
Abstract
Public investments in subway systems are often motivated by improving local air quality. Recent studies, however, have reached different conclusions on the air quality benefits of subway investment. To reconcile these findings, this paper examines the air quality effects of all 359 subway line openings in China between 2013 and 2018. The machine learning method adopted in this paper substantially improves the consistency and precision of the estimates by purging seasonality, volatility, and the nonlinear effects of meteorological conditions in air quality data. The empirical results suggest an insignificant short-term effect and a significant long-term effect, which is expected as the adjustment of commuting mode takes time. Using the causal forest approach, the heterogeneity analysis find that a city that is experiencing rapid economic growth from a lower income level and currently has fewer subway lines is more likely to experience statistically significant improvements in air quality from a subway opening. These findings help reconcile the different findings in the literature and shed light on air pollution reduction as one of the objectives of public transit investment.





Similar content being viewed by others

Notes
We report the results on other pollutants (e.g., SO2, PM10, and ozone) in the Appendix, as the literature (e.g., Cole et al. 2020; Li et al. 2019) suggests that SO2 is predominately caused by industrial emissions, and the formation of ozone is a very complicated process, in which the contribution of the emissions from commuting is not clear.
Source: www.urbanrail.net.
The calculation varies across countries. For example, when the concentration of PM2.5 is 35 µg per cubic meter, China computes the index as 50, whereas the US computes the index as 100. For more information on the calculation, refer to https://www.cnblogs.com/tiandi/p/6158576.html.
Source: Technical Regulation on Ambient Air Quality Index (GB3095-2012).
We compare the standard deviations for stations reporting hourly data and those with interpolation. For example, the standard deviation of pressure reported by stations with hourly data is 104.04, which is 1.02% of the mean. For stations with interpolations, the standard deviation is 102.97, which is 1.01% of the mean.
Grange et al. (2018) included relative humidity rather than dew point, but our meteorological dataset does not have relative humidity. Given that the dew point is a function of relative humidity and temperature, and our data include temperature, in the context of the random forest algorithm, relative humidity and dew point contain the same information.
If a city has more than one weather station, we keep the meteorological data of all weather stations for each single air pollution monitor in the same city. This increases the meteorological information available for machine learning, which improves training performance.
The number of variables that can be split at each node equals the (rounded down) square root of the number of all predictors. The minimum size of the leaf nodes is five. Grange et al. (2018) suggested that the choice of these hyperparameters does not significantly affect the training results, and the training results in this paper support this argument.
The anti-fascist parade is a celebration of the 70th anniversary of the end of World War II.
For example, coal-based heavy industry is one of the main industries of Shanxi province in China, and burning coal is a major source of local air pollution (Song et al. 2021). For such cities, the effect of subway opening is not necessarily greater than in other cities with low initial pollution levels.
Athey and Wager (2019) further improved the causal forest approach by casting forests as adaptive locally weighted estimators rather than simply averaging the treatment effect of each tree. They also slightly adjusted the splitting rule to reduce the calculation burden.
Note that in the short window of each opening, the exact opening date is assigned arbitrarily. Thus, the treatment is orthogonal to the covariates, so the unconfoundedness assumption holds.
This correlation reflects the average treatment effect because the causal forest can be viewed as a residual-on-residual regression that regresses \(predicted AQI-\widehat{predicted AQI}\) on \(open-\widehat{open}\).
We focus on PM2.5 when evaluating the economic benefit, as the literature documents the effect of PM2.5 on health and most major urban areas in China have high levels of PM2.5.
