
Abstract
The effective large-scale properties of materials with random heterogeneities on a small scale are typically determined by the method of representative volumes: a sample of the random material is chosen—the representative volume—and its effective properties are computed by the cell formula. Intuitively, for a fixed sample size it should be possible to increase the accuracy of the method by choosing a material sample which captures the statistical properties of the material particularly well; for example, for a composite material consisting of two constituents, one would select a representative volume in which the volume fraction of the constituents matches closely with their volume fraction in the overall material. Inspired by similar attempts in materials science, Le Bris, Legoll and Minvielle have designed a selection approach for representative volumes which performs remarkably well in numerical examples of linear materials with moderate contrast. In the present work, we provide a rigorous analysis of this selection approach for representative volumes in the context of stochastic homogenization of linear elliptic equations. In particular, we prove that the method essentially never performs worse than a random selection of the material sample and may perform much better if the selection criterion for the material samples is chosen suitably.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The most widely employed method for determining the effective large-scale properties of a material with random heterogeneities on a small scale is the method of representative volumes. It basically proceeds by taking a small sample of the material—a “representative volume element” (RVE)—and determining the properties of the sample by the cell formula. The criteria for the choice of the representative volume have been the subject of an ongoing debate; while in principle increasing the size of the material sample increases the accuracy of the approximation of the material properties, this comes at a correspondingly larger computational cost. It has been conjectured that for a fixed size of the material sample, selecting a material sample which captures certain statistical properties of the material in a particularly good way may be beneficial; for example, for a composite material consisting of two constituent materials, one would try to select a material sample for which the volume fraction of each constituent material within the sample matches the overall volume fraction of this constituent in the composite as closely as possible (see Fig. 1). Alternatively, for linear materials one might try to match the averaged material coefficient in the sample with the average taken over the full material. There have been efforts in materials science and mechanics towards replicating further statistical properties of the material in a representative volume, an approach called “special quasirandom structures” [82, 83, 86] or “statistically similar representative volume elements” [15,16,17,18, 28, 81]. A particularly successful approach in this direction has been developed for linear materials by Le Bris et al. [64]; their method proceeds by considering a large number of material samples, evaluating one or more cheaply computable statistical quantities of the samples (like, for example, the spatial average of the coefficient), and then choosing the sample as the representative volume that is most representative for the material as measured by these quantities. In the present work, in the context of stochastic homogenization of linear elliptic PDEs we provide the first rigorous justification of these approaches.Footnote 1

Among the six depicted material samples, the method of Le Bris, Legoll, and Minvielle in its simplest realization would choose either the first sample or the fifth sample as the representative volume element and discard the others, as the volume fraction of the inclusions in the first and the fifth sample is closest to the overall material average. Note that in the depicted material samples the volume fraction of the inclusions is proportional to the number of inclusions, as all inclusions are of equal size. For a better illustration of the method, both the size and the number of the depicted samples have been chosen much smaller than in actual computations
For materials with random heterogeneities on small scales, the approximation of the effective material coefficient by the method of representative volumes is a random quantity itself, as the outcome depends on the sample of the material. In the setting of linear elliptic PDEs with random coefficient fields—which corresponds to the setting of heat conduction, electrical currents, or electrostatics in a material with random microstructure—Gloria and Otto [48, 53, 54] have investigated the structure of the error of the approximation of the effective material coefficient by the method of representative volumes: the leading-order contribution to the error (with respect to the size of the RVE) consists of random fluctuations; in expectation the approximation of effective coefficients by the method of representative volumes is accurate to higher order, that is the systematic error of the RVE method is of higher order.Footnote 2 For a given size of the RVE—which corresponds to a fixed computational effort—the accuracy of the RVE method may therefore be increased significantly by reducing the variance of the approximations of the effective coefficient. It is precisely such a reduction of the variance by which the selection approach for representative volumes of Le Bris et al. [64] achieves its gain in accuracy.
For linear elliptic PDEs with random coefficients and moderate ellipticity contrast, the reduction of the variance by the ansatz of Le Bris et al. [64] is particularly remarkable; by selecting the representative volume according to the criterion that the averaged coefficient in the RVE should be particularly close to the averaged coefficient in the overall material, in numerical examples with ellipticity contrast \(\sim 5\) they observed a variance reduction by a factor of \(\sim 10\). Going beyond this simple selection criterion, they devised a criterion based on an expansion of the effective coefficient in the regime of small ellipticity contrast, which numerically achieves a remarkable variance reduction factor of \(\sim 60\) even for a moderate ellipticity contrast \(\sim 5\). Note that this basically corresponds to the gain of about one order of magnitude in accuracy for a negligible additional computational cost and implementation effort.
However, the analysis of the selection approach for representative volumes has been restricted to the one-dimensional setting [64], in which the homogenization of linear elliptic PDEs is linear in the inverse coefficient and therefore independent of the geometry of the material. Besides the highly nonlinear dependence of the effective coefficient on the heterogeneous coefficient field in dimensions \(d\geqq 2\), one of the main challenges in the analysis of the selection method for representative volumes is the fact that it is only expected to increase the accuracy by a (though often very large) constant factor, at least for a fixed set of statistical quantities by which the selection is performed. At the same time, the available error estimates for the representative volume element method in stochastic homogenization are only optimal up to constant factors. For this reason, the analysis of the selection approach for representative volumes necessitates a fine-grained analysis of the structure of fluctuations in stochastic homogenization.
1.1 Stochastic Homogenization of Linear Elliptic PDEs: A Brief Outline
The subject of the present contribution is the rigorous justification of the selection method for representative volumes by Le Bris et al. [64] in the context of linear elliptic equations
with random coefficient fields a on \(\mathbb {R}^d\) for arbitrary spatial dimension d. Note that this setting describes, for example, heat conduction or electrostatics in a random material. Our assumptions on the probability distribution of the coefficient field a are standard in the theory of stochastic homogenization; we assume just uniform ellipticity and boundedness, stationarity, and finite range of dependence (see conditions (A1)–(A3) below). In particular, our analysis includes the case of a two-material composite with random non-overlapping inclusions as depicted in Fig. 1.
The theory of stochastic homogenization of linear elliptic PDEs predicts that for coefficient fields with only short-range correlations on a scale \(\varepsilon \ll 1\) the solution u to the equation with random coefficient field (1) may be approximated by the solution \(u_{\mathsf {hom}}\) of an effective equation of the form
where \(a_{\mathsf {hom}}\in \mathbb {R}^{d\times d}\) is a constant effective coefficient which describes the effective behavior of the material. In this context of linear materials, the method of representative volumes is employed to compute the effective coefficient \(a_{\mathsf {hom}}\).
Let us describe the method of representative volumes for the approximation of the effective material coefficient \(a_{\mathsf {hom}}\) in more detail. It proceeds by choosing a sample of the material, say, a cube with side length \(L\varepsilon \) for some \(L\gg 1\), uniformly at random. Roughly speaking—for the moment passing silently over the question of boundary conditions—by solving the equation for the homogenization corrector \(\phi _i\) associated with the i-th coordinate direction on the representative volume
(\(e_i\in \mathbb {R}^d\) denoting the i-th vector of the standard basis) one may obtain an approximation \(a^{{\text {RVE}}}\) for the effective coefficient \(a_{\mathsf {hom}}\) in terms of the averaged fluxes

This expression is also known in homogenization as the cell formula. As already mentioned before, the approximation \(a^{{{\text {RVE}}}}\) for the effective material coefficient \(a_{\mathsf {hom}}\) is a random variable itself, as it depends on the realization of the random coefficient field a on the sample volume \([0,L\varepsilon ]^d\). It has been proven by Gloria and Otto [54, 55] and also observed in numerical computations that the main contribution to the error of the RVE method is caused by the random fluctuations of the approximation \(a^{{\text {RVE}}}\), while the systematic error is of higher order: For spatial dimensions \(d\geqq 1\) one has
but
As a consequence, a reduction of the fluctuations of the approximations \(a^{{\text {RVE}}}\) would lead to an increase in accuracy of the approximation for the effective coefficient \(a_{\mathsf {hom}}\). It has been observed numerically by Le Bris et al. [64], and shall be proven below rigorously, that the selection approach for representative volumes achieves its gain in accuracy precisely by reducing the fluctuations of the approximations for the effective coefficients.
1.2 Informal Summary of Our Main Results
In the present work, we prove that in the setting of stochastic homogenization of linear elliptic equations the selection approach for representative volumes by Le Bris et al. [64]
-
essentially never performs worse than a completely random selection of the representative volume element, but may perform much better for suitable selection criteria,
-
basically maintains the order of the systematic error of the approximation for the effective coefficient, and
-
reduces also the error in the approximation for the effective coefficient that may occur with a given low probability, that is reduces also the “outliers” of the approximation for the effective coefficient.
As mentioned before, in the setting of linear elliptic PDEs the method of representative volumes is employed to obtain an approximation \(a^{{\text {RVE}}}\) for the effective (homogenized) coefficient \(a_{\mathsf {hom}}\). The role of “material samples” is assumed by realizations of the random coefficient field \(a:[0,L\varepsilon ]^d\rightarrow \mathbb {R}^{d\times d}\), on which the computation of the approximations \(a^{{\text {RVE}}}\) is based.
The selection approach for representative volumes proposed in [64] then proceeds as follows: at first, one or more statistical quantities \(\mathcal {F}\) are chosen which assign a real number \(\mathcal {F}(a)\in \mathbb {R}\) to any realization \(a:[0,L\varepsilon ]^d \rightarrow \mathbb {R}^{d\times d}\). Note that the simplest statistical quantity proposed in [64] is the spatial average  . Next, one considers a sequence of independent samples of the random coefficient field until a sample meets the selection criterion
. Next, one considers a sequence of independent samples of the random coefficient field until a sample meets the selection criterion
for some chosen parameter \(\delta \) with \(CL^{-d/2} |\log L|^C \leqq \delta \leqq 1\). Finally, the approximation for the effective coefficient is computed by solving the equation for the homogenization corrector (3) and using the cell formula (4) for this sample of the random coefficient field.
To give a flavor of our main result, let us formulate it informally in the case of a single statistical quantity \(\mathcal {F}(a)\). We denote the approximation for the effective coefficient by the standard representative volume element method (without selection of material samples) by \(a^{{\text {RVE}}}\) and the approximation for the effective coefficient by the selection approach for representative volumes by \(a^{{\text {sel-RVE}}}\). In this case, our main theorems Theorems 2 and 3 may be summarized as follows:
-
The systematic error of the approximation \(a^{{\text {sel-RVE}}}\) is essentially (up to powers of \(\log L\) and some prefactors) of the same order as the systematic error of the standard representative volume element method \(a^{{\text {RVE}}}\): We have
$$\begin{aligned} \big |\mathbb {E}\big [a^{{\text {sel-RVE}}}\big ]-a_{\mathsf {hom}}\big | \leqq \frac{C\kappa ^{3/2}}{\delta } L^{-d} |\log L|^C. \end{aligned}$$The quantity \(\kappa \) will be discussed below.
-
The fluctuations of the approximation \(a^{{\text {sel-RVE}}}\) are reduced by the fraction of the variance of \(a^{{\text {RVE}}}\) that is explained by \(\mathcal {F}(a)\). More precisely, we derive the estimate
$$\begin{aligned} \frac{{{\text {Var}}~}a^{{\text {sel-RVE}}}}{{{\text {Var}}~}a^{{\text {RVE}}}} \leqq&1-(1-\delta ^2)|\rho _{\mathcal {F}(a),a^{{\text {RVE}}}}|^2 +\frac{C \kappa ^{3/2} r_{{\text {Var}}}}{\delta } L^{-d/2} |\log L|^C \end{aligned}$$where \(\rho _{\mathcal {F}(a),a^{{\text {RVE}}}} \in [-1,1]\) denotes the correlation coefficient of \(\mathcal {F}(a)\) and \(a^{{\text {RVE}}}\), given by
$$\begin{aligned} \rho _{\mathcal {F}(a),a^{{\text {RVE}}}}:= \frac{{\text {Cov}}[a^{{\text {RVE}}},\mathcal {F}(a)]}{\sqrt{{{\text {Var}}~}\mathcal {F}(a) {{\text {Var}}~}a^{{\text {RVE}}}}}, \end{aligned}$$and where \(r_{{\text {Var}}}:=\frac{L^{-d}}{{{\text {Var}}~}a^{{\text {RVE}}}}\) denotes the ratio between the expected order of fluctuations of \(a^{{\text {RVE}}}\) and the actual magnitude of fluctuations. Note that the last term in the estimate on \({{\text {Var}}~}a^{{\text {sel-RVE}}}\) converges to zero as the size L of the representative volume increases.
-
The probability of “outliers” is reduced by the selection method just as suggested by the variance reduction, at least in an “intermediate” region between the “bulk” and the “outer tail” of the probability distribution: One has a moderate-deviations-type estimate of the form
$$\begin{aligned}&\mathbb {P}\Bigg [\frac{\big |a^{{\text {sel-RVE}}}_{ij}-a_{{\mathsf {hom}},ij}\big |}{\sqrt{\big (1-|\rho _{\mathcal {F}(a),a^{{\text {RVE}}}}|^2+\delta ^2\big ){{\text {Var}}~}a^{{\text {RVE}}}_{ij}+L^{-d/2-\beta }}}\geqq s\Bigg ]\\&\quad \leqq \Big (1+\frac{C\delta }{\sqrt{1-|\rho |^2} s}+\frac{C}{\delta L^\beta }\Big )\mathbb {P}\big [|\mathcal {N}_1|\geqq s\big ]+\frac{C}{\delta }\exp (-L^{2\beta }) \end{aligned}$$for any \(s\geqq C\max \{(1-|\rho |^2)^{1/2} \delta ^{-1},\delta (1-|\rho |^2)^{-1/2}\}\) and some \(\beta =\beta (d)>0\), where \(\mathcal {N}_1\) denotes the centered normal distribution with unit variance.
-
In the above bounds, \(\kappa :=(1-|\rho _{\mathcal {F}(a),a^{{\text {RVE}}}}|^2)^{-1}\) denotes (essentially) the condition number of the covariance matrix \({{\text {Var}}~}(a^{{\text {RVE}}},\mathcal {F}(a))\). For the case that the correlation \(|\rho _{\mathcal {F}(a),a^{{\text {RVE}}}}|\) is close to one, we derive bounds which are independent of \(\kappa \) but come at the cost of a lower rate of convergence in L, namely
$$\begin{aligned} \big |\mathbb {E}\big [a^{{\text {sel-RVE}}}\big ]-a_{\mathsf {hom}}\big | \leqq \frac{C}{\delta } L^{-d/2-d/8} |\log L|^C \end{aligned}$$and
$$\begin{aligned} \frac{{{\text {Var}}~}a^{{\text {sel-RVE}}}}{{{\text {Var}}~}a^{{\text {RVE}}}} \leqq&1-(1-\delta ^2)\big |\rho _{\mathcal {F}(a),a^{{\text {RVE}}}}\big |^2 +\frac{C r_{{\text {Var}}}}{\delta } L^{-d/8} |\log L|^C. \end{aligned}$$
Our estimate on the variance reduction achieved by the selection approach for representative volumes is implicit in the sense that it is determined by the correlation coefficient
In fact, the failure of the correlation coefficient \(\rho _{\mathcal {F}(a),a^{{\text {RVE}}}}\) to be nonzero also implies the failure of gaining accuracy by the selection approach for the representative volumes (see Theorem 4): In such a case of vanishing correlation, the method of Le Bris et al. [64] is not superior (but essentially also not inferior) to the standard method of choosing a representative volume randomly.
This raises the question whether such a degeneracy of the correlation coefficient can occur for “natural” choices of the statistical quantity \(\mathcal {F}(a)\). In Theorem 4, we shall prove that even for a “natural” choice like  there is a priori no guarantee that there is a nonzero correlation between \(a^{{\text {RVE}}}\) and \(\mathcal {F}(a)\): We construct an example of a probability distribution of a for which the covariance of \(a^{{\text {RVE}}}\) and the average of the coefficient field
there is a priori no guarantee that there is a nonzero correlation between \(a^{{\text {RVE}}}\) and \(\mathcal {F}(a)\): We construct an example of a probability distribution of a for which the covariance of \(a^{{\text {RVE}}}\) and the average of the coefficient field  in fact vanishes, while the variances
in fact vanishes, while the variances  and \({{\text {Var}}~}a^{{\text {RVE}}}\) are nondegenerate.
and \({{\text {Var}}~}a^{{\text {RVE}}}\) are nondegenerate.
However, the failure of the variance reduction approaches to effectively reduce the variance is presumably limited to rather artificial examples: we prove that the covariance of \(a^{{\text {RVE}}}\) and the average of the coefficient field  is positive for coefficient fields which are obtained from iid random variables by applying a “monotone” function, see Proposition 5.
is positive for coefficient fields which are obtained from iid random variables by applying a “monotone” function, see Proposition 5.

For a multivariate Gaussian probability distribution, conditioning on the event of one variable being close to its expectation reduces the variance of the other variable, provided that the two random variables are nontrivially correlated. In our setting, conditioning on the event “spatial average of coefficient field is close to its expectation” reduces the variance of the random variable “approximation for the effective conductivity” \(a^{{\text {RVE}}}\), as their joint probability distribution is close to a multivariate Gaussian
1.3 Outline of Our Strategy
The basic idea underlying our analysis of the selection approach for representative volumes is the observation that the joint probability distribution of the approximation for the effective coefficient \(a^{{\text {RVE}}}\) and one or more statistical quantities \(\mathcal {F}(a)\) like the average of the coefficient field  is close to a multivariate Gaussian, up to an error of the order \(L^{-d} |\log L|^C\) in a suitable notion of distance between probability measures. The selection of representative volumes by the criterion (7)—which amounts to conditioning on the event \(|\mathcal {F}(a)-\mathbb {E}[\mathcal {F}(a)]|\leqq \delta \sqrt{{{\text {Var}}~}\mathcal {F}(a)}\)—then reduces the variance of the probability distribution of \(a^{{\text {RVE}}}\) by the variance explained by the statistical quantity \(\mathcal {F}(a)\), up to error terms due to the deviation of the probability distribution from a multivariate Gaussian and the non-perfectness of the conditioning \(\delta >0\), see Fig. 2. Note that for an ideal multivariate Gaussian distribution, the expected value of the approximation \(a^{{\text {RVE}}}\) would be left unchanged under conditioning since the criterion (7) is symmetric around \(\mathbb {E}[\mathcal {F}(a)]\), that is the conditioning would not introduce a bias. As a consequence, for our approximate multivariate Gaussian \((a^{{\text {RVE}}},\mathcal {F}(a))\) the expectation of \(a^{{\text {RVE}}}\) is changed under conditioning only by the distance of our probability distribution to a multivariate Gaussian, which is a higher-order term. Note that both the reduction of the variance by conditioning and the estimate on the bias introduced by the conditioning rely crucially on the fact that our probability distribution is close to a multivariate Gaussian (and not another probability distribution); it is obvious from the picture in Fig. 2 that a probability distribution other than a multivariate Gaussian could introduce a large bias under conditioning and even an increase in variance. Our analysis of the selection approach for representative volumes by Le Bris et al. [64] is a first practical application of the beautiful theory of fluctuations in stochastic homogenization, which has been developed in recent years and which our work both draws ideas from and contributes to.
is close to a multivariate Gaussian, up to an error of the order \(L^{-d} |\log L|^C\) in a suitable notion of distance between probability measures. The selection of representative volumes by the criterion (7)—which amounts to conditioning on the event \(|\mathcal {F}(a)-\mathbb {E}[\mathcal {F}(a)]|\leqq \delta \sqrt{{{\text {Var}}~}\mathcal {F}(a)}\)—then reduces the variance of the probability distribution of \(a^{{\text {RVE}}}\) by the variance explained by the statistical quantity \(\mathcal {F}(a)\), up to error terms due to the deviation of the probability distribution from a multivariate Gaussian and the non-perfectness of the conditioning \(\delta >0\), see Fig. 2. Note that for an ideal multivariate Gaussian distribution, the expected value of the approximation \(a^{{\text {RVE}}}\) would be left unchanged under conditioning since the criterion (7) is symmetric around \(\mathbb {E}[\mathcal {F}(a)]\), that is the conditioning would not introduce a bias. As a consequence, for our approximate multivariate Gaussian \((a^{{\text {RVE}}},\mathcal {F}(a))\) the expectation of \(a^{{\text {RVE}}}\) is changed under conditioning only by the distance of our probability distribution to a multivariate Gaussian, which is a higher-order term. Note that both the reduction of the variance by conditioning and the estimate on the bias introduced by the conditioning rely crucially on the fact that our probability distribution is close to a multivariate Gaussian (and not another probability distribution); it is obvious from the picture in Fig. 2 that a probability distribution other than a multivariate Gaussian could introduce a large bias under conditioning and even an increase in variance. Our analysis of the selection approach for representative volumes by Le Bris et al. [64] is a first practical application of the beautiful theory of fluctuations in stochastic homogenization, which has been developed in recent years and which our work both draws ideas from and contributes to.
The underlying reason for the convergence of the joint probability distribution of \(a^{{\text {RVE}}}\) and one or more functionals \(\mathcal {F}(a)\) towards a multivariate Gaussian is a central limit theorem for suitable collections of vector-valued random variables. We show that the approximation \(a^{{\text {RVE}}}\) for the effective coefficient \(a_{\mathsf {hom}}\)—and also the functionals \(\mathcal {F}(a)\) that are used in the work of Le Bris et al. [64]—may be written as a sum of random variables with a local dependence structure with multiple levels, see Definition 6 and Proposition 7. For such sums of vector-valued random variables with multilevel local dependence, a proof of quantitative normal approximation is provided in the companion article [43] (see also Theorem 9 below). To the best of our knowledge such quantitative normal approximation results were previously known only for sums of random variables with local dependence structure [33, 34, 80] (corresponding more or less to just the lowest level of random variables in Fig. 4 below), a framework into which the approximation for the effective coefficient \(a^{{\text {RVE}}}\) does not fit. Note that the sharp boundaries of the region defined by the selection criterion (7) (see also the sharp boundaries in Fig. 2) necessitate the use of a rather strong (though standard) distance between probability measures for our quantitative normal approximation result (see Definition 8); in particular, a stronger notion of distance between probability measures than the 1-Wasserstein distance must be used.
As a by-product, our work also provides a proof of quantitative normal approximation for \(a^{{\text {RVE}}}\) in a different setting than available in the literature so far. To the best of our knowledge, the results on quantitative normal approximation for \(a^{{\text {RVE}}}\) in the literature always rely on an assumption that the coefficient field a is obtained as a function of iid random variables [39, 52, 77] or that the probability distribution of a is subject to a second-order Poincaré inequality like in [38]. In contrast, our result holds under the assumption of finite range of dependence, in which to the best of our knowledge only a qualitative normal approximation result had been known [6].
The companion article [43] also provides a result on moderate deviations in the sense of Kramers for sums of random variables with multilevel local dependence structure, see Theorem 10. Our result on the reduction of the error by the selection approach for representative volumes in the case of unlikely events (Theorem 3) is based on this moderate deviations theorem.
Our counterexample for the variance reduction—which shows that even “natural” statistical quantities like the spatial average  do not necessarily explain a positive fraction of the variance of \(a^{{\text {RVE}}}\)—is based on the nonlinear dependence of the effective coefficient in periodic homogenization on the underlying coefficient field. More precisely, our counterexample consists of an interpolation between a standard random checkerboard and a random checkerboard with two types of tiles, one tile type being a constant coefficient field and one tile type being a second-order laminate microstructure; see Section 6 for details of the construction.
do not necessarily explain a positive fraction of the variance of \(a^{{\text {RVE}}}\)—is based on the nonlinear dependence of the effective coefficient in periodic homogenization on the underlying coefficient field. More precisely, our counterexample consists of an interpolation between a standard random checkerboard and a random checkerboard with two types of tiles, one tile type being a constant coefficient field and one tile type being a second-order laminate microstructure; see Section 6 for details of the construction.
1.4 Computation of Effective Properties of Random Materials: A More Detailed Look
In the homogenization of periodic linear materials—that is in the homogenization of the linear elliptic PDE (1) with periodic coefficient field a in the sense \(a(x)=a(x+\varepsilon k)\) for all \(k\in \mathbb {Z}^d\)—it is possible to compute the effective coefficient \(a_{\mathsf {hom}}\) by exploiting the periodicity of the coefficient field, basically reducing the problem to solving a PDE—the PDE for the homogenization corrector—on a single periodicity cell: for a period of length \(\varepsilon \), the effective coefficient is given by the cell formula

