
Abstract
In recent years, deep learning methods have been successfully applied to single-image super-resolution tasks. Despite their great performances, deep learning methods cannot be easily applied to real-world applications due to the requirement of heavy computation. In this paper, we address this issue by proposing an accurate and lightweight deep network for image super-resolution. In detail, we design an architecture that implements a cascading mechanism upon a residual network. We also present variant models of the proposed cascading residual network to further improve efficiency. Our extensive experiments show that even with much fewer parameters and operations, our models achieve performance comparable to that of state-of-the-art methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Super-resolution (SR) is a computer vision task that reconstructs a high-resolution (HR) image from a low-resolution (LR) image. Specifically, we are concerned with single image super-resolution (SISR), which performs SR using a single LR image. SISR is generally difficult to achieve due to the fact that computing the HR image from an LR image is a many-to-one mapping. Despite such difficulty, SISR is a very active area because it can offer the promise of overcoming resolution limitations, and could be used in a variety of applications such as video streaming or surveillance system.

Super-resolution result of our methods compared with existing methods.
Recently, convolutional neural network-based (CNN-based) methods have provided outstanding performance in SISR tasks [6, 19, 23]. From the SRCNN [6] that has three convolutional layers to MDSR [25] that has more than 160 layers, the depth of the network and the overall performance have dramatically grown over time. However, even though deep learning methods increase the quality of the SR images, they are not suitable for real-world scenarios. From this point of view, it is important to design lightweight deep learning models that are practical for real-world applications. One way to build a lean model is reducing the number of parameters. There are many ways to achieve this [11, 18], but the most simple and effective approach is to use a recursive network. For example, DRCN [20] uses a recursive network to reduce redundant parameters, and DRRN [34] improves DRCN by adding a residual architecture to it. These models decrease the number of model parameters effectively when compared to the standard CNN and show good performance. However, there are two downsides to these models: (1) They first upsample the input image before feeding it to the CNN model, and (2) they increase the depth or the width of the network to compensate for the loss due to using a recursive network. These points enable the model to maintain the details of the image when reconstructed, but at the expense of the increased number of operations and inference time.
Most of the works that aim to build a lean model focused primarily on reducing the number of parameters. However, as mentioned above, the number of operations is also an important factor to consider in real-world scenarios. Consider a situation where an SR system operates on a mobile device. Then, the execution speed of the system is also of crucial importance from a user-experience perspective. Especially the battery capacity, which is heavily dependent on the amount of computation performed, becomes a major problem. In this respect, reducing the number of operations in the deep learning architectures is a challenging and necessary step that has largely been ignored until now. Another scenario relates to applying SR methods to video streaming services. The demand for streaming media has skyrocketed and hence requires large storage to store massive multimedia data. It is therefore imperative to compress data using lossy compression techniques before storing. Then, an SR technique can be applied to restore the data to the original resolution. However, because latency is the most critical factor in streaming services, the decompression process (i.e., super-resolution) has to be performed in real-time. To do so, it is essential to make the SR methods lightweight in terms of the number of operations.
To handle these requirements and improve the recent models, we propose a Cascading residual network (CARN) and its variant CARN-Mobile (CARN-M). We first build our CARN model to increase the performance and extend it to CARN-M to optimize it for speed and the number of operations. Following the FSRCNN [7], CARN family take the LR images and compute the HR counterparts as the output of the network. The middle parts of our models are designed based on the ResNet [13]. The ResNet architecture has been widely used in deep learning-based SR methods [25, 34] because of the ease of training and superior performance. In addition to the ResNet architecture, CARN uses a cascading mechanism at both the local and the global level to incorporate the features from multiple layers. This has the effect of reflecting various levels of input representations in order to receive more information. In addition to the CARN model, we also provide the CARN-M model that allows the designer to tune the trade-off between the performance and the heaviness of the model. It does so by means of the efficient residual block (residual-E) and recursive network architecture, which we describe in more detail in Sect. 3.
