
Abstract
The Mouse Disease Information System (MoDIS) is a data capture system for pathology data from laboratory mice designed to support phenotyping studies. The system integrates the mouse anatomy (MA) and mouse pathology (MPATH) ontologies into a Microsoft Access database facilitating the coding of organ, tissue, and disease process to recognized semantic standards. Grading of disease severity provides scores for all lesions that can then be used for quantitative trait locus (QTL) analyses and haplotype association gene mapping. Direct linkage to the Pathbase online database provides reference definitions for disease terms and access to photomicrographic images of similar diagnoses in other mutant mice. MoDIS is an open source and freely available program (http://research.jax.org/faculty/sundberg/index.html). This provides a valuable tool for setting up a mouse pathology phenotyping program.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The relationship between genetic variation and phenotype is at the heart of the model organism approach to the study of human disease. In recent years the mouse has become the model organism of choice for the study of human disease, partly as a consequence of its physiologic and genomic similarities, but also because of the developments in mouse genetics, that now provide powerful tools for the manipulation of the mouse genome (Rosenthal and Brown 2007). The last five years have also seen rapid advances in the instrumentation and technology available for detailed phenotyping, and these factors together provide enormous potential for the advancement of our understanding of gene function in health and disease.
The torrent of phenotype data currently being generated from both gene-driven and phenotype-driven experimental approaches to functional genomics will accelerate over the next few years. With the accumulation of data now emerging from the large ethyl-nitrosourea (ENU) mutagenesis projects (Auwerx et al. 2004) and the ambitious whole mouse genome mutagenesis projects represented by the International Knockout Mouse Consortium (Collins et al. 2007), there is the risk that this will overwhelm our ability to retain, share, and exploit the resulting information. The challenges presented by the collection and analysis of this volume of phenotype data are unprecedented, not only because of the quantity, but also the range and depth of the information. This requires specifically tailored approaches to the capture and representation of radically different types of data, for example, craniofacial morphology and blood chemistry (Brown et al. 2006; Gkoutos et al. 2005). The dominant approach to this set of problems is exemplified by that adopted by the EUMORPHIA consortium using EmPRESS (Green et al. 2005), where phenotype is represented by a standard assay, which then defines a set of measurements or descriptions derived from formal description frameworks and ontologies (Mallon et al. 2008). The power of this approach is that it allows for high-resolution data to be captured on individual mice for one or more assays and then combined to provide data that can be compared with that from background or control strains. Relating this accumulated variant phenotype data to genetic information is then a matter for new computational tools and resources, many of which are newly available or under development (Chen et al. 2007; Groth et al. 2007; Swertz et al. 2004).
Crucial to the utility of this data is that it is presented in a formalized way to facilitate data sharing, which requires that databases use standard data structures and semantics. Currently, two databases present raw data for individual mouse strains: the Mouse Phenome Database (Bogue et al. 2007) (http://www.jax.org/phenome) and the EuroPhenome Database (http://www.europhenome.org) (Mallon et al. 2008).
Pathology is an essential aspect of phenotyping that requires labor-intensive workup and detailed knowledge of laboratory mouse anatomy, physiology, and genetics to be fully effective. There are two major problems with recording this aspect of phenotype: standardization of pathology data, and the availability of pathology expertise to derive and interpret that data. The latter is a well-recognized problem: “The importance of pathology in mouse phenotyping cannot be underestimated. However, the laborious nature of pathology analysis and the dependence on a small cadre of experts continues to represent a significant stumbling block to unraveling the mouse phenome” (Brown et al. 2006). Such expertise is not easy to find (Barthold et al. 2007; Cardiff et al.2008; Valli et al. 2007) and the perils of “DIY pathology” are well illustrated in the article by Cardiff et al. (2008). The gold standard is represented in the systematic pathology segment of the German Mouse Clinics phenotyping process where there is standardized morphologic phenotyping of potential mouse models (Mossbrugger et al. 2007).
