
Abstract
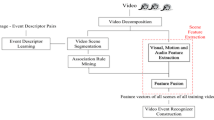
Automatic event detection in a large collection of unconstrained videos is a challenging and important task. The key issue is to describe long complex video with high level semantic descriptors, which should find the regularity of events in the same category while distinguish those from different categories. This paper proposes a novel unsupervised approach to discover data-driven concepts from multi-modality signals (audio, scene and motion) to describe high level semantics of videos. Our methods consists of three main components: we first learn the low-level features separately from three modalities. Secondly we discover the data-driven concepts based on the statistics of learned features mapped to a low dimensional space using deep belief nets (DBNs). Finally, a compact and robust sparse representation is learned to jointly model the concepts from all three modalities. Extensive experimental results on large in-the-wild dataset show that our proposed method significantly outperforms state-of-the-art methods.
Chapter PDF
Similar content being viewed by others

Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 60, 91–110 (2004)
Laptev, I., Lindeberg, T.: Space-time interest points. In: ICCV, pp. 432–439 (2003)
Rabiner, L., Juang, B.: Fundamentals of Speech Recognition, Englewood Cliffs, New Jersey. Prentice-Hall Signal Processing Series (1993)
Loui, A.C., Luo, J., Chang, S.F., Ellis, D., Jiang, W., Kennedy, L.S., Lee, K., Yanagawa, A.: Kodak’s consumer video benchmark data set: concept definition and annotation. In: Multimedia Information Retrieval, pp. 245–254 (2007)
Wei, X.Y., Jiang, Y.G., Ngo, C.W.: Concept-driven multi-modality fusion for video search. IEEE Trans. Circuits Syst. Video Techn. 21, 62–73 (2011)
Le, Q.V., Ngiam, J., Chen, Z., Chia, D., Koh, P.W., Ng, A.Y.: Tiled convolutional neural networks. In: NIPS 2010 (2010)
Hinton, G.E., Osindero, S., Whye Teh, Y.: A fast learning algorithm for deep belief nets. Neural Computation (2006)
Schindler, G., Zitnick, L., Brown, M.: Internet video category recognition. In: CVPRW 2008, pp. 1–7 (2008)
Wang, Z., Zhao, M., Song, Y., Kumar, S., Li, B.: Youtubecat: Learning to categorize wild web videos. In: CVPR 2010, pp. 879–886 (2010)
Dollár, P., Rabaud, V., Cottrell, G., Belongie, S.: Behavior recognition via sparse spatio-temporal features. In: VS-PETS (2005)
van Hateren, J.H., Ruderman, D.L.: Independent component analysis of natural image sequences yields spatiotemporal filters similar to simple cells in primary visual cortex (1998)
Hyvärinen, A., Hoyer, P.: Emergence of phase- and shift-invariant features by decomposition of natural images into independent feature subspaces. Neural Computation (2000)
Le, Q., Zou, W., Yeung, S., Ng, A.: Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In: CVPR 2011, pp. 3361–3368 (2011)
Liu, X., Huet, B.: Automatic concept detector refinement for large-scale video semantic annotation. In: 2010 IEEE Fourth International Conference on Semantic Computing (ICSC), pp. 97–100 (2010)
Liu, J., Luo, J., Shah, M.: Recognizing realistic actions from videos ”in the wild”. In: CVPR (2009)
Rodriguez, M.D., Ahmed, J., Shah, M.: Action mach a spatio-temporal maximum average correlation height filter for action recognition. In: CVPR. IEEE Computer Society (2008)
Hinton, G., Salakhutdinov, R.: Reducing the dimensionality of data with neural networks. Science 313, 504–507 (2006)
Snoek, C.G.M.: Early versus late fusion in semantic video analysis. ACM Multimedia, 399–402 (2005)
Olshausen, B.A.: Sparse coding of time-varying natural images. In: Proc. of the Int. Conf. on Independent Component Analysis and Blind Source Separation, pp. 603–608 (2000)
Hyvarinen, A., Hoyer, P., Inki, M.: Topographic ica as a model of v1 receptive fields. In: IJCNN 2000, vol. 4, pp. 83–88 (2000)
Taylor, G.W., Fergus, R., LeCun, Y., Bregler, C.: Convolutional Learning of Spatio-temporal Features. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010, Part VI. LNCS, vol. 6316, pp. 140–153. Springer, Heidelberg (2010)
Trecvid (2011), http://www-nlpir.nist.gov/projects/tv2011/tv2011.html
van Gemert, J.C., Veenman, C.J., Smeulders, A.W.M., Geusebroek, J.M.: Visual word ambiguity. IEEE Transactions on Pattern Analysis and Machine Intelligence 32, 1271–1283 (2010)
Lee, H., Ekanadham, C., Ng, A.Y.: Sparse deep belief net model for visual area V2. In: Advances in Neural Information Processing Systems 20, pp. 873–880 (2008)
Chang, C.C., Lin, C.J.: LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology 2, 27:1–27:27 (2011), Software http://www.csie.ntu.edu.tw/~cjlin/libsvm
Wang, H., Ullah, M.M., Kläser, A., Laptev, I., Schmid, C.: Evaluation of local spatio-temporal features for action recognition. In: British Machine Vision Conference, p. 127 (2009)
Wang, H., Klaser, A., Schmid, C., Liu, C.L.: Action recognition by dense trajectories. In: CVPR 2011, pp. 3169–3176 (2011)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2012 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Yang, Y., Shah, M. (2012). Complex Events Detection Using Data-Driven Concepts. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds) Computer Vision – ECCV 2012. ECCV 2012. Lecture Notes in Computer Science, vol 7574. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-33712-3_52
Download citation
DOI: https://doi.org/10.1007/978-3-642-33712-3_52
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-33711-6
Online ISBN: 978-3-642-33712-3
eBook Packages: Computer ScienceComputer Science (R0)