
Abstract
We analyze approximation rates by deep ReLU networks of a class of multivariate solutions of Kolmogorov equations which arise in option pricing. Key technical devices are deep ReLU architectures capable of efficiently approximating tensor products. Combining this with results concerning the approximation of well-behaved (i.e., fulfilling some smoothness properties) univariate functions, this provides insights into rates of deep ReLU approximation of multivariate functions with tensor structures. We apply this in particular to the model problem given by the price of a European maximum option on a basket of d assets within the Black–Scholes model for European maximum option pricing. We prove that the solution to the d-variate option pricing problem can be approximated up to an \(\varepsilon \)-error by a deep ReLU network with depth \({\mathcal {O}}\big (\ln (d)\ln (\varepsilon ^{-1})+\ln (d)^2\big )\) and \({\mathcal {O}}\big (d^{2+\frac{1}{n}}\varepsilon ^{-\frac{1}{n}}\big )\) nonzero weights, where \(n\in {\mathbb {N}}\) is arbitrary (with the constant implied in \({\mathcal {O}}(\cdot )\) depending on n). The techniques developed in the constructive proof are of independent interest in the analysis of the expressive power of deep neural networks for solution manifolds of PDEs in high dimension.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Motivation
The development of new classification and regression algorithms based on deep neural networks—coined “deep learning”—revolutionized the area of artificial intelligence, machine learning and data analysis [15]. More recently, these methods have been applied to the numerical solution of partial differential equations (PDEs for short) [3, 12, 21, 22, 27, 32, 39, 41, 42]. In these works, it has been empirically observed that deep learning-based methods work exceptionally well when used for the numerical solution of high-dimensional problems arising in option pricing. The numerical experiments carried out in [2, 3, 21, 42] in particular suggest that deep learning-based methods may not suffer from the curse of dimensionality for these problems, but only few theoretical results exist which support this claim: In [38], a first theoretical result on rates of expression of infinite-variate generalized polynomial chaos expansions for solution manifolds of certain classes of parametric PDEs has been obtained. Furthermore, recent work [4, 18] shows that the algorithms introduced in [2] for the numerical solution of Kolmogorov PDEs are free of the curse of dimensionality in terms of network size and training sample complexity.
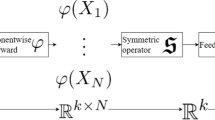
Neural networks constitute a parametrized class of functions constructed by successive applications of affine mappings and coordinatewise nonlinearities; see [35] for a mathematical introduction. As in [34], we introduce a neural network via a tuple of matrix-vector pairs
for given hyperparameters \(L\in {\mathbb {N}}\), \(N_0,N_1,\dots ,N_L\in {\mathbb {N}}\). Given an “activation function” \(\varrho \in C({\mathbb {R}},{\mathbb {R}})\), a neural network \(\Phi \) then describes a function \(R_\varrho (\Phi )\in C({\mathbb {R}}^{N_0},{\mathbb {R}}^{N_L})\) that can be evaluated by the recursion
The number of nonzero values in the matrix-vector tuples defining \(\Phi \) describes the size of \(\Phi \) which will be denoted by \({\mathcal {M}}(\Phi )\) and the depth of the network \(\Phi \), i.e., its number of affine transformations, will be denoted by \({\mathcal {L}}(\Phi )\). We refer to Setting 5.1 for a more detailed description. A popular activation function \(\varrho \) is the so-called rectified linear unit \(\mathrm {ReLU}(x)=\max \{x,0\}\) [15].
An increasing body of research addresses the approximation properties (or “expressive power”) of deep neural networks, where by “approximation properties” we mean the study of the optimal trade-off between the size \({\mathcal {M}}(\Phi )\) and the approximation error \(\Vert u-R_\varrho (\Phi )\Vert \) of neural networks approximating functions u from a given function class. Classical references include [1, 7, 8, 23] as well as the summary [35] and the references therein. In these works, it is shown that deep neural networks provide optimal approximation rates for classical smoothness spaces such as Sobolev spaces or Besov spaces. More recently, these results have been extended to Shearlet and Ridgelet spaces [5], modulation spaces [33], piecewise smooth functions [34] and polynomial chaos expansions [38]. All these results indicate that all classical approximation methods based on sparse expansions can be emulated by neural networks.
1.2 Contributions and Main Result
As a first main contribution of this work, we show in Proposition 6.4 that low-rank functions of the form
with \(h_j^s\in C({\mathbb {R}},{\mathbb {R}})\) sufficiently regular and \((c_s)_{s=1}^R\subseteq {\mathbb {R}}\) can be approximated to a given relative precision by deep ReLU neural networks of size scaling like \(Rd^2\). In particular, we obtain a dependence on the dimension d that is only polynomial and not exponential, i.e., we avoid the curse of dimensionality. In other words, we show that in addition all classical approximation methods based on sparse expansions and on more general low-rank structures, can be emulated by neural networks. Since the solutions of several classes of high-dimensional PDEs are precisely of this form (see, e.g., [38]), our approximation results can be directly applied to these problems to establish approximation rates for neural network approximations that do not suffer from the curse of dimensionality. Note that approximation results for functions of the form (1.2) have previously been considered in [37] in the context of statistical bounds for nonparametric regression.
Moreover, we remark that the networks realizing the product in (1.2) itself have a connectivity scaling which is logarithmic in the accuracy \(\varepsilon ^{-1}\). While we will, for our concrete example, only obtain a spectral connectivity scaling, i.e., like \(\varepsilon ^{-{\frac{1}{n}}}\) for any \(n\in {\mathbb {N}}\) with the implicit constant depending on n, this tensor construction may be used to obtain logarithmic scaling (w.r.t. the accuracy) for d-variate functions in cases where the univariate \(h_j^s\) can be approximated with a logarithmic scaling.
As a particular application of the tools developed in the present paper, we provide a mathematical analysis of the rates of expressive power of neural networks for a particular, high-dimensional PDE which arises in mathematical finance, namely the pricing of a so-called European maximum option (see, e.g., [43]).
We consider the particular (and not quite realistic) situation that the log-returns of these d assets are uncorrelated, i.e., their log-returns evolve according to d uncorrelated drifted scalar diffusion processes.
The price of the European maximum option on this basket of d assets can then be obtained as solution of the multivariate Black–Scholes equation which reads, for the presently considered case of uncorrelated assets, as
For the European maximum option, (1.3) is completed with the terminal condition
for \( x = ( x_1, \dots , x_d ) \in (0,\infty )^d \). It is well known (see, e.g., [11, 20] and the references therein) that there exists a unique solution of (1.3)–(1.4). This solution can be expressed as conditional expectation of the function \(\varphi (x)\) in (1.4) over suitable sample paths of a d-dimensional diffusion.
One main result of this paper is the following result (stated with completely detailed assumptions as Theorem 7.3), on expression rates of deep neural networks for the basket option price u(0, x) for \(x\in [a,b]^d\) for some \(0<a<b< \infty \). To render their dependence on the number d of assets in the basket explicit, we write \(u_d\) in the statement of the theorem.
Theorem 1.1
Let \(n\in {\mathbb {N}}\), \(\mu \in {\mathbb {R}}\), \(T,\sigma ,a\in (0,\infty )\), \(b\in (a,\infty )\), \((K_i)_{i\in {\mathbb {N}}}\subseteq [0,K_{\mathrm {max}})\), and let \(u_d:(0,\infty )\times [a,b]^d\rightarrow {\mathbb {R}}\), \(d\in {\mathbb {N}}\), be the functions which satisfy for every \(d\in {\mathbb {N}}\), and for every \((t,x) \in [0,T]\times (0,\infty )^d\) the equation (1.3) with terminal condition (1.4).
Then there exist neural networks \((\Gamma _{d,\varepsilon })_{\varepsilon \in (0,1],d\in {\mathbb {N}}}\) which satisfy
-
(i)
\(\displaystyle \sup _{\varepsilon \in (0,1],d\in {\mathbb {N}}}\left[ {\frac{{\mathcal {L}}(\Gamma _{d,\varepsilon })}{\max \{1,\ln (d)\}\left( {|\ln (\varepsilon )|+\ln (d)+1}\right) }}\right] <\infty \),
-
(ii)
\(\displaystyle \sup _{\varepsilon \in (0,1],d\in {\mathbb {N}}}\left[ {\frac{{\mathcal {M}}(\Gamma _{d,\varepsilon })}{d^{2+\frac{1}{n}}\varepsilon ^{-\frac{1}{n}}}}\right] <\infty \), and
-
(iii)
for every \(\varepsilon \in (0,1]\), \(d\in {\mathbb {N}}\),
$$\begin{aligned} \sup _{x\in [a,b]^d}\left| {u_d(0,x)-\left[ {R_{\mathrm {ReLU}}(\Gamma _{d,\varepsilon })}\right] \!(x)}\right| \le \varepsilon . \end{aligned}$$(1.5)
Informally speaking, the previous result states that the price of a d-dimensional European maximum option can, for every \(n\in {\mathbb {N}}\), be expressed on cubes \([a,b]^d\) by deep neural networks to pointwise accuracy \(\varepsilon >0\) with network size bounded as \({\mathcal {O}}(d^{2+1/n} \varepsilon ^{-1/n})\) for arbitrary, fixed \(n\in {\mathbb {N}}\) and with the constant implied in \({\mathcal {O}}(\cdot )\) independent of d and of \(\varepsilon \) (but depending on n). In other words, the price of a European maximum option on a basket of d assets can be approximated (or “expressed”) by deep ReLU networks with spectral accuracy and without curse of dimensionality.
The proof of this result is based on a near explicit expression for the function \(u_d(0,x)\) (see Sect. 2). It uses this expression in conjunction with regularity estimates in Sect. 3 and a neural network quadrature calculus and corresponding error estimates (which is of independent interest) in Sect. 4 to show that the function \(u_d(0,x)\) possesses an approximate low-rank representation consisting of tensor products of cumulative normal distribution functions (Lemma 4.3) to which the low-rank approximation result mentioned above can be applied.
Related results have been shown in the recent work [18] which proves (by completely different methods) that solutions to general Kolmogorov equations with affine drift and diffusion terms can be approximated by neural networks of a size that scales polynomially in the dimension and the reciprocal of the desired accuracy as measured by the \(L^p\) norm with respect to a given probability measure. The approximation estimates developed in the present paper only apply to the European maximum option pricing problem for uncorrelated assets but hold with respect to the much stronger \(L^\infty \) norm and provide spectral accuracy in \(\varepsilon \) (as opposed to a low-order polynomial rate obtained in [18]), which is a considerable improvement. In summary, compared to [18], the present paper treats a more restricted problem but achieves stronger approximation results.
In order to give some context to our approximation results, we remark that solutions to Kolmogorov PDEs may, under reasonable assumptions, be approximated by empirical risk minimization over a neural network hypothesis class. The key here is the Feynman–Kac formula which allows to write the solution to the PDE as the expectation of an associated stochastic process. This expectation can be approximated by Monte Carlo integration, i.e., one can view it as a neural network training problem where the data are generated by Monte Carlo sampling methods which, under suitable conditions, are capable of avoiding the curse of dimensionality. For more information on this, we refer to [4].
While we admit that the European maximum option pricing problem for uncorrelated assets constitutes a rather special problem, the proofs in this paper develop several novel deep neural network approximation results of independent interest that can be applied to more general settings where a low-rank structure is implicit in high-dimensional problems. For mostly numerical results on machine learning for pricing American options, we refer to [16]. Lastly we note that after a first preprint of the present paper was submitted, a number of research articles related to this work have appeared [13, 14, 17, 19, 24,25,26, 28, 36].
1.3 Outline
The structure of this article is as follows. Section 2 provides a derivation of the semi-explicit formula for the price of European maximum options in a standard Black–Scholes setting. This formula consists of an integral of a tensor product function. In Sect. 3, we develop some auxiliary regularity results for the cumulative normal distribution that are of independent interest which will be used later on. In Sect. 4, we show that the integral appearing in the formula of Sect. 2 can be efficiently approximated by numerical quadrature. Section 5 introduces some basic facts related to deep ReLU networks, and Sect. 6 develops basic approximation results for the approximation of functions which possess a tensor product structure. Finally, in Sect. 7 we show our main result, namely a spectral approximation rate for the approximation of European maximum options by deep ReLU networks without curse of dimensionality. In Appendix A, we collect some auxiliary proofs.
2 High-Dimensional Derivative Pricing
In this section, we briefly review the Black–Scholes differential equation (1.3) which arises, among others, as Kolmogorov equation for multivariate geometric Brownian Motion. This linear, parabolic equation is for one particular type of financial contracts (so-called European maximum option on a basket of d stocks whose log-returns are assumed for simplicity as mutually uncorrelated) endowed with the terminal condition (1.4) and solved for \((t,x)\in [0,T]\times (0,\infty )^d\).
Proposition 2.1
Let \( d \in {\mathbb {N}}\), \( \mu \in {\mathbb {R}}\), \( \sigma , T, K_1, \dots , K_d, \xi _1, \dots , \xi _d \in (0,\infty ) \), let \( ( \Omega , {\mathcal {F}}, {\mathbb {P}}) \) be a probability space, and let \( W = ( W^{ (1) }, \dots , W^{ (d) } ) :[0,T] \times \Omega \rightarrow {\mathbb {R}}^d \) be a standard Brownian motion and let \(u\in C([0,T]\times (0,\infty )^d)\) satisfy (1.3) and (1.4). Then for \(x = (\xi _1,\dots , \xi _d)\in (0,\infty )^d\) it holds that
For the proof of this Proposition, we require the following well-known result.
Lemma 2.2
(Complementary distribution function formula) Let \( \mu :{\mathcal {B}}( [0,\infty ) ) \rightarrow [0,\infty ] \) be a sigma-finite measure. Then
We are now in position to provide a proof of Proposition 2.1.
Proof of Proposition 2.1
The first equality follows directly from the Feynman–Kac formula [20, Corollary 4.17]. We proceed with a proof of the second equality. Throughout this proof, let \(X_i :\Omega \rightarrow {\mathbb {R}}\), \(i \in \{ 1, 2, \dots , d \}\), be random variables which satisfy for every \( i \in \{ 1, 2, \dots , d \} \)
and let \( Y :\Omega \rightarrow {\mathbb {R}}\) be the random variable given by
Observe that for every \( y \in (0,\infty ) \) it holds
Hence, we obtain that for every \( y \in (0,\infty ) \) it holds
This shows that for every \( y \in (0,\infty ) \) it holds
Combining this with Lemma 2.2 completes the proof of Proposition 2.1. \(\square \)
With Lemma 2.2 and Proposition 2.1, we may write
(“semi-explicit” formula). Let us consider the case \( \mu = \sigma ^2 / 2 \), \( T = \sigma = 1 \) and \( K_1 = \ldots = K_d = K \in (0,\infty ) \). Then for every \( x = ( x_1, \dots , x_d) \in (0,\infty )^d \)
3 Regularity of the Cumulative Normal Distribution
Now that we have derived an semi-explicit formula for the solution, we establish regularity properties of the integrand function in (2.9). This will be required in order to approximate the multivariate integrals by quadratures (which are subsequently realized by neural networks) in Sect. 4 and to apply the neural network results from Sect. 6 to our problem. To this end, we analyze the derivatives of the factors in the tensor product, which essentially are compositions of the cumulative normal distribution with the natural logarithm. As this function appears in numerous closed-form option pricing formulae (see, e.g., [29]), the (Gevrey) type regularity estimates obtained in this section are of independent interest. (They may, for example, also be used in the analysis of deep network expression rates and of spectral methods for option pricing).