The depth of data captured, data structure, and description semantics are not yet fully standardized and require not only community agreement on the minimal information needed to record a phenotype but also data capture tools that allow for rapid and accurate recording of data in a form in which it may be uploaded to central databases (Mouse Phenotype Database Integration Consortium 2007). The terminology for lesions in widespread use is a mixture of veterinary and human diagnostic names that do not always correspond, although recent recommendations by the Mouse Models of Human Cancer Consortium (MMHCC) have gone some way toward standardization of nomenclature for neoplastic diseases (Cardiff et al. 2000; Kogan et al. 2002; Nikitin et al. 2004a, b; Shappell et al. 2004). Unfortunately, adoption of these recommendations has been slow among pathologists working in different environments and traditions. Much needed resources are being developed to provide standard reference vocabularies for mouse anatomy at the gross level (mouse anatomy ontology) and disease processes (mouse pathology ontology) useful at both the gross and microscopic levels. Integration of these with annotated and labeled line drawings, gross photographs or photomicrographs, and literature references provides tools that can be rapidly used for reference and for training the next generation of mouse specialist pathologists. These are adjuncts to, not replacements for, traditional training and mentorship approaches (Barthold et al. 2007; Sundberg et al. 2004). Unfortunately these types of resources are spread all over the world at many different institutions and if online are often unlinked.
Diagnostic laboratories face record-keeping problems that can be overwhelming. Using traditional approaches to diagnostic case record-keeping linked to flat files of anatomy (Hayamizu et al. 2005) and pathology ontologies (Schofield et al. 2005) provides one approach to rapidly coding case materials, standardizing the diagnoses, and retrieving all case materials. Development of a disease diagnostic field with assessment of the disease severity provides a definitive answer that is also semiquantitative. These are necessary for quantitative trait locus analysis (QTL mapping) as well as for defining the pathogenesis of a novel disease in a mouse model system.
Web-based systems can now integrate all of these activities to allow a pathologist to review slides from a case and rapidly enter the diagnosis, which is automatically accurately coded and can be exported in a defined format, e.g. XML, to other databases. More importantly, hyperlinks to the appropriate web site provide access to photomicrographs of representative cases in other genetically engineered mice or inbred strains and provides the pathologist with reference information, descriptions, and original papers on the disease process. This approach provides tools for verification of a diagnosis, training for those not familiar with laboratory mice, and a means to improve the quality of the service to the molecular biologist submitting the samples. Furthermore, because panels of veterinary and physician pathologists volunteer to maintain the quality of these databases, it is possible to access expertise not otherwise available to accurately define diseases and make appropriate comparisons with human diseases.
In this article we describe MoDIS (Mouse Disease Information System), a system that integrates all of the above-mentioned tools using a Microsoft Access-based database and which is open source and freely available (The Jackson Laboratory, Bar Harbor, ME; http://research.jax.org/faculty/sundberg/index.html). This provides a valuable tool for setting up a mouse pathology phenotyping program.
Materials and methods
Case materials
Routine disease surveillance cases received by The Jackson Laboratory’s Laboratory Animal Health Disease Surveillance Program from 1987 to 2000 were used to develop the original medical records database (Sundberg and Sundberg 1990, 2000), which used a traditional free-text diagnostic field. In 2006 this was converted so that the MPATH pathology ontology could be used to standardize detailed histopathologic phenotyping methods for defining and describing diseases. This conversion was done to expedite large-scale phenotyping and haplotype mapping of chronic diseases in the most important inbred strains of mice used today in biomedical research. Complete systematic necropsies (Seymour et al. 2004) were performed on 15 males and 15 females of each of the 31 inbred strains designated in the Mouse Phenome Database (http://phenome.jax.org) at 12 and 20 months of age. All tissues were screened by one pathologist (JPS) to standardize the first screen interpretation (R. Yuan et al., unpublished). Additional protocols from the major international research consortiums doing phenotyping can be accessed through a common website (www.interphenome.org) (Mouse Phenotype Database Integration Consortium 2007).
