
Abstract
Most traditional pedestrian simulation methods suffer from short-sightedness, as they often choose the best action at the moment without considering the potential congesting situations in the future. To address this issue, we propose a hierarchical model that combines Deep Reinforcement Learning (DRL) and Optimal Reciprocal Velocity Obstacle (ORCA) algorithms to optimize the decision process of pedestrian simulation. For certain complex scenarios prone to local optimality, we include expert trajectory imitation degree in the reward function, aiming to improve pedestrian exploration efficiency by designing simple expert trajectory guidance lines without constructing databases of expert examples and collecting priori datasets. The experimental results show that the proposed method presents great stability and generalizability, evidenced by its capability to adjust the behavioral strategy earlier for the upcoming congestion situations. The overall simulation time for each scenario is reduced by approximately 8-44% compared to traditional methods. After including the expert trajectory guidance, the convergence speed of the model is greatly improved, evidenced by the reduced 56-64% simulation time from the first exploration to the global maximum cumulative reward value. The expert trajectory establishes the macro rules while preserving the space for free exploration, avoiding local dilemmas, and achieving optimized training efficiency.
















Similar content being viewed by others

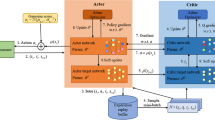
Data availability
All of the material is owned by the authors and/or no permissions are required.
References
Xu D (2021) Study on micro-scale pedestrian simulation using reinforcement learning [D]. East China Normal University. https://doi.org/10.27149/d.cnki.ghdsu.2021.000427
Du J (2020) Research on emergency evacuation modeling and path planning based on artificial bee colony algorithm [D]. Hubei University of Technology. https://doi.org/10.27131/d.cnki.ghugc.2020.000042
Helbing D, Farkas IJ, Molnar P et al (2002) Simulation of pedestrian crowds in normal and evacuation situations[J]. Pedestr Evacuation Dyn 21(2):21–58
Dijkstra J, Jessurun J, Timmermans HJP (2001) A multi-agent cellular automata model of pedestrian movement[J]. Pedestr Evacuation Dyn 173:173–180
Helbing D (1998) A fluid dynamic model for the movement of pedestrians[J]. arXiv preprint cond-mat/9805213
Wu Z, Liu D, Cheng Y, Sun Y (2012) Three-dimensional crowd simulation of agent-based method[J]. Comput Technol Dev 22(11):108–112
Zhao L, Guo M, Tang S, Tang J (2022) Adaptive crowd evacuation simulation model based on bounded rationality constraints [J/OL]. J Syst Simul: 1–9. https://doi.org/10.16182/j.issn1004731x.joss.21-0472
Shen Y, Han J, Li L et al (2020) AI in game intelligence—from multi-role game to parallel game[J]. Chin J Intell Sci Technol 2(3):205–213
Hu Y, Mottaghi R, Kolve E et al (2017) Target-driven visual navigation in indoor scenes using deep reinforcement learning[C]. 2017 IEEE international conference on robotics and automation (ICRA). Piscataway: IEEE Press, pp 3357–3364
Shani G, Heckerman D, Brafman RI et al (2005) An MDP-based recommender system[J]. J Mach Learn Res 6(9):1265–1295
Yao Z (2020) Research on simulation method of crowd evacuation based on reinforcement learning and deep residual network learning [D]. Shandong Normal University. https://doi.org/10.27280/d.cnki.gsdsu.2020.001531
Xu D, Huang X, Li Z et al (2020) Local motion simulation using deep reinforcement learning[J]. Trans GIS 24(3):756–779
Lowe R, Wu Y I, Tamar A, et al (2017) Multi-agent actor-critic for mixed cooperative-competitive environments[J]. Advances in Neural Information Processing systems. https://doi.org/10.48550/arXiv.1706.02275
Zhang F, Li J, Li ZA (2020) TD3-based multi-agent deep reinforcement learning method in mixed cooperation-competition environment[J]. Neurocomputing 411:206–215
Zhelo O, Zhang J, Tai L et al (2018) Curiosity-driven exploration for mapless navigation with deep reinforcement learning[J], arXiv: 1804.00456
Yang Y (2019) Study on crowd evacuation simulation models for semi-submersible accommodation platform [D]. Shanghai Jiao Tong University. https://doi.org/10.27307/d.cnki.gsjtu.2019.001894
Bounini F, Gingras D, Pollart H et al (2017) Modified artificial potential field method for online path planning applications[C]. 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, pp 180–185