According to the official document (document number: 000013039–2013-00176) released in 2013, the investment in a subway line in Wuhan is 2.0 billion dollars, and there are 12 stations. http://zfxxgk.ndrc.gov.cn/web/iteminfo.jsp?id=12397
References
Apte JS, Messier KP, Gani S, Brauer M, Kirchstetter TW, Lunden MM, Marshall JD, Portier CJ, Vermeulen RCH, Hamburg SP (2017) High-resolution air pollution mapping with google street view cars: exploiting big data. Environ Sci Technol 51:6999–7008. https://doi.org/10.1021/acs.est.7b00891
Athey S, Imbens G (2016) Recursive partitioning for heterogeneous causal effects. Proc Natl Acad Sci 113:7353–7360. https://doi.org/10.1073/pnas.1510489113
Athey S, Wager S (2019) Estimating treatment effects with causal forests: an application. Obs Stud 5:37–51. https://doi.org/10.1353/obs.2019.0001
Athey S, Imbens G, Pham T, Wager S (2017) Estimating average treatment effects: supplementary analyses and remaining challenges. Am Econ Rev 107:278–281. https://doi.org/10.1257/aer.p20171042
Barwick PJ, Li S, Lin L, Zou E (2019) From fog to smog: the value of pollution information. Working Paper Series. https://doi.org/10.3386/w26541
Beaudoin J, Farzin YH, Lin Lawell C-YC (2015) Public transit investment and sustainable transportation: a review of studies of transit’s impact on traffic congestion and air quality. Res. Transp. Econ. Sustain Transport 52:15–22. https://doi.org/10.1016/j.retrec.2015.10.004
Beaudoin J, Lin Lawell CYC (2017) Is public transit’s ‘green’ reputation deserved? Evaluating the effects of transit supply on air quality
Bradley KS, Stedman DH, Bishop GA (1999) A global inventory of carbon monoxide emissions from motor vehicles. Chemosphere - Glob Change Sci 1:65–72. https://doi.org/10.1016/S1465-9972(99)00017-3
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Britto DGC, Pinotti P, Sampaio B (2022) The effect of job loss and unemployment insurance on crime in Brazil. Econometrica 90:1393–1423. https://doi.org/10.3982/ECTA18984
Burlig F, Knittel C, Rapson D, Reguant M, Wolfram C (2020) Machine learning from schools about energy efficiency. J Assoc Environ Resour Econ 7:1181–1217. https://doi.org/10.1086/710606
Chang T, Graff Zivin J, Gross T, Neidell M (2016) Particulate pollution and the productivity of pear packers. Am Econ J Econ Policy 8:141–169. https://doi.org/10.1257/pol.20150085
Chang YS, Lee YJ, Choi SSB (2017) Is there more traffic congestion in larger cities? -Scaling analysis of the 101 largest U.S. urban centers-. Transp Policy 59:54–63. https://doi.org/10.1016/j.tranpol.2017.07.002
Chay KY, Greenstone M (2003) The impact of air pollution on infant mortality: evidence from geographic variation in pollution shocks induced by a recession*. Q J Econ 118:1121–1167. https://doi.org/10.1162/00335530360698513
Chen Y, Whalley A (2012) Green infrastructure: the effects of urban rail transit on air quality. Am Econ J Econ Policy 4:58–97. https://doi.org/10.1257/pol.4.1.58
Cole MA, Elliott RJR, Liu B (2020) The impact of the Wuhan covid-19 lockdown on air pollution and health: a machine learning and augmented synthetic control approach. Environ Resour Econ 76:553–580. https://doi.org/10.1007/s10640-020-00483-4
Cui B, Boisjoly G, Miranda-Moreno L, El-Geneidy A (2020) Accessibility matters: exploring the determinants of public transport mode share across income groups in Canadian cities. Transp Res Part Transp Environ 80:102276. https://doi.org/10.1016/j.trd.2020.102276
Currie J, Neidell M (2005) Air pollution and infant health: what can we learn from California’s recent experience?*. Q J Econ 120:1003–1030. https://doi.org/10.1093/qje/120.3.1003
