
Abstract
This paper introduces a new class of judgment aggregation rules, to be called ‘scoring rules’ after their famous counterparts in preference aggregation theory. A scoring rule generates the collective judgment set which reaches the highest total ‘score’ across the individuals, subject to the judgment set having to be rational. Depending on how we define ‘scores’, we obtain several (old and new) solutions to the judgment aggregation problem, such as distance-based aggregation, premise- and conclusion-based aggregation, truth-tracking rules, and a generalization of the Borda rule to judgment aggregation theory. Scoring rules are shown to generalize the classical scoring rules of preference aggregation theory.
Similar content being viewed by others

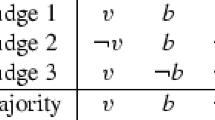
Avoid common mistakes on your manuscript.
1 Introduction
The judgment aggregation problem consists in merging many individuals’ yes/no judgments on some interconnected propositions into collective yes/no judgments on these propositions. The classical example, born in legal theory, is that three jurors in a court trial disagree on which of the following three propositions are true: the defendant has broken the contract \((p)\); the contract is legally valid \((q)\); the defendant is liable \((r)\). According to a universally accepted legal doctrine, \(r\) (the ‘conclusion’) is true if and only if \(p\) and \(q\) (the two ‘premises’) are both true. So, \(r\) is logically equivalent to \(p\wedge q\). The simplest rule to aggregate the jurors’ judgments—namely propositionwise majority voting—may generate logically inconsistent collective judgments, as Table 1 illustrates. There are of course numerous other possible ‘agendas’, i.e., kinds of interconnected propositions a group might face. Preference aggregation is a special case with propositions of the form ‘\(x\) is better than \(y\)’ (for many alternatives \(x\) and \(y\)), where these propositions are interconnected through standard conditions such as transitivity. In this context, Condorcet’s classical voting paradox about cyclical majority preferences is nothing but another example of inconsistent majority judgments. Starting with List and Pettit’s (2002) seminal paper, a whole series of contributions have explored which judgment aggregation rules can be used, depending on, firstly, the agenda in question, and, secondly, the requirements placed on aggregation, such as anonymity, and of course the consistency of collective judgments. Some theorems generalize Arrow’s Theorem from preference to judgment aggregation (Dietrich and List 2007a; Dokow and Holzman 2010; both build on Nehring and Puppe 2010a and strengthen Wilson 1975). Other theorems have no immediate counterparts in classical social choice theory (e.g., List 2004; Dietrich 2006a, 2010; Nehring and Puppe 2010b; Dietrich and Mongin 2010).
It is fair to say that judgment aggregation theory has until recently been dominated by ‘impossibility’ findings, as is evident from the Symposium on Judgment Aggregation in Journal of Economic Theory (List and Polak 2010). The recent conference ‘Judgment aggregation and voting’ in Freudenstadt in 2011 however marks a visible shift of attention towards constructing concrete aggregation rules and finding ‘second best’ solutions in the face of impossibility results. The new proposals range from a first Borda-type aggregation rule (Zwicker 2011) to, among others, new distance-based rules (Duddy and Piggins 2012) and rules which approximate the majority judgments when these are inconsistent (Nehring et al. 2011). The more traditional proposals include premise- and conclusion-based rules (e.g., Kornhauser and Sager 1986; Pettit 2001; List and Pettit 2002; Dietrich 2006a; Dietrich and Mongin 2010), sequential rules (e.g., List 2004; Dietrich and List 2007b), distance-based rules (e.g., Konieczny and Pino-Perez 2002; Pigozzi 2006; Miller and Osherson 2008; Eckert and Klamler 2009; Hartmann et al. 2010; Lang et al. 2011), and quota rules with well-calibrated acceptance thresholds and various degrees of collective rationality (e.g., Dietrich and List 2007b; see also Nehring and Puppe 2010a).
The present paper contributes to the theory’s current ‘constructive’ effort by investigating a class of aggregation rules to be called scoring rules. The inspiration comes from classical scoring rules in preference aggregation theory. These rules generate collective preferences which rank each alternative according to the sum-total ‘score’ it receives from the group members, where the ‘score’ could be defined in different ways, leading to different classical scoring rules such as the Borda rule (see Smith 1973; Young 1975; Zwicker 1991, and for abstract generalizations Myerson 1995; Zwicker 2008; Conitzer et al. 2009; Pivato 2011b). In a general judgment aggregation framework, however, there are no ‘alternatives’; so our scoring rules are based on assigning scores to propositions, not alternatives. Nonetheless, our scoring rules are related to classical scoring rules, and generalize them, as will be shown.
The paradigm underlying our scoring rules—i.e., the maximization of total score of collective judgments—differs from standard paradigms in judgment aggregation, such as the premise-, conclusion- or distance-based paradigms. Nonetheless, it will turn out that several existing rules can be re-modelled as scoring rules, and can thus be ‘rationalized’ in terms of the maximization of total scores. Of course, the way scores are being assigned to propositions—the ‘scoring’—differs strongly across rules; for instance, the Kemeny rule and the premise-based rule can each be viewed as a scoring rule, but with respect to two very different scorings. This paper explores various plausible scorings. It uncovers the scorings which implicitly underlie several well-known aggregation rules, and suggests other scorings which generate novel aggregation rules. For instance, a particularly natural scoring, to be called reversal scoring, will lead to a new generalization of the Borda rule from preference aggregation to judgment aggregation. The problem of how to generalize the Borda rule has been a long-lasting open question in judgment aggregation theory. Recently, an interesting (so far incomplete) proposal was made by Zwicker (2011). Surprisingly, his and the present Borda generalizations are somewhat different, as detailed below.Footnote 1
Though large, the class of scoring rules is far from universal: some important aggregation rules fall outside this class (notably the mentioned rule approximating the majority judgments, proposed by Nehring et al. 2011). I will also investigate a natural generalization of scoring rules, to be called set scoring rules, which are based on assigning scores to entire judgment sets rather than single propositions (judgments). Such rules are examples of Zwicker’s (2008) ‘generalized scoring rules’ for an abstract aggregation problem whose inputs and outputs are arbitrary objects rather than judgment sets (see also Myerson 1995; Pivato 2011a).Footnote 2
After this introduction, Sect. 2 defines the general framework, Sect. 3 analyses various scoring rules, Sect. 4 goes on to analyse several set scoring rules, and Sect. 5 draws some conclusions about where we stand in terms of concrete aggregation procedures.
2 The framework, examples and interpretations
I now introduce the framework, following List and Pettit (2002) and Dietrich (2007).Footnote 3 We consider a set of n (\(\ge \)2) individuals, denoted \(N=\{1,\ldots ,n\}\). They need to decide which of certain interconnected propositions to ‘believe’ or ‘accept’.
The agenda The set \(X\) of propositions under consideration is called the agenda. It is subdivided into issues, i.e., pairs of a proposition and its negation, such as ‘it will rain’ and ‘it won’t rain’. Rationally, an agent accepts a proposition from each issue (‘completeness’), while respecting any logical interconnections between propositions (‘consistency’). We write ‘\(\lnot p\)’ for the negation of a proposition ‘\(p\)’, so that the agenda takes the form \(X=\{p,\lnot p,q,\lnot q,\ldots \}\), with issues \(\{p,\lnot p\}, \{q,\lnot q\}\), etc. It is worth defining the present notion of an agenda formally:
Definition 1
An agenda is a set \(X\) (of ‘propositions’) endowed with:
-
(a)
binary ‘issues’ \(\{p,p^{\prime }\}\) which partition \(X\) (where the members \(p\) and \(p'\) of an issue are the ‘negations’ of each other, written \(p=\lnot p^{\prime } \) and \(p^{\prime }=\lnot p\)),
-
(b)
interconnections, i.e., a notion of which subsets of \(X\) are consistent, or formally, a system \(\mathcal C \equiv \mathcal C _{X}\) of (‘consistent’) subsets.Footnote 4
A simple example is the agenda given by
where \(p\) and \(q\) are two atomic sentences, for instance ‘it rains’ and ‘it is cold’, and \(p\wedge q\) is their conjunction. The structure of the agenda—i.e., the issues and interconnections—is obvious, as it is directly inherited from logic. For instance, the set \(\{p,p\wedge q\}\) is consistent while the set \(\{\lnot p,p\wedge q\}\) is not.
Given an agenda \(X\), an individual’s judgment set is the set \(J\subseteq X\) of propositions he accepts. It is complete if it contains a member of each issue \(\{p,\lnot p\}\), and (fully) rational if it is complete and consistent. The set of all rational judgment sets is denoted by \(\mathcal J \equiv \mathcal J _{\mathrm{X}}\).
Under the above defnition of an agenda, the set \(\mathcal C \) of consistent sets is a primitive, while the set \(\mathcal{J }\) is derived from it. One could proceed the over way round, by using a slightly modified defnition of an agenda in which clause (b) is replaced by the following clause:
-
(b)
interconnections, i.e., a notion of which judgment sets are rational, or formally, a system \(\mathcal J \equiv \mathcal J _{\mathrm{X}} \ne \varnothing \) of (‘rational’) judgment sets \(J\subset X\), each containing exactly one member from any issue.Footnote 5
Here, \(\mathcal{J }\) is the primitive, and the system of consistent sets is defined as \(\mathcal{C } = \mathcal{C }_X = \{C \subseteq X : C \subseteq J\) for some \(J{\in }\, \mathcal{J }\}\). The main difference between the two ways to define an agenda is that under the second way the agenda – more precisely, its consistency notion — is automatically well-behaved, that is, satisfies the following regularity conditions (see Dietrich 2007):
-
C1:
no set \(\{p,\lnot p \}\) is consistent (self-entailment);
-
C2:
subsets of consistent sets are consistent (monotonicity);
-
C3:
\(\varnothing \) is consistent and each consistent set can be extended to a complete and consistent set (completability). Well-behavedness can be expressed equivalently by a single condition:
-
\(\mathcal{C } = \{C \subseteq J : J \in \mathcal{J }\} \ne \varnothing \), i.e., the consistent sets are the subsets of the fully rational sets.
-
An advantage of the second way to define an agenda is that well-behavedness – a common assumption of the theory up to date – comes for free and thus need not be added explicitly. An advantage of the first way is that it has no hidden assumptions, and lends itself to future relaxations of well-behavedness (for instance when studying judgment aggregation in non-monotonic logics).
Henceforth, let \(X\) be a given finite agenda with well-behaved interconnections (de-fined in any of the two ways). Notationally, a judgment set \(J\subseteq X\) is often abbreviated by concatenating its members in any order (so, \(p\lnot q\lnot r\) is short for \(\{p,\lnot q,\lnot r\}\)); and the negation-closure of a set \(Y \subseteq X\) is denoted
We now introduce the two lead examples of this paper, the first one being isomorphic to the previous example (1).
Example 1
The ‘doctrinal paradox agenda’ This is the agenda
where \(p, q\) and \(r\) are atomic sentences and where the interconnections are defined by classical logic relative to the external constraint \(r\leftrightarrow (p\wedge q).\) So, there are four rational judgment sets:
Example 2
The preference agenda For an arbitrary, finite set of alternatives \(A\), the preference agenda is defined as
where the negation of a proposition \(xPy\) is of course \(\lnot xPy = yPx\), and where logical interconnections are defined by the usual conditions of transitivity, asymmetry and connectedness, which define a strict linear order. Formally, to each binary relation \(\succ \) over \(A\) uniquely corresponds a judgment set, denoted \(J_\succ = \{xPy\in X : x \succ y\}\), and the set of all rational judgment sets is
Aggregation rules A (multi-valued) aggregation rule is a correspondence \(F\) which to every profile of ‘individual’ judgment sets \((J_{1},\ldots ,J_{n})\) (from some domain, usually \(\mathcal J ^{n}\)) assigns a set \(F(J_{1},\ldots ,J_{n})\) of ‘collective’ judgment sets. Typically, the output \(F(J_{1},\ldots ,J_{n})\) is a singleton set \(\{C\}\), in which case we identify this set with \(C\) and write \(F(J_{1},\ldots ,J_{n})=C\). If \(F(J_{1},\ldots ,J_{n})\) contains more than one judgment set, there is a ‘tie’ between these judgment sets. An aggregation rule is called single-valued or tie-free if it always generates a single judgment set. A standard (single-valued) aggregation rule is majority rule; it is given by
and generates inconsistent collective judgment sets for many agendas and profiles. If both individual and collective judgment sets are rational (i.e., in \(\mathcal J \)), the aggregation rule defines a correspondence \(\mathcal J ^{n}\rightrightarrows \mathcal J \), and in the case of single-valuedness a function \(\mathcal J ^{n}\rightarrow \mathcal J \).Footnote 6
Some thoughts about the model As an excursion for interested readers, let me add some considerations about the present model and its flexibility. Firstly, I mention three salient ways of specifying an agenda in practice. All three approaches could qualify broadly as ‘logical’:
-
Under the syntactic approach, the propositions are sentences of formal logic. The structure of the agenda—i.e., the issues \(\{p,\lnot p\}\) and the interconnections—need not be specified explicitly, as it is directly inherited from the logic: it is given by the logic’s negation symbol and consistency notion.Footnote 7 The logic needs to have the right expressive power to adequately render the group’s decision problem: one might use standard propositional logic, or standard predicate logic, or various modal or conditional logics (see Dietrich 2007). Many real-life agendas draw on non-standard logics by involving for instance modal operators or non-material conditionals. Fortunately, most relevant logics are well-behaved, i.e., satisfy the conditions C1–C3 (now read as conditions on sentences of the logic), so that the agenda is automatically well-behaved.