Databases
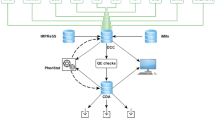
MoDIS is implemented on a Microsoft Access database (Microsoft Corp., Redman, WA) platform and is the descendent of earlier versions of our pathology medical records database, which were converted from dBASE III Plus (Ashton-Tate, Torrance, CA) (Sundberg and Sundberg 1990) to FoxPro 2.6 for Windows (Microsoft) (Sundberg and Sundberg 2000) and then to its current form. Accumulated practical experience of using this database for pathology data capture in a large institutional setting has greatly improved its development. MoDIS stores information from individual mice and cross references to images captured in an image database, e.g., Extensis Portfolio (http://www.extensis.com). The database is structured to record information associated with husbandry, pedigree, strain, assays performed, location of material, and pathologic diagnosis. The primary entity in the database is a necropsy case consisting of one mouse. A mouse can have many diagnoses and several special tests such as immunohistochemistry or microbiology associated with the record. Each mouse case can have many types of materials associated with it (histology, photographs, frozen tissue) (Fig. 1).

Diagram of work and data flow. Investigators/collaborators submit a mouse. The animal is necropsied, at which point samples are collected for histopathology and special tests. When all results are received they are added to the case file, including diagnoses for all lesions and final diagnoses. The finalized report can then be emailed to the submitter or printed out and signed to create a legal diagnostic medical report
The diagnostic information includes a “Disease Description” field, in which an extendable controlled vocabulary containing high-level diagnostic terms is used by the pathologist to input a summative pathologic diagnosis. This allows for locally preferred terminology to be defined and recorded. The recording of standardized pathologic terminology uses terms from the MPATH and MA ontologies for each lesion. It is possible to record several Disease Descriptions and several MA/MPATH pairs of terms for each mouse.
An additional field grades severity of lesions that builds on the commonly used adjectives no lesions (0), mild (1), moderate (2), severe (3), and extreme (4). This provides an estimate of the variation of severity within a group of mice of the same strain and genotype or treatment group which provides a semiquantitative set of parameters for comparison which can be used in quantitative trait locus analyses.
Ontologies and controlled vocabularies
MoDIS uses the MPATH (Schofield et al. 2005) and MA ontologies (Hayamizu et al. 2005) downloaded from the OBO foundry web site (http://www.obofoundry.org/) as flat files. Terms from the two ontologies are used to specify the intersection of anatomy and pathology for each lesion. Strains and genotypes are recorded in compliance with standard nomenclature (http://www.informatics.jax.org/mgihome/nomen/gene.shtml). Special tests, organisms found in testing, submitters, and housing locations may also be recorded in free text or locally controlled vocabulary (CV). The facility is available to build a local controlled vocabulary (CV) for high-level summative disease diagnoses.
Results
MoDIS is currently designed for local installation but with the facility to output files to other databases and programs. The local MoDIS database at The Jackson Laboratory now contains nearly 40,000 records and forms the core resource for other databases and resources at The Jackson Laboratory, such as the Mouse Tumor Biology Database (Begley et al. 2007), and elsewhere. These clinical records can be quickly searched for individual cases or case series by disease, organ, and strain to output to comma-separated values (CSV) or a Microsoft Excel file that can be further sorted and analyzed. All case materials are linked by a common accession number code for each animal in other databases of the laboratory. Individual or groups of images representing example sections have been placed online with annotations. Summaries of studies are also being put online as they are completed and curated [Mouse Phenome Database (MPD), http://phenome.jax.org (Bogue et al. 2007; Mouse Phenotype Database Integration Consortium 2007); Mouse Tumor Biology Database (MTB), http://tumor.informatics.jax.org (Krupke et al. 2008); and Pathbase, http://www.Pathbase.net (Schofield et al. 2004a, b)]. Complete tables of spontaneous background diseases, although currently published only for strain disease surveillance (Mikaelian et al. 2004; Sundberg and Ichiki 2005a), will soon be online with links to the specific photomicrographs of lesions from the strain in question.
