
Abstract
Aims/hypothesis
Multiple genetic variants are associated with type 2 diabetes-related traits in Europeans, but their role in South Asian populations needs further study. We hypothesised that genetic variants associated with diabetes-related traits in Europeans would explain a similar proportion of phenotypic variance in a Pakistani population and could be used in Mendelian randomisation analyses.
Methods
We used data from 2,131 individuals from the Control of Blood Pressure and Risk Attenuation Trial (COBRA) in Karachi, Pakistan. Individuals were aged 40 years or older.
Results
Combining information from multiple genetic variants showed that fasting glucose, BMI, triacylglycerol, and systolic and diastolic blood pressure variants explained 2.9%, 0.7%, 5.5%, 1.2% and 1.8% of the variance in those traits respectively. Genetic risk scores of fasting glucose, triacylglycerol, BMI, systolic blood pressure and diastolic blood pressure variants were associated with these traits, with per allele SD effects of 0.057 (95% CI 0.041, 0.074), p = 3.44 × 10−12, 0.130 (95% CI 0.105, 0.155), p = 2.9 × 10−21, 0.04 (95% CI 0.014, 0.072), p = 0.004, 0.031 (95% CI 0.016, 0.047), p = 7.9 × 10−5, 0.028 (95% CI 0.015, 0.042), p = 5.5 × 10−5, respectively. These effects are consistent with those observed in Europeans, except that the effect of triacylglycerol variants in South Asians was slightly lower. Mendelian randomisation provided evidence that genetically influenced, raised triacylglycerol levels do not causally affect type 2 diabetes risk to the extent predicted from observational data (p = 0.0003 for difference between observed and instrumental variables correlations).
Conclusions/interpretation
Genetic variants identified in Europeans are associated with type 2 diabetes-related traits in Pakistanis, with comparable effect sizes. Larger studies are needed to perform adequately powered Mendelian randomisation and help dissect the relationships between type 2 diabetes-related traits in diverse South Asian subgroups.
Similar content being viewed by others

Introduction
The risk of type 2 diabetes is particularly elevated in South Asians compared with Western populations and is associated with greater morbidity and mortality rates [1]. About 20% of persons aged 40 years and older have diabetes in Pakistan, making it the seventh highest ranking country in terms of the global burden of diabetes. Interestingly, the interrelationships between intermediate metabolic traits such as BMI, blood pressure, lipids and glucose are inconsistent within different ethnic subgroups of South Asian populations compared with those observed in European-origin populations. For example, we have shown that Pakistani ethnic subgroups with the greatest burden of hypertension have the lowest relative prevalence of diabetes [2].
Genetic variants may be useful in helping us understand the complex relationships between metabolic traits and why these relationships may differ across populations. There are several reasons for further testing the role of genetic variants in type 2 diabetes-related traits in South Asian populations. First, genetic variants are randomly sorted in meiosis and are independent of non-genetic factors, including environmental risk factors, confounding factors or disease processes. This principle of Mendelian randomisation has been used to assess the causal relationship between several related metabolic phenotypes, e.g. C-reactive protein and heart disease [3], and sex hormone-binding globulin levels and diabetes [4]. Most recently, studies have combined multiple risk variants in a ‘genetic risk score’ to provide more power compared with individual variants. These studies have assessed the role of glucose in subclinical atherosclerosis [5] and triacylglycerol in type 2 diabetes [6]. Second, large meta-analyses of genome-wide association studies (GWAS) have recently increased the number of common variants robustly associated with type 2 diabetes-related quantitative traits to more than 100. These also include 95, 32 and 16 variants associated with lipid measures, BMI and fasting glucose, respectively, and most recently 29 variants associated with blood pressure [7–10]. Some of these large [10] meta-analyses showed that common variants identified in Europeans are associated with similar effect sizes in other ethnic groups [11, 12], but these studies tended to focus on single traits. Third, while individual common variants identified by GWAS have small effects with regard to the associated phenotype, they can, when combined, explain a more substantial proportion of phenotypic variance. For example, genetic loci associated with triacylglycerol or fasting glucose levels explain ∼7.4% and ∼3% of the variance in triacylglycerol [9] and fasting glucose [7] levels in European populations, respectively. These effects are similar in magnitude to well established risk factors, such as the effect of BMI on fasting glucose levels [13].