-
Under the semantic approach, the propositions are subsets of some fixed underlying set \(\Omega \) of possibilities or worlds. The structure of the agenda (the issues \(\{p,\lnot p\}\) and the interconnections) need again not be specified explicitly, as it is inherited from set theory: the negation of a proposition \(p\) is the complement \(\lnot p:=\Omega \backslash p\), and a set of propositions is consistent just in case its intersection is non-empty.Footnote 8 Such a semantic agenda is automatically well-behaved.Footnote 9
-
Under an algebraic (or abstract semantic) approach, the agenda is a subset of an underlying Boolean algebra.Footnote 10 The structure of the agenda (the issues \(\{p,\lnot p\}\) and the interconnections) is once again automatically inherited, this time from the Boolean algebra.Footnote 11 The agenda is automatically well-behaved.
Secondly, I mention an interpretational point (orthogonal to the question of whether one works with a syntactic, semantic, algebraic or other agenda). Under the standard interpretation, we are aggregating ‘judgments’, i.e., belief-type attitudes towards propositions. But one may re-interpret the nature of the attitude, so that judgment sets become desire sets, or hope sets, or normative approval sets, or intention sets, and so on—which leads to desire aggregation, or hope aggregation, and so on. In this case we still aggregate propositional attitudes, albeit not judgments. In a more radical departure, we may consider the aggregation of arbitrary individual properties (characteristics). Here the agenda contains not propositions which someone may or may not believe (or desire, or hope etc.), but properties which someone may or may not have or satisfy. For instance, the agenda might contain the properties of liking peace, being successful, and so on. Each individual \(i\) has some set of properties \(J_{i}\), and the goal is to derive a collective property set. This is the general property aggregation problem, distinct from the problem of aggregating propositional attitudes such as judgments.Footnote 12
The mathematics built on the model does not ‘know’ which kind of interpretation or application one has in mind. Nonetheless, interpretation and context matter, since the question of how to best aggregate and which axioms to require depends on it.
3 Scoring rules
Scoring rules are particular judgment aggregation rules, defined on the basis of a so-called scoring function. A scoring function—or simply a scoring—is a function \(s:X\times \mathcal J \rightarrow \mathbb R \) which to each proposition \(p\) and rational judgment set \(J\) assigns a number \(s_{J}(p)\), called the score of \(p\) given \(J\) and measuring how \(p\) performs (‘scores’) from the perspective of holding judgment set \(J\). As an elementary example, so-called simple scoring is given by:
so that all accepted propositions score 1, whereas all rejected propositions score 0. This and many other scorings will be analysed. Let us think of the score of a set of propositions as the sum of the scores of its members. So, the scoring \(s\) is extended to a function which (given the agent’s judgment set \(J\in \mathcal J \)) assigns to each set \(C\subseteq X\) the score
(In Sect. 4, we move to a generalized approach in which the score of a set \(C\) is a primitive and need not be additively derivable from scores of single propositions.)
A scoring \(s\) gives rise to an aggregation rule, called the scoring rule w.r.t. \(s\) and denoted \(F_{s}\). Given a profile \((J_{1},\ldots ,J_{n} )\in \mathcal J ^{n}\), this rule determines the collective judgments by selecting the rational judgment set(s) with the highest sum-total score across all judgments and all individuals:
By a scoring rule simpliciter we of course mean an aggregation rule which is a scoring rule w.r.t. some scoring. Different scorings \(s\) and \(s^{\prime }\) can generate the same scoring rule \(F_{s}=F_{s^{\prime }}\), in which case they are called equivalent. For instance, \(s\) is equivalent to \(s^{\prime }=2s\).Footnote 13
3.1 Simple scoring and the Kemeny rule
We first consider the most elementary definition of scoring, namely simple scoring (2). Table 2 illustrates the corresponding scoring rule \(F_{s}\) for the case of the agenda and profile of our doctrinal paradox example. The entries in Table 2 are derived as follows. First, enter the score of each proposition \((p,\lnot p,q,\ldots )\) from each individual (1, 2 and 3). Second, enter each individual’s score of each judgment set by taking the row-wise sum. For instance, individual 1’s score of \(pqr\) is \(1+1+1=3\), and his score of \(p\lnot q\lnot r\) is \(1+0+0=1\). Third, enter the group’s score of each proposition by taking the column-wise sum. For instance, the group’s score of \(p\) is \(1+1+0=2\). Finally, enter the group’s score of each judgment set, by taking either a vertical or a horizontal sum (the two give the same result), and add a star ‘*’ in the field(s) with maximal score to indicate the winning judgment set(s). For instance, the group’s score of \(pqr\) using a vertical sum is \(3+1+1=5\), and using a horizontal sum it is \(2+2+1=5\). Since the judgment sets \(pqr, p\lnot q\lnot r\) and \(\lnot pq\lnot r\) all have maximal group score, the scoring rule delivers a tie:
This is a tie between the premise-based outcome \(pqr\) and the conclusion-based outcomes \(p\lnot q\lnot r\) and \(\lnot pq\lnot r\). Were we to add more individuals, the tie would presumably be broken in one way or the other. In large groups, ties are a rare coincidence.
To link simple scoring to distance-based aggregation, suppose we measure the distance between two rational judgment sets by using some distance function (‘metric’) \(d\) over \(\mathcal J \).Footnote 14 The most common example is the Kemeny distance \(d=d_{\mathrm{Kemeny}}\), which can also be attributed to the statistician Kendall. It is defined as follows (where by a ‘judgment reversal’ I mean the replacement of an accepted proposition by its negation):
For instance, the Kemeny-distance between \(pqr\) and \(p\lnot q\lnot r\) (for our doctrinal paradox agenda) is 2.
Now the distance-based rule w.r.t. distance \(d\) is the aggregation rule \(F_{d}\) which for any profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) determines the collective judgment set(s) by minimizing the sum-total distance to the individual judgment sets:
The most popular example, the Kemeny rule \(F_{d_{\mathrm{Kemeny}}}\) (also referred to as the Hamming rule or the median rule), can be characterized as a scoring rule:
Proposition 1
The simple scoring rule is the Kemeny rule.
3.2 Classical scoring rules for preference aggregation
I now show that our scoring rules generalize the classical scoring rules of preference aggregation theory. Consider the preference agenda \(X\) for a given set of alternatives \(A\) of finite size \(k\). Classical scoring rules (such as the Borda rule) are defined by assigning scores to alternatives in \(A\), not to propositions \(xPy\) in \(X\). Given a strict linear order \(\succ \) over \(A\), each alternative \(x\in A\) is assigned a score \({ SCO}_{\succ }(x)\in \mathbb R \). The most popular example is of course Borda scoring, for which the highest ranked alternative in \(A\) scores \(k\), the second-highest \(k-1\), the third-highest \(k-2\), ..., and the lowest 1. Given a profile \((\succ _{1},\ldots ,\succ _{n})\) of individual preferences (strict linear orders), the collective ranks the alternatives \(x\in X\) according to their sum-total score \(\sum _{i\in N}{ SCO}_{\succ _{i}}(x)\). To translate this into the judgment aggregation formalism, recall that each strict linear order \(\succ \) over \(A\) uniquely corresponds to a rational judgment set \(J\in \mathcal J \) (given by \(xPy\in J\Leftrightarrow x\succ y\)); we may therefore write \({ SCO}_{J}(x)\) instead of \({ SCO}_{\succ }(x)\), and view the classical scoring \({ SCO}\) as a function of \((x,J)\) in \(A\times \mathcal J \). Formally, I define a classical scoring as an arbitrary function \({ SCO}:A\times \mathcal J \rightarrow \mathbb R \), and the classical scoring rule w.r.t. it as the judgment aggregation rule \(F\equiv F_{{ SCO}}\) for the preference agenda which for every profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) returns the rational judgment set(s) that rank an alternative \(x\) over another \(y\) whenever \(x\) has a higher sum-total score than \(y\):Footnote 15
Now, any given classical scoring \({ SCO}\) induces a scoring \(s\) in our (proposition-based) sense. In fact, there are two canonical (and, as we will see, equivalent) ways to define \(s\): one might define \(s\) either by
or, if one would like the lowest achievable score to be zero, by
(where the last equality assumes that \({ SCO}_{J}(x)>{ SCO}_{J}(y)\Leftrightarrow xPy\in J\) for all \(x, y\) and \(J\), a property that is so natural that we might have built it into the definition of a ‘classical scoring’ \(\textit{SCO}\)). This allows us to characterize classical scoring rules in terms of proposition-based rather than alternative-based scoring:
Proposition 2
In the case of the preference agenda (for any finite set of alternatives), every classical scoring rule is a scoring rule, namely one with respect to a scoring \(s\) derived from the classical scoring \({ SCO}\) via (3) or via (4).
3.3 Reversal scoring and a Borda rule for judgment aggregation
Given the agent’s judgment set \(J\), let us think of the score of a proposition \(p\in X\) as a measure of how ‘distant’ the negation \(\lnot p\) is from \(J\); so, \(p\) scores high if \(\lnot p\) is far from \(J\), and low if \(\lnot p\) is contained in \(J\). More precisely, let the score of a proposition \(p\) given \(J\in \mathcal J \) be the number of judgment reversals needed to reject \(p\), i.e., the number of propositions in \(J\) that must (minimally) be negated in order to obtain a consistent judgment set containing \(\lnot p\). So, denoting the judgment set arising from \(J\) by negating the propositions in a subset \(R\subseteq J\) by \(J_{\lnot R}=(J\backslash R)\cup \{\lnot r:r\in R\}\), so-called reversal scoring is defined by
For instance, a rejected proposition \(p\not \in J\) scores zero, since \(J\) itself contains \(\lnot p\) so that it suffices to negate zero propositions (\(R=\varnothing \)). An accepted proposition \(p\in J\) scores 1 if \(J\) remains consistent by negating \(p\, (R=\{p\})\), and scores more than 1 otherwise (\(R\supsetneq \{p\}\)). Table 3 illustrates reversal scoring for our doctrinal paradox example. For instance, individual 1’s judgment set \(pqr\) leads to a score of 2 for proposition \(p\), since in order for him to reject \(p\) he needs to negate not just \(p\) (as \(\lnot pqr\) is inconsistent), but also \(r\) (where \(\lnot pq\lnot r\) is consistent). The scoring rule delivers a tie between the judgment sets \(p\lnot q\lnot r\) and \(\lnot pq\lnot r\). This is a tie between two conclusion-based outcomes; the premise-based outcome \(pqr\) is rejected (unlike for simple scoring in Sect. 3.1).
The remarkable feature of reversal scoring rule is that it generalizes the Borda rule from preference to judgment aggregation. The Borda rule is initially only defined for the preference agenda \(X\) (for a given finite set of alternatives), namely as the classical scoring rule w.r.t. Borda scoring; see the last subsection. The key observation is that reversal scoring is intimately linked to Borda scoring:
Remark 1
In the case of the preference agenda (for any finite set of alternatives), reversal scoring \(s\) is given by (4) with \(\textit{SCO}\) defined as classical Borda scoring.
Let me sketch the simple argument—it should sound familiar to social choice theorists. Let \(s\) be reversal scoring, \(X\) the preference agenda for a set of alternatives \(A\) of size \(k<\infty \), and \(\textit{SCO}\) classical Borda scoring. Consider any \(xPy\in X\) and \(J\in \mathcal J \). If \(xPy\in X\backslash J\), then \(\lnot xPy=yPx\in J\), which implies \(s_{J}(xPy)=0\), as required by (4). Now suppose \(xPy\in J\). Clearly, \(\textit{SCO}_{J}(x)>\textit{SCO}_{J}(y)\). Consider the alternatives in the order \(\succ \) established by \(J\):
where \(x_{j}\) is the alternative with \(\textit{SCO}_{J}(x_{j})=j\). Step by step, we now move \(y\) up in the ranking, where each step consists in raising the position (score) of \(y\) by one. Each step corresponds to negating one proposition in \(J\), namely the proposition \(zPy\) where \(z\) is the alternative that is currently being ‘overtaken’ by \(y\). After exactly \(\textit{SCO}_{J}(x)-\textit{SCO}_{J}(y)\) steps, \(y\) has ‘overtaken’ \(x\), i.e., \(xPy\) has been negated. So, \(s_{J}(xPy)\) is at most \(\textit{SCO}_{J}(x)-\textit{SCO}_{J}(y)\). It is exactly \(\textit{SCO}_{J} (x)-\textit{SCO}_{J}(y)\), since, as the reader may check, no smaller number of judgment reversals allows \(y\) to ‘overtake’ \(x\) in the ranking.