In summary, our main contributions are as follows: (1) We propose CARN, a neural network based on the cascading modules, which achieves high performance on SR task (Fig. 1). Our cascading modules, effectively boost the performance via multi-level representation and multiple shortcut connections. (2) We also propose CARN-M for efficient SR by combining the efficient residual block and the recursive network scheme. (3) We show through extensive experiments, that our model uses only a modest number of operations and parameters to achieve competitive results. Our CARN-M, which is the more lightweight SR model, shows comparable results to others with much fewer operations.
2 Related Work
Since the success of AlexNet [22] in image recognition task [5], many deep learning approaches have been applied to diverse computer vision tasks [9, 26, 29, 39]. The SISR task is one such task, and we present an overview of the deep learning-based SISR in Sect. 2.1. Another area we deal with in this paper is model compression. Recent deep learning models focus on squeezing model parameters and operations for application in low-power computing devices, which has many practical benefits in real-world applications. We briefly review in Sect. 2.2.
2.1 Deep Learning Based Image Super-Resolution
Recently, deep learning based models have shown dramatic improvements in the SISR task. Dong et al. [6] first proposed a deep learning-based SR method, SRCNN, which outperformed traditional algorithms. However, SRCNN has a large number of operations compared to its depth, since network takes upsampled images as input. Taking a different approach from SRCNN, FSRCNN [7] and ESPCN [32] upsample images at the end of the networks. By doing so, it leads to the reduction in the number of operations compared to the SRCNN. However, the overall performance could be degraded if there are not enough layers after the upsampling process. Moreover, they cannot manage multi-scale training, as the input image size differs for each upsampling scale.
Despite the fact that the power of deep learning comes from deep layers, the aforementioned methods have settled for shallow layers because of the difficulty in training. To better harness the depth of deep learning models, Kim et al. [19] proposed VDSR, which uses residual learning to map the LR images \(\mathbf x \) to their residual images \(\mathbf r \). Then, VDSR produces the SR images \(\mathbf y \) by adding the residual back into the original, i.e., \(\mathbf {y = x + r}\). On the other hand, LapSRN [23] uses a Laplacian pyramid architecture to increase the image size gradually. By doing so, LapSRN effectively performs SR on extremely low-resolution cases with a fewer number of operations compared to VDSR.
Another issue of deep learning-based SR is how to reduce the parameters and operation. For example, DRCN [20] uses a recursive network to reduce parameters by engaging in redundant usages of a small number of parameters. DRRN [34] improves DRCN by combining the recursive and residual network schemes to achieve better performance with fewer parameters. However, DRCN and DRRN use very deep networks to compensate for the loss of performance and hence these require heavy computing resources. Hence, we aim to build a model that is lightweight in both size and computation. We will briefly discuss previous works that address such model efficiency issues in the following section.

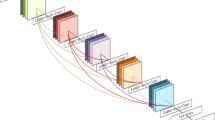
Network architectures of plain ResNet (top) and the proposed CARN (bottom). Both models are given an LR image and upsample to HR at the end of the network. In the CARN model, each residual block is changed to a cascading block. The blue arrows indicate the global cascading connection. (Color figure online)
2.2 Efficient Neural Network
There has been rising interest in building small and efficient neural networks [11, 15, 18]. These approaches can be categorized into two groups: (1) Compressing pretrained networks, and (2) designing small but efficient models. Han et al. [11] proposed deep compressing techniques, which consist of pruning, vector quantization, and Huffman coding to reduce the size of a pretrained network. In the latter category, SqueezeNet [18] builds an AlexNet-based architecture and achieves comparable performance level with 50\(\times \) fewer parameters. MobileNet [15] builds an efficient network by applying depthwise separable convolution introduced in Sifre et al. [33]. Because of this simplicity, we also apply this technique in the residual block with some modification to achieve a lean neural network.
3 Proposed Method
As mentioned in Sect. 1, we propose two main models: CARN and CARN-M. CARN is designed to be a high-performing SR model while suppressing the number of operations compared to the state-of-the-art methods. Based on CARN, we design CARN-M, which is a much more efficient SR model in terms of both parameters and operations.
