
Abstract
In the context of the challenge of “automatic InterVertebral Disc (IVD) localization and segmentation from 3D multi-modality MR images” that took place at MICCAI 2018, we have proposed a segmentation method based on simple image processing operators. Most of these operators come from the mathematical morphology framework. Driven by some prior knowledge on IVDs (basic information about their shape and the distance between them), and on their contrast in the different modalities, we were able to segment correctly almost every IVD. The most interesting feature of our method is to rely on the morphological structure called the Three of Shapes, which is another way to represent the image contents. This structure arranges all the connected components of an image obtained by thresholding into a tree, where each node represents a particular region. Such structure is actually powerful and versatile for pattern recognition tasks in medical imaging.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Segmenting intervertebral discs (IVDs) is important to be able to measure automatically their degeneration. Indeed, there is a strong association between such degeneration and low back pain, which is one of the most prevalent health problems amongst population and, consequently, a leading cause of disability that affects work performances and well-being.
The recent trend in medical imaging segmentation is to use convolutional neural networks (CNN), which was not yet the case of the (rather) recent state-of-the-art methods such as [1, 10, 14, 15]. Since many research groups would probably take advantage of the powerful—yet black-boxed–CNNs, we have decided to propose an alternative approach based on mathematical morphology. Section 2 explains the morphological tools used in our method, which is described in Sect. 3. The result we obtained on the data provided by the challenge “Automatic intervertebral disc localization and segmentation from 3D multi-modality MR images (IVDM3Seg)”Footnote 1, that took place at the 21st International Conference on Medical Image Computing & Computer Assisted Intervention (MICCAI) 2018, are given in Sect. 4. As we advocate reproducible research, the code of the method presented here is available from:
2 Theoretical Background
The method we propose falls into the framework of mathematical morphology. This section thus recalls the basic notions that are used in this paper. We will consider that an image, either a 2D digital image or a 3D digital volume, are represented by a function \(f : X \rightarrow Y\), where X is a subset of \(\mathbb {Z} ^2\), resp. \(\mathbb {Z} ^3\), and where Y is a subset of \(\mathbb {N} \), typically \(\llbracket 0, 255 \rrbracket \) in the case of an 8-bit quantization.
2.1 Operators
An operator \(\varphi \) on images (i.e., taking an image as input and producing an image as output) is:
-
increasing iff \(f_1 \le f_2 \,\Rightarrow \, \varphi (f_1) \le \varphi (f_2)\),
-
idempotent iff \(\varphi \circ \varphi (f) = \varphi (f)\),
-
extensive iff \(\varphi (f) \ge f\),
-
anti-extensive iff \(\varphi (f) \le f\).
In the writing of these properties, we implicitly consider that, for an operator \(\varphi \), they apply whatever the considered functions. Furthermore, \(\varphi \circ \varphi (f) = \varphi (f)\) means that \(\forall x \in X,\) we have \(\varphi \circ \varphi (f)(x) = \varphi (f)(x)\). In the following, we will also use the classical operator compact notation, such as \(\varphi \circ \varphi = \varphi \), meaning that such a property applies whatever the function. Last, we say that:
-
the operators \(\varphi \) and \(\psi \) are dual iff \(\,\varphi (f) = -\psi (-f)\),
-
the operator \(\varphi \) is self-dual iff \(\,\varphi (f) = -\varphi (-f)\).
2.2 Morphology with Structuring Elements
First let us recall the couple of fundamental operators of mathematical morphology. We call structuring element, a set B of vectors having the same discrete coordinate system than X. In the following, we will only consider structuring elements with the two following properties:
-
centered, that is, \(0\in B\),
-
and symmetrical, that is, \(b \in B \,\Rightarrow \, -b \in B\).
The structuring element is a parameter for some morphological operators; its shape influences the filtering effect, while its size adjusts the filtering strength.
Given a structuring element B, the dilation \(\delta \) and the erosion \(\varepsilon \) are operators on images, respectively defined by:
These two operators are dual, so \(\,\varepsilon _B(f) = -\delta _B(-f)\). The dilation is extensive (the resulting image is brighter than the input image), whereas the erosion is anti-extensive (the result is darker than the input).