Remark 1 and Proposition 2 imply that reversal scoring allows us to extend the Borda rule to arbitrary judgment aggregation problems:
Proposition 3
The reversal scoring rule generalizes the Borda rule, i.e., matches it in the case of the preference agenda (for any finite set of alternatives).
I note that one could use a perfectly equivalent variant of reversal scoring \(s\) which, in the case of the preference agenda, is related to classical Borda scoring \({ SCO}\) via (3) instead of (4):
Remark 2
Reversal scoring \(s\) is equivalent (in terms of the resulting scoring rule) to the scoring \(s^{\prime }\) given by
and in the case of the preference agenda (for any finite set of alternatives) this scoring is given by
with \(\textit{SCO}\) defined as classical Borda scoring.
For comparison, I now sketch Zwicker (2011) interesting approach to extending the Borda rule to judgment aggregation—let me call such an extension a ‘Borda-Zwicker’ rule. The motivation derives from a geometric characterization of Borda preference aggregation obtained by Zwicker (1991). Let me write the agenda as \(X=\{p_{1},\lnot p_{1},p_{2},\lnot p_{2} ,\ldots ,p_{m},\lnot p_{m}\}\), where \(m\) is the number of ‘issues’. Each profile gives rise to a vector \(\mathbf{v}\equiv (v_{1},\ldots ,v_{m})\) in \(\mathbb R ^{m}\) whose jth entry \(v_{j}\) is the net support for \(p_{j}\), i.e., the number of individuals accepting \(p_{j}\) minus the same number for \(\lnot p_{j}\). Now if \(X\) is the preference agenda for any finite set of alternatives \(A\), then each \(p_{j}\) takes the form \(xPy\) for certain alternatives \(x,y\in A\). Each preference cycle can be mapped to a vector in \(\mathbb R ^{m}\); for instance, if \(p_{1}=xPy, p_{2}=yPz\) and \(p_{3}=xPz\), then the cycle \(x\succ y\succ z\succ x\) becomes the vector \((1,1,-1,0,\ldots ,0)\in \mathbb R ^{m}\). The linear span of all vectors corresponding to preference cycles defines the so-called ‘cycle space’ \(\mathbf{V}_{cycle}\subseteq \mathbb R ^{m}\), and its orthogonal complement defines the ‘cocycle space’ \(\mathbf{V}_{cocycle}\subseteq \mathbb R ^{m}\). Let \(\mathbf{v}_{cocycle}\) be the orthogonal projection of \(\mathbf{v}\) on the cocycle space \(\mathbf{V}_{cocycle}\). Intuitively, \(\mathbf{v}_{cocycle}\) contains the ‘consistent’ or ‘acyclic’ part of \(\mathbf{v}\). The upshot is that the Borda outcome can be read off from \(\mathbf{v}_{cocycle}\): for each \(p_{j}=xPy\), the Borda group preference ranks \(x\) above (below) \(y\) if the jth entry of \(\mathbf{v}_{cocycle}\) is positive (negative). Zwicker’s strategy for extending the Borda rule to judgment aggregation is to define a subspace \(\mathbf{V}_{cycle}\) analogously for agendas other than the preference agenda; one can then again project \(\mathbf{v}\) on the orthogonal complement of \(\mathbf{V}_{cycle}\) and determine collective ‘Borda’ judgments according to the signs of the entries of this projection. This approach has proved successful for simple agendas, in which there is a natural way to define \(\mathbf{V}_{cycle}\). Whether the approach is viable for general agendas (i.e., whether \(\mathbf{V}_{cycle}\) has a useful general definition) seems to be open so far.Footnote 16
A Borda-Zwicker rule is not just constructed differently from a scoring rule in our sense, but, as I conjecture, it also cannot generally be remodelled as a scoring rule, since most interesting scoring rules use information that goes beyond the information contained in the profile’s ‘net support vector’ \(\mathbf{v}\in \mathbb R ^{m}\). (Even more does the required information go beyond the projection of \(\mathbf{v}\) on the orthogonal complement of \(\mathbf{V}_{cycle}\).)
In summary, there seem to exist two quite different approaches to generalizing Borda aggregation. One approach, taken by Zwicker, seeks to filter out the profile’s ‘inconsistent component’ along the lines of the just-described geometric technique. The other approach, taken here, seeks to retain the principle of score-maximization inherent in Borda aggregation (with scoring now defined at the level of propositions, not alternatives, as these do not exist outside the world of preferences). One might view the normative core of the scoring approach as being the use of the strength of someone’s judgments, i.e., the strength of acceptance of propositions, as measured by the score—just as Borda preference aggregation is sometimes interpreted as a way to incorporate the strength of someone’s preference between alternatives \(x\) and \(y\), as measured by the score of \(xPy\), i.e., the difference between \(x\)’s and \(y\)’s score.Footnote 17
3.4 A generalization of reversal scoring
Recall that the reversal score of a proposition \(p\) can be characterized as the distance by which one must deviate from the current judgment set in order to reject \(p\)—where ‘distance’ is understood as Kemeny-distance. It is natural to also consider other kinds of a distance. Relative to any given distance function \(d\) over \(\mathcal J \), one may define a corresponding scoring by
This provides us with a whole class of scoring rules, all of which are variants of our judgment-theoretic Borda rule. In the special case of the preference agenda, we thus obtain new variants of the classical Borda rule.
For instance, we could adopt Duddy and Piggins’ 2012 distance function, i.e., we could define \(d(J,J^{\prime })\) as the number of minimal consistent modifications needed to transform \(J\) into \(J^{\prime } \).Footnote 18 So, while Duddy and Piggins had introduced their distance in the context of distance-based aggregation to develop an alternative to the Kemeny rule, their distance can also be used in our context of (reversal) scoring rules to develop an alternative to Borda aggregation.
3.5 Scoring based on logical entrenchment
We now consider scoring rules which explicitly exploit the logical structure of the agenda. Let us think of the score of a proposition p (\(\in \)X) given the judgment set J (\(\in \mathcal J \)) as the degree to which \(p\) is logically entrenched in the belief system \(J\), i.e., as the ‘strength’ with which \(J\) entails \(p\). We measure this strength by the number of ways in which \(p\) is entailed by \(J\), where each ‘way’ is given by a particular judgment subset \(S\subseteq J\) which entails \(p\), i.e., for which \(S\cup \{\lnot p\}\) is inconsistent. If \(J\) does not contain \(p\), then no judgment subset—not even the full set \(J\)—can entail \(p\); so the strength of entailment (score) of \(p\) is zero. If \(J\) contains \(p\), then \(p\) is entailed by the judgment subset \(\{p\}\), and perhaps also by very different judgment subsets; so the strength of entailment (score) of \(p\) is positive and more or less high.
There are different ways to formalise this idea, depending on precisely which of the judgment subsets that entail \(p\) are deemed relevant. I now propose four formalizations. Two of them will once again allow us to generalize the Borda rule from preference to judgment aggregation. These generalizations differ from that based on reversal scoring in Sect. 3.3.
Our first, naive approach is to count each judgment subset which entails \(p\) as a separate, full-fledged ‘way’ in which \(p\) is entailed. This leads to so-called entailment scoring, defined by:
If \(p\not \in J\) then \(s_{J}(p)=0\), while if \(p\in J\) then \(s_{J} (p)\ge 2^{|X|/2-1}\) since \(p\) is entailed by at least all sets \(S\subseteq J\) which contain \(p\), i.e., by at least \(2^{|J|-1}=2^{|X|/2-1}\) sets. One might object that this definition of scoring involves redundancies, i.e., ‘multiple counting’. Suppose for instance \(p\) belongs to \(J\) and is logically independent of all other propositions in \(J\). Then \(p\) is entailed by several subsets \(S\) of \(J\)—all \(S\subseteq J\) which contain \(p\)—and yet these entailments are essentially identical since all premises in \(S\) other than \(p\) are irrelevant.
I now present three refinements of scoring (7), each of which responds differently to the mentioned redundancy objection. In the first refinement, we count two entailments of \(p\) as different only if they have no premise in common. This leads to what I call disjoint-entailment scoring, formally defined by:
In the mentioned case where \(p \ (\in J)\) is logically independent of all other propositions in \(J\), we now avoid ‘multiple counting’: \(s_{J}(p)\) is only 1, as one cannot find different pairwise disjoint judgment subsets entailing \(p\). For our doctrinal paradox agenda and profile, the scoring rule delivers a tie between the two conclusion-based outcomes \(p\lnot q\lnot r\) and \(\lnot pq\lnot r\), as illustrated in Table 4. For instance, individual 2 has judgment set \(p\lnot q\lnot r\), so that \(p\) scores 1 (it is entailed by \(\{p\}\) but by no other disjoint judgment subset), \(\lnot q\) scores 2 (it is disjointly entailed by \(\{\lnot q\}\) and \(\{p,\lnot r\}\)), \(\lnot r\) scores 2 (it is disjointly entailed by \(\{\lnot r\}\) and \(\{\lnot q\}\)), and all rejected propositions score zero (they are not entailed by any judgment subsets).
Disjoint-entailment scoring turns out to match reversal scoring for our doctrinal paradox agenda (check that Tables 3, 4 coincide), as well as for the preference agenda (as shown later). Is this pure coincidence? The general relationship is that the disjoint-entailment score of a proposition \(p\) is always at most the reversal score, as one may show.Footnote 19
While this refinement of naive entailment scoring (7) avoids ‘multiple counting’ by only counting entailments with pairwise disjoint sets of premises, the next two refinements use a different strategy to avoid ‘multiple counting’. The new strategy is to count only those entailments whose sets of premises are minimal—with minimality understood either in the sense that no premises can be removed, or in the sense that no premises can be logically weakened. To begin with the first sense of minimality, I say that a set minimally entails \(p \ (\in X\)) if it entails \(p\) but no strict subset of it entails \(p\), and I define minimal-entailment scoring by
If for instance \(p\) is contained in \(J\), then \(\{p\}\) minimally entails \(p\),Footnote 20 but strict supersets of \(\{p\}\) do not and are therefore not counted. For our doctrinal paradox agenda, this scoring happens to coincide with reversal scoring and disjoint-entailment scoring. Indeed, Table 3 resp. 4 still applies; e.g., for individual 2 with judgment set \(p\lnot q\lnot r, p \) still scores 1 (it is minimally entailed only by \(\{p\}\)), \(\lnot q\) still scores 2 (it is minimally entailed by \(\{\lnot q\}\) and by \(\{p,\lnot r\}\)), \(\lnot r\) still scores 2 (it is minimally entailed by \(\{\lnot r\}\) and by \(\{\lnot q\}\)), and all rejected propositions still score zero (they are not minimally entailed by any judgment subsets).
Scoring (9) is certainly appealing. Nonetheless, one might complain that it still allows for certain redundancies, albeit of a different kind. Consider the preference agenda with set of alternatives \(A=\{x,y,z,w\}\), and the judgment set \(J=\{xPy, yPz, zPw, xPz, yPw, xPw\} \ (\in \mathcal J )\). The proposition \(xPw\) is minimally entailed by the subset \(S=\{xPy,yPz,zPw\}\). While this entailment is minimal in the (set-theoretic) sense that we cannot remove premises, it is non-minimal in the (logical) sense that we can weaken some of its premises: if we replace \(xPy\) and \(yPz\) in \(S\) by their logical implication \(xPz\), then we obtain a weaker set of premises \(S^{\prime }=\{xPz,zPw\}\) which still entails \(xPw\). We shall say that \(S\) fails to ‘irreducibly’ entail \(xPw\), in spite of minimally entailing it. In general, a set of propositions is called weaker than another one (which is called stronger) if the second set entails each member of the first set, but not vice versa. A set \(S \ (\subseteq X)\) is defined to irreducibly (or logically minimally) entail \(p\) if \(S\) entails \(p\) and no subset of premises \(Y\subsetneq S\) can be weakened in this entailment (i.e., for no subset \(Y\subsetneq S\) there exists a weaker set \(Y^{\prime }\subseteq X\) such that \((S\backslash Y)\cup Y^{\prime }\) still entails \(p\)). Each irreducible entailment is a minimal entailment, as is seen by taking \(Y^{\prime }=\varnothing \).Footnote 21 In the previous example, the set \(\{xPy,yPz,zPw\}\) minimally, but not irreducibly entails \(xPw\), and the set \(\{xPz,zPw\}\) irreducibly entails \(xPw\). Irreducible-entailment scoring is naturally defined by
This scoring matches reversal scoring and both previous scorings in the case of our doctrinal paradox example: Table 3 resp. 4 still applies. But for many other agendas these scorings all deviate from one another, resulting in different collective judgments. As for the preference agenda, we have already announced the following result:
Proposition 4
Disjoint-entailment scoring (8) and irreducible-entailment scoring (10) match reversal scoring (5) in the case of the preference agenda (for any finite set of alternatives).
