosen independently and uniformly at random from a d-dimensional hyperball with radius \(\sqrt{d}\) centered at the origin. In the next section, we argue that the analysis of this simplified random experiment helps to analyze the actual random experiment that occurs in the probabilistic input model.
Due to the rotational symmetry of the simplified model, we assume without loss of generality that P lies at position (0d−1,T) for some T≥0. For i∈[2], Let Z i denote the difference d(O,Q i )−d(P,Q i ). Then the improvement Δ of the 2-change can be expressed as Z 1−Z 2. The random variables Z 1 and Z 2 are identically distributed, and they are independent if T is fixed. We denote by \(f_{Z_{1}\mid T=\tau,R=r}\) the density of Z 1 conditioning on the fact that d(O,Q 1)=r and T=τ. Similarly, we denote by \(f_{Z_{2}\mid T=\tau,R=r}\) the density of Z 2 conditioning on the fact that d(O,Q 2)=r and T=τ. As Z 1 and Z 2 are identically distributed, the conditional densities \(f_{Z_{1}\mid T=\tau,R=r}\) and \(f_{Z_{2}\mid T=\tau,R=r}\) are identical as well. Hence, we can drop the index in the following and write f Z∣T=τ,R=r .
Lemma 15
For \(\tau,r\in(0,\sqrt{d}]\), and z∈(−τ,min{τ,2r−τ}),
For z∉[−τ,min{τ,2r−τ}], the density f Z∣T=τ,R=r (z) is 0.
Proof
We denote by Z the random variable d(O,Q)−d(P,Q), where Q is a point chosen uniformly at random from a d-dimensional hyperball with radius \(\sqrt{d}\) centered at the origin. In the following, we assume that the plane spanned by the points O, P, and Q is fixed arbitrarily, and we consider the random experiment conditioned on the event that Q lies in this plane. To make the calculations simpler, we use polar coordinates to describe the location of Q. Since the radius d(O,Q)=r is given, the point Q is completely determined by the angle α between the y-axis and the line between O and Q (see Fig. 9). Hence, the random variable Z can be written as
It is easy to see that Z can only take values in the interval [−τ,min{τ,2r−τ}], and hence the density f Z∣T=τ,R=r (z) is 0 outside this interval.

The random variable Z is defined as r−d(P,Q)
Since Q is chosen uniformly at random from a hyperball centered at the origin, rotational symmetry implies that the angle α is chosen uniformly at random from the interval [0,2π). For symmetry reasons, we can assume that α is chosen uniformly from the interval [0,π). When α is restricted to the interval [0,π), there exists a unique inverse function mapping Z to α, namely
For |x|<1, the derivative of the arc cosine is
Hence, the density f Z∣T=τ,R=r can be expressed as
where f α denotes the density of α, i.e., the density of the uniform distribution over [0,π). Using the chain rule, we obtain that the derivative of α(z) equals

In order to prove the lemma, we distinguish between the cases r≥τ and r<τ.
First case: r≥τ.
In this case, it suffices to show that
which is implied by

This proves the lemma for r≥τ because

where we have used (4.2) for the inequality.
Second case: r<τ.
In this case, it suffices to show that
which is implied by

where the first equivalence follows because the left hand sides of the first and second inequality are identical and where the last equivalence follows because (−2r+z+τ)<0 and (τ+z)>0. Both these inequalities are true because z∈(−τ,min{τ,2r−τ}). Inequality (4.3) follows from

where the first inequality follows because z≤2r−τ. □
Based on Lemma 15, the density of the random variable Δ=Z 1−Z 2 under the conditions R 1:=d(O,Q 1)=r 1, R 2:=d(O,Q 2)=r 2, and T:=d(O,P)=τ can be computed as the convolution of the densities of the random variables Z 1 and −Z 2. The former density equals f Z∣T=τ,R=r and the latter density can easily be obtained from f Z∣T=τ,R=r .
Lemma 16
Let \(\tau,r_{1},r_{2}\in(0,\sqrt{d}]\), and let Z 1 and Z 2 be independent random variables drawn according to the densities \(f_{Z\mid T=\tau,R=r_{1}}\) and \(f_{Z\mid T=\tau,R=r_{2}}\), respectively. For δ∈(0,1/2] and a sufficiently large constant κ, the density \(f_{\varDelta\mid T=\tau,R_{1}=r_{1},R_{2}=r_{2}}(\delta)\) of the random variable Δ=Z 1−Z 2 is bounded from above by
The simple but somewhat tedious calculation that yields Lemma 16 is deferred to Appendix C.1. In order to prove Lemma 14, we need bounds on the densities of the random variables Δ, Z 1, and Z 2 under certain conditions. We summarize these bounds in the following lemma.
Lemma 17
Let \(\tau,r\in(0,\sqrt{d}]\), δ∈(0,1/2], and let κ denote a sufficiently large constant.
-
(a)
For i∈[2], the density of Δ under the condition R i =r is bounded by
$$f_{\varDelta\mid R_i=r}(\delta) \le\frac{\kappa}{\sqrt{r}}\cdot\ln \bigl( \delta^{-1} \bigr). $$ -
(b)
The density of Δ under the condition T=τ is bounded by
$$f_{\varDelta\mid T=\tau}(\delta) \le\frac{\kappa}{\tau}\cdot\ln \bigl( \delta^{-1} \bigr). $$ -
(c)
The density of Δ is bounded by
$$f_{\varDelta}(\delta) \le \kappa\cdot\ln \bigl(\delta^{-1} \bigr). $$ -
(d)
For i∈[2], the density of Z i under the condition T=τ is bounded by
$$f_{Z_i\mid T=\tau}(z) \le\frac{\kappa}{\sqrt{\tau^2-z^2}} $$if |z|<τ. Since Z i takes only values in the interval [−τ,τ], the conditional density \(f_{Z_{i}\mid T=\tau}(z)\) is 0 for z∉[−τ,τ].
Lemma 17 follows from Lemmas 15 and 16 by integrating over all values of the unconditioned distances. The proof can be found in Appendix C.2.
4.2.2 Simplified Random Experiments
In the previous section we did not analyze the random experiment that really takes place. Instead of choosing the points according to the given density functions, we simplified their distributions by placing point O in the origin and by giving the other points P, Q 1, and Q 2 uniform distributions centered around the origin. In our input model, however, each of these points is described by a density function over the unit hypercube. We consider the probability of the event Δ∈[0,ε] in the original input model as well as in the simplified random experiment. In the following, we denote this event by \(\mathcal{E}\). We claim that the simplified random experiment that we analyze is only slightly dominated by the original random experiment, in the sense that the probability of the event \(\mathcal{E}\) in the simplified random experiment is smaller by at most some factor depending on ϕ.
In order to compare the probabilities in the original and in the simplified random experiment, consider the original experiment and assume that the point O lies at position x∈[0,1]d. Then one can identify a region \(\mathcal{R}_{x}\subseteq\mathbb{R}^{3d}\) with the property that the event \(\mathcal{E}\) occurs if and only if the random vector (P,Q 1,Q 2) lies in \(\mathcal{R}_{x}\). No matter how the position x of O is chosen, this region always has the same shape, only its position is shifted. That is, \(\mathcal{R}_{x}=\{(x,x,x)+\mathcal{R}_{0^{d}}\}\). Let \(\mathcal{V}=\sup_{x\in[0,1]^{d}}\operatorname{Vol}(\mathcal {R}_{x}\cap[0,1]^{3d})\). Then the probability of \(\mathcal{E}\) can be bounded from above by \(\phi^{3}\cdot\mathcal{V}\) in the original random experiment because the density of the random vector (P,Q 1,Q 2) is bounded from above by ϕ 3 as P, Q 1, and Q 2 are independent vectors whose densities are bounded by ϕ. Since Δ is invariant under translating O, P, Q 1, and Q 2 by the same vector, we obtain