Pathologic diagnosis recording is complex and depends to a great extent on the tradition in which the diagnostician was trained. This problem has generated much discussion recently about the standardization of the semantics of pathologic diagnoses. From experience we believe that the solution is to use standard defined ontologies for formal recording but to leave the clinician with the ability to make local annotations in other formalisms. This means that eventual export of key data to central public databases such as Europhenome (Mallon et al. 2008) can be semantically and syntactically compatible with accepted standards and can be achieved automatically. The MPATH ontology is continuously under review by a panel of pathologists at annual meetings of the Pathbase European Mouse Pathology Consortium. The pathologists (both veterinarians and physicians) review new terms, edit them, and arrive at a consensus on the terms and their definitions. Similarly, MA is under constant revision and refinement. Thus, there is an ongoing system of checks and balances of the terminology used as well as a formal means to upgrade the system, especially to expand to a higher level of sophistication and utility.
MoDIS as a training resource
When online and if the ontology flat files used for coding are current and linked to Pathbase (http://www.pathbase.net), it is possible to move from the ontology term to retrieve a formal definition with literature or web references and, where appropriate, annotated images of similar lesions that are posted by pathologists who work with mice worldwide on Pathbase (Fig. 2).

Steps to move from a diagnosis to definitions, references, and images. Once a diagnosis is arrived at and MoDIS is linked to Pathbase, one can move to the MPATH definition and from there to images of lesions given this diagnosis. In this way one can quickly verify the tentative diagnosis using virtual mentoring
Discussion
Standardization and integration
The capture of detailed primary data from phenotyping experiments, with appropriate structure, is a sine qua non for high-throughput large-scale studies. The development of more structured descriptions of phenotypes will allow data to be processed and interpreted in a consistent manner and facilitate the development of new computational software. The capture of primary data from individual mice allows for its reanalysis and reuse in the light of new hypotheses and new information and maximizes the added value of the studies. Development of tools that address this is a recognized need. For example, the MPHASYS system (Calder et al. 2007) is designed to capture and integrate phenotype information, though not in a format that recognizes ontologies and structure. This example emphasizes the importance of semantic and syntactic standardization for the general application of such data capture tools, and the importance of adherence to community consensus standards, which we have begun to implement in MoDIS. Removal of multiple manual curation steps in data entry reduces the risk of error and the cost of large database curation, which can be substantial. Therefore, data capture tools need to be intuitive and readily usable by the “phenotyper,” in this case the pathologist, and consideration of the user’s expertise is an important aspect of their design.
Training and referencing
To help pathologists interpret lesions that develop in inbred, genetically engineered, or experimentally manipulated mice, small pathology programs are being set up in medical centers and universities worldwide. While ideally these programs would be peer-driven, mentor-based programs (Sundberg et al. 2004), in fact they are usually run by isolated junior-level pathologists or clinicians with marginal training in histopathology. While many books are now available (Bannasch and Goessner 1994; Bannasch and Gossner 1994; Frith and Ward 1988; Kaufman et al. in press; Kaufman 1992; Kaufman and Bard 1999; Maronpot et al. 1999; Mohr 2001; Mohr et al. 1996; Smith et al. 2002; Sundberg 1994; Sundberg and Boggess 2000; Sundberg and Ichiki 2005b; Ward et al. 2000), these are only a partial substitute for a team of pathologists with whom one can consult. Formal national training programs (Barthold et al. 2007; Sundberg et al. 2007), mentored by established senior pathologists or other organ or disease experts, can provide support for these junior pathologists. The high volume of case materials with which many are faced, combined with the fact that senior pathologists with expertise in rodent pathology are not readily available at many institutions, results in less than optimal working conditions. We provide here a freely available system that addresses the problem of record-keeping and case retrieval, continuing education, and confirmation (second opinions) on the cases. We provide a relatively simple system that can be easily integrated into larger databases or the data can be downloaded into formats for use in larger, more comprehensive databases. This database and full documentation on how to use it are available free online (http://research.jax.org/faculty/sundberg/index.html).
