
Abstract
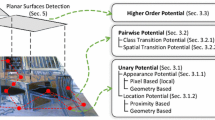
Semantic labeling for indoor scenes has been extensively developed with the wide availability of affordable RGB-D sensors. However, it is still a challenging task for multi-class recognition, especially for “small” objects. In this paper, a novel semantic labeling model based on aggregated features and contextual information is proposed. Given an RGB-D image, the proposed model first creates a hierarchical segmentation using an adapted gPb/UCM algorithm. Then, a support vector machine is trained to predict initial labels using aggregated features, which fuse small-scale appearance features, mid-scale geometric features, and large-scale scene features. Finally, a joint multi-label Conditional random field model that exploits both spatial and attributive contextual relations is constructed to optimize the initial semantic and attributive predicted results. The experimental results on the public NYU v2 dataset demonstrate the proposed model outperforms the existing state-of-the-art methods on the challenging 40 dominant classes task, and the model also achieves a good performance on a recent SUN RGB-D dataset. Especially, the prediction accuracy of “small” classes has been improved significantly.









Similar content being viewed by others

References
Anand, A., Koppula, H.S., Joachims, T., Saxena, A.: Contextually guided semantic labeling and search for three-dimensional point clouds. Int. J. Robot. Res. 32(1), 19–34 (2012)
Arbelaez, P., Maire, M., Fowlkes, C., Malik, J.: Contour detection and hierarchical image segmentation. Pattern Anal. Mach. Intell. IEEE Trans. 33(5), 898–916 (2011)
Bell, S., Upchurch, P., Snavely, N., Bala, K.: Opensurfaces: a richly annotated catalog of surface appearance. ACM Trans. Gr. (TOG) 32(4), 111 (2013)
Bell, S., Upchurch, P., Snavely, N., Bala, K.: Material recognition in the wild with the materials in context database. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3479–3487 (2015)
Bo, L., Ren, X., Fox, D.: Kernel descriptors for visual recognition. In: Annual conference on neural information processing systems, pp. 244–252 (2010)
Cadena, C., Kosecka, J.: Semantic segmentation with heterogeneous sensor coverages. In: Robotics and automation (ICRA), IEEE international conference on, pp. 2639–2645. IEEE (2014)
Chang, C.C., Lin, C.J.: Libsvm: a library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2(3), 27 (2011)
Chao, Y.W., Choi, W., Pantofaru, C., Savarese, S.: Layout estimation of highly cluttered indoor scenes using geometric and semantic cues. In: Image analysis and processing—ICIAP 2013, pp. 489–499. Springer, Berlin (2013)
Chatzichristofis, S.A., Boutalis, Y.S.: Cedd: color and edge directivity descriptor: a compact descriptor for image indexing and retrieval. In: Gasteratos, A., Vincze, M. and Tsotos, J.K. (eds.) Computer vision systems, pp. 312–322. Springer, Berlin (2008)
Chen, K., Lai, Y., Wu, Y.X., Martin, R.R., Hu, S.M.: Automatic semantic modeling of indoor scenes from low-quality RGB-d data using contextual information. ACM Trans. Gr. 33(6), 208:1–208:12 (2014)
Chen, W., Yue, H., Wang, J., Wu, X.: An improved edge detection algorithm for depth map inpainting. Opt. Lasers Eng. 55, 69–77 (2014)
Cheng, M.M., Zheng, S., Lin, W.Y., Vineet, V., Sturgess, P., Crook, N., Mitra, N.J., Torr, P.: Imagespirit: verbal guided image parsing. ACM Trans. Gr. 34(1), 3:1–3:11 (2014). doi:10.1145/2682628
Couprie, C., Farabet, C., Najman, L., LeCun, Y.: Indoor semantic segmentation using depth information. arXiv:1301.3572 (2013) (arXiv preprint)
Csurka, G., Dance, C., Fan, L., Willamowski, J., Bray, C.: Visual categorization with bags of keypoints. In: Workshop on statistical learning in computer vision, ECCV, vol. 1, pp. 1–2. Prague (2004)
Delong, A., Osokin, A., Isack, H.N., Boykov, Y.: Fast approximate energy minimization with label costs. Int. J. Comput. Vis. 96(1), 1–27 (2012)
Deng, Z., Todorovic, S., Jan Latecki, L.: Semantic segmentation of rgbd images with mutex constraints. In: Proceedings of the IEEE international conference on computer vision, pp. 1733–1741 (2015)
Ding, K., Chen, W., Wu, X.: Optimum inpainting for depth map based on l 0 total variation. Vis. Comput. 30(12), 1311–1320 (2014)
Farhadi, A., Endres, I., Hoiem, D., Forsyth, D.: Describing objects by their attributes. In: Computer vision and pattern recognition, CVPR 2009. IEEE conference on, pp. 1778–1785. IEEE (2009)
Gupta, A., Hebert, M., Kanade, T., Blei, D.M.: Estimating spatial layout of rooms using volumetric reasoning about objects and surfaces. In: Advances in neural information processing Systems, pp. 1288–1296 (2010)
