
Abstract
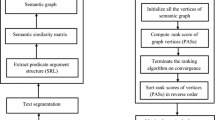
Summarization mainly provides the major topics or theme of document in limited number of words. However, in extract summary we depend upon extracted sentences, while in abstract summary, each summary sentence may contain concise information from multiple sentences. The major facts which affect the quality of summary are: (1) the way of handling noisy or less important terms in document, (2) utilizing information content of terms in document (as, each term may have different levels of importance in document) and (3) finally, the way to identify the appropriate thematic facts in the form of summary. To reduce the effect of noisy terms and to utilize the information content of terms in the document, we introduce the graph theoretical model populated with semantic and statistical importance of terms. Next, we introduce the concept of weighted minimum vertex cover which helps us in identifying the most representative and thematic facts in the document. Additionally, to generate abstract summary, we introduce the use of vertex constrained shortest path based technique, which uses minimum vertex cover related information as valuable resource. Our experimental results on DUC-2001 and DUC-2002 dataset show that our devised system performs better than baseline systems.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Barrera, A., Verma, R.: Automated Extractive Single-document Summarization: Beating the Baselines with a New Approach. In: SAC 2011, pp. 268–269 (2011)
Barrera, A., Verma, R.: Combining syntax and semantics for automatic extractive single-document summarization. In: Gelbukh, A. (ed.) CICLing 2012, Part II. LNCS, vol. 7182, pp. 366–377. Springer, Heidelberg (2012)
Bekkerman, R., Allan, J.: Using Bigrams in Text Categorization. CIIR Technical Report IR-408 (2004)
Cai, S., Su, K., Sattar, A.: Local search with edge weighting and configuration checking heuristics for minimum vertex cover. Artif. Intell. 175(9-10), 1672–1696 (2011)
Cai, S., Su, K., Sattar, A.: Two New Local Search Strategies for Minimum Vertex Cover. In: AAAI 2012 (2012)
Lloret, E., Palomar, M.: Analyzing the Use ofWord Graphs for Abstractive Text Summarization. In: IMMM 2011 (2011)
Filippova, K.: Multi-Sentence Compression: Finding Shortest Paths in Word Graphs. In: COLING 2010, pp. 322–330 (2010)
Kumar, N., Srinathan, K.: Automatic keyphrase extraction from scientific documents using N-gram filtration technique. In: ACM DocEng 2008, pp. 199–208 (2008)
Kumar, N., Srinathan, K., Varma, V.: Using wikipedia anchor text and weighted clustering coefficient to enhance the traditional multi-document summarization. In: Gelbukh, A. (ed.) CICLing 2012, Part II. LNCS, vol. 7182, pp. 390–401. Springer, Heidelberg (2012)
Lin, C.: Rouge: a package for automatic evaluation of summaries. In: Proceedings of Workshop on Text Summarization Branches Out, Post-conference Workshop of ACL 2004, Barcelona, Spain (2004)
Mcdonald, D.M., Chen, H.: Summary in context: searching versus browsing. ACM Transactions on Information Systems 24(1), 111–141 (2006)
Mihalcea, R., Tarau, P.: Textrank: bringing order into texts. In: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (2004)
Wan, X.: Towards a Unified Approach to Simultaneous Single-document and Multi-document Summarizations. In: COLING 2010, pp. 1137–1145 (2010)
Wan, X., Yang, J.: Collabsum: exploiting multiple documents clustering for collaborative single document summarizations. In: Proc. of SIGIR 2007, Amsterdam, The Netherlands, pp. 143–150 (2007)
Tsatsaronis, G., Varlamis, I., Nørvåg, K.: SemanticRank: Ranking Keywords and Sentences Using Semantic Graphs. In: COLING 2010, pp. 1074–1082 (2010)
Kumar, N., Srinathan, K., Varma, V.: Using graph based mapping of co-occurring words and closeness centrality score for summarization evaluation. In: Gelbukh, A. (ed.) CICLing 2012, Part II. LNCS, vol. 7182, pp. 353–365. Springer, Heidelberg (2012)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Kumar, N., Srinathan, K., Varma, V. (2013). A Knowledge Induced Graph-Theoretical Model for Extract and Abstract Single Document Summarization. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2013. Lecture Notes in Computer Science, vol 7817. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-37256-8_34
Download citation
DOI: https://doi.org/10.1007/978-3-642-37256-8_34
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-37255-1
Online ISBN: 978-3-642-37256-8
eBook Packages: Computer ScienceComputer Science (R0)