3.1 Cascading Residual Network
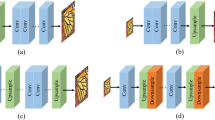
Our CARN model is based on ResNet [13]. The main difference between CARN and ResNet is the presence of local and global cascading modules. Figure 2(b) graphically depicts how the global cascading occurs. The outputs of intermediary layers are cascaded into the higher layers, and finally converge on a single 1\(\,\times \,\)1 convolution layer. Note that the intermediary layers are implemented as cascading blocks, which host local cascading connections themselves. Such local cascading operations are shown in Fig. 2(c) and (d). Local cascading is almost identical to a global one, except that the unit blocks are plain residual blocks.

Simplified structures of (a) residual block (b) efficient residual block (residual-E), (c) cascading block and (d) recursive cascading block. The  operations in (a) and (b) are element-wise addition for residual learning.
operations in (a) and (b) are element-wise addition for residual learning.
To express the implementation formally, let f be a convolution function and \(\tau \) be an activation function. Then, we can define the i-th residual block \(R_i\), which has two convolutions followed by a residual addition, as
Here, \(H^i\) is the output of the i-th residual block, \(W_R^i\) is the parameter set of the residual block, and \(W_R^{i,j}\) is the parameter of the j-th convolution layer in the i-th block. With this notation, we denote the output feature of the final residual block of ResNet as \(H^u\), which becomes the input to the upsampling block.
Note that because our model has a single convolution layer before each residual block, the first residual block gets \(f(\varvec{X}; W_c)\) as input, where \(W_c\) is the parameter of the convolution layer.
In contrast to ResNet, our CARN model has a local cascading block illustrated in block (c) of Fig. 3 instead of a plain residual block. In here, we denote \(B^{i, j}\) as the output of the j-th residual block in the i-th cascading block, and \(W_c^i\) as the set of parameters of the i-th local cascading block. Then, the i-th local cascading block \(B_{local}^{i}\) is defined as
where \(B^{i,U}\) is defined recursively from the \(B^{i,u}\)’s as:
Finally, we can define the output feature of the final cascading block \(H^b\) by combining both the local and global cascading. Here, \(H^0\) is the output of the first convolution layer. And we fix \(u=b=3\) for our CARN and CARN-M.

The main difference between CARN and ResNet lies in the cascading mechanism. As shown in Fig. 2, CARN has global cascading connections represented as the blue arrows, each of which is followed by a 1 \(\times \) 1 convolution layer. Cascading on both the local and global levels has two advantages: (1) The model incorporates features from multiple layers, which allows learning multi-level representations. (2) Multi-level cascading connection behaves as multi-level shortcut connections that quickly propagate information from lower to higher layers (and vice-versa, in case of back-propagation).
CARN adopts a multi-level representation scheme as in [24, 27], but we apply this arrangement to a variety of feature levels to boost performance, as shown in Eq. 4. By doing so, our model reconstructs the LR image based on multi-level features. This facilitates the model to restore the details and contexts of the image simultaneously. As a result, our models effectively improve not only primitive objects but also complex objects.
Another reason for adopting the cascading scheme is two-fold: First, the propagation of information follows multiple paths [16, 31]. Second, by adding extra convolution layers, our model can learn to choose the right pathway with the given input information flows. However, the strength of multiple shortcuts is degraded when we use only one of local or global cascading, especially the local connection. We elaborate the details and present a case study on the effects of cascading mechanism in Sect. 4.4.
3.2 Efficient Cascading Residual Network
To improve the efficiency of CARN, we propose an efficient residual (residual-E) block. We use a similar approach to the MobileNet [15], but use group convolution instead of depthwise convolution. Our residual-E block consists of two 3 \(\times \) 3 group and one pointwise convolution, as shown in Fig. 3(b). The advantage of using group convolution over the depthwise convolution is that it makes the efficiency of the model tunable. The user can choose the group size appropriately since the group size and performance are in a trade-off relationship. The analysis on the cost efficiency of using the residual-E block is as follows.