Illustration of the white top-hat effect, with B being a vertical line of 15 pixels. (Color figure online)
From these two operators, we can define two idempotent operators, the closing (extensive) and the opening (anti-extensive), respectively by:
which are dual: \(\phi _B(f) = -\gamma _B(-f)\). If we consider that an image f is seen as a landscape, where f(x) is the elevation—height of the landscape—at point x, the effect of the closing \(\phi _B\) is to fill valleys, i.e., image parts surrounded (in the sense of B) by brighter pixels, whereas the opening \(\gamma _B\) has the opposite effect: remove mountains, i.e., image parts surrounded by darker pixels. The white top-hat operator is derived from the opening:
where “\(\mathrm {id}\)” denotes the identity operator. Since we have \(\kappa _B \le \mathrm {id}\), the top-hat operator is anti-extensive: it removes some bright regions in images.
The behavior of the opening and top-hat operators are illustrated in Fig. 1. The IVD spaces appear as light parts in the original image f (Fig. 1(a)), surrounded vertically by some darker regions, that correspond to disks. Therefore the effect of an opening with a vertical structuring element is to remove the bright IVD spaces, as it can be seen in Fig. 1(b). In this image, namely \(\gamma _B(f)\), the part of the spine is exclusively dark.
The top-hat is the difference \(\kappa _B(f) = f - \gamma _B(f)\), so the removed IVDs now reappear; this result is depicted in Fig. 1(c). When comparing the original image f with \(\kappa _B(f)\), we can observe that most of the bright parts/objects of f have been filtered out, and, as a corollary, some IVD regions that were connected in f with some other anatomical parts are now de-connected in \(\kappa _B(f)\); see for example the red circle in Fig. 1(a) and (c).
In the following, the top-hat operator will thus be used to “clean” the 3D volumes in different modalities, so that:
-
many non-IVD objects are removed in the resulting volumes,
-
and IVDs appear more clearly and are de-connected from other objects.

Toy example of an image, its level lines, its shapes, and its tree of shapes.
2.3 Tree of Shapes
Given a gray-level image \(f : X \rightarrow Y\) and any scalar \(\lambda \in Y\), the lower level sets are defined as:
and the upper level sets as:
We will now consider the connected components (obtained by the operator denoted by \(\mathcal {CC}\)) of these sets. Let us denote by \(\mathrm {Sat}\) the cavity-fill-in operatorFootnote 2. In the following, we call shape the result of the cavity-fill-in operator applied to a connected component of a (lower or upper) level set. In the image f depicted in Fig. 2(b), we have for instance the lower level set \([f < 1] = \textsf {B}\), and \(\mathcal {CC} ([f < 1]) = \{\textsf {B}\}\). Note that \(\textsf {B}\) has two holes, namely \(\textsf {D}\) and \(\textsf {E}\), so we have the shape \(\mathrm {Sat} (\textsf {B}) = \textsf {B} \cup \textsf {D} \cup \textsf {E}\). An example of upper level set is \([f\ge 2]\), and \(\mathcal {CC} ([f\ge 2]) = \{\textsf {C},\textsf {D},\textsf {E}\}\). \(\textsf {C}\) is a component of a level set, so \(\mathrm {Sat} (\textsf {C}) = \textsf {C} \cup \textsf {F}\) is a shape. Figure 2(d) depicts the two shapes \(\mathrm {Sat} (\textsf {B})\) and \(\mathrm {Sat} (\textsf {C})\).
The tree of shapes (ToS) of an image u is classically [13] defined by:
An image f and its tree of shapes \(\mathfrak {S} (f)\) are depicted respectively in Fig. 2(b) and (e). An element of \(\mathfrak {S} (f)\) is called a shape; it is a connected component of X with no cavity, and its boundary is a level line of f. Two shapes of f are displayed in Fig. 2(d). Every shape corresponds to a node of the tree; for instance, in Fig. 2(e) (right), the sub-tree rooted at node “\(\textsf {B}\)” corresponds to the shape \(\,\textsf {B} \cup \textsf {D} \cup \textsf {E}\). Keeping the level of every node—such as displayed in Fig. 2(e) (right)—allows to reconstruct the image from its tree. It is thus another way to represent the image contents.