where the equality follows from shifting \(\mathcal{R}_{x}\cap[0,1]^{3d}\) by (−x,−x,−x). Hence, \(\mathcal{V}\le\mathcal{V}':=\operatorname{Vol}(\mathcal {R}_{0^{d}}\cap[-1,1]^{3d})\). In the simplified random experiment, P, Q 1, and Q 2 are chosen uniformly from the hyperball centered at the origin with radius \(\sqrt{d}\). This hyperball contains the hypercube [−1,1]d completely. Hence, the region on which the vector (P,Q 1,Q 2) is uniformly distributed contains the region \(\mathcal{R}_{0^{d}}\cap[-1,1]^{3d}\) completely. As the vector (P,Q 1,Q 2) is uniformly distributed on a region of volume \(V_{d}(\sqrt{d})^{3}\), where \(V_{d}(\sqrt{d})\) denotes the volume of a d-dimensional hyperball with radius \(\sqrt{d}\), this implies that the probability of \(\mathcal{E}\) in the simplified random experiment can be bounded from below by \(\mathcal{V}'/V_{d}(\sqrt{d})^{3}\). Since a d-dimensional hyperball with radius \(\sqrt{d}\) is contained in a hypercube with side length \(2\sqrt{d}\), its volume can be bounded from above by \((2\sqrt {d})^{d}=(4d)^{d/2}\). Hence, the probability of \(\mathcal{E}\) in the simplified random experiment is at least \(\mathcal{V}'/(4d)^{3d/2}\), and we have argued above that the probability of \(\mathcal{E}\) in the original random experiment is at most \(\phi^{3}\cdot\mathcal{V}\le\phi^{3}\cdot\mathcal{V}'\). Hence, the probability of \(\mathcal{E}\) in the simplified random experiment is smaller by at most a factor of ((4d)d/2 ϕ)3 compared to the original random experiment.
Taking into account this factor and using Lemma 17(c) and a union bound over all possible 2-changes yields the following lemma about the improvement of a single 2-change.
Lemma 18
The probability that there exists an improving 2-change whose improvement is at most ε≤1/2 is bounded from above by O(n 4⋅ϕ 3⋅ε⋅log(1/ε)).
Proof
As in the proof of Theorem 7, we first consider a fixed 2-change S, whose improvement we denote by Δ(S). For the simplified random experiment, Lemma 17(c) yields the following bound on the probability that the improvement Δ(S) lies in (0,ε]:

where we used ε≤1/2 for the last inequality.
We have argued that the probability of the event Δ(S)∈(0,ε] in the simplified random experiment is smaller by at most a factor of ((4d)d/2 ϕ)3 compared to the original random experiment. Together with the factor of at most n 4 coming from a union bound over all possible 2-changes S, we obtain for the original random experiment
which proves the lemma because d is regarded as a constant. □
Using similar arguments as in the proof of Theorem 7 yields the following upper bound on the expected number of 2-changes.
Theorem 19
Starting with an arbitrary tour, the expected number of steps performed by 2-Opt on ϕ-perturbed Euclidean instances is O(n 7⋅log2(n)⋅ϕ 3).
Proof
As in the proof of Theorem 7, let T denote the longest path in the state graph. Let Δ min denote the smallest improvement made by any of the 2-changes. Then, as in the proof of Theorem 7, we know that T≥t implies that \(\varDelta_{\min}\le(\sqrt{d}n)/t\) because each of the n edges in the initial tour has length at most \(\sqrt{d}\). As T cannot exceed n!, we obtain with Lemma 18

which proves the lemma because d is regarded as a constant. □
Pairs of Type 0
In order to improve upon Theorem 19, we consider pairs of linked 2-changes as in the analysis of ϕ-perturbed Manhattan instances. Since our analysis of pairs of linked 2-changes is based on the analysis of a single 2-change that we presented in the previous section, we also have to consider simplified random experiments when analyzing pairs of 2-changes. For a fixed pair of type 0, we assume that point v 3 is chosen to be the origin and the other points v 1, v 2, v 4, v 5, and v 6 are chosen uniformly at random from a hyperball with radius \(\sqrt{d}\) centered at v 3. Let \(\mathcal{E}\) denote the event that both Δ 1 and Δ 2 lie in the interval [0,ε], for some given ε. With the same arguments as above, one can see that the probability of \(\mathcal{E}\) in the simplified random experiment is smaller compared to the original experiment by at most a factor of ((4d)d/2 ϕ)5. The exponent 5 is due to the fact that we have now five other points instead of only three.
Pairs of Type 1
For a fixed pair of type 1, we consider the simplified random experiment in which v 2 is placed in the origin and the other points v 1, v 3, v 4, and v 5 are chosen uniformly at random from a hyperball with radius \(\sqrt{d}\) centered at v 2. In this case, the probability in the simplified random experiment is smaller by at most a factor of ((4d)d/2 ϕ)4. The exponent 4 is due to the fact that we have now four other points.
4.2.3 Analysis of Pairs of Linked 2-Changes
Finally, we can prove Lemma 14.
Proof of Lemma 14
We start by considering pairs of type 0. We consider the simplified random experiment in which v 3 is chosen to be the origin and the other points are drawn uniformly at random from a hyperball with radius \(\sqrt{d}\) centered at v 3. If the position of the point v 1 is fixed, then the events Δ 1∈[0,ε] and Δ 2∈[0,ε] are independent as only the vertices v 1 and v 3 appear in both the first and the second step. In fact, because the densities of the points v 2, v 4, v 5, and v 6 are rotationally symmetric, the concrete position of v 1 is not important in our simplified random experiment anymore; only the distance R between v 1 and v 3 is of interest.
For i∈[2], we determine the conditional probability of the event Δ i ∈[0,ε] under the condition that the distance d(v 1,v 3) is fixed with the help of Lemma 17(a), and obtain

where the last inequality follows because, as ε≤1/2, 1≤2ln(1/ε). Since for fixed distance d(v 1,v 3) the random variables Δ 1 and Δ 2 are independent, we obtain
For \(r\in[0,\sqrt{d}]\), the density \(f_{\mathsf{d}(v_{1},v_{3})}\) of the random variable d(v 1,v 3) in the simplified random experiment is r d−1/d d/2−1. In order to see this, remember that v 3 is chosen to be the origin and v 1 is chosen uniformly at random from a hyperball with radius \(\sqrt{d}\) centered at the origin. The volume V d (r) of a d-dimensional hyperball with radius r is C d ⋅r d for some constant C d depending on d. Now the density \(f_{\mathsf{d}(v_{1},v_{3})}\) can be written as
Combining this observation with the bound given in (4.5) yields

