
Abstract
In this paper, a novel framework, named global-local feature attention network with reranking strategy (GLAN-RS), is presented for image captioning task. Rather than only adopt unitary visual information in the classical models, GLAN-RS explore attention mechanism to capture local convolutional salient image maps. Furthermore, we adopt reranking strategy to adjust the priority of the candidate captions and select the best one. The proposed model is verified using the MSCOCO benchmark dataset across seven standard evaluation metrics. Experimental results show that GLAN-RS significantly outperforms the state-of-the-art approaches such as M-RNN, Google NIC etc., which gets an improvement of 20% in terms of BLEU4 score and 13 points in terms of CIDER score.
J. Wu—Student Paper.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
With the rapid development of the artificial intelligence in recent years, image caption has been a hot spot in computer vision and natural language processing. Image caption is a multidisciplinary subject involving signal processing, pattern recognition, computer vision and cognitive sciences, which aims to describe the content of the input image by learning dense mappings between images and words. Image caption can be applied to the image retrieval, children’s education and the life support for visually impaired persons, which has a positive role in promoting social life.
Due to the advances of deep neural network [1], some state-of-the-art models have been presented for solving the challenges of generating image captions. For example, Mao et al. [2] propose a multimodal recurrent neural network (MRNN) for sentence generation. Xu et al. [3] explore attention mechanisms that capture salient feature of the raw image to generate caption. However, they only adopt unitary image feature instead of feeding global and local visual information simultaneously. Furthermore, they are easy to generate caption irrelevant to image content.
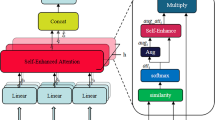
In order to overcome the above limitations, we propose a new global-local feature attention network with reranking strategy (GLAN-RS) for addressing image-captioning task. As illustrated in Fig. 1, GLAN-RS consists of global-local feature attention network to exploit visual information and a reranking strategy to select the consensus caption in candidate captions.

The framework of GLAN-RS, which consists of global-local feature attention network (red dashed) and reranking strategy network (blue dashed). Emb denotes the dense word representation with two integrated layers. SGRU denotes the Stacked Gated Recurrent Unit. (Color figure online)
Our contributions are as follows:
Firstly, GLAN-RS combines global image feature and local convolutional attention maps for capture holistic and salient visual information simultaneously.
Secondly, we explore nearest neighbor approach to calculate the image similarity and obtain their reference captions. Thus we can determine the best candidate caption by finding the one with highest score respect to the reference captions.
Moreover, we validate the effectiveness of GLAN-RS comparing with the state-of-the-art approaches [2, 4] consistently across seven evaluation metrics, which show that GLAN-RS get an improvement of 20% in terms of BLEU4 score and 13 points in terms of CIDER score.
2 Proposed Method
2.1 Encoder-Decoder Framework for Image Caption Generation
We adopt the popular encoder-decoder framework for image caption generation, where convolution neural network (CNN) [5, 6] encodes the image into a fixed-dimension feature vector and then a stacked Gated Recurrent Unit (SGRU) [7] decodes the visual information into sematic information. Given an input image and its corresponding caption, the encoder-decoder model directly maximize the log-likelihood function of the following objective:

The global image attention features and regional convolutional attention feature extraction process.
2.2 Global Image Attention Feature
Where \(f_I\) denotes the global image representation of the raw image, \(s_i\) denotes a sequence of words in a sentence of length L and is the parameters of the model. Images information should be encoded as fix-length vectors to feed into SGRU. CNN is used to extract the image feature map \(f_I\) from a raw image I to give an overview of the image content to the model:
As is shown is Fig. 2, we capture the global image attention feature in the last fully-connected layer.
2.3 Local Convolutional Image Attention Feature
In the encoder-decoder framework with SGRU and local convolutional attention map, the conditional probability of the log-likelihood function is modeled as:
where \(c_t\) is the attention context vector obtained in the third layer of the fifth convolutional layer. In this paper, we utilize the SGRU with two hidden layers to modulate the information flow inside the unit instead of applying a separate memory cells. \(h_t\) is the activation of the hidden state in SGRU at time t, which is a linear combination between previous activation \(h_{t-1}\) and the candidate activation \(h_t^{'}\):
where \(z_t\) denotes how the unit updates its content. The method for computing attention context vector \(c_t\) in spatial attention mechanism is defined as:
where \(f_{att}\) is the spatial attention function. \(I\in R^{d \times k}=[I_1,I_k]\), \(I_i\in R^d\) is the local convolutional image features, each is a d dimensional representation corresponding to a region of the image in conv5, 3 layer. As is shown is Fig. 2, we exploit the 14 * 14 intermediate feature map by attention mechanism.

The visualization of the raw image.

