
Abstract
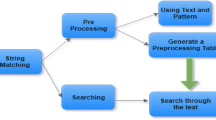
There are hot patterns of huge data sets in numerous regions in the course of the most recent 5 years. Looking through string or pattern from a gigantic record is intense generally in the event of randomized situation. These require the advancement of new algorithmic strategies to investigate such enormous data sets and solve optimization errands utilizing sorting on indexing levels and Applied Machine Learning Models. One of the essential strides in text processing is string searching and pattern matching. A word search algorithm works by finding the first or all the occurrences of a word in a textual data or ASCII files. The pre-processing phase is used to determine the formula for number of positions by which the pattern needs to be shifted in case of a mismatch in the matching phase. The fundamental objective of string search or pattern matching algorithms is to increase efficiency by reducing the number of comparisons and increase the length of shifts in event of a mismatch. The issue of efficiency of string search algorithms has probably never been considered so seriously and genuinely until the virtual content explosion caused by the web and the task of mining valuable data and information from it. In this paper, a better search algorithm “Tara–Paras String Search” is introduced that is faster than conventional Binary Search and Interpolation Search. Indexing levels are introduced by length of the word, sequence total of alphabets and starting letter of the word to reduce the size of input. For analysis, 2 data sets are considered. The dictionary of English words having more than 109,000 words and a list of more than 2.5 Lac sorted numbers and uniformly distributed (multiples of 7) are taken for data sets. Analysis and Implementations Models have been implemented, compared and executed in Python with time complexity and obviously Applied Machine Learning will select the faster one.

Similar content being viewed by others


References
Boyer RS, Moore JS. A fast string searching algorithm. Commun ACM. 1977;20:762–72.
Knuth DE, Morris JH, Pratt VR. Fast pattern matching in strings. Siam. 1977;6(2):323–50.
Horspool RN. Practical fast searching in strings. Softw Pract Exp. 1980;10:501–6.
Karp RM, Rabin MO. Efficient randomized pattern-matching algorithms. IBM J Res Dev. 1987;31(2):249–60.
Raita T. Tuning the boyer-moore-horspool string searching algorithm. Softw Pract Exp. 1992;22(10):879–84.
Haddi E, Liu X, Shi Y (2013) The role of text pre-processing in sentiment analysis. In: International conference on information technology and quantitative management, pp 231–234
Gurung D, Chakraborty UK, Sharma P (2016) Intelligent predictive string search algorithm. In: Proceedings of international conference on communication, computing and virtualization (ICCCV) 2016, Elsevier procedia computer science, vol 79, pp 161–169
Arne A, Mattsson C (1993) Dynamic interpolation search in o(log log n) time. In: Proceeding of the 20th int colloquium on automata, languages and programming, London, UK, pp. 15–27
Saha G, Raju SS. Interpolation sort and its implementation with strings. Int J Comput Theory Eng. 2012;4(5):772–6.
Knuth D (1998) Sorting and searching. The art of computer programming.3 (2 ed.)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Author Dr. Paras Nath Singh declares that he has conflict of interest. Authur Tara P. Gowder declares that she has no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Data Science and Communication” guest edited by Kamesh Namudri, Naveen Chilamkurti, Sushma S. J. and S. Padmashree.
Rights and permissions
About this article

Cite this article
Singh, P.N., Gowdar, T.P. Searching String in Big-Data: A Better Approach by Applied Machine Learning. SN COMPUT. SCI. 2, 192 (2021). https://doi.org/10.1007/s42979-021-00569-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-021-00569-w