
Abstract
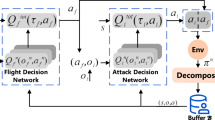
Autonomous decision-making in unmanned aerial vehicle (UVA) confrontations presents challenges in making optimal strategy. Therefore, deep reinforcement learning (DRL) has been adopted to address these issues. However, existing DRL decision-making models suffer from poor situational awareness and inability to distinguish between different intentions. Therefore, a multi-intent autonomous decision-making is proposed in this paper. First, three typical intentions are designed comprising head-on attacking, pursuing and fleeing to derive decision models representing different intentions. Reinforcement learning based air combat game model is constructed with different intentions, which contains designing reward functions for intentions to deal with the problem of sparse rewards. Then, we propose the Temporal Proximal Policy Optimization (T-PPO) algorithm, which optimizes the Proximal Policy Optimization algorithm by integrating the long short-term memory network and feedforward neural network. This algorithm extracts the historical temporal information to enhance situational awareness. In addition, a basic-confrontation progressive training method is proposed to provide intention guidance and increase training diversity, which can improve learning efficiency and intelligent decision-making capability. Finally, experiments in our constructed UAV confrontation environment demonstrate that the proposed intentional decision models exhibit good performance in stability and learning efficiency, achieving high rewards, win rates, and low steps. Specifically, our autonomous decision-making increases win rate by 26% when head-on attacking and learning efficiency by 50% when pursuing. It is further proof of the potential and value of our multi-intent autonomous decision-making applications.




















Similar content being viewed by others

Data availability and access
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
References
Jiang L, Wei R, Wang D (2023) Uavs rounding up inspired by communication multi-agent depth deterministic policy gradient. Appl Intell 53(10):11474–11489. https://doi.org/10.1007/s10489-022-03986-3
Zhao R, Wang Y, Xiao G et al (2022) A method of path planning for unmanned aerial vehicle based on the hybrid of selfish herd optimizer and particle swarm optimizer. Appl Intell 52(14):16775–16798. https://doi.org/10.1007/s10489-021-02353-y
Shi H, Lu F, Wu L et al (2022) Optimal trajectories of multi-uavs with approaching formation for target tracking using improved harris hawks optimizer. Appl Intell 52(12):14313–14335. https://doi.org/10.1007/s10489-022-03270-4
Zhang A, Zhang B, Bi W et al (2022) Attention based trajectory prediction method under the air combat environment. Appl Intell 1–15. https://doi.org/10.1007/s10489-022-03292-y
Li S, Chen M, Wang Y et al (2022) A fast algorithm to solve large-scale matrix games based on dimensionality reduction and its application in multiple unmanned combat air vehicles attack-defense decision-making. Inf Sci 594:305–321. https://doi.org/10.1016/j.ins.2022.02.025
Zhang T, Li C, Ma D et al (2021) An optimal task management and control scheme for military operations with dynamic game strategy. Aerospace Sci Technol 115:106815. https://doi.org/10.1016/j.ast.2021.106815
Guo C, Zhang J, Hu J, et al (2023) Uav air combat algorithm based on bayesian probability model. In: Fu W, Gu M, Niu Y (eds) Proceedings of 2022 International Conference on Autonomous Unmanned Systems (ICAUS 2022). Springer Nature Singapore, Singapore, pp 3176–3185, https://doi.org/10.1007/978-981-99-0479-2_292
Wu H, Li M, Gao Q et al (2022) Eavesdropping and anti-eavesdropping game in uav wiretap system: A differential game approach. IEEE Trans Wirel Commun 21(11):9906–9920. https://doi.org/10.1109/TWC.2022.3180395