with the homogenization corrector \(\phi _i\) defined as the unique \(\varepsilon \)-periodic solution with zero average to the PDE
As a consequence, in periodic homogenization the numerical computation of the effective coefficient \(a_{\mathsf {hom}}\) typically requires only modest effort.
In contrast, in stochastic homogenization this simplification is no longer possible due to the absence of a periodic structure in the random coefficient field \(a^{\mathbb {R}^{d}}:\mathbb {R}^{d}\rightarrow \mathbb {R}^{d\times d}\) and the computation of the effective coefficient becomes a computationally costly problem. The effective coefficient in stochastic homogenization is given by the infinite volume limit cell formulaFootnote 3

with \(\phi _i^{{\text {L,Dir}}}\) denoting the solution to the corrector problem with Dirichlet boundary conditions
In practice, in order to approximate the effective coefficient \(a_{\mathsf {hom}}\) a representative volume \([0,L\varepsilon ]^d\) of finite size must be chosen. However, the approximation of the effective coefficient by the standard cell formula with Dirichlet boundary conditions for the corrector

is only of first-order accuracy \(\mathbb {E}[|a^{{\text {RVE}}}_{{\text {Dir}}}-a_{\mathsf {hom}}|^2]^{1/2}\lesssim L^{-1}\) due to the presence of a boundary layer: the artificial Dirichlet boundary condition leads to the creation of a boundary layer in an \(O(\varepsilon )\)-neighborhood of the boundary \(\partial [0,L\varepsilon ]^d\). The limitation to first-order accuracy is present even in the systematic error \(\mathbb {E}[a^{{\text {RVE}}}]-a_{\mathsf {hom}}\). Note that while replacing the volume average in the cell formula by an average taken strictly in the interior of the representative volume typically increases the accuracy [84], for general probability distributions it does not increase the order of convergence due to global effects of the boundary layer. To achieve the convergence rates \(|\mathbb {E}[a^{{\text {RVE}}}]-a_{\mathsf {hom}}|\lesssim L^{-d}|\log L|^d\) and \(\mathbb {E}[|a^{{\text {RVE}}}-a_{\mathsf {hom}}|^2]^{1/2} \lesssim L^{-d/2}\) stated in (6) and (5), the boundary layer phenomenon must necessarily be addressed by the use of a more careful approximation technique than the method of correctors with Dirichlet boundary data.
One possibility of avoiding the creation of boundary layers is the use of a so-called “periodization” of the probability distribution: Given a probability distribution of coefficient fields \(a^{\mathbb {R}^d}\), one first fixes the size \(L\varepsilon \) of the desired representative volume and then attempts to construct a probability distribution of \(L\varepsilon \)-periodic coefficient fields a such that the law of \(a|_{x+[0,\frac{1}{2} L\varepsilon ]^d}\) (i. e the law of a restricted to some box of half the size of the representative volume) coincides with the law of \(a^{\mathbb {R}^d}|_{x+[0,\frac{1}{2} L\varepsilon ]^d}\) for any \(x\in \mathbb {R}^d\). For one realization of the periodized probability distribution of coefficient fields a one may then solve the corrector equation \(-\nabla \cdot (a(e_i+\nabla \phi _i))=0\) with periodic boundary conditions on \(\partial [0,L\varepsilon ]^d\) and define the approximation \(a^{{\text {RVE}}}\) for the effective coefficient \(a_{\mathsf {hom}}\) as

This approximation \(a^{{\text {RVE}}}\) then has the desired approximation properties (5) and (6). Note that this construction requires the knowledge of the probability distribution of \(a^{\mathbb {R}^{d}}\) and must be done in a case-by-case basis; it is therefore not feasible in all practical situations.
To give an example, random non-overlapping inclusions like in Fig. 1 may be constructed by considering a Poisson point process on \(\mathbb {R}^d\times [0,1]\), ordering the points \((x_k,y_k)\in \mathbb {R}^d\times [0,1]\) with respect to their last coordinate \(y_k\), and then successively placing inclusions in \(\mathbb {R}^d\) centered at the \(x_k\) and with diameter \(\varepsilon \) if the “previous” points \(x_l\), \(l<k\), have a distance of at least \(\varepsilon \) from \(x_k\) (that is \(|x_l-x_k|\geqq \varepsilon \)). The result of such a construction is shown in Fig. 3a. For this probability distribution, one may define a periodization in a natural way by considering a Poisson point process on \([0,L\varepsilon )^d\times [0,1]\) and defining an \(L\varepsilon \)-periodic coefficient field with non-overlapping inclusions in the obvious way, replacing the Euclidean distance \(|x_l-x_k|\) by the periodicity-adjusted distance \(|x_l-x_k|_{{{\text {per}}}}:= \inf _{z\in \mathbb {Z}^d} |x_l-x_k+L\varepsilon z|\). A sample from the periodized probability distribution is shown in Fig. 3b.

a An example of random spherical inclusions distributed according to a Poisson point process, with overlapping inclusions removed. b A sample from the corresponding periodization of the probability distribution (rescaled); the periodicity cell is indicated by black lines
If no periodization of the probability distribution is available—for example if only samples from the probability distribution are available and the underlying probability distribution is not known, like in applications where one has access to samples of the materials—, one has to resort to an alternative means of increasing the rate of convergence of the method of representative volumes. One feasible option is to “screen” the effect of the boundary by introducing a “massive” term in the PDE for the homogenization corrector [24, 47, 54]: Fixing a scale \(\sqrt{T} \sim \frac{L}{\log L}\), one replaces the equation for the homogenization corrector by the PDE
and approximates the effective coefficient \(a_{\mathsf {hom}}\) by
where \(\eta \) is a smooth nonnegative weight supported in the slightly smaller box \([\frac{1}{8} L\varepsilon ,(1-\frac{1}{8})L\varepsilon ]^d\). In up to four spatial dimensions \(d\leqq 4\), this approximation also admits error estimates of the form
and
Due to the already substantial length of the present paper, we shall limit ourselves to the analysis of the selection approach for representative volumes in the context of periodizations of the probability distribution and defer the analysis of the screening approach to a future work.
Generally speaking, in the method of representative volumes the equation for the homogenization corrector may be solved by any numerical algorithm that is feasible for the given size of the representative volume; for example, standard finite element methods may be employed for representative volumes of moderate size, while for very large representative volumes one may use appropriate instances of modern computational homogenization methods like the multiscale finite element method, heterogeneous multiscale methods, and related approaches (see for example [1, 14, 29, 40, 60, 61, 71]) or the local orthogonal decomposition method by Målqvist and Peterseim [70].
Note that besides the modern numerical homogenization methods—which are in principle applicable to any elliptic PDE involving a heterogeneous coefficient field—there have been numerous numerical works on the more specific problem of the approximation of effective coefficients in stochastic homogenization, see for example [13, 32, 41, 42, 62, 72, 79].
1.5 The Selection Approach for Representative Volumes by Le Bris, Legoll and Minvielle
Let us describe the selection approach for representative volumes by Le Bris et al. [64] in more detail. The selection approach for representative volumes achieves its gain in accuracy of approximations \(a^{{\text {RVE}}}\) for the effective coefficient \(a_{\mathsf {hom}}\) (as compared to the standard representative volume element method with completely random choice of the material sample) by selecting only those realizations of the random coefficient field \(a|_{[0,L\varepsilon ]^d}\) which capture some important statistical properties of the coefficient field a in an exceptionally good way. For example, in the simplest setting Le Bris et al. [64] propose to restrict one’s attention to realizations of the coefficient field a for which the average on \([0,L\varepsilon ]^d\) is exceptionally close to its expected value in the sense that

for some \(\delta \ll 1\). Note that for generic realizations of a only

is true by the central limit theorem for the averages  and the finite range of dependence \(\varepsilon \).
and the finite range of dependence \(\varepsilon \).
On a numerical level, such a selection approach typically provides an increase in computational efficiency if the accuracy is indeed increased by conditioning on the event (9): usually, the most expensive step in the computation of the approximations \(a^{{\text {RVE}}}\) is the computation of the homogenization corrector as the solution to the PDE (3). In contrast, the generation of random coefficient fields a and the evaluation of the average of a is typically cheap. Therefore it is often worth generating about \(\frac{1}{\delta }\) independent realizations of a to obtain on average one realization of a which satisfies (9); for this single realization, the corrector equation (3) is solved numerically and the approximation \(a^{{\text {RVE}}}\) for the effective coefficient is computed. This strategy is also applicable to situations in which the probability distribution of the coefficient field is not known, but one has only access to a large number of samples of the coefficient field, like in applications in which one has access to data from actual material samples.
The selection criterion (9) based on the average of the coefficient field in the material sample is the first out of two selection criteria proposed by Le Bris et al. [64]. In order to reduce the variance of \(a^{{\text {RVE}}}\) further, they propose to consider several such statistical quantities at the same time, for example in addition to the spatial average

the quantities

for some (approximation of the) solution \(v_i\) to the constant-coefficient equation
require that all of these statistical quantities be close to their expectation at the same time. The quantities (10) arise as a second-order correction to the effective conductivity \(a^{{\text {RVE}}}\) in the expansion in the regime of small ellipticity contrast: Expanding the homogenization corrector \(\phi _i\) and the approximate effective conductivity \(a^{{\text {RVE}}}\) as a power series in \(\nu \) for the family of coefficient fields
we deduce
with \(\phi _i^0\equiv 0\), \(\phi _i^1=v_i\), and \(\phi _i^2\) defined as the solution to another PDE. As a consequence, for the approximation of the effective conductivity we obtain

where in the last step we have used the periodicity of \(\phi _i^2\). To see that the contribution of \(v_i\) is actually of second order in \(\nu \), one uses again \(a={\text {Id}}+\nu {\hat{a}}\) and the periodicity of \(v_i\).
By selecting the representative volumes by the two criteria (9) and
at the same time, in the model problem of the random checkerboard with an ellipticity ratio of 5 Le Bris, Legoll, and Minvielle were able to reduce the variance of the approximations \(a^{{\text {sel-RVE}}}\) for the effective conductivity by a factor of 60, compared to the approximations \(a^{{\text {RVE}}}\) by the standard representative volume element method.
Another remarkable feature of the selection approach for representative volumes by Le Bris, Legoll, and Minvielle is its compatibility with the vast majority of numerical homogenization methods: As the selection approach for representative volumes operates at the level of the choice of the coefficient field a, it may be combined with essentially any numerical discretization method for the corrector problem (59). Note that there exist many numerical homogenization methods that are particularly well-adapted to certain geometries of the microstructure; the selection approach for representative volumes may be employed in most of these methods to achieve a further speedup.
The selection approach for representative volumes is only one out of several variance reduction concepts in the context of stochastic homogenization: Blanc et al. [22, 23, 25] have succeeded in reducing the variance by the method of antithetic variables; note that however for this approach the achievable variance reduction factor is much more limited. The method of control variates has also been demonstrated to be successful in the context of the computation of effective coefficients in stochastic homogenization [25, 65].
1.6 A Brief Overview of Quantitative Stochastic Homogenization
For the sake of completeness, let us give a short overview of the tremendous progress that has been achieved in the quantitative theory of stochastic homogenization in recent years. The earliest (non-optimal) quantitative homogenization results for linear elliptic equations are due to Yurinskiĭ [85]. A decade later, Naddaf and Spencer [76] introduced the use of spectral gap inequalities in stochastic homogenization and derived optimal fluctuation estimates in the regime of small ellipticity contrast \(||a-{\text {Id}}||_{L^\infty } \ll 1\), that is in a perturbative setting. Another decade later, Caffarelli and Souganidis derived the first—though only logarithmic—rates of convergence for nonlinear stochastic homogenization problems [31]. Gloria and Otto [53, 54] and Gloria et al. [49] succeeded in the derivation of optimal homogenization rates for discrete linear elliptic equations with i. i. d. random conductances. Subsequently, these results were generalized to elliptic equations on \(\mathbb {R}^d\) and correlated probability distributions by Gloria et al. [50, 51]. For coefficient fields a whose correlations decay quickly on scales larger than \(\varepsilon >0\), these quantitative estimates for the homogenization error—that is, for the difference between the solutions to the PDE with the random coefficient field (1) and its homogenized approximation (2)—read
with \(\mathcal {C}(a)\) satisfying stretched exponential moment bounds and for suitable \(p=p(d)\). Armstrong and Smart [9] were the first to obtain power-law rates of convergence for nonlinear equations, deriving and employing an Avellanda–Lin type regularity estimate [12]; see also Armstrong and Mourrat [8]. Their estimates also come with optimal—almost Gaussian—stochastic moment bounds. Recently, the progress in stochastic homogenization culminated in the derivation of the optimal homogenization rates with optimal stochastic moment bounds by Armstrong, et al. [5] and Gloria and Otto [55]: For finite range of dependence \(\varepsilon \), a quantitative error bound for the homogenization error of the form (12) holds true with a random constant \(\mathcal {C}(a)\) with almost Gaussian moments \(\mathbb {E}[\exp (\mathcal {C}(a)^{2-\delta }/C(\delta ))]\leqq 2\) for any \(\delta >0\).
Higher-order approximation results in terms of homogenized problems have been derived in [19,20,21, 56, 69], relying on the concept of higher-order correctors which was first used in the stochastic homogenization context in [44] to establish Liouville principles of arbitrary order in the spirit of Avellaneda and Lin’s result in periodic homogenization [11]. Further works in quantitative stochastic homogenization include the analysis of nondivergence form equations [7], a regularity theory up to the boundary [45], degenerate elliptic equations [2, 46], and the homogenization of parabolic equations [3, 66]. Recently, Armstrong and Dario [4] and Dario [36] succeeded in establishing quantitative homogenization for supercritical Bernoulli bond percolation on the standard lattice.
The fluctuations of the mathematical objects arising in the stochastic homogenization of linear elliptic PDEs have been the subject of a beautiful series of works, starting with the work of Nolen [77] and a subsequent work of Gloria and Nolen [52] on quantitative normal approximation for (a single component of) the approximation of the effective conductivity \(a^{{\text {RVE}}}\) and a work of Mourrat and Otto [74] on the correlation structure of fluctuations in the homogenization corrector \(\phi _i\). Mourrat and Nolen [73] have shown a quantitative normal approximation result for the fluctuations of the corrector. Gu and Mourrat [57] have derived a description of fluctuations in the solutions to the equation with random coefficient field (1). Recently, a pathwise description of fluctuations of the solutions to the equation with random coefficient field (1)—namely, in terms of deterministic linear functionals of the so-called homogenization commutator\(\Xi :=(a-a_{\mathsf {hom}})({\text {Id}}+\nabla \phi )\), a random field converging (for \(\varepsilon \rightarrow 0\)) towards white noise—was developed by Duerinckx et al. [39]. The scaling limit of certain energetic quantities—related to the homogenization commutator—as well as the scaling limit of the homogenization corrector has been identified in the setting of finite range of dependence by Armstrong et al. [5]. As far as quantitative normal approximation results are concerned, all of these works work under the assumption of i.i.d. coefficients (in the discrete setting) or second-order Poincaré inequalities. To the best of our knowledge, the present work provides the first quantitative description of fluctuations (though so far limited to the approximation of the effective conductivity \(a^{{\text {RVE}}}\)) when the decorrelation in the coefficient field is quantified by the assumption of finite range of dependence instead of functional inequalities.
Note that despite its long history [35, 63, 67, 78], the qualitative theory of stochastic homogenization has also been a very active area of research in the past years, see for example [10, 27, 58, 59]; however, due to the substantial length of the present manuscript we shall not provide a more detailed discussion and refer the reader to these references instead.
Notation Throughout the paper, we shall use standard notation for Sobolev spaces and weak derivatives; for a space-time function v(x, s), we denote by \(\nabla v\) its spatial gradient (in the weak sense) and by \(\partial _s v\) its (weak) time derivative. The notation  is used for the average integral over a set B of positive but finite Lebesgue measure. The space of measurable functions f with \(||f||_{L^p}:=(\int _{\mathbb {R}^d} |f|^p \,\mathrm{d}x)^{1/p}<\infty \) will be denoted by \(L^p\). By \(L^p_{loc}\) we denote the space of functions f with \(f\chi _{\{|x|\leqq R\}}\in L^p\) for all \(R<\infty \). We shall also use the weighted space \(L^p_{h}\) of functions with \(||f||_{L^p_h}:=(\int _{\mathbb {R}^d} |f(x)|^p h(x) \,\mathrm{d}x)^{1/p}<\infty \) for a nonnegative measurable weight function h. By \(H^1(\mathbb {R}^d)\) we denote as usual the Sobolev space of functions \(v\in L^2(\mathbb {R}^d)\) with \(\nabla v\in L^2(\mathbb {R}^d)\); similarly, \(H^1_{loc}(\mathbb {R}^d)\) is the space of functions v with \(v\in L^2_{loc}(\mathbb {R}^d)\) and \(\nabla v\in L^2_{loc}(\mathbb {R}^d)\). For a Banach space X we denote by \(L^p([0,T];X)\) the usual Lebesgue–Bochner space.
is used for the average integral over a set B of positive but finite Lebesgue measure. The space of measurable functions f with \(||f||_{L^p}:=(\int _{\mathbb {R}^d} |f|^p \,\mathrm{d}x)^{1/p}<\infty \) will be denoted by \(L^p\). By \(L^p_{loc}\) we denote the space of functions f with \(f\chi _{\{|x|\leqq R\}}\in L^p\) for all \(R<\infty \). We shall also use the weighted space \(L^p_{h}\) of functions with \(||f||_{L^p_h}:=(\int _{\mathbb {R}^d} |f(x)|^p h(x) \,\mathrm{d}x)^{1/p}<\infty \) for a nonnegative measurable weight function h. By \(H^1(\mathbb {R}^d)\) we denote as usual the Sobolev space of functions \(v\in L^2(\mathbb {R}^d)\) with \(\nabla v\in L^2(\mathbb {R}^d)\); similarly, \(H^1_{loc}(\mathbb {R}^d)\) is the space of functions v with \(v\in L^2_{loc}(\mathbb {R}^d)\) and \(\nabla v\in L^2_{loc}(\mathbb {R}^d)\). For a Banach space X we denote by \(L^p([0,T];X)\) the usual Lebesgue–Bochner space.
As usual, we shall denote by C and c constants whose value may change from occurrence to occurrence. We are going to use the notation \(\mathcal {C}(a)\) and similar expressions to denote a random constant subject to suitable moment bounds; again, the precise value of \(\mathcal {C}(a)\) may change from occurrence to occurrence.
For a vector \(v\in \mathbb {R}^m\) we denote by |v| its Euclidean norm. We denote the identity matrix in \(\mathbb {R}^{N\times N}\) by \({\text {Id}}\) or \({\text {Id}}_N\). For a matrix \(A\in \mathbb {R}^{m\times m}\) we shall denote by |A| its natural norm \(|A|:=\max _{v,w\in \mathbb {R}^m,|v|=|w|=1} |v\cdot A w|\) and by \(A^*\) its transpose (as all our matrices are real). For \(x\in \mathbb {R}^d\) we denote by \(|x|_\infty =\max _i |x_i|\) its supremum norm. By \(|x-y|_{{\text {per}}}\) respectively (for sets) \({\text {dist}}_{{\text {per}}}(U,V)\), we denote the periodicity-adjusted distance (in the context of the torus \([0,L\varepsilon ]^d\)). By \(|x-y|_\infty ^{{{\text {per}}}}\) and \({\text {dist}}^{{\text {per}}}_\infty (x,y)\), we denote the corresponding distances associated with the maximum norm. For a positive definite matrix A, we denote by \(\kappa (A)\) its condition number.
Given a positive definite symmetric matrix \(\Lambda \in \mathbb {R}^{N\times N}\), we denote the Gaussian with covariance matrix \(\Lambda \) by
For \(\gamma >0\), we equip the space of random variables X with stretched exponential moment \(\mathbb {E}[\exp (|X|^\gamma /a)]<\infty \) for some \(a=a(X)>0\) with the norm \(||X||_{\exp ^\gamma }:=\sup _{p\geqq 1} p^{-1/\gamma } \mathbb {E}[|X|^p]^{1/p}\). For a discussion of this choice of norm, see Appendix B.
For a map \(f:\mathbb {R}^N\rightarrow V\) into a normed vector space V, we denote for any \(r>0\) by \({{\text {osc}}}_r f(x_0):=\sup _{x,y\in \{|x-x_0|\leqq r\}} |f(x)-f(y)|_V\) its oscillation in the ball of radius r around \(x_0\).
The conditional expectation of a random variable X given Y is denoted by \(\mathbb {E}[X|Y]\).
2 Main Results
In the present work, we establish a rigorous justification of the selection approach for representative volumes by Le Bris et al. [64] in the context of stochastic homogenization of linear elliptic PDEs for quite general probability distributions of the coefficient field \(a^{\mathbb {R}^d}\). Our only assumptions on the probability distribution of the coefficient field \(a^{\mathbb {R}^d}:\mathbb {R}^d\rightarrow \mathbb {R}^{d\times d}\) are uniform ellipticity and boundedness, stationarity, and finite range of dependence, which is a standard set of assumptions in stochastic homogenization [9, 55] (note that we equip the space of uniformly elliptic and bounded coefficient fields with the topology of Murat and Tartar’s H-convergence [75]). Let us remark that all of our results and proofs are also valid in the case of strongly elliptic systems, upon adapting the notation in the obvious way:
-
(A1)
Uniform ellipticity of a coefficient field a as usual means that there exists a positive real number \(\lambda >0\) such that almost surely we have \(a(x)v\cdot v \geqq \lambda |v|^2\) for almost every \(x\in \mathbb {R}^d\) and every \(v\in \mathbb {R}^d\). Furthermore we assume uniform boundedness in the sense that almost surely \(|a(x)v|\leqq \frac{1}{\lambda }|v|\) holds for almost every \(x\in \mathbb {R}^d\) and every \(v\in \mathbb {R}^d\).
-
(A2)
Stationarity means that the law of the shifted coefficient field \(a(\cdot +x)\) must coincide with the law of \(a(\cdot )\) for every \(x\in \mathbb {R}^d\). On a heuristic level, this means that “the probability distribution of a is everywhere the same” or, in other words, that the material is spatially statistically homogeneous.
-
(A3)
Finite range of dependence\(\varepsilon \) means that for any two Borel sets \(A,B\subset \mathbb {R}^d\) with \({\text {dist}}(A,B)\geqq \varepsilon \) the restrictions \(a|_A\) and \(a|_B\) must be stochastically independent. In particular, this assumption restricts the correlations in the coefficient field to the scale \(\varepsilon \ll 1\).
Note that these assumptions include for example the case of a two-material composite with random (either overlapping or non-overlapping) inclusions of diameter \(\varepsilon \), the centers distributed according to a Poisson point process (up to removal in case of overlap); see Fig. 3a. Further examples include coefficient fields \(a^{\mathbb {R}^d}(x):=\xi ({\tilde{a}}(x))\) that arise by pointwise application of a nonlinear function \(\xi :\mathbb {R}^{d\times d}\rightarrow \mathbb {R}^{d\times d}\) to a (tensor-valued) stationary Gaussian random field \({\tilde{a}}\) with finite range of dependence \(\varepsilon \) and integrable correlations, provided that the function \(\xi \) is Lipschitz and takes values in the set of uniformly elliptic and bounded matrices.
For the approximation of the effective coefficient \(a_{\mathsf {hom}}\), it is of advantage to work with a so-called periodization of the stationary ensemble of random coefficient fields \(a^{\mathbb {R}^d}\) (employing terminology from statistical mechanics, a probability measure on the space of coefficient fields shall also be called an ensemble of coefficient fields). By a periodization of an ensemble of coefficient fields \(a^{\mathbb {R}^d}\) we understand an ensemble of coefficient fields a which are almost surely \(L\varepsilon \mathbb {Z}^d\)-periodic for some \(L\gg 1\) and for which the probability distribution of a on each cube of size of half the period \(\frac{L\varepsilon }{2}\) coincides with the probability distribution of the original coefficient field \(a^{\mathbb {R}^d}\), that is for which the probability distribution of \(a|_{x+[0,L\varepsilon /2]^d}\) coincides with the distribution of \(a^{\mathbb {R}^d}|_{x+[0,L\varepsilon /2]^d}\) for all \(x\in \mathbb {R}^d\). For such a periodization, the condition (A3) is replaced by the following conditions (A3\(_a\)), (A3\(_b\)), (A3\(_c\)):
-
(\(\hbox {A3}_a\)) The coefficient field a is almost surely \(L \varepsilon \mathbb {Z}^d\)-periodic.
-
(\(\hbox {A3}_b\)) There exists a finite range of dependence\(\varepsilon >0\) such that for any two measurable \(L \varepsilon \mathbb {Z}^d\)-periodic sets \(A,B\subset \mathbb {R}^d\) with \({\text {dist}}(A,B)\geqq \varepsilon \) the restrictions \(a|_A\) and \(a|_B\) are stochastically independent.
-
(\(\hbox {A3}_c\)) For any \(x_0\in \mathbb {R}^d\) the law of the restriction \(a|_{x_0+[-\frac{L\varepsilon }{4},\frac{L\varepsilon }{4}]^d}\) coincides with the corresponding law for some (non-periodic) ensemble of coefficient fields \(a^{\mathbb {R}^d}\) satisfying (A1)–(A3).
Furthermore, to include examples like the random checkerboard in our analysis, we need the following notion of discrete stationarity:
-
(A2’)
We say that our probability distribution of coefficient fields a satisfies discrete stationarity if the law of the shifted coefficient field \(a(\cdot +x)\) coincides with the law of \(a(\cdot )\) for every shift \(x\in \varepsilon \mathbb {Z}^d\).
Our main assumptions stated in Assumption 1 below consist of two parts. First, we assume that the probability distribution of coefficient fields \(a^{\mathbb {R}^d}\) satisfies the standard assumptions from stochastic homogenization and that there exists a suitable periodization a of the probability distribution. Second, we require the statistical quantities \(\mathcal {F}(a)\) to admit a “multilevel local dependence structure decomposition” as introduced in Definition 6 below. Let us remark that both the spatial average