where the last equation follows because d is assumed to be a constant. There are O(n 6) different pairs of type 0; hence a union bound over all of them concludes the proof of the first term in the sum in Lemma 14 when taking into account the factor ((4d)d/2 ϕ)5 that results from considering the simplified random experiment (see Sect. 4.2.2).
It remains to consider pairs of type 1. We consider the simplified random experiment in which v 2 is chosen to be the origin and the other points are drawn uniformly at random from a hyperball with radius \(\sqrt{d}\) centered at v 2. In contrast to pairs of type 0, pairs of type 1 exhibit larger dependencies as only 5 different vertices are involved in these pairs. Fix one pair of type 1. The two 2-changes share the whole triangle consisting of v 1, v 2, and v 3. In the second step, there is only one new vertex, namely v 5. Hence, there is not enough randomness contained in a pair of type 1 such that Δ 1 and Δ 2 are nearly independent as for pairs of type 0.
We start by considering pairs of type 1(a) as defined in Sect. 4.1.1. First, we analyze the probability that Δ 1 lies in the interval [0,ε]. After that, we analyze the probability that Δ 2 lies in the interval [0,ε] under the condition that the points v 1, v 2, v 3, and v 4 have already been chosen. In the analysis of the second step we cannot make use of the fact that the distances d(v 1,v 3) and d(v 2,v 3) are random variables anymore since we exploited their randomness already in the analysis of the first step. The only distances whose randomness we can exploit are the distances d(v 1,v 5) and d(v 2,v 5). We pessimistically assume that the distances d(v 1,v 3) and d(v 2,v 3) have been chosen by an adversary. This means the adversary can determine an interval of length ε in which the random variable d(v 2,v 5)−d(v 1,v 5) must lie in order for Δ 2 to lie in [0,ε].
Analogously to (4.4), the probability of the event Δ 1∈[0,ε] under the condition d(v 1,v 2)=r can be bounded by
Due to Lemma 17(d), the conditional density of the random variable Z=d(v 2,v 5)−d(v 1,v 5) under the condition d(v 1,v 2)=r can be bounded by
for |z|<r. Note that Lemma 17(d) applies if we set O=v 2, P=v 1, and Q i =v 5. Then T=d(O,P)=d(v 1,v 2).
This upper bound on the density function \(f_{Z\mid \mathsf {d}(v_{1},v_{2})=r}(z)\) is symmetric around zero, it is monotonically increasing for z∈[0,r), and it is monotonically decreasing in (−r,0). This implies that the intervals the adversary can specify that have the highest upper bound on the probability of Z falling into them are [−r,−r+ε] and [r−ε,r]. Hence, the conditional probability of the event Δ 2∈[0,ε] under the condition d(v 1,v 2)=r and for fixed points v 3 and v 4 is bounded from above by
where the lower bound in the integral follows because Z can only take values in [−r,r]. This can be rewritten as
For ε≤r, we have r−ε≥0≥−r and hence,
For ε∈(r,2r], we have 0≥r−ε≥−r and hence,

where we used ε>r for the last inequality. For ε>2r, we have r−ε≤−r and hence,
where we used ε>r for the penultimate inequality. Altogether this argument shows that
Since (4.7) uses only the randomness of v 5 which is independent of Δ 1, we can multiply the upper bounds from (4.6) and (4.7) to obtain
In order to get rid of the condition d(v 1,v 2)=r, we integrate over all possible values the random variable d(v 1,v 2) can take, yielding

where the last equation follows because d is assumed to be constant. Applying a union bound over all O(n 5) possible pairs of type 1(a) concludes the proof when one takes into account the factor ((4d)d/2 ϕ)4 due to considering the simplified random experiment (see Sect. 4.2.2).
For pairs of type 1(b), the situation looks somewhat similar. We analyze the first step and in the second step, we can only exploit the randomness of the distances d(v 2,v 5) and d(v 3,v 5). Due to Lemma 17(b) and similarly to (4.4), the probability of the event Δ 1∈[0,ε] under the condition d(v 2,v 3)=τ can be bounded by
The remaining analysis of pairs of type 1(b) can be carried out completely analogously to the analysis of pairs of type 1(a). □
4.2.4 The Expected Number of 2-Changes
Based on Lemmas 9 and 14, we are now able to prove part (b) of Theorem 2, which states that the expected length of the longest path in the 2-Opt state graph is O(n 4+1/3⋅log(nϕ)⋅ϕ 8/3) for ϕ-perturbed Euclidean instances with n points.
Proof of Theorem 2(b)
We use the same notation as in the proof of part (a) of the theorem. For t>2n 2, we have t/6−7n(n−1)/24>t/48 and hence using Lemma 14 with \(\varepsilon=\frac {48\sqrt{d}n}{t}\) yields
This implies that the expected length of the longest path in the state graph is bounded from above by

In the following, we use the fact that, for a>0,
For t A =n 4⋅log(nϕ)⋅ϕ 5/2, the first sum in (4.9) can be bounded as follows:

In the following, we use the fact that, for a>0,
For t B =n 13/3⋅log2/3(nϕ)⋅ϕ 8/3, the second sum in (4.9) can be bounded as follows:

Together this yields
which concludes the proof of part (b) of the theorem. □
Using the same observations as in the proof of Theorem 3(a) also yields part (b):
Proof of Theorem 3(b)
Estimating the length of the initial tour by O(n (d−1)/d⋅logn) instead of O(n) improves the upper bound on the expected number of 2-changes by a factor of Θ(n 1/d/logn) compared to Theorem 2(b). This observation yields the bound claimed in Theorem 3(b). □
5 Expected Approximation Ratio
In this section, we consider the expected approximation ratio of the solution found by 2-Opt on ϕ-perturbed L p instances. Chandra, Karloff, and Tovey [3] show that if one has a set of n points in the unit hypercube [0,1]d and the distances are measured according to a metric that is induced by a norm, then every locally optimal solution has length at most c⋅n (d−1)/d for an appropriate constant c depending on the dimension d and the metric. Hence, it follows for every L p metric that 2-Opt yields a tour of length O(n (d−1)/d) on ϕ-perturbed L p instances. This implies that the approximation ratio of 2-Opt on these instances can be bounded from above by \(O(n^{(d-1)/d})/\operatorname{Opt}\), where \(\operatorname{Opt}\) denotes the length of the shortest tour. We will show a lower bound on \(\operatorname{Opt}\) that holds with high probability in ϕ-perturbed L p instances. Based on this, we prove Theorem 4.
Proof of Theorem 4
Let \(v_{1},\ldots,v_{n}\in\mathbb{R}^{d}\) denote the points of the ϕ-perturbed instance. We denote by k the largest integer k≤nϕ that can be written as k=ℓ d for some \(\ell\in\mathbb{N}\). We partition the unit hypercube into k smaller hypercubes with volume 1/k each and analyze how many of these smaller hypercubes contain at least one of the points. Assume that X>3d of these hypercubes contain a point; then the optimal tour must have length at least
In order to see this, we construct a set P⊆{v 1,…,v n } of points as follows: Consider the points v 1,…,v n one after another, and insert a point v i into P if P does not contain a point in the same hypercube as v i or in one of its 3d−1 neighboring hypercubes yet. Due to the triangle inequality, the optimal tour on P is at most as long as the optimal tour on v 1,…,v n . Furthermore, P contains at least ⌈X/3d⌉≥2 points and every edge between two points from P has length at least \(1/\sqrt[d]{k}\) since P does not contain two points in the same or in two neighboring hypercubes. Hence, it remains to analyze the random variable X. For each hypercube i with 1≤i≤k, we define a random variable X i which takes value 0 if hypercube i is empty and value 1 if hypercube i contains at least one point. The density functions that specify the locations of the points induce for each pair of hypercube i and point j a probability \(p_{i}^{j}\) such that point j falls into hypercube i with probability \(p_{i}^{j}\). Hence, one can think of throwing n balls into k bins in a setting where each ball has its own probability distribution over the bins. Due to the bounded density, we have \(p_{i}^{j}\le\phi/k\). For each hypercube i, let M i denote the probability mass associated with hypercube i, that is
We can write the expected value of the random variable X i as
as, under the constraint \(\sum_{j}(1-p_{i}^{j})=n-M_{i}\), the term \(\prod_{j}(1-p_{i}^{j})\) is maximized if all \(p_{i}^{j}\) are equal. Due to linearity of expectation, the expected value of X is
Observe that ∑ i M i =n and hence, also the sum ∑ i (1−M i /n)=k−1 is fixed. As the function f(x)=x n is convex for n≥1, the sum ∑ i (1−M i /n)n becomes maximal if the M i ’s are chosen as unbalanced as possible. Hence, we assume that ⌈k/ϕ⌉ of the M i ’s take their maximal value of nϕ/k and the other M i ’s are zero. This yields, for sufficiently large n,