Lemma 3.1
Let \(f:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in (0,\infty )\) that
let \(g_{n,k}:(0,\infty )\rightarrow {\mathbb {R}}\), \(n,k\in {\mathbb {N}}_0\), be the functions which satisfy for every \(n,k\in {\mathbb {N}}_0\), \(t\in (0,\infty )\) that
and let \((\gamma _{n,k})_{n,k\in {\mathbb {Z}}}\subseteq {\mathbb {Z}}\) be the integers which satisfy for every \(n,k\in {\mathbb {Z}}\) that
Then it holds for every \(n\in {\mathbb {N}}\) that
-
(i)
we have that f is n times continuously differentiable and
-
(ii)
we have for every \(t\in (0,\infty )\) that
$$\begin{aligned} f^{(n)}(t)=\tfrac{1}{\sqrt{2\pi }}\left[ {\sum _{k=0}^{n-1}\gamma _{n,k}\,g_{n,k}(t)}\right] . \end{aligned}$$(3.4)
Proof of Lemma 3.1
We prove (i) and (ii) by induction on \(n\in {\mathbb {N}}\). For the base case \(n=1\) note that (3.1), (3.2), (3.3), the fact that the function \({\mathbb {R}}\ni r\mapsto e^{-\frac{1}{2}r^2}\in (0,\infty )\) is continuous, the fundamental theorem of calculus and the chain rule yield
-
(A)
that f is differentiable and
-
(B)
that for every \(t\in (0,\infty )\) it holds
$$\begin{aligned} f'(t)=\tfrac{1}{\sqrt{2\pi }}\, e^{-\frac{1}{2}[\ln (t)]^2}t^{ - 1 } = \tfrac{1}{\sqrt{2\pi }}\, g_{1,0}(t) = \tfrac{1}{\sqrt{2\pi }}\, \gamma _{ 1, 0 } \, g_{1,0}(t) . \end{aligned}$$(3.5)
This establishes (i) and (ii) in the base case \(n=1\). For the induction step \({{\mathbb {N}}\ni n\rightarrow n+1\in \{2,3,4,\dots \}}\), note that for every \(t\in (0,\infty )\) we have
Combining this and (3.2) with the product rule establishes for every \(n\in {\mathbb {N}}\), \(k \in \{ 0, 1, \dots , n - 1 \} \), \( t \in (0,\infty ) \) that
Hence, we obtain that for every \(n\in {\mathbb {N}}\), \(t\in (0,\infty )\) it holds
The fact that for every \(n\in {\mathbb {N}}\) it holds that \(\gamma _{n,-1}=\gamma _{n,n}=\gamma _{n,n+1}=0\) and (3.3) therefore ensure that for every \(n\in {\mathbb {N}}\), \(t\in (0,\infty )\) we have
Induction thus establishes (i) and (ii). The proof of Lemma 3.1 is thus completed. \(\square \)
Using the recursive formula from the above, we can now bound the derivatives of f. Note that the supremum of \(f^{(n)}\) is actually attained on the interval \([e^{-4n},1]\) and scales with n like \(e^{(cn^2)}\) for some \(c\in (0,\infty )\). This can directly be seen by calculating the maximum of the \(g_{n,k}\) from (3.2). For our purposes, however, it is sufficient to establish that all derivatives of f are bounded on \((0,\infty )\).
Lemma 3.2
Let \(f:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in (0,\infty )\) that
Then it holds for every \(n\in {\mathbb {N}}\) that
Proof of Lemma 3.2
Throughout this proof, let \(g_{n,k}:(0,\infty )\rightarrow {\mathbb {R}}\), \(n,k\in {\mathbb {N}}_0\), be the functions introduced in (3.2) and let \((\gamma _{n,k})_{n,k\in {\mathbb {Z}}}\subseteq {\mathbb {Z}}\) be the integers introduced in (3.3). Then Lemma 3.1 shows for every \(n\in {\mathbb {N}}\) that
-
(a)
we have that f is n times continuously differentiable and
-
(b)
we have for every \(t\in (0,\infty )\) that
$$\begin{aligned} f^{(n)}(t)=\tfrac{1}{\sqrt{2\pi }}\left[ {\sum _{k=0}^{n-1}\gamma _{n,k}\,g_{n,k}(t)}\right] . \end{aligned}$$(3.12)
In addition, observe that for every \(m\in {\mathbb {N}}\), \(t\in (0,e^{-2m}]\) holds \({\tfrac{1}{2}\ln (t)\le -m}\). This ensures that for every \(m\in {\mathbb {N}}\), \(t\in (0,e^{-2m}]\subseteq (0,1]\) we have
Moreover, note that the fundamental theorem of calculus implies for every \(t\in (0,1]\) that
Combining (3.2), (3.12) and (3.13) therefore establishes that for every \(n\in {\mathbb {N}}\), \({t\in (0,e^{-4n})}{\subseteq (0,1]}\) it holds
In addition, observe that the fundamental theorem of calculus ensures that for every \(t\in [1,\infty )\) we have
This, (3.2), (3.12) and the fact that for every \(t\in (0,\infty )\) it holds \(|e^{-\frac{1}{2}[\ln (t)]^2}|\le 1\) imply that for every \(n\in {\mathbb {N}}\), \(t\in (1,\infty )\) we have
Moreover, observe that (a) assures that for every \(n\in {\mathbb {N}}\) it holds that the function \(f^{(n)}\) is continuous. This and the boundedness of the set \([e^{-4n},1]\) ensure that for every \(n\in {\mathbb {N}}\) we have
Combining this with (3.15) and (3.17) establishes that for every \(n\in {\mathbb {N}}\) we have
Furthermore, note that (3.3) implies that for every \(n\in \{2,3,4,\dots \}\) it holds
Combining this with the fact that for every \(n\in \{2,3,4,\dots \}\), \(k\in {\mathbb {Z}}\backslash \{0,1,\dots ,n-2\}\) we have \(\gamma _{n-1,k}=0\) implies that for every \(n\in \{2,3,4,\dots \}\) it holds
The fact that \(\gamma _{1,0}=1\) hence implies that for every \(n\in {\mathbb {N}}\) we have
Combining this and (3.19) ensures that for every \(n\in {\mathbb {N}}\) it holds
The proof of Lemma 3.2 is thus completed. \(\square \)
In the following corollary, we estimate the derivatives of the function \(x\rightarrow f(\tfrac{K+c}{x})\) required to approximate this function by neural networks.
Corollary 3.3
Let \(n\in {\mathbb {N}}\), \(K\in [0,\infty )\), \(c,a\in (0,\infty )\), \(b\in (a,\infty )\), let \(f:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in (0,\infty )\) that
and let \(h:[a,b]\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(x\in [a,b]\) that
Then it holds
-
(i)
that f and h are infinitely often differentiable and
-
(ii)
that
$$\begin{aligned}&\max _{k\in \{0,1,\dots ,{n}\}}\sup _{x\in [a,b]}\left| {h^{(k)}\!(x)}\right| \nonumber \\&\quad \le n2^{n-1} n! \left[ {\max _{k\in \{0,1,\dots ,{n}\}} \sup _{t\in [\frac{K+c}{b},\frac{K+c}{a}]}\left| {f^{(k)}\!(t)}\right| }\right] \max \{a^{-2n},1\}\max \{(K+c)^n,1\}.\nonumber \\ \end{aligned}$$(3.26)
Proof of Corollary 3.3
Throughout this proof, let \(\alpha _{m,j}\in {\mathbb {Z}}\), \(m,j\in {\mathbb {Z}}\), be the integers which satisfy that for every \(m,j\in {\mathbb {Z}}\) it holds
Note that Lemma 3.1 and the chain rule ensure that the functions f and h are infinitely often differentiable. Next we claim that for every \(m\in {\mathbb {N}}\), \(x\in [a,b]\) it holds
We prove (3.28) by induction on \(m\in {\mathbb {N}}\). To prove the base case \(m=1\) we note that the chain rule ensures that for every \(x\in [a,b]\) we have
This establishes (3.28) in the base case \(m=1\). For the induction step \({\mathbb {N}}\ni m \rightarrow m+1\in {\mathbb {N}}\) observe that the chain rule implies for every \(m\in {\mathbb {N}}\), \(x\in [a,b]\) that
Induction thus establishes (3.28). Next note that (3.27) ensures that for every \(m\in \{2,3,\dots \}\) it holds
Induction hence proves that for every \(m\in {\mathbb {N}}\) we have \(\max _{j\in \{1,2,\dots ,{m}\}}\left| {\alpha _{m,j}}\right| \le 2^{m-1}m!\). Combining this with (3.28) implies that for every \(m\in \{1,2,\dots ,{n}\}\), \(x\in [a,b]\) we have
Combining this with the fact that \(\sup _{x\in [a,b]}\left| {h(x)}\right| =\sup _{t\in [\frac{K+c}{b},\frac{K+c}{a}]}\left| {f(t)}\right| \) establishes that it holds
This completes the proof of Corollary 3.3. \(\square \)
Next we consider the derivatives of the functions \(c\mapsto f(\tfrac{K+c}{x_i})\), \(i\in \{1,2,\dots ,{d}\}\), and their tensor product, which will be needed in order to approximate the outer integral in (2.9) by composite Gaussian quadrature.
Corollary 3.4
Let \(n\in {\mathbb {N}}\), \(K\in [0,\infty )\), \(x\in (0,\infty )\), let \(f:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in (0,\infty )\) that
and let \(g:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in (0,\infty )\) that
Then it holds
-
(i)
that f and g are infinitely often differentiable and
-
(ii)
that
$$\begin{aligned} \sup _{t\in (0,\infty )}\left| {g^{(n)}(t)}\right| \le \left[ \sup _{t\in (0,\infty )}\left| {f^{(n)}(t)}\right| \right] \left| {x}\right| ^{-n}<\infty . \end{aligned}$$(3.36)
Proof of Corollary 3.4
Combining Lemma 3.2 with the chain rule implies that for every \(t\in (0,\infty )\) it holds
This completes the proof of Corollary 3.4. \(\square \)
Lemma 3.5
Let \(d,n\in {\mathbb {N}}\), \(a\in (0,\infty )\), \(b\in (a,\infty )\), \(K=(K_1,\dots ,K_d)\in [0,\infty )^d\), \(x=(x_1,\dots ,x_d)\in [a,b]^d\), let \(f:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in (0,\infty )\) that
and let \(F:(0,\infty )\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(c\in (0,\infty )\) that
Then it holds
-
(i)
that f and F are infinitely often differentiable and
-
(ii)
that
$$\begin{aligned} \sup _{c\,\in (0,\infty )}\left| {F^{(n)}(c)}\right| \le \left[ \max _{k\in \{0,1,\dots ,{n}\}}\sup _{t\in (0,\infty )}\left| {f^{(k)}(t)}\right| \right] ^n d^n a^{-n}<\infty . \end{aligned}$$(3.40)
Proof of Lemma 3.5
Note that Lemma 3.1 ensures that f and F are infinitely often differentiable. Moreover, observe that (3.39) and the general Leibniz rule imply for every \(c\in (0,\infty )\) that
Next note that the fact that for every \(r\in {\mathbb {R}}\) it holds that \(e^{-\frac{1}{2}r^2}\ge 0\) ensures that
Corollary 3.4 hence establishes that for every \(c\in [0,\infty )\), \(l_1,\dots ,l_d\in {\mathbb {N}}_0\) with \(\sum _{i=1}^d l_i=n\) it holds
Moreover, note that the multinomial theorem ensures that
Combining this with (3.41), (3.43) and the assumption that \(x\in [a,b]^d\) implies that for every \(c\in (0,\infty )\) we have
This completes the proof of Lemma 3.5. \(\square \)
4 Quadrature
To approximate the function \(x\mapsto u(0,x)\) from (2.9) by a neural network, we need to evaluate, for arbitrary, given x, an expression of the form \(\int _0^{\infty } F_x(c)\mathrm {d}c\) with \(F_x\) as defined in Lemma 4.2. We achieve this by proving in Lemma 4.2 that the functions \(F_x\) decay sufficiently fast for \(c\rightarrow \infty \), and then employ numerical integration to show that the definite integral \(\int _0^N F_x(c)\mathrm {d}c\) can be sufficiently well approximated by a weighted sum of \(F_x(c_j)\) for suitable quadrature points \(c_j\in (0,N)\). The representation of such a sum can be realized by neural networks. We show in Sects. 6 and 7 how the functions \(x\mapsto F_x(c_j)\) for \((c_j)\in (0,N)\) can be realized efficiently due to their tensor product structure. We start by recalling an error bound for composite Gaussian quadrature which is explicit in the step size and quadrature order.
Lemma 4.1
Let \(n,M\in {\mathbb {N}}\), \(N\in (0,\infty )\). Then there exist real numbers \((c_j)_{j=1}^{nM}\subseteq (0,N)\) and \({(w_j)_{j=1}^{nM}\subseteq (0,\infty )}\) such that for every \(h\in C^{2n}([0,N],{\mathbb {R}})\) it holds
Proof of Lemma 4.1
Throughout this proof, let \(h\in C^{2n}([0,N],{\mathbb {R}})\) and \(\alpha _k\in [0,N]\), \(k\in \{0,1,\dots ,M\}\), such that for every \(k\in \{0,1,\dots ,M\}\) it holds \(\alpha _k=\tfrac{kN}{M}\). Observe that [30, Theorems 4.17, 6.11 and 6.12] ensure that for every \(k\in \{0,1,\dots ,M-1\}\) there exist \((\gamma ^k_i)_{i=1}^{n}\subseteq (\alpha _k,\alpha _{k+1})\), \((\omega ^k_i)_{i=1}^{n}\subseteq (0,\infty )\) and \(\xi ^k\in [\alpha _k,\alpha _{k+1}]\) such that
Next note that for every \(k\in \{0,1,\dots ,M-1\}\) it holds
Combining this with (4.2) yields that for every \(k\in \{0,1,\dots ,M\}\) we have
Hence, we obtain
Let \((c_j)_{j=1}^{nM}\subseteq (0,N)\), \((w_j)_{j=1}^{nM}\subseteq (0,\infty )\) such that for every \(i\in \{1,2,\dots ,{n}\}\), \(k\in \{0,1,\dots ,M-1\}\) it holds
Next observe that
This completes the proof of Lemma 4.1. \(\square \)
In the following, we bound the error due to truncating the domain of integration.
Lemma 4.2
Let \(d,n\in {\mathbb {N}}\), \(a\in (0,\infty )\), \(b\in (a,\infty )\), \(K=(K_1,K_2,\dots ,K_d)\in [0,\infty )^d\), let \(F_x:(0,\infty )\rightarrow {\mathbb {R}}\), \(x\in [a,b]^d\), be the functions which satisfy for every \(x=(x_1,x_2,\dots ,x_d)\in [a,b]^d\), \(c\in (0,\infty )\) that
and for every \(\varepsilon \in (0,1]\) let \(N_{\varepsilon }\in {\mathbb {R}}\) be given by \(N_{\varepsilon }=2e^{2(n+1)}(b+1)^{1+\frac{1}{n}}d^{\frac{1}{n}}\varepsilon ^{-\frac{1}{n}}\). Then it holds for every \(\varepsilon \in (0,1]\) that
Proof of Lemma 4.2
Throughout this proof, let \(g:(0,\infty )\rightarrow (0,1)\) be the function given by
Note that [6, Eq.(5)] ensures that for every \(y\in [0,\infty )\) we have \(\tfrac{2}{\sqrt{\pi }}\int _y^{\infty }e^{-r^2}\mathrm {d}r \le e^{-y^2}\). This implies for every \(t\in [1,\infty )\) that
Furthermore, observe that for every \(t\in [e^{2(n+1)},\infty )\) it holds
This, (4.11) and the fact that for every \(\varepsilon \in (0,1]\), \(c\in [N_{\varepsilon },\infty )\), \(x\in [a,b]^d\), \(i\in \{1,2,\dots ,{d}\}\) we have \(\tfrac{K_i+c}{x_i}\ge \tfrac{c}{b}\ge e^{2(n+1)}\ge 1\) imply that for every \(\varepsilon \in (0,1]\), \(c\in [N_{\varepsilon },\infty )\), \(x\in [a,b]^d\) it holds
Combining this with the binomial theorem and the fact that for every \(i\in \{1,2,\dots ,{d}\}\) we have \(\left( {\begin{array}{c}d\\ i\end{array}}\right) \le \tfrac{d^i}{i!}\le \tfrac{d^i}{\exp (i\ln (i)-i+1)}\le \tfrac{(de)^i}{i^i}\) establishes that for every \(\varepsilon \in (0,1]\), \(c\in [N_{\varepsilon },\infty )\), \(x\in [a,b]^d\) it holds
This, the geometric sum formula and the fact that for every \(\varepsilon \in (0,1]\) it holds that \(N_\varepsilon \ge 2bd^{\frac{1}{n}}\) imply that for every \(\varepsilon \in (0,1]\), \(c\in [N_{\varepsilon },\infty )\), \(x\in [a,b]^d\) we have
Hence, we obtain for every \(\varepsilon \in (0,1]\), \(x\in [a,b]^d\) that
This completes the proof of Lemma 4.2. \(\square \)
Next we combine the above result with Lemma 4.1 in order to derive the number of terms needed in order to approximate the integral by a sum to within a prescribed error bound \(\varepsilon \).