and the higher-order quantity \(\mathcal {F}_{2-\mathrm{point}}(a)\) considered by Le Bris et al. [64] as defined in (10) satisfy the conditions in Definition 6; a proof of this fact is provided in Proposition 7 below. As a consequence, both the spatial average \(\mathcal {F}_{avg}(a)\) and the higher-order quantity \(\mathcal {F}_{2-\mathrm{point}}(a)\) may be chosen as the statistical quantities by which the selection of representative volumes is performed in our main theorems Theorem 2 and Theorem 3.
Assumption 1
(Assumptions and Notation) Consider a probability distribution of random coefficient fields \(a^{\mathbb {R}^d}\) on \(\mathbb {R}^d\), \(d\geqq 1\), which satisfies the conditions of ellipticity, stationarity, and finite range of dependence (A1)–(A3). Let \(L\geqq 2\) and suppose that there exists an \(L\varepsilon \)-periodization a of the probability distribution of \(a^{\mathbb {R}^d}\) subject to (A1), (A2), (A3\(_a\))–(A3\(_c\)). Denote by \(a^{{\text {RVE}}}\) the approximation for the effective coefficient \(a_{\mathsf {hom}}\) by the standard representative volume element method with a material sample of size \([0,L\varepsilon ]^d\), that is set

with \(\phi _i\) being the unique \(L\varepsilon \)-periodic solution with vanishing average to the corrector equation
Let \(\mathcal {F}(a)=(\mathcal {F}_1(a),\ldots ,\mathcal {F}_N(a))\) be a collection of statistical quantities of the coefficient field a which are subject to the conditions of Definition 6 with \(K\leqq C_0\), \(B\leqq C_0 |\log L|^{C_0}\), and \(\gamma \geqq c_0\) for some \(0<c_0,C_0<\infty \). Suppose that the covariance matrix of \(\mathcal {F}(a)\) is nondegenerate and bounded in the natural scaling in the sense
For any \(1\leqq i,j\leqq d\) introduce the condition number \(\kappa _{ij}\) of the covariance matrix of \((a^{{\text {RVE}}}_{ij},\mathcal {F}(a))\)
and the ratio \(r_{{\text {Var}},ij}\) between the expected order of fluctuations and the actual fluctuations of the approximation \(a^{{\text {RVE}}}_{ij}\)
Denote by C a constant depending on d, \(\lambda \), \(\gamma \), N, and \(C_0\).
Under the above assumptions, the selection approach for representative volumes to capture certain statistical properties of the material in the representative volume particularly well—as proposed by Le Bris et al. [64]—leads to the following increase in accuracy of the computed material coefficients:
Theorem 2
(Justification of the Selection Approach for Representative Volumes) Let the assumptions and notations of Assumption 1 be in place. Denote by \(a^{{\text {sel-RVE}}}\) the approximation for the effective coefficient \(a_{\mathsf {hom}}\) by the selection approach for representative volumes introduced by Le Bris et al. [64] in the case of a representative volume of size \(L\varepsilon \). Suppose that the representative volumes \(a|_{[0,L\varepsilon ]^d}\) are selected from the periodized probability distribution according to the criterion
for some \(\delta \in (0,1]\). Let the selection criterion be chosen not too strict in the sense that \(\delta ^N \geqq C L^{-d/2} |\log L|^{C(d,\gamma ,C_0)}\). Then the selection approach for representative volumes is subject to the following error analysis:
-
(a)
The systematic error of the approximation \(a^{{\text {sel-RVE}}}\) satisfies the estimate
$$\begin{aligned} \big |\mathbb {E}\big [a^{{\text {sel-RVE}}}\big ]-a_{\mathsf {hom}}\big | \leqq \frac{C \kappa _{ij}^{3/2}}{\delta ^N} L^{-d} |\log L|^{C(d,\gamma )}. \end{aligned}$$(15) -
(b)
The variance of the approximation \(a^{{\text {sel-RVE}}}\) is estimated from above by
$$\begin{aligned} \frac{{{\text {Var}}~}a^{{\text {sel-RVE}}}_{ij}}{{{\text {Var}}~}a^{{\text {RVE}}}_{ij}} \leqq 1-(1-\delta ^2) |\rho |^2 + \frac{C \kappa _{ij}^{3/2}r_{{\text {Var}},ij}}{\delta ^N} L^{-d/2} |\log L|^{C(d,\gamma )}, \end{aligned}$$(16)where \(|\rho |^2\) is the fraction of the variance of \(a^{{\text {RVE}}}_{ij}\) explained by the \(\mathcal {F}(a)\), that is, \(|\rho |^2\) is the maximum of the squared correlation coefficient between \(a^{{\text {RVE}}}_{ij}\) and any linear combination of the \(\mathcal {F}_n(a)\). The explained fraction of the variance is given by the formula
$$\begin{aligned} |\rho |^2 := \frac{{\text {Cov}}[a^{{\text {RVE}}}_{ij},\mathcal {F}(a)] \cdot ({{\text {Var}}~}\mathcal {F}(a))^{-1} {\text {Cov}}[\mathcal {F}(a),a^{{\text {RVE}}}_{ij}]}{{{\text {Var}}~}a^{{\text {RVE}}}_{ij}}. \end{aligned}$$(17) -
(c)
The probability that a randomly chosen coefficient field a satisfies the selection criterion (14) is at least
$$\begin{aligned} \mathbb {P}\big [|\mathcal {F}(a)-\mathbb {E}\big [\mathcal {F}(a)\big ]|\leqq \delta L^{-d/2}\big ] \geqq c(N) \delta ^N. \end{aligned}$$(18) -
(d)
The systematic error and the variance of \(a^{{\text {sel-RVE}}}\) may be estimated independently of \(\kappa _{ij}\) at the price of lower rate of convergence in L
$$\begin{aligned} \big |\mathbb {E}\big [a^{{\text {sel-RVE}}}\big ]-a_{\mathsf {hom}}\big | \leqq \frac{C}{\delta ^N} L^{-d/2-d/8} |\log L|^{C(d,\gamma )} \end{aligned}$$(19)and
$$\begin{aligned} \frac{{{\text {Var}}~}a^{{\text {sel-RVE}}}_{ij}}{{{\text {Var}}~}a^{{\text {RVE}}}_{ij}} \leqq 1-(1-\delta ^2) |\rho |^2 + \frac{Cr_{{\text {Var}},ij}}{\delta ^N} L^{-d/8} |\log L|^{C(d,\gamma )}. \end{aligned}$$(20)
The previous theorem states that the approximation of effective coefficients by the selection approach for representative volumes is essentially at least as accurate as a random selection of samples (except for a possible additional relative error of the order \(C L^{-d/2} |\log L|^C\), which however converges to zero quickly as L increases), at least when measuring the mean-square error. If the selection is based on a statistical quantity \(\mathcal {F}(a)\) which is capable of explaining a large part of the variance of \(a^{{\text {RVE}}}_{ij}\), the selection approach achieves a much better accuracy than a random selection of samples (namely, by a factor of about \(\sqrt{1-|\rho |^2}\)).
However, the previous theorem only provides a statement about the reduction of the mean-square error by the selection approach for representative volumes. A natural question is whether this reduction of the error also applies to rare events: More precisely, if we fix a small probability \(p>0\), is the bound on the error \(|a^{{\text {sel-RVE}}}_{ij}-a_{{\mathsf {hom}},ij}|\) which holds with probability \(1-p\) also improved as suggested by the variance reduction estimate (16)? The following theorem shows that this is in fact true for “moderate deviations”, that is basically for probabilities \(p\gtrsim \exp (-L^\beta )\) for some \(\beta >0\). More precisely, the theorem is to be read as follows: up to error terms that converge to zero as \(L\rightarrow \infty \) and \(s\rightarrow \infty \), the probability of \(a^{{\text {sel-RVE}}}_{ij}\) deviating from \(a_{{\mathsf {hom}},ij}\) by more than s times the ideally reduced standard deviation \(\sqrt{(1-|\rho |^2){{\text {Var}}~}a^{{\text {RVE}}}_{ij}}\) behaves like the probability of a normal distribution deviating from its mean by more than s standard deviations, at least in some regime \(s\leqq L^{\beta /3}\).
Theorem 3
Let the assumptions and notations of Theorem 2 be in place. Suppose in addition \(L\geqq C\). Then the selection approach for representative volumes leads to a reduction of the “outliers” of the probability distribution of \(a^{{\text {sel-RVE}}}\) in the sense of the moderate-deviations-type bound
for any \(s\geqq \max \big \{1,\frac{\delta }{\sqrt{1-|\rho |^2}}\big \}\) and some \(\beta =\beta (d)>0\).
We have shown in the preceding two theorems that the selection approach for representative volumes by Le Bris et al. essentially does not increase the error; it succeeds in reducing the fluctuations of the approximations as soon as the functionals \(\mathcal {F}(a)\) and the approximation \(a^{{\text {RVE}}}\) have a nonzero covariance.
However, as we shall show in the next theorem there exist cases in which the selection approach for representative volumes in fact fails to reduce the variance significantly, even for a “natural” statistical quantity like the average of the coefficient field

Theorem 4
(Possible Failure of the Reduction of the Variance) Suppose that the assumptions of Theorem 2 hold. Then the estimate (16) on the reduction of the variance is sharp in the sense
Furthermore, for \(d\geqq 2\) there exist \(L\varepsilon \)-periodic probability distributions of coefficient fields a which satisfy the conditions of ellipticity, discrete stationarity, and finite range of dependence (A1), (A2’), (A3\(_a\))–(A3\(_c\)) with the following property: the covariance of \(a^{{\text {RVE}}}\) and the spatial average  vanishes
vanishes

while the fluctuations of \(a^{{\text {RVE}}}\) and  are nondegenerate in the sense that
are nondegenerate in the sense that

for some universal constant c. These coefficient fields may be chosen to be of the form \(a(x)={\tilde{a}}(x){\text {Id}}\) for some scalar random field \({\tilde{a}}\).
As a consequence, for these probability distributions of coefficient fields the selection approach for representative volumes based on the spatial average  fails to efficiently reduce the variance in the sense that
fails to efficiently reduce the variance in the sense that
Let us note that it is presumably not too difficult to replace the random checkerboard in our construction of the counterexample featuring (23) by random spherical inclusions distributed according to a Poisson point process (with overlaps of the inclusions). This would yield a counterexample subject to the continuous stationarity (A2).
The next theorem suggests that the failure of effective variance reduction is atypical and may be limited to rather artificial examples. For a large class of random coefficient fields—namely for coefficient fields that are obtained from a collection of iid random variables \(\xi _{k}\), \(k\in \varepsilon \mathbb {Z}^d\), by applying a stationary monotone map with finite range of dependence—the correlation coefficient between \(a^{{\text {RVE}}}\) and the average  is bounded from below by a positive number. Therefore, for such (ensembles of) coefficient fields both the method of special quasirandom structures and the method of control variates in fact reduce the variance by some factor \(\tau <1\) when applied with the choice
is bounded from below by a positive number. Therefore, for such (ensembles of) coefficient fields both the method of special quasirandom structures and the method of control variates in fact reduce the variance by some factor \(\tau <1\) when applied with the choice  .
.
Proposition 5
(Reduction of the Variance for a Large Class of Coefficient Fields) Let \(\varepsilon >0\) and let \(L\geqq 2\) be an integer and let V denote some measure space. Let \((\Gamma _k)\), \(k\in \varepsilon \mathbb {Z}^d\cap [0,L\varepsilon )^d\), be a collection of independent identically distributed V-valued random variables, and denote by \(({\tilde{\Gamma }}_k)\) an independent copy. Extend \(\Gamma _k\) to \(k\in \varepsilon \mathbb {Z}^d\) by \(L\varepsilon \)-periodicity. For \(k\in \varepsilon \mathbb {Z}^d\) and \(z\in V\), denote by \(\Delta _{k,z} \Gamma \) the collection \(({\tilde{\Gamma }}_k)\) obtained by setting \({\tilde{\Gamma }}_k:=z\) and \({\tilde{\Gamma }}_j=\Gamma _j\) for all \(j\ne k\).
Let \(a=a(x,\Gamma )\) be a measurable map into the uniformly elliptic \(L\varepsilon \)-periodic symmetric coefficient fields with the property that \(a(x,\Gamma )\) depends only on the \(\Gamma _k\) with \(|x-k|_{{\text {per}}}\leqq K\varepsilon \) for some \(K\geqq 1\) (in a measurable way). Suppose that the map is stationary in the sense that \(a(x+y,\Gamma )=a(x,\Gamma _{\cdot +y})\) for any \(y\in \varepsilon \mathbb {Z}^d\).
Suppose that the dependence of a on \(\Gamma \) is monotone in the sense that for every \(k\in \varepsilon \mathbb {Z}^d\) and every pair \(z_1,z_2 \in V\), either for all x the inequality
holds, or for all x the reverse inequality
holds. Suppose furthermore that there exists \(\nu >0\) such that we have the quantified monotonicity
for all \(x\in [0,L \varepsilon )^d\) and all \(\Gamma \), where \(\big (a(x,\Gamma )-a(x,\Delta _{k,{\tilde{\Gamma }}_k}\Gamma )\big )_+^{1/2}\) denotes the matrix square root and where \({\tilde{\Gamma }}\) denotes an independent copy of \(\Gamma \).
Then the probability distribution of \(a=a(x,\Gamma )\) satisfies the conditions of ellipticity, periodicity, and finite range of dependence (A1), (A3\(_a\)), and (A3\(_b\)) (with \(\varepsilon \) replaced by \(4K\varepsilon \)), as well as the discrete stationarity (A2’). Furthermore, for such coefficient fields a the correlation between \(\xi \cdot a^{{\text {RVE}}}\xi \) (where \(\xi \in \mathbb {R}^d\) is any nonzero vector) and the average

is bounded from below by a positive number in the sense
In the statements of our main theorems, we have made use of the following notion of “multilevel local dependence decomposition”; this structure will also be at the heart of the proof of our main results (an illustration of this decomposition is provided in Fig. 4):
Definition 6
(Sums of Random Variables with Multilevel Local Dependence Structure) Let \(d\geqq 1\), \(N\in \mathbb {N}\), \(\varepsilon >0\), and \(L\geqq 2\). Consider a probability distribution of coefficient fields a on \(\mathbb {R}^d\) subject to the assumptions of ellipticity and boundedness, stationarity, and finite range of dependence \(\varepsilon \) (A1), (A2), and (A3), or the periodization of such an ensemble subject to the conditions (A1), (A2), and (A3\(_a\)) - (A3\(_c\)). Let \(X=X(a)\) be an \(\mathbb {R}^N\)-valued random variable.
We then say that X is a sum of random variables with multilevel local dependence if there exist random variables \(X_y^m=X_y^m(a)\), \(0\leqq m\le 1+\log _2 L\) and \(y\in 2^m \varepsilon \mathbb {Z}^d\cap [0,L\varepsilon )^d\), and constants \(K\geqq 1\), \(\gamma \in (0,2]\), and \(B\geqq 1\) with the following properties:
-
The random variable \(X_y^m(a)\) only depends on \(a|_{y+K \log L \, [-2^m \varepsilon ,2^m \varepsilon ]^d}\). More precisely, \(X_y^m(a)\) is a measurable function of \(a|_{y+K \log L \, [-2^m \varepsilon ,2^m \varepsilon ]^d}\) equipped with the topology of H-convergence.
-
We have
$$\begin{aligned} X=\sum _{m=0}^{1+\log _2 L} \sum _{y\in 2^m \varepsilon \mathbb {Z}^d\cap [0,L\varepsilon )^d} X_y^m. \end{aligned}$$ -
The random variables \(X_y^m\) satisfy the bound
$$\begin{aligned} ||X_y^m||_{\exp ^\gamma } \leqq B L^{-d}. \end{aligned}$$(26)