Propositions 3 and 4 jointly have an immediate corollary.
Corollary 1
The scoring rules w.r.t. scorings (8) and (10) both generalize the Borda rule, i.e., match it in the case of the preference agenda (for any finite set of alternatives).
3.6 Propositionwise scoring and a way to repair quota rules with non-rational outputs
We now consider a special class of scorings: propositionwise scorings. This will allow us to relate scoring rules to the well-known judgment aggregation rules called quota rules (Dietrich and List 2007b)—in fact, to ‘repair’ these rules by rendering their outcomes rational across all profiles.
I call scoring \(s\) propositionwise if the score of a proposition \(p\in X\) only depends on whether \(p\) is accepted, i.e., if \(s_{J}(p)=s_{K}(p)\) whenever \(J\) and \(K\) (in \(\mathcal J \)) both contain \(p\) or both do not contain \(p\). Equivalently, scoring is propositionwise just in case for each \(p\in X\) there is a pair of real numbers \(s_{+}(p),s_{-}(p)\) such that
Intuitively, \(s_{+}(p)\) is the score of an accepted proposition \(p\), and \(s_{-}(p)\) is the score of a rejected proposition \(p\). Typically, of course, \(s_{+}(p)>s_{-}(p)\). An example is simple scoring: there, \(s_{+}(p)=1\) and \(s_{-}(p)=0\).
How do propositionwise scoring rules behave? They derive a proposition \(p\)’s sum-total score ‘locally’, i.e., based only on people’s judgments about \(p\). This property stands in obvious analogy to a well-studied axiom on aggregation rules, namely the axiom of propositionwise or independent aggregation, which prescribes that the collective judgment about any given proposition \(p\) is derived ‘locally’, i.e., again based only on people’s judgments about \(p\). Can we therefore relate propositionwise scoring to independent aggregation? The paradigmatic independent aggregation rules are the quota rules.Footnote 22 A quota rule is a (single-valued) aggregation rule which is given by an acceptance threshold \(m_{p}\in \{1,\ldots ,n\}\) for each proposition \(p\in X\). The quota rule corresponding to the so-called threshold family \((m_{p})_{p\in X}\) is denoted \(F_{(m_{p})_{p\in X}}\) and accepts those propositions \(p\) which are supported by at least \(m_{p}\) individuals: for each profile \((J_{1} ,\ldots ,J_{n})\in \mathcal J ^{n}\),
Special cases are unanimity rule (given by \(m_{p}=n\) for all \(p\)), majority rule (given by the majority threshold \(m_{p}=\left\lceil (n+1)/2\right\rceil \) for all \(p\)), and more generally, uniform quota rules (given by a uniform threshold \(m_{p}\equiv m\) for all \(p\)). A uniform quota rules is also referred to as a supermajority rule if \(m\) exceeds the majority threshold, and a submajority rule if \(m\) is below the majority threshold. Note that supermajority rules may generate incomplete collective judgment sets, while submajority rule may accept both members of a pair \(p,\lnot p\in X\), a drastic form of inconsistency. If one wishes that exactly one member of each pair \(p,\lnot p\in X\) is accepted, the thresholds of \(p\) and \(\lnot p \) should be ‘complements’ of each other: \(m_{p}=n+1-m_{\lnot p}\).
A non-trivial question is how the acceptance thresholds would have to be set to ensure that the collective judgment set satisfies some given degree of rationality, such as to be (i) consistent, or (ii) deductively closed, or (iii) consistent and deductively closed, or even (iv) fully rational, i.e., in \(\mathcal J \). These questions have been settled [see Nehring and Puppe 2010a for (iv), and, subsequently, Dietrich and List 2007b for (i)–(iv)]. Unfortunately, for many agendas the thresholds would have to be set at ‘extreme’ and normatively unattractive levels. Worse, often no thresholds achieve (iv) (see Nehring and Puppe 2010a). For our doctrinal paradox agenda \(X=\{p,q,r\}^{\pm }\) only the extreme thresholds \(m_{p} =m_{q}=m_{r}=n\) and \(m_{\lnot p}=m_{\lnot q}=m_{\lnot r}=1\) achieve (iv), and for the preference agenda (with more than two alternatives) no thresholds achieve (iv).
Given that quota rules with ‘reasonable’ thresholds typically violate many of the conditions (i)–(iv), one may want to depart from ordinary quota rules by modifying (‘repairing’) them so that they always generate rational outputs. This can be done by using propositionwise scoring rules. Given an arbitrary quota rule with threshold family \((m_{p})_{p\in X}\), one can specify a propositionwise scoring such that the scoring rule replicates the quota rule whenever the quota rule generates a rational output, while ‘repairing’ the output otherwise. How must we calibrate \(s_{+}(p)\) and \(s_{-}(p)\) in order to achieve this? The idea is that individuals who accept \(p\) should contribute a positive score \(s_{+}(p)>0\), while those who reject \(p \) should contribute a negative score \(s_{-}(p)<0\). The absolute sizes of \(s_{+}(p)\) and \(s_{-}(p)\) should be calibrated such that the sum-total score of \(p\) becomes positive (helping the scoring rule to accept \(p\)) exactly when the quota rule accepts \(p\), i.e., when at least \(m_{p}\) individuals accept \(p\). Specifically, we set:
Intuitively, the higher the acceptance threshold \(m_{p}\) is, the smaller the positive contribution \(s_{+}(p)\) is and the larger the negative contribution \(s_{-}(p)\) is (in absolute value); hence, the more individuals accepting \(p\) are needed for \(p\)’s sum-total score to get positive, and the harder it becomes for the scoring rule to accept \(p\). This scoring does the intended job:
Proposition 5
For every threshold family \((m_{p})_{p\in X}\), the scoring rule w.r.t. scoring (12) matches the quota rule \(F_{(m_{p})_{p\in X}}\) at all profiles where the quota rule generates rational outputs (and still generates rational outputs at all other profiles).
As an example, consider our doctrinal paradox agenda \(X=\{p,q,r\}^{\pm }\) with \(n=3\) individuals, and suppose the quota rule departs only slightly from propositionwise majority voting: all propositions \(t\) in \(X\backslash \{\lnot r\}\) keep a majority threshold of \(m_{t}=2\), but \(\lnot r\) receives a unanimity threshold \(m_{\lnot r}=3\). This quota rule manages to never generate logically inconsistent collective judgment sets,Footnote 23 but does so at the expense of allowing collective incompleteness. Indeed, for our example profile, the quota rule returns the collective judgment set \(pq\), which is silent on the choice between \(r\) and \(\lnot r\). As illustrated in Table 5, the scoring rule w.r.t. (12) restores collective rationality by leading to the premise-based outcome \(pqr\). To read the table, note that scoring (12) is given by \(s_{+}(t)=2\) and \(s_{-}(t)=-2\) for all \(t\) in \(X\backslash \{\lnot r\}, s_{+}(\lnot r)=1\) and \(s_{-}(\lnot r)=-3\).
How does our scoring rule ‘repair’ those special quota rules which use a uniform threshold \(m\equiv m_{p}\ (p\in X)\), such as majority rule?
Remark 3
For a uniform threshold \(m\equiv m_{p}\), the scoring rule w.r.t. scoring (12) is the Kemeny rule, or equivalently, the simple scoring rule.
This remark follows from Proposition 1 and the fact that, for a uniform threshold \(m\equiv m_{p}\), scoring (12) is equivalent to simple scoring by footnote 13.
Finally, I note that the scoring rule w.r.t. (12) is not the only scoring rule which can ‘repair’ the quota rule \(F_{(m_{p})_{p\in X}}\)—though it might be the most plausible one, as long as we do not wish to introduce additional parameters. If, however, we are prepared to introduce additional parameters, scoring (12) can be generalized: for each \(p\in X\) let \(\alpha _{p}>0\) be a coefficient measuring how important it is that the scoring rule is faithful to the quota rule’s collective judgment on \(p\); and let scoring be defined by
The earlier scoring (12) is obviously a special case in which all \(\alpha _{p}\) are 1. Proposition 5 still holds for this generalized kind of propositionwise scoring. The scoring rule will tend to match the quota rule on propositions \(p\) with high importance coefficient \(\alpha _{p}\), while modifying (‘repairing’) the quota rule at propositions \(p\) with low \(\alpha _{p}\).
3.7 Premise- and conclusion-based aggregation
I have just mentioned the possibility of a differential treatment of propositions when ‘repairing’ a quota rule. This possibility is particularly salient in the popular context of premise- or conclusion-based aggregation.Footnote 24 One may indeed view the classical premise- and conclusion-based rules as two (rival) ways of repairing the simplest of all quota rules—majority rule—by privileging certain propositions over others, namely premise propositions or conclusion propositions, respectively.
Let me put this precisely. Consider majority voting, i.e., the quota rule with a uniform majority threshold \(m\equiv m_{p}\) (the smallest integer above \(n/2\)). To restore collective rationality, we again endow each proposition \(p\in X\) with a ‘coefficient of importance’, but now let this coefficient be determined by whether \(p\) has a ‘premise’ or ‘conclusion’ status. Formally, suppose the agenda is partitioned into two negation-closed sets, the set \(P\) of ‘premise propositions’ and the set \(X\backslash P\) of ‘conclusion propositions’. In the case of our doctrinal paradox agenda \(X=\{p,q,r\}^{\pm } \), we have \(P=\{p,q\}^{\pm }\). Each premise proposition \(p\in P\) has the importance coefficient \(\alpha _{p}\equiv \alpha _{\mathrm{premise}}\), and each conclusion proposition \(p\in X\backslash P\) has the importance coefficient \(\alpha _{p}\equiv \alpha _{\mathrm{conclusion}}\), for fixed parameters \(\alpha _{\mathrm{premise}},\alpha _{\mathrm{conclusion}}\ge 0\). In this scenario, the scoring (13) becomes equivalent (by footnote 13) to the scoring given by
By calibrating the two importance coefficients, we can influence the relative weights of premises and conclusions. If we give far more importance to premise propositions (\(\alpha _{\mathrm{premise}}\gg \alpha _{\mathrm{conclusion} }\)) or to conclusion propositions (\(\alpha _{\mathrm{conclusion}}\gg \alpha _{\mathrm{premise}}\)), the scoring rule reduces to the premise- or conclusion-based rule, respectively. To substantiate this claim, one needs to define both rules. For simplicity, I restrict attention to our doctrinal paradox agenda \(X=\{p,q,r\}^{\pm }\) with \(P=\{p,q\}^{\pm }\) (though more general \(X\) and \(P\) could be consideredFootnote 25). In this case, assuming for simplicity that the group size \(n\) is odd,
-
the premise-based rule is the aggregation rule which for each profile in \(\mathcal J ^{n}\) delivers the (unique) judgment set in \(\mathcal J \) containing each premise proposition accepted by a majority;
-
the conclusion-based rule is the aggregation rule which for each profile in \(\mathcal J ^{n}\) delivers the judgment set (or sets) in \(\mathcal J \) containing the conclusion proposition accepted by a majority.Footnote 26
These two rules have the following characterizations as scoring rules:
Remark 4
For our doctrinal paradox agenda \(X=\{p,q,r\}^{\pm }\) with set of premise propositions \(P=\{p,q\}^{\pm }\), and for an odd group size, the scoring rule w.r.t. scoring (14) is
-
the premise-based rule if and only if \(\alpha _{\mathrm{premise}}>(n-2)\alpha _{\mathrm{conclusion}}\),
-
the conclusion-based rule if and only if \(\alpha _{\mathrm{conclusion} }>\alpha _{\mathrm{premise}}=0\).
This result lets premise- and conclusion-based aggregation appear in a rather extreme light: each rule is based on somewhat unequal importance coefficients \(\alpha _{\mathrm{premise}}\) and \(\alpha _{\mathrm{conclusion}}\), deeming one type of proposition to be overwhelmingly more important than the other. It might therefore be interesting to consider more equilibrated values of the importance coefficients, so as to achieve a compromise between democracy at the premise level and democracy at the conclusion level.
4 Set scoring rules: assigning scores to entire judgment sets
An interesting generalization of scoring rules is obtained by assigning scores directly to entire judgment sets rather than single propositions. A set scoring function—or simply set scoring—is a function \(\sigma \) which to every pair of rational judgment sets \(C\) and \(J\) assigns a real number \(\sigma _{J}(C)\), the score of \(C\) given \(J\), which measures how well \(C\) performs (‘scores’) from the perspective of holding the judgment set \(J\). Formally, \(\sigma :\mathcal J \times \mathcal J \rightarrow \mathbb R \). The most elementary example, to be called naive set scoring, is given by
Any set scoring \(\sigma \) gives rise to an aggregation rule \(F_{\sigma }\), the set scoring rule (or generalized scoring rule) w.r.t. \(\sigma \), which for each profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) selects the collective judgment set(s) \(C\) in \(\mathcal J \) having maximal sum-total score across individuals:
An aggregation rule is a set scoring rule simpliciter if it is the set scoring rule w.r.t. some set scoring \(\sigma \). Set scoring rules generalize ordinary scoring rules, since to any ordinary scoring \(s\) corresponds a set scoring \(\sigma \), given by
and the ordinary scoring rule w.r.t. \(s\) coincides with the set scoring rule w.r.t. \(\sigma \).