Testing variants against diabetes-related traits can be useful to help understand the relationship between those traits and how those relationships differ across ethnic groups. Thus, with regard to the FTO variant known to be associated with BMI in Europeans, we have recently shown that its association with type 2 diabetes differs between Europeans and South Asians, probably because BMI is a poorer surrogate of adiposity in South Asians [14].
The objectives of this study were: (1) to determine the extent to which genetic risk scores based on common gene variants detected in European-origin populations explain phenotypic variance in type 2 diabetes-related traits in a South Asian context; and (2) to use these genetic risk scores to detect any potential causal relationships of substantial magnitude in Mendelian randomisation analyses in South Asians. We used individual data from the Control of Blood Pressure and Risk Attenuation Trial (COBRA) cohort study in Karachi, a population-based study with measures of multiple metabolic traits and consisting of 2,073 (72%) participants of Muhajir ethnicity. We focused on three traits strongly associated with type 2 diabetes: fasting glucose levels, BMI and triacylglycerol levels. We also used the most recently identified blood pressure variants [12], because of the strong association between these traits in different ethnic subgroups in Pakistan [2].
Methods
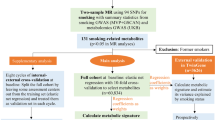
Details of participants are given in Table 1 and Fig. 1. Ethical approval was obtained from the Ethics Review Committee at the Aga Khan University, Karachi, Pakistan.

Flow diagram of study procedures. aParticipants with type 2 diabetes excluded n = 462 (23%), where per cent is of n = 2,006
Study design
A population-based sample representative of adults in Karachi was recruited in a cluster randomised trial of strategies for control of hypertension (COBRA, ClinicalTrials.gov ID no. NCT00327574). The sampling details have been described previously [15]. Briefly, a multi-stage cluster random sampling design was used to randomly select 12 geographical clusters in Karachi, the largest metropolitan city in Pakistan. A census was done and a listing made of all individuals from all households in the selected areas. All participants aged 40 years or above and residing in the same household were invited to participate in the study by trained community health workers. All participants were evaluated after obtaining informed consent. A range of anthropometric and biochemical data were collected from all consenting participants, with and without hypertension, who had been screened for eligibility for the trial. The enrolled group was categorised according to the five main Pakistani ethnic subgroups into Muhajirs, Punjabis, Sindhis, Baluchis, Pashtun and others (Table 1) [16, 17]. The numbers of individuals involved differed slightly by trait, as genotyping success rates differed slightly and individuals with diabetes had to be excluded from the fasting glucose analysis.
SNP selection
We only selected single nucleotide polymorphisms (SNPs) from GWAS studies of European individuals because these studies include the majority of GWAS findings. We aimed to test the effects of SNPs identified through European GWAS in Pakistanis. We selected the ten SNPs most strongly associated with triacylglycerol levels [8, 9] (excluding FADS1 rs174547 and GCKR rs1260326 because they are strongly associated with several other quantitative traits relevant to diabetes), the five SNPs most strongly associated with BMI [10], 16 SNPs associated with fasting glucose [7] and 29 SNPs associated with blood pressure [12].
Genotyping
We genotyped all SNPs except the five BMI SNPs, using a modified Taqman assay, KASPAR assay (www.kbioscience.co.uk). The five BMI SNPs were genotyped using a pre-designed Taqman SNP genotyping assay from Applied Biosystems (Warrington, UK), followed by genotype clustering using Klustercaller software (Kbiosciences, Hoddesdon, UK). The final number of analysed individuals differed by trait because of different genotype success rates (we required individuals to have >85% of SNPs successfully genotyped for any one trait typed) and, for fasting glucose, because we excluded individuals with diabetes.
Fasting glucose SNPs
We excluded participants with diabetes as defined by use of glucose-lowering medication or fasting glucose ≥7 mmol/l, since these individuals would be on glucose-lowering agents, making their fasting glucose levels uninformative. Appropriate samples were available from 1,544 individuals, of which 18 (1%) failed four or more of the 16 attempted SNPs in the batch; these samples were excluded. The call rates were therefore generated from a subset of 1,526 samples, for which at least 13 of 16 SNPs were called (Fig. 1). Call rates by SNP in these 1,526 samples ranged from 96.81% to 99.4%.