Deryugina T, Heutel G, Miller NH, Molitor D, Reif J (2019) The mortality and medical costs of air pollution: evidence from changes in wind direction. Am Econ Rev 109:4178–4219. https://doi.org/10.1257/aer.20180279
Duranton G, Turner MA (2011) The fundamental law of road congestion: evidence from US cities. Am Econ Rev 101:2616–2652. https://doi.org/10.1257/aer.101.6.2616
Fan Y, Guthrie A, Levinson D (2012) Impact of light-rail implementation on labor market accessibility: a transportation equity perspective. J Transp Land Use 5:28–39
Gendron-Carrier N, Gonzalez-Navarro M, Polloni S, Turner MA (2022) Subways and urban air pollution. Am Econ J Appl Econ 14:164–196. https://doi.org/10.1257/app.20180168
Goel D, Gupta S (2017) The effect of metro expansions on air pollution in Delhi. World Bank Econ Rev 31:271–294. https://doi.org/10.1093/wber/lhv056
Grange SK, Carslaw DC (2019) Using meteorological normalisation to detect interventions in air quality time series. Sci Total Environ 653:578–588. https://doi.org/10.1016/j.scitotenv.2018.10.344
Grange SK, Carslaw DC, Lewis AC, Boleti E, Hueglin C (2018) Random forest meteorological normalisation models for Swiss PM10 trend analysis. Atmospheric Chem Phys 18:6223–6239. https://doi.org/10.5194/acp-18-6223-2018
Greenstone M, Hanna R (2014) Environmental regulations, air and water pollution, and infant mortality in India. Am Econ Rev 104:3038–3072. https://doi.org/10.1257/aer.104.10.3038
Greenstone M, He G, Li S, Zou EY (2021) China’s war on pollution: evidence from the first 5 years. Rev Environ Econ Policy 15:281–299. https://doi.org/10.1086/715550
Greenstone M, He G, Jia R, Liu T (2022) Can technology solve the principal-agent problem? Evidence from China’s war on air pollution. Am Econ Rev Insights 4:54–70. https://doi.org/10.1257/aeri.20200373
Gu Y, Jiang C, Zhang J, Zou B (2021) Subways and road congestion. Am Econ J Appl Econ 13:83–115. https://doi.org/10.1257/app.20190024
Handel B, Kolstad J (2017) Wearable technologies and health behaviors: new data and new methods to understand population health. Am Econ Rev 107:481–485. https://doi.org/10.1257/aer.p20171085
Hang L, Tu M (2007) The impacts of energy prices on energy intensity: evidence from China. Energy Policy 35:2978–2988. https://doi.org/10.1016/j.enpol.2006.10.022
Hausman C, Rapson DS (2018) Regression discontinuity in time: considerations for empirical applications. Annu Rev Resour Econ 10:533–552. https://doi.org/10.1146/annurev-resource-121517-033306
Huang X, (Jason) Cao X, Yin J, Cao X (2019) Can metro transit reduce driving? Evidence from Xi’an China. Transp Policy 81:350–359. https://doi.org/10.1016/j.tranpol.2018.03.006
Imbens G, Kalyanaraman K (2012) Optimal bandwidth choice for the regression discontinuity estimator. Rev Econ Stud 79:933–959. https://doi.org/10.1093/restud/rdr043
Lee K, Greenstone M (2021) Air quality life index
Li W, Yin S (2012) Analysis on cost of urban rail transit. J Transp Syst Eng Inf Technol 12:9–14. https://doi.org/10.1016/S1570-6672(11)60190-6
Li S, Liu Y, Purevjav A-O, Yang L (2019) Does subway expansion improve air quality? J Environ Econ Manag 96:213–235. https://doi.org/10.1016/j.jeem.2019.05.005
Li P, Lu Y, Wang J (2020) The effects of fuel standards on air pollution: Evidence from China. J Dev Econ 146:102488. https://doi.org/10.1016/j.jdeveco.2020.102488
Lin D, Allan A, Cui J (2016) Exploring differences in commuting behaviour among various income groups during polycentric urban development in China: new evidence and its implications. Sustainability 8:1188. https://doi.org/10.3390/su8111188