Chai S, Lau VKN (2021) Multi-uav trajectory and power optimization for cached uav wireless networks with energy and content recharging-demand driven deep learning approach. IEEE J Sel Areas Commun 39(10):3208–3224. https://doi.org/10.1109/JSAC.2021.3088694
McGrew JS, How JP, Williams B et al (2010) Air-combat strategy using approximate dynamic programming. J Guid Control Dyn 33(5):1641–1654. https://doi.org/10.2514/1.46815
Crumpacker JB, Robbins MJ, Jenkins PR (2022) An approximate dynamic programming approach for solving an air combat maneuvering problem. Expert Syst Appl 203:117448. https://doi.org/10.1016/j.eswa.2022.117448
Ng CBR, Bil C, Sardina S et al (2022) Designing an expert system to support aviation occurrence investigations. Expert Syst Appl 207:117994. https://doi.org/10.1016/j.eswa.2022.117994
Yu X, Gao X, Wang L, et al (2022) Cooperative multi-uav task assignment in cross-regional joint operations considering ammunition inventory. Drones 6(3). https://doi.org/10.3390/drones6030077
Xue L, Zhou R, Ran H (2022) Air combat decision based on genetic fuzzy tree. In: Yan L, Duan H, Yu X (eds) Advances in Guidance, Navigation and Control. Springer Singapore, Singapore, pp 5515–5525, https://doi.org/10.1007/978-981-15-8155-7_456
Samigulina GA, Samigulina ZI (2019) Modified immune network algorithm based on the random forest approach for the complex objects control. Artif Intell Rev 52(4):2457–2473. https://doi.org/10.1007/s10462-018-9621-7
Yu VF, Qiu M, Pan H et al (2021) An improved immunoglobulin-based artificial immune system for the aircraft scheduling problem with alternate aircrafts. IEEE Access 9:16532–16545. https://doi.org/10.1109/ACCESS.2021.3051971
Xu X, Duan H, Guo Y et al (2020) A cascade adaboost and cnn algorithm for drogue detection in uav autonomous aerial refueling. Neurocomputing 408:121–134. https://doi.org/10.1016/j.neucom.2019.10.115
Jiang H, Shi D, Xue C et al (2021) Multi-agent deep reinforcement learning with type-based hierarchical group communication. Appl Intell 51:5793–5808. https://doi.org/10.1007/s10489-020-02065-9
Puente-Castro A, Rivero D, Pazos A et al (2022) Uav swarm path planning with reinforcement learning for field prospecting. Appl Intell 52(12):14101–14118. https://doi.org/10.1007/s10489-022-03254-4
Wu K, Yang Y, Liu Q et al (2023a) Hierarchical independent coding scheme for varifocal multiview images based on angular-focal joint prediction. IEEE Trans Multimed 1–13. https://doi.org/10.1109/TMM.2023.3306072
Wu K, Yang Y, Liu Q et al (2023b) Focal stack image compression based on basis-quadtree representation. IEEE Trans Multimed 25:3975–3988. https://doi.org/10.1109/TMM.2022.3169055
Wu K, Liu Q, Wang Y et al (2023c) End-to-end varifocal multiview images coding framework from data acquisition end to vision application end. Optics Express 31(7):11659–11679. https://doi.org/10.1364/OE.482141
Sun Z, Piao H, Yang Z et al (2021) Multi-agent hierarchical policy gradient for air combat tactics emergence via self-play. Eng Appl Artif Intell 98:104112. https://doi.org/10.1016/j.engappai.2020.104112
Hu D, Yang R, Zhang Y et al (2022) Aerial combat maneuvering policy learning based on confrontation demonstrations and dynamic quality replay. Eng Appl Artif Intell 111:104767. https://doi.org/10.1016/j.engappai.2022.104767
Wang B, Li S, Gao X et al (2022) Weighted mean field reinforcement learning for large-scale uav swarm confrontation. Appl Intell 1–16. https://doi.org/10.1007/s10489-022-03840-6
Yang Q, Zhang J, Shi G et al (2019) Maneuver decision of uav in short-range air combat based on deep reinforcement learning. IEEE Access 8:363–378. https://doi.org/10.1109/ACCESS.2019.2961426
Jiandong Z, Qiming Y, Guoqing S et al (2021) Uav cooperative air combat maneuver decision based on multi-agent reinforcement learning. J Syst Eng Electron 32(6):1421–1438. https://doi.org/10.23919/JSEE.2021.000121
