
Abstract
COVID-19 has significant fatality rate since its appearance in December 2019 as a respiratory ailment that is extremely contagious. As the number of cases in reduction zones rises, highly health officials are control that authorized treatment centers may become overrun with corona virus patients. Artificial neural networks (ANNs) are machine coding that can be used to find complicate relationships between datasets. They enable the detection of category in complicated biological datasets that would be impossible to identify with traditional linear statistical analysis. To study the survival characteristics of patients, several computational techniques are used. Men and older age groups had greater mortality rates than women, according to this study. COVID-19 patients discharge times were predicted; also, utilizing various machine learning and statistical tools applied technically. In medical research, survival analysis is a regularly used technique for identifying relevant predictors of adverse outcomes and developing therapy guidelines for patients. Historically, demographic statistics have been used to predict outcomes in such patients. These projections, on the other hand, have little meaning for the individual patient. We present the training of neural networks to predict outcomes for individual patients at one institution, as well as their predictive performance using data from another institution in a different region. The research output show that the Gradient boosting longevity model beats the all other different models, also in this research study for predicting patient longevity. This study aims to assist health officials in making more informed decisions during the outbreak.
Similar content being viewed by others
Keywords
1 Introduction
COVID-19 has quickly expanded throughout several countries, and overcrowded hospitals may be a direct result of the rapid rise in corona virus cases. The COVID-19 pandemic's rapid spread has caused a public health emergency and raised global concern. The rapid epidemic of corona virus in the year 2020 shook the entire world, affecting both symptomatic and asymptomatic COVID-19 carriers. Many cases of COVID-19 have begun to emerge to rise at multiple hospitals, primarily in Chennai and other cities of importance elsewhere, as the deadly virus from Chennai spread across the country. In fact, hospitals and medical institutions that were proven to be harboring corona virus patients were shuttered in March 2020. Patients were swiftly transferred to alternative care units once the main public hospitals were shuttered. A surge in atypical pneumonia cases was observed in Wuhan, China, in December of 2019. COVID-19, a new corona virus, was quickly identified as the source of the outbreak [1] The virus had spread to more than 175 nations as of March 2020, with four and half lakh confirmed cases and more than 19,000 deaths [2]. The death rate fluctuates throughout world population, age distribution, and health infrastructure, according to the earliest reports. COVID-19 patients in China had a death rate of 2.3 percent overall. It is possible to reduce the amount of recuperation, and discharge time can help health officials devise effective measures for lowering the mortality toll. Patients who needed to be transferred to these hospitals could only be admitted to locations that had been approved by the healthcare authorities. Patients with coronary artery disease could only be treated at specialized hospitals. As a result, patients from all across the country were gradually relocated to these places, limiting the spread of the disease. This period is critical because it provides decision-makers with the information they need to plan for hospital overcrowding.
2 Methodology
Early research has indicated that statistical analysis may be used to develop predictive models for COVID-19 problems in order to identify death rates and their risk factors [3,4,5]. In medical research, there are many techniques for predicting survival rate of infected patients. But we are used in this work to construct models with the ability to anticipate of forecasting patient’s length of stay in the hospital utilizing patient release time as the intriguing occurrence. We apply techniques for determining survival analysis technologies in this research to estimate periods of patient survival and investigate the impact of primary risk factors that influence the likelihood of being discharged from the hospital. We adopt perfectly matched approaches with the ability to analyzing censored cases, resulting in more trustworthy results by avoiding large data shrinkage. Experimental approaches introduce these methods to examine the link between hazard elements and the fascinating occurrence in clinical research, reliable approaches for censored data [1, 6]. It has been frequently used to predict corona prognosis in order to aid in the optimization and improvement of corona treatment [2, 7,8,9]. Survival analysis is one of the most well-known types of research is Cox [6, 10, 11] PH regression. It has been commonly employed in several forecasts of prognosis tasks and has been implemented in many well-known software tool boxes [4] (Figs. 1 and 2).