About properties of the tree of shapes and the level lines. (Color figure online)
It is worth mentioning that the tree of shapes has also been defined for multi-variate data [5], that is, images whose pixel values are not scalars but vectors, such as it is the case for instance for color images, multi-modality medical images, and multi-band satellite imagesFootnote 3.
The tree of shapes of an image f is a morphological representation of f, which makes it easier to deal with the image contents [9]. For a “classical” image, there is about as many nodes in the tree than pixels in the image. Such a tree thus encodes a lot of shapes (connected components, i.e., regions) and their inclusion relationship. Despite one might think that such a structure should be complex and long to compute, and heavy to store in memory, this is actually not true. Indeed, storing [3] and computing [6, 11, 12] the tree of shapes can both be done very efficiently.
The tree of shapes is an operator satisfying two important major properties. First, we have:
meaning that this representation does not favor a particular contrast (light regions surrounded by darker ones, or the opposite). This property thus “contrasts” with the morphological operators presented in Sect. 2.3, where dual operators (such as \(\delta \) and \(\varepsilon \), or \(\phi \) and \(\gamma \)) can be useful exactly because they rely on a particular kind of contrast: we choose one of the dual operators so that we process either brighter or darker parts of the images (remind Fig. 1 for instance). Conversely, the tree of shapes is a structure from which we can derive self-dual operators, that are, operators that process “the same way” light objects and dark objects. The second property is that, with any non-negative function \(\ell \) acting over gray-levels (that is, a contrast change function), we have:
This property implies that it is not the gray-level values of the pixels that matters, but only their ordering. Applying a gray-level change (or look-up table) such as \(\ell = [0\mapsto 0,\, 1\mapsto 2,\, 2\mapsto 4,\, 3\mapsto 5]\) to the image in Fig. 2(b) does not change the structure of its tree of shapes: the ToS of the new image is the one of Fig. 2(e). As a direct consequence, the image processing operators that derive from the ToS structure apply the same way on low-contrasted images (or low-contrasted parts of images) than on better contrasted ones.

These properties are illustrated in Fig. 3. The image on the left in Fig. 3(a) has been modified to produce two new images. The modification #1 consists in contrast-change and contrast-inversion on the different color components; we have applied a function \(\ell _i\) (such as in Eq. 10) on each \(i^{\mathrm {th}}\) component. The modification #2 is a local contrast change. In both cases, the original image and the modified ones have exactly the same set of level lines, depicted on the right. In Fig. 3(b), two images (on the left and on the right) share partially the same contents—a DVD jacket; yet the point of view, the lighting environment, and the quantity of noise are different. Despite these differences, the “meaningful” level lines extracted from both images are very similar; the lines are depicted on the middle, the colors expressing the depth in their respective tree of shapes. In the grain filter example, depicted on the top-left part in Fig. 4, we can see that both bright and dark objects tiny are filtering out at the same time, thus illustrating the self-dual property, Eq. 9, of the ToS structure.
2.4 Some Applications of the Tree of Shapes
The tree of shapes is a versatile tool to perform image filtering [17], and a very relevant structure to perform some pattern recognition and computer vision tasks [2, 7]. For illustration purpose, Fig. 4 shows that many applications can be derived from manipulating—or just using—the tree of shapes.

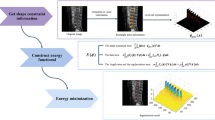
Scheme of our method.
3 Method Description
In the IVDM3Seg challenge, for each patient we have four aligned high-resolution 3D volumes: in-phase, opposed-phase, fat and water images. We only use the three last modalities, abbreviated in the following opp, fat, and wat respectively.
Our method has four main steps, illustrated in Fig. 5:
-
Step 1: obtain some prior knowledge about IVDs localization, i.e., get a 2D region of interest (ROI) for each IVD;
-
Step 2: prepare a 3D “input” volume from the volumes corresponding to the 3 modalities;
-
Step 3: identify shapes that correspond to IVDs in the set of “input” slices, using the ROIs as localization constraints;
-
Step 4: regularize the output in 3D.
These steps are described in the next four sections.

Step 1: obtaining localization prior knowledge.
3.1 Obtaining Prior Knowledge About IVDs Localization
The first step of the method aims at getting a gross estimation of the IVDs in 3D which will be refined later. At this stage, we do not need a precision at pixel level, only the bounding box of the IVDs.
Image Preprocessing. The method works with the opp volume only. In slices which reveal the IVDs the most, IVDs appear as bright oriented blobs which are at least 7-pixels high. Thus, for each slice, a top-hat (as described in Sect. 2.2) with a flat vertical structuring element of size \(15 \times 1\) allows filtering out the background and highlights the IVDs. Then, the slices are summed up (similar to an Average Intensity Projection along the z-azis) to produce a consensus image. The projection serves as a Temporal Noise Reduction to reduce noisy structures that could have passed the top-hat filtering in some frames. Figure 6(b) shows the result of the preprocessing of a volume whose slices are shown in Fig. 6(a).
IVD Selection. The method computes the Tree of Shapes (ToS) on the preprocessed image. The latter enables a hierarchical representation of the inclusion of the hole-filled connected components of the image. The tree is then filtered by some prior-knowledge-based basic criteria:
-
bounding box size and position of the shape
-
position of the center of the shape
-
orientation of the shape
-
height of the shape
-
average gray level of the shape.
Only about 20 maximal (i.e., not included in any other shape) shapes \(S_i\) are able to pass these requirements but have non-regular contours. To overcome this problem, we then look for the sub-shapes \(S_i^*\) the most compact (i.e., maximizing the ratio of the surface over the enclosing oriented rectangle surface) included in the maximal shapes \(S_i\).
From this set of candidates, we then need to select only 7 of them—because exactly 7 IVDs are expected for the challenge. The candidates are sorted by decreasing average gray value (remind that IVDs appear very bright in the preprocessed image). The brightest shape serves as a reference and is augmented with shapes taken from \(S_i^*\) satisfying some relative positioning constraints:
-
the y-distance between the shape center and the current bounding box is between 15 and 45 pixels
-
the x-distance between the shape center and top/bottom selected shapes is below 15 pixels.
Figure 6(e) and (f) illustrate the 7 maximal and regular shapes retained by our shape selection algorithm. From these shapes, we extract the 7 Region of Interests (ROI) as the bounding boxes of the selected shapes. These ROIs and shape center will be used as markers in Step 3.