Let K be the kernel size and \(C_{in}, C_{out}\) be the number of input and output channels. Because we retain the feature resolution of the input and output by padding, we can denote F to be both the input and output feature size. Then, the cost of a plain residual block is as \(2\times \left( K \cdot K \cdot C_{in} \cdot C_{out} \cdot F \cdot F\right) \). Note that we only count the cost of convolution layers and ignore the addition or activation because both the plain and the efficient residual blocks have the same amount of cost in terms of addition and activation.
Let G be the group size. Then, the cost of a residual-E block, which consist of two group convolutions and one pointwise convolution, is as given in Eq. 5.
By changing the plain residual block to our efficient residual block, we can reduce the computation by the ratio of
Because our model uses a kernel of size 3 \(\times \) 3 for all group convolutions, and the number of channels is constantly 64, using an efficient residual block instead of a standard residual block can reduce the computation from 1.8 up to 14 times depending on the group size. To find the best trade-off between performance and computation, we performed an extensive case study in Sect. 4.4.
To further reduce the parameters, we apply a technique similar to the one used by the recursive network. That is, we make the parameters of the Cascading blocks shared, effectively making the blocks recursive. Figure 3(d) shows our block after applying the recursive scheme. This approach reduces the parameters by up to three times of their original number.
3.3 Comparison to Recent Models
Comparison to SRDenseNet. SRDenseNet [36] uses dense block and skip connection. The differences from our model are: (1) We use global cascading, which is more general than the skip connection. In SRDenseNet, all levels of features are combined at the end of the final dense block, but our global cascading scheme connects all blocks, which behaves as multi-level skip connection. (2) SRDenseNet preserves local information of dense block via concatenation operations, while we gather it progressively by 1 \(\times \) 1 convolution layers. The use of additional 1 \(\times \) 1 convolution layers results in a higher representation power.
Comparison to MemNet. The motivation of MemNet [35] and ours is similar. However, there are two main differences from our mechanism. (1) Inside of the memory blocks of MemNet, the output features of each recursive units are concatenated at the end of the network and then fused with 1 \(\times \) 1 convolution. On the other hand, we fuse the features at every possible point in the local block, which can boost up the representation power via the additional convolution layers and nonlinearity. In general, this representation power is often not met because of the difficulty of training. However, we overcome this problem by using both local and global cascading mechanisms. We will discuss the details on Sect. 4.4. (2) MemNet takes upsampled images as input so the number of multi-adds is larger than ours. The input to our model is a LR image and we upsample it at the end of the network in order to achieve computational efficiency.
4 Experimental Results
4.1 Datasets
There exist diverse single image super-resolution datasets, but the most widely used ones are the 291 image set by Yang et al. [38] and the Berkeley Segmentation Dataset [2]. However, because these two do not have sufficient images for training a deep neural network, we additionally use the DIV2K dataset [1]. The DIV2K dataset is a newly-proposed high-quality image dataset, which consists of 800 training images, 100 validation images, and 100 test images. Because of the richness of this dataset, recent SR models [4, 8, 25, 30] use DIV2K as well. We use the standard benchmark datasets such as Set5 [3], Set14 [38], B100 [28] and Urban100 [17] for testing and benchmarking.
4.2 Implementation and Training Details
We use the RGB input patches of size 64 \(\times \) 64 from the LR images for training. We sample the LR patches randomly and augment them with random horizontal flips and \(90^{\circ }\) rotation. We train our models with the ADAM optimizer [21] by setting \(\beta _{1} = 0.9\), \(\beta _{2} = 0.999\), and \(\epsilon = 10^{-8}\) in \(6 \times 10^5\) steps. The minibatch size is 64, and the learning rate begins with \(10^{-4}\) and is halved every \(4 \times 10^5\) steps. All the weights and biases are initialized by \(\theta \sim U(-k,\ k)\) with \(k = 1/\sqrt{c_{in}}\) where, \(c_{in}\) is the number of channels of input feature map.
The most well-known and effective weight initialization methods are given by Glorot et al. [10] and He et al. [12]. However, such initialization routines tend to set the weights of our multiple narrow 1 \(\times \) 1 convolution layers very high, resulting in an unstable training. Therefore, we sample the initial values from a uniform distribution to alleviate the initialization problem.