Analysis diagram

Censoring diagram
2.1 Analysis of Longevity
Survival analysis is a well-known statistical technique for predicting the elapsed time until a notable event over a particular time frame or a variety of applications; it is common to use survival analysis in the economy [12] as well as health care [13]. The point at which a patient is released from the hospital is the event of interest in this study [14,15,16]. A continuous variable is predicted using analysis of longevity, which is a type of regression. The key distinction between these sorts of backward and backward traditional approaches is that model data for analysis of longevity noted partially.
Censoring
According to the examination of survival data, some study participants did not experience the occurrence of interest at the completion of the research or during the analysis. At the end of the experiment, some patients may still be alive or in remission. These are the topics. It's impossible to say how long you’ll live. Observations or times that have been censored are referred to as censored observations or censored times, respectively. A person does not have the opportunity to see the incident before the study concludes. A person is lost to follow-up during the study term. An individual drops out of the research for a variety of reasons (assuming death is not the event of interest) [17]. Intervals, right censoring, and left censoring.
Survival Function
The function S(t) describes the likelihood that a person will live longer than t.S(t) = p(T > t) = 1 (Before t, a person fails). S(t) is a non-increasing time function that has the property. If t = 0, S(t) is 1, and if t = 1, S(t) is 0. The cumulative survival rate is another name for the function S(t),‘t’ is the current time, T is the death time, and P is probability. The function of survival, in other words, the likelihood that the moment of death will be later than a specified time [12]. The function is also known as the survivorship function in biological survival problems [18]. Simply, the probability of failure in a brief interval per unit time is calculated in the short interval t and to (t + ∆t) per unit width t.
Hazard Function
The “h” is the survival function of hazard over time (t). The conditional failure rate is denoted by the letter T. This is defined as the top the upper limit likelihood that a person fails in a major way short time period (t + ∆t) if someone unique survives to time t [19].
The pdf and the cdf (t) can also be used to define the hazard function (t).
The instantaneous failure rates, as well as the force of failure of mortalities, age and rate of conditional mortality specific failure rate are all terms used to describe the hazard function. The cumulative hazard function is defined as follows:
The KM estimator uses life-time data to estimate the survival function. It could be used in medical research to determine the percentage of patients who live for a specific amount of time after treatment [13]. Let S(t) denote the probability that an item from a given population would outlive t. For a population with this size of sample,
Let t1 ≤ t2 ≤ t3 ≤ ⋯ ≤ tN be represent the N sample members’ observed periods until death. ni of each ti corresponds to the number “at risk” just before time ti and di, the death count at a certain point in time ti. The KM estimator provides a nonparametric MLE of S(t).
Cox Proportional Hazard Model
The model in which the probability of dying the values x1, x2, x3, …, xp of p explanatory variables X1, X2, X3, …, Xp determine what happens at any given time. The values will be presumed to have been recorded during the study period [12,13,14, 17,18,19,20]. The vector x will in the proportional hazard model, represent the collection of values of the explanatory factors, with x = (x1, x2, x3, …, xp). Let h0(t) be the function of hazard for a person whose explanatory variables in the vector x are all zero [15, 16, 21, 22]. The base line hazard function is referred to as h0(t). The function of hazard for the ith someone unique may then be represented as
2.2 Artificial Neural Networks—ANN
Technology is becoming more integrated in our daily lives by the minute, and firms are increasingly relying on learning algorithms to make things easier in order to stay up with the pace of consumer demands. These technologies are typically connected with artificial intelligence, machine learning, deep learning, and neural networks, and while they all play a part, these phrases are sometimes used interchangeably in speech, leading to some misunderstanding about the differences between them. Hopefully, we’ll be able to clear up some of the confusion with this blog article.
Neural networks more specifically, Artificial Neural Networks (ANNs) use a set of algorithms to simulate the human brain. A neural network is made up of four parts: inputs, weights, a bias or threshold, and an output. The algebraic formula would be similar to linear regression: The premise behind ANNs is that the human brain's functioning can be mimicked by employing silicon and wires as living neurons and dendrites. The human brain is made up of 86 billion neurons. Axons connect them to tens of thousands of other cells. Dendrites take external stimuli as well as sensory organ input. Electric impulses are created by these inputs and travel fast across the neural network. These inputs create electric impulses, which quickly travel through the neural network. A neuron can then send the message to other neuron to handle the issue or does not send it forward (Figs. 3 and 4).