Wu H (2017) Evacuation Simulation of indoor pedestrian [D]. University of Electronic Science and Technology of China
Ma S, Zhang R, Qi Z, Hao J (2021) Research on improvement of social force model of opposite avoidance and contact behavior [J]. Comput Simul 38(03):63–67
Guo K, Wang D, Fan T et al (2021) VR-ORCA: variable responsibility optimal reciprocal collision Avoidance[J]. IEEE Rob Autom Lett 6(3):4520–4527
He G, Jiang D, Jin Y, Chen Q, Lu X, Xu M (2018) Crowd behavior simulation based on shadow obstacle and ORCA models [J]. Sci Sin Informationis 48(03):233–247
Silver D, Huang A, Maddison CJ et al (2016) Mastering the game of go with deep neural networks and tree search[J]. Nature 529(7587):484–489
Mnih V, Kavukcuoglu K, Silver D et al (2015) Human-level control through deep reinforcement learning[J]. Nature 518(7540):529–533
Van Hasselt H, Guez A, Silver D (2016) Deep reinforcement learning with double q-learning[C]. Proceedings of the AAAI conference on artificial intelligence, 30(1)
Wang Z, Schaul T, Hessel M et al (2016) Dueling network architectures for deep reinforcement learning[C]. International conference on machine learning. PMLR, pp 1995–2003
Schaul T, Quan J, Antonoglou I et al (2015) Prioritized experience replay[J]. arXiv preprint arXiv:1511.05952
Williams RJ (1992) Simple statistical gradient-following algorithms for connectionist reinforcement learning[J]. Mach Learn 8(3):229–256
Schulman J, Levine S, Abbeel P et al (2015) Trust region policy optimization[C]. International conference on machine learning. PMLR, pp 1889–1897
Schulman J, Wolski F, Dhariwal P et al (2017) Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347
Lillicrap TP, Hunt JJ, Pritzel A et al (2015) Continuous control with deep reinforcement learning[J]. arXiv preprint arXiv:1509.02971
Fujimoto S, Hoof H, Meger D (2018) Addressing function approximation error in actor-critic methods[C]. International conference on machine learning. PMLR, pp 1587–1596
Haarnoja T, Zhou A, Abbeel P et al (2018) Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]. International conference on machine learning. PMLR, pp 1861–1870
Lee J, Won J, Lee J (2018) Crowd simulation by deep reinforcement learning[C]. Proceedings of the 11th Annual International Conference on Motion, Interaction, and Games. pp 1–7
Sharma J, Andersen PA, Granmo OC et al (2020) Deep q-learning with q-matrix transfer learning for novel fire evacuation environment[J]. IEEE Trans Syst Man Cybernet Syst 51(12):7363–7381
Lu G (2021) Regularized maximum entropy imitation learning based on prior reward of trajectory [D]. East China Normal University. https://doi.org/10.27149/d.cnki.ghdsu.2021.000029
Levine S, Kumar A, Tucker G et al (2020) Offline reinforcement learning: Tutorial, review, and perspectives on open problems[J]. arXiv preprint arXiv:2005.01643
Berg J, Guy SJ, Lin M et al (2011) Reciprocal n-body collision avoidance[M]. Robotics research. Springer, Berlin, Heidelberg, pp 3–19
Fortunato M, Azar MG, Piot B et al (2017) Noisy networks for exploration[J]. arXiv preprint arXiv:1706.10295
Gwynne S, Rosenbaum ER (2016) Employing the hydraulic model in assessing emergency movement[M]. SFPE handbook of fire protection engineering. Springer, New York, pp 2115–2151
Thunderhead Engineering (2011) Pathfinder technical reference. Thunderhead Engineering Consultants, Inc, Manhattan
Acknowledgements
We thank the editors and reviewers for their valuable comments. This work is partially supported by the projects funded by the Chongqing Natural Science Foundation (Grant Number: CSTB2022NSCQ-MSX2069) and the Ministry of Education of China (Grant Number: 19JZD023).
Author information
Authors and Affiliations
Contributions
S.M. and X.L. conceived and designed the experiments. S.M., X.H., M.W., D.Z., D.X. performed the experiments and analyzed the results. S.M., X.H., and M.W. wrote the manuscript. X.L. gave comments and suggestions on the manuscript and proofread the document. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mu, S., Huang, X., Wang, M. et al. Optimizing pedestrian simulation based on expert trajectory guidance and deep reinforcement learning. Geoinformatica 27, 709–736 (2023). https://doi.org/10.1007/s10707-023-00486-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10707-023-00486-5