Gupta, S., Arbeláez, P., Girshick, R., Malik, J.: Indoor scene understanding with RGB-d images: bottom-up segmentation, object detection and semantic segmentation. Int. J. Comput. Vis. 112(2), 133–149 (2015)
Gupta, S., Arbelaez, P., Malik, J.: Perceptual organization and recognition of indoor scenes from RGB-d images. In: Computer vision and pattern recognition (CVPR), IEEE conference on, pp. 564–571. IEEE (2013)
Gupta, S., Girshick, R., Arbeláez, P., Malik, J.: Learning rich features from RGB-d images for object detection and segmentation. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer vision–ECCV 2014, pp. 345–360. Springer, Berlin (2014)
Hermans, A., Floros, G., Leibe, B.: Dense 3d semantic mapping of indoor scenes from RGB-d images. In: Robotics and automation (ICRA), IEEE international conference on, pp. 2631–2638. IEEE (2014)
Hoiem, D., Efros, A.A., Hebert, M.: Putting objects in perspective. Int. J. Comput. Vis. 80(1), 3–15 (2008)
Lai, K., Bo, L., Fox, D.: Unsupervised feature learning for 3d scene labeling. In: Robotics and automation (ICRA), IEEE international conference on, pp. 3050–3057. IEEE (2014)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: Computer vision and pattern recognition (CVPR), IEEE Computer society conference on, vol. 2, pp. 2169–2178. IEEE (2006)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. arXiv:1411.4038 (2014) (arXiv preprint)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004)
Silberman, N., Hoiem, D., Kholi, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: ECCV (2012)
Ren, X., Bo, L., Fox, D.: RGB-(d) scene labeling: features and algorithms. In: Computer vision and pattern recognition (CVPR), IEEE Conference on, pp. 2759–2766. IEEE (2012)
Shao, T., Xu, W., Zhou, K., Wang, J., Li, D., Guo, B.: An interactive approach to semantic modeling of indoor scenes with an RGBD camera. ACM Trans. Gr. (TOG) 31(6), 136 (2012)
Silberman, N., Fergus, R.: Indoor scene segmentation using a structured light sensor. In: Computer vision workshops (ICCV Workshops), IEEE international conference on, pp. 601–608. IEEE (2011)
Sivic, J., Zisserman, A.: Video google: a text retrieval approach to object matching in videos. In: Computer vision. Proceedings. Ninth IEEE international conference on, pp. 1470–1477. IEEE (2003)
Song, S., Lichtenberg, S.P., Xiao, J.: Sun RGB-d: A RGB-d scene understanding benchmark suite. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 567–576 (2015)
Song, S., Xiao, J.: Sliding shapes for 3d object detection in RGB-d images. In: European conference on computer vision, vol. 2, pp. 6 (2014)
Tighe, J., Lazebnik, S.: Superparsing: scalable nonparametric image parsing with superpixels. In: Danilidis, K., Maragos, P., Paragios, N. (eds.) Computer Vision–ECCV 2010, pp. 352–365. Springer, Berlin (2010)
Wang, A., Lu, J., Wang, G., Cai, J., Cham, T.J.: Multi-modal unsupervised feature learning for RGB-d scene labeling. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision–ECCV 2014, pp. 453–467. Springer, Berlin (2014)
Wolf, D., Prankl, J., Vincze, M.: Fast semantic segmentation of 3d point clouds using a dense crf with learned parameters. In: Robotics and automation (ICRA), IEEE international conference on, pp. 4867–4873. IEEE (2015)
Xiao, J., Hays, J., Ehinger, K., Oliva, A., Torralba, A., et al.: Sun database: large-scale scene recognition from abbey to zoo. In: Computer vision and pattern recognition (CVPR), IEEE conference on, pp. 3485–3492. IEEE (2010)
Yu, K., Lin, Y., Lafferty, J.: Learning image representations from the pixel level via hierarchical sparse coding. In: Computer vision and pattern recognition (CVPR), IEEE conference on, pp. 1713–1720. IEEE (2011)
Zhang, J., Kan, C., Schwing, A.G., Urtasun, R.: Estimating the 3d layout of indoor scenes and its clutter from depth sensors. In: Computer Vision (ICCV), IEEE international conference on, pp. 1273–1280. IEEE (2013)
Zhang, Y., Song, S., Tan, P., Xiao, J.: Panocontext: A whole-room 3d context model for panoramic scene understanding. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer vision–ECCV 2014, pp. 668–686. Springer, Berlin (2014)
Acknowledgments
The work described in this paper was supported by the National Natural Science Foundation of China under Grant No. 61573048, 61620106012, and the International Scientific and Technological Cooperation Projects of China under Grant No. 2015DFG12650.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wang, J., Zheng, C., Chen, W. et al. Learning aggregated features and optimizing model for semantic labeling. Vis Comput 33, 1587–1600 (2017). https://doi.org/10.1007/s00371-016-1302-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-016-1302-4