Basic structure of ANN

ANNs are composed of multiple nodes, which imitate biological neurons of human brain. The output at each node is called its activation or node value
Artificial neural networks (ANNs) are extremely strong computational models inspired by the brain. They’ve been used in a variety of fields, including computing, medicine, engineering, economics, and many more. The optimization theory is the foundation of an Artificial Neural Network. ANN is a machine coding based on how the hominal brain works. It is made up of a group of utopian neurons that are coupled with other neurons and are controlled by the neural network's weights. As in a neural network, the word network refers to the connections between neurons in different layers of a system. The connections between the utopian that govern the consequence of one neuron on another are represented by these weights (Figs. 5 and 6).

Neural network layers

Multi-layer perceptron
Before being delivered to the next layer's neurons, the data is mathematically processed. The output is supplied by the neurons in the last layer. The jth neuron in a hidden layer processes the incoming data (xi) by (i) calculating the weighted sum and adding a “bias” term (θj) according to
2.3 Methods and Details
This data was gathered from the Internet. Data is widely taken from national health reports and Internet resources, which are primarily published by various nations, according to the dataset descriptions. Case number, age, gender, and symptom beginning date, date of admission, infection, death, status discharge of, symptoms, chronic, travel history, and location are among the epidemiological details collected. Preparing data for statistical analysis and training, several filtering techniques are used. Missing data points in incomplete situations are first deleted from the dataset. Only a few parameters, such as age, gender, and available dates, as well as the final result are maintained in among the datasets available variables. Finally, the data filtered and reformatted because of the format inconsistencies in certain areas, such as age and outcome characteristics. Calculating the days following the start of from the research until the event accessible date is one of the most difficult aspects of survival analysis (censoring days). Although all cases have a beginning date, censor days are estimated by difference the case's commencement the last known date. The data must then be restructured in order to be suitable analysis methodologies. The status of the case is the first element in the data that is structured (censored or uncensored). The current situation is set to uncensored (True) for cases that have been discharged, whereas the status is set to censor for cases with no available result information (False).
Days of censorship or incident is the second component. Age and gender are now included as predictive variables. In the last step, therefore, a more complete description of them is required. One of the key goals of this research is to see how distinct age and gender groups affect survival of the patient. The quartiles of age are used to divide it into four categories, as seen in Fig. 2. Because the variable sex is a category unstable with a duplicate encoding is used to convert converting into a monetary cost that may be used in subsequent analysis. Nonetheless, the studies drawbacks, the dataset lacks blood type, for example, is another potential risk factor and BMI, or only comprises a small number of patient’s preconditions [18, 19].
The beginning date is presumed to be the same as the date when the symptoms first appeared or when you were admitted to the hospital in this study. For many samples, the discharge time data, on the other hand, is not accurate uncertain. The date of the most recent follow-up is used when the censorship period progresses in these circumstances. Survival analysis experts have created a variety of statistical and machine-learning methods to solve prediction challenges in a variety of domains. According to Fig. 5, the KM estimator, Cox PH, Cox net, and Accelerated Failure Time are the statistical practices to be evaluated. Additionally, Stage wise GB, Component wise GB, and SVMs are employed as machine-learning techniques. The following sections compare and contrast these strategies.
Estimator Kaplan–Meier massive volumes of a large amount of data suppressed to providing only a portion of the information, as previously discussed. However, in some cases, lowering the sample size is preferable, sometimes known as a great full tool. An event's probability of occurrence is first computed at a specified time. The final survival estimate is calculated by multiplying these sequential probabilities. Despite its advantages, the KM estimator is not without flaws. For example, KM is not an acronym, adequate estimator for concurrently accounting for the impact of a range of factors on survival [21]. Furthermore, unlike other health care challenges where the intriguing event is frequently the incidence of a hazard, the time it takes for the patient to recover is the event of interest in our work. As a result, the reverse of KM estimator, an updated version of the KM estimator, is utilized. Cox PH is a proportional hazard model. Cox PH is a semi-parametric and linear technique for estimating the influence of each factor affecting survival on the overall cohort.