4.1 Naive set scoring and plurality voting
The plurality rule is the aggregation rule \(F\) which for every profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) declares the most often submitted judgment set(s) as the collective judgment set(s):
This rule is of course normatively questionable;Footnote 27 but it deserves our attention, if only because of its simplicity and the recognized importance of plurality voting in social choice theory more broadly. The plurality rule can be construed as a set scoring rule:
Remark 5
The naive set scoring rule is the plurality rule.
4.2 Distance-based set scoring
Set scoring rules generalize distance-based aggregation. Given an arbitrary distance function \(d\) over \(\mathcal J \) (not necessarily the Kemeny-distance), all that is needed is to consider what I call distance-based set scoring, defined by
So, \(C\) scores high if it is close to the judgment set held, \(J\). This renders sum-score-maximization equivalent to sum-distance-minimization:
Remark 6
For every given distance function over \(\mathcal J \), the distance-based set scoring rule is the distance-based rule.
So, all distance-based rules can be modelled as set scoring rules (but not vice versaFootnote 28). As an example, consider the so-called discrete distance,Footnote 29 defined by
Here, distance-based set scoring (16) is equivalent to naive set scoring (15), since the two differ only by a constant (of one). So, joining Remarks 5 and 6, we may view the plurality rule either as the naive set scoring rule or as the discrete-distance-based rule.
4.3 Averaging rules
Given an ordinary scoring \(s\), we have so far aimed for collective judgments with a high total score. But this is not the only plausible aim or approach. We now turn to an altogether different approach. Rather than using \(s\) to assign scores only from each individual’s perspective, we now care about how propositions score under the collective judgment set. Instead of wanting the collective judgments to achieve the highest total score from individuals, we now want them to resemble the ‘average individual judgments’ in the sense that the collective judgments should lead (approximately) to the same scores of propositions as the individual judgments do on average. In short, any proposition \(p\)’s collective score should be (approximately) \(p\)’s average individual score. This approach has its own, rather different intuitive appeal. But is it really totally different? As will turn out, aggregation rules which follow this approach—I call them ‘averaging rules’ as opposed to ‘scoring rules’—can be viewed as a particular kind of set scoring rules. This result is essentially a special case of a powerful precursor result by Zwicker (2008), as Marcus Pivato kindly pointed out to me. A comparison with Zwicker (2008) is given at the end of this subsection.
Given an ordinary scoring \(s\), we can represent judgment sets in \(\mathcal J \) as vectors in \(\mathbb R ^{X}\), by identifying each judgment set \(J\) in \(\mathcal J \) with its score vector, i.e., the vector in \(\mathbb R ^{X}\) whose \(p^{\mathrm{th}}\) component is the score of \(p, s_{J} (p)\).Footnote 30 The score vector corresponding to \(J\in \mathcal J \) is denoted \(J^{s}\equiv (s_{J}(p))_{p\in X}\in \mathbb R ^{X}\). Having represented judgment sets as vectors of numbers, we can apply standard algebraic and geometric operations, such as adding judgment sets, taking their average, or measuring their distance—where, of course, sums or averages of (score vectors of) judgment sets in \(\mathcal J \) may be ‘infeasible’, i.e., not correspond to any judgment set in \(\mathcal J \).
The averaging rule w.r.t. scoring \(s\) is defined as the aggregation rule \(F\) which for every profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) chooses the collective judgment set(s) whose score vector comes closest to the group’s average score vector \(\frac{1}{n}\sum _{i\in N}J_{i}^{s}\) in the sense of Euclidean distance in \(\mathbb R ^{X}\):
Viewed geometrically as an operation in \(\mathbb R ^{X}\), the collective score vector is the projection of the average score vector \(\frac{1}{n}\sum _{i} J_{i}^{s}\) on the set \(\mathcal J ^{s}\equiv \{J^{s}:J\in \mathcal J \}\subseteq \mathbb R ^{X}\) of feasible score vectors.Footnote 31
As an illustration, consider once again reversal scoring for our doctrinal paradox example. Table 6 reports the score vector of each judgment set (including the one not submitted by any individual), and its distance to the group’s average score vector. By minimizing this distance, the rule delivers a tie between the two conclusion-based outcomes \(p\lnot q\lnot r\) and \(\lnot pq\lnot r\). The premise-based outcome \(pqr\) looks worse than ever: it is even farther from the average than the never-submitted outcome \(\lnot p\lnot q\lnot r\).
Note that we now have two rival ways of aggregating based on a scoring \(s\): the scoring rule and the averaging rule. Can any connection be established? In fact, the averaging rule can be construed as a set scoring rule, namely in virtue of the set scoring given by
Here, \(C\) is taken to score high if it is close to \(J\) in terms of the squared Euclidean distance of score vectors.
Proposition 6
For any scoring \(s\), the averaging rule w.r.t. \(s\) is the set scoring rule w.r.t. set scoring (17).
As an application, let \(s\) be simple scoring (2). Here, the set scoring (17) is expressible as an increasing affine transformation of the set scoring corresponding to simple scoring, i.e., of the set scoring \(\sigma ^{\prime }\) given byFootnote 32
So, the set scoring rule \(F_{\sigma }\) coincides with the simple scoring rule \(F_{s}\), and hence with the Kemeny rule \(F_{d_{\mathrm{Kemeny}}}\) by Proposition 1. Thus, as a corollary of Propositions 1 and 6, the Kemeny rule can be characterized not just as a scoring rule but also as an averaging rule, both times using the same scoring:
Corollary 2
The Kemeny rule is both the scoring rule and the averaging rule w.r.t. simple scoring.
Our averaging rules are special cases of Zwicker’s (2008) mean proximity rules. Like an averaging rule, a mean proximity rule represents each possible vote as well as each possible output as a vector of characteristics (real numbers), and determines the winning output(s) by minimizing the distance—in that vector representation—to the average vote. In our case, this vector is \(\left| X\right| \)-dimensional and contains the support (score) given to each proposition in \(X\). In Zwicker’s more general case, the vector could have any dimensionality and could contain any sorts of characteristics. Moreover, the votes need not be judgment sets, but could for instance be political candidates, characterized, say, by a three-dimensional vector containing age, number of pre-election speeches, and political orientation on a left-right spectrum. One may therefore view our averaging rules as a concrete way to implement Zwicker’s general approach inside judgment aggregation theory: we offer a concrete method of choosing the vector representation of votes, which is left open in Zwicker’s approach.Footnote 33 Alternative vector representations are of course also imaginable.
4.4 Probability-based set scoring
I close the analysis by taking a brief (skippable) excursion into an important, but different approach to judgment aggregation: the epistemic or truth-tracking approach. In this approach, each proposition \(p\in X\) is taken to have an objective, but unknown truth value (‘true’ or ‘false’), and the goal of aggregation is to track the truth, i.e., to generate true collective judgments.Footnote 34 The truth-tracking perspective has a long history elsewhere in social choice theory (e.g., Condorcet 1785; Grofman et al. 1983; Austen-Smith and Banks 1996; Dietrich 2006b; Pivato 2011a); but within judgment aggregation theory specifically, rather little work has been done on the epistemic side (e.g., Bovens and Rabinowicz 2006; List 2005; Bozbay et al. 2011).
The epistemic approach warrants the use of particular set scoring rules. To show this, I import standard statistical estimation techniques (such as maximum-likelihood estimation), following the path taken by other authors in the context of preference aggregation (e.g., Young 1995) and other aggregation problems (e.g., Dietrich 2006b; Pivato 2011a). My goal is to give no more than a brief introduction to what could be done. The results given below are essentially variants of existing results; see in particular Pivato (2011a).Footnote 35
For each combination \((J_{1},\ldots ,J_{n},T)\in \mathcal J ^{n}\times \mathcal J \) of \(n+1\) judgment sets, let \(\Pr (J_{1},\ldots ,J_{n},T) >0\) measure the probability that people submit the profile \((J_{1},\ldots ,J_{n})\) and the set of true propositions is \(T\), where of course \(\sum _{(J_{1},\ldots ,J_{n} ,T)\in \mathcal J ^{n}\times \mathcal J } \Pr (J_{1},\ldots ,J_{n},T)=1\). From this joint probability function we can, as usual, derive various marginal and conditional probabilities, such as the probability that the truth is \(T\in \mathcal J , \Pr (T)=\sum _{(J_{1},\ldots ,J_{n})\in \mathcal J ^{n}}\Pr (J_{1},\ldots , J_{n},T)\), the probability that the profile is \((J_{1} ,\ldots ,J_{n}), \Pr (J_{1},\ldots ,J_{n})=\sum _{T\in \mathcal J }\Pr (J_{1} ,\ldots ,J_{n}, T)\), the conditional probability \(\Pr (T|J_{1},\ldots ,J_{n} )=\frac{\Pr (J_{1},\ldots ,J_{n},T)}{\Pr (J_{1},\ldots ,J_{n})}\) (called the posterior probability of \(T\) given the ‘data’ \(J_{1},\ldots ,J_{n}\)), and the conditional probability \(\Pr (J_{1},\ldots ,J_{n}|T)=\frac{\Pr (J_{1} ,\ldots ,J_{n},T)}{\Pr (T)}\) (called the likelihood of the ‘data’ \(J_{1},\ldots ,J_{n}\) given \(T\)).
The maximum-likelihood rule is the aggregation rule \(F:\mathcal J ^{n}\rightrightarrows \mathcal J \) which for each profile \((J_{1},\ldots ,J_{n} )\in \mathcal J ^{n}\) defines the collective judgments such that their truth would make the observed profile (‘data’) maximally likely:
The maximum-posterior rule is the aggregation rule \(F:\mathcal J ^{n}\rightrightarrows \mathcal J \) which for each profile \((J_{1},\ldots ,J_{n} )\in \mathcal J ^{n}\) defines the collective judgments such that they have maximal posterior probability of truth conditional on the observed profile (‘data’):
Both of these rules correspond to well-established statistical estimation procedures.
Let us now make two standard, but restrictive assumptions on probabilities. We assume that voters are ‘independent’ and ‘equally competent’ (in analogy to the assumptions of Condorcet’s classical jury theoremFootnote 36). Formally, for every \(T\in \mathcal J \),
-
(IND)
the individual judgment sets are independent conditional on \(T\) being the true judgment set, i.e., \(\Pr (J_{1},\ldots ,J_{n}|T)=\Pr (J_{1} |T)\cdots \Pr (J_{n}|T)\) for all \(J_{1},\ldots ,J_{n}\in \mathcal J \) (‘independence’)
-
(COM)
for each \(J\in \mathcal J \), each individual has the same probability, denoted \(\Pr (J|T)\), of submitting the judgment set \(J\) conditional on \(T\) being the true judgment set (‘equal competence’).
Condition (COM) in particular implies that individuals have the same (conditional) probability of holding the true judgment set; but nothing is assumed about the size of this probability of ‘getting it right’. The just-defined aggregation rules turn out to be set scoring rules in virtue of defining the score of \(T\in \mathcal J \) given \(J\in \mathcal J \) by, respectively,
Proposition 7
If voters are independent (IND) and equally competent (COM), then
5 Concluding remarks
I hope to have convinced the reader that scoring rules, and more generally set scoring rules, form interesting positive solutions to the judgment aggregation problem. They for instance allow us to generalize Borda aggregation to judgment aggregation (the simplest method being to use reversal scoring). Figure 1 summarizes where we stand, by depicting different classes of rules (scoring rules, set scoring rules, and distance-based rules) and positioning several concrete rules (such as the Kemeny rule).

A map of judgment aggregation possibilities
While the positions of most rules in Fig. 1 have been established above or follow easily, a few positions are of the order of conjectures. This is so for the placement of our Borda generalization outside the class of distance-based rules.Footnote 37
Though several old and new aggregation rules are scoring rules (or at least set scoring rules), there are important counterexamples. One counterexample is the mentioned rule introduced by Nehring et al. (2011) (the so-called Condorcet-admissibility rule, which generates rational judgment set(s) that ‘approximate’ the majority judgment set). Other counterexamples are non-anonymous rules (such as rules prioritizing experts), and rules that return boundedly rational collective judgments (such as rules returning incomplete but still consistent and deductively closed judgments). The last two kinds of counterexamples suggest two generalizations of the notion of a scoring rule. Firstly, scoring might be allowed to depend on the individual; this leads to ‘non-anonymous scoring rules’. Secondly, the search for a collective judgment set with maximal total score might be done within a larger set than the set \(\mathcal J \) of fully rational judgment sets (such as the set of consistent but possibly incomplete judgment sets); this leads to ‘boundedly rational scoring rules’. The same generalizations could of course be made for set scoring rules.
