
Abstract
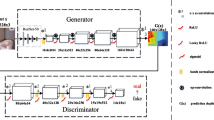
Understanding 3D environment based on deep learning is the subject of interest in computer vision community due to its wide variety of applications. However, learning good 3D representation is a challenging problem due to many factors including high dimensionality of the data, modeling complexity in terms of symmetric objects, required computational costs and expected variations scale up by the order of 1.5 compared to learning 2D representations. In this paper we address the problem of typical 3D representation by transformation from its corresponding single 2D representation using Deep Autoencoder based Generate Adversarial Network termed as 2D-3D Transformation Network (2D-3D-TNET). The proposed model objective is based on traditional GAN loss along with the autoencoder loss, which allows the generator to effectively generate 3D objects corresponding to the input 2D images. Furthermore, instead of training the discriminator to discriminate real from generated image, we allow the discriminator to take both 2D image and 3D object as an input and learn to discriminate whether they are true correspondences or not. Thus, the discriminator learns and encodes the relationship between 3D objects and their corresponding projected 2D images. In addition, our model does not require labelled data for training and learns on unsupervised data. Experiments are conducted on ISRI_DB with real 3D daily-life objects as well as with the standard ModelNet40 dataset. The experimental results demonstrate that our model effectively transforms 2D images to their corresponding 3D representations and has the capability of learning rich relationship among them as compared to the traditional 3D Generative Adversarial Network (3D-GAN) and Deep Autoencoder (DAE).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Carlson, W.E.: An algorithm and data structure for 3D object synthesis using surface patch intersections. ACM SIGGRAPH Comput. Graph. 16(3), 255–263 (1982)
Tangelder, J.W.H., Veltkamp, R.C.: A survey of content based 3D shape retrieval methods. In: Proceedings of Shape Modeling Applications. IEEE (2004)
Van Kaick, O., et al.: A survey on shape correspondence. Comput. Graph. Forum 30(6) (2011)
Chang, A.X., et al.: Shapenet: An information-rich 3D model repository. arXiv preprint arXiv:1512.03012 (2015)
Wu, Z., et al.: 3D shapenets: a deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015)
Girdhar, R., et al.: Learning a predictable and generative vector representation for objects. In: European Conference on Computer Vision. Springer, Cham (2016)
Qi, C.R., et al.: Volumetric and multi-view CNNs for object classification on 3D data. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016)
Su, H., et al.: Multi-view convolutional neural networks for 3D shape recognition. In: Proceedings of the IEEE International Conference on Computer Vision (2015)
Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems (2014)
Radford, A., Metz, L., Chintala, S.: Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015)
Sharma, A., Oliver, G., Fritz, M.: VConv-DAE: deep volumetric shape learning without object labels. In: European Conference on Computer Vision. Springer, Cham (2016)
Laurentini, A.: The visual hull concept for silhouette-based image understanding. IEEE Trans. Pattern Anal. Mach. Intell. 16(2), 150–162 (1994)
Woodham, R.J.: Photometric method for determining surface orientation from multiple images. Opt. Eng. 19(1), 191139 (1980)
Furukawa, Y., Hernández, C.: Multi-view stereo: a tutorial. Found. Trends® Comput. Graph. Vis. 9(1-2), 1–148 (2015)
Flynn, J., et al.: Deepstereo: learning to predict new views from the world’s imagery. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016)
Ji, D., et al.: Deep view morphing. In: Computer Vision and Pattern Recognition (CVPR), vol. 2 (2017)
Garg, R., et al.: Unsupervised cnn for single view depth estimation: geometry to the rescue. In: European Conference on Computer Vision. Springer, Cham (2016)
Dosovitskiy, A., Tobias Springenberg, J., Brox, T.: Learning to generate chairs with convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015)
Wu, J., et al.: Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In: Advances in Neural Information Processing Systems (2016)
Rezende, D.J., et al.: Unsupervised learning of 3D structure from images. In: Advances in Neural Information Processing Systems (2016)
Yan, X., et al.: Perspective transformer nets: learning single-view 3D object reconstruction without 3D supervision. In: Advances in Neural Information Processing Systems (2016)
Maas, A.L., Hannun, A.Y., Ng, A.Y.: Rectifier nonlinearities improve neural network acoustic models. In: Proceedings ICML, vol. 30, no. 1 (2013)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Kim, J., et al.: Octree-based obstacle representation and registration for real-time. In: ICMIT 2007: Mechatronics, MEMS, and Smart Materials, vol. 6794. International Society for Optics and Photonics (2008)
Baldi, P.: Autoencoders, unsupervised learning, and deep architectures. In: Proceedings of ICML Workshop on Unsupervised and Transfer Learning (2012)
Intelligent Systems Research Institute Database of Household Objects (ISRI_DB). http://isrc.skku.ac.kr/DB3D/db.php
Acknowledgement
Sukhan Lee proposed the concept of transformation of single 2D image to its corresponding typical 3D representation using 2D-3D Transformation Network, while Naeem Ul Islam implements the concept and carries out experimentation. This research was supported, in part by the “Robot Industry Fusion Core Technology Development Project” of KEIT (10048320), in part, by the “Project of e-Drive Train Platform Development for small and medium Commercial Electric Vehicles based on IoT Technology” of Korea Institute of Energy Technology Evaluation and Planning (KETEP) (20172010000420), sponsored by the Korea Ministry of Trade, Industry and Energy (MOTIE) and in part by the MSIP under the space technology development program (NRF-2016M1A3A9005563) supervised by the NRF.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Ul Islam, N., Lee, S. (2019). Learning Typical 3D Representation from a Single 2D Correspondence Using 2D-3D Transformation Network. In: Lee, S., Ismail, R., Choo, H. (eds) Proceedings of the 13th International Conference on Ubiquitous Information Management and Communication (IMCOM) 2019. IMCOM 2019. Advances in Intelligent Systems and Computing, vol 935. Springer, Cham. https://doi.org/10.1007/978-3-030-19063-7_35
Download citation
DOI: https://doi.org/10.1007/978-3-030-19063-7_35
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-19062-0
Online ISBN: 978-3-030-19063-7
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)