Lemma 4.3
Let \(n\in {\mathbb {N}}\), \(a\in (0,\infty )\), \(b\in (a,\infty )\), \((K_i)_{i\in {\mathbb {N}}}\subseteq [0,\infty )\), let \(F^d_x:(0,\infty )\rightarrow {\mathbb {R}}\), \(x\in [a,b]^d\), \(d\in {\mathbb {N}}\), be the functions which satisfy for every \(d\in {\mathbb {N}}\), \(x=(x_1,x_2,\dots ,x_d)\in [a,b]^d\), \(c\in (0, \infty )\) that
and for every \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\) let \(N_{d,\varepsilon }\in {\mathbb {R}}\) be given by
Then there exist \(Q_{d,\varepsilon }\in {\mathbb {N}}\), \(c^d_{\varepsilon ,j}\in (0,N_{d,\varepsilon })\), \(w^d_{\varepsilon ,j}\in [0,\infty )\), \(j\in \{1,2,\dots ,{Q_{d,\varepsilon }}\}\), \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\), such
-
(i)
that
$$\begin{aligned} \sup _{\varepsilon \in (0,1], d\in {\mathbb {N}}}\left[ {\frac{Q_{d,\varepsilon }}{d^{1+\frac{2}{n}}\varepsilon ^{-\frac{2}{n}}}}\right] <\infty \end{aligned}$$(4.19)and
-
(ii)
that for every \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\) it holds \(\sum _{j=1}^{Q_{d,\varepsilon }}w^d_{\varepsilon ,j}=N_{d,\varepsilon }\) and
$$\begin{aligned} \sup _{x\in [a,b]^d}\left| {\int _0^\infty F^d_x(c)\,\mathrm {d}c-\sum _{j=1}^{Q_{d,\varepsilon }}w^d_{\varepsilon ,j}F^d_x(c^d_{\varepsilon ,j})}\right| \le \varepsilon . \end{aligned}$$(4.20)
Proof of Lemma 4.3
Note that Lemma 3.5 ensures the existence of \(S_m\in {\mathbb {R}}\), \(m\in {\mathbb {N}}\), such that for every \(d,m\in {\mathbb {N}}\), \(x\in [a,b]^d\) it holds
Let \(Q_{d,\varepsilon }\in {\mathbb {R}}\), \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\), be given by
Next observe that Lemma 4.1 (with \(N\leftrightarrow N_{d,\varepsilon }\) in the notation of Lemma 4.1) establishes the existence of \(c^d_{\varepsilon ,j}\in (0,N_{d,\varepsilon })\), \(w^d_{\varepsilon ,j}\in [0,\infty )\), \(j\in \{1,2,\dots ,{Q_{d,\varepsilon }}\}\), \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\), such that for every \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(x\in [a,b]^d\) we have \(\sum _{j=1}^{Q_{d,\varepsilon }}w^d_{\varepsilon ,j}=N_{d,\varepsilon }\) and
Moreover, note that Lemma 4.2 (with \(N_{d,\frac{\varepsilon }{2}}\leftrightarrow N_{d,\varepsilon }\) in the notation of Lemma 4.2) and (4.23) imply for every \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\), \(x\in [a,b]^d\) that
Furthermore, we have for every \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\) that
This implies
The proof of Lemma 4.3 is thus completed. \(\square \)
5 Basic ReLU DNN Calculus
In order to talk about neural networks we will, up to some minor changes and additions, adopt the notation of P. Petersen and F. Voigtlaender from [34]. This allows us to differentiate between a neural network, defined as a structured set of weights, and its realization, which is a function on \({\mathbb {R}}^d\). Note that this is almost necessary in order to talk about the complexity of neural networks, since notions like depth, size or architecture do not make sense for general functions on \({\mathbb {R}}^d\). Even if we know that a given function “is” a neural network, i.e., can be written a series of affine transformations and componentwise nonlinearities, there are, in general, multiple non-trivially different ways to do so.
Each of these structured sets we consider does, however, define a unique function. This enables us to explicitly and unambiguously construct complex neural networks from simple ones, and subsequently relate the approximation capability of a given network to its complexity. Further note that since the realization of neural network is unique we can still speak of a neural network approximating a given function when its realization does so.
Specifically, a neural network will be given by its architecture, i.e., number of layers L and layer dimensionsFootnote 1\(N_0,N_1,\dots ,N_L\), as well as the weights determining the affine transformations used to compute each layer from the previous one. Note that our notion of neural networks does not attach the architecture and weights to a fixed activation function, but instead considers the realization of such a neural network with respect to a given activation function. This choice is a purely technical one here, as we always consider networks with ReLU activation function.
Setting 5.1
(Neural networks) For every \(L\in {\mathbb {N}}\), \(N_0,N_1,\dots ,N_L\in {\mathbb {N}}\) let \({\mathcal {N}}_L^{N_0,N_1,\dots ,N_L}\) be the set given by
let \({\mathfrak {N}}\) be the set given by
let \({\mathcal {L}},{\mathcal {M}},{\mathcal {M}}_l,\dim _{\mathrm {in}},\dim _{\mathrm {out}}:{\mathfrak {N}}\rightarrow {\mathbb {N}}\), \(l\in \{1,2,\dots ,{L}\}\), be the functions which satisfy for every \(L\in {\mathbb {N}}\) and every \({N_0,N_1,\dots ,N_L\in {\mathbb {N}}}\), \(\Phi =(((A^1_{i,j})_{i,j=1}^{N_1,N_0},(b^1_i)_{i=1}^{N_1}),\dots ,((A^L_{i,j})_{i,j=1}^{N_L,N_{L-1}},(b^L_i)_{i=1}^{N_L}))\in {\mathcal {N}}^{ N_0, N_1,\dots , N_L }_L\), \(l\in \{1,2,\dots ,{L}\}\) \({\mathcal {L}}(\Phi )=L\), \(\dim _{\mathrm {in}}(\Phi )=N_0\), \(\dim _{\mathrm {out}}(\Phi )=N_L\),
and
For every \(\varrho \in C({\mathbb {R}},{\mathbb {R}})\) let \(\varrho ^*:\cup _{d\in {\mathbb {N}}}{\mathbb {R}}^d\rightarrow \cup _{d\in {\mathbb {N}}}{\mathbb {R}}^d\) be the function which satisfies for every \(d\in {\mathbb {N}}\), \(x=(x_1,x_2,\dots ,x_d)\in {\mathbb {R}}^d\) that \(\varrho ^*(x)=(\varrho (x_1),\varrho (x_2),\dots ,\varrho (x_d))\), and for every \(\varrho \in {\mathcal {C}}({\mathbb {R}},{\mathbb {R}})\) denote by \(R_{\varrho }:{\mathfrak {N}}\rightarrow \cup _{a,b\in {\mathbb {N}}}\,C({\mathbb {R}}^a,{\mathbb {R}}^b)\) the function which satisfies for every \(L\in {\mathbb {N}}\), \(N_0,N_1,\dots ,N_L\in {\mathbb {N}}\), \(x_0\in {\mathbb {R}}^{N_0}\), and \(\Phi =((A_1,b_1),(A_2,b_2),\dots ,(A_L,b_L))\in {\mathcal {N}}_L^{N_0,N_1,\dots ,N_L}\), with \(x_1\in {\mathbb {R}}^{N_1},\dots ,x_{L-1}\in {\mathbb {R}}^{N_{L-1}}\) given by
that
The quantity \({\mathcal {M}}(\Phi )\) simply denotes the number of nonzero entries of the network \(\Phi \), which together with its depth \({\mathcal {L}}(\Phi )\) will be how we measure the “size” of a given neural network \(\Phi \). One could instead consider the number of all weights, i.e., including zeroes, of a neural network. Note, however, that for any non-degenerate neural network \(\Phi \) the total number of weights is bounded from above by \({\mathcal {M}}(\Phi )^2+{\mathcal {M}}(\Phi )\). Here, the terminology “degenerate” refers to a neural network which has neurons that can be removed without changing the realization of the NN. This implies for any neural network there also exists a non-degenerate one of smaller or equal size, which has the exact same realization. Since our primary goal is to approximate d-variate functions by networks the size of which only depends polynomially on the dimension, the above means that the qualitatively same results hold regardless of which notion of “size” is used.
We start by introducing two basic tools for constructing new neural networks from known ones and, in Lemma 5.3 and Lemma 5.4, consider how the properties of a derived network depend on its parts. Note that techniques like these have already been used in [34] and [37].
The first tool will be the “composition” of neural networks in (5.7), which takes two networks and provides a new network whose realization is the composition of the realizations of the two constituent functions.
The second tool will be the “parallelization” of neural networks in (5.12), which will be useful when considering linear combinations or tensor products of functions which we can already approximate. While parallelization of same depth networks (5.10) works with arbitrary activation functions, we use for the general case that any ReLU network can easily be extended (5.11) to an arbitrary depth without changing its realization.
Setting 5.2
Assume Setting 5.1, for every \(L_1,L_2\in {\mathbb {N}}\), \(\Phi ^i=\left( {(A_1^i,b_1^i), (A_2^i,b_2^i),\dots ,(A^i_{L_i},b^i_{L_i})}\right) \in {\mathfrak {N}}\), \(i\in \{1,2\}\), with \(\dim _{\mathrm {in}}(\Phi ^1)=\dim _{\mathrm {out}}(\Phi ^2)\) let \(\Phi ^1\odot \Phi ^2\in {\mathfrak {N}}\) be the neural network given by
for every \(d\in {\mathbb {N}}\), \(L\in {\mathbb {N}}\cap [2,\infty )\) let \(\Phi ^{\mathrm {Id}}_{d,L}\in {\mathfrak {N}}\) be the neural network given by
for every \(d\in {\mathbb {N}}\) let \(\Phi ^{\mathrm {Id}}_{d,1}\in {\mathfrak {N}}\) be the neural network given by
for every \(n,L\in {\mathbb {N}}\), \(\Phi ^j=((A^j_1,b^j_1),(A^j_2,b^j_2),\dots ,(A^j_L,b^j_L))\in {\mathfrak {N}}\), \(j\in \{1,2,\dots ,{n}\}\), let \({\mathcal {P}}_s(\Phi ^1,\Phi ^2,\dots ,\Phi ^n)\in {\mathfrak {N}}\) be the neural network which satisfies
for every \(L,d\in {\mathbb {N}}\), \(\Phi \in {\mathfrak {N}}\) with \({\mathcal {L}}(\Phi )\le L\), \(\dim _{\mathrm {out}}(\Phi )=d\), let \({\mathcal {E}}_L(\Phi )\in {\mathfrak {N}}\) be the neural network given by
and for every \(n,L\in {\mathbb {N}}\), \(\Phi ^j\in {\mathfrak {N}}\), \(j\in \{1,2,\dots ,{n}\}\) with \(\max _{j\in \{1,2,\dots ,{n}\}}{\mathcal {L}}(\Phi ^j)=L\), let \({\mathcal {P}}(\Phi ^1,\Phi ^2,\dots ,\Phi ^n)\in {\mathfrak {N}}\) denote the neural network given by
Lemma 5.3
Assume Setting 5.2, let \(\Phi ^1,\Phi ^2\in {\mathfrak {N}}\) and let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in {\mathbb {R}}\) that \(\varrho (t)=\max \{0,t\}\). Then
-
(i)
for every \(x\in {\mathbb {R}}^{\dim _{\mathrm {in}}(\Phi ^2)}\) it holds
$$\begin{aligned}{}[R_{\varrho }(\Phi ^1\odot \Phi ^2)](x)=([R_{\varrho }(\Phi ^1)]\circ [R_{\varrho }(\Phi ^2)])(x)=[R_{\varrho }(\Phi ^1)]([R_{\varrho }(\Phi ^2)](x)), \end{aligned}$$(5.13) -
(ii)
\({\mathcal {L}}(\Phi ^1\odot \Phi ^2)={\mathcal {L}}(\Phi ^1)+{\mathcal {L}}(\Phi ^2)\),
-
(iii)
\({\mathcal {M}}(\Phi ^1\odot \Phi ^2)\le {\mathcal {M}}(\Phi ^1)+{\mathcal {M}}(\Phi ^2)+{\mathcal {M}}_1(\Phi ^1)+{\mathcal {M}}_{{\mathcal {L}}(\Phi ^2)}(\Phi ^2) \le 2({\mathcal {M}}(\Phi ^1)+{\mathcal {M}}(\Phi ^2))\),
-
(iv)
\({\mathcal {M}}_1(\Phi ^1\odot \Phi ^2)={\mathcal {M}}_1(\Phi ^2)\),
-
(v)
\({\mathcal {M}}_{{\mathcal {L}}(\Phi ^1\odot \Phi ^2)}(\Phi ^1\odot \Phi ^2)={\mathcal {M}}_{{\mathcal {L}}(\Phi ^1)}(\Phi ^1)\),
-
(vi)
\(\dim _{\mathrm {in}}(\Phi ^1\odot \Phi ^2)=\dim _{\mathrm {in}}(\Phi ^2)\),
-
(vii)
\(\dim _{\mathrm {out}}(\Phi ^1\odot \Phi ^2)=\dim _{\mathrm {out}}(\Phi ^1)\),
-
(viii)
for every \(d,L\in {\mathbb {N}}\), \(x\in {\mathbb {R}}^d\) it holds that \([R_{\varrho }(\Phi ^{\mathrm {Id}}_{d,L})](x)=x\) and
-
(ix)
for every \(L\in {\mathbb {N}}\), \(\Phi \in {\mathfrak {N}}\) with \({\mathcal {L}}(\Phi )\le L\), \(x\in {\mathbb {R}}^{\dim _{\mathrm {in}}(\Phi )}\) it holds that \([R_{\varrho }({\mathcal {E}}_L(\Phi ))](x)=[R_{\varrho }(\Phi )](x)\).
Proof of Lemma 5.3
For every \(i\in \{1,2\}\) let \(L_i\in {\mathbb {N}}\), \(N^i_1,N^i_2,\dots ,N^i_{L_i}\), \((A^i_l,b^i_l)\in {\mathbb {R}}^{N^i_l\times N^i_{l-1}}\times {\mathbb {R}}^{N^i_l}\), \(l\in \{1,2,\dots ,{L_i}\}\) such that \(\Phi ^i=((A^i_1,b^i_1),\dots ,(A^i_{L_i},b^i_{L_i}))\). Furthermore, let \((A_l,b_l)\in {\mathbb {R}}^{N_l\times N_{l-1}}\times {\mathbb {R}}^{N_l}\), \(l\in \{1,2,\dots ,{L_1+L_2}\}\), be the matrix-vector tuples which satisfy \(\Phi _1\odot \Phi _2=((A_1,b_1),\dots ,(A_{L_1+L_2},b_{L_1+L_2}))\) and let \(r_l:{\mathbb {R}}^{N_0}\rightarrow {\mathbb {R}}^{N_l}\), \(l\in \{1,2,\dots ,{L_1+L_2}\}\), be the functions which satisfy for every \(x\in {\mathbb {R}}^{N_0}\) that
Observe that for every \(l\in \{1,2,\dots ,{L_2-1}\}\) holds \((A_l,b_l)=(A^2_l,b^2_l)\). This implies that for every \(x\in {\mathbb {R}}^{N_0}\) holds
Combining this with (5.7) implies for every \(x\in {\mathbb {R}}^{N_0}\) that
In addition, for every \(d\in {\mathbb {N}}\), \(y=(y_1,y_2,\dots ,y_d)\in {\mathbb {R}}^d\) holds
This, (5.7) and (5.16) ensure that for every \(x\in {\mathbb {R}}^{N_0}\) holds
Combining this with (5.14) establishes (i). Moreover, (ii)-(vii) follow directly from (5.7). Furthermore, (5.8), (5.9) and (5.17) imply (viii). Finally, (ix) follows from (5.11) and (viii). This completes the proof of Lemma 5.3. \(\square \)
Lemma 5.4
Assume Setting 5.2, let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the function which satisfies for every \(t\in {\mathbb {R}}\) that \(\varrho (t)=\max \{0,t\}\), let \(n\in {\mathbb {N}}\), let \(\varphi ^j\in {\mathfrak {N}}\), \(j\in \{1,2,\dots ,{n}\}\), let \(d_j\in {\mathbb {N}}\), \(j\in \{1,2,\dots ,{n}\}\), be given by \(d_j=\dim _{\mathrm {in}}(\varphi ^j)\), let \(D\in {\mathbb {N}}\) be given by \(D=\sum _{j=1}^n d_j\) and let \(\Phi \in {\mathfrak {N}}\) be given by \(\Phi ={\mathcal {P}}(\varphi ^1,\varphi ^2,\dots ,\varphi ^n)\). Then
-
(i)
for every \(x\in {\mathbb {R}}^D\) it holds
$$\begin{aligned} {}[R_{\varrho }(\Phi )](x)=&\left( [R_{\varrho }(\varphi ^1)](x_1,\dots ,x_{d_1}), [R_{\varrho }(\varphi ^2)](x_{d_1+1},\dots ,x_{d_1+d_2}),\dots ,\right. \nonumber \\&\left. [R_{\varrho }(\varphi ^n)](x_{D-d_n+1},\dots ,x_{D})\right) , \end{aligned}$$(5.19) -
(ii)
\({\mathcal {L}}(\Phi )=\max _{j\in \{1,2,\dots ,{n}\}}{\mathcal {L}}(\varphi ^j)\),
-
(iii)
\({\mathcal {M}}(\Phi )\le 2\left( {\sum _{j=1}^n{\mathcal {M}}(\varphi ^j)}\right) +4\left( {\sum _{j=1}^n \dim _{\mathrm {out}}(\varphi ^j)}\right) \max _{j\in \{1,2,\dots ,{n}\}}{\mathcal {L}}(\varphi ^j)\),
-
(iv)
\({\mathcal {M}}(\Phi )=\sum _{j=1}^n{\mathcal {M}}(\varphi ^j)\) provided for every \(j,j'\in \{1,2,\dots ,{n}\}\) holds \({\mathcal {L}}(\varphi ^j)={\mathcal {L}}(\varphi ^{j'})\),
-
(v)
\({\mathcal {M}}_{{\mathcal {L}}(\Phi )}(\Phi )\le \sum _{j=1}^n \max \{2\dim _{\mathrm {out}}(\varphi ^j),{\mathcal {M}}_{{\mathcal {L}}(\varphi ^j)}(\varphi ^j)\}\),
-
(vi)
\({\mathcal {M}}_1(\Phi )=\sum _{j=1}^n{\mathcal {M}}_1(\varphi ^j)\),
-
(vii)
\(\dim _{\mathrm {in}}(\Phi )=\sum _{j=1}^n\dim _{\mathrm {in}}(\varphi ^j)\) and
-
(viii)
\(\dim _{\mathrm {out}}(\Phi )=\sum _{j=1}^n\dim _{\mathrm {out}}(\varphi ^j)\).