Triacylglycerol SNPs
We used 2,111 participants, including those with diabetes. Of these, 60 (3%) failed two or more of the ten attempted SNPs in the batch and we excluded these samples. The call rates were therefore generated from a subset of 2,051 samples, for which at least nine of ten SNPs were called (Fig. 1). Call rates by SNP ranged from 98.5% to 100%.
BMI SNPs
We used 2,004 participants, including those with diabetes. Of these, 249 (12%) failed two or more of the five attempted SNPs in the batch and were excluded. The call rates were therefore generated from a subset of 1,755 samples, for which at least four of the five SNPs were called (Fig. 1). Call rates by SNP ranged from 88.7% to 99.4%.
Blood pressure SNPs
We used 1,833 samples. Of these, 15 (0.8%) failed 22 or more of the 25 attempted SNPs in the batch and were excluded. The call rates were therefore generated from a subset of 1,818 samples, for which at least 23 of 25 SNPs were called (Fig. 1). Call rates by SNP ranged from 94.2% to 98.6%.
Statistical analyses
Association of SNPs with phenotypes in South Asians
We log10-transformed triacylglycerol levels, and systolic and diastolic blood pressure. Fasting glucose did not require transformation. We generated within-study z scores for fasting glucose and log10-transformed triacylglycerol using the mean and SD of the samples. We used individual SNPs as independent variables and outcome measures as dependent variables in a per-allele test, with age, sex, BMI, ethnicity and clustering of household member. We coded ethnicity as a non-ordinal value of 1, 2, 3 and 4 for the Muhajir, Sindhi, Punjabi and other ethnicities respectively. For individual SNP associations, we did not have adequate power to replicate the effects observed in European samples, and we did not correct single SNP analyses for multiple testing. Instead, we report the number of SNPs associated in the same direction as European associations at p < 0.05 and compare this with the one of 20 SNPs expected by chance. We also tested the significance of genetic risk scores that combine information from all known variants. For these tests we had sufficient power, and based on the combined variants explaining >0.7% of the phenotypic variance and a minimal sample size of 1,500 individuals, we had >89% power to detect effects at p = 0.05.
We created weighted allele scores and accounted for the varying, previously reported effect sizes of each SNP using Eq. (1), where w is the β-coefficient from the individual regressions of SNP genotype against the outcome.
We rescaled the weighted score to reflect the number of available SNPs using Eq. (2) as described in Lin et al. [18]:
We used this allele score as the independent variable, and fasting glucose, triacylglycerol, BMI and systolic or diastolic blood pressure as the dependent variables, with age, sex, ethnicity, clustering of household member and BMI (except for the BMI analysis) as covariates in linear regression analyses.
For all traits, we also performed sensitivity analysis by computing the allele score based on only those alleles associated with the dependent variables at p < 0.05, and assessed their significance and the variability that was explained for each model.
We also evaluated the association between SNPs and secondary phenotypes. For this, we used the weighted allele score as independent variable and type 2 diabetes status (defined as use of glucose-lowering medications or a fasting blood glucose level of ≥7.0 mmol/l), hypertension status (defined as mean systolic blood pressure ≥140 mmHg or mean diastolic blood pressure ≥90 mmHg or taking anti-hypertensive medication) or hypertriacylglycerolaemia (defined as serum triacylglycerol >1.7 mmol/l) as the dependent variables in logistic regression analyses, with age and sex as covariates.
Mendelian randomisation and instrumental variables analysis
We performed a series of instrumental variables (IV)-based Mendelian randomisation analyses on several pairs of traits as described below. We used the weighted allele score associated with the primary trait as the ‘instrument’ to test the relationship between each pair of primary and secondary phenotypes. An IV analysis relates the variation in the potentially causal risk factor of interest (here one of the quantitative traits) that is influenced by the ‘instrument’ (here the weighted allele score) to the outcome (here one of the quantitative traits or type 2 diabetes). This method assumes that the IV (1) is not associated with measured or unmeasured confounders (likely to be true for genetic variants) [11] and (2) is only related to the outcome via its effect on the risk factor. This produces an estimate of the causal effect in a similar way to an intention to treat analysis in a randomised controlled trial [11]. To ensure our tests were as close as possible to meeting these assumptions, we excluded two SNPs (in or near GCKR and FADS1) known to have multiple effects on metabolic phenotypes.