Many challenges lie ahead of us. For instance, it would be interesting to characterize scoring rules and set scoring rules by some salient axiomatic properties.Footnote 38 And, in the epistemic context of searching for objectively ‘true’ or ‘correct’ judgments, one might give a maximum-likelihood rationalization of (set) scoring rules, by proving that they are precisely the aggregation rules which generate maximum-likelihood estimators of the truth relative to some probability model from a suitable class. Clearly, the paper raises more questions than it answers.
Notes
Conal Duddy and Ashley Piggins also have independent work in progress on ‘generalizing Borda’, and I learned from Klaus Nehring that he had ideas similar to those in the present paper.
If the inputs and outputs of that aggregation problem are taken to be judgment sets, then Zwicker’s ‘generalized scoring rules’ become our set scoring rules (suitably translated into Zwicker’s setting of an anonymous variable population).
To be precise, I use a slimmer variant of their models, since the logic in which propositions are formed is not explicitly part of the model.
Algebraically, the agenda is thus the structure \((X,\mathcal I ,\mathcal C )\) (where \(\mathcal I \) is the partition into issues), or alternatively the structure \((X,\lnot ,\mathcal C )\). To see why the issues and the negation operator are interdefinable, note that we could alternatively start with an operator \(\lnot \) on \(X\) satisfying \(\lnot p\ne p=\lnot \lnot p\), and then define the issues as the pairs \(\{p,\lnot p\}\).
So, algebraically speaking, the agenda is the structure \((X,\mathcal I ,\mathcal J )\) instead of \((X,\mathcal I ,\mathcal C )\) (where \(\mathcal I \) is the partition of \(X\) into issues, replaceable by the negation operator \(\lnot \) on \(X\)).
More generally, dropping the requirement of collective rationality, we have a correspondence \(\mathcal J ^{n}\rightrightarrows 2^{X}\), where \(2^{X}\) is the set of all judgment sets, rational or not. As usual, I write ‘\(\rightrightarrows \)’ instead of ‘\(\rightarrow \)’ to indicate a multi-function.
Formally, the agenda \(X\) is any set of logical sentences which is partitionable into pairs containing a sentence and its negation. These pairs define the issues. (We have presupposed that the logic includes the negation symbol, as all interesting logics do.)
Formally, the agenda \(X\) is any set of subsets of \(\Omega \) such that \(p\in X\Rightarrow \Omega \backslash p\in X\).
Nehring and Puppe’s (2010a) property spaces are essentially semantically defined agendas.
A Boolean algebra is a distributive lattice \(\mathcal L \) (with its operations of join and meet) in which there exists a top element \(\intercal \) (tautology) and a bottom element \(\perp \) (contradiction) and in which every element \(p\) has a negation/complement (i.e., an element whose join with \(p\) is \(\intercal \) and whose meet with \(p\) is \(\perp \)). An important example is a concrete Boolean algebra \(\mathcal L \subseteq 2^{\Omega }\) (for an underlying set of worlds \(\Omega \)), in which the join is given by the union, the meet by the intersection, the top by \(\Omega \), the bottom by \(\varnothing \), and the negation by the set-theoretic complement. In this case, the algebraic approach reduces to the standard semantic approach. Another example is the Boolean algebra generated from a logic, i.e., the set of sentences modulo logical equivalence (where the logic includes classical negation and conjunction, which induce the algebra’s join, meet and complement operations).
Formally, the agenda \(X\) is any subset of the Boolean algebra which is closed under Boolean-algebraic negation/complementation (see footnote 10).
Property aggregation raises the question of what it means for the collective to ‘have’ a property. Presumably, collective properties are something quite different from individual properties, just as collective judgments (or desires, hopes, \(\ldots \)) do not have the same status as individual ones. More generally, one may of course doubt the meaningfulness and relevance of group attributes. From a behaviourist perspective, the two ‘Humean’ collective attitudes—group beliefs (judgments) and group desires (preferences)—can be given meaning based on group behaviour, at least in principle. From my own (non-behaviourist) perspective, all sorts of non-standard group attributes can be meaningful and relevant, despite possibly being underdetermined by group action. But even if such group attributes are deemed meaningless or irrelevant, one may re-interpret them as being no more than summaries of the group members’ attributes (rather than attributes of any separate group agent).
More generally, certain increasing transformations have no effect. As one may show, scorings \(s\) and \(s^{\prime }\) are equivalent (i.e., \(F_{s}=F_{s^{\prime }}\)) whenever there are coefficients \(a>0\) and \(b_{p}\in \mathbb R \, (p\in X)\) with \(b_{p}=b_{\lnot p}\) for all \(p\in X\) such that \(s^{\prime }\) is given by \(s_{J}^{\prime }(p)=as_{J} (p)+b_{p}\).
A distance function or metric over \(\mathcal J \) is a function \(d:\mathcal J \times \mathcal J \rightarrow [0,\infty )\) satisfying three conditions: for all \(J,K,L\in \mathcal J \), (i) \(d(J,K)=0\Leftrightarrow J=K\), (ii) \(d(J,K)=d(K,J)\) (‘symmetry’), and (iii) \(d(J,L)\le d(J,K)+d(K,L)\) (‘triangle inequality’).
A technical difference between the standard notion of a scoring rule in preference aggregation theory and our judgment-theoretic rendition of it arises when there happen to exist distinct alternatives with identical sum-total score. In such cases, the standard scoring rule returns collective indifferences, whereas our \(F_{{ SCO}}\) returns a tie between strict preferences. From a formal perspective, however, the two definitions are equivalent, since to any weak order corresponds the set (tie) of all strict linear orders which linearize the weak order by breaking its indifferences (in any cycle-free way). The structural asymmetry between input and output preferences of scoring rules as defined standardly (i.e., the possibility of indifferences at the collective level) may have been one of the obstacles—albeit only a small, mainly psychological one—for importing scoring rules and Borda aggregation into judgment aggregation theory.
One might at first be tempted to generally define \(\mathbf{V}_{cycle}\) as the linear span of those vectors which correspond to the agenda’s minimal inconsistent subsets. Unfortunately, this span is often the entire space \(\mathbb R ^{m}\), an example for this being our doctrinal paradox agenda.
By contrast, Condorcet’s rule of pairwise majority voting only cares about whether or not someone prefers an alternative over another, without attempting to extract strength-of-preference information from the person’s full preference relation. It is of course notoriously controversial whether strength or intensity of preference is a permissible concept—and even if it is, whether the score of \(xPy\) is an adequate proxy of the strength to which \(x\) is preferred to \(y\). The ordinalist approach takes a sceptical stance here. Note however that Borda aggregation can be defended for reasons unrelated to strength of preference. For instance, its axiomatic characterizations offer possible normative defences.
Judgment sets \(J,J^{\prime }\in \mathcal J \) are minimal consistent modifications of each other if the set \(S=J\backslash J^{\prime }\) of propositions in \(J\) which need to be negated to transform \(J\) into \(J^{\prime }\) is non-empty and minimal (i.e., \(J\) couldn’t have been transformed into a consistent set by negating only a strict non-empty subset of \(S\)). For our doctrinal paradox agenda, the judgment sets \(pqr\) and \(p\lnot q\lnot r\) are minimal consistent modifications of each other, and hence have Duddy–Piggins-distance of 1.
The reason is that, given \(m\) mutually disjoint judgment subsets which each entail \(p\), the reversal score of \(p\) is at least \(m\) since one must negate at least one proposition from each of these \(m\) sets in order to consistently reject \(p\).
Assuming that \(p\) is not a tautology, i.e., that \(\{\lnot p\}\) is consistent. (Otherwise, \(\varnothing \) minimally entails \(p\).)
Assuming \(X\) contains no tautology, i.e., no \(p\) such that \(\{\lnot p\}\) is inconsistent.
They are the only independent rules which are anonymous, monotonic and unanimity-preserving.
This follows from Nehring and Puppe’s (2010) intersection property, generalized to possibly incomplete collective judgment sets (Dietrich and List 2007b).
Our analysis generalizes easily to any \(X\) and \(P\) such that (i) the premise propositions in \(P\) are logically independent, and (ii) complete judgments across the premise propositions in \(P\) uniquely determine the judgments on the conclusion propositions in \(X\backslash P\).
In the literature, the conclusion-based procedure is usually taken to be silent on the premises, i.e., to return an incomplete judgment set not in \(\mathcal J \). I have replaced this silence by a tie between all compatible judgments on the premise propositions.
It ignores the internal structure of judgment sets, hence ‘throws away’ much information.
In trying to re-model an arbitrary set scoring rule \(F_{\sigma }\) as a distance-based rule, one might be tempted to define the ‘distance’ between \(J \) and \(J^{\prime }\) as \(d_{\sigma }(J,J^{\prime } ):=\sigma _{J}(J)-\sigma _{J}(J^{\prime })\). If \(d_{\sigma }\) turns out to define a proper distance function (see fn. 14), then we obtain a distance-based rule \(F_{d_{\sigma }}\), which coincides with the set scoring rule \(F_{\sigma }\). But for many plausible set scorings \(\sigma , d_{\sigma }\) has little in common with a distance function, violating up to all three axioms, notably symmetry and the triangle inequality.
This metric derives its name from the fact that it induces the discrete topology on whatever set it is defined on (such as \(\mathbb R \) instead of \(\mathcal J \)).
This identification is one-to-one as long as the scoring has the (very plausible) property that \(s_{J}(p)>s_{J}(\lnot p)\) whenever \(p\in J\).
Formally, \(F(J_{1},\ldots ,J_{n})^{s}=\hbox {PROJ}_\mathcal{J ^{s}}(\frac{1}{n}\sum _{i}J_{i}^{s})\), where the projection of \(x\in \mathbb R ^{X}\) on \(Y\subseteq \mathbb R ^{X}\) is defined as \(\hbox {PROJ}_{Y}(x):={\arg \!\min }_{y\in Y}\left\| y-x\right\| \).
Since \(\sigma _{J}(C)=-\left( \sqrt{\left| C\bigtriangleup J\right| }\right) ^{2}=-\left| C\bigtriangleup J\right| =-2\left| C\backslash J\right| =-2\left( \left| C\right| -\left| C\cap J\right| \right) =-\left| X\right| +2\left| C\cap J\right| \).
Zwicker’s Theorem 4.2.1 (more precisely, its proof) essentially implies our Proposition 6 after some translation work.
The epistemic perspective is usually contrasted with the procedural perspective, which takes the goal of aggregation to be to generate collective judgments which reflect the individuals’ judgments in a procedurally fair way. To illustrate the contrast between the two perspectives, suppose that all individuals hold the same judgment set \(J\). Then \(J\) is clearly the right collective judgment set from the perspective of procedural fairness. But from an epistemic perspective, all depends on whether people’s unanimous endorsement of \(J\) is sufficient evidence for \(J\) being true.
The classical Condorcet jury theorem is essentially concerned with a simple judgment aggregation problem with a binary agenda \(X=\{p,\lnot p\}\).
For technical correctness, I also note two details about how to read Fig. 1. First, for trivial agendas, such as a single-issue agenda \(X=\{p,\lnot p\}\), several rules of course become equivalent, and distinctions drawn in
Fig. 1 disappear. More precisely, by positioning a rule outside a class of rules (e.g., by positioning plurality rule outside the class of scoring rules), I am of course not implying that for all agendas the rule does not belong to the class, but that for some (in fact, most) agendas this is so. Second, in placing propositionwise scoring rules among the distance-based rules, I made a very plausible restriction: \(s_{+}(p)>s_{-}(p)\) for each \(p\in X\).