Proof of Lemma 5.4
Observe that Lemma 5.3 implies that for every \(j\in \{1,2,\dots ,{n}\}\) holds
Combining this with (5.10) and (5.12) establishes (i). Furthermore, note that (ii), (vi), (vii) and (viii) follow directly from (5.10) and (5.12). Moreover, (5.10) demonstrates that for every \(m\in {\mathbb {N}}\), \(\psi _i\in {\mathfrak {N}}\), \(i\in \{1,2,\dots ,{m}\}\), with \(\forall i,i'\in \{1,2,\dots ,{m}\}:{\mathcal {L}}(\psi ^i)={\mathcal {L}}(\psi ^{i'})\) holds
This establishes (iv). Next, observe that Lemma 5.3, (5.11) and the fact that for every \(d\in \), \(L\in {\mathbb {N}}\) holds \({\mathcal {M}}(\Phi ^{\mathrm {Id}}_{d,L})\le 2dL\) imply that for every \(j\in \{1,2,\dots ,{n}\}\) we have
Combining this with (5.21) establishes (iii). In addition, note that (5.8), (5.9) and (5.11) ensure for every \(j\in \{1,2,\dots ,{n}\}\) that
Combining this with (5.10) establishes (v). The proof of Lemma 5.4 is thus completed. \(\square \)
6 Basic Expression Rate Results
Here, we begin by establishing an expression rate result for a very simple function, namely \(x\mapsto x^2\) on [0, 1]. Our approach is based on the observation by M. Telgarsky [40] that neural networks with ReLU activation function can efficiently compute high-frequency sawtooth functions and the idea of D. Yarotsky in [44] to use this in order to approximate the function \(x\mapsto x^2\) by networks computing its linear interpolations. This can then be used to derive networks capable of efficiently approximating \((x,y)\mapsto xy\), which leads to tensor products as well as polynomials and subsequently smooth function. Note that [44] uses a slightly different notion of neural networks, where connections between non-adjacent layers are permitted. This does, however, only require a technical modification of the proof, which does not significantly change the result. Nonetheless, the respective proofs are provided in appendix for completeness.
Lemma 6.1
Assume Setting 5.1 and let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\). Then there exist neural networks \((\sigma _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) such that for every \(\varepsilon \in (0,\infty )\)
-
(i)
\({\mathcal {L}}(\sigma _{\varepsilon })\le {\left\{ \begin{array}{ll}\tfrac{1}{2}\left| {\log _2(\varepsilon )}\right| +1 &{} :\varepsilon <1\\ 1 &{} :\varepsilon \ge 1\end{array}\right. }\),
-
(ii)
\({\mathcal {M}}(\sigma _{\varepsilon })\le {\left\{ \begin{array}{ll}15(\tfrac{1}{2}\left| {\log _2(\varepsilon )}\right| +1) &{} :\varepsilon < 1\\ 0 &{} :\varepsilon \ge 1\end{array}\right. }\),
-
(iii)
\(\sup _{t\in [0,1]}\left| {t^2-\left[ {R_{\varrho }(\sigma _{\varepsilon })}\right] \!(t)}\right| \le \varepsilon \),
-
(iv)
\([R_{\varrho }(\sigma _{\varepsilon })]\!(0) = 0\).
We can now derive the following result on approximate multiplication by neural networks, by observing that \(xy=2B^2(|(x+y)/2B|^2-|x/2B|^2-|y/2B|^2)\) for every \(B\in (0,\infty )\), \(x,y\in {\mathbb {R}}\).
Lemma 6.2
Assume Setting 5.1, let \(B\in (0,\infty )\) and let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\). Then there exist neural networks \((\mu _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy for every \(\varepsilon \in (0,\infty )\) that
-
(i)
\({\mathcal {L}}(\mu _{\varepsilon })\le {\left\{ \begin{array}{ll}\tfrac{1}{2}\log _2(\tfrac{1}{\varepsilon })+\log _2(B)+6 &{} :\varepsilon < B^2\\ 1 &{} :\varepsilon \ge B^2\end{array}\right. }\),
-
(ii)
\({\mathcal {M}}(\mu _{\varepsilon })\le {\left\{ \begin{array}{ll}45\log _2(\tfrac{1}{\varepsilon })+90\log _2(B)+259 &{} :\varepsilon < B^2\\ 0 &{} :\varepsilon \ge B^2\end{array}\right. }\),
-
(iii)
\(\sup _{(x,y)\in [-B,B]^2}\left| {xy-\left[ {R_{\varrho }(\mu _{\varepsilon })}\right] \!(x,y)}\right| \le \varepsilon \),
-
(iv)
\({\mathcal {M}}_1(\mu _{\varepsilon })=8,\ {\mathcal {M}}_{{\mathcal {L}}(\mu _{\varepsilon })}(\mu _{\varepsilon })=3\) and
-
(v)
for every \(x\in {\mathbb {R}}\) it holds that \(R_\varrho [\mu _{\varepsilon }](0,x) = R_\varrho [\mu _{\varepsilon }](x,0)=0\).
Next we extend this result to products of any number of factors by hierarchical, pairwise multiplication.
Theorem 6.3
Assume Setting 5.1, let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\), let \(m\in {\mathbb {N}}\cap [2,\infty )\) and let \(B\in [1,\infty )\). Then there exists a constant \(C\in {\mathbb {R}}\) (which is independent of m, B) and neural networks \({(\Pi _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}}\) which satisfy
-
(i)
\({\mathcal {L}}(\Pi _{\varepsilon })\le C\ln (m)\left( {\left| {\ln (\varepsilon )}\right| +m\ln (B)+\ln (m)}\right) \),
-
(ii)
\({\mathcal {M}}(\Pi _{\varepsilon })\le C m\left( {\left| {\ln (\varepsilon )}\right| +m\ln (B)+\ln (m)}\right) \),
-
(iii)
\(\displaystyle \sup _{x\in [-B,B]^m}\left| {\left[ {\prod _{j=1}^m x_j}\right] -\left[ {R_{\varrho }(\Pi _{\varepsilon })}\right] \!(x)}\right| \le \varepsilon \) and
-
(iv)
\(R_\varrho \left[ \Pi _{\varepsilon }\right] (x_1,x_2,\dots ,x_m)=0\), if there exists \(i\in \{1,2,\dots ,m\}\) with \(x_i=0\).
Proof of Theorem 6.3
Throughout this proof, assume Setting 5.2, let \(l=\lceil \log _2 m\rceil \) and let \(\theta \in {\mathcal {N}}^{1,1}_1\) be the neural network given by \(\theta =(0,0)\), let \((A,b)\in {\mathbb {R}}^{l\times m}\times {\mathbb {R}}^{l}\) be the matrix-vector tuple given by
Let further \(\omega \in {\mathcal {N}}^{m,2^l}_2\) be the neural network given by \(\omega =((A,b))\). Note that Lemma 6.2 (with \(B^m\) as B in the notation of Lemma 6.2) ensures that there exist neural networks \((\mu _{\eta })_{\eta \in (0,\infty )}\subseteq {\mathfrak {N}}\) such that for every \(\eta \in (0,\left[ {B^m}\right] ^2)\) it holds
-
(A)
\({\mathcal {L}}(\mu _{\eta })\le \tfrac{1}{2}\log _2(\tfrac{1}{\eta })+\log _2(B^m)+6\),
-
(B)
\({\mathcal {M}}(\mu _{\eta })\le 45\log _2(\tfrac{1}{\eta })+90\log _2(B^m)+259\),
-
(C)
\(\displaystyle \sup _{x,y\in [-B^m,B^m]}\left| {xy-\left[ {R_{\varrho }(\mu _{\eta })}\right] \!(x,y)}\right| \le \eta \),
-
(D)
\({\mathcal {M}}_1(\mu _{\eta })=8,\ {\mathcal {M}}_{{\mathcal {L}}(\mu _{\eta })}(\mu _{\eta })=3\) and
-
(E)
for every \(x\in {\mathbb {R}}\) it holds that \(R_\varrho [\mu _{\eta }](0,x) = R_\varrho [\mu _{\eta }](x,0)=0\).
Let \((\nu _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) be the neural networks which satisfy for every \(\varepsilon \in (0,\infty )\)
Observe that (A) implies that for every \(\varepsilon \in (0,B^m)\subseteq (0,m^2 B^{4m})\) it holds
In addition, note that (B) implies that for every \(\varepsilon \in (0,B^m)\subseteq (0,m^2 B^{4m})\)
Furthermore, (C) implies that for every \(\varepsilon \in (0,B^m)\subseteq (0,m^2 B^{4m})\) holds
Let \(\pi _{k,\varepsilon }\in {\mathfrak {N}}\), \(\varepsilon \in (0,\infty )\), \(k\in {\mathbb {N}}\), be the neural networks which satisfy for every \(\varepsilon \in (0,\infty )\), \(k\in {\mathbb {N}}\)
and let \((\Pi _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) be neural networks given by
Note that for every \(\varepsilon \in (B^m,\infty )\) it holds
We claim that for every \(k\in \{1,2,\dots ,{l}\}\), \(\varepsilon \in (0,B^m)\) it holds
-
(a)
that
$$\begin{aligned} \sup _{x\in [-B,B]^{(2^k)}}\left| {\left[ {\textstyle \prod \limits _{j=1}^{2^k}x_j}\right] -[R_{\varrho }(\pi _{k,\varepsilon })](x)}\right| \le 4^{k-1} m^{-2} B^{(2^k-2m)}\varepsilon , \end{aligned}$$(6.9) -
(b)
that \({\mathcal {L}}(\pi _{k,\varepsilon })\le k{\mathcal {L}}(\nu _{\varepsilon })\) and
-
(c)
that \({\mathcal {M}}(\pi _{k,\varepsilon })\le (2^k-1){\mathcal {M}}(\nu _{\varepsilon })+(2^{k-1}-1)20\).
We prove (a), (b) and (c) by induction on \(k\in \{1,2,\dots ,{l}\}\). Observe that (6.5) and the fact that \(B\in [1,\infty )\) establishes (a) for \(k=1\). Moreover, note that (6.6) establishes (b) and (c) in the base case \(k=1\).
For the induction step \(\{1,2,\dots ,{l-1}\}\ni k\rightarrow k+1\in \{2,3,\dots ,l\}\) note that Lemma 5.3, Lemma 5.4, (6.5) and (6.6) imply that for every \(k\in \{1,2,\dots ,{l-1}\}\), \(\varepsilon \in (0,B^m)\)
Next, for every \(c,\delta \in (0,\infty )\), \(y,z\in [-c,c]\), \({\tilde{y}},{\tilde{z}}\in {\mathbb {R}}\) with \(\left| {y-{\tilde{y}}}\right| , \left| {z-{\tilde{z}}}\right| \le \delta \) it holds
Moreover, for every \(k\in \{1,2,\dots ,{l}\}\)
The fact that \(B\in [1,\infty )\) therefore ensures that for every \(k\in \{1,2,\dots ,{l-1}\}\), \(\varepsilon \in (0,B^m)\)
This and (6.11) imply that for every \(k\in \{1,2,\dots ,{l-1}\}\), \(\varepsilon \in (0,B^m)\), \(x,x'\in [-B,B]^{(2^k)}\)
Combining this, (6.10) and the fact that \(B\in [1,\infty )\) demonstrates that for every \(k\in \{1,2,\dots ,{l-1}\}\), \(\varepsilon \in (0,B^m)\)
This establishes the claim (a). Moreover, Lemma 5.3 and Lemma 5.4 imply for every \(k\in \{1,2,\dots ,{l-1}\}\), \(\varepsilon \in (0,B^m)\) with \({\mathcal {L}}(\pi _{k,\varepsilon })\le k{\mathcal {L}}(\nu _{\varepsilon })\) holds
This establishes the claim (b). Furthermore, Lemma 5.3, Lemma 5.4, (B) and (D) imply for every \(k\in \{1,2,\dots ,{l-1}\}\), \(\varepsilon \in (0,B^m)\) with \({\mathcal {M}}(\pi _{k,\varepsilon })\le (2^k-1){\mathcal {M}}(\nu _{\varepsilon })+(2^{k-1}-1)20\) holds
This establishes the claim (c).
Combining (a) with Lemma 5.3 and (6.7) implies for every \(\varepsilon \in (0,B^m)\) the bound
This and (6.8) establish that the neural networks \((\Pi _{\varepsilon })_{\varepsilon \in (0,\infty )}\) satisfy (iii). Combining (b) with Lemma 5.3, (6.3) and (6.7) ensures that for every \(\varepsilon \in (0,B^m)\)
and that for every \(\varepsilon \in (B^m,\infty )\) it holds \({\mathcal {L}}(\Pi _{\varepsilon })={\mathcal {L}}(\theta )=1\). This establishes that the neural networks \((\Pi _{\varepsilon })_{\varepsilon \in (0,\infty )}\) satisfy (i). Furthermore, note that (c), Lemma 5.3, (6.3) and (6.7) demonstrate that for every \(\varepsilon \in (0,B^m)\)
and that for every \(\varepsilon \in (B^m,\infty )\) holds \({\mathcal {M}}(\Pi _{\varepsilon })={\mathcal {M}}(\theta )=0\). This establishes that the neural networks \((\Pi _{\varepsilon })_{\varepsilon \in (0,\infty )}\) satisfy (ii). Note that (iv) follows from (E) by construction. The proof of Theorem 6.3 is thus completed. \(\square \)
With the above established, it is quite straightforward to get the following result for the approximation of tensor products. Note that the exponential term \(B^{m-1}\) in (iii) is unavoidable as result from multiplying m many inaccurate values of magnitude B. For our purposes, this will not be an issue since the functions we consider are bounded in absolute value by \(B=1\). This is further not an issue in cases, where the \(h_j\) can be approximated by networks whose size scales logarithmically with \(\varepsilon \).
Proposition 6.4
Assume Setting 5.2, let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\), let \(B\in [1,\infty )\), \(m\in {\mathbb {N}}\), for every \(j\in \{1,2,\dots ,{m}\}\) let \(d_j\in {\mathbb {N}}\), \(\Omega _j\subseteq {\mathbb {R}}^{d_j}\), and \(h_j:\Omega _j\rightarrow [-B,B]\), let \((\Phi ^j_{\varepsilon })_{\varepsilon \in (0,\infty )}\in {\mathfrak {N}}\), \(j\in \{1,2,\dots ,{m}\}\), be neural networks which satisfy for every \(\varepsilon \in (0,\infty )\), \(j\in \{1,2,\dots ,{m}\}\)
let \(\Phi ^{{\mathcal {P}}}_{\varepsilon }\in {\mathfrak {N}}\), \(\varepsilon \in (0,\infty )\) be given by \(\Phi ^{{\mathcal {P}}}_{\varepsilon }={\mathcal {P}}(\Phi ^1_{\varepsilon },\Phi ^2_{\varepsilon },\dots ,\Phi ^m_{\varepsilon })\), and let \(L_{\varepsilon }\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\) be given by \(L_{\varepsilon }=\max _{j\in \{1,2,\dots ,{m}\}}{\mathcal {L}}(\Phi ^j_{\varepsilon })\).