An illustration of the “multilevel local dependence structure” introduced in Definition 6 (in a one-dimensional setting). At the bottom, a sample of the random coefficient field a is depicted; the \(X_y^k\) may depend not only on the values of the coefficient field directly below their box, but on the coefficient field in a region that is wider by a factor of \(K \log L\)
The next proposition shows that the approximation \(a^{{\text {RVE}}}\) of the effective coefficient by the method of representative volumes may indeed be rewritten as a sum of random variables with a multilevel local dependence structure. We establish the same result for the spatial average of the coefficient field  and the second-order term \(\mathcal {F}_{2-\mathrm{point}}(a)\) in the low ellipticity contrast expansion of \(\smash {a^{{\text {RVE}}}}\) given by (10).
and the second-order term \(\mathcal {F}_{2-\mathrm{point}}(a)\) in the low ellipticity contrast expansion of \(\smash {a^{{\text {RVE}}}}\) given by (10).
Furthermore, the last result of the next proposition shows that the fraction of the variance of \(a^{{\text {RVE}}}\) that is explained by the statistical quantities \(\mathcal {F}_{avg}(a)\) and \(\mathcal {F}_{2-\mathrm{point}}(a)\)—that is, the gain in accuracy achieved by the selection approach for representative volumes when employing these statistical quantities—stabilizes as the size L of the representative volume increases; more precisely, it converges to some limit with rate \(L^{-d/2}|\log L|^C\).
Proposition 7
Let the assumptions (A1), (A2), (A3\(_a\))–(A3\(_c\)) be satisfied, that is consider the periodization of a stationary ensemble of random coefficient fields. For any coefficient field a, denote by \(\phi _i\) the unique (up to additions of constants) periodic solution to the corrector equation
Then the approximation \(a^{{\text {RVE}}}\) of the effective coefficient \(a_{\mathsf {hom}}\) by the representative volume element method, given by

is a sum of a family of random variables with multilevel local dependence. More precisely, \(a^{{\text {RVE}}}\) satisfies the criteria of Definition 6 for any \(\gamma <1\) with \(K:=C(d,\lambda )\) and \(B:=C(d,\gamma ,\lambda ) |\log L|^{C(d,\gamma )}\).
Furthermore, the spatial average

is also a sum of a family of random variables with multilevel local dependence. The criteria of Definition 6 are satisfied by \(\mathcal {F}_{avg}(a)\) for any \(\gamma <\infty \) with \(K:=C(d)\) and \(B:=C(d,\gamma )\).
Additionally, the second-order correction to the effective conductivity in the setting of small ellipticity contrast \(\mathcal {F}_{2-\mathrm{point}}\), given by

with \(v_i\) denoting the solution to
is a sum of random variables with multilevel local dependence structure: the random variable \(\mathcal {F}_{2-\mathrm{point}}(a)\) satisfies the criteria of Definition 6 for any \(\gamma <1\) with \(K:=C(d,\lambda )\) and \(B:=C(d,\gamma ,\lambda ) |\log L|^{C(d,\gamma )}\).
Finally, the rescaled variances and covariances of \(a^{{\text {RVE}}}\) and the statistical quantities \(\mathcal {F}_{avg}(a)\) and \(\mathcal {F}_{2-\mathrm{point}}(a)\) converge as \(L\rightarrow \infty \). There exist positive semidefinite matrices \(V_{{{\text {RVE}}}}\), \(V_{avg}\), \(V_{2-\mathrm{point}}\) and matrices \(V_{c,{{\text {RVE}}},avg}\), \(V_{c,{{\text {RVE}}},2-\mathrm{point}}\), \(V_{c,avg,2-\mathrm{point}}\) independent of L such that the estimates
and
hold true.
It is interesting to compare our approach on quantitative normal approximation of \(a^{{\text {RVE}}}\) with concepts employed in the derivation of optimal error estimates in stochastic homogenization [5, 6, 55]. A central theme in [5] is the approximate additivity of certain energetic quantities: the energy quantity on a certain scale may approximately be written as a sum of the energy quantities on smaller scales, allowing for an application of the central limit theorem. In [55], the application of the central limit theorem is facilitated by the homogenization of the flux propagation in the parabolic semigroup associated with the random elliptic operator. In our context, while we also introduce an additive decomposition of \(a^{{\text {RVE}}}\), we do not require the summands to be of the same structure as \(a^{{\text {RVE}}}\) and allow for a multilevel structure. This enables us to derive an optimal-order normal approximation result for the fluctuations.
Note that in [5, 6] a certain localization property of the considered energy quantity has been established. In principle, sufficiently strong localization properties of a random field allow for a multilevel decomposition of (linear functionals of) the random field in the sense of Definition 6 and therefore for an application of our quantitative normal approximation result in Theorem 9; see, in particular, the proof of [43, Theorem 2] for such a construction. However, the locality of the energy quantity established in [5, 6] is non-optimal and in general not sufficient for our purposes. In the forthcoming work [37], an optimal-order localization result for (linear functionals of) the homogenization commutator \(\Xi :=(a-a_{\mathsf {hom}})({\text {Id}}+\nabla \phi )\) will be provided, implying an optimal-order normal approximation result.
3 Strategy of the Proof and Intermediate Results
Our main result relies on a quantitative normal approximation result for the joint probability distribution of the approximation of the effective conductivity \(a^{{\text {RVE}}}\) and auxiliary random variables \(\mathcal {F}(a)\) like the spatial average  . The distance of the probability distribution to a multivariate Gaussian will be quantified through the following notion of distance between probability measures. Note that this distance is a standard choice in the theory of multivariate normal approximation, see for example [33] and the references therein.
. The distance of the probability distribution to a multivariate Gaussian will be quantified through the following notion of distance between probability measures. Note that this distance is a standard choice in the theory of multivariate normal approximation, see for example [33] and the references therein.
Definition 8
Given a symmetric positive definite matrix \(\Lambda \in \mathbb {R}^{N\times N}\) and some \({\bar{L}}<\infty \), we consider the classes \(\Phi _{\Lambda }^{{\bar{L}}}\) of functions \(\phi :\mathbb {R}^N\rightarrow \mathbb {R}\) subject to the following properties:
-
\(\phi \) is smooth and its first derivative is bounded in the sense \(|\nabla \phi (x)| \leqq {\bar{L}}\) for all \(x\in \mathbb {R}^N\).
-
For any \(r>0\) and any \(x_0\in \mathbb {R}^N\), we have
$$\begin{aligned} \int _{\mathbb {R}^N} {{\text {osc}}}_r \phi (x) ~\mathcal {N}_{\Lambda }(x-x_0) \,\mathrm{d}x \leqq r, \end{aligned}$$(29)where \({{\text {osc}}}_r \phi (x)\) is the oscillation of \(\phi \) defined as
$$\begin{aligned} {{\text {osc}}}_r\phi (x):=\sup _{|z|\leqq r}\phi (x+z)-\inf _{|z|\leqq r} \phi (x+z) \end{aligned}$$and where
$$\begin{aligned} \mathcal {N}_{\Lambda }(x):=\frac{1}{(2\pi )^{N/2}\sqrt{\det \Lambda }} \exp \bigg (-\frac{1}{2}\Lambda ^{-1} x \cdot x\bigg ). \end{aligned}$$
The class \(\Phi _\Lambda \) is defined as
Furthermore, we introduce the distance \(\mathcal {D}\) between the law of an \(\mathbb {R}^N\)-valued random variable X and the N-variate Gaussian \(\mathcal {N}_\Lambda \) as
Note that defining the distance \(\mathcal {D}\) with the class of functions \(\Phi _\Lambda ^1\) instead of \(\Phi _\Lambda \) would lead to the 1-Wasserstein distance. The distance \(\mathcal {D}\) is a stronger distance than the 1-Wasserstein distance. The 1-Wasserstein distance is defined by taking the supremum in (30) only over all functions \(\phi \) which are 1-Lipschitz. In contrast, the condition (29) corresponds more or less to a slightly stronger condition than an \(L^1_{loc}\)-type bound for \(\nabla \phi \): It in particular implies by letting \(r\rightarrow 0\)
for any \(x_0\in \mathbb {R}^N\).
It is well-known that Stein’s method of normal approximation allows one to establish a quantitative result on normal approximation for sums of random variables with local dependence structure, see for example [33, 34, 80] and the references therein. However, the approximation of the effective coefficient \(a^{{\text {RVE}}}\)—that is, the random variable \(a^{{\text {RVE}}}\) as defined by (4)—features global dependencies. It is shown in Proposition 7 that \(a^{{\text {RVE}}}\) may nevertheless be approximated by a sum of random variables with a multilevel local dependence structure. We then employ the following quantitative central limit theorem for sums of vector-valued random variables with a multilevel local dependence structure, which is not covered by the normal approximation results for sums of random variables with a given dependency graph in the literature and which is established in the companion article [43]:
Theorem 9
([43, Theorem 4]) Consider a probability distribution of uniformly elliptic and bounded coefficient fields a on \(\mathbb {R}^d\) or a periodization of such a probability distribution, and suppose that assumptions (A1)–(A3) respectively (A1), (A2), (A3\(_a\))–(A3\(_c\)) are satisfied. Let \(X=X(a)\) be a random variable that is a sum of random variables with multilevel local dependence in the sense of Definition 6. Then the law of the random variable X is close to a multivariate Gaussian in the sense that
where \(\Lambda :={{\text {Var}}~}X\) and where the constant \(C(d,\gamma ,N,K)\) depends in a polynomial way on d, N, and K.
Furthermore, we have, for any symmetric positive definite \(\Lambda \in \mathbb {R}^{N \times N}\) with \(\Lambda \geqq {{\text {Var}}~}X\) and \(|\Lambda -{{\text {Var}}~}X|\leqq L^{-d}\),
providing a better bound in the case of degenerate covariance matrices \({{\text {Var}}~}X\).
Our result on moderate deviations of the probability distribution of \(a^{{\text {sel-RVE}}}\) is based on the following simple general moderate deviations result for sums of random variables with multilevel local dependence structure:
Theorem 10
([43, Theorem 5]) Consider an ensemble of coefficient fields a on \(\mathbb {R}^d\), \(d\geqq 1\), or its periodization for some \(L\geqq 1\), subject to the conditions (A1)–(A3) respectively (A1), (A2), and (A3\(_a\))–(A3\(_c\)). Let \(X=X(a)\) be a random variable that may be written as a sum of random variables with multilevel local dependence structure \(X=\sum _{m=0}^{1+\log _2 L} \sum _{i\in 2^m \varepsilon \mathbb {Z}^d \cap [0,L\varepsilon )^d} X_i^m\) in the sense of Definition 6.
Then there exists \(\beta =\beta (d,\gamma )>0\) and a positive definite symmetric matrix \(\Lambda \in \mathbb {R}^{N\times N}\) with \(|\Lambda -{{\text {Var}}~}X|\leqq C(d,\gamma ,N,K) B^2 L^{-2\beta } L^{-d}\) such that for any measurable \(A\subset \mathbb {R}^N\) we have the estimate
4 Justification of the Selection Approach for Representative Volumes
We now provide the proof of our main result—the error estimates for the selection approach for representative volumes by Le Bris et al. [64]—which is stated in Theorems 2 and 3.
The idea for the proof of all statements of Theorem 2 is that Theorem 9 enables us in conjunction with Proposition 7 to approximate the joint probability distribution of \(a^{{\text {RVE}}}\) and \(\mathcal {F}(a)\) by a multivariate Gaussian with the same covariance matrix. The probability distribution of \(a^{{\text {sel-RVE}}}\) arises as the probability distribution of \(a^{{\text {RVE}}}\) conditioned on the event (14). As a consequence, the probability distribution of \(a^{{\text {sel-RVE}}}\) may be approximated by the marginal of the conditional probability distribution of an ideal multivariate Gaussian. The results of Theorem 2 on the probability distribution of \(a^{{\text {sel-RVE}}}\) are then a consequence of corresponding properties of multivariate normal distributions.
Proof of Theorem 2
For the proof of the theorem we may assume without loss of generality that \(\mathbb {E}[\mathcal {F}(a)]=0\). Throughout the proof, the constants c and C may depend on d, \(\lambda \), N, \(\gamma \), \(c_0\), and \(C_0\), if not otherwise stated.
Recall that the probability distribution of \(a^{{\text {sel-RVE}}}\) is given by the probability distribution of \(a^{{\text {RVE}}}\) conditioned on the event (14). Theorem 9 and Proposition 7 entail that the joint probability distribution of any component \(a^{{\text {RVE}}}_{ij}\) of \(a^{{\text {RVE}}}\) and \(\mathcal {F}(a)\) is close to a multivariate Gaussian \(\mathcal {N}_{{{\text {Var}}~}(a^{{\text {RVE}}}_{ij},\mathcal {F}(a))}(\cdot \,-\mathbb {E}[a^{{\text {RVE}}}_{ij}],\cdot )\). As a consequence of this result, the probability distribution of \(a^{{\text {sel-RVE}}}_{ij}\) may be approximated in a quantitative sense by the first-variable marginal of the conditional distribution of \(\mathcal {N}_{{{\text {Var}}~}(a^{{\text {RVE}}}_{ij},\mathcal {F}(a))}(\cdot \,-\mathbb {E}[a^{{\text {RVE}}}_{ij}],\cdot )\) given the event \(|\mathcal {F}(a)|\leqq \delta L^{-d/2}\). As we shall show below, the latter marginal probability distribution has the density
where the renormalization factor p is given by
and where the unexplained variance \({{{\text {Var}}~}a^{{\text {RVE}}}_{ij}|_{{\text {unexpl}}}}\) (that is the variance of \(a^{{\text {RVE}}}_{ij}\) which is not explained by the \(\mathcal {F}_n(a)\)) is given by
The assertions (15) and (16) on the systematic error and the variance reduction in Theorem 2 will be a consequence of the lower bound (18) on the probability of a random coefficient field satisfying the selection criterion, the related lower bound
the stretched exponential moment bounds for any \(\gamma <1/2\),
and the approximation result of the distribution of \(a^{{\text {sel-RVE}}}_{ij}\) by \(\mathcal {M}^\delta \)
for any continuous \({\tilde{\phi }}:\mathbb {R}\rightarrow \mathbb {R}\) satisfying
and
for all \(r>0\) and all \(x_0\in \mathbb {R}\). To obtain the \(\kappa \)-independent estimates (19) and (20), the bound (37) is replaced by
We defer the proof of (18) and (37) (as well as (39)) to the last step and first demonstrate that these estimates entail the assertions (15) and (16) of our theorem.
Step 1: Estimate on the systematic error. In order to derive the estimate on the systematic error (15), we first use the formula (34) and Fubini’s theorem to see that
where in the second step we have used the symmetry of the Gaussian \(\mathcal {N}_{{{\text {Var}}~}\mathcal {F}(a)}\). In other words, if the probability distribution of \((a^{{\text {RVE}}},\mathcal {F}(a))\) were an ideal multivariate Gaussian, we would have the perfect equality \(\mathbb {E}[a^{{\text {sel-RVE}}}]=\mathbb {E}[a^{{\text {RVE}}}]\).
We would now like to transfer the property (40) (up to an error) from \(\mathcal {M}^\delta \) to our actual probability distribution \(a^{{\text {sel-RVE}}}\) by choosing \({\tilde{\phi }}(x):=x\) in the estimate (37). However, this choice is not possible due to the upper bound on \({\tilde{\phi }}\) in (38a). Instead, for some cutoff factor \(B_c\geqq 1\) we consider the function \({\tilde{\phi }}(x) = \min \{\max \{x-\mathbb {E}[a^{{\text {RVE}}}_{ij}],-B_c L^{-d/2}\},B_c L^{-d/2}\}\). Note that for this choice of \({\tilde{\phi }}\) we have \(|\nabla {\tilde{\phi }}|\leqq 1\) and \(|{\tilde{\phi }}|\leqq B_c L^{-d/2}\). As a consequence, \(\frac{1}{B_c}{\tilde{\phi }}\) satisfies (38) and hence is an admissible choice in (37), which gives, by (40),
Using first the lower bounds (18) and (35) and the representation (44) and then in the next step Hölder’s inequality, the previous estimate implies
This yields, by Lemma 19b and the bounds (36a) and (36b),
Choosing \(B_c:=C|\log L|^{C(\gamma )}\), we deduce
Plugging in the bound for the systematic error of the standard representative volume element method \(|\mathbb {E}[a^{{\text {RVE}}}]-a_{\mathsf {hom}}|\leqq C L^{-d} |\log L|^C\) from [55] (note that this estimate for the systematic error of the standard representative volume element method may also be derived by slightly modifying the proof of our Proposition 7), we obtain (15). Repeating the previous proof but replacing the use of the estimate (37) by (39), we obtain (19).
Step 2: Proof of the variance reduction estimate. To prove the variance estimate (16), we proceed similarly and define for a cutoff factor \(B_c\geqq 1\) the function \(\phi (x):=\min \{(x-\mathbb {E}[a^{{\text {RVE}}}_{ij}])^2, B_c^2 L^{-d}\}\). Note that this function satisfies the global bounds \(|\nabla \phi |\leqq 2B_c L^{-d/2}\) and \(|\phi |\leqq B_c^2 L^{-d}\). Thus, \(\frac{1}{2 B_c^2 L^{-d/2}} \phi \) satisfies (38) and is therefore an admissible choice in (37), yielding
The tails (subject to truncation in our choice of \(\phi \)) can be estimated by
where in the last step we have used (18), (35), and (44). Applying Hölder’s inequality, we obtain
where in the last step we have used Lemma 19b and the bounds (36a) and (36b).
Combining this estimate with (42) and choosing \(B_c:=C|\log L|^{C(d,\gamma )}\), we infer
In other words, the variance of \(a^{{\text {sel-RVE}}}_{ij}\) is determined up to an error by the variance of the probability distribution \(\mathcal {M}^\delta \). To estimate the latter, a straightforward computation yields
By the symmetry of the set \(\{|y|\leqq \delta L^{-d/2}\}\) and the probability density \(\mathcal {N}_{{{\text {Var}}~}\mathcal {F}(a)}(y)\) we have \(\int _{\mathbb {R}^N} y \chi _{\{|y|\leqq \delta L^{-d/2}\}} \mathcal {N}_{{{\text {Var}}~}\mathcal {F}(a)}(y) \,\mathrm{d}y =0\). As a consequence, we get
Together with (43), this entails (16). To prove (20), we repeat the proof of (43) and just replace the use of (37) in the proof of (43) by (39).
Note that the lower bound (22) on the variance given in Theorem 4 follows also from the estimates (43) and (15) and the lower bound \(\int (x-\mathbb {E}[a^{{\text {RVE}}}_{ij}])^2 \mathcal {M}^\delta (x) \,\mathrm{d}x\geqq (1-|\rho |^2){{\text {Var}}~}a^{{\text {RVE}}}_{ij}\), the latter of which is derived analogously to the upper bound \(\int (x-\mathbb {E}[a^{{\text {RVE}}}_{ij}])^2 \mathcal {M}^\delta (x) \,\mathrm{d}x\leqq (1-(1-\delta ^2)|\rho |^2){{\text {Var}}~}a^{{\text {RVE}}}_{ij}\).
Step 3: The probability density of the reference distribution. For the purpose of this subsection, introduce the abbreviation for the covariance matrix
The probability density \(\mathcal {M}^\delta \) of the first-variable marginal of the corresponding multivariate Gaussian conditioned on \(|\mathcal {F}(a)|\leqq \delta L^{-d/2}\), which is the probability distribution by which we approximate the distribution of \(a^{{\text {sel-RVE}}}_{ij}\), is given by
Our goal is to show that this probability density \(\mathcal {M}^\delta \) may be rewritten in the form (34). To this end, we recall some basic linear algebra. The Schur complement of the symmetric block matrix
(with \(A^T=A\) and \(D^T=D\)) is given by \(T:=A-BD^{-1}B^T\), and the inverse of the matrix may be written as
The determinant may be expressed as \(\det M =\det T \cdot \det D\). The Schur complement allows us to rewrite the quadratic form defined by \(M^{-1}\) as
As a consequence, we get for \(M:=\Lambda \) that
and
Now, (34) and (44) are seen to be equivalent.
Step 4: Proof of the normal approximation estimate and the lower bound on the probability of the event\(|\mathcal {F}(a)|\leqq \delta L^{-d/2}\). First, let us show the lower bound (35). We have
establishing (35).
The estimate (36b) is a consequence of the estimate on \({{\text {Var}}~}(a^{{\text {RVE}}},\mathcal {F}(a))\) which follows from (36a), (13), and the exponential moment bounds for Gaussians. The bound (36a) is a consequence of Lemma 12 (note that by Proposition 7, Lemma 12 is indeed applicable).
Our next goal is to show (37) and (39). Let \({\tilde{\phi }}:\mathbb {R}\rightarrow \mathbb {R}\) satisfy (38) and suppose that we would like to estimate the error
As the distribution of \(a^{{\text {sel-RVE}}}_{ij}\) is obtained from the distribution of \(a^{{\text {RVE}}}_{ij}\) by conditioning on the event \(|\mathcal {F}(a)|\leqq \delta L^{-d/2}\), by (34) and (44) this error expression is equal to
Up to the normalizing factor \(1/\mathbb {P}\big [|\mathcal {F}(a)|\leqq \delta L^{-d/2}\big ]\), the first term on the right-hand side is given by
where \(\phi :\mathbb {R} \times \mathbb {R}^{N} \rightarrow \mathbb {R}\) is defined as
We would now like to show that (a suitable multiple of) the function \(\phi \) is admissible in the error bound (33). By the estimate
we obtain, for any \(z_0=(x_0-\mathbb {E}[a^{{\text {RVE}}}_{ij}],y_0)\in \mathbb {R}\times \mathbb {R}^N\), also making use of the abbreviation \(Q:={\text {Cov}}[a^{{\text {RVE}}},\mathcal {F}(a)]({{\text {Var}}~}\mathcal {F}(a))^{-1}\),
and therefore
By our assumption (13), this yields, for any \(z_0\in \mathbb {R}\times \mathbb {R}^N\),
Looking at Definition 8, we would have \(\frac{1}{C}\phi \in \Phi _\Lambda \) if it were not for the qualitative Lipschitz continuity condition for functions in \(\Phi _\Lambda \). However, for a standard family of mollifiers \(\rho _\varepsilon \) supported in \(\{|x|^2+|y|^2\leqq \varepsilon \}\) the approximations \(\phi _\varepsilon (x,y):= (\rho _\varepsilon *\phi ) (x,(1-2\delta ^{-1}L^{d/2}\varepsilon )y)\) satisfy \(\frac{1}{C}\phi _\varepsilon \in \Phi _\Lambda \) for any \(\varepsilon \in (0,\frac{1}{4}\delta L^{-d/2}]\) (see Definition 8) for some constant C. Furthermore, the \(\phi _\varepsilon \) converge poinwise to \(\phi \) for \(\varepsilon \rightarrow 0\) (by (47) and the continuity assumption on \({\tilde{\phi }}\); it is here that we need the dilation factor \((1-2\delta ^{-1}L^{d/2}\varepsilon )\) in the second variable due to the discontinuity in the definition (47)) and satisfy a uniform bound of the form \(|\phi _\varepsilon (x,y)|\leqq L^{-d/2}\) (by (47) and (38a)). Choosing the functions \(\frac{1}{C} \phi _\varepsilon \) in the definition of the distance \(\mathcal {D}\) and passing to the limit \(\varepsilon \rightarrow 0\), we infer
Theorem 9 is applicable to the random variable \(X:=(a^{{\text {RVE}}}_{ij},\mathcal {F}(a))\) by our assumptions on \(\mathcal {F}(a)\) (see Assumption 1) and by the multilevel decomposition of \(a^{{\text {RVE}}}_{ij}\) provided by Proposition 7. In total, with the notation \(\Lambda :={{\text {Var}}~}(a^{{\text {RVE}}}_{ij},\mathcal {F}(a))\) the application of Theorem 9 to \((a^{{\text {RVE}}}_{ij},\mathcal {F}(a))\) yields
where in the last step we have used (13) (which entails \(L^{-d} \leqq |\Lambda ^{1/2}|^2\)) and the definition of \(\kappa _{ij}\).
Applying a similar line of argument to the random variable \(\mathcal {F}(a)\) and the function
we obtain
where we have estimated \(\kappa ({{\text {Var}}~}\mathcal {F}(a))\) by (13). Together with the lower bound (35) and our assumption \(\delta ^N \geqq CL^{-d/2} |\log L|^{C(d,\gamma ,C_0)}\), this estimate implies (18).
Plugging in the estimate (48), the lower bound (18), and the estimate (49) as well as the assumption (38a) into (46), we deduce (37). The estimate (39) follows by repeating the above steps, but appealing in the proof of (48) to the bound (33) instead of (32) and choosing \(\Lambda :={{\text {Var}}~}(a^{{\text {RVE}}}_{ij},\mathcal {F}(a))+L^{-d/2-d/8}{\text {Id}}\) (which ensures by (13) that \(\kappa (\Lambda )\leqq CL^{d/8}\)). \(\quad \square \)
We now turn to the proof of the moderate-deviations-type result for the selection approach for representative volumes stated in Theorem 3.
Proof of Theorem 3
Fix \({\tilde{S}}\geqq CL^{-d/2-\beta /2}\). Our goal is to estimate the probability
The main task is the derivation of a suitable estimate for the numerator. To this aim, we apply the moderate deviations estimate from Theorem 10 to the random variable \((a^{{\text {RVE}}}_{ij}-\mathbb {E}[a^{{\text {RVE}}}_{ij}],\mathcal {F}(a))\) and the set \(A:=A_1\times A_2\) with
By Proposition 7 and our assumptions, the application of Theorem 10 is possible, resulting in the estimate
for some positive definite matrix \({\tilde{\Lambda }}\) with
We intend to apply the factorization property (45) to the matrix \({\tilde{\Lambda }}\) with the notation
By (52) and the bounds \(L^{-d}{\text {Id}}\leqq {{\text {Var}}~}\mathcal {F}(a) \leqq CL^{-d}{\text {Id}}\) (see (13)) and \({{\text {Var}}~}a^{{\text {RVE}}}_{ij} \leqq CL^{-d} |\log L|^d\) (see (36a)), we deduce
and
As a consequence of these estimates and (52), the formula (17) for \(|\rho |^2\) implies for \({\tilde{T}}:={\tilde{A}}-{\tilde{B}} {\tilde{D}}^{-1} {\tilde{B}}^T\) that
Using the bounds \({{\text {Var}}~}a^{{\text {RVE}}}_{ij}\leqq C L^{-d} |\log L|^d\) and \(|\rho |\leqq 1\) as well as (54), (17), and (13), we obtain for any \(|y|\leqq (\delta +CL^{-\beta })L^{-d/2}\) that
Applying the factorization property (45) to the first term on the right-hand side of (51), we obtain
Assuming that \({\tilde{S}}\geqq C L^{-d/2-\beta /2}\), we deduce
with
Using (53) to estimate the last factor in this estimate and assuming for the moment \({\tilde{S}} \geqq C\delta |\rho | \sqrt{{{\text {Var}}~}a^{{\text {RVE}}}_{ij}}\) as well as \(L\geqq C(\beta )\) to estimate the quotient in the first factor, we get
Using the bound \(L^{-d}{\text {Id}}\leqq {{\text {Var}}~}\mathcal {F}(a)\) from (13) and assuming \(L^{-2\beta }\leqq c\), we get
and therefore by the upper bound \(|\mathcal {N}_{{{\text {Var}}~}\mathcal {F}(a)}|\leqq C (L^{-d/2})^{-d}\) and the estimate on the volume \(|\{\delta L^{-d/2}\leqq |y|\leqq (\delta +2CL^{-\beta }) L^{-d/2}\}|\leqq C (L^{-d/2})^{d-1} L^{-d/2-\beta }\),
By \({\tilde{T}}\leqq (1-|\rho |^2){{\text {Var}}~}a_{ij}^{{\text {RVE}}}+CL^{-d-\beta }{\text {Id}}\) (which follows from (55)) and \({{\text {Var}}~}a_{ij}^{{\text {RVE}}}\leqq C L^{-d} {\text {Id}}\), we deduce from (57) under the assumptions \({\tilde{S}} \geqq C\delta |\rho | \sqrt{{{\text {Var}}~}a^{{\text {RVE}}}_{ij}}\) and \(L\geqq C(\beta )\)
As a consequence, we obtain
Plugging this bound into (51), we obtain
Inserting the previous estimate into (50) and using (49), (35), and (18) as well as the assumption \(\delta ^N \geqq C L^{-d/2}\) to estimate the denominator, we get
Note that we have the estimate \(|\mathbb {E}[a^{{\text {RVE}}}_{ij}]-a_{{\mathsf {hom}},ij}|\leqq C L^{-d} |\log L|^C\). By redefining \({\tilde{S}}\) (and possibly increasing the constant in (58); recall that \({\tilde{S}}\geqq L^{-d/2-\beta /2}\)), we obtain
Finally, we set \({\tilde{S}} := \sqrt{(1+\frac{C\delta }{\sqrt{1-|\rho |^2}s})(1-|\rho |^2){{\text {Var}}~}a_{ij}^{{\text {RVE}}}+L^{-d-\beta /2}} \cdot s\). Upon redefining \(\beta \), this yields the desired estimate (21).\(\quad \square \)
5 The Multilevel Local Dependence Structure of the Approximation for the Effective Conductivity
We now prove that the approximation \(a^{{\text {RVE}}}\) for the effective conductivity obtained by the representative volume element method may indeed be written as a sum of a family of random variables with multilevel local dependence structure in the sense of Definition 6. Furthermore, we show that the same is true for the spatial average of the coefficient field  and also for the second-order correction \(\mathcal {F}_{2-\mathrm{point}}(a)\) to \(a^{{\text {RVE}}}\) in the setting of small ellipticity contrast.
and also for the second-order correction \(\mathcal {F}_{2-\mathrm{point}}(a)\) to \(a^{{\text {RVE}}}\) in the setting of small ellipticity contrast.
Proof of Proposition 7
Part 1: The spatial average of the coefficient. First, let us show that the average  is approximately the sum of a family of random variables with multilevel local dependence structure. Decomposing
is approximately the sum of a family of random variables with multilevel local dependence structure. Decomposing