Liu C, Li L (2020) How do subways affect urban passenger transport modes?—Evidence from China. Econ Transp 23:100181. https://doi.org/10.1016/j.ecotra.2020.100181
Mohring H (1972) Optimization and scale economies in urban bus transportation. Am Econ Rev 62:591–604
Newham M, Valente M (2023) The cost of influence: how gifts to physicians shape prescriptions and drug costs. https://doi.org/10.2139/ssrn.4048089
Pargal S, Wheeler D (1996) Informal regulation of industrial pollution in developing countries: evidence from Indonesia. J Polit Econ 104:1314–1327. https://doi.org/10.1086/262061
Parrish DD, Kuster WC, Shao M, Yokouchi Y, Kondo Y, Goldan PD, de Gouw JA, Koike M, Shirai T (2009) Comparison of air pollutant emissions among mega-cities. Atmos Environ 43:6435–6441. https://doi.org/10.1016/j.atmosenv.2009.06.024
Pucher J, Peng Z, Mittal N, Zhu Y, Korattyswaroopam N (2007) Urban transport trends and policies in China and India: impacts of rapid economic growth. Transp Rev 27:379–410. https://doi.org/10.1080/01441640601089988
Shen Q, Chen P, Pan H (2016) Factors affecting car ownership and mode choice in rail transit-supported suburbs of a large Chinese city. Transp Res Part Policy Pract 94:31–44. https://doi.org/10.1016/j.tra.2016.08.027
Song H, Zhuo H, Fu S, Ren L (2021) Air pollution characteristics, health risks, and source analysis in Shanxi Province China. Environ Geochem Health 43:391–405. https://doi.org/10.1007/s10653-020-00723-y
Valente M (2023) Policy evaluation of waste pricing programs using heterogeneous causal effect estimation. J Environ Econ Manag 117:102755. https://doi.org/10.1016/j.jeem.2022.102755
Verhoef KAS, Erik T (2007) The economics of urban transportation, 2nd edn. Routledge, London. https://doi.org/10.4324/9780203642306
Viard VB, Fu S (2015) The effect of Beijing’s driving restrictions on pollution and economic activity. J Public Econ 125:98–115. https://doi.org/10.1016/j.jpubeco.2015.02.003
Vickrey WS (1969) Congestion theory and transport investment. Am Econ Rev 59:251–260
Vu TV, Shi Z, Cheng J, Zhang Q, He K, Wang S, Harrison RM (2019) Assessing the impact of clean air action on air quality trends in Beijing using a machine learning technique. Atmos Chem Phys 19:11303–11314. https://doi.org/10.5194/acp-19-11303-2019
Wager S, Athey S (2018) Estimation and inference of heterogeneous treatment effects using random forests. J Am Stat Assoc 113:1228–1242. https://doi.org/10.1080/01621459.2017.1319839
Wang Y, Wen Y, Wang Y, Zhang S, Zhang KM, Zheng H, Xing J, Wu Y, Hao J (2020) Four-month changes in air quality during and after the COVID-19 lockdown in six megacities in China. Environ Sci Technol Lett 7:802–808. https://doi.org/10.1021/acs.estlett.0c00605
Wang W, Sun X, Zhang M (2021) Does the central environmental inspection effectively improve air pollution?-An empirical study of 290 prefecture-level cities in China. J Environ Manage 286:112274. https://doi.org/10.1016/j.jenvman.2021.112274
Xiao D, Li B, Cheng S (2020) The effect of subway development on air pollution: evidence from China. J Clean Prod 275:124149. https://doi.org/10.1016/j.jclepro.2020.124149
Xiao D, Li B, Li Q, An L, Cheng S (2021) The effects of subway openings on air quality: evidence from China. Environ Sci Pollut Res 28:66133–66157. https://doi.org/10.1007/s11356-021-15482-1
Xie L (2016) Automobile usage and urban rail transit expansion: evidence from a natural experiment in Beijing, China. Environ Dev Econ 21:557–580. https://doi.org/10.1017/S1355770X16000048
Zheng S, Kahn ME (2013) Understanding China’s urban pollution dynamics. J Econ Lit 51:731–772. https://doi.org/10.1257/jel.51.3.731