Then there exists a constant \(C\in {\mathbb {R}}\) ( which is independent of \(m,B,\varepsilon \)) and neural networks \((\Psi _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy
-
(i)
\({\mathcal {L}}(\Psi _{\varepsilon })\le C\ln (m)\left( {\left| {\ln (\varepsilon )}\right| +m\ln (B)+\ln (m)}\right) +L_{\varepsilon }\),
-
(ii)
\({\mathcal {M}}(\Psi _{\varepsilon }) \le C m\left( {\left| {\ln (\varepsilon )}\right| +m\ln (B)+\ln (m)}\right) +{\mathcal {M}}(\Phi ^{{\mathcal {P}}}_{\varepsilon })+{\mathcal {M}}_{L_{\varepsilon }}(\Phi ^{{\mathcal {P}}}_{\varepsilon })\) and
-
(iii)
\(\displaystyle \sup _{t=(t_1,t_2,\dots ,t_m)\in \times _{j=1}^m \Omega _j}\left| {\left[ {\textstyle \prod \limits _{j=1}^m h_j(t_j)}\right] -\left[ {R_{\varrho }(\Psi _{\varepsilon })}\right] \!(t)}\right| \le 3mB^{m-1}\varepsilon .\)
Proof of Proposition 6.4
In the case of \(m=1\), the neural networks \((\Phi ^1_{\varepsilon })_{\varepsilon \in (0,\infty )}\in {\mathfrak {N}}\) satisfy (i), (ii) and (iii) by assumption. Throughout the remainder of this proof, assume \(m\ge 2\), and let \(\theta \in {\mathcal {N}}^{1,1}_1\) denote the trivial neural network \(\theta =(0,0)\). Observe that Theorem 6.3 (with \(\varepsilon \leftrightarrow \eta \), \(C'\leftrightarrow C\) in the notation Theorem 6.3) ensures that there exist \(C'\in {\mathbb {R}}\) and neural networks \((\Pi _{\eta })_{\eta \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy for every \(\eta \in (0,\infty )\) that
-
(a)
\({\mathcal {L}}(\Pi _{\eta })\le C'\ln (m)\left( {\left| {\ln (\eta )}\right| +m\ln (B)+\ln (m)}\right) \),
-
(b)
\({\mathcal {M}}(\Pi _{\eta })\le C' m\left( {\left| {\ln (\eta )}\right| +m\ln (B)+\ln (m)}\right) \) and
-
(c)
\(\displaystyle \sup _{x\in [-B,B]^m}\left| {\left[ {\prod _{j=1}^m x_j}\right] -\left[ {R_{\varrho }(\Pi _{\eta })}\right] \!(x)}\right| \le \eta \).
Let \((\Psi _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) be the neural networks which satisfy for every \(\varepsilon \in (0,\infty )\) that
Note that for every \(\varepsilon \in (0,\tfrac{B}{2m})\)
Combining this with Lemma 5.3, Lemma 5.4, (6.21) and (c) implies that for every \(\varepsilon \in (0,\tfrac{B}{2m})\), \(t=(t_1,t_2,\dots ,t_m)\in \Omega \) it holds
Moreover, for every \(\varepsilon \in [\tfrac{B}{2m},\infty )\), \(t=(t_1,t_2,\dots ,t_m)\in \Omega \) it holds that
This and (6.24) establish that the neural networks \((\Psi _{\varepsilon })_{\varepsilon ,c\,\in (0,\infty )}\) satisfy (iii). Next observe that Lemma 5.3, Lemma 5.4 and (a) demonstrate that for every \(\varepsilon \in (0,\tfrac{B}{2m})\)
This and the fact that for every \(\varepsilon \in [\tfrac{B}{2m},\infty )\) it holds that \({\mathcal {L}}(\Psi _{\varepsilon })={\mathcal {L}}(\theta )=1\) establish that the neural networks \((\Psi _{\varepsilon })_{\varepsilon ,c\,\in (0,\infty )}\) satisfy (i). Furthermore, note that Lemma 5.3, Lemma 5.4 and (b) ensure that for every \(\varepsilon \in (0,\tfrac{B}{2m})\)
This and the fact that for every \(\varepsilon \in [\tfrac{B}{2m},\infty )\) it holds that \({\mathcal {M}}(\Psi _{\varepsilon })={\mathcal {M}}(\theta )=0\) imply the neural networks \((\Psi _{\varepsilon })_{\varepsilon ,c\,\in (0,\infty )}\) satisfy (ii). The proof of Proposition 6.4 is completed. \(\square \)
Another way to use the multiplication results is to consider the approximation of smooth functions by polynomials. This can be done for functions of arbitrary dimension using the multivariate Taylor expansion (see [44] and [31, Thm. 2.3]). Such a direct approach, however, yields networks whose size depends exponentially on the dimension of the function. As our goal is to show that high-dimensional functions with a tensor product structure can be approximated by networks with only polynomial dependence on the dimension, we only consider univariate smooth functions here. In appendix, we present a detailed and explicit construction of this Taylor approximation by neural networks. In the following results, we employ an auxiliary parameter r, so that the bounds on the depth and connectivity of the networks may be stated for all \(\varepsilon \in (0,\infty )\). Note that this parameter does not influence the construction of the networks themselves.
Theorem 6.5
Assume Setting 5.1, let \(n\in {\mathbb {N}}\), \(r\in (0,\infty )\), let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\) and let \(B^n_1\subseteq C^n([0,1],{\mathbb {R}})\) be the set given by
Then there exist neural networks \((\Phi _{f,\varepsilon })_{f\in B^n_1,\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy
-
(i)
\(\displaystyle \sup _{f\in B^n_1,\varepsilon \in (0,\infty )}\left[ {\frac{{\mathcal {L}}(\Phi _{f,\varepsilon })}{\max \{r,\left| {\ln (\varepsilon )}\right| \}}}\right] <\infty \),
-
(ii)
\(\displaystyle \sup _{f\in B^n_1,\varepsilon \in (0,\infty )}\left[ {\frac{{\mathcal {M}}(\Phi _{f,\varepsilon })}{\varepsilon ^{-\frac{1}{n}}\max \{r,|\ln (\varepsilon )|\}}}\right] <\infty \) and
-
(iii)
for every \(f\in B^n_1\), \(\varepsilon \in (0,\infty )\) that
$$\begin{aligned} \sup _{t\in [0,1]}\left| {f(t)-\left[ {R_{\varrho }(\Phi _{f,\varepsilon })}\right] \!(t)}\right| \le \varepsilon . \end{aligned}$$(6.29)
For convenience of use, we also provide the following more general corollary.
Corollary 6.6
Assume Setting 5.1, let \(r\in (0,\infty )\) and let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\). Let further the set \({\mathcal {C}}^n\) be given by \({\mathcal {C}}^n=\cup _{[a,b]\subseteq {\mathbb {R}}_+}C^n([a,b],{\mathbb {R}})\), and let \(\left\Vert \cdot \right\Vert _{n,\infty }:{\mathcal {C}}^n\rightarrow [0,\infty )\) satisfy for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\)
Then there exist neural networks \(\left( {\Phi _{f,\varepsilon }}\right) _{f\in {\mathcal {C}}^n,\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy
-
(i)
\(\displaystyle \sup _{f\in {\mathcal {C}}^n, \varepsilon \in (0,\infty )}\left[ {\frac{{\mathcal {L}}(\Phi _{f,\varepsilon })}{\max \{r,|\ln (\frac{\varepsilon }{\max \{1,b-a\}\left\Vert f\right\Vert _{n,\infty }})|\}}}\right] <\infty \),
-
(ii)
\(\displaystyle \sup _{f\in {\mathcal {C}}^n, \varepsilon \in (0,\infty )}\left[ {\frac{{\mathcal {M}}(\Phi _{f,\varepsilon })}{\max \{1,b-a\}\left\Vert f\right\Vert _{n,\infty }^{\frac{1}{n}}\varepsilon ^{-\frac{1}{n}}\max \{r,|\ln (\frac{\varepsilon }{\max \{1,b-a\}\left\Vert f\right\Vert _{n,\infty }})|\}}}\right] <\infty \) and
-
(iii)
for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\) that
$$\begin{aligned} \sup _{t\in [a,b]}\left| {f(t)-\left[ {R_{\varrho }(\Phi _{f,\varepsilon })}\right] \!(t)}\right| \le \varepsilon . \end{aligned}$$(6.31)
7 DNN Expression Rates for High-Dimensional Basket Prices
Now that we have established a number of general expression rate results, we can apply them to our specific problem. Using the regularity result (3.3), we obtain the following.
Corollary 7.1
Assume Setting 5.1, let \(n\in {\mathbb {N}}\), \(r\in (0,\infty )\), \(a\in (0,\infty )\), \(b\in (a,\infty )\), let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\), let \(f:(0,\infty )\rightarrow {\mathbb {R}}\) be as defined in (3.1) and let \(h_{c,K}:[a,b]\rightarrow {\mathbb {R}}\), \(c\in (0,\infty )\), \(K\in [0,\infty )\), denote the functions which satisfy for every \(c\in (0,\infty )\), \(K\in [0,\infty )\), \(x\in [a,b]\) that
Then there exist neural networks \(\left( {\Phi _{\varepsilon ,c,K}}\right) _{\varepsilon ,c\,\in (0,\infty ),K\in [0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy
-
(i)
\(\displaystyle \sup _{\varepsilon ,c\in (0,\infty ),K\in [0,\infty )}\left[ {\frac{{\mathcal {L}}(\Phi _{\varepsilon ,c,K})}{\max \{r,|\ln (\varepsilon )|\}+\max \{0,\ln (K+c)\}}}\right] <\infty \),
-
(ii)
\(\displaystyle \sup _{\varepsilon ,c\,\in (0,\infty ),K\in [0,\infty )}\left[ {\frac{{\mathcal {M}}(\Phi _{\varepsilon ,c,K})}{(K+c+1)^{\frac{1}{n}}\varepsilon ^{-\frac{1}{n^2}}}}\right] <\infty \) and
-
(iii)
for every \(\varepsilon ,c\in (0,\infty )\), \(K\in [0,\infty )\) that
$$\begin{aligned} \sup _{x\in [a,b]}\left| {h_{c,K}(x)-\left[ {R_{\varrho }(\Phi _{\varepsilon ,c,K})}\right] \!(x)}\right| \le \varepsilon . \end{aligned}$$(7.2)
Proof of Corollary 7.1
We observe Corollary 3.3 ensures the existence of a constant \(C\in {\mathbb {R}}\) with
Moreover, observe for every \(\varepsilon ,c\in (0,\infty )\), \(K\in [0,\infty )\) it holds
Furthermore, note for every \(\varepsilon ,c\in (0,\infty )\), \(K\in [0,\infty )\) it holds
Combining this, (7.3), (7.4) with Lemma A.1 and Corollary 6.6 (with \(n\leftrightarrow 2n^2\) in the notation of Corollary 6.6) completes the proof of Corollary 7.1. \(\square \)
We can then employ Proposition 6.4 in order to approximate the required tensor product.
Corollary 7.2
Assume Setting 5.1, let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\), let \(n\in {\mathbb {N}}\), \(a\in (0,\infty )\), \(b\in (a,\infty )\), \((K_i)_{i\in {\mathbb {N}}}\subseteq [0,K_{\mathrm {max}})\), and consider, for \(h_{c,K}:[a,b]\rightarrow {\mathbb {R}}\), \(c\in (0,\infty )\), \(K\in [0,K_{\mathrm {max}})\), the functions which are, for every \(c\in (0,\infty )\), \(K\in [0,K_{\mathrm {max}})\), \(x\in [a,b]\), given by
For any \(c\in (0, \infty )\), \(d\in {\mathbb {N}}\) let the function \(F^d_c(x):[a,b]^d\rightarrow {\mathbb {R}}\) be given by
Then there exist neural networks \((\Psi ^d_{\varepsilon ,c})_{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\subseteq {\mathfrak {N}}\) which satisfy
-
(i)
\(\displaystyle \sup _{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\left[ {\frac{{\mathcal {L}}(\Psi ^d_{\varepsilon ,c})}{\max \{1,\ln (d)\}(\left| {\ln (\varepsilon )}\right| +\ln (d)+1)+\ln (c+1)}}\right] <\infty \),
-
(ii)
\(\displaystyle \sup _{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\left[ {\frac{{\mathcal {M}}(\Psi ^d_{\varepsilon ,c})}{(c+1)^{\frac{1}{n}}d^{1+\frac{1}{n}}\varepsilon ^{-\frac{1}{n}}}}\right] <\infty \) and
-
(iii)
for every \(\varepsilon ,c\,\in (0,\infty )\), \(d\in {\mathbb {N}}\) that
$$\begin{aligned} \sup _{x\in [a,b]^d}\left| {F^d_c(x)-\left[ {R_{\varrho }(\Psi ^d_{\varepsilon ,c})}\right] \!(x)}\right| \le \varepsilon . \end{aligned}$$(7.8)
Proof of Corollary 7.2
Throughout this proof, assume Setting 5.2. Corollary 7.1 ensures there exist constants \(b_L,b_M\in (0,\infty )\) and neural networks \(\left( {\Phi ^i_{\eta ,c}}\right) _{\eta ,c\,\in (0,\infty )}\subseteq {\mathfrak {N}}\), \(i\in {\mathbb {N}}\) such that for every \(i\in {\mathbb {N}}\) it holds
-
(a)
\(\displaystyle \sup _{\eta ,c\in (0,\infty )}\left[ {\frac{{\mathcal {L}}(\Phi ^i_{\eta ,c})}{\max \{1,|\ln (\eta )|\}+\max \{0,\ln (K_{\mathrm {max}}+c)\}}}\right] <b_L\),
-
(b)
\(\displaystyle \sup _{\eta ,c\,\in (0,\infty )}\left[ {\frac{{\mathcal {M}}(\Phi ^i_{\eta ,c})}{(K_{\mathrm {max}}+c+1)^{\frac{1}{n}}\eta ^{-\frac{1}{n^2}}}}\right] <b_M\) and
-
(c)
for every \(\eta ,c\in (0,\infty )\) that
$$\begin{aligned} \sup _{x\in [a,b]}\left| {h_{c,K_i}(x)-\left[ {R_{\varrho }(\Phi ^i_{\eta ,c})}\right] \!(x)}\right| \le \eta . \end{aligned}$$(7.9)
Furthermore, for every \(c\in (0,\infty )\), \(i\in {\mathbb {N}}\), \(x\in [a,b]\) holds
Combining this with (a) and Proposition 6.4 and Lemma 5.4 implies there exist \(C\in {\mathbb {R}}\) and neural networks \((\psi ^d_{\eta ,c})_{\eta \in (0,\infty )}\subseteq {\mathfrak {N}}\), \(c\in (0,\infty )\), \(d\in {\mathbb {N}}\), such that for every \(c\in (0,\infty )\), \(d\in {\mathbb {N}}\) it holds
-
(A)
\(\displaystyle {\mathcal {L}}(\psi ^d_{\eta ,c})\le C\ln (d)\left( {\left| {\ln (\eta )}\right| +\ln (d)}\right) +\max _{i\in \{1,2,\dots ,{d}\}}{\mathcal {L}}(\Phi ^i_{\eta ,c})\),
-
(B)
\(\displaystyle {\mathcal {M}}(\psi ^d_{\eta ,c})\le C d\left( {\left| {\ln (\eta )}\right| +\ln (d)}\right) +4\sum _{i=1}^d {\mathcal {M}}(\Phi ^i_{\eta ,c})+8d\max _{i\in \{1,2,\dots ,{d}\}}{\mathcal {L}}(\Phi ^i_{\eta ,c})\) and
-
(C)
for every \(\eta \in (0,\infty )\) that
$$\begin{aligned} \sup _{x\in [a,b]^d}\left| {\left[ {\textstyle \prod \limits _{i=1}^d h_{c,K_i}(x_i)}\right] -\left[ {R_{\varrho }(\psi ^d_{\eta ,c})}\right] \!(x)}\right| \le 3d\eta . \end{aligned}$$(7.11)
Let \(\lambda \in {\mathcal {N}}_1^{1,1}\) be the neural network given by \(\lambda =\left( {(-1,1)}\right) \), let \(\theta \in {\mathcal {N}}^{1,1}_1\) be the neural network given by \(\theta =(0,0)\) and let \((\Psi ^d_{\varepsilon ,c})_{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\subseteq {\mathfrak {N}}\) be the neural networks given by
Observe that this and (B) imply for every \(\varepsilon \in (0,2]\), \(c\,\in (0,\infty )\), \(d\in {\mathbb {N}}\), \(x\in [a,b]^d\) it holds
Moreover, (7.12) and (7.10) ensure for every \(\varepsilon \in (2,\infty )\), \(c\,\in (0,\infty )\), \(d\in {\mathbb {N}}\), \(x\in [a,b]^d\) it holds
This and (7.13) establish the neural networks \((\Psi ^d_{\varepsilon ,c})_{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\) satisfy (iii). Next observe that for every \(c\,\in (0,\infty )\) it holds
Hence, we obtain that for every \(\varepsilon ,c\,\in (0,\infty )\), \(d\in {\mathbb {N}}\) it holds
In addition, for every \(\varepsilon ,c\,\in (0,\infty )\), \(d\in {\mathbb {N}}\) it holds
Combining this with Lemma 5.3, (a), (A) and (7.16) yields
Moreover, (7.12) shows
This and (7.18) establish that \((\Psi ^d_{\varepsilon ,c})_{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\) satisfy (i). Next observe Lemma A.1 implies that
-
for every \(\varepsilon \in (0,2]\) it holds
$$\begin{aligned} |\ln (\varepsilon )|\le \left[ {\sup _{\delta \in [\exp (-2n^2),2]}\ln (\delta )}\right] \varepsilon ^{-\frac{1}{n}}=2n^2\varepsilon ^{-\frac{1}{n}}, \end{aligned}$$(7.20) -
for every \(d\in {\mathbb {N}}\) it holds
$$\begin{aligned} \ln (d)\le \left[ {\max _{k\in \{1,2,\dots {\exp (2n^2)}\}}\ln (k)}\right] d^{\frac{1}{n}}=2n^2d^{\frac{1}{n}}, \end{aligned}$$(7.21) -
and for every \(c\in (0,\infty )\) it holds
$$\begin{aligned} \ln (c+1)\le \left[ {\sup _{t\in (0,\exp (2n^2-1)]}\ln (t+1)}\right] (c+1)^{\frac{1}{n}}=2n^2(c+1)^{\frac{1}{n}}. \end{aligned}$$(7.22)
For every \(m\in {\mathbb {N}}\), \(x_i\in [1,\infty )\), \(i\in \{1,2,\dots ,{m}\}\), it holds
Combining this with (7.20), (7.21) and (7.22) shows for every \(\varepsilon \in (0,2]\), \(d\in {\mathbb {N}}\), \(c\in (0,\infty )\) it holds
Furthermore, note (7.15), (7.20), (7.21), (7.22) and (7.23) ensure for every \(\varepsilon \in (0,2]\), \(d\in {\mathbb {N}}\), \(c\in (0,\infty )\) it holds
In addition, observe that for every \(\varepsilon \in (0,2]\), \(d\in {\mathbb {N}}\), \(c\in (0,\infty )\) it holds
Combining this with Lemma 5.3, (a), (b), (B), (7.24) and (7.25) yield
Furthermore, note that (7.12) ensures
This and (7.27) establish that the neural networks \((\Psi ^d_{\varepsilon ,c})_{\varepsilon ,c\,\in (0,\infty ),d\in {\mathbb {N}}}\) satisfy (ii). Thus the proof of Corollary 7.2 is completed. \(\square \)
Finally, we add the quadrature estimates from Sect. 4 to achieve approximation with networks whose size only depends polynomially on the dimension of the problem.