defining the \(X_y^0\) as indicated in this formula, and setting \(X_y^m:=0\) for \(m\geqq 1\), we immediately observe that the average \(\mathcal {F}_{avg}(a)\) is the sum of a family of random variables with multilevel local dependence structure with \(K:=1\). The bound (26) follows immediately from the uniform bound on a (with \(B:=||a||_{L^\infty }\) and arbitrary \(\gamma >0\)).
Part 2: The approximation\(a^{{\text {RVE}}}\)for the effective coefficient. Next, let us show that \(a^{{\text {RVE}}}\) is approximately the sum of a family of random variables with multilevel local dependence structure. For simplicity of notation, let us assume that \(\varepsilon =1\).
Recall that the corrector \(\phi _i\) associated with the periodized ensemble is the unique L-periodic solution to the equation
with vanishing average  . We shall use the decomposition of the (L-periodic) corrector \(\phi _i\) according to
. We shall use the decomposition of the (L-periodic) corrector \(\phi _i\) according to
where \(u_i=u_i(x,s)\) is the (L-periodic) solution to the parabolic PDE
Observe that the parabolic PDE directly entails
Thus, decay of \(u_i\) for \(t\rightarrow \infty \) implies that \(\phi _i\) may indeed be decomposed as \(\int _0^\infty u_i(\cdot ,s)\,\mathrm{d}s\). Note that exponential decay of \(u_i\) (with an L-dependent constant) is immediate by the standard energy estimate, the vanishing average of \(u_i(\cdot ,s)\) for any \(s\geqq 0\) (as the average of the initial conditions on \([0,L]^d\) vanishes), and the Poincaré inequality.
Recall the key result from [55] which states that under the assumptions of ellipticity, stationarity, and finite range of dependence (A1)–(A3) the full-space variant \(u_i^{\mathbb {R}^d}(\cdot ,s)\)—that is, the solution to the equation
with \(a^{\mathbb {R}^d}\) denoting a coefficient field from the original (non-periodic) ensemble of coefficient fields—actually decays like \(s^{-(1+d/2)/2}\) in suitable norms.
Theorem 11
([55], Corollary 4) Consider an ensemble of random coefficient fields \(a^{\mathbb {R}^d}\) subject to the assumptions (A1)–(A3) with range of dependence \(\varepsilon :=1\). Then for any \(T>0\) we have the estimate


where the random constant \(\mathcal {C}(a^{\mathbb {R}^d},T)\) satisfies for any \(\delta >0\) a bound of the form
Note that the second inequality (62b) is actually not contained in [55, Corollary 4]. However, it is an easy consequence of (62a) (the proof is provided below).
By \(\phi _j^*\) and \(u_j^*\) we shall denote the corresponding quantities for the adjoint coefficient field \(a^*\), that is \(\phi _j^*(\cdot ):=\int _0^\infty u_j^*(\cdot ,s)\,\,\mathrm{d}s\) with \(u_j^*\) being the L-periodic solution to
The full space variants \(u_j^{*,\mathbb {R}^d}\) satisfy also estimates of the form (62a)–(62b), as the conditions (A1)–(A3) are invariant under passing to the adjoint coefficient fields.
We introduce a “cutoff scale” \(L_K\) as the largest integer power of 2 not larger than \(\frac{L}{16 K \log L}\) for some constant \(K\geqq 1\) that remains to be chosen. Defining \(T_L:=(L_K)^2\), we now compute, using the properties (59), (60) and (61), that

We now decompose the integrals into integrals over cubes with side length \(\sim 2^k\), resulting in

We now intend to replace \(u_i\) and \(u_j^*\) in each of these expressions by a proxy with localized dependence. To this end, for any \(k\in \mathbb {N}_0\) and any \(x_0\in 2^k \mathbb {Z}^d\), define the coefficient field \(a_{k,x_0}\) on the full space \(\mathbb {R}^d\) as
Define a corresponding \(u_{i,k,x_0}\) as the solution to the equation
and introduce, analogously, the function \(u_{i,k,x_0}^*\) as the solution to the equation with \(a_{k,x_0}\) replaced by \(a^*_{k,x_0}\). Note that while \(u_i\) and a are defined on \([0,L]^d\) and extended to \(\mathbb {R}^d\) by periodicity, both \(a_{k,x_0}\) and \(u_{i,k,x_0}\) are defined on \(\mathbb {R}^d\) and lack any periodicity.
By Lemma 15—applied with \(M:=\frac{1}{2} \sqrt{K |\log L|}\) and \(r:=2^k\)—we have

for any \(t\leqq 4^{k+1}\) and

and analogous estimates for the difference \(u_j^*-u_{j,k,x_9}^*\).
As our probability distribution of coefficient fields a on \([0,L]^d\) is the periodization of a probability distribution of coefficient fields \(a^{\mathbb {R}^d}\) on \(\mathbb {R}^d\), by definition of a periodization (see (A3\(_c\))) for each \(x_0\in [0,L)^d\) and any \(k\leqq \log _2 L_K\) the law of \(a|_{x_0+K \log L [-2^k,2^k]^d}\) coincides with the law of \(a^{\mathbb {R}^d}|_{x_0+K \log L [-2^k,2^k]^d}\). As a consequence, the law of \(u_{i,k,x_0}\) coincides with the law of \(u_{i,k,x_0}^{\mathbb {R}^d}\), where \(u_{i,k,x_0}^{\mathbb {R}^d}\) is defined analogously to \(u_{i,k,x_0}\) (replacing a in the definition by \(a^{\mathbb {R}^d}\)). Therefore, any moment bound on \(u_{i,k,x_0}^{\mathbb {R}^d}\) carries over to \(u_{i,k,x_0}\). Applying Lemma 15 to \(u_{i,k,x_0}^{\mathbb {R}^d}\), we obtain estimates analogous to (66) and (67). The estimates from Theorem 11 therefore carry over to \(u_{i,k,x_0}^{\mathbb {R}^d}\), provided that we choose \(K\geqq C\); we have for \(t\in [4^k,4^{k+1}]\) and \(T=4^k\) with \(2^k\leqq L\) that

for some random constants \(\mathcal {C}(a^{\mathbb {R}^d},t)\), \(\mathcal {C}(a^{\mathbb {R}^d},T)\), with
for any \(\delta >0\). By the coincidence of laws, we get, for \(t\in [4^k,4^{k+1}]\) and \(T=4^k\),


for random constants \(\mathcal {C}\) satisfying
for any \(\delta >0\). Furthermore, the bound (102) yields an estimate of the form

By (61), its analogue for \(u_{i,0,x_0}\), and the definition of \(a_{0,x_0}\), we have in \(\{|x-x_0|\leqq 2d\}\) that \(-\nabla \cdot (a\nabla (\int _0^1 u_i(\cdot ,s)-u_{i,0,x_0}(\cdot ,s) \,\,\mathrm{d}s)) = u_i(\cdot ,1)-u_{i,0,x_0}(\cdot ,1)\), which implies, by the Caccioppoli inequality,

As a consequence of our definition of \(u_{i,k,x_0}\), for the choice
for \(0\leqq k\le \log _2 L_K\), we see, by (64) and (65) and \(\sqrt{K\log L}\geqq 1\), that \(X_{x_0}^k\) is a random variable which depends only on \(a|_{x_0+K \log L [-2^k,2^k]^d}\), that is the first condition of Definition 6 is satisfied. Furthermore, by (68) and (69), we obtain, for any \(0<\gamma <1\), an estimate of the form
We now intend to replace the terms in the first five terms on the right-hand side of (63) by the \(X_{x_0}^k\) with \(0\leqq k\le \log _2 L_K+1\), using the estimates (66), (67), (70), and Hölder’s inequality to bound the arising error. For example, we may estimate
where in the last step we have used \(4^k \leqq CL^2\) and \((2^k)^{d/2}\leqq C L^{d/2}\), absorbing these factors in the factor \(L^{-cK}\) (possible for \(cK\geqq 4+2d\)). Proceeding analogously for the other terms in (63), we deduce

Inserting the estimates (68) and (69), we get, for some \(\mathcal {C}(a)\) with \(||\mathcal {C}(a)||_{\exp ^\gamma } \leqq C(d,\lambda ,K,\gamma )\) for any \(\gamma \in (0,1)\),

The bound (66) and its equivalent for \(u_i^{\mathbb {R}^d}\) and \(u_{i,k,x_0}^{\mathbb {R}^d}\) enable us to transfer the bounds in Theorem 11 from \(u_i^{\mathbb {R}^d}\) to \(u_i\). Recalling that \(T_L=(L_K)^2\), we obtain

and
The latter estimate entails, in view of Theorem 11 (choosing \(K\geqq C\) and recalling that \(\sqrt{T_L}=L_K\leqq \frac{L}{4K \log L}\)), that

where again \(||\mathcal {C}(a^{\mathbb {R}^d},y,T_L)||_{\exp ^{2-\delta }}\leqq C(d,\lambda ,K,\delta )\). By coincidence of the laws of \(a|_{x_0+K \log L [-L_K,L_K]^d}\) and \(a^{\mathbb {R}^d}|_{x_0+K \log L [-L_K,L_K]^d}\), we get, for \(K\geqq C\) from the previous estimate and (74),

where \(||\mathcal {C}(a,T_L)||_{\exp ^\gamma }\leqq C(d,\lambda ,K,\gamma )\) for any \(\gamma <1\). An analogous bound holds for \(u_j^*\). Finally, the energy estimate for \(u_i\) implies

As the average of \(u_i\) over \({[0,L]^d}\) vanishes, the Poincaré inequality implies, for \(T\geqq T_L\),

and as a consequence,

Note that this estimate yields, in particular, that

where in the last step we have used that \(\sqrt{T_L}=L_K\) is the largest power of 2 with \(L_K\leqq \frac{L}{4 K \log L}\).
Plugging these bounds and (75) into (73), we get, for \(K\geqq C\),
with \(||\mathcal {C}(a,T_L)||_{\exp ^\gamma }\leqq C(d,\lambda ,K,\gamma )\) for any \(\gamma <1\). Choosing \(\gamma \in (0,1)\) and \(B:=C(d,\lambda ,K,\gamma ) (4K \log L)^{2+d}\) in Definition 6, defining the variable \(X_0^{\log _2 L+1}\) (which may depend on a on the full volume \([0,L]^d\)) to account for the remaining difference \(a^{{\text {RVE}}}e_i \cdot e_j-\sum _{k=0}^{1+\log _2 L_K} \sum _{x_0\in 2^k \mathbb {Z}^d\cap [0,L)^d} X_{x_0}^k\), and setting the remaining \(X_i^{k}:=0\) for \(\log _2 L_K+1<k<\log _2 L+1\), establishes that \(a^{{\text {RVE}}}\) may be rewritten as a sum of a family of random variables with multilevel local dependence.
Part 3: The higher-order statistical quantity Next, we derive the multilevel decomposition of the higher-order quantity in the small ellipticity contrast setting \(\mathcal {F}_{2-\mathrm{point}}\). To do this, we decompose the solution \(v_i\) to (28) as
where \(w_i\) is defined as the solution to the parabolic PDE
As before, the representation (77) follows from the exponential decay of \(w_i\), as we have \(-\Delta \int _0^T w_i (\cdot ,t)\,\mathrm{d}t = \nabla \cdot (ae_i)-w_i(\cdot ,T)\).
We introduce analogous definitions for \(v_j^*\). Again, we may assume without loss of generality that \(\varepsilon =1\). We then observe, following an argument of Mourrat [72], that by formula (78) below, we have

Next, we deduce

We may now proceed to argue just as in the case of \(a^{{\text {RVE}}}\). The required decay estimates for the semigroup of the form

(with \(||\mathcal {C}(a,T,x_0)||_{\exp ^2}\leqq C(d,\lambda )\)) are now a consequence of the explicit heat kernel representation of the solution \(w_i\) (as we are now dealing with a constant-coefficient parabolic equation), the finite range of dependence \(\varepsilon =1\) of the initial data \(w_i(\cdot ,0)=\nabla \cdot (ae_i)\), and standard Gaussian concentration estimates (or, alternatively—though then with a less strong stretched exponential bound—the concentration estimates of Lemma 20).
In the computation above we have used the simple fact that