The visualization of the partial activation feature in conv5, 3 layer.
We show in Fig. 3 raw image and visualize its CNN features in Fig. 4, from which we can find the fifth convolutional layer is effective to capture accurate semantic content due to its low spatial resolution while the third layer is more effective to highlight details precisely. This means the activation feature in the conv5, 3 layer can detect some pivotal image areas and guide our model to excavate regional visual representation.
We feed the spatial image features \(I_i\) and hidden state \(h_t\) through a hyperbolic tangent neural function followed by a softmax function to generate the attention distribution over the k regions of the image:
where \(w_i\),\(w_h\) are the project parameters to be learnt. \(\alpha _t\) is the spatial attention weight over features in \(I_i\). The attention context vector \(c_t\) is computed bases on the attention distribution:
We combine \(c_t\) and \(h_t\) to predict the next word as in Eq. (3). As is shown in Fig. 5, we design a bimodal layer to process the information from the local image attention feature and the activation of the current hidden layer of SGRU. The Cascaded semantic layer is explored to capture dense syntactic representation.

The flowchart of GLAN model. Modules of different colors represent layers of different functions. The input layer feeds the words one by one. (Color figure online)
2.4 Reranking Strategy
For a test image, we first utilize global-local feature attention network to create the hypothetical captions adopting Beam Search algorithm. Then we use nearest neighbor approach to find the similar images and their corresponding reference captions. In this paper, Euclidean distance measure \(D_E (x_1,x_2 )\) is adopted to calculate the feature similarities, which are defined by:
We define consensus caption \(C^*\) as the one that has the highest accumulated similarity with the reference captions. The consensus caption selective function is defined by [8]:
where H is the set of hypothetical captions while R is the set of reference captions. \(Sim(c_1,c_2)\) is the accumulated lexical similarity function between two captions \(c_1\),\(c_2\)
where \(p_n\) is the modified n-gram precision and BP is a brevity penalty for the short sentences, which is computed by:
where b is the length of the reference sentence while c is the length of the candidate sentence.
3 Experimental Results
We evaluate the performance of GLAN-RS using the MSCOCO dataset [9, 10], which contains 82,783 images for training, 40,504 for validation, with 5 reference captions provided by human annotators [11]. We randomly sample 1000 images for testing. We utilize two classical CNN models, i.e., IV3 network [5] and VggNet [6] to en-code the visual information. Seven standard evaluation metrics are adopted for evaluations, including BLEU scores (i.e. B-1, B-2, B-3 and B-4) [12] and MSCOCO validate toolkit (ROUGE-L, CIDEr and METEOR) [13,14,15].
3.1 Datasets
Microsoft COCO Caption is a datasets released by Microsoft Corporation and contains almost 300,000 images with five reference sentences; The MS COCO Caption datasets is created for image caption, which not only consists of rich images and captions, but also provides the computing servers and code of evaluation merits. The MS COCO Caption datasets has become the first choice of researchers in recent year. Figure 6 illustrates some pictures in MSCOCO datasets.

The illustration of pictures in MSCOCO datasets.
3.2 Evaluation Metrics
In order to validate the quality of the caption generated by the model, we choose seven automatic evaluation merits that have a high correlation with human judgments. The higher the score of merits, the better effect of image caption.
Bleu [12] was designed for automated evaluation of statistical machine translation, which can be adopted to measure similarity of descriptions. Given the diversity of possible image descriptions, Bleu may penalize candidates which are arguably descriptive of image content. CIDEr [13] is a special automatic evaluation metrics for image caption, which measures the consistency of image caption by calculating TF-IDF weights of each n-tuple. ROUGE [14] is a set of evaluation metrics designed to evaluate text summarization algorithms. ROUGE-L uses a measure based on the Longest Common Subsequence. Meteor [15] is the harmonic mean of unigram precision and recall that allows for exact, synonym, and paraphrase matchings between candidates and references. The researchers can calculate precision, recall, and F-measure by Meteor.
3.3 Model Details
We trained all sets of weights using stochastic gradient descent with changed learning rate and no momentum. We set fix learning rate in initial iteration period and decline 15% every iteration period after initial iteration period
Dropout and ReLu function are adopted to avoid gradient vanishing or exploding. All weights are randomly initialized with the range of (−1.0, 1.0). we use 1028 dimensions for dense embedding and the size of the SGRU is set to 2048. To infer the sentence given an input image, we use Beam Search algorithm, which keeps the best m generated captions. For convenience, we introduce the architectural details in the following:
GLAN+VGG uses VGGnet to extract the 4096-dimensions holistic visual embedding features while GLAN+IV3 utilizes Inception V3 network to encode the 2048-dimensions holistic image representations. GLAN+RS applies the Euclidean distance function to re-rank the order of the caption. We denote GLAN+RS as our proposed model to compare with several state-of-the-art models.
3.4 Performance Comparison of GLAN-RS with the State-of-the-Art Models
In order to verify the superiority of our proposed model, we compare its performance with some state-of-the-art methods including: Google NIC [4], GLSTM [11], Attention [3] and MRNN [2].
Tables 1 and 2 list the comparison results, where we respectively encode visual embedding features with VggNet and IV3 network. From the tables, we can obtain the follow conclusion:
-
1.
GLAN performs best for almost all the listed evaluation criteria with using VggNet and IV3 network respectively to extract the visual embedding feature. This may due to the reason that our model employ global and local attention feature to learn deep image-to-word mapping, which is able to exploit semantic context to high quality image captions.
-
2.
GLAN+IV3 outperforms GLAN+VGG, which means robust image representation benefits the performance.
-
3.
Attention mechanism is able to capture the latent visual representation to get higher Bleu1 score and generate high-level caption.
-
4.
Reranking strategy makes it possible to select the caption with the highest accumulated similarity with the reference captions.
-
5.
GLAN+RS has a remarkable improvement on the all evaluation criteria. GLAN+RS significantly outperforms the state-of-the-art approaches such as M-RNN, Google NIC etc., which gets an improvement of 20% in terms of BLEU4 score and 13 points in terms of CIDER score.