When the outcome was a continuously distributed trait, we performed the IV estimation for each outcome in each study using the two-stage least squares estimator, implemented in the Stata command ‘ivreg2’. We tested for a difference between the IV and observational estimates using the Durbin–Wu–Hausman test of endogeneity.
When the outcome was a dichotomous trait (type 2 diabetes case–control status) we performed IV analysis using a logistic control function estimator. The analysis was performed in two stages. In the first stage, we assessed the observational association between the weighted allele score and the triacylglycerol z score. We saved the predicted values and residuals from this regression model. In the second stage, we used the predicted values from stage 1 as the independent variable (reflecting an unconfounded estimate of triacylglycerol levels due to these genotypes) and diabetes status as the dependent variable in a logistic regression analysis. The residuals from stage 1 were included as a covariate, representing residual variation in triacylglycerol levels that is not due to these genotypes. We then used a Wald test to assess the evidence of any difference between the predicted values coefficient (IV estimate of the causal effect of triacylglycerol levels on type 2 diabetes) and the residuals coefficient as a test of endogeneity.
The sensitivity analysis for the IV analysis was performed using the weighted allele score from the model only with alleles significantly associated with the outcomes.
Given a minimum sample size of 1,500, we had 80% power, at p < 0.05, to detect combinations of genetic variants that explain >0.5% of phenotypic variance. It is difficult to estimate the statistical power of Mendelian randomisation tests, but an approximate method is to take the product of the SNP–primary trait and primary trait–secondary trait effects. For example, an effect of 0.5% variance would require a SNP–primary trait association explaining 5% variance and a primary trait–secondary trait association explaining 10% variance. Most associations in our study were weaker than this and power therefore lower than 80% in most tests. However, given that these calculations are very approximate, we present the results of the tests, which in themselves provide better power calculations for further study [19, 20]. All statistical analyses were performed in Stata/IC v.12.1 for Windows (Stata, College Station, TX, USA).
Results
Study procedures
Figure 1 illustrates the study flow diagram. Of the 3,546 invited participants aged 40 years or above, 3,143 (88.6%) consented to enrol in the population-based study. We attempted genotyping of 2,131 individuals from whom DNA was available at the time of the genetic study.
Fasting glucose SNPs
Results from the individual 16 SNPs and the weighted allele score are shown in Table 2. Of the 16 SNPs, seven were associated with fasting glucose at p < 0.05 (all with the same allele direction as reported in Europeans, p = 0.00001, binomial, compared with the number expected by chance), and the weighted allele score was very strongly associated with fasting glucose (p = 8.9 × 10−9). Together the SNPs explained 2.9% (95% CI 1.2, 4.6%) of the variance in fasting glucose or 3.4% in sensitivity analysis consisting of only the seven SNPs at p < 0.05 as shown in electronic supplementary material (ESM) Table 1, a finding that is similar to the 3% (95% CI 2.7, 3.3%) reported in Europeans [7]. The association of the weighted allele score with fasting glucose is shown in Fig. 2a.

The combined impact of the 16 SNPs associated with fasting glucose on fasting glucose levels in the control group (a). (b) The combined impact, in all individuals, of SNPs associated with triacylglycerol (ten SNPs), (c) BMI (five SNPs), and (d) systolic BP (SBP) and (e) diastolic BP (DBP) (25 SNPs) on circulating triacylglycerol, BMI, and systolic and diastolic BP, respectively. Participants were grouped by the total number of trait-increasing alleles at all trait-associated SNPs. Grey bars, number of individuals in each trait-increasing allele group; circles, mean trait z score within each trait-increasing allele group; error bars, SEM of the observed mean trait; dashed line, fitted mean trait level
Triacylglycerol SNPs
Results from the individual ten SNPs and the weighted allele score are shown in Table 3. Of the ten SNPs, six were associated with triacylglycerol at p < 0.05 (all with the same allele direction as reported in Europeans, p = 0.000005, binomial, compared with the number expected by chance), and the weighted allele score was very strongly associated with triacylglycerol (p = 1.3 × 10−25). Together the SNPs explained 5.5% (95% CI 3.5, 7.5%) of the variance in triacylglycerol or 5.4% in sensitivity analysis consisting of only the six SNPs at p < 0.05 (ESM Table 1), which is slightly less, based on 95% CIs, than the 7.4% (95% CI 6.7, 8.1%) reported in Europeans [9]. The association of the weighted allele score with triacylglycerol levels is shown in Fig. 2b.