Zheng S, Kahn ME (2017) A new era of pollution progress in urban China? J Econ Perspect 31:71–92. https://doi.org/10.1257/jep.31.1.71
Zheng S, Kahn ME, Sun W, Luo D (2014) Incentives for China’s urban mayors to mitigate pollution externalities: the role of the central government and public environmentalism. Reg Sci Urban Econ 47:61–71. https://doi.org/10.1016/j.regsciurbeco.2013.09.003
Zheng S, Zhang X, Sun W, Wang J (2019) The effect of a new subway line on local air quality: a case study in Changsha. Transp Res Part Transp Environ Urbaniz, Transp Air Quality Develop Countr 68:26–38. https://doi.org/10.1016/j.trd.2017.10.004
Zheng M, Guo X, Liu F, Shen J (2021) Contribution of subway expansions to air quality improvement and the corresponding health implications in Nanjing, China. Int J Environ Res Public Health 18:969. https://doi.org/10.3390/ijerph18030969
Acknowledgements
Financial support from National Science Foundation of China (No. 72103220) and the Environment for Development (EfD) Initiative at the University of Gothenburg are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Consent for Publication
The manuscript is approved by all authors for publication. The work is original research that has not been published previously, nor that is under consideration for publication elsewhere.
Ethical Approval
All the authors listed have approved the manuscript that is enclosed.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Joshua Linn is a Senior Fellow at resources for the future.
Appendices
Appendix A
The Fig.

Policy Interventions and Predicted AQI. Panel a Predicted AQI in Beijing. Panel b Predicted AQI in Shanghai
6 shows the predicted AQI in Beijing and Shanghai as well as policy interventions, indicated by the vertical lines. For Beijing, the policies are,
-
(1)
Implementation of Beijing Air Pollution Prevention and Control Regulations. (2014/1/22)
-
(2)
APEC Leaders' 8th Informal Meeting (2014/11/3).
-
(3)
Anti-fascist Parades (2015/9/3).
-
(4)
Implementation of Beijing Stage 6 "Gasoline for Vehicles" (DB11/238-2016) and "Diesel for Vehicles" (DB11/239-2016) standards (2017/1/1).
-
(5)
Intensive inspection of the Blue-sky Defense Campaign (2018/6/11).
For Shanghai, the policies are:
-
(1)
Implementation of Emergency Plan for Heavy Air Quality Pollution (2013/12/1).
-
(2)
Prohibiting vehicles according to the National II standard (GB 18352.2) (2016/1/1).
-
(3)
Regional Air Pollution Prevention and Control Cooperation Group meeting held (2014/4/21).
-
(4)
National Environmental Protection Inspection (2016/11/28).
-
(5)
National Environmental Protection Inspection Review Works (huitoukan) (2018/5/31).
As an example, the first red line in Panel (a) refers to January 22, 2014, which is the date of the implementation of Beijing air pollution prevention and control regulations. The regulations set standards for air quality, as well as emission control standards and industry governance measures. These measures tend to reduce air pollution. The blue line in Panel (a) shows a rapid decline in AQI after that day. The other events reported in Fig. 6 are similar to the example. The figure indicates that air quality improved during these events and that the magnitude of the improvements varied across events. The air quality improvements that we detect help validate the model and suggest that the predicted air pollution data is sensitive to non-weather shocks (Fig.

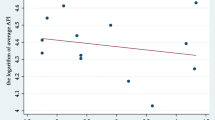
CATEs of Subway Opening on PM2.5 by the Minimum Distance between Subway and Air Pollution Monitor
7).