Xianyong J, Hou M, Wu G et al (2022) Research on maneuvering decision algorithm based on improved deep deterministic policy gradient. IEEE Access 10:92426–92445. https://doi.org/10.1109/ACCESS.2022.3202918
Bae JH, Jung H, Kim S et al (2023) Deep reinforcement learning-based air-to-air combat maneuver generation in a realistic environment. IEEE Access 11:26427–26440. https://doi.org/10.1109/ACCESS.2023.3257849
Pope AP, Ide JS, Mićović D et al (2021) Hierarchical reinforcement learning for air-to-air combat. In: 2021 international conference on unmanned aircraft systems (ICUAS), IEEE, pp 275–284, https://doi.org/10.1109/ICUAS51884.2021.9476700
Yuan W, Xiwen Z, Rong Z et al (2022) Research on ucav maneuvering decision method based on heuristic reinforcement learning. Comput Intell Neurosci 2022. https://doi.org/10.1155/2022/1477078
Li B, Huang J, Bai S et al (2023) Autonomous air combat decision-making of uav based on parallel self-play reinforcement learning. CAAI Trans Intell Technol 8(1):64–81. https://doi.org/10.1049/cit2.12109
Wr Kong, Dy Zhou, Zhou Y et al (2023) Hierarchical reinforcement learning from competitive self-play for dual-aircraft formation air combat. J Comput Des Eng 10(2):830–859. https://doi.org/10.1093/jcde/qwad020
Hu J, Wang L, Hu T et al (2022) Autonomous maneuver decision making of dual-uav cooperative air combat based on deep reinforcement learning. Electronics 11(3):467. https://doi.org/10.3390/electronics11030467
Cao Y, Kou YX, Li ZW et al (2023) Autonomous maneuver decision of ucav air combat based on double deep q network algorithm and stochastic game theory. Int J Aerosp Eng 2023. https://doi.org/10.1155/2023/3657814
Jiang F, Xu M, Li Y et al (2023) Short-range air combat maneuver decision of uav swarm based on multi-agent transformer introducing virtual objects. Eng Appl Artif Intell 123:106358. https://doi.org/10.1016/j.engappai.2023.106358
Zhang H, Zhou H, Wei Y et al (2022) Autonomous maneuver decision-making method based on reinforcement learning and monte carlo tree search. Front Neurorobot 16:996412. https://doi.org/10.3389/fnbot.2022.996412
Sutton RS (2018) Reinforcement learning: An introduction. MIT press
Van Houdt G, Mosquera C, Nápoles G (2020) A review on the long short-term memory model. Artif Intell Rev 53:5929–5955. https://doi.org/10.1007/s10462-020-09838-1
Austin F, Carbone G, Falco M, et al (1987) Automated maneuvering decisions for air-to-air combat. In: Guidance, navigation and control conference, p 2393, https://doi.org/10.2514/6.1987-2393
Yu X, Wang Y, Qin J et al (2023) A q-based policy gradient optimization approach for doudizhu. Appl Intell 53(12):15372–15389. https://doi.org/10.1007/s10489-022-04281-x
Li X, Xiao J, Cheng Y et al (2023) An actor-critic learning framework based on lyapunov stability for automatic assembly. Appl Intell 53(4):4801–4812. https://doi.org/10.1007/s10489-022-03844-2
Acknowledgements
This work is supported by a grant from Key Laboratory of Avionics System Integrated Technology, Fundamental Research Funds for the Central Universities in China, Grant No. 3072022JC0601, and the National Natural Science Foundation of China under Grant No. 52171332.
Author information
Authors and Affiliations
Contributions
Formal analysis and investigation: Zhengkun Ding, Junzheng Xu, Jiaqi Liu; Writing - original draft preparation: Luyu Jia; Writing - review and editing: Xingmei Wang, Chengtao Cai, Kejun Wu; authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Ethical and informed consent for data used
Ethical and informed consent for data used not applicable to this article as no datasets were used during the current study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jia, L., Cai, C., Wang, X. et al. Multi-intent autonomous decision-making for air combat with deep reinforcement learning. Appl Intell 53, 29076–29093 (2023). https://doi.org/10.1007/s10489-023-05058-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-05058-6