Part 4: Convergence of the variance Finally, we prove that the rescaled variances \(L^d {{\text {Var}}~}a^{{\text {RVE}}}\), \(L^d {{\text {Var}}~}\mathcal {F}_{avg}(a)\), and \(L^d {{\text {Var}}~}\mathcal {F}_{2-\mathrm{point}}(a)\) and the covariances \(L^d {\text {Cov}}[a^{{\text {RVE}}},\mathcal {F}_{avg}(a)]\), \(L^d {\text {Cov}}[a^{{\text {RVE}}},\mathcal {F}_{2-\mathrm{point}}(a)]\), and \(L^d {\text {Cov}}[\mathcal {F}_{avg}(a),\mathcal {F}_{2-\mathrm{point}}(a)]\) converge for \(L\rightarrow \infty \). We limit ourselves to proving the convergence of the rescaled variance \(L^d{{\text {Var}}~}a^{{\text {RVE}}}\); the proofs for the convergence of the other variances and the covariances are analogous. Furthermore, to simplify notation, we limit ourselves to proving the convergence of the variance for \(L=2^n\) for some \(n\in \mathbb {N}\); the proof in the general case is similar.
By Lemma 12, we obtain \({{\text {Var}}~}a^{{\text {RVE}}}\leqq C(d,\lambda ,K) L^{-d} |\log L|^{C(d)}\). Using (76) and this estimate, we deduce
Expanding the sum and using stochastic independence of many of these terms, we may write
Denote by \(X_{y}^{k,\mathbb {R}^d}\) the quantities defined as in (71) but with \(u_{i,k,x_0}\) and \(u_{j,k,x_0}^*\) replaced by \(u_i^{\mathbb {R}^d}\) and \(u_j^{*,\mathbb {R}^d}\), that is for example, for \(k\geqq 0\) and \(y\in 2^k \mathbb {Z}^d\),
Set \(X_{y}^{k,\infty }:=L^d X_{y}^{k,\mathbb {R}^d}\). Note that \({\text {Cov}}[X_{y}^{k,\infty },X_{{\tilde{y}}}^{{\tilde{k}},\infty }]\) does not depend on L (by definition of \(X_y^{k,\mathbb {R}^d}\)). By the full-space variants of the estimates (66), (67), and (70) (that is the estimates for the differences \(u_i^{\mathbb {R}^d}-u_{i,k,x_0}^{\mathbb {R}^d}\) etc., which are derived in exactly the same way) and (72) as well as the equality of laws of (products of the) \(u_{i,k,x_0}\) etc. and (products of the) \(u_{i,k,x_0}^{\mathbb {R}^d}\) etc. , we get for \(k,{\tilde{k}}\leqq 1+\log _2 L_K\) that
By the definition of the \(X_y^k\) (see (71)), the definition of the \(u_{i,k,x_0}\), and the stationarity of the probability distribution of \(a^{\mathbb {R}^d}\), the covariance \({\text {Cov}}[X_{y}^{k,\mathbb {R}^d},X_{{\tilde{y}}}^{{\tilde{k}},\mathbb {R}^d}]\) depends only on k, \({\tilde{k}}\), \(y-{\tilde{y}}\), L, and the law of \(a^{\mathbb {R}^d}\) (but not on y for fixed \(y-{\tilde{y}}\)). Furthermore, by (72) we have \(|{\text {Cov}}[X_{{\tilde{y}}}^{{\tilde{k}}},X_y^k]|\leqq C L^{-2d}\). This implies, by (79),
for K chosen large enough.
The fact that (by stochastic independence) we have \({\text {Cov}}[L^d X_{{\tilde{y}}}^{{\tilde{k}}},L^d X_y^{k}]=0\) for \(|y-{\tilde{y}}|_{{\text {per}}}\geqq C(d) 2^k K \log L\) and \(k\geqq {\tilde{k}}\) implies together with (79) and the definition of \(X_y^{k,\infty }\) that (by selecting K large enough and by choosing L to be just small enough for \(|y-{\tilde{y}}|\geqq C(d) 2^k K \log L\) to hold in case \(|y-{\tilde{y}}|\geqq C(d) K 2^k\), and otherwise—that is for \(|y-{\tilde{y}}|\leqq C(d) K 2^k\)—appealing to the upper bound (72))
As a consequence, we obtain
This implies
We now distinguish the cases \({\tilde{y}}\in [-R_k 2^k,R_k 2^k]^d\) and \({\tilde{y}}\notin [-R_k 2^k,R_k 2^k]^d\) for some \(R_k\) to be chosen. Using (80) in the latter case, we get
For \({\tilde{k}} \leqq k\) and \(R 2^k \leqq L_K\) we have, by Lemma 12 and (72),
which entails, by (79), upon choosing \(L^{1/2}=R2^k\),
As a consequence, choosing \(R_k=Sk\) for \(S\geqq 1\) large enough, we get
In total, we have shown convergence of the rescaled variance \(L^d {{\text {Var}}~}a^{{\text {RVE}}}\) towards a limit independent of L with the desired rate.
The proof of the other cases is analogous. \(\quad \square \)
Proof of Theorem 11
The estimate (62a) is contained in [55, Corollary 4]. In view of the Poincaré inequality the bound (62b) is a consequence of (62a) and an estimate on a (weighted) average of \(u_i^{\mathbb {R}^d}\). Hence, we only need to derive a bound on
for a suitably chosen smooth function \(\psi \) supported in \(\{|x|\leqq 1\}\). To this end, we compute
which yields upon applying the Poincaré inequality to the second term (note that the second factor in the integral has vanishing average) and using the bound (62a)
Summing over a dyadic sequence of times \(2^k T\) and using the fact that almost surely
we infer (62b) (upon redefining the constant \(\mathcal {C}(a,T)\)). \(\quad \square \)
In the previous proofs, we have made use of the following elementary concentration estimate for sums of random variables with multilevel local dependence:
Lemma 12
([43], Lemma 9) Consider a probability distribution of uniformly elliptic and bounded coefficient fields a on \(\mathbb {R}^d\) or a periodization of such a probability distribution, and suppose that assumptions (A1)–(A3) respectively (A1), (A2), (A3\(_a\))–(A3\(_c\)) are satisfied. Let \(X=X(a)\) be a random variable that is approximately a sum of random variables with multilevel local dependence in the sense of Definition 6. Then for \({\tilde{\gamma }}:=\gamma /(\gamma +1)\) the concentration estimate
holds true.
6 Failure and Success of the Variance Reduction Approaches
We now establish our theorems on the failure and the success of the variance reduction approaches in stochastic homogenization. We start with the counterexample that shows that in general there is no guarantee that the variance reduction techniques provide an effective reduction of the variance, even for “natural” choices of the statistical quantity \(\mathcal {F}(a)\) like the spatial average  .
.
Proof of Theorem 4
Before turning to the main result of Theorem 4, the failure of the spatial average \(\mathcal {F}_{avg}(a)\) to explain a fraction of the variance of \(a^{{\text {RVE}}}\) (inequality (23)), let us first show (22). The estimate (22) is in fact a consequence of the estimate (43) in the proof of Theorem 2 in combination with (41) and the lower bound for the variance of \(\mathcal {M}^\delta \) which is a straightforward consequence of the formula (34) and the definition of \({{{\text {Var}}~}a^{{\text {RVE}}}_{ij}|_{{\text {unexpl}}}}=(1-|\rho |^2){{\text {Var}}~}a_{ij}^{{\text {RVE}}}\).
Note that the derivation of (24) from (23) requires the estimate (22) under the assumption (A2’) instead of (A2). However, the only place where the assumption (A2) entered in our analysis is in Proposition 7, where it was used to apply the result of [55] on the decay of the semigroup. However, the arguments of [55] may be modified to yield the corresponding estimate under the assumption of discrete stationarity (A2’).
Let us now turn to the construction of our counterexample featuring the degenerate covariance (23). The construction is based on the following ideas:
-
The approximation \(a^{{\text {RVE}}}\) for the effective coefficient depends in a uniformly continuous way on a as a map \(L^\infty ([0,L\varepsilon ]^d;\mathbb {R}^{d\times d})\rightarrow \mathbb {R}^{d\times d}\), as long as a is uniformly elliptic and bounded.
-
Consider a probability distribution of coefficient fields a for which a is almost surely almost everywhere a multiple of the identity matrix. If in addition the law of a is invariant under reflections of coordinate axes and invariant under exchange of coordinate axes (that is, invariant under diagonal reflections), the covariance

is a multiple of \({\text {Id}}\otimes {\text {Id}}\). For a proof of this fact, see Lemma 13, below.
-
Consider the “periodized random checkerboard” with the set of tiles \(\mathcal {T}:=\{x_0+[0,\varepsilon )^d: x_0\in \varepsilon \mathbb {Z}^d\cap [0,L\varepsilon )^d\}\). On each tile \(T\in \mathcal {T}\), choose at random (and independently from the other tiles) \(a(x)={\text {Id}}\) with probability 0.5 and \(a(x)=\frac{1}{2} {\text {Id}}\) with probability 0.5. By Proposition 5 and the preceding considerations, for this probability distribution the covariance
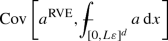
is a positive multiple of \({\text {Id}}\otimes {\text {Id}}\); in fact, one has a lower bound of the form \(\gtrsim L^{-d}{\text {Id}}\otimes {\text {Id}}\).
-
We now consider a “periodized random checkerboard with microstructure” with the set of tiles \(\mathcal {T}:=[0,\varepsilon )^d+ (\varepsilon \mathbb {Z}^d\cap [0,L\varepsilon )^d)\): Fix some \(\tau \ll 1\) with \(1/\tau \in 2\mathbb {N}\). On each tile \(T=\varepsilon k +[0,\varepsilon )^d \in \mathcal {T}\), choose at random (and independently from the other tiles) \(a_\tau (x)=\sigma {\text {Id}}\) with probability 0.5 (where \(\sigma >0\) is to be chosen below) and \(a_\tau (x)=A_{\tau }((x-\varepsilon k)/\varepsilon )\) with probability 0.5, where \(A_{\tau }:[0,1]^2\rightarrow \mathbb {R}^{2\times 2}\) is the tile described in Fig. 5, rotated and reflected at random (with equal probability for all 8 orientations and independently on all such tiles; see Fig. 6 for an illustration). The probability distribution of a satisfies the same isotropy properties as in the case of the periodized random checkerboard. Thus, by Lemma 13 the covariance

is a multiple of \({\text {Id}}\otimes {\text {Id}}\).
-
We shall argue below that for suitable \(\sigma ,\lambda ,\mu >0\) and for \(\tau \ll 1\) small enough the covariance

is negative; in fact, one has an upper bound of the form \(\lesssim -L^{-d} {\text {Id}}\otimes {\text {Id}}\).
-
Linearly interpolating between \(a_\tau \) and a—that is, considering for \(\kappa \in [0,1]\) the coefficient field
$$\begin{aligned} a_{\tau ,\kappa }:=(1-\kappa ) a + \kappa a_\tau \end{aligned}$$defined on the product probability space, that is for independent \(a_\tau \) and a—we find a probability distribution of coefficient fields \({\tilde{a}}\) for which the covariance
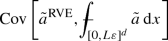
vanishes. This is possible by the continuous dependence of \(a^{{\text {RVE}}}\) and
 on a (and hence the continuous dependence on \(\kappa \in [0,1]\) in the case of the family \(a_{\tau ,\kappa }\)) and by the fact that for all \(\kappa \in [0,1]\) the covariance
on a (and hence the continuous dependence on \(\kappa \in [0,1]\) in the case of the family \(a_{\tau ,\kappa }\)) and by the fact that for all \(\kappa \in [0,1]\) the covariance 
is a multiple of \({\text {Id}}\otimes {\text {Id}}\) (this latter property holds again by the isotropy properties of the probability distribution and Lemma 13, below).
-
For any \(\kappa \in (0,1)\) the variances
 and \({{\text {Var}}~}a^{{\text {RVE}}}_{\tau ,\kappa }\) are nondegenerate in the sense \(\gtrsim L^{-d}{\text {Id}}\otimes {\text {Id}}\). For the spatial average
and \({{\text {Var}}~}a^{{\text {RVE}}}_{\tau ,\kappa }\) are nondegenerate in the sense \(\gtrsim L^{-d}{\text {Id}}\otimes {\text {Id}}\). For the spatial average  this non-degeneracy is an easy consequence of the formula
this non-degeneracy is an easy consequence of the formula 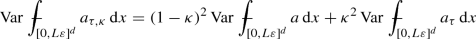
(which follows from the definition of \(a_{\tau ,\kappa }\) and the independence of a and \(a_\tau \)) and the fact that the latter two variances satisfy such a lower bound (note that the spatial average of the coefficient field on a tile with microstructure \(A_{\tau }\) does not equal \(\sigma {\text {Id}}\)). The non-degeneracy of \({{\text {Var}}~}a_{\tau ,\kappa }^{{\text {RVE}}}\) is shown as follows: first, a new coefficient field \(a_{\tau ,\kappa ,{\text {eff}}}\) is introduced by letting \(a_{\tau ,\kappa ,{\text {eff}}}=a_{\tau ,\kappa }\) on each tile without microstructure but replacing the values of \(a_{\tau ,\kappa }\) by the effective coefficient from periodic homogenization on each tile with microstructure. Note that \(a_{\tau ,\kappa ,{\text {eff}}}\) corresponds to a standard random checkerboard. Denote by \(a_{\tau ,\kappa ,{\text {eff}}}^{{\text {RVE}}}\) the approximation for the effective coefficient associated with the coefficient field \(a_{\tau ,\kappa ,{\text {eff}}}\) (that is the result of formula (8) for the coefficient field \(a_{\tau ,\kappa ,{\text {eff}}}\)). The nondegeneracy of \({{\text {Var}}~}a_{\tau ,\kappa }^{{\text {RVE}}}\) now follows from the nondegeneracy \({{\text {Var}}~}a_{\tau ,\kappa ,{\text {eff}},ii}^{{\text {RVE}}}\gtrsim L^{-d}\) and the convergence \(|a_{\tau ,\kappa }^{{\text {RVE}}}-a_{\tau ,\kappa ,{\text {eff}}}^{{\text {RVE}}}|\rightarrow 0\) for \(\tau \rightarrow 0\) (uniformly in \(\kappa \), see below). Note that \(a_{\tau ,\kappa ,{\text {eff}}}^{{\text {RVE}}}\) corresponds to a random checkerboard with tiles \((\kappa \sigma + (1-\kappa )){\text {Id}}\), \(\kappa \sigma + (1-\kappa )\cdot \frac{1}{2}{\text {Id}}\), \(\kappa A_{\tau } + (1-\kappa ){\text {Id}}\), and \(\kappa A_{\tau } + (1-\kappa ) \cdot \frac{1}{2}{\text {Id}}\), each tile chosen with probability \(\frac{1}{4}\) (and the microscopic tiles rotated and reflected at random). Thus the nondegeneracy of \({{\text {Var}}~}a_{\tau ,\kappa ,{\text {eff}},ii}^{{\text {RVE}}}\) for \(1\leqq i\le d\) follows from the covariance estimate of Proposition 5 and the quantitative upper bound
 .
.

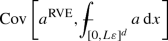


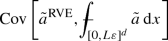
 on a (and hence the continuous dependence on
on a (and hence the continuous dependence on 
 and
and  this non-degeneracy is an easy consequence of the formula
this non-degeneracy is an easy consequence of the formula 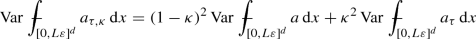
 .
.
A single tile with (second-order laminate) microstructure, as used in the proof of Theorem 4. Blue corresponds to the regions with \(a(x)=\lambda {\text {Id}}\), red to the regions with \(a(x)={\text {Id}}\), and violet to the regions with \(a(x)=\mu {\text {Id}}\)

A single realization of the probability distribution of our counterexample (with an exaggerated size of the microstructure in the tiles with microstructure). The tiles with microstructure behave almost like a homogeneous tile with an effective conductivity. Note that the tiles with microstructure are oriented randomly in order to enforce exact isotropy of the (co-)variances \({{\text {Var}}~}a^{{\text {RVE}}}\) and 
To complete the proof, it only remains to establish the negativity of the covariance

for \(\tau \ll 1\) small enough and suitable \(\sigma \), \(\mu \), \(\lambda \), as well as the convergence \(a_{\tau ,\kappa }^{{\text {RVE}}}\rightarrow a_{\tau ,\kappa ,{\text {eff}}}^{{\text {RVE}}}\) for \(\tau \rightarrow 0\), uniformly in \(\kappa \). The underlying idea for our choice of the tiles in Fig. 5 is that we intend to exploit the nonlinear dependence of the effective coefficients in periodic homogenization on the coefficient field, equipping such a tile with an effective coefficient that is unrelated to the spatial average of the coefficient field. Heuristically, by classical results in periodic homogenization we expect the following to happen:
-
Consider our (sub)pattern of periodic horizontal stripes of equal height (that is the red-and-blue subpattern in Fig. 5), in which the coefficient field a alternatingly takes the values \({\text {Id}}\) and \(\lambda {\text {Id}}\). Then the (large-scale) effective coefficient for this pattern is given by
$$\begin{aligned} \begin{pmatrix} \frac{1+\lambda }{2}&{}0\\ 0&{}\frac{2\lambda }{1+\lambda } \end{pmatrix}, \end{aligned}$$that is by the arithmetic mean in the horizontal direction and by the harmonic mean in the vertical direction.
-
Consider now the pattern of periodic vertical stripes of equal width, in which the coefficient alternatingly takes the value \(\mu {\text {Id}}\) respectively is given by the pattern of horizontal stripes from the previous step. The effective coefficient for this (second-order laminate) pattern is (at least in the limit of an infinitesimally fine horizontal pattern) given by the arithmetic mean of the effective coefficients in the vertical direction and the harmonic mean of the effective coefficients in the horizontal direction, that is by
$$\begin{aligned} \begin{pmatrix} \frac{2\mu (1+\lambda )}{2\mu +1+\lambda }&{}\quad 0\\ 0&{}\quad \frac{\lambda }{1+\lambda }+\frac{\mu }{2}. \end{pmatrix}. \end{aligned}$$Choosing \(\mu :=\frac{3\lambda ^2+(1-\lambda )\sqrt{9\lambda ^2+14\lambda +9}+2\lambda +3}{4(\lambda +1)}\)—which is positive for any \(\lambda \in (0,1]\)—, the effective coefficient becomes a multiple of the identity matrix. Note that the spatial average of the coefficient field on a tile is given by
$$\begin{aligned} \frac{\mu +\frac{\lambda +1}{2}}{2} {\text {Id}}. \end{aligned}$$ -
Consider the coefficient field \(a_{\tau ,{\text {eff}}}\) that is obtained from our random checkerboard with microstructure \(a_\tau \) by replacing \(a_\tau \) on the tiles with microstructure with the effective coefficient \((\frac{\lambda }{1+\lambda }+\frac{\mu }{2}){\text {Id}}\). The coefficient field \(a_{\tau ,{\text {eff}}}\) is now just a usual random checkerboard; by Lemma 13 and Proposition 5, the covariance

is a positive multiple of \({\text {Id}}\otimes {\text {Id}}\), and we have a lower bound of the form \(\geqq cL^{-d} {\text {Id}}\otimes {\text {Id}}\) for the choice of \(\lambda \), \(\mu \), and \(\tau \) to be made below. Note that \(a_{\tau ,{\text {eff}}}\)—and hence also the preceding covariance—is actually independent of \(\tau \) (we just keep the \(\tau \) to emphasize that \(a_{\tau ,{\text {eff}}}\) is the coefficient field obtained from \(a_\tau \) in the homogenization limit \(\tau \rightarrow 0\)). We shall prove below that \(a_\tau ^{{\text {RVE}}}\) is (quantitatively) close to \(a_{\tau ,{\text {eff}}}^{{\text {RVE}}}\) for \(\tau \ll 1\) small enough, which implies that
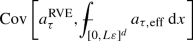
is close to a positive multiple of \({\text {Id}}\otimes {\text {Id}}\) (again with a lower bound of the form \(\geqq c L^{-d} {\text {Id}}\otimes {\text {Id}}\)).
-
The average
 is an affine function of
is an affine function of 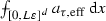 : The coefficient field \(a_{\tau ,{\text {eff}}}\) is constant on each tile and may only take the values \(\sigma {\text {Id}}\) or \((\frac{\lambda }{1+\lambda }+\frac{\mu }{2}){\text {Id}}\). On the tiles on which the value of \(a_{\tau ,{\text {eff}}}\) is \(\sigma {\text {Id}}\), \(a_\tau \) also takes the constant value \(\sigma {\text {Id}}\). However, on the tiles on which \(a_{\tau ,{\text {eff}}}\) is given by \((\frac{\lambda }{1+\lambda }+\frac{\mu }{2}){\text {Id}}\) (that is on the tiles on which \(a_\tau \) features a microstructure), the average of \(a_\tau \) is \(\frac{2\mu +\lambda +1}{4}{\text {Id}}\). We thus have
: The coefficient field \(a_{\tau ,{\text {eff}}}\) is constant on each tile and may only take the values \(\sigma {\text {Id}}\) or \((\frac{\lambda }{1+\lambda }+\frac{\mu }{2}){\text {Id}}\). On the tiles on which the value of \(a_{\tau ,{\text {eff}}}\) is \(\sigma {\text {Id}}\), \(a_\tau \) also takes the constant value \(\sigma {\text {Id}}\). However, on the tiles on which \(a_{\tau ,{\text {eff}}}\) is given by \((\frac{\lambda }{1+\lambda }+\frac{\mu }{2}){\text {Id}}\) (that is on the tiles on which \(a_\tau \) features a microstructure), the average of \(a_\tau \) is \(\frac{2\mu +\lambda +1}{4}{\text {Id}}\). We thus have 
and

Choosing \(\sigma \) such that \(\sigma >\frac{\lambda }{1+\lambda }+\frac{\mu }{2}\) but \(\sigma <\frac{2\mu +\lambda +1}{4}\)—which is possible for \(\lambda >0\) small enough—, we obtain a relation of the form
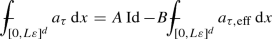
for suitable positive constants A and B. Thus, the sign of the covariance flips upon replacing the \(a_{\tau ,{\text {eff}}}\) by \(a_\tau \) in the spatial average, that is

must be a negative multiple of \({\text {Id}}\otimes {\text {Id}}\), with an upper bound of the form \(\leqq -cL^{-d} {\text {Id}}\otimes {\text {Id}}\).