For the second inequality we have used that \(\frac{k}{\phi}\ge1\) for sufficiently large n and hence \(\lceil\frac{k}{\phi} \rceil\le\frac{2k}{\phi}\). For the third inequality we have used that \(n\ge\frac{k}{\phi}\), which follows from the definition of k as the largest integer k≤nϕ that can be written as k=ℓ d for some \(\ell\in\mathbb{N}\). This definition also implies
and hence, E[X]≥n/2d+2.
Next we show that X is sharply concentrated around its mean value. The random variable X is the sum of k 0-1-random variables X i . If these random variables were independent, we could simply use a Chernoff bound to bound the probability that X takes a value that is much smaller than its mean value. Intuitively, whenever we already know that some of the X i ’s are zero, then the probability of the event that another X i also takes the value zero becomes smaller. Hence, intuitively, the dependencies can only help to bound the probability that X takes a value smaller than its mean value.
To formalize this intuition, we use the framework of negatively associated random variables, introduced by Dubhashi and Ranjan [4]. In Appendix D, we repeat the formal definition and we show that the X i are negatively associated. Dubhashi and Ranjan show (Proposition 7 of [4]) that in the case of negatively associated random variables, one can still apply a Chernoff bound. The Chernoff bound from [14] implies that, for any δ∈(0,1),
This yields
where we used E[X]≥n/2d+2 for the first and last inequality.
In order to bound the expected approximation ratio of any locally optimal solution, we distinguish between two cases:
-
If \(X\ge\frac{n}{2^{d+3}}\), then, assuming that n is large enough, we have that X>3d and hence, (5.1) implies that
$$\operatorname{Opt}\ge \biggl\lceil\frac{X}{3^d} \biggr\rceil\cdot \frac{1}{\sqrt[d]{k}} \ge \frac{X}{3^d\sqrt[d]{k}} \ge\frac{n}{2^{d+3}3^d\sqrt[d]{k}} = \varTheta \biggl(\frac{n^{(d-1)/d}}{\sqrt[d]{\phi}} \biggr), $$where we used that k=Θ(nϕ) for the last equation. Combining this with Chandra, Karloff, and Tovey’s [3] result that every locally optimal solution has length at most O(n (d−1)/d) yields an approximation ratio of
$$\frac{O(n^{(d-1)/d})}{\varTheta (\frac{n^{(d-1)/d}}{\sqrt [d]{\phi }} )} = O\bigl(\sqrt[d]{\phi}\bigr). $$ -
If \(X < \frac{n}{2^{d+3}}\), then we use n as an upper bound on the approximation ratio of any locally optimal solution. This bound holds in fact for any possible tour, as the following argument shows: The length of every tour is bounded from above by n times the length α of the longest edge. Let u and v be the vertices that this edge connects. Then every tour has to contain a path between u and v. Due to the triangle inequality, this path must have length at least α.
We have seen in (5.2) that the event \(X < \frac{n}{2^{d+3}}\) occurs only with exponentially small probability. This implies that it adds at most
$$\exp \biggl(-\frac{n}{2^{d+5}} \biggr)\cdot n = o(1) $$to the expected approximation ratio.
This concludes the proof as the contribution of both cases to the expected approximation ratio is \(O(\sqrt[d]{\phi})\). □
6 Smoothed Analysis
Smoothed Analysis was introduced by Spielman and Teng [19] as a hybrid of worst case and average case analysis. The semi-random input model in a smoothed analysis is designed to capture the behavior of algorithms on typical inputs better than a worst case or average case analysis alone as it allows an adversary to specify an arbitrary input which is randomly perturbed afterwards. In Spielman and Teng’s analysis of the Simplex algorithm the adversary specifies an arbitrary linear program which is perturbed by adding independent Gaussian random variables to each number in the linear program. Our probabilistic analysis of Manhattan and Euclidean instances can also be seen as a smoothed analysis in which an adversary can choose the distributions for the points over the unit hypercube. The adversary is restricted to distributions that can be represented by densities that are bounded by ϕ. Our model cannot handle Gaussian perturbations directly because the support of Gaussian random variables is not bounded.
Assume that every point v 1,…,v n is described by a density whose support is restricted to the hypercube [−α,1+α]d, for some α≥1. Then after appropriate scaling and translating, we can assume that all supports are restricted to the unit hypercube [0,1]d. Thereby, the maximal density ϕ increases by at most a factor of (2α+1)d. Hence, after appropriate scaling and translating, Theorems 2, 3, and 4 can still be applied if one takes into account the increased densities.
One possibility to cope with Gaussian perturbations is to consider truncated Gaussian perturbations. In such a perturbation model, the coordinates of each point are initially chosen from [0,1]d and then perturbed by adding Gaussian random variables with mean 0 and with some standard deviation σ to them that are conditioned to lie in [−α,α] for some α≥1. The maximal density of such truncated Gaussian random variables for σ≤1 is bounded from above by
This is shown by the following calculation in which we denote by X a Gaussian random variable with mean 0 and standard deviation σ, by \(f(z)=\exp(-z^{2}/(2\sigma^{2}))/ (\sigma\sqrt{2\pi})\) its density function and by f X∣X∈[−α,α] the density of X conditioned on the fact that X∈[−α,α]:

where we used the following bound on the probability that X does not lie in [−α,α]:

where the inequality follows from α≥1.
After such a truncated perturbation, all points lie in the hypercube [−α,1+α]d. Hence, one can apply Theorems 2, 3, and 4 with
where the first equality follows from (6.1) and the observation that shifting and scaling the hypercube [−α,1+α]d to [0,1]d leads to densities that are larger than the original densities by at most a factor of (2α+1)d. The second equality follows because the term \(\sigma^{2}\sqrt{2\pi }\exp(-\alpha^{2}/(2\sigma^{2}))\) is in o(σ) if σ goes to 0.
It is not necessary to truncate the Gaussian random variables if the standard deviation is small enough. For \(\sigma\le \min\{\alpha/\sqrt{2(n+1)\ln{n}+2\ln{d}},1\}\), the probability that one of the Gaussian random variables has an absolute value larger than α≥1 is bounded from above by n −n. This follows from a union bound over all dn Gaussian variables and (6.2):
We have used σ≤1 for the second inequality. In this case, even if one does not truncate the random variables, Theorems 2, 3, and 4 can be applied with ϕ=O(α d/σ d). To see this, it suffices to observe that the worst-case bound for the number of 2-changes is n! and the worst-case approximation ratio is O(logn) [3]. Multiplying these values with the failure probability of n −n adds less than 1 to the expected values. In particular, this implies that the expected length of the longest path in the state graph is bounded by O(poly(n,1/σ)).
7 Conclusions and Open Problems
We have shown several new results on the running time and the approximation ratio of the 2-Opt heuristic. However, there are still a variety of open problems regarding this algorithm. Our lower bounds only show that there exist families of instances on which 2-Opt takes an exponential number of steps if it uses a particular pivot rule. It would be interesting to analyze the diameter of the state graph and to either present instances on which every pivot rule needs an exponential number of steps or to prove that there is always an improvement sequence of polynomial length to a locally optimal solution. Also the worst number of local improvements for some natural pivot rules like, e.g., the one that always makes the largest possible improvement or the one that always chooses a random improving 2-change, is not known yet. Furthermore, the complexity of computing locally optimal solutions is open. The only result in this regard is due to Krentel [9] who shows that it is PLS-complete to compute a local optimum for the metric TSP for k-Opt for some constant k. It is not known whether his construction can be embedded into the Euclidean metric and whether it is PLS-complete to compute locally optimal solutions for 2-Opt. Fischer and Torenvliet [6] show, however, that for the general TSP, it is PSPACE-hard to compute a local optimum for 2-Opt that is reachable from a given initial tour.
The obvious open question concerning the probabilistic analysis is how the gap between experiments and theory can be narrowed further. In order to tackle this question, new methods seem to be necessary. Our approach, which is solely based on analyzing the smallest improvement made by a sequence of linked 2-changes, seems to yield too pessimistic bounds. Another interesting area to explore is the expected approximation ratio of 2-Opt. In experiments, approximation ratios close to 1 are observed. For instances that are chosen uniformly at random, the bound on the expected approximation ratio is a constant but unfortunately a large one. It seems to be a very challenging problem to improve this constant to a value that matches the experimental results.
Besides 2-Opt, there are also other local search algorithms that are successful for the traveling salesperson problem. In particular, the Lin–Kernighan heuristic [11] is one of the most successful local search algorithm for the symmetric TSP. It is a variant of k-Opt in which k is not fixed and it can roughly be described as follows: Each local modification starts by removing one edge {a,b} from the current tour, which results in a Hamiltonian path with the two endpoints a and b. Then an edge {b,c} is added, which forms a cycle; there is a unique edge {c,d} incident to c whose removal breaks the cycle, producing a new Hamiltonian path with endpoints a and d. This operation is called a rotation. Now either a new Hamiltonian cycle can be obtained by adding the edge {a,d} to the tour or another rotation can be performed. There are a lot of different variants and heuristic improvements of this basic scheme, but little is known theoretically. Papadimitriou [16] shows for a variant of the Lin–Kernighan heuristic that computing a local optimum is PLS-complete, which is a sharp contrast to the experimental results. Since the Lin–Kernighan heuristic is widely used in practice, a theoretical explanation for its good behavior in practice is of great interest. Our analysis of 2-Opt relies crucially on the fact that there are only a polynomial number of different 2-changes. For the Lin–Kernighan heuristic, however, the number of different local improvements is exponential. Hence, it is an interesting question as to whether nonetheless the smallest possible improvement is polynomially large or whether different methods yield a polynomial upper bound on the expected running time of the Lin–Kernighan heuristic.
References
Arora, S.: Polynomial time approximation schemes for Euclidean traveling salesman and other geometric problems. J. ACM 45(5), 753–782 (1998)
Bronshtein, I.N., Semendyayev, K.A., Musiol, G., Mühlig, H.: Handbook of Mathematics. Springer, Berlin (2007)
Chandra, B., Karloff, H.J., Tovey, C.A.: New results on the old k-Opt algorithm for the traveling salesman problem. SIAM J. Comput. 28(6), 1998–2029 (1999)
Dubhashi, D.P., Ranjan, D.: Balls and bins: a study in negative dependence. Random Struct. Algorithms 13(2), 99–124 (1998)
Englert, M., Röglin, H., Vöcking, B.: Worst case and probabilistic analysis of the 2-Opt algorithm for the TSP. In: Proc. of the 18th ACM-SIAM Symp. on Discrete Algorithms (SODA), pp. 1295–1304 (2007)
Fischer, S., Torenvliet, L.: The malleability of TSP2opt. In: Proc. of the 21st Int. Workshop on Graph-Theoretic Concepts in Computer Science (WG), pp. 152–166 (1995)
Johnson, D.S., McGeoch, L.A.: The traveling salesman problem: a case study in local optimization. In: Aarts, E.H.L., Lenstra, J.K. (eds.) Local Search in Combinatorial Optimization. Wiley, New York (1997)
Kern, W.: A probabilistic analysis of the switching algorithm for the Euclidean TSP. Math. Program. 44(2), 213–219 (1989)
Krentel, M.W.: Structure in locally optimal solutions. In: Proc. of the 30th Ann. IEEE Symp. on Foundations of Computer Science (FOCS), pp. 216–221 (1989)
Lenzen, C., Wattenhofer, R.: Tight bounds for parallel randomized load balancing. Technical Report 324, Computer Engineering and Networks Laboratory, ETH, Zurich (2010)
Lin, S., Kernighan, B.W.: An effective heuristic for the traveling salesman problem. Oper. Res. 21, 489–516 (1973)
Lueker, G.S.: Unpublished manuscript, Princeton University (1975)
Mitchell, J.S.B.: Guillotine subdivisions approximate polygonal subdivisions: a simple polynomial-time approximation scheme for geometric TSP, k-MST, and related problems. SIAM J. Comput. 28(4), 1298–1309 (1999)
Motwani, R., Raghavan, P.: Randomized Algorithms. Cambridge University Press, Cambridge (1995)
Papadimitriou, C.H.: The Euclidean traveling salesman problem is NP-complete. Theor. Comput. Sci. 4(3), 237–244 (1977)
Papadimitriou, C.H.: The complexity of the Lin-Kernighan heuristic for the traveling salesman problem. SIAM J. Comput. 21(3), 450–465 (1992)
Reinelt, G.: TSPLIB—a traveling salesman problem library. ORSA J. Comput. 3(4), 376–384 (1991)
Rosenkrantz, D.J., Stearns, R.E., Lewis II, P.M.: An analysis of several heuristics for the traveling salesman problem. SIAM J. Comput. 6(3), 563–581 (1977)
Spielman, D.A., Teng, S.-H.: Smoothed analysis of algorithms: why the simplex algorithm usually takes polynomial time. J. ACM 51(3), 385–463 (2004)
van Leeuwen, J., Schoon, A.A.: Untangling a traveling salesman tour in the plane. In: Proc. of the 7th Int. Workshop on Graph-Theoretic Concepts in Computer Science (WG), pp. 87–98 (1981)
Acknowledgements
This work was supported in part by the EU within the 6th Framework Programme under contract 001907 (DELIS), by DFG grants VO 889/2 and WE 2842/1, and by EPSRC grant EP/F043333/1. We thank the referee for extraordinary efforts and many helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
An extended abstract appeared in Proc. of the 18th ACM-SIAM Symposium on Discrete Algorithms (SODA 2007).
Appendices
Appendix A: Inequalities from Sect. 3.2.2
Inequalities corresponding to the improvements made by the 2-changes in the sequence in which \(G_{n-1}^{P}\) changes its state from (S,L) to (S,S) while resetting \(G_{n-1}^{R}\):
Inequality 1:
For p≥3, we obtain
and
Hence, for p≥3,

Inequality 2:
For p≥4, we obtain
and
Hence, for p≥4,

For the remaining case p=3, the inequality can simply be checked by plugging in the appropriate values.
Inequality 3:
For p≥4, we obtain
and
Hence, for p≥4,

For the remaining case p=3, the inequality can simply be checked by plugging in the appropriate values.
Inequality 4:
For p≥3, we obtain
and
Hence, for p≥3,

Inequality 5:
For p≥7, we obtain
and
Hence, for p≥7,

For the remaining cases p∈{3,4,5,6}, the inequality can simply be checked by plugging in the appropriate values.
Inequality 6:
For p≥5, we obtain
and
Hence, for p≥5,

For the remaining cases p∈{3,4}, the inequality can simply be checked by plugging in the appropriate values.
Inequality 7:
For p≥3, we obtain
and
Hence, for p≥3,

Inequalities corresponding to the improvements made by the 2-changes in the sequence in which gadget \(G^{R}_{n-2}\) resets gadget \(G^{P}_{n-1}\) from (S,S) to (L,L):
Inequality 1:
For p≥10, we obtain
and
Hence, for p≥10,

For the remaining cases p∈{3,4,5,6,7,8,9}, the inequality can simply be checked by plugging in the appropriate values.
Inequality 2:
For p≥4, we obtain
and
Hence, for p≥4,

For the remaining case p=3, the inequality can simply be checked by plugging in the appropriate values.
Inequality 3:

For p≥4, we obtain
and
Hence, for p≥4,

For the remaining case p=3, the inequality can simply be checked by plugging in the appropriate values.
Inequality 4:
For p≥5, we obtain
and
Hence, for p≥5,

For the remaining cases p∈{3,4}, the inequality can simply be checked by plugging in the appropriate values.
Inequality 5:
For p≥3, we obtain
Hence, for p≥3,

Inequality 6:
For p≥7, we obtain
and
Hence, for p≥7,

For the remaining cases p∈{3,4,5,6}, the inequality can simply be checked by plugging in the appropriate values.
Inequality 7:
For p≥4, we obtain
and
Hence, for p≥4,