Theorem 7.3
Assume Setting 5.1, let \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) be the ReLU activation function given by \(\varrho (t)=\max \{0,t\}\), let \(n\in {\mathbb {N}}\), \(a\in (0,\infty )\), \(b\in (a,\infty )\), \((K_i)_{i\in {\mathbb {N}}}\subseteq [0,K_{\mathrm {max}})\) and let \(F_d:(0,\infty )\times [a,b]^d\rightarrow {\mathbb {R}}\), \(d\in {\mathbb {N}}\), be the functions which satisfy for every \(d\in {\mathbb {N}}\), \(c\in (0, \infty )\), \(x\in [a,b]^d\)
Then there exists neural networks \((\Gamma _{d,\varepsilon })_{\varepsilon \in (0,1],d\in {\mathbb {N}}}\in {\mathfrak {N}}\) which satisfy
-
(i)
\(\displaystyle \sup _{\varepsilon \in (0,1],d\in {\mathbb {N}}}\left[ {\frac{{\mathcal {L}}(\Gamma _{d,\varepsilon })}{\max \{1,\ln (d)\}\left( {|\ln (\varepsilon )|+\ln (d)+1}\right) }}\right] <\infty \),
-
(ii)
\(\displaystyle \sup _{\varepsilon \in (0,1],d\in {\mathbb {N}}}\left[ {\frac{{\mathcal {M}}(\Gamma _{d,\varepsilon })}{d^{2+\frac{1}{n}}\varepsilon ^{-\frac{1}{n}}}}\right] <\infty \) and
-
(iii)
for every \(\varepsilon \in (0,1]\), \(d\in {\mathbb {N}}\) that
$$\begin{aligned} \sup _{x\in [a,b]^d}\left| {\int _0^{\infty }F_d(c,x)\mathrm {d}c-\left[ {R_{\varrho }(\Gamma _{d,\varepsilon })}\right] \!(x)}\right| \le \varepsilon . \end{aligned}$$(7.30)
Proof of Theorem 7.3
Throughout this proof, assume Setting 5.2, let \(S_{b,n}\in {\mathbb {R}}\) be given by
and let \(N_{d,\varepsilon }\in {\mathbb {R}}\), \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\), be given by
Note Lemma 4.3 (with \(4n\leftrightarrow n\), \(F_x^d(c)\leftrightarrow F_d(x,c)\), \(N_{d,\frac{\varepsilon }{2}}\leftrightarrow N_{d,\varepsilon }\), \(Q_{d,\frac{\varepsilon }{2}}\leftrightarrow Q_{d,\varepsilon }\) in the notation of Lemma 4.3) ensures that there exist \(Q_{d,\varepsilon }\in {\mathbb {R}}\), \(c^d_{\varepsilon ,j}\in (0,N_{d,\varepsilon })\), \(w^d_{\varepsilon ,j}\in [0,\infty )\), \(j\in \{1,2,\dots ,{Q_{d,\varepsilon }}\}\), \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\) with
and for every \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\) it holds
and
Furthermore, Corollary 7.2 (with \(4n\leftrightarrow n\), \(F_{c^d_{\varepsilon ,j}}^d(x)\leftrightarrow F_d(x,c^d_{\varepsilon ,j})\)) ensures there exist neural networks \((\Psi ^d_{\varepsilon ,j})_{\varepsilon \in (0,\infty ),d\in {\mathbb {N}},j\in \{1,2,\dots ,{Q_{d,\varepsilon }}\}}\subseteq {\mathfrak {N}}\) which satisfy
-
(a)
\(\displaystyle \sup _{\varepsilon \in (0,\infty ),d\in {\mathbb {N}}}\left[ {\frac{\max _{j\in \{1,2,\dots ,{Q_{d,\varepsilon }}\}}{\mathcal {L}}(\Psi ^d_{\varepsilon ,j})}{\max \{1,\ln (d)\}\left( {|\ln (\frac{\varepsilon }{2N_{d,\varepsilon }})|+\ln (d)+1}\right) +\ln (N_{d,\varepsilon }+1)}}\right] <\infty \),
-
(b)
\(\displaystyle \sup _{\varepsilon \in (0,\infty ),d\in {\mathbb {N}}}\left[ {\frac{\max _{j\in \{1,2,\dots ,{Q_{d,\varepsilon }}\}}{\mathcal {M}}(\Psi ^d_{\varepsilon ,j})}{(N_{d,\varepsilon }+1)^{\frac{1}{4n}}d^{1+\frac{1}{4n}}\left[ {\frac{\varepsilon }{2N_{d,\varepsilon }}}\right] ^{-\frac{1}{4n}}}}\right] <\infty \) and
-
(c)
for every \(\varepsilon \in (0,\infty )\), \(d\in {\mathbb {N}}\) that
$$\begin{aligned} \sup _{x\in [a,b]^d}\left| {F_d(c^d_{\varepsilon ,j},x)-\left[ {R_{\varrho }(\Psi ^d_{\varepsilon ,j})}\right] \!(x)}\right| \le \tfrac{\varepsilon }{2N_{d,\varepsilon }}. \end{aligned}$$(7.36)
Let \(\mathrm {Id}_{{\mathbb {R}}^d}\in {\mathbb {R}}^{d\times d}\), \(d\in {\mathbb {N}}\), be the matrices given by \(\mathrm {Id}_{{\mathbb {R}}^d}=\mathrm {diag}(1,1,\dots ,1)\), let \(\nabla _{d,q}\in {\mathcal {N}}_1^{d,dq}\), \(d,q\in {\mathbb {N}}\), be the neural networks given by
let \(\Sigma _{d,\varepsilon }\in {\mathcal {N}}_1^{d,1}\), \(d\in {\mathbb {N}}\), \(\varepsilon \in (0,1]\), be the neural networks given by
and let \((\Gamma _{d,\varepsilon })_{\varepsilon \in (0,1],d\in {\mathbb {N}}}\in {\mathfrak {N}}\) be the neural networks given by
Combining Lemma 5.3, Lemma 5.4, (7.34), (7.35) and (c) implies for every \(\varepsilon \in (0,\infty )\) and \(d\in {\mathbb {N}}\), \(x\in [a,b]^d\) it holds
This establishes that the neural networks \((\Gamma _{d,\varepsilon })_{\varepsilon \in (0,1],d\in {\mathbb {N}}}\) satisfy (iii). Next, observe for every \(\varepsilon \in (0,\infty )\), \(d\in {\mathbb {N}}\)
Combining this with Lemma 5.3, Lemma 5.4 and (a) implies
This establishes \((\Gamma _{d,\varepsilon })_{\varepsilon \in (0,1],d\in {\mathbb {N}}}\) satisfy (i). In addition, for every \(\varepsilon \in (0,\infty )\), \(d\in {\mathbb {N}}\) it holds
Combining this with Lemma 5.3, Lemma 5.4, (7.33), (b) and the fact that for every \(\psi \in {\mathfrak {N}}\) which satisfies \({\min _{l\in \{1,2,\dots ,{{\mathcal {L}}(\psi )}\}}{\mathcal {M}}_l(\psi )>0}\) it holds \({\mathcal {L}}(\psi )\le {\mathcal {M}}(\psi )\) ensures
This establishes the neural networks \((\Gamma _{d,\varepsilon })_{\varepsilon \in (0,1],d\in {\mathbb {N}}}\) satisfy (ii). The proof of Theorem 7.3 is thus completed. \(\square \)
8 Discussion
While Theorem 7.3 only establishes formally that the solution of one specific high-dimensional PDE may be approximated by neural networks without curse of dimensionality, the constructive approach also serves to illustrate that neural networks are capable of accomplishing the same for any PDE solution which exhibits a similar low-rank structure. Note here, that the tensor product construction in Proposition 6.4 only introduces a logarithmic dependency on the approximation accuracy. That we end up with a spectral rate in this specific case is due to Proposition 6.4 and Lemma 4.3, i.e., the insufficient regularity of the univariate functions inside the tensor product, as well as the number of terms required by the Gaussian quadrature used to approximate the outer integral. In particular, this means that the approach in Sect. 6 might also be used to produce approximation results with connectivity growing only logarithmically in the inverse of the approximation error, given that one has a suitably well-behaved low-rank structure.
The present result is a promising step toward higher-order, numerical solution of high-dimensional PDEs, which are notoriously troublesome to handle with any of the classical approaches based on discretization of the domain, or with randomized (a.k.a. Monte Carlo-based) arguments. Of course, answering the question of approximability can only ensure that there exist networks with a reasonable size-to-accuracy trade-off, whereas for any practical purpose it is also necessary to establish whether and how one can find these networks.
An analysis of the generalization error for linear Kolmogorov equations can be found in [4], which concludes that, under reasonable assumptions, the number of required Monte Carlo samples is free of the curse of dimensionality. Moreover, there are a number of empirical results [2, 3, 21, 39, 42], which suggest that the solutions of various high-dimensional PDEs may be learned efficiently using standard stochastic gradient descent-based methods. However, a satisfying formal analysis of this training process does not seem to be available at the present.
Lastly we would like to point out that, even though we had a semi-explicit formula available, the ReLU networks we used for approximation were in no way adapted to use this knowledge and have been shown to exhibit excellent approximation properties for, e.g., piecewise smooth functions [34], affine and Gabor systems [10] and even fractal structures [9]. So, while a spline dictionary-based approach specifically designed for the approximation of this one PDE solution may have similar rates, it would most certainly lack the remarkable universality of neural networks.
Notes
Often phrased as input dimension \(N_0\) and output dimension \(N_L\) with \(N_l\), \(l\in \{1,2,\dots ,{L-1}\}\) many neurons in the lth layer.