Investigators usually want a summative diagnosis rather than a list of lesions. Pathologists understand that lesions can be independent of each other or linked, and that they can be specific to the strain used, the husbandry conditions, or be related to the experimental manipulation done on the animals. For those mapping complex genetic traits, keeping lesions separated by organ system and quantified is critical for these types of analyses. By adding a field for disease severity by simply converting adjectives commonly used by pathologists to describe lesions (mild, moderate, severe, and extreme) to a graded scale (1, 2, 3, and 4, respectively), one now has a simple semiquantitative scale for all lesions. If this is done consistently one can immediately run a quantitative trait analysis. We have used this successfully for many years for mapping inflammatory bowel disease severity and resistant genes in the mouse (Bleich et al. 2004; Bristol et al. 2000; Farmer et al. 2001; Mahler et al. 1998, 1999, 2002).
Future developments
While the use of small locally instituted MoDIS databases can be useful for a wide range of users, migration to a server-based relational database management system (RDBMS) such as MySQL would open up a range of further possibilities with regard to sophistication of structure, access, and interoperability. Live linkage of ontologies to the Ontology Lookup Service (OLS) (http://www.ebi.ac.uk/ontology-lookup/) would maintain currency with the standard ontologies and remove any requirement for manual updating. Standards for the reporting of environmental and husbandry conditions as well as other assays are now being developed and inclusion of compatibility with these standards will enhance interoperability with larger databases and computational tools to generate a data capture, coding, and uploading resource of wide utility.
References
Auwerx J, Avner P, Baldock R, Ballabio A, Balling R et al (2004) The European dimension for the mouse genome mutagenesis program. Nat Genet 36:925–927
Bannasch B, Goessner W (1994) Pathology of neoplasia and preneoplasia in rodents, vol 2. Schattauer, Stuttgart
Bannasch P, Gossner W (1994) Pathology of neoplasia and preneoplasia in rodents, vol 1. Schattauer, Stuttgart
Barthold SW, Borowsky AD, Brayton C, Bronson R, Cardiff RD et al (2007) From whence will they come? A perspective on the acute shortage of pathologists in biomedical research. J Vet Diagn Invest 19:455–456
Begley DA, Krupke DM, Vincent MJ, Sundberg JP, Bult CJ et al (2007) Mouse Tumor Biology Database (MTB): status update and future directions. Nucleic Acids Res 35:D638–D642
Bleich A, Mahler M, Most C, Leiter EH, Lieber-Tenorio E et al (2004) Refined histopathologic scoring systems improves power to detect colitis QTL in mice. Mamm Genome 15:865–871
Bogue MA, Grubb SC, Maddatu TP, Bult CJ (2007) Mouse Phenome Database (MPD). Nucleic Acids Res 35:D643–D649
Bristol IJ, Farmer MA, Cong Y, Zheng XX, Strom TB et al (2000) Heritable susceptibility for colitis in mice induced by IL-10 deficiency. Inflamm Bowel Dis 6:290–302
Brown SD, Hancock JM, Gates H (2006) Understanding mammalian genetic systems: the challenge of phenotyping in the mouse. PLos Genet 2:e118
Calder RB, Beems RB, vanSteeg H, Mian IS, Lohman PH et al (2007) MPHASYS: a mouse phenotype analysis system. BMC Bioinformatics 8:183
Cardiff RD, Ward JM, Barthold SW (2008) Lab Invest 88(1):18–26. [Epub 2007 Nov 26]
Cardiff RD, Moghanaki D, Jensen RA (2000) Genetically engineered mouse models of mammary intraepithelial neoplasia. J Mammary Gland Biol Neoplasia 5:421–437
Chen J, Xu H, Aronow BJ, Jegga AG (2007) Improved human disease candidate gene prioritization using mouse phenotype. BMC Bioinformatics 8:392