For the remaining case p=3, the inequality can simply be checked by plugging in the appropriate values.
Appendix B: Some Probability Theory
Lemma 20
Let X 1,…,X n∈[0,1]d be stochastically independent d-dimensional random row vectors, and, for i∈[n] and some ϕ≥1, let f i :[0,1]d→[0,ϕ] denote the joint probability density of the entries of X i. Furthermore, let \(\lambda^{1},\ldots,\lambda^{k}\in\mathbb {Z}^{dn}\) be fixed linearly independent row vectors. For i∈[n] and a fixed ε≥0, we denote by \(\mathcal{A}_{i}\) the event that λ i⋅X takes a value in the interval [0,ε], where X denotes the vector \(X=(X^{1},\ldots,X^{n})^{\operatorname{T}}\). Under these assumptions,
Proof
The main tool for proving the lemma is a change of variables. Instead of using the canonical basis of the dn-dimensional vector space \(\mathbb{R}^{dn}\), we use the given linear combinations as basis vectors. To be more precise, the basis \(\mathcal{B}\) that we use consists of two parts: it contains the vectors λ 1,…,λ k and it is completed by some vectors from the canonical basis {e 1,…,e dn}, where e i denotes the i-th canonical row vector, i.e., \(e^{i}_{i}=1\) and \(e^{i}_{j}=0\) for j≠i. That is, the basis \(\mathcal{B}\) can be written as {λ 1,…,λ k,e π(1),…,e π(dn−k)}, for some injective function π:[dn−k]→[dn].
Let \(\varPhi\colon\mathbb{R}^{dn}\to\mathbb{R}^{dn}\) be defined by Φ(x)=Ax, where A denotes the (dn)×(dn)-matrix
Since \(\mathcal{B}\) is a basis of \(\mathbb{R}^{dn}\), the function Φ is a bijection. We define \(Y=(Y_{1},\ldots,Y_{dn})^{\operatorname{T}}\) as Y=Φ(X), and for i∈[n], we denote by Y i the vector (Y d(i−1)+1,…,Y di ). Let \(f\colon\mathbb{R}^{dn}\to \mathbb{R}\) denote the joint density of the entries of the random vectors X 1,…,X n, and let \(g\colon\mathbb{R}^{dn}\to\mathbb{R}\) denote the joint density of the entries of the random vectors Y 1,…,Y n. Due to the independence of the random vectors X 1,…,X n, we have f(x 1,…,x dn )=f 1(x 1,…,x d )⋅⋯⋅f n (x d(n−1)+1,…,x dn ). We can express the joint density g as
where det ∂ denotes the determinant of the Jacobian matrix of Φ −1 (see, e.g., [19]).
The matrix A is invertible as \(\mathcal{B}\) is a basis of \(\mathbb{R}^{dn}\). Hence, for \(y\in\mathbb{R}^{dn}\), Φ −1(y)=A −1 y and the Jacobian matrix of Φ −1 equals A −1. Thus, det ∂ Φ −1=detA −1=(detA)−1. Since all entries of A are integers, also its determinant must be an integer, and since it has rank dn, we know that detA≠0. Hence, |detA|≥1 and |detA −1|≤1. For \(y\in\mathbb{R}^{dn}\), we decompose \(\varPhi^{-1}(y)\in\mathbb{R}^{dn}\) into n subvectors with d entries each, i.e., \(\varPhi^{-1}(y)=(\varPhi^{-1}_{1}(y),\ldots,\varPhi ^{-1}_{n}(y))\) with \(\varPhi^{-1}_{i}(y)\in\mathbb{R}^{d}\) for i∈[n]. This yields
where we used that |detA −1|≤1 and that the vectors X 1,…,X n are stochastically independent.
The probability we want to estimate can be written as
Since all entries of the vectors X 1,…,X n take only values in the interval [0,1] and since for i∈{k+1,…,dn}, the random variable Y i coincides with one of these entries, (B.1) simplifies to
By the definition of π, the basis \(\mathcal{B}\) consists of the vectors λ 1,…,λ k and the canonical vectors e i for i∈Π={ℓ∣∃j∈[dn−k]:π(j)=ℓ}. We divide the vectors e 1,…,e dn into n groups of d vectors each, i.e., the first group consists of the vectors e 1,…,e d, the second group consists of the vectors e d+1,…,e 2d, and so on. The set of vectors e i with i∉Π, i.e., the vectors from the canonical basis that are replaced by the vectors λ 1,…,λ k in basis \(\mathcal{B}\), can intersect at most k of these groups. In order to simplify the notation, we reorder and rename the groups such that only vectors from the first k groups are replaced by the vectors λ 1,…,λ k. As every group consists of d vectors, we can assume that, after renaming, [dn]∖Π⊆[dk], i.e., only vectors e i from the canonical basis with i≤dk are replaced by the vectors λ 1,…,λ k in the basis \(\mathcal{B}\). After that, we can reorder and rename the groups k+1,…,n such that π(i)=i, for i>dk. This implies, in particular, that for i>k we have \(\varPhi^{-1}_{i}(y)=(y_{di+1},\ldots,y_{d(i+1)})\). Under these assumptions, the density g can be upper bounded as follows:
where we bounded each of the densities f 1,…,f k from above by ϕ and used that \(\varPhi^{-1}_{i}(y)=(y_{di+1},\ldots,y_{d(i+1)})\) for i>k.
Putting together (B.2) and (B.3) yields
where the last equation follows because f k+1,…,f n are density functions. The occurrence of ε k is due to the first k integrals in (B.2) because each of the variables y 1,…,y k is integrated over an interval of length ε and none of them appears in the integrand coming from (B.3). □
Appendix C: Proofs of Some Lemmas from Sect. 4.2
3.1 C.1 Proof of Lemma 16
Let a,c∈(0,C] for some C>0. In the following proof, we use the following two identities (see [2]):

and

Since in both identities the integrands are non-negative, the following inequalities are true for any [α 1,α 2]⊆[0,c] and [β 1,β 2]⊆[0,a]:
and
We will frequently use these inequalities in the following.
Proof of Lemma 16
The conditional density of Δ can be calculated as convolution of the conditional densities of Z 1 and Z 2 as follows:
In order to estimate this integral, we distinguish between several cases. In the following, let κ denote a sufficiently large constant.
First case: τ≤r 1 and τ≤r 2.
Since Z i takes only values in the interval [−τ,τ], we can assume 0<δ≤min{1/2,2τ} and
Due to Lemma 15, we can estimate the densities of Z 1 and Z 2 by
For δ∈(0,min{1/2,2τ}], we obtain the following upper bound on the density of Δ:

For the four integrals, we used the substitutions z′=τ−z, z′=τ+z, z′=τ−z, and z′=τ−δ+z, respectively. Using (C.1) and (C.2) and the fact that \(2\tau-\delta\le2\sqrt{d}=O(1)\) yields that the previous term is bounded from above by

Since we assume that δ≤1/2, the logarithm ln(δ −1) is bounded from below by the constant ln(2). Using this observation, we can absorb the O(1) term and bound the previous expression from above by
if κ is a large enough constant.
Second case: r 1≤τ and r 2≤τ.
Since Z i takes only values in the interval [−τ,2r i −τ], we can assume 0<δ≤min{1/2,2r 1} and
The limits of the integral follow because \(f_{Z\mid T=\tau,R=r_{1}}(z)\) is only nonzero for z∈[−τ,2r 1−τ] and \(f_{Z\mid T=\tau,R=r_{2}}(z-\delta)\) is only nonzero for z∈[−τ+δ,2r 2−τ+δ]. The intersection of these two intervals is [−τ+δ,min{2r 1−τ,2r 2−τ+δ}].
Due to Lemma 15, we can estimate the densities of Z 1 and Z 2 by

Case 2.1: δ∈(max{0,2(r 1−r 2)},2r 1].
We obtain the following upper bound on the density of Δ:

For the four integrals, we used the substitutions z′=z+τ−δ, z′=z+τ−δ, z′=z+τ, and z′=2r 1−τ−z, respectively. Using (C.1) and (C.2) and the facts that \(2r_{1}-\delta\le2\sqrt{d}\) and \(2(r_{2}-r_{1})+\delta\le2r_{2} \le2\sqrt{d}\) yields that the previous term is bounded from above by

where the last inequality assumes that κ is a large enough constant.
Case 2.2: δ∈(0,max{0,2(r 1−r 2)}).
We obtain the following upper bound on the density of Δ:

For the four integrals, we used the substitutions z′=z+τ−δ, z′=z+τ−δ, z′=2r 2−τ+δ−z, and z′=2r 2−τ+δ−z, respectively. Using (C.1) and (C.2) and the facts that \(\delta\le2(r_{1}-r_{2}) \le2\sqrt{d}\) and \(2(r_{1}-r_{2})-\delta\le2(r_{1}-r_{2}) \le2\sqrt{d}\) yields the penultimate inequality. The last inequality follows for the same reasons as in Case 2.1.
Third case: r 1≤τ≤r 2.
Since Z 1 takes only values in the interval [−τ,2r 1−τ] and Z 2 takes only values in the interval [−τ,τ], the random variable Δ=Z 1−Z 2 takes only values in the interval [−2τ,2r 1]. For δ∉[−2τ,2r 1], the density of Δ is trivially zero. As additionally, by definition, δ∈(0,1/2], we can assume 0<δ≤min{1/2,2r 1} and
Using (C.3) and (C.4), we obtain the following upper bound on the density of Δ for δ∈(0,min{1/2,2r 1}]:

For the four integrals, we used the substitutions z′=z+τ, z′=2r 1−τ−z, z′=z+τ−δ, and z′=z+τ−δ, respectively. Using (C.1) and (C.2) and the facts that \(2(\tau-r_{1})+\delta\le2\tau\le2\sqrt{d}\) and \(\delta\le2r_{1} \le2\sqrt{d}\) yields the penultimate inequality. The last inequality follows for the same reasons as in Case 2.1.
Fourth case: r 2≤τ≤r 1.
Since Z 1 takes only values in the interval [−τ,τ] and Z 2 takes only values in the interval [−τ,2r 2−τ], the random variable Δ=Z 1−Z 2 takes only values in the interval [−2r 2,2τ]. For δ∉[−2r 2,2τ], the density of Δ is trivially zero. As additionally, by definition, δ∈(0,1/2], we can assume 0<δ≤min{1/2,2τ} and
The limits of the integral follow because \(f_{Z\mid T=\tau,R=r_{1}}(z)\) is only nonzero for z∈[−τ,τ] and \(f_{Z\mid T=\tau,R=r_{2}}(z-\delta)\) is only nonzero for z∈[−τ+δ,2r 2−τ+δ]. The intersection of these two intervals is [−τ+δ,min{2r 2−τ+δ,τ}].
Case 4.1: δ∈(0,2(τ−r 2)).
Using (C.3) and (C.4), we obtain the following upper bound on the density of Δ:

For the four integrals, we used the substitutions z′=z+τ−δ, z′=z+τ−δ, z′=2r 2−τ−z+δ, and z′=2r 2−τ−z+δ, respectively. Using (C.1) and (C.2) and the facts that \(\delta\le2r_{2} \le2\sqrt{d}\) and \(2(\tau-r_{2})-\delta\le2\tau\le2\sqrt{d}\) yields the penultimate inequality. The last inequality follows for the same reasons as in Case 2.1.
Case 4.2: δ∈(2(τ−r 2),2τ].
Using (C.3) and (C.4), we obtain the following upper bound on the density of Δ:

For the four integrals, we used the substitutions z′=τ+z−δ, z′=τ+z−δ, z′=τ−z, and z′=τ+z, respectively. Using (C.1) and (C.2) and the facts that \(\delta\le2\tau\le2\sqrt{d}\) and \(2(r_{2}-\tau)+\delta\le2r_{2} \le2\sqrt{d}\) yields the penultimate inequality. The last inequality follows for the same reasons as in Case 2.1.
Altogether, this yields the lemma. □
3.2 C.2 Proof of Lemma 17
First, we derive the following lemma, which gives bounds on the conditional density of the random variable Δ when only one of the radii R 1 and R 2 is given.
Lemma 21
Let \(r_{1},r_{2},\tau\in(0,\sqrt{d})\) and δ∈(0,1/2]. In the following, let κ denote a sufficiently large constant.
-
(a)
The density of Δ under the conditions T=τ and R 1=r 1 is bounded by
$$f_{\varDelta\mid T=\tau,R_1=r_1}(\delta) \le \begin{cases} \frac{\kappa}{\sqrt{\tau r_1}}\cdot\ln (\delta^{-1} ) & \textit{if }r_1\le\tau,\\ \frac{\kappa}{\tau}\cdot\ln (\delta^{-1} ) & \textit{if }r_1\ge\tau. \end{cases} $$ -
(b)
The density of Δ, under the conditions T=τ and R 2=r 2, is bounded by
$$f_{\varDelta\mid T=\tau,R_2=r_2}(\delta) \le \begin{cases} \frac{\kappa}{\sqrt{\tau r_2}}\cdot(\ln (\delta^{-1} )+\ln\bigl| 2(\tau-r_2)-\delta\bigr|^{-1}) & \textit{if } r_2\le\tau,\\ \frac{\kappa}{\tau}\cdot\ln (\delta^{-1} ) & \textit{if } r_2\ge\tau. \end{cases} $$
Proof
(a) We can write the density of Δ under the conditions T=τ and R 1=r 1 as
where \(f_{R_{2}}\) denotes the density of the length R 2=d(O,Q 2). The point Q 2 is chosen uniformly at random from a hyperball with radius \(\sqrt{d}\) centered at the point O. The volume of a d-dimensional hyperball of radius r≥0 is V d (r)=αr d for \(\alpha=\frac{\pi^{d/2}}{\varGamma(d/2+1)}\) (see [2]). The probability distribution \(F_{R_{2}}(r)\) of R 2 is, for \(r\in[0,\sqrt{d}]\), proportional to V d (r). Let \(F_{R_{2}}(r)=\beta\alpha r^{d}\) for some β≥0. Since \(F_{R_{2}}(\sqrt{d})=1\), it must be true that \(\beta=\frac {1}{\alpha d^{d/2}}\). This yields, for \(r\in[0,\sqrt{d}]\),
Together with (C.5) this implies
We use Lemma 16 to bound this integral. For r 1≤τ, we obtain

The integral in the second line corresponds to the case r 1≤τ and r 2≤τ of Lemma 16 and the integral in the third line corresponds to the case r 1≤τ≤r 2. Using the fact that \(\tau\le\sqrt{d}=O(1)\) and ln(δ −1)≥ln(2)=Ω(1), the density \(f_{\varDelta \mid T=\tau ,R_{1}=r_{1}}(\delta)\) can be bounded from above by

In order to bound the integral in the second term, we use the following lemma.
Lemma 22
Let \(f\colon\mathbb{R}\to\mathbb{R}\) be a linear function of the form f(x)=ax+b for arbitrary \(a,b\in\mathbb{R}\) with |a|≥1. Furthermore, let \(c\in\mathbb{R}\) and ε>0 be arbitrary. Then
Proof
First we substitute z for ax+b in the integral:
We first consider the case a>0. In this case, the integral \(\int_{B}^{B+a\varepsilon}\ln(1/|z|)\,dz\) is maximized for B=−aε/2 because ln(1/|z|) is symmetric around 0 and monotonically decreasing for z>0. This yields