References
Barron, A.R.: Universal approximation bounds for superpositions of a sigmoidal function. IEEE Trans. Inf. Theory 39(3), 930–945 (1993)
Beck, C., Becker, S., Grohs, P., Jaafari, N., Jentzen, A.: Solving stochastic differential equations and Kolmogorov equations by means of deep learning. arXiv:1806.00421 (2018)
Beck, C., E, W., Jentzen, A.: Machine learning approximation algorithms for high-dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations. J. Nonlinear Sci. (2017)
Berner, J., Grohs, P., Jentzen, A.: Analysis of the generalization error: Empirical risk minimization over deep artificial neural networks overcomes the curse of dimensionality in the numerical approximation of Black-Scholes partial differential equations. SIAM J. Math. Data Sci. 2, 631–657 (2020)
Bölcskei, H., Grohs, P., Kutyniok, G., Petersen, P.: Optimal approximation with sparsely connected deep neural networks. SIAM J. Math. Data Sci. 1(1), 8–45 (2019)
Chiani, M., Dardari, D., Simon, M.K.: New exponential bounds and approximations for the computation of error probability in fading channels. IEEE Trans. Wireless Commun. 2(4), 840–845 (2003)
Chui, C., Li, X., Mhaskar, H.: Neural networks for localized approximation. Math. Comput. 63(208), 607–623 (1994)
Cybenko, G.: Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 2(4), 303–314 (1989)
Dym, N., Sober, B., Daubechies, I.: Expression of fractals through neural network functions. IEEE J. Select. Areas Inf. Theory 1(1), 57–66 (2020)
Elbrächter, D., Perekrestenko, D., Grohs, P., Bölcskei, H.: Deep neural network approximation theory. arXiv:1901.02220 (2019)
Freidlin, M.: Functional Integration and Partial Differential Equations. Annals of Mathematics Studies, vol. 109. Princeton University Press, Princeton (1985)
Fujii, M., Takahashi, A., Takahashi, M.: Asymptotic expansion as prior knowledge in deep learning method for high dimensional BSDEs. Asia-Pac. Finan. Mark. 29, 1563–1619 (2017)
Gonon, L., Grohs, P., Jentzen, A., Kofler, D., Šiška, D. Uniform error estimates for artificial neural network approximations for heat equations. arXiv:1911.09647 (2019)
Gonon, L., Schwab, C.: Deep ReLU network expression rates for option prices in high-dimensional, exponential Lévy models. Tech. Rep. 2020-52, Seminar for Applied Mathematics, ETH Zürich, 2020
Goodfellow, I., Bengio, Y., Courville, A., Bengio, Y.: Deep Learning, vol. 1. MIT Press, Cambridge (2016)
Goudenège, L., Molent, A., Zanette, A.: Machine learning for pricing American options in high-dimensional Markovian and non-Markovian models. Quant. Finance 20(4), 573–591 (2020)
Grohs, P., Herrmann, L.: Deep neural network approximation for high-dimensional elliptic PDEs with boundary conditions. arXiv:2007.05384 (2020)
Grohs, P., Hornung, F., Jentzen, A., von Wurstemberger, P.A., proof that artificial neural networks overcome the curse of dimensionality in the numerical approximation of Black–Scholes partial differential equations. arXiv:1809.02362. Accepted in Mem. Amer. Math, Soc (2019)
Grohs, P., Jentzen, A., Salimova, D.: Deep neural network approximations for Monte Carlo algorithms. arXiv:1908.10828 (2019)
Hairer, M., Hutzenthaler, M., Jentzen, A.: Loss of regularity for Kolmogorov equations. Ann. Probab. 43(2), 468–527 (2015)
Han, J., Jentzen, A., Weinan, E.: Solving high-dimensional partial differential equations using deep learning. Proc. Natl. Acad. Sci. 115(34), 8505–8510 (2018)
Henry-Labordere, P.: Deep Primal-Dual Algorithm for BSDEs: Applications of Machine Learning to CVA and IM. Available at SSRN: https://ssrn.com/abstract=3071506
Hornik, K., Stinchcombe, M., White, H.: Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks. Neural Netw. 3(5), 551–560 (1990)
Hornung, F., Jentzen, A., Salimova, D.: Space-time deep neural network approximations for high-dimensional partial differential equations. arXiv:2006.02199 (2020)
Hutzenthaler, M., Jentzen, A., Kruse, T., Nguyen, T.A.: A proof that rectified deep neural networks overcome the curse of dimensionality in the numerical approximation of semilinear heat equations. SN Partial Differ. Equ. Appl. 1, 10 (2020)
Jentzen, A., Salimova, D., Welti, T.: A proof that deep artificial neural networks overcome the curse of dimensionality in the numerical approximation of Kolmogorov partial differential equations with constant diffusion and nonlinear drift coefficients. arXiv:1809.07321 (2018)
Khoo, Y., Lu, J., Ying, L.: Solving parametric PDE problems with artificial neural networks. Eur. J. Appl. Math. (2020)
Kutyniok, G., Petersen, P., Raslan, M., Schneider, R.: A theoretical analysis of deep neural networks and parametric PDEs. arXiv:1904.00377 (2019)
Kwok, Y.-K.: Mathematical Models of Financial Derivatives, 2nd edn. Springer, Berlin (2008)
Levy, D.: Introduction to Numerical Analysis, 2010. Available: https://api.semanticscholar.org/CorpusID:123255603
Mhaskar, H.N.: Neural Networks for optimal approximation of smooth and analytic functions. Neural Comput. 8, 164–177 (1996)
Mishra, S.: A machine learning framework for data driven acceleration of computations of differential equations. Math. Eng. 1(1), 118–146 (2018)
Perekrestenko, D., Grohs, P., Elbrächter, D., Bölcskei, H.: The universal approximation power of finite-width deep ReLU networks. arXiv:1806.01528 (2018)
Petersen, P., Voigtlaender, F.: Optimal approximation of piecewise smooth functions using deep ReLU neural networks. Neural Netw. 108, 296–330 (2018)
Pinkus, A.: Approximation theory of the MLP model in neural networks. Acta Numer. 8, 143–195 (1999)
Reisinger, C., Zhang, Y.: Rectified deep neural networks overcome the curse of dimensionality for nonsmooth value functions in zero-sum games of nonlinear stiff systems. arXiv:1903.06652 (2019)
Schmidt-Hieber, J.: Nonparametric regression using deep neural networks with ReLU activation function. Ann. Stat. 48(4), 1875–1897 (2020)
Schwab, C., Zech, J.: Deep learning in high dimension: Neural network expression rates for generalized polynomial chaos expansions in UQ. Anal. App. 17(01), 19–55 (2019)
Sirignano, J., Spiliopoulos, K.: DGM: A deep learning algorithm for solving partial differential equations. J. Comput. Phys. 375, 1339–1364 (2018)
Telgarsky, M.: Representation benefits of deep feedforward networks. arXiv:1509.0810 (2015)
Weinan, E., Yu, B.: The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems. Commun. Math. Stat. 6(1), 1–12 (2018)
Weinan, E., Han, J., Jentzen, A.: Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat. 5(4), 349–380 (2017)
Wilmott, P.: Paul Wilmott Introduces Quantitative Finance, 2nd edn. Wiley, Hoboken (2007)
Yarotsky, D.: Error bounds for approximations with deep ReLU networks. Neural Networks 94, 103–114 (2017)
Funding
Open access funding provided by University of Vienna.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Wolfgang Dahmen, Ronald A. Devore, and Philipp Grohs.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was performed during visits of PG at the Seminar for Applied Mathematics and the FIM of ETH Zürich, and completed during the thematic term “Numerical Analysis of Complex PDE Models in the Sciences” at the Erwin Schrödinger Institute, Vienna, from June-August, 2018. AJ acknowledges support by the Swiss National Science Foundation under grant No. 175699 DE and PhG are supported in part by the Austrian Science Fund (FWF) under project number P 30148.
Additional Proofs
Additional Proofs
1.1 Technical Lemma
Lemma A.1
It holds for every \(r\in (0,\infty )\), \(t\in (0,\exp (-2r^2)]\) that
and for every \(r\in (0,\infty )\), \(t\in [\exp (2r^2),\infty )\) that
Proof of Lemma A.1
First, observe that for every \(r\in (0,\infty )\), \(y\in [2r^2,\infty )\) it holds that
This implies that for every \(r\in (0,\infty )\), \(x\in [\exp (2r^2),\infty )\) it holds that
Hence, we obtain that for every \(r\in (0,\infty )\), \(t\in (0,\exp (-2r^2)]\subseteq (0,1]\) it holds that
This completes the proof of Lemma A.1. \(\square \)
1.2 Proof of Lemma 6.1
Proof of Lemma 6.1
The proof follows [44]. We provide it in order to provide values of constants in the bounds on depth and width, and to reveal the dependence on the scaling parameter B. Throughout this proof, let \(\theta \in {\mathcal {N}}^{1,1}_1\) be the neural network given by \(\theta =(0,0)\), let \(g_s:[0,1]\rightarrow [0,1]\), \(s\in {\mathbb {N}}\), be the functions which satisfy for every \(s\in {\mathbb {N}}\), \(t\in [0,1]\) that
and let \(f_m:[0,1]\rightarrow [0,1]\), \(m\in {\mathbb {N}}\), be the functions which satisfy for every \(m\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^m}\}\), \(x\in \left[ {\tfrac{k}{2^m},\tfrac{k+1}{2^m}}\right] \) that
We claim for every \(s\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^{s-1}-1}\}\) it holds
We now prove (A.8) by induction on \(s\in {\mathbb {N}}\). Equation (A.6) establishes (A.8) in the base case \(s=1\). For the induction step \({\mathbb {N}}\ni s\rightarrow s+1\in \{2,3,\dots \}\) observe that (A.6) implies for every \(s\in {\mathbb {N}}\), \(l\in \{0,1,\dots ,{2^{s-1}-1}\}\) that
-
(a)
it holds for every \(x\in \left[ {\tfrac{2l}{2^s},\tfrac{2l+(\nicefrac {1}{2})}{2^s}}\right] \)
$$\begin{aligned} \begin{aligned} g_{s+1}(x)&=g(g_s(x))=g(2^s(x-\tfrac{2l}{2^s}))=2\left[ {2^s(x-\tfrac{2l}{2^s})}\right] \\&=2^{s+1}(x-\tfrac{2l}{2^s})=2^{s+1}(x-\tfrac{2(2l)}{2^{s+1}}). \end{aligned}\end{aligned}$$(A.9) -
(b)
it holds for every \(x\in \left[ {\tfrac{2l+(\nicefrac {1}{2})}{2^s},\tfrac{2l+1}{2^s}}\right] \)
$$\begin{aligned} \begin{aligned} g_{s+1}(x)&=g(g_s(x))=g(2^s(x-\tfrac{2l}{2^s}))=2-2\left[ {2^s(x-\tfrac{2l}{2^s})}\right] \\&=2-2^{s+1}x+4l=2^{s+1}\left( \tfrac{4l+2}{2^{s+1}}-x\right) \\&=2^{s+1}\left( \tfrac{2(2l+1)}{2^{s+1}}-x\right) . \end{aligned}\end{aligned}$$(A.10) -
(c)
it holds for every \(x\in \left[ {\tfrac{2l+1}{2^s},\tfrac{2l+(\nicefrac {3}{2})}{2^s}}\right] \)
$$\begin{aligned} \begin{aligned} g_{s+1}(x)&=g(g_s(x))=g\left( 2^s\left( \tfrac{2l+2}{2^s}-x\right) \right) =2-2\left[ {2^s \left( \tfrac{2l+2}{2^s}-x\right) }\right] \\&=2-2(2l+2)+2^{s+1}x=2^{s+1}x-2(2l+1)\\&=2^{s+1}(x-\tfrac{2(2l+1)}{2^{s+1}}). \end{aligned}\end{aligned}$$(A.11) -
(d)
it holds for every \(x\in \left[ {\tfrac{2l+(\nicefrac {3}{2})}{2^s},\tfrac{2l+2}{2^s}}\right] \)
$$\begin{aligned} \begin{aligned} g_{s+1}(x)&=g(g_s(x))=g\left( 2^s\left( \tfrac{2l+2}{2^s}-x\right) \right) =2\left[ {2^s\left( \tfrac{2l+2}{2^s}-x\right) }\right] \\&=2^{s+1}\left( \tfrac{2l+2}{2^s}-x\right) =2^{s+1} \left( \tfrac{2(2l+2)}{2^{s+1}}-x\right) . \end{aligned}\end{aligned}$$(A.12)
Next observe that for every \(s\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^s-1}\}\) there exists \(l\in \{0,1,\dots ,{2^{s-1}-1}\}\) such that
Furthermore, for every \(s\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^s-1}\}\) there exists \(l\in \{0,1,\dots ,{2^{s-1}-1}\}\) such that
Combining this with (A.9), (A.10), (A.11), (A.12) and (A.13) completes the induction step \({\mathbb {N}}\ni s\rightarrow s+1\in \{2,3,\dots \}\) and thus establishes the claim (A.8).
Next, for every \(m\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^{m-1}}\}\) it holds
In addition, note that (A.7) implies that for every \(m\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^m-1}\}\) it holds
and
For every \(m\in {\mathbb {N}}\), \(k\in \{0,1,\dots ,{2^m-1}\}\) it holds
Combining this with (A.8), (A.7) and (A.15) demonstrates that for every \(m\in {\mathbb {N}}\), \(x\in [0,1]\) it holds
The fact that for every \(x\in [0,1]\) it holds that \(f_0(x)=x\) therefore implies that for every \(m\in {\mathbb {N}}_0\), \(x\in [0,1]\) it holds
We observe \(f_m\) is the affine, linear interpolant of the twice continuously differentiable function \([0,1]\ni x\mapsto x^2\in [0,1]\) at the points \(\tfrac{k}{2^m}\), \(k\in \{0,1,\dots ,{2^m}\}\). This establishes that for every \(m\in {\mathbb {N}}\)
Let \((A_k,b_k)\in {\mathbb {R}}^{4\times 4}\times {\mathbb {R}}^4\), \(k\in {\mathbb {N}}\), be the matrix-vector tuples which satisfy for every \(k\in {\mathbb {N}}\)
let \(\varphi _m\in {\mathfrak {N}}\), \(m\in {\mathbb {N}}\), be the neural networks which satisfy \(\varphi _1=(1,0)\) and, for every \(m\in {\mathbb {N}}\),
Let further \(r^k:{\mathbb {R}}\rightarrow {\mathbb {R}}\), \(k\in {\mathbb {N}}\) denote the function which satisfies for every \(x\in {\mathbb {R}}\)
and for every \(x\in {\mathbb {R}}\), \(k\in {\mathbb {N}}\)
We claim that for every \(k\in \{1,2,\dots ,{m-1}\}\), \(x\in [0,1]\) it holds
-
(a)
$$\begin{aligned} 2r^k_1(x)-4r^k_2(x)+2r^k_3(x)=g_k(x) \end{aligned}$$(A.26)
and
-
(b)
$$\begin{aligned} r^k_4(x)=x-\sum _{j=1}^{k-1} 2^{-2j}g_j(x). \end{aligned}$$(A.27)
We prove (a) and (b) by induction over \(k\in \{1,2,\dots ,{m-1}\}\). For the base case \(k=1\) we note that for every \(x\in [0,1]\) it holds
Hence, we obtain that for every \(x\in [0,1]\) it holds
Furthermore, note that for every \(x\in [0,1]\) it holds that \(r^1_4(x)=x\). This and (A.29) establish the base case \(k=1\). For the induction step \(\{1,2,\dots ,{m-2}\}\ni k-1\rightarrow k\in \{2,3,\dots ,m-1\}\) observe that (A.28) ensures for every \(x\in [0,1]\), \(k\in \{2,3,\dots ,m-1\}\), with \(g_{k-1}(x)=2r^{k-1}_1(x)-4r^{k-1}_2(x)+2r^{k-1}_3(x)\), it holds
Induction thus establishes (a). Moreover note that (A.7) and (A.20) for every \(k\in {\mathbb {N}}\), \(x\in [0,1]\) it holds
Combining this with (A.28) implies that for every \(x\in [0,1]\), \(k\in \{2,3,\dots ,m-1\}\) with \(g_{k-1}(x)=2r^{k-1}_1(x)-4r^{k-1}_2(x)+2r^{k-1}_3(x)\) and \(r^{k-1}_4(x)=x-\sum _{j=1}^{k-2} 2^{-2j}g_j(x)\) it holds
Induction thus establishes (b). Next observe that (a) and (b) that for every \(m\in {\mathbb {N}}\), \(x\in [0,1]\) it holds
Combining this with (A.20) establishes that for every \(m\in {\mathbb {N}}\), \(x\in [0,1]\) it holds
This and (A.21) imply that for every \(m\in {\mathbb {N}}\) it holds
Furthermore, observe that by construction it holds for every \(m\in {\mathbb {N}}\)
Let \((\sigma _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) be the neural networks which satisfy for \(\varepsilon \in (0,1)\)
and for every \(\varepsilon \in [1,\infty )\) that \(\sigma _{\varepsilon }=\theta \). Observe that for every \(\varepsilon \in [1,\infty )\) it holds
In addition, note for every \(\varepsilon \in (0,1)\) it holds
Moreover, observe that (A.36) implies for every \(\varepsilon \in (0,1)\) it holds
and
Furthermore, for every \(\varepsilon \in [1,\infty )\) it holds \({\mathcal {L}}(\sigma _{\varepsilon })={\mathcal {L}}(\theta )=1\) and \({\mathcal {M}}(\sigma _{\varepsilon })={\mathcal {M}}(\theta )=0\). This completes the proof of Lemma 6.1. \(\square \)
1.3 Proof of Lemma 6.2
Proof of Lemma 6.2
Throughout this proof, assume Setting 5.2, let \(\theta \in {\mathcal {N}}^{1,1}_1\) be the neural network given by \(\theta =(0,0)\), let \(\alpha \in {\mathcal {N}}_2^{2,6,3}\) be the neural network given by
and let \(\Sigma \in {\mathcal {N}}^{3,1}_1\) be the neural network given by \(\Sigma =\left( {(\begin{pmatrix}2B^2&-2B^2&-2B^2\end{pmatrix},0)}\right) \). Observe that Lemma 6.1 ensures the existence of neural networks \((\sigma _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy Lemma 6.1, (i) – (iv). Let \((\mu _{\varepsilon })_{\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) be the neural networks which satisfy for every \(\varepsilon \in (0,\infty )\)
Note first that for every \(\varepsilon \in [B^2,\infty )\) it holds
Next observe that for every \((x,y)\in {\mathbb {R}}^2\) it holds
Furthermore, for every \((x,y,z)\in {\mathbb {R}}^3\) holds \([R_{\varrho }(\Sigma )](x,y,z) = 2B^2x - 2B^2y - 2B^2z\). Combining this with Lemma 5.3, Lemma 5.4, (A.43) and (A.45) establishes that for every \(\varepsilon \in (0,B^2)\), \((x,y)\in [-B,B]^2\) it holds
With Lemma 6.1, Item iv, (A.46) establishes (v). In addition note that Lemma 6.1 demonstrates for every \(\varepsilon \in (0,\infty )\) it holds
This and (A.46) establish that for every \(\varepsilon \in (0,B^2)\) it holds
Next observe that \({\mathcal {L}}(\alpha )=2\) and \({\mathcal {L}}(\Sigma )=1\). Combining this with Lemma 5.3, Lemma 5.4 and Lemma 6.1(i) ensures for every \(\varepsilon \in (0,B^2)\)
Combining \({\mathcal {M}}(\alpha )=14\) and \({\mathcal {M}}(\Sigma )=3\) with Lemma 5.3, Lemma 5.4, Lemma 6.1(ii) and (A.42) demonstrate that for every \(\varepsilon \in (0,B^2)\) it holds
Moreover, for every \(\varepsilon \in (B^2,\infty )\) it holds \({\mathcal {L}}(\mu _{\varepsilon })=1\) and \({\mathcal {M}}(\mu _{\varepsilon })=0\). Next, observe Lemma 5.3 and Lemma 5.4 demonstrate that for every \(\varepsilon \in (0,\infty )\) it holds that \({\mathcal {M}}_1(\mu _\varepsilon )={\mathcal {M}}_1(\alpha )=8\) and \({\mathcal {M}}_{{\mathcal {L}}(\mu _{\varepsilon })}(\mu _{\varepsilon })={\mathcal {M}}(\Sigma )=3\). This completes the proof of Lemma 6.2. \(\square \)
1.4 Proof of Theorem 6.5
Proof of Theorem 6.5
Throughout this proof, assume Setting 5.2, let \(h_{N,j}:{\mathbb {R}}\rightarrow {\mathbb {R}}\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,N\}\), be the functions which satisfy for every \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,N\}\), \(x\in {\mathbb {R}}\)
let \(T_{f,N,j}:{\mathbb {R}}\rightarrow {\mathbb {R}}\), \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,N\}\), be the functions which satisfy for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,N\}\), \(x\in [0,1]\)
For every \(f\in B^n_1\), let \(f_N:{\mathbb {R}}\rightarrow {\mathbb {R}}\), \(N\in {\mathbb {N}}\) denote functions which satisfy for every \(N\in {\mathbb {N}}\), \(x\in [0,1]\)
Observe that Taylor’s theorem (with Lagrange remainder term) ensures that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,N\}\), \(x\in [\max \{0,\tfrac{j-1}{N}\},\min \{1,\tfrac{j+1}{N}\}]\)
Moreover, for every \(N\in {\mathbb {N}}\), \(x\in [0,1]\), \(j\notin \{\lceil Nx\rceil -1,\lceil Nx\rceil \}\) it holds that \(h_{N,j}(x)=0\). We obtain for every \(N\in {\mathbb {N}}\) and \(x\in [0,1]\)
Furthermore, (A.51) implies for every \(N\in {\mathbb {N}}\), \(j\in \{1,\dots ,N-1\}\), \(x\in [\tfrac{j-1}{N},\tfrac{j}{N}]\) holds
Combining this with (A.53), (A.54) and (A.55) establishes that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(x\in [0,1]\)
We now realize this local Taylor approximation using neural networks. To this end, note that Theorem 6.3 ensures that there exist \(C\in {\mathbb {R}}\) and neural networks \((\Pi _{\eta }^k)_{\eta \in (0,\infty )}\), \(k\in {\mathbb {N}}\cap [2,\infty )\) which satisfy
-
(A)
\(\displaystyle {\mathcal {L}}(\Pi _{\eta }^k)\le C\ln (k)\left( {\left| {\ln (\eta )}\right| +k\ln (3)+\ln (k)}\right) \),
-
(B)
\(\displaystyle {\mathcal {M}}(\Pi _{\eta }^k)\le C k\left( {\left| {\ln (\eta )}\right| +k\ln (3)+\ln (k)}\right) \),
-
(C)
\(\displaystyle \sup _{x\in [-3,3]^k}\left| {\left[ {\prod _{i=1}^k x_i}\right] -\left[ {R_{\varrho }(\Pi _{\eta }^k)}\right] \!(x)}\right| \le \eta \) and
-
(D)
\(R_\varrho \left[ \Pi _{\eta }^k\right] (x_1,x_2,\dots ,x_k)=0\), if there exists \(i\in \{1,2,\dots ,k\}\) with \(x_i=0\).