References
Austen-Smith D, Banks J (1996) Information aggregation. Rationality, and the Condorcet Jury Theorem. Am Political Sci Rev 90:34–45
Bovens L, Rabinowicz W (2006) Democratic answers to complex questions: an epistemic perspective. Synthese 150(1):131–153
Bozbay I, Dietrich F, Peters H (2011) Judgment aggregation in search for the truth. Working paper, London School of Economics
Condorcet Marquis de (1785) Essai sur l’application de l’analyse á la probabilité des décisions rendues á la pluralité des voix
Conitzer V, Rognlie M, Xia L (2009) Preference functions that score rankings and maximum likelihood estimation. IJCAI’09 Proceedings of the 21st international jont conference on Artifical intelligence, Morgan Kaufmann Publishers Inc. San Francisco, pp 109–115
Dietrich F (2006a) Judgment aggregation: (im)possibility theorems. J Econ Theory 126(1):286–298
Dietrich F (2006b) General representation of epistemically optimal procedures. Soc Choice Welf 26(2):263–283
Dietrich F (2007) A generalised model of judgment aggregation. Soc Choice Welf 28(4):529–565
Dietrich F (2010) The possibility of judgment aggregation on agendas with subjunctive implications. J Econ Theory 145(2):603–638
Dietrich F, List C (2007a) Arrow’s theorem in judgment aggregation. Soc Choice Welf 29(1):19–33
Dietrich F, List C (2007b) Judgment aggregation by quota rules: majority voting generalized. J Theor Politics 19(4):391–424
Dietrich F, List C (2010) Majority voting on restricted domains. J Econ Theory 145(2):512–543
Dietrich F, Mongin P (2010) The premise-based approach to judgment aggregation. J Econ Theory 145(2):562–582
Dokow E, Holzman R (2010) Aggregation of binary evaluations. J Econ Theory 145:495–511
Duddy C, Piggins A (2012) A measure of distance between judgment sets. Soc Choice Welf 39:855–867
Eckert D, Klamler C (2009) A geometric approach to paradoxes of majority voting: from Anscombe’s paradox to the discursive dilemma with Saari and Nurmi. Homo Oeconomicus 26:471–488
Grofman B, Owen G, Feld SL (1983) Thirteen theorems in search of the truth. Theory Decis 15:261–278
Hartmann S, Pigozzi G, Sprenger J (2010) Reliable methods of judgment aggregation. J Log Comput 20:603–617
Konieczny S, Pino-Perez R (2002) Merging information under constraints: a logical framework. J Log Comput 12:773–808
Kornhauser LA, Sager LG (1986) Unpacking the court. Yale Law J 96(1):82–117
Lang J, Pigozzi G, Slavkovik M, van der Torre L (2011) Judgment aggregation rules based on minimization. Proceedings of the 13th conference on the theoretical aspects of rationality and knowledge (TARK XIII), ACM, pp 238–246
List C (2004) A model of path dependence in decisions over multiple propositions. Am Political Sci Rev 98(3):495–513
List C (2005) The probability of inconsistencies in complex collective decisions. Soc Choice Welf 24(1):3–32
List C, Pettit P (2002) Aggregating sets of judgments: an impossibility result. Econ Philos 18(1):89–110
List C, Polak B (eds) (2010) Symposium on judgment aggregation. J Econ Theory 145(2)
Miller MK, Osherson D (2008) Methods for distance-based judgment aggregation. Soc Choice Welf 32(4):575–601
Myerson RB (1995) Axiomatic derivation of scoring rules without the ordering assumption. Soc Choice Welf 12(1):59–74
Nehring K, Pivato M, Puppe C (2011) Condorcet admissibility: indeterminacy and path-dependence under majority voting on interconnected decisions. Working paper, University of California at Davis
Nehring K, Puppe C (2010a) Abstract Arrowian Aggregation. J Econ Theory 145:467–494
Nehring K, Puppe C (2010b) Justifiable group choice. J Econ Theory 145:583–602
Pettit P (2001) Deliberative democracy and the discursive dilemma. Philos Issues 11:268–299
Pigozzi G (2006) Belief merging and the discursive dilemma: an argument-based account to paradoxes of judgment aggregation. Synthese 152(2):285–298
Pivato M (2011a) Voting rules as statistical estimators. Working Paper, Trent University, Canada
Pivato M (2011b) Variable-population voting rules. Working Paper, Trent University, Canada
Smith JH (1973) Aggregation of preferences with variable electorate. Econometrica 41:1027–1041
Wilson R (1975) On the theory of aggregation. J Econ Theory 10:89–99
Young HP (1975) Social choice scoring functions. SIAM J Appl Math 28:824–838
Young HP (1995) Optimal voting rules. J Econ Perspect 9(1):51–64
Zwicker W (1991) The voters’ paradox, spin, and the Borda count. Math Soc Sci 22:187–227
Zwicker W (2008) Consistency without neutrality in voting rules: When is a vote an average? Math Comput Model 48:1357–1373
Zwicker W (2011) Towards a ”Borda count” for judgment aggregation, extended abstract. Presented at the conference ‘Judgment Aggregation and Voting’, Karlsruhe Institute of Technology
Acknowledgments
I am grateful for very useful suggestions received from two anonymous referees and the editor.
Author information
Authors and Affiliations
Corresponding author
Appendix: proofs
Appendix: proofs
Throughout, the complement of a set \(J\subseteq X\) is denoted by \(\overline{J}:=X\backslash J\).
Proof of Proposition 1
The Kemeny-distance between \(J,C\in \mathcal J \) can be written as
Now, since \(J\) and \(C\) each contains exactly one member of each pair \(\{p,\lnot p\}\subseteq X\), we have \(p\in J\cap C\Leftrightarrow \lnot p\in \overline{J}\cap \overline{C}\), and so, \(\left| J\cap C\right| =\left| \overline{J}\cap \overline{C}\right| \). Hence, \(d_{\mathrm{Kemeny}}(J,C)=\frac{1}{2}\left| X\right| -\left| J\cap C\right| \). So, for each profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\), minimizing \(\sum _{i\in N}d_{\mathrm{Kemeny}}(J_{i},C)\) is equivalent to maximizing \(\sum _{i\in N}\left| J_{i}\cap C\right| \). Hence, rewriting each \(\left| J_{i}\cap C\right| \) as \(\sum _{p\in C}s_{J_{i}}(p)\) where \(s\) is simple scoring (2), it follows that \(F_{d_{\mathrm{Kemeny}} }(J_{1},\ldots ,J_{n})=F_{s}(J_{1},\ldots ,J_{n})\). \(\square \)
Before proving Proposition 2, I start with a lemma.
Lemma 1
Consider the preference agenda (for any finite set of alternatives \(A\)), any classical scoring \(\textit{SCO}\), and the scoring \(s\) given by (4). For all distinct \(x,y\in A\) and all \(J\in \mathcal J \),
Proof
This follows easily from (4). \(\square \)
Two elements of a set of alternatives \(A\) are called neighbours w.r.t. a strict linear order \(\succ \) over \(A\) if they differ and no alternative in \(A\) is ranked strictly between them. In the case of the preference agenda (for a set of alternatives \(A\)), the strict linear order over \(A\) corresponding to any \(J\in \mathcal J \) is denoted \(\succ _{J}\).
Proof of Proposition 2
Consider the preference agenda \(X\) for a set of alternatives \(A\) of finite size \(k\), and let \(\textit{SCO}\) be any classical scoring. I show that \(F_{\textit{SCO}}=F_{s}\) for each scoring \(s\) satisfying (20), and hence for the scoring (4) (since it satisfies (20) by Lemma 1) and the scoring (3) (since a half times it satisfies (20)).
Consider any scoring \(s\) satisfying (20). Fix a profile \((J_{1} ,\ldots ,J_{n})\in \mathcal J ^{n}\); I show \(F_{s}(J_{1},\ldots , J_{n} )=F_{\textit{SCO}}(J_{1},\ldots ,J_{n})\). The proof is in three claims.
Claim 1 For all \(a,b\in A\) and \(C,C^{\prime }\in \mathcal J \), if \(C\backslash C^{\prime }=\{aPb\}\), then
Consider \(a,b\in A\) and \(C,C^{\prime }\in \mathcal J \) such that \(C\backslash C^{\prime }=\{aPb\}\). For each individual \(i\in N\), we by (20) have
which, noting that \(C^{\prime }=(C\backslash \{aPb\})\cup \{bPa\}\), implies that
Summing over all individuals, the claim follows. \(\square \)
Claim 2 \(F_{s}(J_{1},\ldots ,J_{n})\subseteq F_{\textit{SCO}}(J_{1},\ldots ,J_{n})\).
Consider any \(C\in F_{s}(J_{1},\ldots ,J_{n})\). We have to show that \(C\in F_{\textit{SCO}}(J_{1},\ldots ,J_{n})\), i.e., that for all distinct \(x,y\in A\),
or equivalently,
Said in yet another way, we have to show that
where I have labelled the alternatives \(x_{1},x_{2},\ldots ,x_{k}\) such that \(x_{k}\succ _{C}x_{k-1}\succ _{C}\cdots \succ _{C}x_{1}\). Consider any \(t\in \{1,\ldots ,k-1\}\), and write \(a\) for \(x_{t+1}\) and \(b\) for \(x_{t}\). Let \(C^{\prime }\) be the judgment set arising from \(C\) by replacing \(aPb\) with its negation \(bPa\). Now \(C^{\prime }\in \mathcal J \); this is because \(a\) and \(b\) are neighbours w.r.t. \(\succ _{C}\), which guarantees that \(C^{\prime }\) corresponds to a strict linear order (namely to the same one as for \(C\) except that \(b\) now ranks above \(a\)). Since \(C\in F_{s}(J_{1},\ldots ,J_{n}), C \) has maximal sum-total score within \(\mathcal J \); in particular,
which by Claim 1 implies the desired inequality,
\(\square \)
Claim 3 \(F_{\textit{SCO}}(J_{1},\ldots ,J_{n})\subseteq F_{s}(J_{1},\ldots ,J_{n})\).
Consider any \(C\in F_{SCO}(J_{1},\ldots ,J_{n})\). To show that \(C\in F_{s} (J_{1},\ldots ,J_{n}),\) we consider an arbitrary \(C^{\prime }\in \mathcal J \backslash \{C\}\) and have to show that \(C\) has an at least as high sum-total score as \(C^{\prime }\):
To prove this, we first transform \(C\) gradually into \(C^{\prime }\) in \(m\equiv |C^{\prime }\backslash C|\) steps, where each step consists in a single judgment reversal, i.e., in the replacement of a single proposition \(xPy \ (\in C\backslash C^{\prime })\) by its negation \(yPx\, (\in C^{\prime }\backslash C)\). This defines a sequence of judgment sets \(C_{0},\ldots ,C_{m}\), where \(C_{0}=C\) and \(C_{m}=C^{\prime }\), and where for each step \(t\in \{1,\ldots ,m\}\) there is a proposition \(x_{t}Py_{t}\) such that \(C_{t} =(C_{t-1}\backslash \{x_{t}Py_{t}\})\cup \{y_{t}Px_{t}\}\). Note that \(\{x_{t}Py_{t}:t=1,\ldots ,m\}=C\backslash C^{\prime }\). By a standard relation-theoretic argument, we may assume that in each step \(t\) the judgment reversal consists in switching the relative order of two neighbouring alternatives; i.e., \(x_{t},y_{t}\) are neighbours w.r.t. the old and new relations \(\succ _{C_{t-1}}\) and \(\succ _{C_{t}}\). This guarantees that each step \(t\) generates a set \(C_{t}\) such that \(\succ _{C_{t}}\) is still a strict linear order, i.e., such that \(C_{t}\in \mathcal J \).
Now for each step \(t\), by Claim 1 we have
and also, since \(y_{t}Px_{t}\not \in C\) and \(C\in F_{\textit{SCO}}(J_{1},\ldots ,J_{n})\), we have
using Claim 1, it follows that
Summing this inequality over all steps \(t\in \{1,\ldots ,m\}\), we obtain
which is equivalent to the desired inequality (21) since \(C_{0}=C\) and \(C_{m}=C^{\prime }\). \(\square \)
Proof of Remark 2
Let \(s^{\prime }\) be defined from reversal scoring \(s\) in the specified way.
Claim 1 \(s^{\prime }\) and \(s\) are equivalent.
Consider any profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\). I show for all \(C,D\in \mathcal J \) that
Consider any \(C,D\in \mathcal J \). I prove that \(\Delta \ge 0\Leftrightarrow \Delta ^{\prime }\ge 0\), where
We have
So, noting that \(D\backslash C=\{\lnot p:p\in C\backslash D\}\), we obtain
By an analogous reasoning,
Hence, using the definition of \(s^{\prime }\),
So, \(\Delta \ge 0\Leftrightarrow \Delta ^{\prime }\ge 0\). \(\square \)
Claim 2 If \(X\) is the preference agenda, \({ SCO}\) is classical Borda scoring, \(J\in \mathcal J \), and \(xPy\in X\), then \(s_{J}^{\prime } (xPy)={ SCO}_{J}(x)-{ SCO}_{J}(y)\).
Let \(X, { SCO}, J\) and \(xPy\) be as specified. If \(xPy\in J\), then
If \(xPy\not \in J\), i.e., \(yPx\in J\), then
\(\square \)
Proof of Proposition 4
Let \(X\) be the preference agenda for some set of alternatives \(A\) of size \(k<\infty \). Let \(s^{\mathrm{rev}}, s^{\mathrm{dis}}\) and \(s^{\mathrm{irr}}\) be reversal, disjoint-entailment, and irreducible-entailment scoring, respectively. Consider any \(J\in \mathcal J \), denote the corresponding strict linear order by \(\succ \), let \(x_{1},\ldots ,x_{k}\) be the alternatives in the order given by \(x_{k}\succ x_{k-1}\succ \cdots \succ x_{1}\), and consider any \(p\in X\), say \(p=x_{i}Px_{i^{\prime }}\in X\).
Claim 1 \(s_{J}^{\mathrm{rev}}(p)=s_{J}^{\mathrm{dis}}(p)\).