Cox PH is built on assumptions and limits that limit its applicability, according to Wang et al. [22]. The traits are thought to grow at a rate that is exponential. Impacts on the final outcome in addition, all people are believed to have the same hazard functions. Furthermore, because the baseline hazard function hasn’t changed, h0(t) remains undefined, which makes it unsuitable for a number of real-world conditions. One of Cox PH’s faults is that it is prone to over fitting [23]. Datasets containing a large number of dimensions and samples not only is this a problem as a result of it, but it also has a negative impact on the environment. Despite the fact that the training may be extensive, Cox PH is likely to retain the information. The materials for training, furthermore, Cox PH is useless when there is multico-linearity. Inside the data gathering, a standardized version of the Cox net model, often known as Cox PH, is investigated to address these issues.
3 Data Analysis
The longevity (survival) models are widely used longevity analysis of are shown here. The parametric models are based on descriptive distributions and are only dependent on genuine unknown categories, such as the Cox model and require unknown functions to be estimated (Table 1).
Now that large amount datasets are available, such as artificial intelligence (AI or machine learning). Those algorithms can be interpreted in a probabilistic way. Several of the previous methods are shown here. We provide the neural networks technique as an alternative to the latter methods, which include neural networks, SVM, random forests, and others (see Hastie, Tibshirani, et al. (2005) [1] second edition, January 2017). For large data prediction, neural networks have a track record of success.
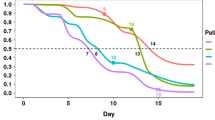
Figure 7a Discharge time probability estimation in various age and sex groups (A) Gender groups’ discharge time likelihood eftsoon displaying attributes. (B) Probability of Gender groups’ discharge time of post-dispensary. (C) Prediction of discharge time for two age groups. (D) Prediction of discharge time for four age groups.

a Discharge time prob. estimation, b range of four age groups, and c censorship diagram
Figure 7b 360-degree four age groupings 35, 45, and 60, respectively, are the first, second, and third quartiles.
Figure 7c Censor data A, B, and D have not influenced at end of the research, so censored but not C.
Discussion
In this section, we examine the consequence of span and sex as two important peril factors on the performance of machine-learning approaches employed in patient survival prediction based on Fig. 1.
Time prediction-Discharge
We present and compare the outcomes of 360 patients’ rebate-time prediction techniques. Taking much action into account, because of being censored data’s, the traditional AUC isn’t applied to evaluate the effectiveness of these models. Instead, the concordance index is used to compare model performance in discharge time prediction (C-index) [11]. For example, if patient A’s current event occurs before patient B, and thus A’s anticipate time frame for the event occurs before B’s, this pair is termed concordant, regardless of how long before B’s event occurs. Among the six algorithms tested in this study, IPC Ridge had the lowest accuracy. If the algorithm's assumptions are violated, the algorithm is supposed to behave unpredictably. Because the survival data distribution in this study is unknown also the features, the IPC Ridge executes at random [11, 24, 25]. After the event converting categorical features to numerical, the Cox Proportional Hazard (Cox PH) and Cox net models produce identical findings because the numerical value conquers many features. Regular SVM beats the kernel function, according to the findings. The findings indicate that the dataset contains no major non-linear dependency, and that the relationship between characteristics and survival rate can be linear (Table 2).
As a result, because of the existence of censored data’s, the traditional AUC isn’t employed to evaluate the effectiveness of longevity models. When comparing the approaches increasing, the results show that the Stage wise GB algorithm is not only more accurate than the other boosting methods, but also outperforms other algorithms in terms of accuracy in discharge time prediction. Because the ensemble method uses a collection of decision trees (DTs) rather than a single predictor, it tends to produce the best output in this investigation. Deep learning, like the aforementioned methods, is a strong technology that can be applied in a variety of domains and can be continued to analyzed data. This strategy, like the boosting methods, necessitates a higher number of samples so that their performance may be compared equitably in the future research.