BMI SNPs
Results from the individual five SNPs and the weighted allele score are shown in Table 4. Of the five SNPs, two were associated with fasting glucose (p = 0.007 and p = 0.059) FTO and GNPDA2, respectively, with the same allele direction as reported in Europeans (p = 0.045, binomial, compared with the number expected by chance); the weighted allele score was associated with BMI (p = 0.00028). Together the SNPs explained 0.7% (95% CI −0.2, 1.6%) (or 0.9% in sensitivity analysis consisting of the two most strongly associated SNPs [ESM Table 1]) of the variance in BMI, consistent with the 1.4% (95% CI 1.3, 1.5%) reported in Europeans for a wider set of 32 SNPs [10]. The association of the weighted allele score with BMI is shown in Fig. 2c.
Blood pressure SNPs
Results from the individual 25 SNPs and the weighted allele score are shown in Table 5. Of the 25 SNPs, four were associated with systolic and diastolic blood pressure at p < 0.05 (all with the same allele direction as reported in Europeans, p = 0.068, binomial), and the weighted allele score was very strongly associated with systolic blood pressure. Together the SNPs explained 1.2% (95% CI 0.02, 2.38%) and 1.8% (95% CI 0.4, 3.2%) of the variance in systolic and diastolic blood pressure, respectively (0.9% and 1.3%, respectively, in sensitivity analysis [ESM Table 1]). These estimates of variance in systolic and diastolic blood pressure are similar to the 0.92% (95% CI 0.80, 1.04) and 0.94% (95% CI 0.82, 1.06) reported in Europeans [12]. The associations of the weighted allele score with systolic and diastolic blood pressure are shown in Fig. 2d, e.
Association of SNPs with secondary phenotypes
We observed a significant association between the weighted allele score of BMI and hypertriacylglycerolaemia (p = 0.014). No other significant associations were detected (Table 6).
Mendelian randomisation analysis
Significant observational associations were present between primary and secondary phenotypes as seen in Table 7, except between BMI and systolic blood pressure. For every 1 SD increase in log10-transformed triacylglycerol levels, the OR (95% CI) for type 2 diabetes was 1.77 (95% CI 1.59, 1.98), p = 1.38 × 10−24. Each 1 SD increase in log10-transformed triacylglycerol levels was associated with a 0.039 SD (95% CI 0.029, 0.049) increase in fasting glucose levels. Every one unit increase in BMI was associated with a 0.353 (95% CI 0.224, 0.482) mmHg increase of diastolic blood pressure, and 0.045 SD (95% CI 0.035, 0.054) and 0.017 SD (95% CI 0.014, 0.020) increases in triacylglycerol and fasting glucose, respectively (Table 7).
We found evidence against the hypothesis that genetically raised triacylglycerol levels are causally related to type 2 diabetes status, in keeping with recently reported results in Europeans [6]. We also found nominal evidence against the hypothesis that raised fasting glucose levels are causally related to triacylglycerol levels. In the triacylglycerol versus type 2 diabetes status and fasting glucose versus triacylglycerol analyses, the instrumental variable estimates of the associations were lower than the observed associations (p = 0.0003 and p = 0.05 for difference, respectively) (Table 7). The sensitivity analysis revealed that findings were consistent (ESM Table 2).