By the argument given in footnote 19, \(s_{J}^{\mathrm{rev}}(p)\ge s_{J}^{\mathrm{dis}}(p)\). I now show that \(s_{J}^{\mathrm{dis}}(p)\ge s_{J}^{\mathrm{rev}}(p)\). This inequality is trivial if \(p\not \in J\), since then \(s_{J}^{\mathrm{rev}}(p)=0\) (as \(\lnot p\in J\)). Now suppose \(p\in J\). By Remark 1, \(s_{J}^{\mathrm{rev}}(p)=i-i^{\prime }\). So we need to show that \(s_{J}^{\mathrm{dis}}(p)\ge i-i^{\prime }\). Consider the \(i-i^{\prime }\) judgment subsets \(S_{1},\ldots ,S_{i-i^{\prime }}\subseteq J\) defined as follows: for each \(j\in \{1,\ldots ,i-i^{\prime }\}\),
where \(S_{i-i^{\prime }}\) is interpreted as the set \(\{x_{i}Px_{i^{\prime }}\}\) (rather than the set \(\{x_{i}Px_{i^{\prime }},x_{i^{\prime }}Px_{i^{\prime }}\}\), which is not well-defined since \(x_{i^{\prime }}Px_{i^{\prime }}\) is not a proposition in \(X\)). Since these judgment subsets are pairwise disjoint and each of them entails \(p (=x_{i}Px_{i^{\prime }})\), we have \(s_{J} ^{\mathrm{dis}}(p)\ge i-i^{\prime }\). \(\square \)
Claim 2 \(s_{J}^{\mathrm{rev}}(p)=s_{J}^{\mathrm{irr}}(p)\).
If \(p\not \in J\), then \(s_{J}^{\mathrm{rev}}(p)=s_{J}^{\mathrm{irr}}(p)\) since \(s_{J}^{\mathrm{rev}}(p)=0\) (as \(\lnot p\in J\)) and \(s_{J}^{\mathrm{irr}}(p)=0\) (as \(J\) does not entail \(p\)). Now suppose \(p\in J\). Then, as already mentioned, \(s_{J}^{\mathrm{rev}}(p)=i-i^{\prime }\) by Remark 1. So we need to show that \(s_{J}^{\mathrm{irr}}(p)=i-i^{\prime }\). As one may show, each of the just-defined sets \(S_{1},\ldots ,S_{i-i^{\prime }}\) irreducibly entails \(p (=x_{i}Px_{i^{\prime }})\). So it remains to show that no other judgment subset irreducibly entails \(p\). Suppose \(S\subseteq J\) irreducibly entails \(p\). I have to show that \(S\in \{S_{1},\ldots ,S_{i-i^{\prime }}\}\). As is easily checked, the set \(S\cup \{\lnot p\} (=S\cup \{x_{i^{\prime }}Px_{i}\})\) is minimal inconsistent. Hence, this set is cyclic, i.e., of the form \(S\cup \{\lnot p\}=\{y_{1}Py_{2},y_{2}Py_{3},\ldots ,y_{m-1}Py_{m},y_{m}Py_{1}\}\) for some \(m\ge 2\) and some distinct alternatives \(y_{1},\ldots ,y_{m}\in A\) (see Dietrich and List 2010). Without loss of generality, assume \(y_{1}=x_{i}\) and \(y_{m}=x_{i^{\prime }}\), so that \(y_{m}Py_{1}=x_{i^{\prime }}Px_{i}\) and
If \(m=2\), then \(S=\{y_{1}Py_{2}\}=\{x_{i}Px_{i^{\prime }}\}\), which equals \(S_{i-i^{\prime }}\), and we are done. If \(m=3\), then \(S=\{y_{1}Py_{2} ,y_{2}Py_{3}\}=\{x_{i}Py_{2},y_{2}Px_{i^{\prime }}\}\). Since \(S\) is by assumption included in \(J\), it follows that \(J\) ranks \(y_{2}\) between \(x_{i}\) and \(x_{i^{\prime }}\). So there is a \(j\in \{1,\ldots ,i-i^{\prime }-1\}\) such that \(y_{2}=x_{i-j}\). Hence, \(S\) is the set \(\{x_{i}Px_{i-j},x_{i-j}Px_{i^{\prime } }\}=S_{j}\), and we are done again. Finally, \(m\) cannot exceed 3, since otherwise the set \(S (=\{x_{i}Py_{2},y_{2}Py_{3},\ldots ,y_{m-1}Px_{i^{\prime } }\})\) would entail \(p (=x_{i}Px_{i^{\prime }})\) non-irreducibly, since the set arising from \(S\) by replacing \(x_{i}Py_{2}\) and \(y_{2}Py_{3}\) with their implication \(x_{i}Py_{3}\) still entails \(p\). \(\square \)
Proof of Proposition 5
Consider any threshold family \((m_{p})_{p\in X} (\in \{1,\ldots ,n\}^{X})\), and define scoring \(s\) by (12). Consider a profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) for which \(C^{*}\equiv F_{(m_{p})_{p\in X}}(J_{1},\ldots , J_{n})\) belongs to \(\mathcal J \). We have to show that \(F_{s}(J_{1},\ldots ,J_{n})=C^{*}\). For each proposition \(p\in X\), writing the number of individuals accepting \(p\) as \(n_{p}\equiv |\{i:p\in J_{i}\}|\), the sum-total score of \(p\) is given by
and so,
Now we have \(\{C^{*}\}=\mathrm{argmax }_{C\in \mathcal J }\sum _{p\in C,i\in N}s_{J_{i}}(p)\), because for each \(C\in \mathcal J \backslash \{C^{*}\}\),
So, \(F_{s}(J_{1},\ldots ,J_{n})=\{C^{*}\}\equiv C^{*}\). \(\square \)
Proof of Remark 4
Consider this \(X\) and \(P\), let \(n\) be odd, and let \(s\) be scoring (14). I write \(\alpha _{\mathrm{pr}}\) for \(\alpha _{\mathrm{premise}}\) and \(\alpha _{\mathrm{co}}\) for \(\alpha _{\mathrm{conclusion}}\). Whenever I consider a profile \((J_{1},\ldots ,J_{n} )\in \mathcal J ^{n}\), I write \(N_{t}:=\{i:t\in J_{i}\}\) for all \(t\in X\), and I write \(\mathcal{MAJ }, \mathcal{PRE }, \mathcal{CON }\) and \(\mathcal{SCO }\) for the outcome of the majority rule, premise-based rule, conclusion-based rule, and the scoring rule w.r.t. (14), respectively. Note that for all \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) the sum-total score of a \(C=\{p^{\prime },q^{\prime },r^{\prime }\}\in \mathcal J \) (where \(p^{\prime }\in \{p,\lnot p\}, q^{\prime }\in \{q,\lnot q\}\) and \(r^{\prime }\in \{r,\lnot r\}\)) is given by
Claim 1 [\(\mathcal{PRE }=\mathcal{SCO }\) for all profiles in \(\mathcal J ^{n}\)] if and only if \(\alpha _{\mathrm{pr}}>(n-2)\alpha _{\mathrm{co}}\).
First, assume \(\mathcal{PRE }=\mathcal{SCO }\) for all profile in \(\mathcal J ^{n}\). As one may check, there is a profile such that \(\left| N_{p}\right| =\left| N_{q}\right| =\frac{n+1}{2}\) and \(\left| N_{r}\right| =1\). For this profile, \(\mathcal{PRE }=\{p,q,r\}\). So, \(\mathcal{SCO }=\{p,q,r\}\). Hence, the sum-total score of \(\{p,q,r\}\) exceeds that of \(\{\lnot p,q,\lnot r\}\). By (23), these two sum-total scores can be written, respectively, as
Hence,
or equivalently, \(\alpha _{\mathrm{pr}}>(n-2)\alpha _{\mathrm{co}}\).
Conversely, assume \(\alpha _{\mathrm{pr}}>(n-2)\alpha _{\mathrm{co}}\). Consider any profile. We have to show that \(\mathcal{PRE }=\mathcal{SCO }\).
Case 1 \(\mathcal{MAJ }\in \mathcal J \). Check that it follows that \(\mathcal{PRE }=\mathcal{MAJ }\), and also that \(\mathcal{SCO }=\mathcal{MAJ }\). So, \(\mathcal{PRE }=\mathcal{SCO }\).
Case 2 \(\mathcal{MAJ }\not \in \mathcal J \). Check that it follows that \(\mathcal{MAJ }=\{p,q,\lnot r\}\). Hence \(\mathcal{PRE }=\{p,q,r\}\). We thus have to show that \(\mathcal{SCO }=\{p,q,r\}\), i.e., that
By (23),
In this, as \(p\in \mathcal{MAJ }\) we have \(\left| N_{p}\right| \ge (n+1)/2\); and further, as \(p,q\in \mathcal{MAJ }\) the sets \(N_{p}\) and \(N_{q}\) each contain a majority, so that \(N_{p}\cap N_{q}\ne \varnothing \), which (since \(N_{p}\cap N_{q}\subseteq N_{r}\)) implies \(\left| N_{r}\right| \ge 1\). Using these lower bounds for \(\left| N_{p}\right| \) and \(\left| N_{r}\right| \), we obtain
The proof that \(\Delta _{2}>0\) is analogous. Finally, by (23),
Since \(\left| N_{q}\right| >\left| N_{\lnot q}\right| \) (as \(q\in \mathcal{MAJ }\)), it follows using (24) that \(\Delta _{3}>\Delta _{1}\), and hence, that \(\Delta _{3}>0\). \(\square \)
Claim 2 [\(\mathcal{CON }=\mathcal{SCO }\) for all profiles in \(\mathcal J ^{n}\)] if and only if \(\alpha _{\mathrm{co}}>\alpha _{\mathrm{pr} }=0\).
Unlike in the proof of the Claim, there may be ties, and so we treat \(\mathcal{CON }\) and \(\mathcal{SCO }\) as subsets of \(\mathcal J \), not elements. First, if \(\alpha _{\mathrm{co}}>\alpha _{\mathrm{pr}}=0\), then it is easy to show that \(\mathcal{CON }=\mathcal{SCO }\) for each profile. Conversely, suppose it is not the case that \(\alpha _{\mathrm{co}}>\alpha _{\mathrm{pr}}=0\). Then either \(\alpha _{\mathrm{co}}=\alpha _{\mathrm{pr}}=0\) or \(\alpha _{\mathrm{pr} }>0\). In the first case, clearly \(\mathcal{CON }\ne \mathcal{SCO }\) for some profiles, since \(\mathcal{SCO }\) is always \(\mathcal J \). In the second case, again \(\mathcal{CON }\ne \mathcal{SCO }\) for some profiles: for instance, if each individual submits \(\lnot pq\lnot r\) then \(\mathcal{SCO }=\{\lnot pq\lnot r\}\) while \(\mathcal{CON }=\{\lnot pq\lnot r,p\lnot q\lnot r,\lnot p\lnot q\lnot r\}\). \(\square \)
Proof of Proposition 6
It will sometimes be convenient to write a vector \(D=(D_{1},\ldots ,D_{n}) \in \mathbb R ^{n}\) as \(\left\langle D_{i}\right\rangle \). The mean and variance of this vector \(D\) are denoted and defined by, respectively,
In this notation, the average square deviation of a constant \(c\in \mathbb R \) from the components in \(D\) is \(\overline{\left\langle (c-D_{i})^{2} \right\rangle }\) and satisfies
by the following argument borrowed from statistics:
Now consider any scoring \(s\) and let the set scoring \(\sigma \) be defined by (17). Consider any profile \((J_{1},\ldots ,J_{n})\in \mathcal J ^{n}\) and any \(C\in \mathcal J \). Under \(\sigma \), the sum-total score of \(C\) can be written as
Here, the inner expression can be re-expressed as
where the last equality applies (25) with \(c=C_{p}^{s}\) and \(D=\left\langle J_{ip}^{s}\right\rangle \). It follows that
Maximizing this expression w.r.t. \(C\in \mathcal J \) is equivalent to minimizing its strictly decreasing transformation \(\left\| C-\overline{\left\langle J_{i}^{s}\right\rangle }\right\| \) w.r.t. \(C\in \mathcal J \). So, the set scoring rule w.r.t. \(\sigma \) delivers the same collective judgment set(s) \(C\) as the averaging rule w.r.t. \(s\). \(\square \)
Proof of Proposition 7
Assume (IND) and (COM) and consider a profile \((J_{1},\ldots ,J_{n}) \in \mathcal J ^{n}\).
Firstly, using (IND), the likelihood of the profile given \(C\in \mathcal J \) can be written as
Maximizing this expression (w.r.t. \(T\in \mathcal J \)) is equivalent to maximizing its logarithm,
which is precisely the sum-total score of \(T\) under set scoring (18).
Secondly, writing \(\pi \) for the profile’s probability \(\Pr (J_{1},\ldots ,J_{n}) \), the posterior probability of \(T\in \mathcal J \) given the profile can be written as
Maximizing this expression (w.r.t. \(T\in \mathcal J \)) is equivalent to maximizing its logarithm, and hence, to maximizing
which is the sum-total score of \(T\) under set scoring (19). \(\square \)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Dietrich, F. Scoring rules for judgment aggregation. Soc Choice Welf 42, 873–911 (2014). https://doi.org/10.1007/s00355-013-0757-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-013-0757-8