Step 2: creation of a 3D volume from three different modalities.
3.2 Preparing a 3D “input” Volume
The previously detected seeds are used to guide the search in the 2D slices. We are now going to work on an image combining the opp, fat and wat modalities, as IVDs contours may be spread among these images. To that aim, the top-hat filtering is used to enhance the contrast of IVDs. The combination of the 3 volumes is given by:
and is illustrated in Fig. 7.
3.3 Identifying Shapes of IVDs in 2D Slices
This step is very similar to the IDV Selection process of Step 2 described in Sect. 3.1. A ToS is computed on each slice of the 3D input volume. In each ROI of the IVDs localized previously, we look for the best regular shape passing some basic geometric criteria (min/max size, bounding box, minimum intensity...). Note that for an IVD ROI, there may not exist such shape, as some IVDs might not be visible in some slices.
3.4 3D Regularization
Z-axis Regularization: In some slices, when no shape can be found for a given IVD, it may be normal but also might be a missed detection. If a pixel (x, y) is labeled at \(z=k-1\) and \(z=k+1\), but not at slice \(z=k\), it is likely a miss-detection. As a consequence, the regularization applies:
3D Shape Regularization: In each 2D slice, shapes are quite regular because of the shape selection algorithm that favors regular contours. On the contrary, back in 3D, the concatenation of 2D results has no 3D coherence. To tackle this problem, a structural opening followed by a structural closing with a small 3D ball allows to remove contour irregularities.

Quantitative results on the challenge data sets.
Isolated Pixels Removal: While the z-axis regularization tackles the missed-detection problem, false-detections may appear due to some natural noise (especially at the beginning and the end of the sequence). These shapes are generally disconnected in 3D from the real IVDs. Thus, as a final step, we perform a 3D connected component labeling and only retain the 7 largest ones.
Step 4 in Fig. 5 illustrates the 3D regularization of the shapes performed by our method.
4 Results
First we have run our method on the 16 cases of the challenge training set. We can observe in Fig. 8(a) that the average Dice value of 0.881 is good, with a very low standard deviation. On the 8 cases of the test set, the different rows in Fig. 8(b), we miss some IVDs (which is symbolized by “—” in the table). Since we do not have access to the data of the test set, we cannot figure out what makes our method fail for these few IVDs. Yet, for the ones we segment, the Dice values are satisfactory, with an overall average Dice of 0.816. Last, some qualitative results, compared to the reference images provided by the challenge organizers, are depicted in Fig. 9.