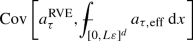
 is an affine function of
is an affine function of 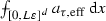 : The coefficient field
: The coefficient field 

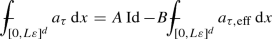

It now only remains to prove two things: We need to show that \(a_\tau ^{{\text {RVE}}}\) is quantitatively close to \(a_{\tau ,{\text {eff}}}\) if we choose the width \(\tau \) of the vertical stripes and the height \(\tau ^2\) of the horizontal stripes in the pattern in Fig. 5 small enough and we need to establish the corresponding assertion for the interpolated coefficient field \(a_{\tau ,\kappa ,{\text {eff}}}\). As the latter result is shown similarly—though with two different microscopic tiles \(\kappa A_{\tau }+(1-\kappa )\frac{1}{2}{\text {Id}}\) and \(\kappa A_{\tau }+(1-\kappa )\frac{1}{2}{\text {Id}}\), depending on whether the random checkerboard a equals \({\text {Id}}\) or \(\frac{1}{2}{\text {Id}}\) on the tile (and correspondingly, with two sets of homogenization correctors and two characteristic functions \(\chi _{microtile1}\) and \(\chi _{microtile2}\), see below for this notation)—we only provide the proof of the latter result.
For the remainder of the proof, we shall fix without loss of generality \(\varepsilon :=1\) to avoid even more cumbersome notation. Again, to avoid even more cumbersome notation, we only give the proof in the case that all tiles with microstructure have the same orientation as in Fig. 5.
To see this quantitative closeness, we construct an approximate homogenization corrector \(\phi _{i,{\text {appr}}}\) for \(a_\tau ^{{\text {RVE}}}\). To this end, let \(\phi _{i,{\text {eff}}}\) be the homogenization corrector associated with the coefficient field \(a_{\tau ,{\text {eff}}}\), that is let \(\phi _{i,{\text {eff}}}\) solve
on \([0,L]^2\) with periodic boundary conditions. We now intend to build the approximate homogenization corrector \(\phi _{i,{\text {appr}}}\) for \(a_\tau ^{{\text {RVE}}}\) by a nested two-scale expansion, using the homogenization correctors for the periodic laminate microstructures.
By Meyer’s estimate, there exists \(p>2\) with

Furthermore, \(a_{\tau ,{\text {eff}}}\) is constant on each tile \(k + [0,1)^2\), which implies on each tile \(T=k + [0,1)^2\) (with \(k\in \mathbb {Z}^2\)) for each \(x\in T\) by regularity theory for constant coefficient equations

Let \(\rho _\delta \) denote a standard mollifier. The \(L^p\) estimate and the estimate on \(\nabla ^2 \phi _{i,{\text {eff}}}\) imply (for notational convenience we extend \(\phi _{i,{\text {eff}}}\) by periodicity)

for some \(\alpha >0\) (for a proof of this estimate, split the domain into a neighborhood of size \(\delta ^{1/5}\) of the tile boundaries \(\partial T\), on which one uses the Hölder inequality and the \(L^p\) bound on \(\nabla \phi _{i,{\text {eff}}}\) in (81), and the interior \(\{x\in T:{\text {dist}}(x,\partial T)\geqq \delta ^{1/5}\}\), where one applies the regularity estimate (82)).
Let \(\phi _{i,h}\) denote the 2-periodic homogenization corrector for the coefficient field \(a_h(x,y)\) associated with the pattern of horizontal stripes in Fig. 5 (that is let \(a_h(x,y)=a_h(y)\) take alternatingly on intervals of length 1 the values \({\text {Id}}\) and \(\lambda {\text {Id}}\)). Note that \(\phi _{1,h}\equiv 0\) and that \(\phi _{2,h}\) is explicitly given by

We shall frequently use the uniform bound on the gradient \(|\nabla \phi _{i,h}|\leqq C\) derived easily from this formula.
Let \(\phi _{i,v}\) denote the 2-periodic homogenization corrector associated with the pattern of vertical stripes of width 1, in which the coefficient field \(a_v(x,y)=a_v(x)\) alternatingly takes the values \(\mu {\text {Id}}\) and
Note that we have \(\phi _{2,v}\equiv 0\) and that \(\phi _{1,v}\) is given explicitly by

We shall again frequently use the uniform bound on the gradient \(|\nabla \phi _{i,v}|\leqq C\).
We define the vector potential for the flux correction \(\sigma _{h,ijk}\), skew-symmetric in its last two indices, as \(\sigma _{h,212}:=0\) and
Note that with this definition \(\sigma _{h,ijk}\) satisfies \(\nabla \cdot \sigma _{h,i} = a_h (e_i+\nabla \phi _{i,h})-a_{h,{\text {eff}}}e_i\), as one checks by a case-by-case analysis.
Similarly, we define \(\sigma _{v,ijk}\), skew-symmetric in its last two indices, as \(\sigma _{v,121}:=0\) and
which then satisfies \(\nabla \cdot \sigma _{v,i} = a_v (e_i+\nabla \phi _{i,v})-a_{v,{\text {eff}}}e_i\).
Let us denote the indicator function of the tiles with microstructure by \(\chi _\mathrm{microtile}\) (that is \(\chi _\mathrm{microtile}\) is 1 on all tiles \(k+[0,1)^d\subset [0,L)^d\) with microstructure and 0 on the other tiles). Similarly, we denote by \(\chi _{v\mathrm{microstripe}}\) the indicator functions of all vertical stripes that according to Fig. 5 contain a micropattern of horizontal stripes. We then build our approximate correctors as
and
We observe that \(\phi _{i,{\text {appr}},1}\) satisfies the estimate
We also have the bound
Furthermore, if we are at least \(\tau \delta _1\) away from the tile boundaries and the boundaries of the vertical stripes (note that \(\rho _{\delta _1 \tau } *\nabla \phi _{j,v}(\cdot /\tau )\) is then equal to \(\nabla \phi _{j,v}(\cdot /\tau )\) as the latter quantity is constant in each stripe; note also that then \(\rho _{\tau \delta _1} *\chi _{microtile}\) is locally constant \(=0\) or \(=1\) and that we have a uniform bound on \(\nabla \phi _{j,v}\)), we have by (82) on each tile \(T=k + [0,1)^2\), \(k\in \mathbb {Z}^d\cap [0,L)^d\),

If we are at least \(\tau \delta _1\) away from the tile boundaries and the boundaries of the vertical stripes and at least \(\tau ^2 \delta _2\) away from the boundary of the horizontal stripes, we get (note that \(\rho _{\delta _2 \tau ^2} *\nabla \phi _{k,h}(\cdot /\tau ^2)\) is then equal to \(\nabla \phi _{k,h}(\cdot /\tau ^2)\) as the latter quantity is constant in each small horizontal stripe; note also that then \(\rho _{\tau ^2 \delta _2} *\chi _{hmicrostripe}\) is locally constant \(=0\) or \(=1\) and that we have a uniform bound on \(\nabla \phi _{k,h}\))

Using the fact that by Meyers inequality we have for some \(p=p(\lambda )>2\) that

we obtain, by choosing \(\delta _0\), \(\delta _1\), and \(\delta _2\) as appropriate powers of \(\tau \) and using (87),

for some \(\eta >0\).
Having bounded the error in the gradient, we next estimate the error in the flux. In an analogous fashion to the definition of \(a_{\tau ,{\text {eff}}}\) as the effective coefficient from periodic homogenization on each tile, we define \(a_{\tau ,{\text {veff}}}\) as equal to \(a_{\tau ,{\text {eff}}}=a_\tau \) on the tiles without microstructure and equal to the effective coefficient from periodic homogenization on each vertical stripe of width \(\tau \) on each tile with microstructure. Recalling the definitions (84) and (85), we may rewrite the error in the flux in a pointwise way as
Thus, having choosen \(\delta _0\), \(\delta _1\), and \(\delta _2\) as suitable powers of \(\tau \), we obtain, by (89), (82) and (81),

It now only remains to show that \(\nabla \phi _{i,{\text {appr}},2}\) is a good approximation for \(\nabla \phi _i\). To do so, we consider the difference \(\phi _i-\phi _{i,{\text {appr}},2}\) and observe that it satisfies the PDE
We now replace the divergence-form right-hand side using (89)
for some g with  (recall that \(\delta _1\) and \(\delta _2\) have been chosen as a suitable small powers of \(\tau \) and recall also the uniform \(L^p\) bound for \(\nabla \phi _{i,{\text {eff}}}\) in (81)). This expression in turn may be rewritten by (83) and (90) for any \(\beta >0\) small enough as
(recall that \(\delta _1\) and \(\delta _2\) have been chosen as a suitable small powers of \(\tau \) and recall also the uniform \(L^p\) bound for \(\nabla \phi _{i,{\text {eff}}}\) in (81)). This expression in turn may be rewritten by (83) and (90) for any \(\beta >0\) small enough as
for some \({\tilde{g}}\) with  .
.
Using the skew-symmetry of \(\sigma _{v,i}\) and \(\sigma _{h,i}\), we obtain
Using again the skew-symmetry of \(\sigma _{v,i}\) and \(\sigma _{h,i}\), we get
Choosing \(\beta >0\) small enough, we finally end up with
with  for some \({\tilde{\nu }}>0\). A standard energy estimate now implies
for some \({\tilde{\nu }}>0\). A standard energy estimate now implies

\(\square \)
Lemma 13
Consider a probability distribution of coefficient fields a subject to the conditions (A1), (A2), and (A3\(_a\))–(A3\(_c\)). Suppose in addition that a is almost surely almost everywhere a multiple of the identity matrix. If, in addition, the law of a is invariant under reflections of coordinate axes (that is maps of the form \(x\mapsto (x_1,\ldots ,-x_i,\ldots ,x_d)\)) and invariant under exchange of coordinate axes (that is maps of the form \(x\mapsto (x_1,\ldots ,x_{i-1},x_j,x_{i+1},\ldots ,x_{j-1},x_i,x_{j+1},\ldots ,x_d)\)), the covariance

is a multiple of \({\text {Id}}\otimes {\text {Id}}\).
Proof
For such a probability distribution of coefficient fields a, the spatial average  is almost surely a multiple of the identity matrix, which entails that
is almost surely a multiple of the identity matrix, which entails that

for some \(B\in \mathbb {R}^{d\times d}\).
The matrix B must also be a multiple of the identity matrix. Under reflection of the i-th coordinate, by the corrector equation (3) and the fact that a is pointwise a multiple of the identity matrix we have that the i-th corrector for the reflected coefficient field \({\hat{a}}(x)=a(x_1,\ldots ,-x_i,\ldots ,x_d)\) is given by \({\hat{\phi }}_i(x)=-\phi _i(x_1,\ldots ,-x_i,\ldots ,x_d)\). Thus, the off-diagonal entries of \(a^{{\text {RVE}}}\) which are given by (for \(i\ne j\), using also that \(a(x)=a_\mathrm{scalar}(x) {\text {Id}}\))

switch sign under such reflections, while the average  remains invariant. As our probability distribution is invariant under reflections, the off-diagonal entries of B must be zero. Similarly, as our probability distribution is invariant under exchange of coordinates, all diagonal entries of B must coincide; therefore the covariance must be a multiple of \({\text {Id}}\otimes {\text {Id}}\). \(\quad \square \)
remains invariant. As our probability distribution is invariant under reflections, the off-diagonal entries of B must be zero. Similarly, as our probability distribution is invariant under exchange of coordinates, all diagonal entries of B must coincide; therefore the covariance must be a multiple of \({\text {Id}}\otimes {\text {Id}}\). \(\quad \square \)
We now turn to the proof of our theorem on successful variance reduction for random coefficient fields that are obtained by applying “monotone” functions to a collection of iid random variables.
Proof of Proposition 5
Without loss of generality (by rescaling), we may consider the case \(\varepsilon =1\).
Given any \(\xi \in \mathbb {R}^d\), the L-periodic correctors associated with two L-periodic coefficient fields a and \({\tilde{a}}\) are given as the solutions to the PDEs
and
Define \(\phi ^{L,(1-s)a+s{\tilde{a}}}_\xi \) as the L-periodic solution to
Setting

we then obtain

Given two coefficient fields a and \({\tilde{a}}\) with \(a-{\tilde{a}}\geqq 0\), we therefore have the estimate

We now would like to derive a lower bound for the term on the right-hand side. We have, by (91) and (92),
Testing this PDE by the solution (note that \((1-s)a+s{\tilde{a}}\) is \(\lambda \)-uniformly elliptic) yields

and therefore by Young’s inequality (note that the matrix \(a-{\tilde{a}}\) is symmetric and by (A1) bounded by \(\frac{1}{\lambda }\) in the natural matrix norm), we have

In particular, we obtain, by (93) (and the analogous version of the previous estimate for \(\phi _\xi ^{L,{\tilde{a}}}\) instead of \(\phi _\xi ^{L,a}\)) and \(a\geqq {\tilde{a}}\),

This entails

The estimate (95) from Lemma 14 implies

where in the last step we have used the Hölder inequality and the fact that \(a(x,\Gamma )-a(x,\Delta _{k,{\tilde{\Gamma }}_k}\Gamma )\) is only nonzero for \(|x-k|\leqq K\).
By our assumption (25) we infer

To conclude our proof, by
it suffices to bound \({{\text {Var}}~}a^{{\text {RVE}}}\xi \cdot \xi \) and \({{\text {Var}}~}\mathcal {F}(a)\) by \(C(d,\lambda ,K) L^{-d} |\xi |^2\). A corresponding bound for \({{\text {Var}}~}a^{{\text {RVE}}}\xi \cdot \xi \) is provided for example by the methods of Gloria and Otto [55]. To estimate \({{\text {Var}}~}\mathcal {F}(a)\), we simply apply (96), which yields

\(\square \)
In the previous proof, we have used the following standard estimate for covariances of nonlinear functions of a finite number of independent random variables:
Lemma 14
Let \(f:[0,1]^N \rightarrow \mathbb {R}\), \(g:[0,1]^N \rightarrow \mathbb {R}\) be two functions that are monotonous with respect to each of their arguments. Let \(X_i:\Omega \rightarrow [0,1]\), \(1\leqq i\le N\), and \(Y_i:\Omega \rightarrow [0,1]\), \(1\leqq i\le N\), be 2N independent identically distributed random variables. Define
and
Then
and, by Jensen’s inequality,
Furthermore, we have
Proof
The proof proceeds similarly to the proof of the standard form of this lemma which provides the weaker assertion \({\text {Cov}}[f(X),g(X)]\geqq 0\); see for example [68, page 24] or [23, Lemma 2.1].
We have by the identity of the laws of \((X_1,\ldots ,X_{n-1},Y_n,Y_1,\ldots ,Y_{n-1},X_n)\) and \((X_1,\ldots ,X_n,Y_1,\ldots ,Y_n)\) (which allow us to swap \(X_n\) and \(Y_n\) in the expectations below),
By the independence of the \(X_i\) and the \(Y_i\), we infer
As both f and g are increasing functions in each of their arguments, the integrands in this formula are either nonnegative (for \(X_n\geqq Y_n\)) or nonpositive (for \(X_n\leqq Y_n\)). Thus, we have
and therefore by Hölder’s inequality we have
Taking the sum of these formulas for \(n=1,\ldots ,N\), we infer
which establishes the desired lower bound (94) for the covariance.
To obtain (96), we apply Young’s inequality and subsequently Jensen’s inequality to (97), which yields
This is equivalent to
Taking the sum with respect to n entails
which establishes the upper bound (96) for the covariance. \(\quad \square \)
Notes
Note that for one-dimensional linear elliptic PDEs—a case in which homogenization is linear in the inverse of the coefficient and thus independent of the geometry of the material—an analysis has directly been provided in [64].
At least if a suitable periodization of the probability distribution of the coefficient field is available, see below for an explanation of this concept.
This limit is to be read in an almost sure sense: By ergodicity, for almost every realization of a this limit exists and is equal to a matrix which is independent of the realization.
References
Abdulle, A.: On a priori error analysis of fully discrete heterogeneous multiscale FEM. Multiscale Model. Simul. 4(2), 447–459, 2005
Andres, S., Neukamm, S.: Berry–Esseen theorem and quantitative homogenization for the random conductance model with degenerate conductances. Preprint arXiv:1706.09493, 2017
Armstrong, S., Bordas, A., Mourrat, J.-C.: Quantitative stochastic homogenization and regularity theory of parabolic equations. Preprint arXiv:1705.07672, 2017
Armstrong, S., Dario, P.: Elliptic regularity and quantitative homogenization on percolation clusters. to appear in Commun. Pure Appl. Math. arXiv:1609.09431, 2018
Armstrong, S., Kuusi, T., Mourrat, J.-C.: The additive structure of elliptic homogenization. Invent. Math. 208(3), 999–1154, 2017
Armstrong, S., Kuusi, T., Mourrat, J.-C.: Quantitative stochastic homogenization and large-scale regularity. Lecture Notes. Preprint arXiv:1705.05300, 2017
Armstrong, S., Lin, J.: Optimal quantitative estimates in stochastic homogenization for elliptic equations in nondivergence form. Arch. Ration. Mech. Anal. 225(2), 937–991, 2017
Armstrong, S.N., Mourrat, J.-C.: Lipschitz regularity for elliptic equations with random coefficients. Arch. Ration. Mech. Anal. 219(1), 255–348, 2016
Armstrong, S.N., Smart, C.K.: Quantitative stochastic homogenization of convex integral functionals. Ann. Sci. Éc. Norm. Supér. (4) 49(2), 423–481, 2016
Armstrong, S.N., Souganidis, P.E.: Stochastic homogenization of Hamilton–Jacobi and degenerate Bellman equations in unbounded environments. J. Math. Pures Appl. (9) 97(5), 460–504, 2012
Avellaneda, M., Lin, F.: Une théorème de liouville pour des équations elliptiques à coefficients périodiques. C. R. Acad. Sci. Paris Sér. I Math. 309, 245–250, 1989
Avellaneda, M., Lin, F.-H.: Compactness methods in the theory of homogenization. Commun. Pure Appl. Math. 40(6), 803–847, 1987
Ayoul-Guilmard, Q., Nouy, A., Binetruy, C.: Tensor-based numerical method for stochastic homogenisation. Preprint arXiv:1805.00902, 2018
Babuška, I., Caloz, G., Osborn, J.E.: Special finite element methods for a class of second order elliptic problems with rough coefficients. SIAM J. Numer. Anal. 31(4), 945–981, 1994
Balzani, D., Brands, D., Schröder, J.: Construction of statistically similar representative volume elements. In: Plasticity and Beyond, Vol. 550 (Eds. Schröder J. and Hackl K.) Springer, Berlin, 355–412, 2014
Balzani, D., Brands, D., Schröder, J., Carstensen, C.: Sensitivity analysis of statistical measures for the reconstruction of microstructures based on the minimization of generalized least-square functionals. Tech. Mech. 30, 297–315, 2010
Balzani, D., Scheunemann, L., Brands, D., Schröder, J.: Construction of two- and three-dimensional statistically similar RVEs for coupled micro-macro simulations. Comput. Mech. 54, 1269–1284, 2014
Balzani, D., Schröder, J.: Some basic ideas for the reconstruction of statistically similar microstructures for multiscale simulations. PAMM 8(1), 10533–10534, 2009
Bella, P., Fehrman, B., Fischer, J., Otto, F.: Stochastic homogenization of linear elliptic equations: higher-order error estimates in weak norms via second-order correctors. SIAM J. Math. Anal. 49(6), 4658–4703, 2017
Bella, P., Giunti, A., Otto, F.: Effective multipoles in random media. Preprint arXiv:1708.07672, 2017
Benoit, A., Gloria, A.: Long-time homogenization and asymptotic ballistic transport of classical waves. Preprint arXiv:1701.08600, 2017
Blanc, X., Costaouec, R., Le Bris, C., Legoll, F.: Variance reduction in stochastic homogenization: the technique of antithetic variables. In: Engquist, B., Runborg, O., Tsai, Y.-H. (eds.) Numerical Analysis of Multiscale Computations, Volume 82 of Lect. Notes Comput. Sci. Eng. Springer, Heidelberg, 47–70, 2012
Blanc, X., Costaouec, R., Le Bris, C., Legoll, F.: Variance reduction in stochastic homogenization using antithetic variables. Markov Process. Relat. Fields 18(1), 31–66, 2012
Blanc, X., Le Bris, C.: Improving on computation of homogenized coefficients in the periodic and quasi-periodic settings. Netw. Heterog. Media 5, 1–29, 2010
Blanc, X., Le Bris, C., Legoll, F.: Some variance reduction methods for numerical stochastic homogenization. Philos. Trans. A 374(2066), 20150168, 2016. 15
Boucheron, S., Lugosi, G., Massart, P.: Concentration inequalities using the entropy method. Ann. Probab. 31(3), 1583–1614, 2003
Braides, A., Cicalese, M., Ruf, M.: Continuum limit and stochastic homogenization of discrete ferromagnetic thin films. Anal. PDE 11(2), 499–553, 2018
Brands, D., Balzani, D., Scheunemann, L., Schröder, J., Richter, H., Raabe, D.: Computational modeling of dual-phase steels based on representative three-dimensional microstructures obtained from ebsd data. Arch. Appl. Mech. 86(3), 575–598, 2016
Brezzi, F., Franca, L., Hughes, T., Russo, A.: \(b=\int g\). Comput. Methods Appl. Mech. Eng. 145, 329–339, 1997
Burkholder, D.L.: Distribution function inequalities for martingales. Ann. Probab. 1(1), 19–42, 1973
Caffarelli, L.A., Souganidis, P.E.: Rates of convergence for the homogenization of fully nonlinear uniformly elliptic pde in random media. Invent. Math. 180(2), 301–360, 2010
Cancès, É., Ehrlacher, V., Legoll, F., Stamm, B.: An embedded corrector problem to approximate the homogenized coefficients of an elliptic equation. C. R. Math. 353(9), 801–806, 2015
Chen, L.H.Y., Goldstein, L., Shao, Q.-M.: Normal Approximation by Stein’s Method. Probability and Its Applications (New York). Springer, Heidelberg 2011
Chen, L.H.Y., Shao, Q.-M.: Normal approximation under local dependence. Ann. Probab. 32(3A), 1985–2028, 2004
Dal Maso, G., Modica, L.: Nonlinear stochastic homogenization and ergodic theory. J. Reine Angew. Math. 368, 28–42, 1986
Dario, P.: Optimal corrector estimates on percolation clusters. Preprint arXiv:1805.00902, 2018
Duerinckx, M., Fischer, J., Gloria, A., Otto, F.: The structure of fluctuations in stochastic homogenization: the case of finite range of dependence, 2019 (in preparation)
Duerinckx, M., Gloria, A.: Weighted second-order Poincaré inequalities: application to RSA models. Preprint arXiv:1711.03158, 2017
Duerinckx, M., Gloria, A., Otto, F.: The structure of fluctuations in stochastic homogenization. Preprint arXiv:1602.01717, 2016
E, W., Engquist, B.: The heterogeneous multiscale methods. Commun. Math. Sci. 1(1), 87–132, 2003
Efendiev, Y., Kronsbein, C., Legoll, F.: Multilevel Monte Carlo approaches for numerical homogenization. Multiscale Model. Simul. 13(4), 1107–1135, 2015
Eigel, M., Peterseim, D.: Simulation of composite materials by a network FEM with error control. Comput. Methods Appl. Math. (online) 15(1), 21–37, 2015
Fischer, J.: Quantitative normal approximation for sums of random variables with multilevel local dependence. Preprint arXiv:1905.10273, 2018
Fischer, J., Otto, F.: A higher-order large-scale regularity theory for random elliptic operators. Commun. Partial Differ. Equ. 41(7), 1108–1148, 2016
Fischer, J., Raithel, C.: Liouville principles and a large-scale regularity theory for random elliptic operators on the half-space. SIAM J. Math. Anal. 49(1), 82–114, 2017
Giunti, A., Mourrat, J.-C.: Quantitative homogenization of degenerate random environments. Ann. Inst. Henri Poincaré Probab. Stat. 54(1), 22–50, 2018
Gloria, A.: Reduction of the resonance error. part 1: approximation of homogenized coefficients. Math. Models Methods Appl. Sci. 21(08), 1601–1630, 2011
Gloria, A.: Numerical approximation of effective coefficients in stochastic homogenization of discrete elliptic equations. ESAIM: M2AN 46(1), 1–38, 2012
Gloria, A., Neukamm, S., Otto, F.: An optimal quantitative two-scale expansion in stochastic homogenization of discrete elliptic equations. ESAIM Math. Model. Numer. Anal. 48(2), 325–346, 2014
Gloria, A., Neukamm, S., Otto, F.: A regularity theory for random elliptic operators. Preprint arXiv:1409.2678, 2014
Gloria, A., Neukamm, S., Otto, F.: Quantification of ergodicity in stochastic homogenization: optimal bounds via spectral gap on Glauber dynamics. Invent. Math. 199(2), 455–515, 2015
Gloria, A., Nolen, J.: A quantitative central limit theorem for the effective conductance on the discrete torus. Commun. Pure Appl. Math. 69(12), 2304–2348, 2016
Gloria, A., Otto, F.: An optimal variance estimate in stochastic homogenization of discrete elliptic equations. Ann. Probab. 39(3), 779–856, 2011
Gloria, A., Otto, F.: An optimal error estimate in stochastic homogenization of discrete elliptic equations. Ann. Appl. Probab. 22(1), 1–28, 2012
Gloria, A., Otto, F.: The corrector in stochastic homogenization: optimal rates, stochastic integrability, and fluctuations. Preprint arXiv:1510.08290, 2015
Gu, Y.: High order correctors and two-scale expansions in stochastic homogenization. Probab. Theory Relat. Fields 169(3), 1221–1259, 2017
Gu, Y., Mourrat, J.-C.: Scaling limit of fluctuations in stochastic homogenization. Multiscale Model. Simul. 14(1), 452–481, 2016
Heida, M., Schweizer, B.: Stochastic homogenization of plasticity equations. ESAIM Control Optim. Calc. Var. 24(1), 153–176, 2018
Hornung, P., Pawelczyk, M., Velčić, I.: Stochastic homogenization of the bending plate model. J. Math. Anal. Appl. 458(2), 1236–1273, 2018
Hou, T.Y., Wu, X.-H.: A multiscale finite element method for elliptic problems in composite materials and porous media. J. Comput. Phys. 134(1), 169–189, 1997
Hughes, T.J., Feijóo, G.R., Mazzei, L., Quincy, J.-B.: The variational multiscale method—a paradigm for computational mechanics. Comput. Methods Appl. Mech. Eng. 166(1), 3–24, 1998. (Advances in Stabilized Methods in Computational Mechanics)
Khoromskaia, V., Khoromskij, B., Otto, F.: A numerical primer in 2D stochastic homogenization: CLT scaling in the representative volume element, 2017. Preprint
Kozlov, S.M.: The averaging of random operators. Mat. Sb. (N.S.) 109(151), 188–202, 1979. 327
Le Bris, C., Legoll, F., Minvielle, W.: Special quasirandom structures: a selection approach for stochastic homogenization. Monte Carlo Methods Appl. 22(1), 25–54, 2016
Legoll, F., Minvielle, W.: A control variate approach based on a defect-type theory for variance reduction in stochastic homogenization. Multiscale Model. Simul. 13(2), 519–550, 2015
Lin, J., Smart, C.K.: Algebraic error estimates for the stochastic homogenization of uniformly parabolic equations. Anal. PDE 8(6), 1497–1539, 2015
Lions, P.-L., Souganidis, P.E.: Correctors for the homogenization of Hamilton–Jacobi equations in the stationary ergodic setting. Commun. Pure Appl. Math. 56(10), 1501–1524, 2003
Liu, J.S.: Monte-Carlo Strategies in Scientific Computing. Springer Series in Statistics. Springer, New York 2001
Lu, J., Otto, F.: Optimal artificial boundary condition for random elliptic media. Preprint arXiv:1803.09593, 2018
Målqvist, A., Peterseim, D.: Localization of elliptic multiscale problems. Math. Comput. 83, 2583–2603, 2014
Matache, A.-M., Schwab, C.: Two-scale FEM for homogenization problems. M2AN Math. Model. Numer. Anal. 36(4), 537–572, 2002
Mourrat, J.-C.: Efficient methods for the estimation of homogenized coefficients. Preprint arXiv:1609.06674, 2016
Mourrat, J.-C., Nolen, J.: Scaling limit of the corrector in stochastic homogenization. Ann. Appl. Probab. 27(2), 944–959, 2017
Mourrat, J.-C., Otto, F.: Correlation structure of the corrector in stochastic homogenization. Ann. Probab. 44(5), 3207–3233, 2016
Murat, F., Tartar, L.: H-Convergence. Progress in Nonlinear Differential Equations and Their Applications, vol. 31. Birkhäuser Boston Inc, Boston 1997
Naddaf, A., Spencer, T.: Estimates on the variance of some homogenization problems, 1998. Unpublished preprint
Nolen, J.: Normal approximation for the net flux through a random conductor. Stoch. Partial Differ. Equ. Anal. Comput. 4(3), 439–476, 2016
Papanicolaou, G.C., Varadhan, S.R.S.: Boundary value problems with rapidly oscillating random coefficients. In: Random Fields, Vol. I, II (Esztergom, 1979), volume 27 of Colloquia Mathematica Societatis János Bolyai, pp. 835–873. North-Holland, Amsterdam, 1981
Peterseim, D., Carstensen, C.: Finite element network approximation of conductivity in particle composites. Numer. Math. 124(1), 73–97, 2013
Rinott, Y., Rotar, V.: A multivariate CLT for local dependence with \(n^{-1/2}\log n\) rate and applications to multivariate graph related statistics. J. Multivariate Anal. 56(2), 333–350, 1996
Schröder, J., Balzani, D., Brands, D.: Approximation of random microstructures by periodic statistically similar representative volume elements based on lineal-path functions. Arch. Appl. Mech. 81(7), 975–997, 2011
von Pezold, J., Dick, A., Friák, M., Neugebauer, J.: Generation and performance of special quasirandom structures for studying the elastic properties of random alloys: application to al-ti. Phys. Rev. B 81, 094203, 2010
Wei, S.-H., Ferreira, L.G., Bernard, J.E., Zunger, A.: Electronic properties of random alloys: special quasirandom structures. Phys. Rev. B 42, 9622–9649, 1990
Yue, X., E, W.: The local microscale problem in the multiscale modeling of strongly heterogeneous media: effects of boundary conditions and cell size. J. Comput. Phys. 222(2), 556–572, 2007
Yurinskiĭ, V.V.: Averaging of symmetric diffusion in a random medium. Sibirsk. Mat. Zh. 27, 167–180, 1986. 215
Zunger, A., Wei, S.-H., Ferreira, L.G., Bernard, J.E.: Special quasirandom structures. Phys. Rev. Lett. 65, 353–356, 1990
Acknowledgements
Open access funding provided by Institute of Science and Technology (IST Austria).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by S. Müller
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This project was initiated while the author enjoyed the hospitality of the Hausdorff Research Institute for Mathematics, Bonn, as a participant of the Trimester Program “Multiscale Problems: Algorithms, Numerical Analysis and Computation”. The author would like to thank Sergio Conti, Mitia Duerinckx, Antoine Gloria, Claude Le Bris, Frédéric Legoll, and Ben Schweizer for interesting discussions on the manuscript.
Appendices
Appendix A. Gaussian Propagation Bounds for Parabolic PDEs
We now collect some elementary energy and propagation estimates for second-order linear parabolic equations. By a nongrowing weak solutionu to the equation \(\partial _t u = \nabla \cdot (a\nabla u)\) with initial data \(u(\cdot ,0)=g\), we understand a function \(u\in L^2_{loc}(\mathbb {R}^d\times [0,\infty ))\) with \(\nabla u\in L^2_{loc}(\mathbb {R}^d\times [0,\infty ))\) satisfying the usual weak formulation of the PDE with test functions in \(C^\infty _{cpt}(\mathbb {R}^d\times [0,\infty ))\) and additionally the estimate