Trade-off between performance vs. number of operations and parameters on Set14 \(\times \)4 dataset. The x-axis and the y-axis denote the Multi-Adds and PSNR, and the size of the circle represents the number of parameters. The Mult-Adds is computed by assuming that the resolution of HR image is 720p.
To train our model in a multi-scale manner, we first set the scaling factor to one of \(\times \)2, \(\times \)3, and \(\times \)4 because our model can only process a single scale for each batch. Then, we construct and argument our input batch, as described above. We use the L1 loss as our loss function instead of the L2. The L2 loss is widely used in the image restoration task due to its relationship with the peak signal-to-noise ratio (PSNR). However, in our experiments, L1 provides better convergence and performance. The downside of the L1 loss is that the convergence speed is relatively slower than that of L2 without the residual block. However, this drawback could be mitigated by using a ResNet style model.
4.3 Comparison with State-of-the-Art Methods
We compare the proposed CARN and CARN-M with state-of-the-art SR methods on two commonly-used image quality metrics: PSNR and the structural similarity index (SSIM) [37]. One thing to note here is that we represent the number of operations by Mult-Adds. Mult-Adds is the number of composite multiply-accumulate operations for a single image. We assume the HR image size to be 720p (1280 \(\times \) 720) to calculate Multi-Adds. In Fig. 4, we compare our CARN family against the various benchmark algorithms in terms of the Mult-Adds and the number of the parameters on the Set14 \(\times \)4 dataset. Here, our CARN model outperforms all state-of-the-art models that have less than 5M parameters. Especially, CARN has the similar number of parameters to that of DRCN [20], SelNet [4] and SRDenseNet [36], but we outperform all three models. The MDSR [25] achieves better performance than ours, which is not surprising because MDSR has 8M parameters which are nearly six times more parameters than ours. The CARN-M model also outperforms most of the benchmark methods and shows comparable results against the heavy models.
Moreover, our models are most efficient in terms of the computation cost: CARN shows second best results with 90.9G Mult-Adds, which is on par with SelNet [4]. This efficiency mainly comes from the late-upsample approach that many recent models [7, 23, 36] used. In addition, our novel cascading mechanism shows increased performance compared to the models with the same manner. For example, CARN outperforms SelNet by a margin of 0.11 PSNR using almost identical computation resources. Also, the CARN-M model obtains comparable results against computationally-expensive models, while only requiring the similar number of the operations with respect to SRCNN.
Table 1 also shows the quantitative comparisons of the performances over the benchmark datasets. Note that MDSR is excluded from this table, because we only compare models that have roughly similar number of parameters as ours; MDSR has a parameter set whose size is four times larger than that of the second-largest model. Our CARN exceeds all the previous methods on numerous benchmark dataset. CARN-M model achieves comparable results using very few operations. We would also like to emphasize that although CARN-M has more parameters than SRCNN or DRRN, it is tolerable in real-world scenarios. The sizes of SRCNN and CARN-M are 200 KB and 1.6 MB, respectively, all of which are acceptable on recent mobile devices.
To make our models even more lightweight, we apply the multi-scale learning approach. The benefit of using multi-scale learning is that it can process multiple scales using a single trained model. This helps us alleviate the burden of heavy-weight model size when deploying the SR application on mobile devices; CARN(-M) only needs a single fixed model for multiple scales, whereas even the state-of-the-art algorithms require to train separate models for each supported scale. This property is well-suited for real-world products because the size of the applications has to be fixed while the scale of given LR images could vary. Using the multi-scale learning to our models increases the number of parameters, since the network has to contain possible upsampling layers. On the other hand, VDSR and DRRN do not require this extra burden, even if multi-scale learning is performed, because they upsample the image before processing it.
In Fig. 6, we visually illustrate the qualitative comparisons over three datasets (Set14, B100 and Urban100) for \(\times \)4 scale. It can be seen that our model works better than others and accurately reconstructs not only stripes and line patterns, but also complex objects such as hand and street lamps.