Some qualitative results on selected slices, respectively taken from training samples #6 (top), #14 (middle), and #16 (bottom).
5 Conclusion
We have presented a mathematical morpholology-based of the IVD segmentation problem. This method which is a machine-learning free, only relies on a chain of some simple morphological processing blocks. Despite being a learning-free approach, we have shown that it is able to compete with new CNN-based methods (but still perform worst when looking at the metrics only). On the other hand, the strength of our method lies in its speed. Only few seconds are required to process a whole volume with a single-threaded desktop processor, where CNN-based methods would be several order of magnitude slower. Yet, our implementation does not take benefit neither from a straightforward parallelization of the 2D slices processing, nor from parallel implementations of the tree of shapes [6, 11].
Notes
- 1.
Site of the challenge: https://ivdm3seg.weebly.com/.
- 2.
Topological reminder: In 2D, the cavity-fill-in operator is also called hole filling; in 3D, a cavity is just like a bubble within a sphere (whereas a hole is like a tunnel going through a sphere).
- 3.
References
Ben Ayed, I., Punithakumar, K., Garvin, G., Romano, W., Li, S.: Graph cuts with invariant object-interaction priors: application to intervertebral disc segmentation. In: Székely, G., Hahn, H.K. (eds.) IPMI 2011. LNCS, vol. 6801, pp. 221–232. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22092-0_19
Cao, F., Lisani, J.L., Morel, J.M., Musé, P., Sur, F.: A Theory of Shape Identification. LNM, vol. 1948. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-68481-7
Carlinet, E., Géraud, T.: A comparative review of component tree computation algorithms. IEEE Trans. Image Process. 23(9), 3885–3895 (2014)
Carlinet, E., Géraud, T.: Morphological object picking based on the color tree of shapes. In: Proceedings of the 5th International Conference on Image Processing Theory, Tools and Applications (IPTA), Orléans, France, pp. 125–130, November 2015
Carlinet, E., Géraud, T.: MToS: a tree of shapes for multivariate images. IEEE Trans. Image Process. 24(12), 5330–5342 (2015)
Carlinet, E., Géraud, T., Crozet, S.: The tree of shapes turned into a max-tree: a simple and efficient linear algorithm. In: Proceedings of the 24th IEEE International Conference on Image Processing (ICIP), Athens, Greece, pp. 1488–1492, October 2018
Caselles, V., Coll, B., Morel, J.M.: Topographic maps and local contrast changes in natural images. Int. J. Comput. Vis. 33(1), 5–27 (1999)
Caselles, V., Monasse, P.: Grain filters. J. Math. Imaging Vis. 17(3), 249–270 (2002)
Caselles, V., Monasse, P.: Geometric Description of Images as Topographic Maps. LNM, vol. 1984. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-04611-7
Chen, C., et al.: Localization and segmentation of 3D intervertebral discs in MR images by data driven estimation. IEEE Trans. Med. Imaging 34(8), 1719–1729 (2015)
Crozet, S., Géraud, T.: A first parallel algorithm to compute the morphological tree of shapes of \(n\)D images. In: Proceedings of the 21st IEEE International Conference on Image Processing (ICIP), Paris, France, pp. 2933–2937 (2014)
Géraud, T., Carlinet, E., Crozet, S., Najman, L.: A quasi-linear algorithm to compute the tree of shapes of nD images. In: Hendriks, C.L.L., Borgefors, G., Strand, R. (eds.) ISMM 2013. LNCS, vol. 7883, pp. 98–110. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38294-9_9
Monasse, P., Guichard, F.: Fast computation of a contrast-invariant image representation. IEEE Trans. Image Process. 9(5), 860–872 (2000)
Neubert, A., Fripp, J., Engstrom, C., Walker, D., Weber, M.: Three-dimensional morphological and signal intensity features for detection of intervertebral disc degeneration from magnetic resonance images. J. Am. Med. Inform. Assoc. 20(6), 1082–1090 (2013)
Stern, D., Likar, B., Pernus, F., Vrtovec, T.: Automated detection of spinal centrelines, vertebral bodies and intervertebral discs in CT and MR images of lumbar spine. Phys. Med. Biol. 55(1), 247–264 (2010)
Xu, Y., Carlinet, E., Géraud, T., Najman, L.: Hierarchical segmentation using tree-based shape spaces. IEEE Trans. Pattern Anal. Mach. Intell. 39(3), 457–469 (2017)
Xu, Y., Géraud, T., Najman, L.: Connected filtering on tree-based shape-spaces. IEEE Trans. Pattern Anal. Mach. Intell. 38(6), 1126–1140 (2016)
Xu, Y., Géraud, T., Najman, L.: Hierarchical image simplification and segmentation based on Mumford-Shah-salient level line selection. Pattern Recogn. Lett. 83(3), 278–286 (2016)
Xu, Y., Monasse, P., Géraud, T., Najman, L.: Tree-based morse regions: a topological approach to local feature detection. IEEE Trans. Image Process. 23(12), 5612–5625 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Carlinet, E., Géraud, T. (2019). Intervertebral Disc Segmentation Using Mathematical Morphology—A CNN-Free Approach. In: Zheng, G., Belavy, D., Cai, Y., Li, S. (eds) Computational Methods and Clinical Applications for Spine Imaging. CSI 2018. Lecture Notes in Computer Science(), vol 11397. Springer, Cham. https://doi.org/10.1007/978-3-030-13736-6_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-13736-6_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-13735-9
Online ISBN: 978-3-030-13736-6
eBook Packages: Computer ScienceComputer Science (R0)