To complete the proof, we introduce the following neural networks:
-
\(\nabla _{N,j,k}\in {\mathcal {N}}^{k,1}_1\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\), \(k\in \{2,3,\dots ,n-1\}\) given by
$$\begin{aligned} \nabla _{N,j,k}=\left( {(\begin{pmatrix}1 \\ \vdots \\ 1\end{pmatrix}, \begin{pmatrix}-\tfrac{j}{N} \\ \vdots \\ -\tfrac{j}{N} \end{pmatrix})}\right) , \end{aligned}$$(A.58) -
\(\xi _{\varepsilon ,N,j}^k\in {\mathfrak {N}}\), \(\varepsilon \in (0,\infty )\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\), \(k\in \{1,2,\dots ,n-1\}\), given by
$$\begin{aligned} \xi _{\varepsilon ,N,j}^k={\left\{ \begin{array}{ll}(1,0) &{} :k=1\\ \Pi ^k_{\nicefrac {\varepsilon }{8e}}\odot \nabla _{N,j,k} &{} :k>1\end{array}\right. }, \end{aligned}$$(A.59) -
\(\Sigma _{f,N,j}\in {\mathcal {N}}^{1,n-1}_1\), \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\) given by
$$\begin{aligned} \Sigma _{f,N,j}=\left( {(\begin{pmatrix}\frac{f^{(n-1)}\left( \tfrac{j}{N}\right) }{(n-1)!}&\frac{f^{(n-2)}\left( \tfrac{j}{N}\right) }{(n-2)!}&\dots&\frac{f^{(1)}\left( \tfrac{j}{N}\right) }{(1)!}\end{pmatrix},f\left( \tfrac{j}{N}\right) )}\right) , \end{aligned}$$(A.60) -
\(\tau _{f,\varepsilon ,N,j}\in {\mathfrak {N}}\), \(f\in B^n_1\), \(\varepsilon \in (0,\infty )\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\) given by
$$\begin{aligned} \tau _{f,\varepsilon ,N,j}=\Sigma _{f,N,j}\odot {\mathcal {P}}(\xi _{\varepsilon ,N,j}^{n-1}, \xi _{\varepsilon ,N,j}^{n-2}, \dots , \xi _{\varepsilon ,N,j}^1)\odot \nabla _{1,0,n-1}, \end{aligned}$$(A.61) -
\(\chi _{N,j}\in {\mathcal {N}}^{1,3,1}_2\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\) given by
$$\begin{aligned} \chi _{N,j}=\left( {(\begin{pmatrix}1 \\ 1 \\ 1 \end{pmatrix}, \begin{pmatrix}-\nicefrac {(j-1)}{N} \\ -\nicefrac {j}{N} \\ -\nicefrac {(j+1)}{N}\end{pmatrix}), (\begin{pmatrix}1&-2&1\end{pmatrix},0)}\right) \end{aligned}$$(A.62) -
\(\lambda _N\in {\mathcal {N}}^{1,N+1}_1\), \(N\in {\mathbb {N}}\) given by
$$\begin{aligned} \lambda _N=\left( {(\begin{pmatrix}1&\dots&1\end{pmatrix},0)}\right) , \end{aligned}$$(A.63) -
\(\psi _{f,\varepsilon ,N,j}\in {\mathfrak {N}}\), \(f\in B^n_1\), \(\varepsilon \in (0,\infty )\), \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\) given by
$$\begin{aligned} \psi _{f,\varepsilon ,N,j}=\Pi ^2_{\nicefrac {\varepsilon }{8}}\odot {\mathcal {P}}(\chi _{N,j},\tau _{f,\varepsilon ,N,j}), \end{aligned}$$(A.64) -
\(\varphi _{f,\varepsilon ,N}\in {\mathfrak {N}}\), \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\) given by
$$\begin{aligned} \varphi _{f,\varepsilon ,N}=\lambda _N\odot {\mathcal {P}}\left( {\psi _{f,\varepsilon ,N,1}, \psi _{f,\varepsilon ,N,2}, \dots , \psi _{f,\varepsilon ,N,N}}\right) \odot \nabla _{1,0,2N+2}. \end{aligned}$$(A.65)
With these networks, we note Lemma 5.3, Lemma 5.4, (C), (A.58) and (A.59) ensure that for every \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\), \(k\in \{2,3,\dots ,n-1\}\)
and
Moreover, Lemma 5.3, Lemma 5.4, (A.58), (A.59), (A.60) and (A.61) demonstrate that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\), \(x\in [0,1]\) it holds
Combining this with (A.52), (A.61), (A.66) and (A.66) establishes that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\), \(x\in [0,1]\) it holds
Next, (A.62) ensures for every \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\), \(x\in [0,1]\)
Now (A.69) and Taylor’s Theorem imply for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,1)\), \(j\in \{0,1,\dots ,{N}\}\), \(x\in [0,1]\) that
Combining this with Lemma 5.3, Lemma 5.4, (A.51), (C), (A.69) and (A.70) establishes for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,1)\), \(j\in \{0,1,\dots ,{N}\}\), \(x\in [0,1]\) the bound
Furthermore, note that for every \(N\in {\mathbb {N}}\), \(j\in \{0,1,\dots ,{N}\}\), \(x\notin [\tfrac{j-1}{N},\tfrac{j+1}{N}]\) it holds that \(h_{N,j}(x)=\chi _{N,j}(x)=0\). Thus (D) ensures that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,1)\), \(j\in \{0,1,\dots ,{N}\}\), \(x\in [0,1]\) it holds
This, Lemma 5.3, Lemma 5.4, (A.53), (A.65) and (A.72) imply that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,1)\), \(x\in [0,1]\) it holds
Combining this with (A.57) establishes that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,1)\), \(x\in [0,1]\) it holds
Let \(N_{\varepsilon }\in {\mathbb {N}}\) satisfy for every \(\varepsilon \in (0,\infty )\)
let \(\theta \in {\mathcal {N}}^{1,1}_1\) be given by \(\theta =(0,0)\) and let \((\Phi _{f,\varepsilon })_{f\in B^n_1,\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) be the neural networks given by
Observe that (A.75) implies that for every \(f\in B^n_1\), \(\varepsilon \in (0,1)\), \(x\in [0,1]\)
Moreover that for every \(f\in B^n_1\), \(\varepsilon \in [1,\infty )\), \(x\in [0,1]\) it holds
This and (A.78) establish that the neural networks \((\Phi _{f,\varepsilon })_{f\in B^n_1,\varepsilon \in (0,\infty )}\) satisfy (iii).
Next, Lemma 5.3, Lemma 5.4, (A), (A.58) and (A.59) imply for every \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\), \(k\in \{1,2,\dots ,n-1\}\)
Combining this with Lemma 5.3, Lemma 5.4, (A.58), (A.60), (A.61) shows for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\) the bound
This, Lemma 5.3, Lemma 5.4, (A), (A.62), (A.63), (A.65) and (A.58) ensure for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\) it holds
With the constant C from (A.82), define the term \(T_1\) by
Observe that (A.82) implies for every \(f\in B^n_1\), \(\varepsilon \in (0,1)\)
Hence we obtain
In addition, note that (A.84) ensures that
Furthermore,
This, (A.85) and (A.86) establish that the neural networks \((\Phi _{f,\varepsilon })_{\varepsilon \in (0,\infty )}\) satisfy (i). Next, Lemma 5.3, (B), (A.58) and (A.59) imply for every \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\), \(k\in \{1,2,\dots ,n-1\}\)
Combining this with Lemma 5.3, Lemma 5.4, (A.58), (A.60) and (A.61) shows for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\), \(j\in \{0,1,\dots ,{N}\}\) it holds
Let the term \(T_2\) be given by
and let the term \(T_3\) be given by
This, Lemma 5.3, Lemma 5.4, (B), (A.58), (A.62), (A.63), (A.65) and the fact that for every \(\psi \in {\mathfrak {N}}\) with \(\min _{l\in \{1,2,\dots ,{{\mathcal {L}}(\psi )}\}}{\mathcal {M}}_l(\psi )>0\) it holds that \({\mathcal {L}}(\psi )\le {\mathcal {M}}(\psi )\) ensure that for every \(f\in B^n_1\), \(N\in {\mathbb {N}}\), \(\varepsilon \in (0,\infty )\) it holds
Combining this with Lemma A.1 demonstrates that for every \(f\in B^n_1\), \(\varepsilon \in (0,\exp (-2n^2)]\) it holds
Hence we obtain
Combining (A.93) with the fact that continuous function are bounded on compact sets ensures
In addition note
This, (A.94) and (A.95) establish that the neural networks \((\Phi _{f,\varepsilon })_{f\in B^n_1,\varepsilon \in (0,\infty )}\) satisfy (ii). The proof of Theorem 6.5 is completed. \(\square \)
1.5 Proof of Corollary 6.6
Proof of Corollary 6.6
Throughout this proof, assume Setting 5.2, let \(c_{a,b}\in {\mathbb {R}}\), \([a,b]\subseteq {\mathbb {R}}_+\), be the real numbers given by \(c_{a,b}=\min \{1,(b-a)^{-n}\}\), let \(\lambda _{a,b}\in {\mathcal {N}}^{1,1}_1\), \([a,b]\subseteq {\mathbb {R}}_+\), be the neural networks given by \(\lambda _{a,b}=(\tfrac{1}{b-a},-\tfrac{a}{b-a})\), let \(\alpha _f\in {\mathcal {N}}^{1,1}_1\), \(f\in {\mathcal {C}}^n\) be the neural networks given by \(\alpha _f=(\tfrac{1}{c}\left\Vert f\right\Vert _{n,\infty },0)\), let \(L_{a,b}:[0,1]\rightarrow [a,b]\), \([a,b]\subseteq {\mathbb {R}}_+\) be the functions which satisfy for every \([a,b]\subseteq {\mathbb {R}}_+\), \(t\in [0,1]\)
and for every \(f\in {\mathcal {C}}^n\) let \(f_*\in C^n([0,1],{\mathbb {R}})\) be the function which satisfies for every \(t\in [0,1]\)
We claim that for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(m\in \{1,2,\dots ,{n}\}\), \(t\in [0,1]\) it holds
We now prove (A.100) by induction on \(m\in \{1,2,\dots ,{n}\}\). For the base case \(m=1\), the chain rule implies for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(t\in [0,1]\)
This establishes (A.100) in the base case \(m=1\).
For the induction step \(\{1,2,\dots ,n-1\}\ni m\rightarrow m+1\in \{2,3,\dots ,n\}\) observe that the chain rule ensures for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(m\in {\mathbb {N}}\), \(t\in [0,1]\)
Induction thus establishes (A.100).
In addition, for every \([a,b]\subseteq {\mathbb {R}}_+\), \(k\in \{0,1,\dots ,n\}\)
Combining this with (6.30), (A.98) and (A.100) ensures for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\)
Theorem 6.5 therefore establishes that there exist neural networks \((\Phi _{g,\eta })_{g\in B^n_1,\eta \in (0,\infty )}\subseteq {\mathfrak {N}}\) which satisfy
-
(a)
\(\displaystyle \sup _{g\in B^n_1,\eta \in (0,\infty )}\left[ {\frac{{\mathcal {L}}(\Phi _{g,\eta })}{\max \{r,\left| {\ln (\eta )}\right| \}}}\right] <\infty \),
-
(b)
\(\displaystyle \sup _{g\in B^n_1,\eta \in (0,\infty )}\left[ {\frac{{\mathcal {M}}(\Phi _{g,\eta })}{\eta ^{-\frac{1}{n}}\max \{r,|\ln (\eta )|\}}}\right] <\infty \) and
-
(c)
for every \(g\in B^n_1\), \(\eta \in (0,\infty )\) that
$$\begin{aligned} \sup _{t\in [0,1]}\left| {g(t)-\left[ {R_{\varrho }(\Phi _{g,\eta })}\right] \!(t)}\right| \le \eta . \end{aligned}$$(A.105)
Let \(\left( {\Phi _{f,\varepsilon }}\right) _{f\in {\mathcal {C}}^n,\varepsilon \in (0,\infty )}\subseteq {\mathfrak {N}}\) denote neural networks which satisfy for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\)
Observe that for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(t\in [0,1]\) it holds
Lemma 5.3 therefore demonstrates for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\), \(t\in [0,1]\) it holds
Moreover, note (A.99) ensures that for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(t\in [a,b]\) it holds
Combining (c), (A.106) and (A.108) implies for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\)
This establishes that the neural networks \(\left( {\Phi _{f,\varepsilon }}\right) _{f\in {\mathcal {C}}^n, \varepsilon \in (0,\infty )}\) satisfy (iii). Furthermore, Lemma 5.3 ensures for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\) holds
In addition, for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\) holds
Combining this with (a) and (A.111) implies that
This establishes that the neural networks \(\left( {\Phi _{f,\varepsilon }}\right) _{f\in {\mathcal {C}}^n, \varepsilon \in (0,\infty )}\) satisfy (i). Next, Lemma 5.3 implies that for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\)
In addition, note that (A.112) shows for every \([a,b]\subseteq {\mathbb {R}}_+\), \(f\in C^n([a,b],{\mathbb {R}})\), \(\varepsilon \in (0,\infty )\)
Combining this with (b) and (A.106) therefore ensures
This establishes that the neural networks \(\left( {\Phi _{f,\varepsilon }}\right) _{f\in {\mathcal {C}}^n, \varepsilon \in (0,\infty )}\) satisfy (ii) and completes the proof. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elbrächter, D., Grohs, P., Jentzen, A. et al. DNN Expression Rate Analysis of High-Dimensional PDEs: Application to Option Pricing. Constr Approx 55, 3–71 (2022). https://doi.org/10.1007/s00365-021-09541-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00365-021-09541-6