Discharge Rate in Hospital
In addition to testing the accuracy of machine approaches, measuring clinical discharge time for different age and gender levels is critical. Some data points are censored, as illustrated in Fig. 7a. The possession of the reversed KM estimator can be applied to construct the probabilities of patient discharge time. Figure 1a shows that male hospitalized patients have a higher chance of recovering and being discharged in the first 15 days after exhibiting symptoms than females. This ratio is very higher for the first 15 days, beyond that, till roughly 35–45 days after the onset of cures; females have a slightly better chance of recovery. Males had a greater average chance of being discharged from the hospital. Females had a 5% higher likelihood of being discharged from hospital than males, according to the failure ratio in relation with gender calculated from the Cox PH. Furthermore, Pan et al. [17] found that the average probability of mean time is 43 for both gender of patients from hospitalization to discharge is about 1 to 17 days. However, after 27 days, according to Fig. 1b, this likelihood is nearly one. The gap between these reported figures could be due to a difference in the applied data.
The gap amid the announced the outcomes could be due to a variation in the data used and the quantity of patients. Nonetheless, because this article examines a much larger number of cases, the variability of the results must be smaller. Span is important peril factors employed in this research to predict longevity times, and its impact on patient survival is of great importance. Age is divided into four subgroups using the first, second, third quartiles of age ranges. The influence of span on clinical rebate rates is depicted in Fig. 1c and d. It is obvious that these age groups are separated by clear lines. Aside from the KM outputs, the coefficient of Cox PH for age suggests that raising the age by one unit (year) reduces the likelihood of being discharged from the hospital by about 3%. Finally, to assess the effect of sex in aged patients, a second research is undertaken for middle age cases, which is 46 years. Females have a probability of recovery of 0.86 after 35 days, while males have a probability of recovery of 0.83 after 37 days, according to the findings. This survival rate shows that elderly women have slightly higher testosterone levels.
4 Conclusion
This study examines the accuracy of different survival analysis models in predicting the rebate time of patients using clinical data from 360 COVID-19 patients. To begin, the results show that when simply age and sex are used as model parameters, Stage wise GB gives the best accurate rebate-time prediction when compared to the others. This research provides a baseline criterion for future research one more extensive clinical data is available, because model features such as age and gender are used to make predictions. Second, the results of the KM and Cox methods reveal that the gender and span of clinical patients have a direct impact on their cure time. The results show that being a man or aged group is linked to a decreased likelihood of getting discharged from the hospital. For future research investigations, this study serves as a baseline for predicting recovery times. Once they become available, other peril factors, such as patient pre status, will be able to be assessed for their impact on patient survival.
References
Li Q, Guan X, Wu P, Wang X, Zhou L, Tong Y, Ren R, Leung KS, Lau EH, Wong JY, Xing X (2020) Early transmission dynamics in Wuhan, China, of novel coronavirus-infected pneumonia. N Engl J Med 382:1199–1207
World Health Organization (2020) Coronavirus Disease 2019 (COVID-19): Situation Report, 61. https://apps.who.int/iris/handle/10665/331605?show=full
Ji JS, Liu Y, Liu R, Zha Y, Chang X, Zhang L, Zhang Y, Zeng J, Dong T, Xu X, Zhou L (2020) Survival analysis of hospital length of stay of novel coronavirus (COVID-19) pneumonia patients in Sichuan China. medRxiv. https://doi.org/10.1101/2020.04.07.20057299
Li X, Xu S, Yu M, Wang K, Tao Y, Zhou Y, Shi J, Zhou M, Wu B, Yang Z et al (2020) Risk factors for severity and mortality in adult COVID-19 inpatients in Wuhan. J Allergy Clin Immunol 146:110–118