4.4 Model Analysis
To further investigate the performance behavior of the proposed methods, we analyze our models via ablation study. First, we show how local and global cascading modules affect the performance of CARN. Next, we analyze the trade-off between performance vs. parameters and operations.
Cascading Modules. Table 2 presents the ablation study on the effect of local and global cascading modules. In this table, the baseline is ResNet, CARN-NL is CARN without local cascading and CARN-NG is CARN without global cascading. The network topologies are all same, but because of the 1 \(\times \) 1 convolution layer, the overall number of parameters is increased by up to 10%.
We see that the model with only global cascading (CARN-NL) shows better performance than the baseline because the global cascading mechanism effectively carries mid- to high-level frequency signals from shallow to deep layers. Furthermore, by gathering all features before the upsampling layers, the model can better leverage multi-level representations. By incorporating multi-level representations, the CARN model can consider a variety of information from many different receptive fields when reconstructing the image.
Somewhat surprisingly, using only local cascading blocks (CARN-NG) harms the performance. As discussed in He et al. [14], multiplicative manipulations such as 1 \(\times \) 1 convolution on the shortcut connection can hamper information propagation, and thus lead to complications during optimization. Similarly, cascading connections in the local cascading blocks of CARN-NG behave as shortcut connections inside the residual blocks. Because these connections consist of concatenation and 1 \(\times \) 1 convolutions, it is natural to expect performance degradation. That is, the advantage of multi-level representation is limited to the inside of each local cascading block. Therefore, there appears to be no benefit of using the cascading connection because of the increased number of multiplication operations in the cascading connection. However, CARN uses both local and global cascading levels and outperforms all three models. This is because the global cascading mechanism eases the information propagation issues that CARN-NG suffers from. In detail, information propagates globally via global cascading, and information flows in the local cascading blocks are fused with the ones that come through global connections. By doing so, information is transmitted by multiple shortcuts and thus mitigates the vanishing gradient problem. In other words, the advantage of multi-level representation is leveraged by the global cascading connections, which help the information to propagate to higher layers.
Efficiency Trade-Off. Figure 5 depicts the trade-off study of PSNR vs. parameters, and PSNR vs. operations in relation to the efficient residual block and recursive network. In this experiment, we evaluate all possible group sizes of the efficient residual block for both the recursive and non-recursive cases. In both graphs, the blue line represents the model that does not use the recursive scheme and the orange line is the model that uses recursive cascading block.

Results of using efficient residual block and recursive network in terms of PSNR vs. parameters (left) and PSNR vs. operations (right). We evaluate all models on Set14 with \(\times \)4 scale. GConv represents the group size of group convolution and R means the model with the recursive network scheme (i.e., G4R represents group four with recursive cascading blocks). (Color figure online)
Although all efficient models perform worse than the CARN, which shows 28.70 PSNR, the number of parameters and operations are decreased dramatically. For example, the G64 shows a five-times reduction in both parameters and operations. However, unlike the comparable result that is shown in Howard et al. [15], the degradation of performance is more pronounced in our case.
Next, we observe the case which uses the recursive scheme. As illustrated in Fig. 5b, there is no change in the Mult-Adds but the performance worsens, which seems reasonable given the decreased number of parameters in the recursive scheme. On the other hand, Fig. 5a shows that using the recursive scheme makes the model achieve better performance with fewer parameters. Based on these observations, we decide to choose the group size as four in the efficient residual block and use the recursive network scheme as our CARN-M model. By doing so, CARN-M reduces the number of parameters by five times and the number of operations by nearly four times with a loss of 0.29 PSNR compared to CARN.

Visual qualitative comparison on \(\times \)4 scale datasets.
5 Conclusion
In this work, we proposed a novel cascading network architecture that can perform SISR accurately and efficiently. The main idea behind our architecture is to add multiple cascading connections starting from each intermediary layer to the others. Such connections are made on both the local (block-wise) and global (layer-wise) levels, which allows for the efficient flow of information and gradient. Our experiments show that employing both types of connections greatly outperforms those using only one or none at all.