Collins FS, Rossant J, Wurst W (2007) A mouse for all reasons. Cell 128:9–13
Farmer MA, Sundberg JP, Bristol IJ, Churchill GA, Li R et al (2001) A major quantitative trait locus on chromosome 3 controls colitis severity in IL-10-deficient mice. Proc Natl Acad Sci USA 98:13820–13825
Frith CH, Ward JM (1988) Color atlas of neoplastic and non-neoplastic lesions in aging mice. Elsevier, Amsterdam
Gkoutos GV, Green EC, Mallon AM, Hancock JM, Davidson D (2005) Using ontologies to describe mouse phenotypes. Genome Biol 6:R8
Green EC, Gkoutos GV, Lad HV, Blake A, Weekes J et al (2005) EMPReSS: European mouse phenotyping resource for standardized screens. Bioinformatics 21:2930–2931
Groth P, Pavlova N, Kalev I, Tonov S, Georgiev G et al (2007) PhenomicDB: a new cross-species genotype/phenotype resource. Nucleic Acids Res 35:D696–D699
Hayamizu TF, Mangan M, Corradi JP, Kadin JA, Ringwald M (2005) The adult mouse anatomical dictionary: a tool for annotating and integrating data. Genome Biol 6:R29
Kaufman MH (1992) The atlas of mouse development. Academic Press, London
Kaufman MH, Bard JBL (1999) The anatomical basis of mouse development. Academic Press, San Diego
Kaufman M, Nikitin A, Sundberg JP (in press) Comparative embryology of the endocrine system. Boca Raton, FL: CRC Press
Kogan SC, Ward JM, Anver MR, Berman JJ, Brayton C et al (2002) Bethesda proposals for classification of nonlymphoid hematopoietic neoplasms in mice. Blood 100:238–245
Krupke D, Begley D, Sundberg J, Bult C, Eppig J (2008) The mouse tumor biology database. Nat Rev Cancer 8:459–465
Mahler M, Bristol I, Leiter E, Workman A, Birkenmeier E et al (1998) Differential susceptibility of inbred mouse strains to dextran sulfate sodium-induced colitis. Am J Physiol 274:G544–G551
Mahler M, Sundberg JP, Birkenmeier EH, Bristol JJ, Elson CO et al (1999) Genetic analysis of susceptibility to dextran sulfate sodium-induced colitis in mice. Genomics 55:147–156
Mahler M, Most C, Schmidtke S, Sundberg JP, Li R et al (2002) Genetics of colitis susceptibility in IL-10-deficient mice: backcross versus F2 results contrasted by principal component analysis. Genomics 80:274–282
Mallon AM, Blake A, Hancock JM (2008) EuroPhenome and EMPReSS: online mouse phenotyping resource. Nucleic Acids Res 36:D715–D718
Maronpot RR, Boorman GA, Gaul BW (1999) Pathology of the mouse. Reference and atlas. Cache River Press, Vienna, IL
Mikaelian I, Ichiki T, Ward JM, Sundberg JP (2004) Diversity of spontaneous neoplasms in commonly used inbred strains and stocks of laboratory mice. In: Hedrich HJ (ed) The laboratory mouse. Academic Press, London, pp 345–354
Mohr U (2001) International classification of rodent tumors: the mouse. Springer Verlag, Berlin
Mohr U, Dungworth DL, Capen CC, Carlton WW, Sundberg JP et al (1996) Pathobiology of the aging mouse. ILSI Press, Washington, DC
Mossbrugger I, Hoelzlwimmer G, Calzada-Wack J, Quintanilla-Martinez L (2007) Standardized morphological phenotyping of mouse models of human diseases within the German Mouse Clinic. Verh Dtsch Ges Pathol 91:98–103
Mouse Phenotype Database Integration Consortium (2007) Mouse Phenotype Database Integration Consortium: integration of mouse phenome data resources. Mamm Genome 18:157–163
Nikitin A, Alcaraz A, Anver MR, Bronson RT, Cardiff RD et al (2004a) Classification of proliferative pulmonary lesions of the mouse: recommendations of the mouse models of human cancers consortium. Cancer Res 64:2307–2316
Nikitin AY, Connolly DC, Hamilton TC (2004b) Pathology of ovarian neoplasms in genetically modified mice. Comp Med 54:26–28