for any \(T>0\). Note that for initial data \(u(\cdot ,0)=\nabla \cdot b\) for some vector field \(b\in L^\infty (\mathbb {R}^d;\mathbb {R}^d)\), the initial data is incorporated into the weak formulation in a weak form, that is as
Many of our computations in the next sections will be formal, but can be justified by the appropriate standard approximation arguments. Note also that the estimates which we shall prove ensure the existence of such nongrowing weak solutions for merely \(b\in L^\infty (\mathbb {R}^d;\mathbb {R}^d)\), as they ensure that one may construct a solution by constructing solutions with the initial data b truncated outside of some large ball \(\{|x|\leqq R\}\) (in which case the standard existence theorems apply) and then passing to the limit \(R\rightarrow \infty \).
Lemma 15
Let a be a uniformly elliptic and bounded coefficient field on \(\mathbb {R}^d\). For \(r\geqq 0\) and \(M\geqq 5d\), define the coefficient field
Consider the unique nongrowing weak solutions \(u_i\) and \(u_{i,r,M}\) to the equations
and
Then we have

for any \(t\leqq 16 M^2 r^2\) and

Proof
For an arbitrary function \(\psi \in L^2(\mathbb {R}^d)\) supported in \(\{|x|\leqq 2dr\}\) and any \(T\in [0,16M^2 r^2]\), consider the solutions \(v_\psi \) and \(v_{\psi ,r,M}\) to the dual equations
and
We then have
The penultimate term may be estimated by Lemma 17 (applied to the backward-in-time equations for \(v_\psi \) and \(v_{\psi ,r,M}\) and breaking up the “initial” condition \(\psi \) into pieces supported on scale \(\sqrt{T}\) if necessary), resulting in the bound (note that \(2dr\leqq \frac{Mr}{4}\))

and therefore by \(\sqrt{T}\leqq 4 M r\),
An estimate for the last term on the right-hand side of (100) can be obtained as follows: observe that
We rewrite \((v_\psi -v_{\psi ,r,M})(\cdot ,0)\) as \((v_\psi -v_{\psi ,r,M})(\cdot ,0)=\int _0^T w_t(\cdot ,0) \,\mathrm{d}t\) with \(w_{t_0}\) being the solution to the equation
Considering the estimate (103) centered at \(x_0\) (instead of 0) and integrating over the set \(\{|x_0|\leqq \frac{M}{2}r\}\) and applying it to the backward-in-time equation for \(w_{t_0}\), we obtain (also using the condition \(t_0 \leqq T\le C M^2 r^2\))
Lemma 17 (applied to \(v_{\psi ,r,M}\)) implies by breaking up the “initial” condition \(\psi \) into contributions supported on balls of size \(\sqrt{T-t_0}\)
Combining the previous two estimates, we deduce
Taking the square root and integrating with respect to \(t_0\), this entails
Using \(T\leqq C M^2 r^2\) and plugging in this bound into (100), we get, by \(M\geqq 5d\),
Passing to the supremum over all \(\psi \) supported in \(\{|x|\leqq 2dr\}\) with \(\int |\psi |^2 \,\mathrm{d}x\leqq 1\), we deduce our bound (98).
Now choose a cutoff \(\eta \) with \(\eta \equiv 1\) in \(\{|x|\leqq dr\}\) and \(\eta \equiv 0\) outside of \(\{|x|\leqq 2dr\}\). For any \(t\leqq 16 r^2\), we obtain by testing the equation for the difference \(u_i-u_{i,r,M}\) with \((u_i-u_{i,r,M})\eta ^2\)
Using our bound (98) and \(t\leqq 16r^2\), we get

Taking the sum over all \(t=2^k\) for \(2^k\leqq T\), we deduce our desired estimate (99). \(\quad \square \)
Lemma 16
Let \(a\in L^\infty (\mathbb {R}^d;\mathbb {R}^{d\times d})\) be a uniformly elliptic and bounded coefficient field in the sense of (A1). Let \(b\in L^\infty (\mathbb {R}^d;\mathbb {R}^d)\) be a bounded vector field. Then the unique nongrowing weak solution w to the equation
satisfies for any \(T>0\) the estimate

Furthermore, we have the bounds

and

Proof
Let \(T>0\) and let \(g\in L^2(\mathbb {R}^d)\) be a function supported in \(\{|x|\leqq \sqrt{T}\}\). Introducing the solution v to the dual (backward-in-time) equation
we see that we have
Introducing
we obtain
Lemma 17 (applied to v, which solves a parabolic PDE backward in time) provides the estimate
Inserting this estimate in the previous inequality and passing to the supremum over all \(g\in L^2\) supported in \(\{|x|\leqq \sqrt{T}\}\) with \(\int _{\{|x|\leqq \sqrt{T}\}} |g|^2 \,\mathrm{d}x \leqq 1\), we get
This establishes the estimate (101).
To prove the estimate (102), we first observe that we have
Testing this PDE with \(\eta ^2 \int _0^1 w(\cdot ,t) \,\mathrm{d}t\) where \(\eta \) is a standard cutoff with \(\eta \equiv 1\) in \(\{|x|\leqq 1\}\) and \(\eta \equiv 0\) outside of \(\{|x|\leqq 2\}\), we obtain
The estimate (101) entails

The previous two estimates yield (102).
Finally, to prove (103), we first deduce from (101)

Splitting the function \(w(\cdot ,T/2)\) into pieces each supported on a ball of size \(\sqrt{T}/2\)—that is, splitting \(w(\cdot ,T/2)=\sum _l \eta _l w(\cdot ,T/2)\) with a partition of unity \(\eta _l\) subordinate to the set of balls \(\{|x-x_0|\leqq \sqrt{T/2}\}\), \(x_0 \in \frac{1}{d} \sqrt{T/2} \mathbb {Z}^d\)—and applying Lemma 17 to the solutions of the parabolic equation with initial data \(\eta _l w(\cdot ,T/2)\) for all l (note that w is equal to the sum of all of these solutions), we obtain

A straightforward estimate then entails (103) (with a different constant C). \(\quad \square \)
Lemma 17
Let \(a\in L^\infty (\mathbb {R}^d;\mathbb {R}^{d\times d})\) be a uniformly elliptic and bounded coefficient field in the sense of (A1) and let \(T>0\). Let \(g\in L^2(\mathbb {R}^d)\) be a function supported in \(\{|x|\leqq \sqrt{T}\}\). Then there exists \(C=C(d,\lambda )>0\) such that the unique nongrowing weak solution w to the equation
satisfies the estimate

Proof
As
satisfies
we have for \(C_1\geqq C(d,\lambda )\)
This provides the bound
We now would like to show (basically) \(\nabla w\in C^\gamma ([\frac{1}{2}T,\frac{3}{2}T];L^2_{\Theta _T^m})\) for some \(\gamma >0\) and some m. To this end, we abbreviate \(\Theta _{T,t}^m := \Theta _{T}^m(\cdot ,t)\) and compute
Applying the Hölder inequality to the first term and Young’s inequality (and absorption) to the second term, we get
Choosing a weight \(\Theta _T^2\) with slower growth than in (105)—for example, setting \(C_2:=4C_1\)—, we may ensure that \(\frac{|\nabla \Theta _T^2(\cdot ,t)|^2}{\Theta _T^2(\cdot ,t)}\leqq \frac{C}{T} \Theta _T^1(\cdot ,{\tilde{t}})\) and \(\Theta _T^2(\cdot ,t)\leqq \Theta _T^1(\cdot ,{\tilde{t}})\) for any \(t,{\tilde{t}}\in [0,\frac{T}{3}]\). As a consequence, we may find for any \(h\leqq \frac{T}{10}\) a suitable \(t\in [0,\frac{T}{10}]\) with
Plugging in these bounds in the previous estimate and using (105), we obtain, for this t,
Abbreviating \(\Delta _h w (\cdot ,t) := w(\cdot ,t+h)-w(\cdot ,t)\), we compute, for \(C_m\geqq C(d,\lambda )\),
Combining this with the existence of \(t\in [0,\frac{T}{10}]\) for which the bound (107) holds, this entails, for any \(h\leqq \frac{T}{10}\),
We intend to plug back this estimate into (106). First, for any \(h\in [0,\frac{T}{10}]\) we infer the existence of \(t\in [\frac{T}{5},\frac{T}{3}]\) which in addition to the bound
satisfies
Plugging these three estimates and (105) back into (106), we obtain for some \(t\in [\frac{T}{5},\frac{T}{3}]\) the improved bound
By (108) we obtain, for any \(h\in [0,\frac{T}{10}]\),
In other words, \(\nabla w\) belongs to the Nikolskii space on the time interval \([\frac{T}{3},2T]\) with order of differentiability \(\frac{3}{4}\), integrability 2, and values in \(L^2_{\Theta _{T,2T}^2}(\mathbb {R}^d)\); furthermore, the Nikolskii seminorm is subject to a bound of the order \(\frac{C}{T^{3/2}} \int |g|^2 \,\mathrm{d}x\). By the embedding theorem for Nikolskii spaces, we deduce

This establishes our lemma. \(\quad \square \)
Appendix B. Calculus for Random Variables with Stretched Exponential Moments
On the space of random variables X with stretched exponential moments in the sense that
for some \(\gamma >0\) and some \(C>0\), it is convenient to work with the norm
For \(\gamma \geqq 1\), this norm is equivalent to the Luxemburg norm associated with the convex function \(\exp (x^\gamma )-1\). However, this norm has two advantages: first, it simplifies calculus when considering the integrability of products of random variables or the concentration properties of independent random variables; secondly and more importantly, it is also a well-defined norm for \(\gamma \in (0,1)\), a parameter range which we shall employ heavily.
Lemma 18
Let \(\gamma >0\). Consider a random variable X on some probability space. Define the quasinorm
Then we have \(||X||_{\exp ^\gamma ,{\text {quasi}}}<\infty \) if and only if \(||X||_{\exp ^\gamma }<\infty \) and there exist constants \(c(\gamma ),C(\gamma )\) such that the estimate
is satisfied.
Proof
The function
satisfies \(f_q'(x)= (q-x) x^{q-1} \exp (-x)\) and attains its maximal value
at \(x=q\). Applying the resulting estimate \(x^q\leqq q^q \exp (x)\) to \(x:=|X|^{\gamma }/||X||_{\exp ^\gamma ,{\text {quasi}}}^\gamma \) we deduce
By definition we have \(\mathbb {E}[\exp (|X|^\gamma /||X||_{\exp ^\gamma ,{\text {quasi}}}^\gamma )]\leqq 2\). Setting \(p:=\gamma q\) and taking the p-th root, we obtain, for any \(p\geqq 1\),
This proves \(||X||_{\exp ^\gamma } \leqq C(\gamma ) ||X||_{\exp ^\gamma ,{\text {quasi}}}\).
To establish the reverse inequality, observe that for \(z\in [q,q+1)\) we have \(z^q e^{-z/2}\geqq q^q e^{-(q+1)/2}\). This entails, for all \(z\geqq 0\),
and therefore for any \(b>0\) (by setting \(z=|X|^\gamma /b^\gamma \)),
As a consequence, we obtain
Setting \(b:=a||X||_{\exp ^\gamma }\), we get
Choosing \(a:=C(\gamma )\) large enough, we deduce
which entails \(||X||_{\exp ^\gamma ,{\text {quasi}}}\leqq C(\gamma )||X||_{\exp ^\gamma }\). \(\quad \square \)
Lemma 19
(Calculus for random variables with stretched exponential moments) Let X, Y be random variables with stretched exponential moments in the sense that \(||X||_{\exp ^\gamma }<\infty \) and \(||Y||_{\exp ^\beta }<\infty \) for some \(\gamma ,\beta >0\). Then:
-
(a)
The product XY has stretched exponential moments with exponent \(\alpha \) given by \(\frac{1}{\alpha }=\frac{1}{\gamma }+\frac{1}{\beta }\) and satisfies the bound
$$\begin{aligned} ||XY||_{\exp ^\alpha }\leqq C(\beta ,\gamma ) ||X||_{\exp ^\gamma } ||Y||_{\exp ^\beta }. \end{aligned}$$ -
(b)
There exists constants \(c=c(\gamma )>0\), \(C=C(\gamma )<\infty \), with the following property: for any \(K\geqq 0\), we have the estimate
$$\begin{aligned} \mathbb {P}\big [|X|\geqq K||X||_{\exp ^\gamma }\big ] \leqq C\exp (-c K^\gamma ). \end{aligned}$$
Proof
For the first assertion, we estimate, for any \(p\geqq 1\), by Hölder’s inequality, that
This establishes the first assertion.
For the second assertion, we estimate, for any \(p\geqq 1\) and any \(K> 0\),
Using the fact that \(||X||_{\exp ^\gamma ,{\text {quasi}}}\leqq C(\gamma ) ||X||_{\exp ^\gamma }\), the second assertion follows upon redefining K. \(\quad \square \)
For independent random variables with stretched exponential moments, a standard argument via an inequality by Burkholder [30] provides a simple concentration estimate. Note that the estimate is not sharp and may be improved, see for example [26].
Lemma 20
Let \(X_1,\ldots ,X_M\) be independent random variables with vanishing expectation and uniformly bounded stretched exponential moments
for some \(\gamma _0>0\) and some \(b>0\). Then the sum
has uniformly bounded stretched exponential moments
for \({\tilde{\gamma }} := \gamma _0/(\gamma _0+1)\).
Proof
The discrete-time stochastic process
is a square-integrable martingale. An estimate by Burkholder [30, Theorem 3.2]—applied for “timestep” \(m:=M\)—yields for any \(k\in \mathbb {N}\)
This entails
and therefore
We infer
for any \(k\in \mathbb {N}\), which, by Hölder’s inequality, entails
for any \(p\geqq 1\). \(\quad \square \)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Fischer, J. The Choice of Representative Volumes in the Approximation of Effective Properties of Random Materials. Arch Rational Mech Anal 234, 635–726 (2019). https://doi.org/10.1007/s00205-019-01400-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00205-019-01400-w