We wish to further develop this work by applying our technique to video data. Many streaming services require large storage to provide high-quality videos. In conjunction with our approach, one may devise a service that stores low-quality videos that go through our SR system to produce high-quality videos on-the-fly.
References
Agustsson, E., Timofte, R.: NTIRE 2017 challenge on single image super-resolution: dataset and study. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (2017)
Arbelaez, P., Maire, M., Fowlkes, C., Malik, J.: Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 33(5), 898–916 (2011)
Bevilacqua, M., Roumy, A., Guillemot, C., Alberi-Morel, M.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the British Machine Vision Conference (BMVC) (2012)
Choi, J.S., Kim, M.: A deep convolutional neural network with selection units for super-resolution. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (2017)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2009)
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8692, pp. 184–199. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10593-2_13
Dong, C., Loy, C.C., Tang, X.: Accelerating the super-resolution convolutional neural network. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 391–407. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_25
Fan, Y., et al.: Balanced two-stage residual networks for image super-resolution. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (2017)
Girshick, R.: Fast R-CNN. In: Proceedings of the International Conference on Computer Vision (ICCV) (2015)
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the International Conference on Artificial Intelligence and Statistics (2010)
Han, S., Mao, H., Dally, W.J.: Deep compression: compressing deep neural networks with pruning, trained quantization and Huffman coding. In: Proceedings of the International Conference on Learning Representations (ICLR) (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: surpassing human-level performance on imagenet classification. In: Proceedings of the International Conference on Computer Vision (ICCV) (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 630–645. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_38
Howard, A.G., et al.: MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
Huang, G., Liu, Z., van der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Huang, J.B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
Iandola, F.N., Han, S., Moskewicz, M.W., Ashraf, K., Dally, W.J., Keutzer, K.: SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and \(<\)0.5 MB model size. arXiv preprint arXiv:1602.07360 (2016)
Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Kim, J., Kwon Lee, J., Mu Lee, K.: Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: Proceedings of the International Conference on Learning Representations (ICLR) (2015)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proceedings of the Conference on Neural Information Processing Systems (NIPS) (2012)
Lai, W.S., Huang, J.B., Ahuja, N., Yang, M.H.: Deep Laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Lee, J., Nam, J.: Multi-level and multi-scale feature aggregation using pretrained convolutional neural networks for music auto-tagging. IEEE Signal Process. Lett. 24(8), 1208–1212 (2017)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (2017)
Liu, W., et al.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the International Conference on Computer Vision (ICCV) (2001)
Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: Proceedings of the International Conference on Computer Vision (ICCV) (2015)
Ren, H., El-Khamy, M., Lee, J.: Image super resolution based on fusing multiple convolution neural networks. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (2017)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Shi, W., et al.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Sifre, L., Mallat, S.: Rigid-motion scattering for image classification. Ph.D. thesis, Citeseer (2014)
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Tai, Y., Yang, J., Liu, X., Xu, C.: MemNet: a persistent memory network for image restoration. In: Proceedings of the International Conference on Computer Vision (ICCV) (2017)
Tong, T., Li, G., Liu, X., Gao, Q.: Image super-resolution using dense skip connections. In: Proceedings of the International Conference on Computer Vision (ICCV) (2017)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Yang, J., Wright, J., Huang, T.S., Ma, Y.: Image super-resolution via sparse representation. IEEE Trans. Image Process. 19(11), 2861–2873 (2010)
Zhang, R., Isola, P., Efros, A.A.: Colorful image colorization. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 649–666. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_40
Acknowledgement
This research was supported through the National Research Foundation of Korea (NRF) funded by the Ministry of Education: NRF-2016R1D1A1B03933875 (K.-A. Sohn) and NRF-2016R1A6A3A11932796 (B. Kang).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Ahn, N., Kang, B., Sohn, KA. (2018). Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11214. Springer, Cham. https://doi.org/10.1007/978-3-030-01249-6_16
Download citation
DOI: https://doi.org/10.1007/978-3-030-01249-6_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01248-9
Online ISBN: 978-3-030-01249-6
eBook Packages: Computer ScienceComputer Science (R0)