Rosenthal N, Brown S (2007) The mouse ascending: perspectives for human-disease models. Nat Cell Biol 9:993–999
Schofield PN, Bard JB, Boniver J, Covelli V, Delvenne P et al (2004a) Pathbase: a new reference resource and database for laboratory mouse pathology. Radiat Prot Dosimetry 112:525–528
Schofield PN, Bard JB, Booth C, Boniver J, Covelli V et al (2004b) Pathbase: a database of mutant mouse pathology. Nucleic Acids Res 32:D512–D515
Schofield PN, Bard JBL, Rozell B, Sundberg JP (2005) Computational pathology: challenges in the informatics of phenotype description in mutant mice. In: Sundberg JP, Ichiki JP (eds) Handbook on genetically engineered mice. CRC Press, Boca Raton, FL, pp 61–81
Seymour R, Ichiki T, Mikaelian I, Boggess D, Silva KA et al (2004) Necropsy methods. In: Hedrich HJ (ed) Laboratory mouse. Academic Press, London, pp 495–516
Shappell SB, Thomas GV, Roberts RL, Herbert R, Ittmann MM et al (2004) Prostate pathology of genetically engineered mice: definitions and classification. The consensus report from the Bar Harbor meeting of the Mouse Models of Human Cancer Consortium Prostate Pathology Committee. Cancer Res 64:2270–2305
Smith RS, John SWM, Nashina PM, Sundberg JP (2002) Systematic evaluation of the mouse eye. anatomy, pathology, and biomethods. CRC Press, Boca Raton, FL
Sundberg JP (1994) Handbook of mouse mutations with skin and hair abnormalities. Animal models and biomedical tools. CRC Press, Boca Raton, FL
Sundberg JP, Boggess D (2000) Systematic characterization of mouse mutations. CRC Press, Boca Raton, FL
Sundberg JP, Ichiki T (2005a) Common diseases found in inbred strains of laboratory mice. In: Sundberg JP, Ichiki T (eds) Handbook on genetically engineered mice. CRC Press, Boca Raton, FL, pp 223–229
Sundberg JP, Ichiki T (eds) (2005b) Handbook on genetically engineered mice. CRC Press, Boca Raton, FL
Sundberg BA, Sundberg JP (1990) A database system for small diagnostic laboratories. Lab Anim 19:55–58
Sundberg BA, Sundberg JP (2000) Medical record keeping for project analysis. In: Sundberg JP, Boggess D (eds) Systematic approach to evaluation of mouse mutations. CRC Press, Boca Raton, FL, pp 47–55
Sundberg JP, Haschek WM, Hackman RC, HogenEsch H (2004) Developing a comprehensive mouse pathology program. Comp Med 54:615–619
Sundberg JP, Hackman RC, HogenEsch H, Nikitin AY, Ward JM (2007) Training mouse pathologists: five years of pathology of mouse models of human disease workshops. Toxicol Pathol 35:447–448
Swertz MA, DeBrock EO, VanHijum SA, DeJong A, Buist G et al (2004) Molecular Genetics Information System (MOLGENIS): alternatives in developing local experimental genomics databases. Bioinformatics 20:2075–2083
Valli T, Barthold SW, Ward JE, Brayton C, Nikitin A et al (2007) Over 60% of NIH extramural funding involves animal-related research. Vet Pathol 44:962–963
Ward J, Mahler J, Maronpot R, Sundberg JP (2000) Pathology of genetically engineered mice. Iowa State University Press, Ames, IA
Acknowledgments
This work was supported by grants from the Ellison Medical Foundation, the National Institutes of Health (CA34196, CA089713, and AG025707), and the Commission of the European Community, Framework Programme 6 contract No. LSH-2005-1.1.3-2.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License ( https://creativecommons.org/licenses/by-nc/2.0 ), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Sundberg, J.P., Sundberg, B.A. & Schofield, P. Integrating mouse anatomy and pathology ontologies into a phenotyping database: Tools for data capture and training. Mamm Genome 19, 413–419 (2008). https://doi.org/10.1007/s00335-008-9123-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00335-008-9123-z