Discussion
We have tested the role of multiple genetic variants in five metabolic phenotypes that are especially relevant to diabetes and related outcomes in a Pakistani population. Our results show that genetic risk scores containing multiple SNPs are associated with fasting glucose levels, triacylglycerol levels, BMI, and systolic and diastolic blood pressure in Pakistanis. These risk scores have similar effects on the total phenotypic variance explained in Pakistanis as they do in Europeans. The distribution of allele frequencies in the study population was also comparable to that reported in participants of European origin, indicating that the attributable risk from these genes is likely to be similar across the two populations [7–10]. These results are consistent with data reported by recent large GWAS for lipids [21] and blood pressure [12], and provide further evidence that the majority of variants identified in GWAS have similar effects in South Asian populations to those in Europeans. This consistency between genetic effects in Pakistanis and Europeans probably reflects generally similar patterns of linkage disequilibrium and consistent biological factors between Europeans and Asians, despite the frequently very different environmental components.
A second aim of our study was to use genetic risk scores to help understand possible major causal directions between metabolic traits. Further studies are needed to increase statistical power for these tests. However, we did observe evidence that genetically influenced, raised triacylglycerol and glucose levels do not causally affect type 2 diabetes risk and triacylglycerol levels, respectively. The lack of evidence that genetically influenced triacylglycerol levels causally affect type 2 diabetes risk is consistent with recent evidence from Europeans [6].
The strengths of our study include its population-based design, which means the effect size estimates and proportions of variance explained are likely to be representative of the situation in Pakistani individuals. We have also brought together information from several traits in one study, allowing a simple comparison of effects between traits, and between Europeans and South Asians.
There are some limitations to this study. First, we did not use all confirmed SNPs for all traits; for example, recent publications have identified additional variants associated with triacylglycerol levels and BMI [10, 21]. However, the SNPs we used represent most of those with the strongest effects on these traits and account for the majority of the phenotypic variance reported for known SNPs in Europeans [10, 21]. Second, our sample was representative of Karachi and thus predominantly consists of a single ethnic subgroup, i.e. Muhajirs (representative of North Indian descent); it remains to be evaluated whether our findings can be generalised to South Indian populations. Finally, the study was possibly underpowered to perform robust Mendelian randomisation analyses, although the estimates of our IV results (Table 7) do provide more meaningful power estimates for larger studies [2, 17].
It should also be emphasised that we did not study the impact of genetic risk score on BMI, fasting glucose, triacylglycerol and blood pressure levels in relation to other environmental risk factors (e.g. diet, physical activity) in this population. These metabolic risk factors could have population-specific familial clustering and could potentially interact with the genetic scores. This may be particularly relevant in native South Asian populations exposed to in-utero nutritional deficiencies with the subsequent enhanced susceptibility to metabolic disorders with weight gain [22].
In conclusion, our analyses provide valuable evidence that the relationships between genetic variants associated with important type 2 diabetes-related traits are similar in Pakistanis and Europeans. Our instrumental variable analysis findings, moreover, suggest that genetic risk scores may help disentangle the causal relationships between type 2 diabetes-related traits in larger sample sizes.
Abbreviations
- COBRA:
-
Control of Blood Pressure and Risk Attenuation Trial
- GWAS:
-
Genome-wide association studies
- IV:
-
Instrumental variable
- SNP:
-
Single nucleotide polymorphism
References
Danaei G, Finucane MM, Lu Y et al (2011) National, regional, and global trends in fasting plasma glucose and diabetes prevalence since 1980: systematic analysis of health examination surveys and epidemiological studies with 370 country-years and 2.7 million participants. Lancet 378:31–40
Jafar TH, Levey AS, Jafary FH et al (2003) Ethnic subgroup differences in hypertension in Pakistan. J Hypertens 21:905–912