For a<0, the last integral in (C.7) can be rewritten as follows:
In this case the integral \(\int_{B+a\varepsilon}^{B}\ln(1/|z|)\,dz\) is maximized for B=−aε/2 because ln(1/|z|) is symmetric around 0 and monotonically decreasing for z>0. This yields

Altogether this proves the lemma because |a|≥1. □
The previous lemma and (C.6) imply that the density \(f_{\varDelta\mid T=\tau,R_{1}=r_{1}}(\delta)\) is bounded from above by

where we used \(\tau\le\sqrt{d}=O(1)\) (which implies τln(2/τ)=O(1)) for the equality. For a sufficiently large constant κ′ we can bound the previous term from above by
where we used ln(δ −1)≥ln(2)=Ω(1) and \(\tau\le\sqrt{d}\).
For τ≤r 1 we obtain
where the integral in the first line corresponds to the case r 2≤τ≤r 1 of Lemma 16 and the integral in the second line corresponds to the case τ≤r 1 and τ≤r 2. Analogously to the case r 1≤τ, this implies that the density \(f_{\varDelta\mid T=\tau,R_{1}=r_{1}}(\delta)\) is bounded from above by

By Lemma 22 this is bounded from above by
for a sufficiently large constant κ′.
(b) We can write the density of Δ under the conditions T=τ and R 2=r 2 as
For r 2≤τ and sufficiently large constants κ′ and κ″, we obtain
The integral in the first line corresponds to the case r 1≤τ and r 2≤τ of Lemma 16 and the integral in the second line corresponds to the case r 2≤τ≤r 1. Using that \(\tau\le\sqrt{d}=O(1)\) and ln(δ −1)≥ln(2)=Ω(1) yields that the density \(f_{\varDelta\mid T=\tau,R_{2}=r_{2}}(\delta)\) is bounded from above by

Together with Lemma 22 the previous formula implies the following upper bound on the density \(f_{\varDelta \mid T=\tau,R_{2}=r_{2}}(\delta)\):

for a sufficiently large constant κ′.
For τ≤r 2 and a sufficiently large constant κ′, we obtain by (C.8) and Lemma 16
The first integral corresponds to the case r 1≤τ≤r 2 of Lemma 16 and the second integral corresponds to the case τ≤r 1 and τ≤r 2. Using that \(\tau\le\sqrt{d}=O(1)\) yields that the previous term is bounded from above by

for a sufficiently large constant κ′. □
Now we are ready to prove Lemma 17.
Proof of Lemma 17(a)
In order to prove part (a), we integrate \(f_{\varDelta\mid T=\tau,R_{1}=r}(\delta)\) over all values τ that T can take. We denote by f T the density of the length T=d(O,P). We have argued in the proof of Lemma 21 that, for \(\tau\in[0,\sqrt{d}]\), \(f_{R_{2}}(\tau)=f_{T}(\tau)=\frac{\tau^{d-1}}{d^{d/2-1}}\). We obtain, for a sufficiently large constant κ′,

where we used Lemma 21(a) for the first inequality, and \(0\le r\le\sqrt{d}=O(1)\) and ln(δ −1)≥ln(2)=Ω(1) for the other inequalities.
Furthermore, we integrate \(f_{\varDelta\mid T=\tau,R_{2}=r}(\delta)\) over all values τ that T can take:
where we used Lemma 21(b) for the first inequality, and Lemma 22, \(0\le r\le\sqrt{d}=O(1)\), and ln(δ −1)≥ln(2)=Ω(1) for the second and third inequalities.
(b) Let \(f_{R_{1}}(r)=\frac{r^{d-1}}{d^{d/2-1}}\) denote the density of the length R 1=d(O,Q 1). For a sufficiently large constant κ′,

For the penultimate inequality we used \(0\le\tau\le\sqrt{d}=O(1)\) and ln(δ −1)≥ln(2)=Ω(1).
(c) Using part (b), for a sufficiently large constant κ′,

(d) Let \(f_{R_{i}}\) denote the density of R i . Using Lemma 15, we obtain

The lower limit of the first integral follows from the fact that, according to Lemma 15, z always takes a value in the interval (−τ,min{τ,2R i −τ}). Since z≤2R i −τ is equivalent to \(R_{i}\ge\frac{z+\tau}{2}\), we can bound \(f_{Z_{i}\mid T=\tau}(z)\) from above by

where we used \(r^{d-1} \le\tau^{d-1} \le(\sqrt{d})^{d-1}\) and the fact that the integral over a density is at most 1. Because
we can bound the conditional density of Z i from above by

for a large enough constant κ′, where we used
for the last inequality, which holds because \(\tau\le\sqrt{d}\) and z≥0. □
Appendix D: Negatively Associated Random Variables
Dubhashi and Ranjan [4] define negatively associated random variables as follows.
Definition 23
([4], Definition 3)
The random variables X 1,…,X n are negatively associated if for every two disjoint index sets I,J⊆[n],
for all functions \(f:\mathbb{R}^{|I|}\to\mathbb{R}\) and \(g:\mathbb {R}^{|J|}\to\mathbb{R}\) that are both non-decreasing or both non-increasing.
In Sect. 5, we used the following result from Dubhashi and Ranjan’s paper.
Lemma 24
([4], Proposition 6)
The Chernoff–Hoeffding bounds are applicable to sums of random variables that satisfy the negative association condition.
It remains to show that the random variables X 1,…,X k defined in Sect. 5 satisfy the negative association condition. Remember that these variables come from a balls-into-bins process in which n balls are put independently into k bins. Each ball has its own probability distribution on the k bins and the 0-1-variable X i indicates whether bin i contains at least one ball.
In order to show that the variables X 1,…,X k are negatively associated, we follow the same line of arguments as Lenzen and Wattenhofer [10], who showed the same statement for a balls-into-bins process in which the balls are put uniformly at random into the bins. The proof is based on the following statements proven in [4].
Lemma 25
-
(a)
If X 1,…,X n are 0-1-random variables with ∑X i =1, then X 1,…,X n are negatively associated.
-
(b)
If X and Y are sets of negatively associated random variables and if the random variables in X and Y are mutually independent, then X∪Y is also negatively associated.
-
(c)
Assume that the random variables X 1,…,X n are negatively associated and, for some \(k\in\mathbb{N}\), let I 1,…,I k ⊆[n] be mutually disjoint index sets. For j∈[k], let \(h_{j}:\mathbb{R}^{|I_{j}|}\to\mathbb{R}\) be functions that are all non-decreasing or all non-increasing, and define Y j =h j (X i ,i∈I j ). Then the random variables Y 1,…,Y k are also negatively associated.
Based on this lemma, we prove the theorem about the balls-into-bins process.
Theorem 26
Consider a balls-into-bins process in which n balls are put independently into k bins. Each ball has its own probability distribution on the k bins and the 0-1-variable X i indicates whether bin i contains at least one ball. The random variables X 1,…,X k are negatively associated.
Proof
First we define for each bin i∈[k] and each ball j∈[n] a 0-1-variables \(X_{i}^{j}\) indicating whether ball j ends up in bin i. For a ball j∈[n], the random variables \(X_{1}^{j},\ldots,X_{k}^{j}\) are negatively associated according to Lemma 25(a). Since the balls are put independently into the bins, all random variables \(X_{i}^{j}\) for i∈[k] and j∈[n] are negatively associated according to Lemma 25(b).
Now we define for each bin i∈[k] the set \(I_{i}=\{X_{i}^{1},\ldots ,X_{i}^{n}\}\) and the function
Observe that \(X_{i} = h_{i}(X_{i}^{1},\ldots,X_{i}^{n})\). As these functions are non-decreasing Lemma 25(c) implies that the random variables X 1,…,X k are negatively associated. □
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Englert, M., Röglin, H. & Vöcking, B. Worst Case and Probabilistic Analysis of the 2-Opt Algorithm for the TSP. Algorithmica 68, 190–264 (2014). https://doi.org/10.1007/s00453-013-9801-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00453-013-9801-4