The illustration of the generated caption by GLAN-RS model.
3.5 Generation Results
In order to qualitatively validate the effective of GLAN-RS, we select several images to generate captions by GLAN-RS model, which is shown in the Fig. 7.
As is shown in Fig. 7, our proposed model can detect the activity phrases such as “catch a frisbee”, “ride a snowboard” and “pullig a carriage” in different instances, which indicates that GLAN-RS is able to capture the key action information in the image. our model notices the “red fire hydrant” and “donut with sprinkles” in instance (D) and (C), which validate that our model make it possible to exploit latent detail information. It’s amazing to find that the phrase “at night” is generated for instance (F) , which show that GLAN-RS benefits its distinctive encoder-decoder framework which combines the global and regional attention features to capture semantic-related visual concept representation.
4 Conclusion
In this paper, we propose a novel global-local feature attention network with re-ranking strategy (GLAN-RS) for image caption generation. We utilize global image feature and local convolutional attention maps for exploiting visual representation. The consensus caption is selected by nearest neighbor approach and reranking strategy. The experimental results on benchmark MSCOCO dataset demonstrate the superiority of GLAN-RS for generating high quality image captions.
References
Krizhevsky, A., Sutskever, I., Hinton, G.: ImageNet classification with deep convolutional neural networks. In: NIPS (2012)
Mao, J., Xu, W., Yang, Y., Wang, J., Yuille, A.: Deep captioning with multimodal recurrent neural networks (mRNN). arXiv preprint arXiv:1412.6632 (2014)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A.C., Salakhutdinov, R., Zemel, R.S., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. CoRR, abs/1502.03044 (2015)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: CVPR (2015)
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. arXiv preprint arXiv:1409.4842 (2014)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556 (2014)
Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Empirical evaluation of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555 (2014)
Devlin, J., Gupta, S., Girshick, R., Mitchell, M., Zitnick, C.L.: Exploring nearest neighbor approaches for image captioning. arXiv preprint arXiv:1505.04467 (2015)
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Chen, X., Fang, H., Lin, T.Y., Vedantam, R., et al.: Microsoft coco captions: data collection and evaluation server. arXiv:1504.00325 (2015)
Rashtchian, C., Young, P., Hodosh, M., et al.: Collecting image captions using Amazon’s mechanical turk. In: NAACL Hlt 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, pp. 139–147 (2010)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: BLEU: a method for automatic evaluation of machine translation. In: ACL, pp. 311–318 (2002)
Vedantam, R., Zitnick, C.L., Parikh, D.: Cider: consensus-based image description evaluation. In: CVPR (2015)
Lin, C.-Y.: Rouge: a package for automatic evaluation of summaries. In: Text Summarization Branches Out: Proceedings of the ACL-04 Workshop, vol. 8 (2004)
Banerjee, S., Lavie, A.: Meteor: an automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, vol. 29, pp. 65–72 (2005)
Jia, X., Gavves, E., Fernando, B., et al.: Guiding the long-short term memory model for image caption generation. In: ICCV (2015)
Acknowledgements
We are grateful for the financial support from the Innovative Application and Re-search Project of Guangdong Province (No. 2016KZDXM013) and the Science & Technology Project of Shantou City (A201400150).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Wu, J., Xie, S., Shi, X., Chen, Y. (2017). Global-Local Feature Attention Network with Reranking Strategy for Image Caption Generation. In: Yang, J., et al. Computer Vision. CCCV 2017. Communications in Computer and Information Science, vol 771. Springer, Singapore. https://doi.org/10.1007/978-981-10-7299-4_13
Download citation
DOI: https://doi.org/10.1007/978-981-10-7299-4_13
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7298-7
Online ISBN: 978-981-10-7299-4
eBook Packages: Computer ScienceComputer Science (R0)