Du RH, Liang LR, Yang CQ, Wang W, Cao TZ, Li M, Guo GY, Du J, Zheng CL, Zhu Q, Hu M (2020) Predictors of mortality for patients with COVID-19 pneumonia caused by SARS-CoV-2: a prospective cohort study. Eur Respir J 55:2000524
Mahase E (2020) Coronavirus: Covid-19 has killed more people than SARS and MERS combined, despite lower case fatality rate. BMJ 368:m641
Wu Z, McGoogan JM (2020) Characteristics of and important lessons from the coronavirus disease 2019 (COVID-19) outbreak in China: summary of a report of 72 314 cases from the Chinese center for disease control and prevention. JAMA 323(1239–1242):5
Dowd JB, Andriano L, Brazel DM, Rotondi V, Block P, Ding X, Liu Y, Mills MC (2020) Demographic science aids in understanding the spread and fatality rates of COVID-19. Proc Natl Acad Sci U S A 117:9696–9698
Livingston E, Bucher K (2020) Coronavirus disease 2019 (COVID-19) in Italy. JAMA 323:1335
Uno H, Cai T, Pencina MJ, D’Agostino RB, Wei LJ (2011) On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat Med 30:1105–1117
Fotso S (2018) Deep neural networks for survival analysis based on a multi-task framework. arXiv, 1801.05512
Zhou F, Yu T, Du R, Fan G, Liu Y, Liu Z, Xiang J, Wang Y, Song B, Gu X, Guan L (2020) Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: a retrospective cohort study. Lancet 395:1054–1062
Xu B, Gutierrez B, Mekaru S, Sewalk K, Goodwin L, Loskill A, Cohn EL, Hswen Y, Hill SC, Cobo MM, Zarebski AE (2020) Epidemiological data from the COVID-19 outbreak, real-time case information. Sci Data 7:1–6
Ji W, Wang X, Zhang D (2016) A probabilistic multi-touch attribution model for online advertising. In: Proceedings of the 25th ACM international on conference on information and knowledge management, pp 1373–1382
Reddy CK, Li Y (2015) A review of clinical prediction models. Healthc Data Analytics 36:343–378
Po¨ lsterl S, Gupta P, Wang L, Conjeti S, Katouzian A, Navab N (2016) Heterogeneous ensembles for predicting survival of metastatic, castrate-resistant prostate cancer patients. F1000Res 5:2676
Pan F, Ye T, Sun P, Gui S, Liang B, Li L, Zheng D, Wang J, Hesketh RL, Yang L, Zheng C (2020) Time course of lung changes on chest CT during recovery from 2019 novel coronavirus (COVID-19) pneumonia. Radiology 295:715–721
Brentnall AR, Cuzick J (2018) Use of the concordance index for predictors of censored survival data. Stat Methods Med Res 27:2359–2373
Ruan Q, Yang K, Wang W, Jiang L, Song J (2020) Clinical predictors of mortality due to COVID-19 based on an analysis of data of 150 patients from Wuhan China. Intensive Care Med 46:846–848
Pencina MJ, D’Agostino RB Sr (2015) Evaluating discrimination of risk prediction models: the C statistic. JAMA 314:1063–1106
Kourou K, Exarchos TP, Exarchos KP, Karamouzis MV, Fotiadis DI (2015) Machine learning applications in cancer prognosis and prediction. Comput Struct Biotechnol J 13:8–17
Abbasi-Kesbi R, Memarzadeh-Tehran H, Deen MJ (2017) Technique to estimate human reaction time based on visual perception. Healthc Technol Lett 4:73–77
Goel MK, Khanna P, Kishore J (2010) Understanding survival analysis: Kaplan-Meier estimate. Int J Ayurveda Res 1:274
Farhangi A, Bian J, Wang J, Guo Z (2019) Work-in-progress: a deep learning strategy for I/O scheduling in storage systems. In: 2019 IEEE real-time systems symposium (RTSS), IEEE, pp 568–571
Fotso S (2019) PySurvival: open source package for survival analysis modeling. https://square.github.io/pysurvival/
https://ourworldindata.org/explorers/coronavirus-data-explorer?zoomToSelection=true&time=2020-03-01
https://datacatalog.worldbank.org/search/collections/coronavirus-%28COVID-19%29-related-datasets
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Muruganandham, S., Venmani, A. (2023). Survival Analysis and Its Application of Discharge Time Likelihood Prediction Using Clinical Data on COVID-19 Patients-Machine-Learning Approaches. In: Mahapatra, R.P., Peddoju, S.K., Roy, S., Parwekar, P. (eds) Proceedings of International Conference on Recent Trends in Computing. Lecture Notes in Networks and Systems, vol 600. Springer, Singapore. https://doi.org/10.1007/978-981-19-8825-7_28
Download citation
DOI: https://doi.org/10.1007/978-981-19-8825-7_28
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-8824-0
Online ISBN: 978-981-19-8825-7
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)