Wensley F, Gao P, Burgess S et al (2011) Association between C reactive protein and coronary heart disease: mendelian randomisation analysis based on individual participant data. BMJ 342:d548
Perry JR, Weedon MN, Langenberg C et al (2009) Genetic evidence that raised sex hormone binding globulin (SHBG) levels reduce the risk of type 2 diabetes. Hum Mol Genet 19:535–544
Zabrodsky S (1990) [Chronic candidosis]. Prakt Zubn Lek 38:115–122 (article in Czech)
De Silva NM, Freathy RM, Palmer TM et al (2011) Mendelian randomization studies do not support a role for raised circulating triglyceride levels influencing type 2 diabetes, glucose levels, or insulin resistance. Diabetes 60:1008–1018
Dupuis J, Langenberg C, Prokopenko I et al (2010) New genetic loci implicated in fasting glucose homeostasis and their impact on type 2 diabetes risk. Nat Genet 42:105–116
Kathiresan S, Melander O, Guiducci C et al (2008) Six new loci associated with blood low-density lipoprotein cholesterol, high-density lipoprotein cholesterol or triglycerides in humans. Nat Genet 40:189–197
Kathiresan S, Willer CJ, Peloso GM et al (2009) Common variants at 30 loci contribute to polygenic dyslipidemia. Nat Genet 41:56–65
Speliotes EK, Willer CJ, Berndt SI et al (2010) Association analyses of 249,796 individuals reveal 18 new loci associated with body mass index. Nat Genet 42:937–948
Lawlor DA, Bedford C, Taylor M, Ebrahim S (2003) Geographical variation in cardiovascular disease, risk factors, and their control in older women: British Women’s Heart and Health Study. J Epidemiol Commun Health 57:134–140
Ehret GB, Munroe PB, Rice KM et al (2011) Genetic variants in novel pathways influence blood pressure and cardiovascular disease risk. Nature 478:103–109
Freathy RM, Timpson NJ, Lawlor DA et al (2008) Common variation in the FTO gene alters diabetes-related metabolic traits to the extent expected given its effect on BMI. Diabetes 57:1419–1426
Rees SD, Islam M, Hydrie MZ et al (2011) An FTO variant is associated with type 2 diabetes in South Asian populations after accounting for body mass index and waist circumference. Diabet Med 28:673–680
Jafar TH, Qadri Z, Chaturvedi N (2008) Coronary artery disease epidemic in Pakistan: more electrocardiographic evidence of ischaemia in women than in men. Heart 94:408–413
Hussain R (1999) Community perceptions of reasons for preference for consanguineous marriages in Pakistan. J Biosoc Sci 31:449–461
Jafar TH, Levey AS, White FM et al (2004) Ethnic differences and determinants of diabetes and central obesity among South Asians of Pakistan. Diabet Med 21:716–723
Lin X, Song K, Lim N et al (2009) Risk prediction of prevalent diabetes in a Swiss population using a weighted genetic score—the CoLaus Study. Diabetologia 52:600–608
Neter J, Wasserman W, Kutner MH (1990) Applied linear statistical models: regression, analysis of variance, and experimental designs. Irwin, Homewood
Pierce BL, Ahsan H, Vanderweele TJ (2011) Power and instrument strength requirements for Mendelian randomization studies using multiple genetic variants. Int J Epidemiol 40:740–752
Teslovich TM, Musunuru K, Smith AV et al (2010) Biological, clinical and population relevance of 95 loci for blood lipids. Nature 466:707–713
Bhargava SK, Sachdev HS, Fall CH et al (2004) Relation of serial changes in childhood body-mass index to impaired glucose tolerance in young adulthood. N Engl J Med 350:865–875
Acknowledgements
We thank N. Poulter (Imperial College London, UK), and J. Hatcher (Aga Khan University, Pakistan) for advice and S. Hashmi (Aga Khan University, Pakistan) for project implementation and R. Bux (Aga Khan University, Pakistan) for data management support.
Funding
The study was financially supported by a research award (080747/Z/06/Z) from the Wellcome Trust, UK. The design, conduct, analysis, interpretation and presentation of the data were the responsibility of the authors, with no involvement from the funder.
Duality of interest
The authors declare that there is no duality of interest associated with this manuscript.
Contribution statement
MI, THJ and TMF analysed and interpreted the data, and drafted the manuscript. THJ, NC, and TMF contributed to the conception and design of the study. All authors contributed to the interpretation of data, critical review and approved the final version of manuscript to be published.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM Table 1
(PDF 18 kb)
ESM Table 2
(PDF 14 kb)
Rights and permissions
About this article
Cite this article
Islam, M., Jafar, T.H., Wood, A.R. et al. Multiple genetic variants explain measurable variance in type 2 diabetes-related traits in Pakistanis. Diabetologia 55, 2193–2204 (2012). https://doi.org/10.1007/s00125-012-2560-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00125-012-2560-y