This figure shows how the conditional average treatment effects (CATEs) vary with the minimum distance between the subway and air pollution monitor. CATEs are estimated using causal forest algorithms (Tables
9,
10,
11,
12,
13 and
14). The outcome variable was predicted PM2.5, and the covariates are those listed in Fig. 4.
Appendix B
2.1 An Illustrative Example of Predicting the AQI
To predict the counterfactual Air Quality Index (AQI), we train a random forest model to fit air pollution with predictors, where \(\widehat{AQI}=f(meteorological, temporal,human)\).
-
1.
To calculate the expectation, we randomly assign meteorological and temporal factors and conduct counterfactual predictions using the trained model, obtaining the counterfactual AQI for each random assignment, denoted as \({\widehat{AQI}}_{random1}^{Jan 1st 2010}=f({meteorological}_{random1},{ temporal}_{random1},{human}^{Jan 1st 2010})\)
-
2.
Repeating the second step 1000 times, we obtain \({\widehat{AQI}}_{random300}^{Jan 1st 2010}=f({meteorological}_{random300},{ temporal}_{random300},{human}^{Jan 1st 2010})\). We then consider the average of the predicted outcomes, \({\overline{\widehat{AQI}} }^{Jan 1st 2010}\) as the predicted AQI. This predicted AQI is the counterfactual AQI if the meteorological and temporal factors are typical on that day.
Appendix C
3.1 Methods of Calculating Standard Errors
In the two-stage method we employ, uncertainty arises from both the prediction and regression steps, and currently, there is no established guideline for calculating standard errors in this context.
In the main text, we utilize the bootstrap method to calculate standard errors, considering only the uncertainty from the second step. Theoretically, considering the uncertainty from the first step could lead to a larger standard error. Since our baseline result indicates an insignificant effect, this conclusion remains robust even with a potentially larger standard error.
To further affirm the robustness, following the approach suggested by Burlig et al. (2020), we attempt to capture uncertainty from both steps by employing a bootstrap method. Unfortunately, we find that performing the bootstrap is not feasible. As an alternative, we opt to conduct the robustness check using the residual approach (Burlig et al. 2020).
We employ the following procedure: First, for each air quality monitor, we sample N observations with replacement (where N equals the original number of observations). We then train the random forest model using bootstrapped data and obtain the residual (\(y-\widehat{y}\)). We repeat these steps 20 times. Next, we should sample the data from step one with replacement, generate multiple subsamples, estimate treatment effects using these subsamples, and calculate the standard deviation as the bootstrapped standard error. However, the data obtained from step one is substantial, estimated at approximately 400 GB (20 GB for the baseline dataset * sampled 20 times), exceeding the computer’s available memory for processing. Therefore, we opt for an approximate estimation. In the approximation, we exclusively employ the Air Quality Index (AQI) as the dependent variable, disregarding other indices of pollutants and restricting our analysis to the subsample representing the first occurrence of a subway opening in a city. To ensure comparability, we also apply similar approximations to the cluster regressions used for comparison. The estimates and standard errors may deviate from the baseline, primarily because we use subsamples instead of the full sample, leading to a reduction in the number of observations.
As demonstrated in Table
15 we observe that the standard errors, accounting for prediction errors from the first step, are quantitatively similar (albeit slightly larger) to the standard errors that only include the uncertainty from the second step. Given our assertion of an insignificant effect in the baseline estimation, a slightly larger standard error further reinforces the robustness of our baseline results.
Considering both the theoretical analysis and the bootstrap results of the residual approach, we believe that the issue of uncertainty from the first step may not pose a significant threat to our baseline results.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xie, L., Zou, T., Linn, J. et al. Can Building Subway Systems Improve Air Quality? New Evidence from Multiple Cities and Machine Learning. Environ Resource Econ 87, 1009–1044 (2024). https://doi.org/10.1007/s10640-024-00852-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10640-024-00852-3